回顾上一节,我们给出了贝尔曼方程的状态价值函数:
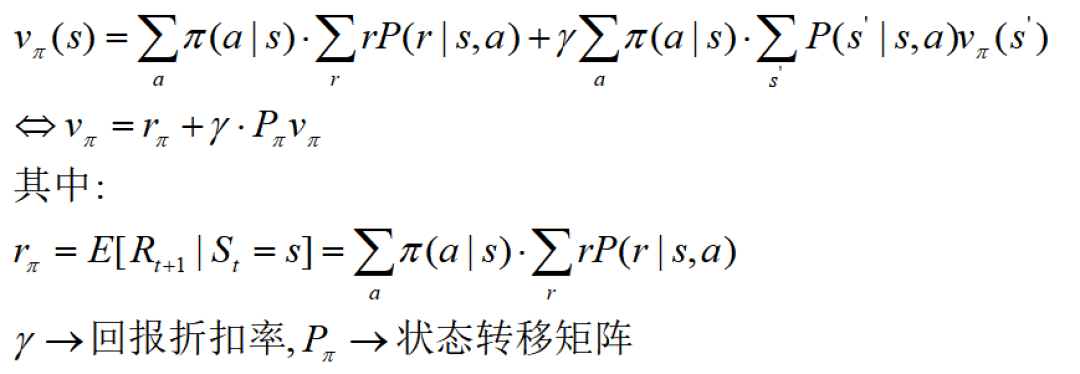
和动作价值函数:
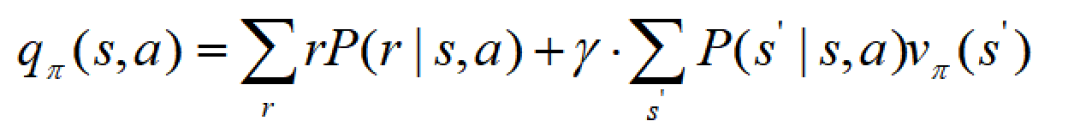
这两个函数都是对于给定策略π来说的,强化学习的目的是寻找最佳策略,所以下一个问题自然而然的是:
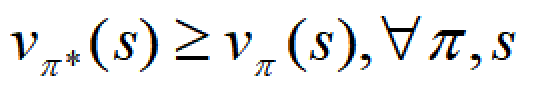
本篇就研究这个问题,进一步要回答四个问题:
- 最优策略是否存在
- 如果存在,最优策略是唯一的吗
- 最优策略是固定的还是随机的
- 怎么样获取最优策略
1
贝尔曼最优方程
首先,我们给出贝尔曼最优方程(Bellman optimality equation)的定义:
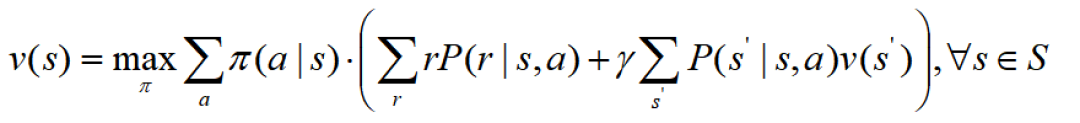
也可以写成矩阵形式:
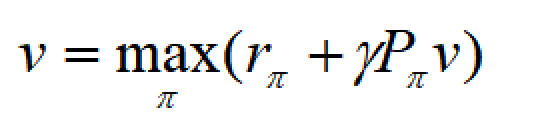
这东西怎么求?还是得回到最简单的数学分析。先看两个例子。
- 例1

- 例2
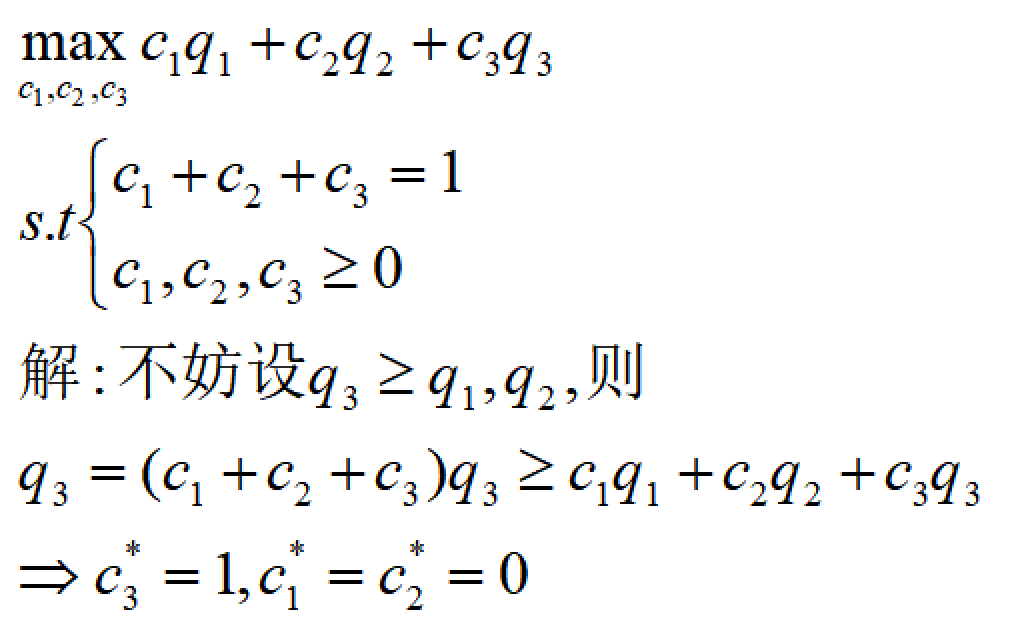
我们再调整一下BOE公式,就很容易得到:
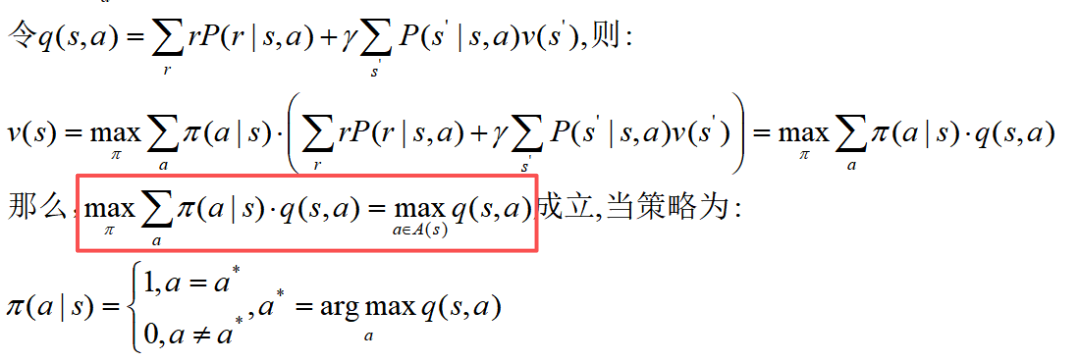
2
求解BOE
BOE的矩阵形式是关于状态价值函数的向量形式,我们可以定义函数:
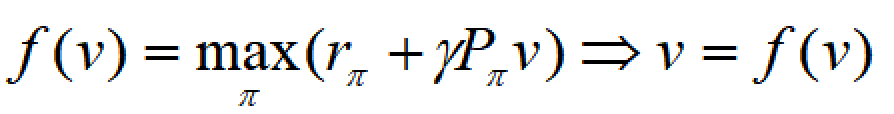
为求解这个函数,我们要引入压缩映射定理,又称Banach不动点定理(Contraction Mapping Theorem):
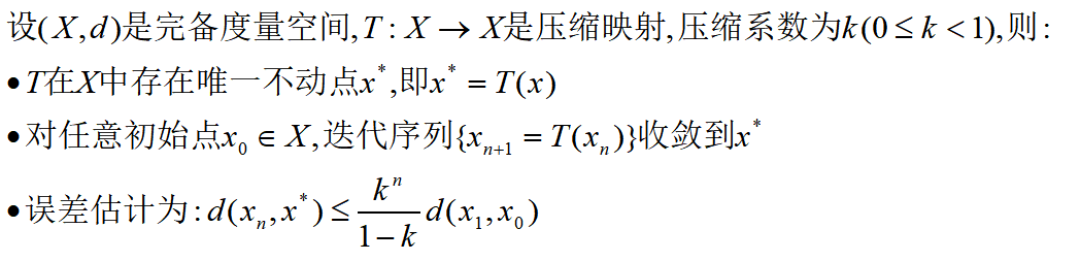
什么是压缩映射,标准定义:

我们证明BOE函数矩阵形式满足压缩映射定理,其实也很简单:
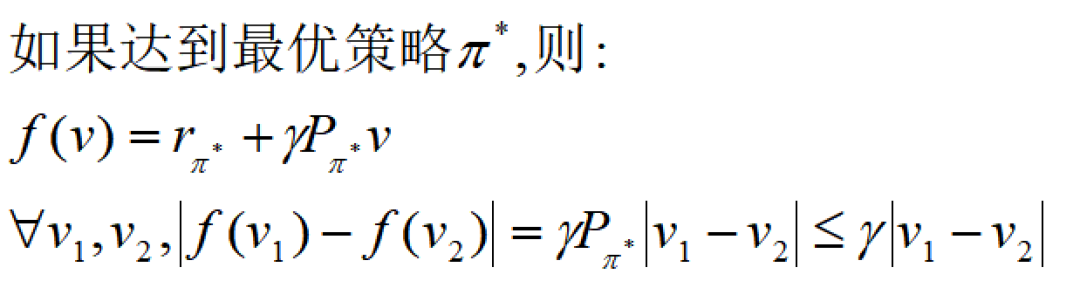
3
BOE迭代算法
综上,我们可以给出贝尔曼最优方程的迭代步骤了:

这个也成为BOE的数值迭代算法(value iteration)!