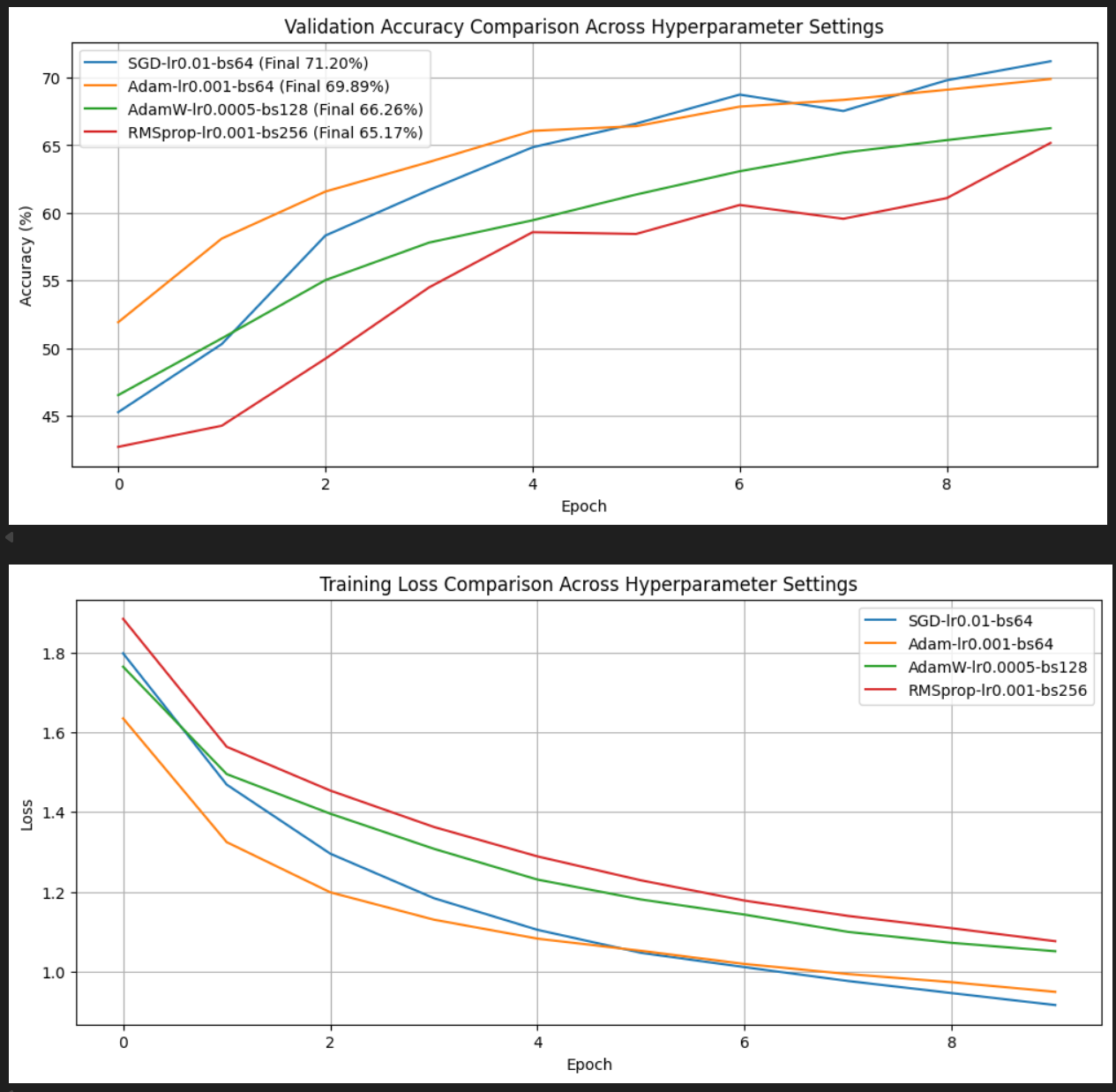
对简单的CNN进行调参:
# =========================================================
# CNN多组超参数对比实验模板
# =========================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import random, numpy as np, time
# ------------------ 1. 随机性控制 ------------------
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed(42)
# ------------------ 2. 数据准备 ------------------
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# ------------------ 3. 模型结构 ------------------
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.dropout = nn.Dropout(0.5)
self.fc1 = nn.Linear(64 * 8 * 8, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1)
x = self.dropout(F.relu(self.fc1(x)))
return self.fc2(x)
# ------------------ 4. 实验参数定义 ------------------
param_grid = [
{"lr": 0.01, "batch_size": 64, "optimizer": "SGD"},
{"lr": 0.001, "batch_size": 64, "optimizer": "Adam"},
{"lr": 0.0005, "batch_size": 128, "optimizer": "AdamW"},
{"lr": 0.001, "batch_size": 256, "optimizer": "RMSprop"},
]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
criterion = nn.CrossEntropyLoss()
# ------------------ 5. 实验执行函数 ------------------
def run_experiment(params, epochs=10):
print(f"\n🚀 Running experiment: {params}")
model = SimpleCNN().to(device)
trainloader = DataLoader(trainset, batch_size=params["batch_size"], shuffle=True, num_workers=2)
testloader = DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
# 选择优化器
if params["optimizer"] == "SGD":
optimizer = optim.SGD(model.parameters(), lr=params["lr"], momentum=0.9, weight_decay=1e-4)
elif params["optimizer"] == "Adam":
optimizer = optim.Adam(model.parameters(), lr=params["lr"], weight_decay=1e-4)
elif params["optimizer"] == "AdamW":
optimizer = optim.AdamW(model.parameters(), lr=params["lr"], weight_decay=1e-4)
else:
optimizer = optim.RMSprop(model.parameters(), lr=params["lr"], weight_decay=1e-4)
train_losses, val_accuracies = [], []
for epoch in range(epochs):
model.train()
running_loss = 0.0
for inputs, labels in trainloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 验证阶段
model.eval()
correct, total = 0, 0
with torch.no_grad():
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
acc = 100 * correct / total
avg_loss = running_loss / len(trainloader)
train_losses.append(avg_loss)
val_accuracies.append(acc)
print(f"Epoch [{epoch+1}/{epochs}] | Loss: {avg_loss:.4f} | Val Acc: {acc:.2f}%")
return train_losses, val_accuracies
# ------------------ 6. 运行所有实验 ------------------
results = {}
for params in param_grid:
start = time.time()
losses, accs = run_experiment(params, epochs=10)
end = time.time()
key = f"{params['optimizer']}-lr{params['lr']}-bs{params['batch_size']}"
results[key] = {"loss": losses, "acc": accs, "time": round(end-start, 2)}
# ------------------ 7. 可视化对比 ------------------
plt.figure(figsize=(12,5))
for key, data in results.items():
plt.plot(data["acc"], label=f"{key} (Final {data['acc'][-1]:.2f}%)")
plt.title("Validation Accuracy Comparison Across Hyperparameter Settings")
plt.xlabel("Epoch")
plt.ylabel("Accuracy (%)")
plt.legend()
plt.grid(True)
plt.show()
plt.figure(figsize=(12,5))
for key, data in results.items():
plt.plot(data["loss"], label=key)
plt.title("Training Loss Comparison Across Hyperparameter Settings")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.grid(True)
plt.show()
# 打印汇总表
print("\n📊 实验结果汇总:")
for key, data in results.items():
print(f"{key:30s} | Final Acc: {data['acc'][-1]:.2f}% | Time: {data['time']}s")