从激活函数到超参搜索:一份"能落地"的深度学习手册
1. 激活函数:先选对,再调参
| 函数 | 零中心 | 梯度消失 | 计算速度 | 稀疏性 | 典型坑 | 适用场景 |
|---|---|---|---|---|---|---|
| Sigmoid | × | 严重 | 慢(exp) | × | 输出≠0 均值 | 二分类输出层 |
| Tanh | √ | 较重 | 慢(exp) | × | 两端饱和 | 浅层网络 |
| ReLU | × | 缓解 | 极快 | √ | Dead ReLU | 99% 隐藏层首选 |
| Leaky ReLU | × | 缓解 | 快 | √ | 斜率手工 | 实验性替代 |
| ELU | √ | 缓解 | 慢(exp) | √ | 计算贵 | 小数据集精调 |
| Swish | × | 缓解 | 中 | √ | 参数增加 | 深层网络 SOTA |
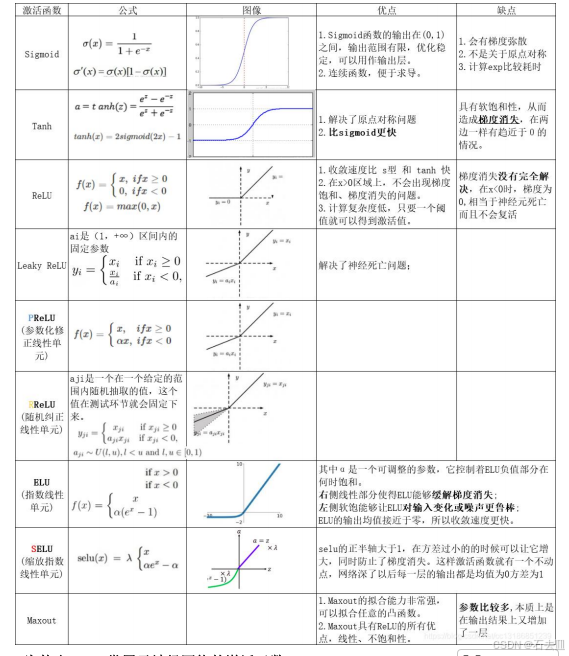
一句话总结:
隐藏层默认 ReLU;如果训练很深且显存充足,换成 Swish 往往有 0.5%~1% 的额外收益;输出层二分类用 Sigmoid,多分类用 Softmax 。
2. 梯度消失 & 爆炸:诊断 + 处方
| 现象 | 快速判断 | 根因 | 实战组合拳 |
|---|---|---|---|
| 梯度消失 | 层越靠前,‖∂Loss/∂W‖趋 0 | 链式<1 连乘 | 1) ReLU 家族激活 2) BN + 残差 3) Xavier/He 初始化 |
| 梯度爆炸 | Loss → NaN,‖∂Loss/∂W‖>100 | 链式>1 连乘 | 1) Gradient Clip by norm=5 2) 降低 lr 1 个量级 3) L2 weight decay 1e-4 |
BN 能把激活值拉回 N(0,1),相当于给梯度做了"保险丝":既防消失也防爆炸 。

3. 正则化全家桶:何时用、怎么用
| 技术 | 作用面 | 训练/测试差异 | 调参经验 |
|---|---|---|---|
| Dropout | 神经元 | 训练 p=0.5,测试关闭 | 小网络 0.3,大网络 0.5;与 BN 共存时降至 0.1 |
| L2 | 权重 | 无差异 | 系数 1e-4 起步,观察验证集再 ×10 或 ÷10 |
| Early Stop | 迭代次数 | 无差异 | 验证 loss 连续 5 epoch 不降即停 |
| Data Aug | 样本 | 无差异 | 分类任务先水平翻转+随机裁剪,再考虑颜色扰动 |
注意:
BN 本身自带噪声,ResNet 后几层可完全去掉 Dropout,不降精度反而省显存 。
4. 参数初始化:别让网络"死"在起跑线
| 激活函数 | 推荐初始化 | 原理 | 代码一行 |
|---|---|---|---|
| ReLU | He | 方差=2/fan_in | torch.nn.init.kaiming_normal_ |
| Tanh/Sigmoid | Xavier | 方差=2/(fan_in+fan_out) | torch.nn.init.xavier_normal_ |
| 全零初始化 | × | 对称破坏,梯度相同 | 永远别用 |
5. 优化器选择:Adam 快,SGD 准
| 阶段 | 数据量 | 推荐组合 | 学习率起点 |
|---|---|---|---|
| 快速实验 | 任意 | Adam | 1e-3 |
| 中期精调 | >10k | AdamW + CosineLR | 3e-4 |
| 收官冲刺 | 任意 | SGD+Momentum | 1e-2(再 ×0.1 两次) |
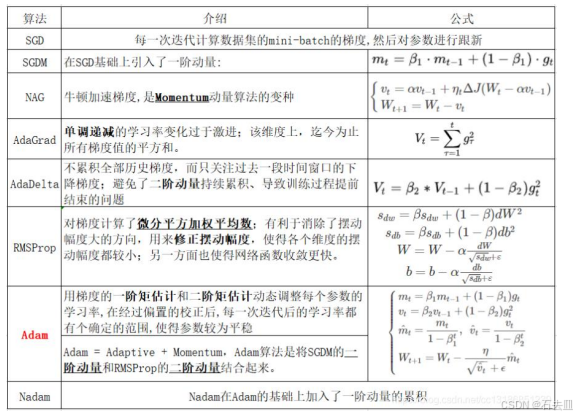
经验:
先用 Adam 把验证 AUC 拉到 0.9x,再换 SGD 往往能再提 0.5~1 个点,代价是 3× 训练时间 。
6. 学习率:一步到位最省钱
-
搜索套路:
- 从 {3,1,0.3,0.1,0.03,0.01} 跑 3 epoch,找最快降 loss 的那个;
- 用 Cosine/One-Cycle 在剩余 epoch 里平滑下降;
- 最后 10% epoch 做 Warm-Restarts 微调。
-
自动化 :
把上述过程写成回调函数,配合早停,一次训练就能拿到"手工调 3 天"的效果。
7. Batch Size & Epoch:不是越大越好
| 显卡 | 显存 | 最大 bs | 平衡策略 |
|---|---|---|---|
| 1080Ti | 11 G | 64~128 | 梯度累加 4 步 = 有效 256 |
| V100 | 32 G | 256~512 | 直接上,配合 LARS 可上千 |
规律:
线性缩放 lr 只适用于 ≤512;再大时用 LARS 层自适应学习率,否则 val acc 会掉 。

8. 超参搜索:从网格到贝叶斯
| 方法 | 搜索空间 | 适合维度 | 预算 | 备注 |
|---|---|---|---|---|
| 网格搜索 | 离散 | ≤3 | 指数爆炸 | 教学演示用 |
| 随机搜索 | 连续/离散 | 5~10 | 线性 | baseline 首选 |
| 贝叶斯优化 | 连续 | ≥10 | 10× 随机 | 利用历史评估,3~5 轮就能逼近最优 |
贝叶斯四件套 :
- 目标函数:验证集 1-AUC
- 搜索空间:lr∈1e-4,1e-1 对数、dropout∈0,0.5 均匀
- 采集函数:EI (Expected Improvement)
- 历史结果:上一轮 (lr, dropout, 1-AUC) 三元组
9. 微调预训练模型:冻结多少层?
| 数据规模 | 与源域相似度 | 推荐方案 |
|---|---|---|
| <1 k | 高 | 只改分类层,lr=1e-3 |
| 1 k~10 k | 中 | 解冻 top-1 block,lr=1e-4 |
| >10 k | 低 | 解冻全部,lr=3e-5 + 早停 |
先冻结底层训练 5 epoch,再解冻一半层继续 10 epoch,可减小 30% 过拟合风险 。
10. 一份"能跑"的调参 Checklist
- 数据:可视化 100 张,确认标签干净;
- 预处理:零均值 + 方差归一化,分类做 One-Hot;
- 模型:隐藏层默认 ReLU,输出层匹配任务;
- 初始化:He/Xavier + bias=0;
- 正则:BN 必备,小网络加 Dropout(0.3);
- 优化器:Adam 1e-3 先跑 10 epoch;
- 学习率:Cosine 下降,Warm-Restarts 最后 10%;
- 早停:val loss 不降 5 epoch 停,回滚最优 ckpt;
- 复现:固定 numpy/torch 随机种子;
- 记录:用 TensorBoard 把 loss、lr、grad norm 全写进日志,方便复盘。
彩蛋:一张"炼丹"壁纸
"如果 loss 不下降,先把 lr 除以 10,再把 batch size 乘 2,最后检查数据标签。"
------ 深度学习第一定律
参考文献
:
程序员学长《终于把神经网络中的激活函数搞懂了!!》
:
CSDN《神经网络激活函数优缺点和比较》