一.Fine-Tuning发展史
1.1发展历程
- 第一范式:基于「传统机器学习模型」的范式,如TF-IDF特征+朴素贝叶斯等机器算法;
- 第二范式:基于「深度学习模型」的范式,如word2vec特征+LSTM等深度学习算法,相比于第一范式,模型准确有所提高,特征工程的工作也有所减少;
- 第三范式:基于「预训练模型+fine-tuningJ 的范式,如Bert+fine-tuning的NLP任务,相比于第二范式,模型准确度显著提高,模型也随之变得更大,但小数据集就可训练出好模型;
- 第四范式:基于「预训练模型+Prbmpt+预测」的范式,如Bert+Prompt的范式相比于第三范式郭羿训练所需的训练数据显著减少。
这里可能会有一个疑问,为什么使用提示词微调PLM可以完成下游任务?
因为这个PLM本身就是在这个方向上完成训练的,我们使用Prompt微调的目标的是和PLM目标相似的任务
微调的前提条件是你需要找到一个和你下游任务类似的PLM才能实现好的效果
1.2bert微调
bert模型的原始任务是掩码预测和句子生成.现在我想用bert模型来预测一个文本是积极的还是消极的,这个任务不是bert模型原本是配的任务.
- 传统Fine-Tuning方式是通过打标签的方式送到bert模型中预测,在训练bert模型的时候需要一定量的训练数据来训练.
- 使用Prompt-Tuning的方式是CLS I like the Disney films very much.SEP It wasMASK。SEP。这样就把下游任务转化为bert模型原本适配的任务格式,然后通过概率分布得到最大的概率的文本的信息作为我们的预测值.预测值可能是great或者good,这时候我们需要标签词映射把他们转换为positive.
综上所诉,Prompt-Turning的方式包括Prompt模版设计以及标签词映射两部分
这样我们通过使用Prompt-Turning的方式达到了一个类似于全参微调的效果.
1.3 Prompt-Tuning(提示微调)
Fine-Tuning的本质:调整预训练模型,让预训练模型去迁就下游任务。
Prompt-Tuing的本质:让下游任务去迁就预训练模型,将Fine-tuning的下游任务目标转换为Pre-training的任务。

1.4指示微调(lnstruction-Tuning)
任务一:带女朋友去了一家餐厅,她吃的很开心,这家餐厅太_了!
任务二:判断这句话的情感,回答是积极还是消极:带女朋友去了一家餐厅,她吃的很开心。
这两个任务一个是补全任务,一个是判别任务,Prompt就是第一种模式,Instruction就是第二种。
Prompt是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空。
Instruction-Tuning则是激发语言模型的理解能力,通过给出更明显的指令/指示,让模型去理解并做出正确的action.任务。
综上所述:提示词微调分为指示微调和提示微调.
二.PET(Prompt-Turning鼻祖)
2.1PET模型介绍
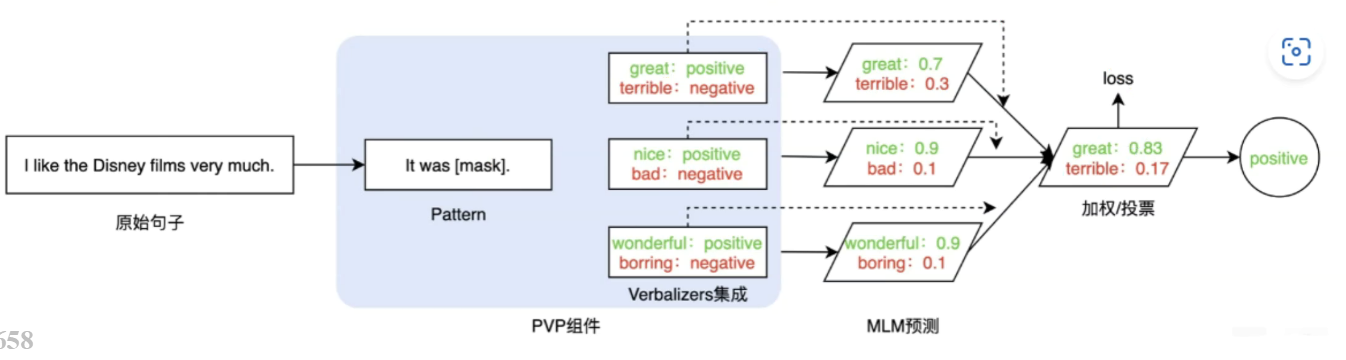
PET模型 :通过设计自然语言模式(pattern)和标签词(verbalizer),将输入句子转换为带有MASK位置的文本
例如"这个电影很MASK。",然后用预训练语言模型(如BERT)预测MASK位置的词,再通过verbalizer转换来完成分类任务。
2.2组件
PET模型提出两个很重要的组件:
Pattern(Template):记作T,即上文提到的Template,其为额外添加的带有[mask]标记的短文本,通常一个样本只有一个Pattern(因为我们希望只有1个让模型预测的[mask]标记)。由于不同的任务、不同的样本可能会有其更加合适的pattern,因此如何构建合适的pattern是Prompt-Tuning的研究点之一;;
Verbalizer:记作V,即标签词的映射,对于具体的分类任务,需要选择指定的标签词(labelword)。例如情感分析中,我们期望Verbalizer可能是(positive和negative是类标签)。同样,不同的任务有其相应的label word,但需要注意的是,Verbalizer的构建需要取决于对应的Pattern。因此如何构建Verbalizer是另一个研究挑战
2.2.1具体难点
映射关系不同,精确度结果不同

2.3PET任务图示
2.4PET模型的核心思想
(1)PET模型的核心思想:将下游任务重构为预训练模型最熟悉的"完形填空"问题,从而利用语言模型对文本的理解能力,最终通过少量示例训练获得较好的下游性能。
(2)方法:通过设计自然语言模式(pattern)和标签词映射(verbalizer),将输入句子转换为带有MASK位置的文本,例如"这个电影很MASK。",然后用预训练语言模型(如BERT)预测MASK位置的词,再通过verbalizer转换来完成分类任务。
缺点:模版和映射不同,最终的结果也不同
2.5PET模型微调流程
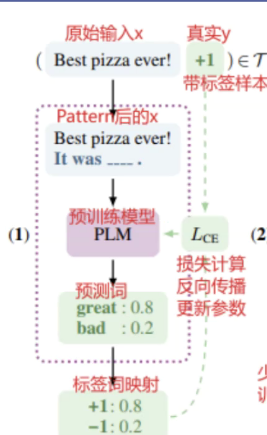
- 有标签样本
先使用文本组成patten(patten格式有很多,可以训练出来很多效果不错的模型),然后使用预训练模型得到概率分布,在通过真实标签计算损失训练PLM
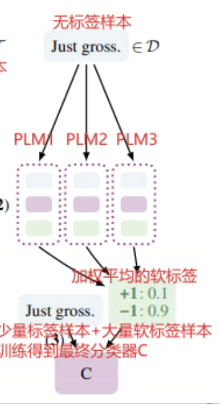
- 无标签样本:
先使用大量无标签样本训练多个模型,把结果加权平均得到软标签,然后在使用硬标签和软标签一起训练PLM
2.5PET两种训练方式的优点:
1、通过prompt tuning形式实现用少量数据训练得到更好的效果(相对于全量微调)
2、解决了标注数据不足的问题
3、通过融合多个模型,提高模型的泛化性
4、使用蒸馏的方式可以降低模型的大小
2.6POFT分类
硬模板:固定的自然语言模版,缺点明显,不同的模版训练出来的结果不一样
软模版:使用可训练的向量放入到embedding序列中完成不同的任务
混合模版:同时使用硬模板和软模版
按照训练时参数更新的范围不同,POFT方法主要分成三种类型:
- 全量微调(Full Fine-Tuning):模型所有参数都参与更新,包括预训练模型参数和下游任务层参数。如PET模型。
- 部分参数微调(Partial Fine-Tuning):只更新预训练模型中的一部分参数,比如高层transformer block、某些 attention 层或特定模块,其余参数冻结。 如Adapter Tuning。
- 仅提示参数微调(Prompt-Only Tuning):冻结原始预训练模型参数,只训练 prompt 参数。如P-tuning、Prompt Tuning等。
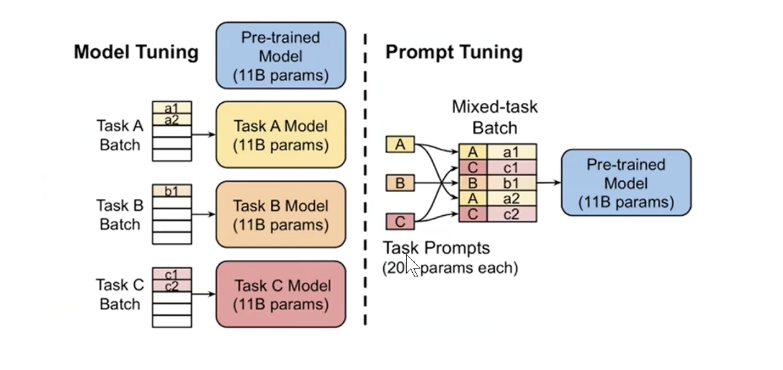
我们平时推荐使用软模版+仅提示参数微调的方式(只调整prompt里面的参数)
2.7soft Prompt及微调方法
把软标签(可训练向量)和原始文本拼接起来,放到模型里面训练,得到结果,在进行反向传播,计算损失更新参数(更新的是可训练向量).
2.8P-Turning(当时造成了一些影响的微调方法)
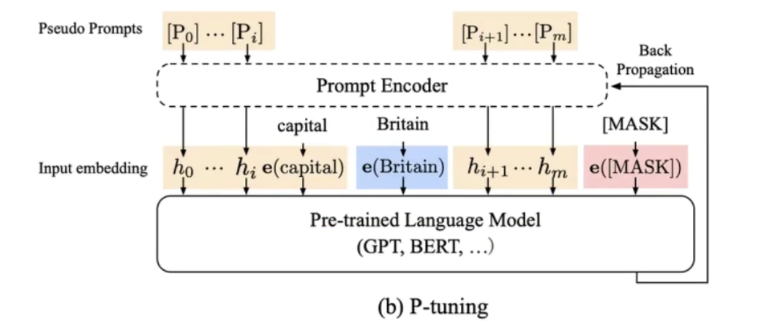
- P-Turning_v1
这个微调方法是把可训练的向量参数插入到embedding中,冻结其它参数,只训练这些可训练向量,最后只留下训练好的向量(相较于Prompt-Turning随机生成的可训练向量,P-Turning的可训练向量收敛更快)
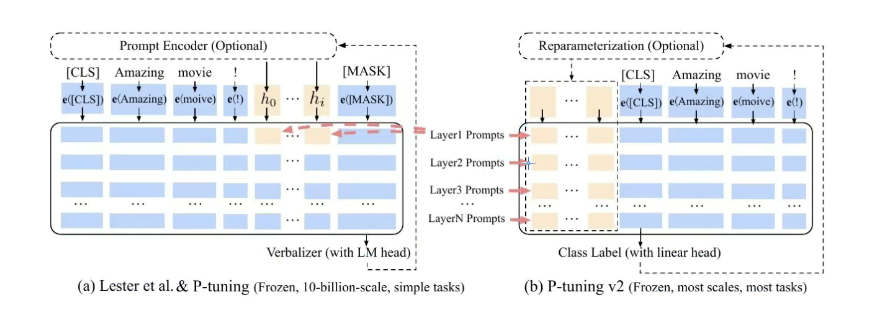
- P-Turning_v2
P-Turning_v1在训练大模型的效果不是很好,P-Turning_v2在注意力机制层都加了可训练向量参数
2.9pre_fix Turning
这个模型可P-TurningV2极其相似,主要的原理是在k,v上增加一个可训练参数,通过训练这些参数实现模型微调.
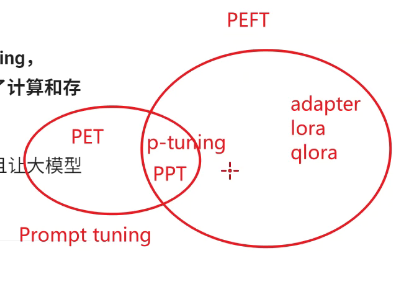
三.各种微调方式的关系
- PET是通过提示词模版+映射实现全量微调
- P-Turning和PPT都是通过训练可训练向量软模版实现部分参数微调
- PETF指的是高效部分参数微调