本章参考ARM Cortex-A(armV7)编程手册V4.0文档和uboot的cache-v7.s
目录
[场景1:CPU 准备让其他主设备读取数据](#场景1:CPU 准备让其他主设备读取数据)
[场景2:其他主设备修改了数据,CPU 需要读取](#场景2:其他主设备修改了数据,CPU 需要读取)
[2,cache line的概念](#2,cache line的概念)
[3,cache way 概念](#3,cache way 概念)
[2,通过CSIDR读取cache line](#2,通过CSIDR读取cache line)
[5,dsb(Data Synchronization Barrier)](#5,dsb(Data Synchronization Barrier))
[五, cache invalid clean flush的实现逻辑](#五, cache invalid clean flush的实现逻辑)
[1,dcache invalid](#1,dcache invalid)
[2,dcache clean](#2,dcache clean)
[3,dcache full](#3,dcache full)
一,cache一致性
场景1:CPU 准备让其他主设备读取数据
(例如:DMA 输出,CPU → 外设)
CPU 修改数据 → 内存 → 外设读取需求:
-
确保 CPU 的修改到达内存
-
外设从内存读取到最新数据
-
CPU 之后可能还要访问这些数据(保留在缓存中)
操作选择 :✅ Clean 只清理
clean_cache_range(buffer, size);
// 或 DCCMVAC 指令原因:
-
只需要把脏数据写回内存
-
CPU 缓存可以保留副本(可能还会使用)
-
不需要失效(CPU 的副本仍然有效)
场景2:其他主设备修改了数据,CPU 需要读取
(例如:DMA 输入,外设 → CPU)
外设写入数据 → 内存 → CPU 读取需求:
-
确保 CPU 缓存中的旧副本被丢弃
-
CPU 从内存加载外设写入的新数据
-
不关心 CPU 之前的修改是否写回(通常不应有脏数据)
操作选择 :✅ Invalidate 只失效
invalidate_cache_range(buffer, size);
// 或 DCIMVAC 指令前提条件:
-
必须确保 CPU 对该区域没有脏数据需要保留
-
如果可能有脏数据,必须先 Clean,或者使用 Clean+Invalidate
场景3:双向共享缓冲区
(CPU 和外设交替读写同一块内存)
需求:
-
需要完整的缓存行所有权转移
-
保证没有数据丢失
操作选择 :✅ Clean and Invalidate 清理并失效
clean_invalidate_cache_range(buffer, size);
// 或 DCCIMVAC 指令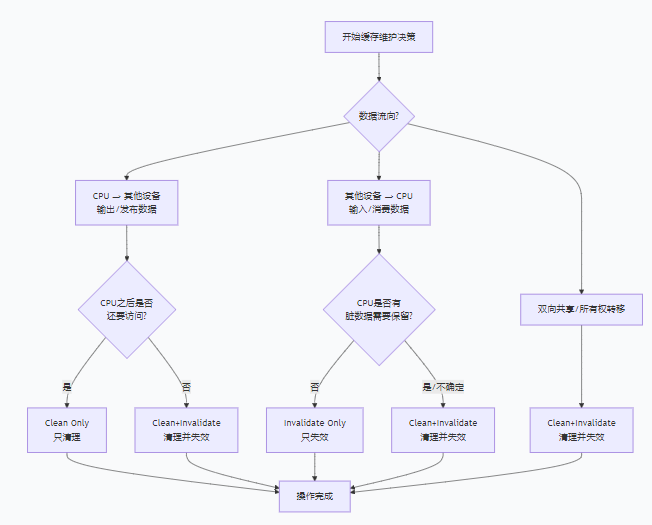
二,armv7的cache关键概念
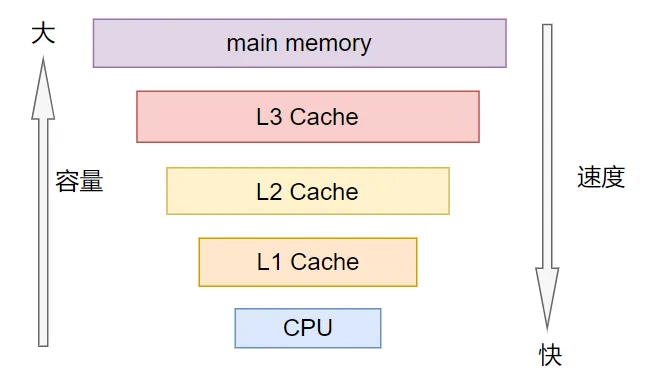
1,多级Cache存储结构
通常来说,Cache不止一个,而是有多个,即多级Cache,为什么呢?
原因:cpu访问cache速度也是很快的。但是我们做不到速度和容量完全兼容,如果cpu访问cache的速度跟cpu访问寄存器的速度差不多,那么就意味着这个cache速度很快,但是容量很小,这么小的cache容量还不足够满足我们的需求,因此引入了多级Cache。
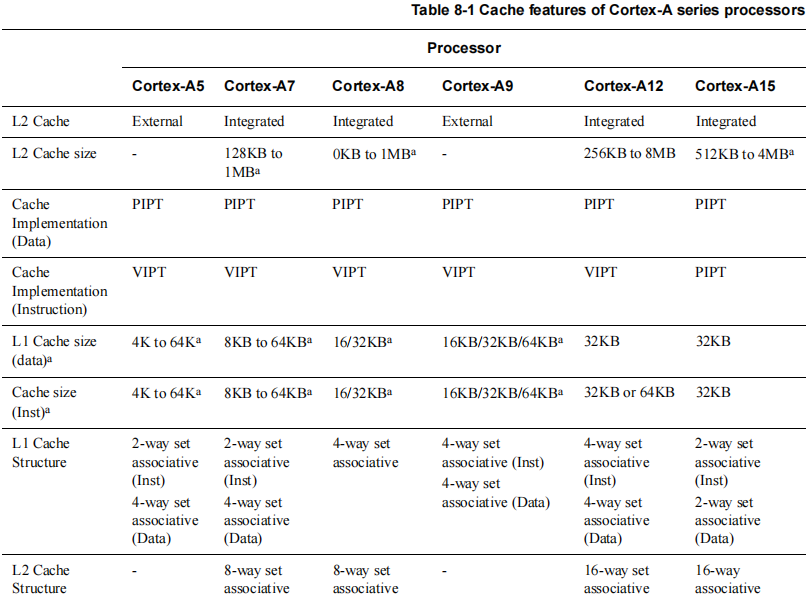
多级Cache将Cache分成多个级别L1、L2、L3等。
- 按照速度快慢,依次是L1>L2>L3。
- 按照存储容量大小,依次是L3>L2>L1
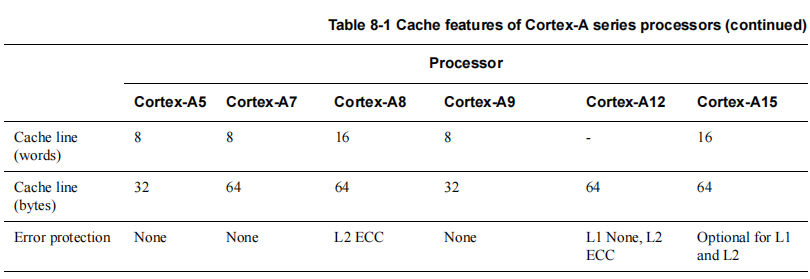
2,cache line的概念
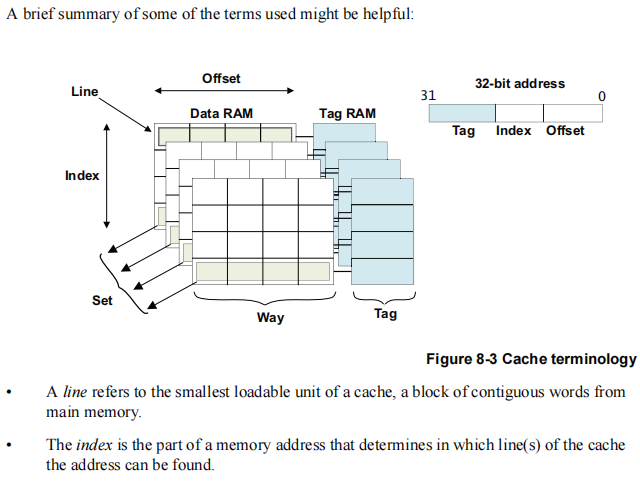
cache line:高速缓存行,将cache平均分成相等的很多块,每一个块大小称之为cache line。
cache line也是cache和主存之间数据传输的最小单位.
当CPU试图load一个字节数据的时候,如果cache缺失,那么cache控制器会从主存中一次性的load cache line大小的数据到cache中。例如,cache line大小是8字节。CPU即使读取一个byte,在cache缺失后,cache会从主存中load 8字节填充整个cache line。
CPU访问cache时的地址编码,通常由tag、index和offset三部分组成
- tag**(标记域)** :用于判断cache line缓存的数据的地址是否和处理器寻址地址一致。
- index**(索引域)** :用于索引和查找地址在高速缓存中的哪一行
- offset**(偏移量)** :高速缓存行中的偏移量。可以按字或字节来寻址高速缓存行的内容
cache line和tag、index、offset等的关系如图
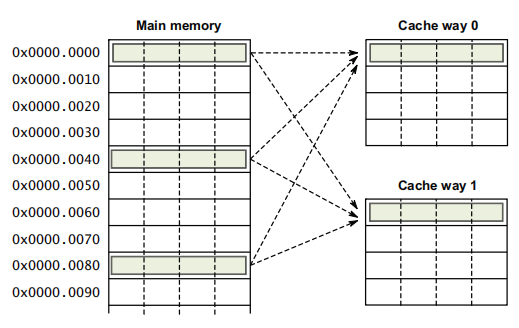
3,cache way 概念
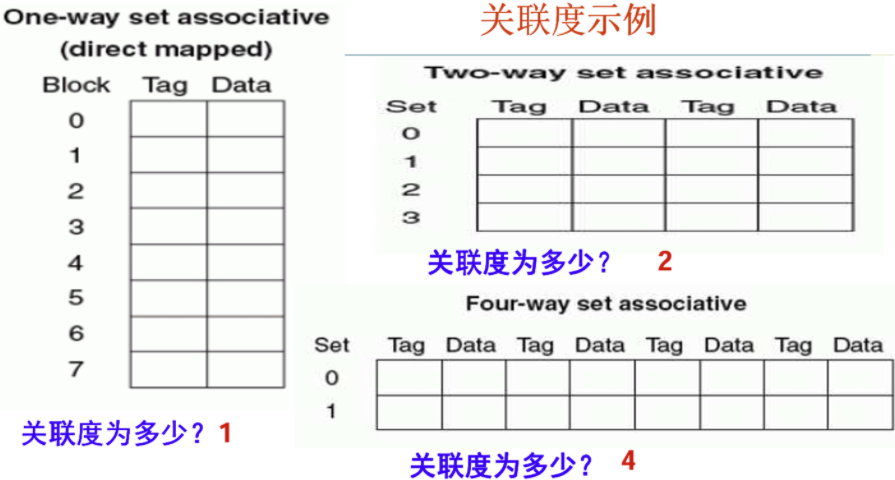
关联度越高,数据块放入缓存时选择位置的灵活性越大,可以减少冲突未命中。但更高的关联度通常会增加硬件复杂度和访问时间。
Arm v7 L1指令cache 采用2way
arm v7 L1数据cache 采用4way
arm v7 L2 cache 采用8way
arm v7 cache line 每行8word, 16byte
三,cache相关的寄存器,
1,CSIDR寄存器
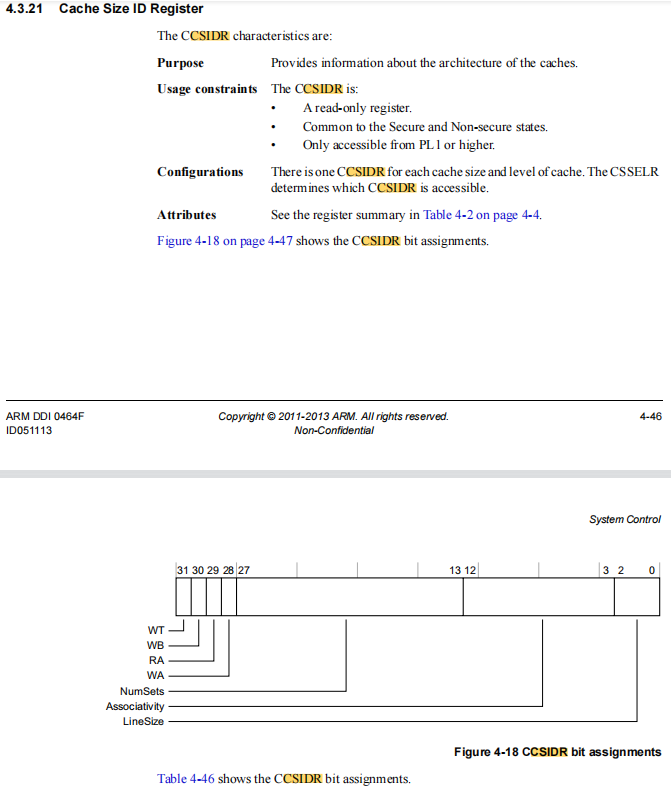
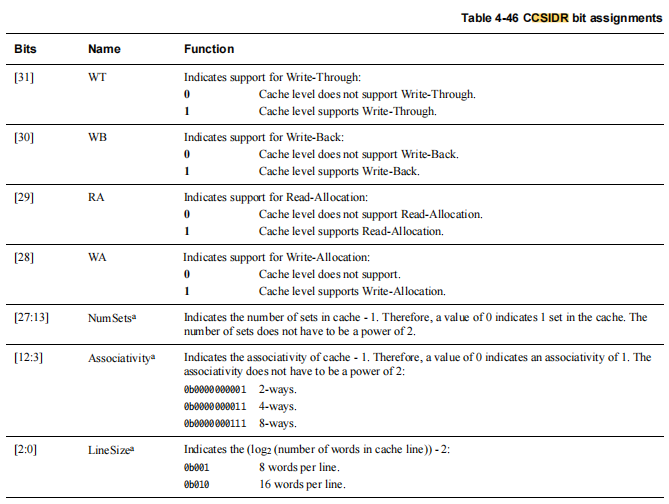
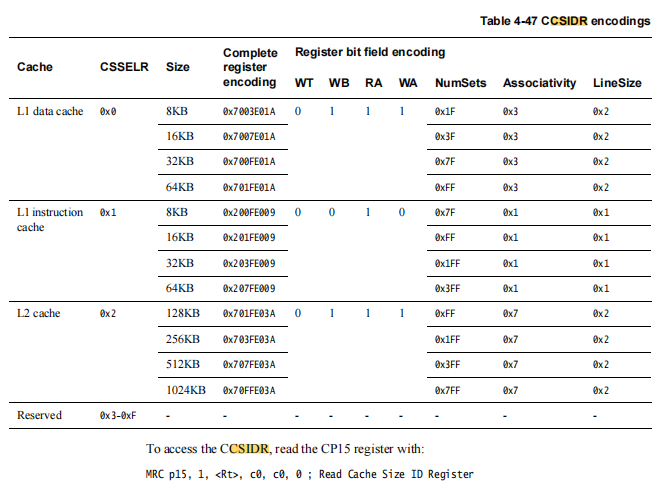
2,通过CSIDR读取cache line
从这个CPU的CTR寄存器上获取最小D-cache行大小
.macro dcache_line_size, reg, tmp
mrc p15, 1, \tmp, c0, c0, 0 @ read CSIDR
and \tmp, \tmp, #7 @ cache line size encoding
mov \reg, #16 @ size offset,8个word的byte数,bit(2-0)的基数
mov \reg, \reg, lsl \tmp @ actual cache line size,reg左移tmp位再赋值给reg
.endm
执行完成后,armv7是8word cache line,reg值为16,tmp值为1
四,cache用到的汇编指令
1,tst
tst指令用法执行两个寄存器的按位逻辑与(AND)操作,并根据结果设置状态标志(S、Z),用于条件判断(如后续条件分支指令)。
实现机制
数据读取:
读取寄存器 reg2 的值(32位)。
读取寄存器 reg1 的值(32位)。
逻辑运算:
将两个寄存器的值进行按位与操作:result = reg2 AND reg1。
标志位设置:
S(符号标志):若结果的最高位(MSB)为1,则S=1;否则S=0。
Z(零标志):若结果为0,则Z=1;否则Z=0。
OV(溢出标志):固定清零。
CY(进位标志):保持不变。
SAT(饱和标志):保持不变。
2,bic
bic (Bit Clear)位清除指令 bic指令的格式为: bic{条件}{S} Rd,Rn,operand
bic指令将Rn 的值与操作数operand2 的反码按位逻辑"与",结果存放到目的寄存器Rd 中
bic R0,R0,#0x1F ; //将R0最低5位清零,其余位不变
3,mcrne
mcr(Move to Coprocessor from ARM Register)是ARM架构中用于将ARM寄存器的数据传送到协处理器寄存器的指令。ne是ARM指令集中的一个条件执行后缀,表示"不相等"(Not Equal),当处理器的状态标志满足特定条件时,该指令才会被执行。
因此,mcrne指令的完整含义是:当上一条指令的结果不相等(Z标志位为0)时,将ARM寄存器的数据传送到指定的协处理器寄存器
mcrne p14, 0, r0, c1, c0, 0 @ 示例:当不相等时,将r0的值传送到协处理器14的c1寄存器
4,blo
ARM汇编中的BLO指令 :BLO是ARM架构中一条有条件的分支指令,用于根据特定条件决定程序的跳转方向。
- 核心功能 :它基于无符号数比较的结果进行跳转。具体来说,当比较结果为"小于"(即被比较的无符号数A小于B)时,BLO指令会触发跳转。
- 工作原理 :BLO指令的执行依赖于CPSR(当前程序状态寄存器) 中的标志位(特别是C标志位,用于指示无符号数比较的进位/借位情况)。通常,在执行BLO指令前,会先使用
CMP(比较)指令来设置这些标志位。 - 语法与应用 :其基本语法为
BLO label,其中label是目标地址的标签。它广泛应用于需要条件控制的场景,例如: - 循环控制:根据计数器或条件决定是否继续循环。
- 边界检查:在内存访问前检查索引是否在有效范围内。
- 算法优化:在查找、排序等算法中根据比较结果选择不同的执行路径。
- 状态机逻辑:实现简单的状态跳转。
- 特点:BLO指令执行效率高,执行时间相对固定,有利于性能分析。它不会改变参与比较的操作数的值,也不会清除CPSR中的标志位。
5,dsb(Data Synchronization Barrier)
确保所有在它之前的内存访问指令(如加载/存储)完成,后续指令(不限于内存操作)必须等待此屏障执行完毕
五, cache invalid clean flush的实现逻辑
1,dcache invalid
v7_cache_inv_range(start, end)
dcache_line_size r2, r3 @r2值为16,r3值为1
sub r3, r2, #1 @r3=15
tst r0, r3 @ 检查起始地址是否对齐
bic r0, r0, r3 @ 向下对齐到缓存行边界
mcrne p15, 0, r0, c7, c14, 1 @ clean & invalidate D / U line 如果未对齐,清理第一行
tst r1, r3@ 检查结束地址是否对齐
bic r1, r1, r3 @ 向下对齐到缓存行边界
mcrne p15, 0, r1, c7, c14, 1 @ clean & invalidate D / U line如果未对齐,清理最后一行
1: @ 标签:循环开始
mcr p15, 0, r0, c7, c6, 1 @ invalidate D / U line 失效当前行
add r0, r0, r2 @ 地址 += 缓存行大小
cmp r0, r1 @ 比较当前地址与结束地址
blo 1b @ 如果小于,继续循环
dsb @ 数据同步屏障
mov pc, lr @函数返回
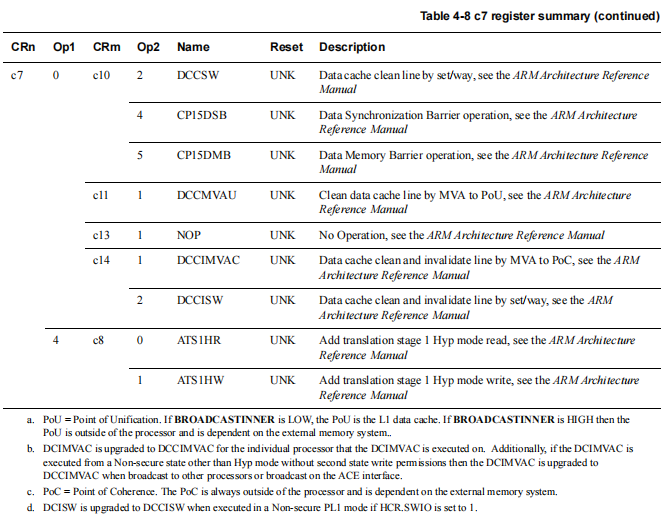
DCCIMVAC它是一个汇编指令,对指定虚拟地址对应的数据缓存行执行先清理(Clean)后失效(Invalidate) 的连续操作,并将操作传递到一致性点
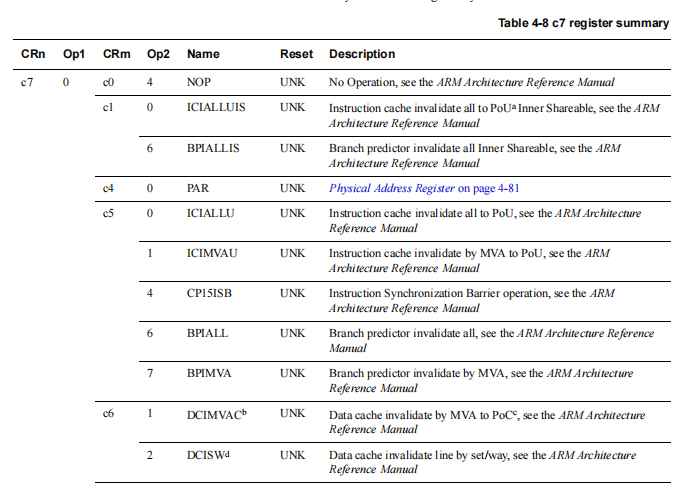
DCIMVAC 的作用是:将一个特定的虚拟地址对应的数据从 CPU 数据缓存中"踢出去",并确保系统的其他部分能看到这个变化。
它的主要应用场景是解决 CPU 缓存与内存之间的数据一致性问题。在以下情况下,CPU 缓存中的数据可能已经"过时"
2,dcache clean
v7_cache_clean_range(start, end)
dcache_line_size r2, r3
sub r3, r2, #1
bic r0, r0, r3
1:
mcr p15, 0, r0, c7, c10, 1 @ clean D / U line 清理当前缓存行 (DCCMVAC)
add r0, r0, r2 @ 地址 += 缓存行大小
cmp r0, r1 @ 比较当前地址与结束地址
blo 1b @ 如果小于,继续循环
dsb
mov pc, lr
3,dcache full
v7_cache_flush_range(start, end)
dcache_line_size r2, r3
sub r3, r2, #1
bic r0, r0, r3
1:
mcr p15, 0, r0, c7, c14, 1 @ clean & invalidate D / U line
add r0, r0, r2
cmp r0, r1
blo 1b
dsb
mov pc, lr