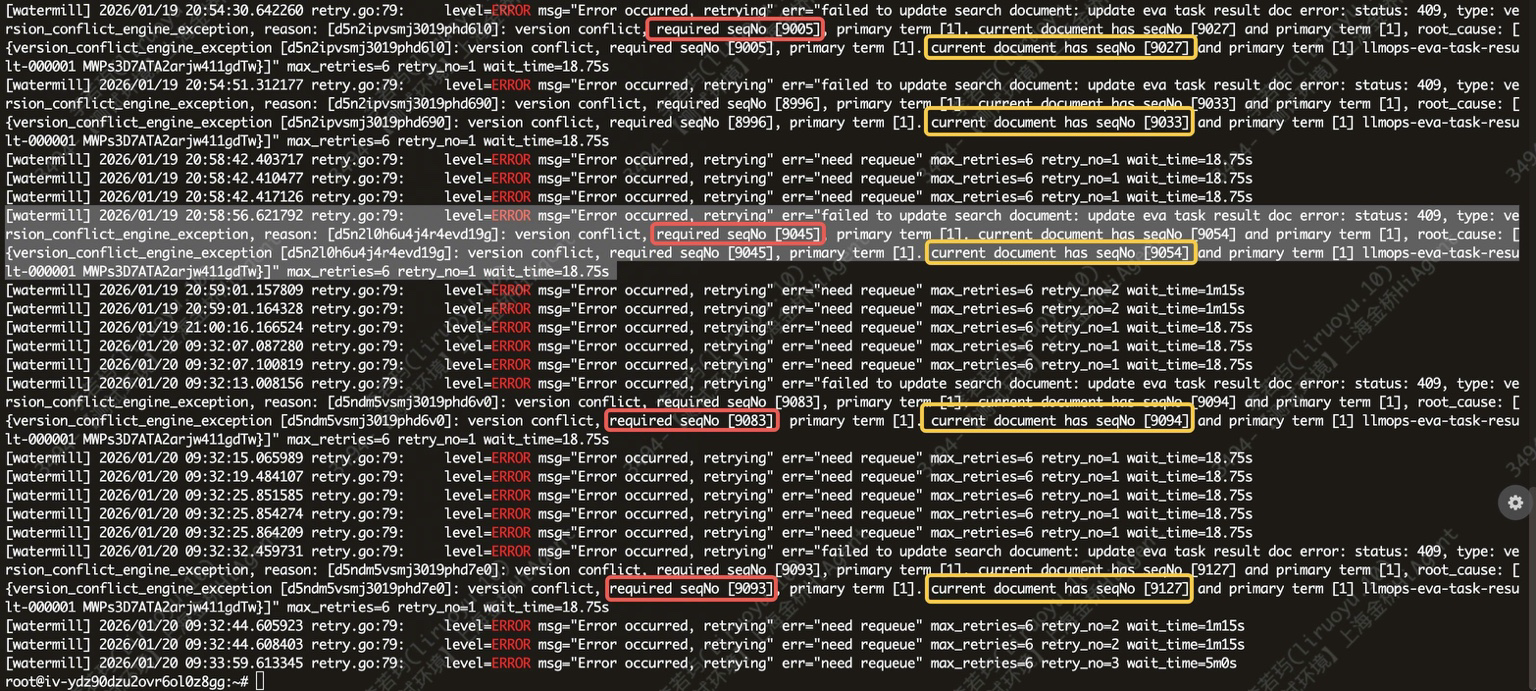
- 这段日志到底在说什么
日志核心信息类似:
• status: 409
• type: version_conflict_engine_exception
• reason: version conflict, required seqNo 9005, primary term 1. current document has seqNo 9027 ...
含义是:
-
你的 eva worker 在更新某个文档时,带了条件:只有当该文档当前的 seq_no 和 primary_term 与我期望的一致时才允许更新(也就是 if_seq_no / if_primary_term)。
-
但 ES 发现:你拿到的版本已经过期了。
• 你以为文档是 seqNo=9005
• 实际上它已经被别的写入更新到 seqNo=9027(甚至更多)
- 所以 ES 拒绝你的更新并返回 409。
日志里重复出现 need requeue / retrying,说明 worker 在捕获 409 后把任务重新入队或重试,但因为冲突持续存在(高并发对同一 doc 写入),所以一直失败。
⸻
- 根因(99% 是下面这几类)
A. 多个 worker/线程在同时更新同一条 ES 文档
比如把多个 eva task 的结果都写进同一个 "聚合结果 doc"(同一个 _id),并发一高就必冲突。
B. 你在更新前 GET 了一次文档拿到 seq_no,但更新时已经过期
如果更新链路是:GET -> 业务处理 -> UPDATE(if_seq_no/if_primary_term)
中间时间窗口越大,冲突概率越高。
C. 你用的是"整文档覆盖式更新"
即使只改一个字段,也把整个 _source 重新写回,会导致写冲突更频繁、重试更难收敛。
⸻
- 解决思路(按推荐优先级)
方案 1(推荐,架构上消灭冲突):不要多人写同一个 doc
把"每个 eva task result"做成单独一条文档(例如 _id = task_id),或者按 task_id 分片写入。
优点:冲突几乎归零;性能和可用性最好。
适用:task 结果天然是"多条记录"而不是必须塞进一个 doc。
如果你当前是"一个主 doc 里维护一个 results map/数组",高并发下非常容易被打爆。
⸻
方案 2(推荐,最常见工程解法):用 Update API 的 retry_on_conflict
如果你的更新是 update 部分字段,而且允许"读到新版本后重放更新",可以直接让 ES 帮你重试。
• REST 示例:
POST index/_update/<doc_id>?retry_on_conflict=10
{
"doc": { "field": "value" }
}
• Go client(示意):
• UpdateRequest / UpdateService 里设置 RetryOnConflict(10)(具体取决于你用的 ES Go client 版本)。注意:这只解决"轻度并发冲突"。如果你是几十上百并发持续写同一个 doc,retry_on_conflict 也可能一直打不赢。
⸻
方案 3(强烈建议配合使用):用 scripted update 做"原子合并",避免整文档覆盖
如果你要往同一个 doc 里写入某个 task 的结果,应该用 painless 脚本只改那一小块,且做到幂等。
示例(把 task_id 对应的结果写入 map):
POST index/_update/<doc_id>?retry_on_conflict=10
{
"script": {
"source": """
if (ctx._source.results == null) { ctx._source.results = :; }
ctx._source.resultsparams.task_id = params.result;
""",
"params": {
"task_id": "t123",
"result": { "status": "OK", "score": 0.98 }
}
},
"upsert": { "results": {} }
}
价值:
• 避免"读出来整个文档 -> 改一点 -> 写回整个文档"导致的高冲突
• 写入粒度更小、重试更容易收敛
⸻
方案 4(如果你现在强制用了 if_seq_no/if_primary_term):409 时必须 重新 GET 最新版本再更新
如果你的业务必须严格用 OCC(例如不能覆盖别人的更新),那正确流程是:
-
GET doc,拿最新的 _seq_no、_primary_term
-
立即 UPDATE(尽量缩短窗口)
-
若 409:回到第 1 步,加入 指数退避 + 抖动(jitter),设置最大重试次数
如果你现在"只重试 update,但不重新 get 最新 seqNo",那会永远 409。
⸻
- 你应该怎么选(结合 eva worker 典型场景)
• 如果你把多个 task 的结果写进同一个聚合 doc:
优先做 方案 1(拆文档/按 task_id 存储)。这是根治。
• 如果必须写进同一个 doc(例如需要一个总览 doc):
用 方案 3(scripted update)+ 方案 2(retry_on_conflict),并控制并发。
• 如果你们对一致性要求非常强:
用 方案 4(409 → 重新 GET → 再更新),并把写入窗口缩到最短。
⸻
- 额外建议(避免"重试风暴")
- 限制同一 doc_id 的并发写入:按 doc_id 做单飞(singleflight)/分布式锁/队列串行化。
- 重试要指数退避:例如 50ms、100ms、200ms、400ms...并加随机抖动,避免所有 worker 同步撞车。
- 设置合理 max_retries:一直 requeue 会造成队列堆积和雪崩。
- 观测指标:统计 409 比例、每个 doc_id 的更新 QPS、队列重入次数,能快速定位热点 doc。