一、随机森林算法概述
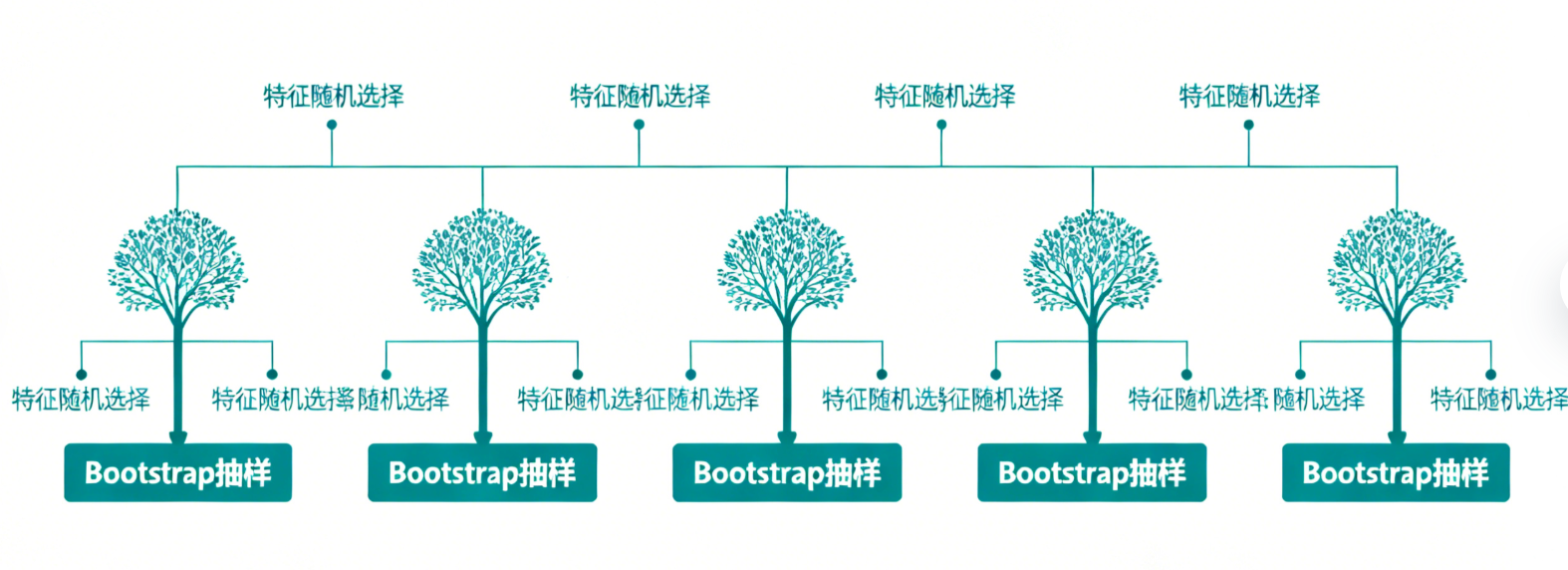
随机森林(Random Forest)是由Leo Breiman于2001年提出的一种集成学习算法,其核心思想是"集成多个弱分类器/回归器,形成一个强分类器/回归器"。它以决策树为基学习器,通过 Bootstrap 抽样和特征随机选择两种随机性策略,降低单棵决策树的过拟合风险,同时提升模型的泛化能力和稳定性。
随机森林可同时适用于分类和回归任务,在工业界、数据挖掘等领域应用广泛,兼具易实现、鲁棒性强、无需复杂特征预处理等优点,是入门集成学习的核心算法之一。
二、随机森林核心原理
2.1 两大随机性策略
随机森林的"随机"主要体现在两个层面,这也是其优于单棵决策树和传统集成方法的关键:
-
样本随机(Bootstrap 抽样):从原始训练集中,通过有放回抽样(Bootstrap)的方式,为每一棵基决策树生成独立的训练样本集。假设原始样本量为N,每次抽样均从N个样本中随机选择N个(允许重复),最终约有37%的样本不会出现在单棵树的训练集中,这部分样本被称为"袋外样本(OOB)",可用于无额外验证集的模型评估。
-
特征随机:在每棵决策树的每个分裂节点处,不使用全部特征,而是从所有特征中随机选择K个特征(K通常取√总特征数,分类任务)或K=总特征数/3(回归任务),再从这K个特征中选择最优分裂特征构建决策树。此举可降低基决策树之间的相关性,避免单特征主导模型结果,进一步抑制过拟合。
2.2 模型构建与预测流程
构建流程
-
设定基决策树数量(n_estimators),初始化模型参数。
-
对每一棵决策树,通过Bootstrap抽样生成专属训练集。
-
对每棵树的每个分裂节点,随机选择K个特征,基于信息增益、信息增益比或Gini系数选择最优分裂特征,构建决策树(不进行剪枝,保留决策树的复杂度以保证多样性)。
-
重复步骤2-3,生成n_estimators棵独立的基决策树,组成随机森林。
预测流程
-
分类任务:对新样本,每棵基决策树输出一个类别预测结果,通过"投票法"(少数服从多数)确定最终类别。
-
回归任务:对新样本,每棵基决策树输出一个回归值,通过"平均值法"计算所有结果的均值作为最终预测值。
2.3 核心优势
-
泛化能力强:通过双重随机性降低过拟合风险,对噪声数据和异常值具有较强鲁棒性。
-
支持多任务:同时适配分类、回归任务,无需修改核心逻辑。
-
可解释性较强:能输出特征重要性,辅助特征筛选和业务理解。
-
训练高效:基决策树可并行训练,提升大规模数据下的训练速度。
三、Python实战代码解析
本文基于sklearn库实现随机森林分类和回归任务,使用经典数据集演示,步骤包括数据加载、预处理、模型训练、评估及特征重要性分析。
3.1 环境准备
需安装以下依赖库:
pip install numpy pandas scikit-learn matplotlib3.2 随机森林分类实战(以鸢尾花数据集为例)
3.2.1 数据加载与预处理
鸢尾花数据集包含3类鸢尾花,共150个样本,每个样本有4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),目标是根据特征分类。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载数据集
iris = load_iris()
X = iris.data # 特征矩阵
y = iris.target # 标签
feature_names = iris.feature_names # 特征名称
# 划分训练集和测试集(7:3)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y # stratify保证类别分布一致
)3.2.2 模型训练与参数说明
sklearn的RandomForestClassifier核心参数:
-
n_estimators:基决策树数量,默认100,数量越多效果越稳定,但计算成本越高。
-
max_depth:每棵树的最大深度,默认None(不限制),可设置数值防止单棵树过深。
-
max_features:每个分裂节点随机选择的特征数,默认√总特征数(分类)。
-
random_state:随机种子,保证实验可复现。
-
oob_score:是否使用袋外样本评估模型,默认False。
初始化随机森林分类器
rf_clf = RandomForestClassifier(
n_estimators=100, # 100棵决策树
max_depth=5, # 每棵树最大深度5
max_features="sqrt", # 特征随机选择策略
oob_score=True, # 使用袋外样本评估
random_state=42
)训练模型
rf_clf.fit(X_train, y_train)
袋外样本准确率
print(f"袋外样本准确率(OOB Score):{rf_clf.oob_score_:.4f}")
3.2.3 模型评估
# 测试集预测
y_pred = rf_clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率:{accuracy:.4f}")
# 输出分类报告(精确率、召回率、F1值)
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print("\n混淆矩阵:")
print(cm)运行结果说明:鸢尾花数据集较简单,随机森林分类准确率通常可达95%以上,OOB分数与测试集分数接近,说明模型无明显过拟合。
3.2.4 特征重要性分析
随机森林可通过feature_importances_属性输出每个特征对模型的贡献度,辅助特征筛选。
# 计算特征重要性
feature_importance = rf_clf.feature_importances_
importance_df = pd.DataFrame({
"特征名称": feature_names,
"重要性": feature_importance
}).sort_values(by="重要性", ascending=False)
print("\n特征重要性排序:")
print(importance_df)
# 可视化特征重要性
plt.figure(figsize=(10, 6))
plt.barh(importance_df["特征名称"], importance_df["重要性"], color="skyblue")
plt.xlabel("重要性")
plt.ylabel("特征名称")
plt.title("随机森林分类特征重要性")
plt.gca().invert_yaxis() # 倒序显示
plt.show()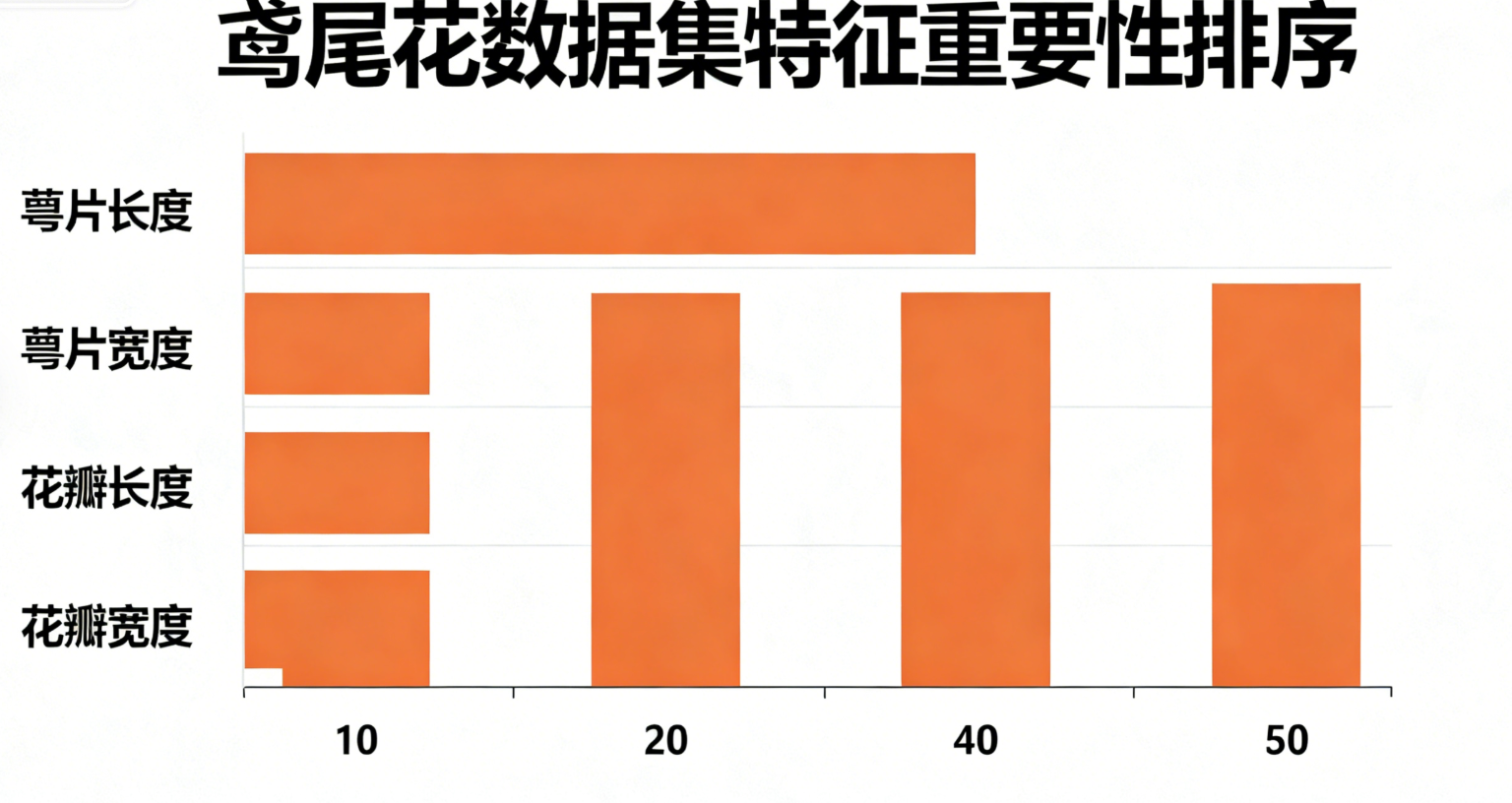
结果分析:鸢尾花数据集中,花瓣长度和花瓣宽度的重要性通常远高于花萼特征,与业务逻辑一致(花瓣特征更能区分鸢尾花品种)。
3.3 随机森林回归实战(以波士顿房价数据集为例)
波士顿房价数据集用于预测房价(连续值),共506个样本,13个特征,使用RandomForestRegressor实现回归任务。
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
# 加载数据集(sklearn 1.2.0后需通过fetch_openml获取,此处兼容旧版本)
try:
boston = load_boston()
except ImportError:
from sklearn.datasets import fetch_openml
boston = fetch_openml(name="boston", version=1, as_frame=True)
X = boston.data.values
y = boston.target.values
else:
X = boston.data
y = boston.target
feature_names = boston.feature_names
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# 初始化随机森林回归器
rf_reg = RandomForestRegressor(
n_estimators=100,
max_depth=8,
max_features="sqrt",
oob_score=True,
random_state=42
)
# 训练模型
rf_reg.fit(X_train, y_train)
# 预测与评估
y_pred = rf_reg.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print(f"袋外样本R²分数:{rf_reg.oob_score_:.4f}")
print(f"测试集MSE:{mse:.4f}")
print(f"测试集RMSE:{rmse:.4f}")
print(f"测试集R²分数:{r2:.4f}")
# 特征重要性可视化
feature_importance = rf_reg.feature_importances_
importance_df = pd.DataFrame({
"特征名称": feature_names,
"重要性": feature_importance
}).sort_values(by="重要性", ascending=False)
plt.figure(figsize=(10, 6))
plt.barh(importance_df["特征名称"], importance_df["重要性"], color="lightcoral")
plt.xlabel("重要性")
plt.ylabel("特征名称")
plt.title("随机森林回归特征重要性")
plt.gca().invert_yaxis()
plt.show()结果说明:R²分数越接近1表示回归效果越好,随机森林在波士顿房价预测中通常可达到R²>0.85,特征重要性显示RM(犯罪率)、LSTAT(低收入人口比例)等是影响房价的核心因素。
四、模型调优建议
随机森林的性能受参数影响较大,常用调优方向如下:
-
n_estimators:从100开始逐步增加,当模型性能趋于稳定时停止(避免过度增加计算成本)。
-
max_depth:针对过拟合场景,可适当减小max_depth(如3-10),无过拟合时可保留默认None。
-
max_features:分类任务可尝试√总特征数、log2(总特征数);回归任务尝试总特征数/3、√总特征数。
-
min_samples_split:每个分裂节点所需的最小样本数,默认2,增大该值可抑制过拟合。
-
使用网格搜索调优:通过sklearn的GridSearchCV自动搜索最优参数组合,示例如下:
from sklearn.model_selection import GridSearchCV
定义参数网格
param_grid = {
"n_estimators": [100, 200, 300],
"max_depth": [3, 5, 8, None],
"max_features": ["sqrt", "log2"]
}网格搜索
grid_search = GridSearchCV(
estimator=RandomForestClassifier(random_state=42),
param_grid=param_grid,
cv=5, # 5折交叉验证
scoring="accuracy", # 分类任务评估指标
n_jobs=-1 # 并行计算
)grid_search.fit(X_train, y_train)
print("最优参数组合:", grid_search.best_params_)
print("最优交叉验证准确率:", grid_search.best_score_)
五、总结
随机森林通过"多树集成+双重随机"策略,兼顾了模型性能、鲁棒性和可解释性,是解决分类、回归问题的"万能工具"之一。其核心优势在于无需复杂的数据预处理(如标准化、缺失值填充可通过决策树自身特性适配),训练高效且易落地。
在实际应用中,需根据数据规模调整n_estimators、max_depth等参数,通过特征重要性辅助业务理解,同时结合交叉验证和网格搜索优化模型性能。需要注意的是,随机森林在高维稀疏数据(如文本)上的表现可能不如SVM、神经网络,需根据数据特性选择合适算法。