庞志奇1^{1}1, 赵玲玲1^{1}1, 刘洋1^{1}1, 王春宇1†^{1\dagger}1†, Gaurav Sharma2^{2}2
1^{1}1哈尔滨工业大学计算学部,哈尔滨,中国
2^{2}2罗切斯特大学电气与计算机工程系,罗切斯特,美国
zqpang98@gmail.com, zhaoll@hit.edu.cn, liuyang@hit.edu.cn, chunyu@hit.edu.cn, g.sharma@ieee.org
https://arxiv.org/pdf/2601.11243
摘要
我们提出了无监督多场景(UMS)行人重识别(ReID)作为一个新任务,它在一个统一的框架内将ReID扩展到跨不同场景(跨分辨率、衣物变化等)。为了应对UMS-ReID,我们引入了图像-文本知识建模(ITKM)------一个有效利用视觉-语言模型表示能力的三阶段框架。我们从一个包含图像编码器和文本编码器的预训练CLIP模型开始。在第一阶段,我们在图像编码器中引入场景嵌入,并对编码器进行微调,以自适应地利用多个场景的知识。在第二阶段,我们优化一组可学习的文本嵌入,使其与第一阶段生成的伪标签相关联,并引入多场景分离损失来增加场景间文本表示的差异性。在第三阶段,我们首先引入集群级和实例级异构匹配模块,以在每个场景内获得可靠的异构正样本对(例如,同一人的可见光图像和红外图像)。接着,我们提出了一种动态文本表示更新策略,以保持文本与图像监督信号之间的一致性。跨多个场景的实验结果证明了ITKM的优越性和泛化能力;它不仅超越了现有的场景特定方法,而且通过整合多场景知识提升了整体性能。
1 引言
给定一个行人的查询图像,行人重识别(ReID)(Ye et al. 2021b,a; Li et al. 2024; Gong et al. 2024; Tan et al. 2024)旨在从一个包含大量行人图像的图库中识别出同一人的图像。为了减少人力劳动和繁琐性,研究者们探索了各种无监督传统ReID(UT-ReID)方法(Wang et al. 2021; Xuan and Zhang 2021; Chen, Lagadec, and Bremond 2021; Dai et al. 2022; He et al.(2024),这些方法通常利用聚类算法生成的伪标签来替代人工标注的身份标签以指导模型优化。尽管先进的UT-ReID方法在简单场景中取得了有希望的性能,但它们往往难以处理更具挑战性的场景。因此,研究者们探索了各种具有挑战性的场景,例如无监督可见光-红外ReID(UVI-ReID)(Pang et al. 2023; Shi et al. 2024; Yang, Chen, and Ye 2023; Wang et al. 2025)、无监督衣物变化ReID(UCC-ReID)(Pang, Zhao, and Wang 2024a; Pang et al. 2025)以及无监督跨分辨率ReID(UCR-ReID)(Pang, Zhao, and Wang 2024b),并提出了针对每个场景的方法。
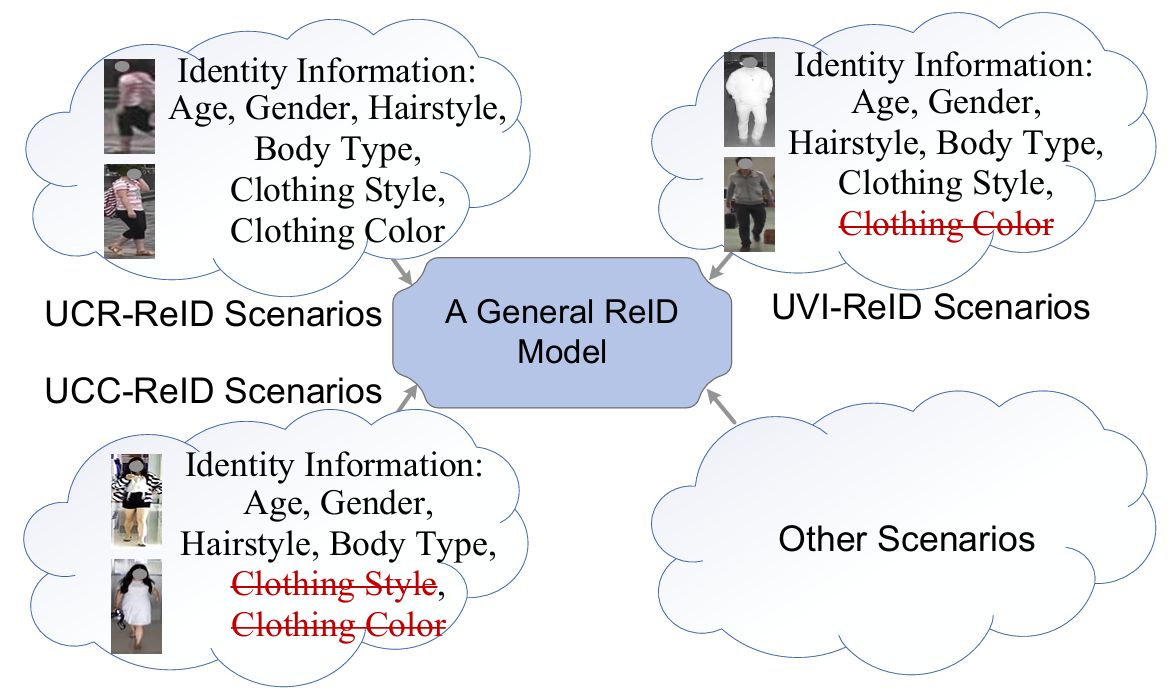
图 1: 身份信息是依赖于场景的。
与身份相关的信息在不同场景中本质上是不同的。如图1所示,在UCR-ReID中,衣物的样式和颜色都被视为身份相关信息(Pang, Zhao, and Wang 2024b)。然而,在UVI-ReID中,颜色与身份无关(Yang et al. 2022),因为红外图像缺乏颜色信息。此外,UCC-ReID通常假设同一个人可能穿着不同的衣物,因此衣物的样式和颜色可能不是身份相关的(Pang et al. 2025)。由于上述无监督场景特定ReID(USS-ReID)方法专注于每个场景独有的身份相关特征,限制了它们在多场景中的泛化能力。这导致了两个关键限制。首先,实际的ReID应用通常跨越多个场景------例如,一个人可能更换衣物或在低光照条件下出现。现有的USS-ReID方法通常需要为每个场景单独训练模型,涉及不同的训练策略和多组权重,这增加了系统复杂性和部署成本。其次,现有的USS-ReID方法是针对单个场景设计的,不支持跨多个场景的联合训练,因此无法利用数据多样性增加带来的性能优势(Zheng et al. 2024; Shi et al. 2023)。
为了解决上述问题,我们提出了一个新的图像-文本知识建模(ITKM)框架,该框架有效利用视觉-语言模型(VLMs)(Radford et al. 2021)的表示能力来处理具有挑战性的无监督多场景行人重识别(UMS-ReID)。UMS-ReID是一个新任务,旨在以无监督方式训练一个单一的通用模型来处理多个不同的场景------这与先前针对单个场景的任务(Yang et al. 2022; Pang et al. 2025)不同。为了应对UMS-ReID的挑战,ITKM在数据处理和模型优化方面都引入了进展。在数据方面,基于数据异构性(例如,模态差异、衣物变化和分辨率差异)与编码器结构之间的关系(Wu and Ye 2023; Shi et al. 2024),我们一致地将每个场景中的异构数据划分为两个同构组,确保ITKM中的图像编码器可以适应所有场景的输入。在优化方面,考虑到VLMs强大的表示和迁移能力,我们基于CLIP(Radford et al. 2021; Zhou et al. 2022)将ITKM设计为一个三阶段框架。在第一阶段,我们在CLIP图像编码器中引入场景嵌入,并对编码器进行微调以适应并有效利用多个场景的知识。在第二阶段,为了获得场景特定的文本表示,我们:(a)优化一组可学习的文本嵌入,通过CLIP使其与来自第一阶段的身份伪标签相关联;(b)引入多场景分离损失以增加场景间文本表示的差异性。第三阶段首先引入集群级异构匹配(CHM)和实例级异构匹配(IHM)模块,以在每个场景内获得可靠的异构正样本对(例如,同一人的可见光图像和红外图像、穿着不同衣物的同一人图像、或不同分辨率的同一人图像)。接着,第三阶段引入了一种动态文本表示更新(DRU)策略,该策略由最新的伪标签指导,有助于在无监督设置下保持文本和图像监督信号之间的一致性。
主要贡献总结如下:
- 我们提出了一个新任务UMS-ReID,以及一个量身定制的框架ITKM来解决它。据我们所知,这是首个探索跨多个场景的无监督行人重识别的研究。
- 为了适应不同场景并鼓励场景特定的文本表示,我们为CLIP图像编码器引入了一种新颖的场景嵌入,并提出了多场景分离损失。
- 我们构建了两个新模块CHM和IHM,用于获取在我们的无监督设置中至关重要的可靠异构正样本对。此外,我们引入了DRU策略以确保文本和图像监督信号之间的一致性。
- 在不同场景数据集上的实验结果验证了ITKM的优越性和泛化性,它不仅在每个场景内超越了现有的USS-ReID方法,而且通过整合多场景知识提升了整体性能。
2 相关工作
UT-ReID方法(Cho et al. 2022; Lan et al. 2023)通常假设同一人的不同图像表现出高度相似性。然而,实际应用通常涉及多个具有挑战性的场景,其中同一人的不同图像可能表现出显著的异构性。这些现实世界的复杂性在先前研究中通过建立特定任务和定制方法得到了部分解决。例如,给定一个人的可见光(红外)图像,UVI-ReID(Yang, Chen, and Ye 2024)旨在在由红外(可见光)图像组成的图库中找到具有相同身份的图像。UCC-ReID(Li et al. 2023)通常假设人们可能更换衣物,并试图匹配穿着不同衣物的同一人的图像。此外,UCR-ReID(Pang, Zhao, and Wang 2024b)旨在匹配低分辨率与高分辨率的同一人图像。基于先前工作,本文提出了一种新颖的UMS-ReID方法,能够同时支持多个场景,旨在促进ReID更广泛的实际应用。
预训练的VLMs(Radford et al. 2021; Zhou et al. 2022; Lin et al. 2024)在下游任务中展现出了有希望的迁移能力。该领域的先驱是CLIP(Radford et al. 2021)模型,它通过最大化匹配的图像-文本对之间的表示相似性来训练一对图像和文本编码器。后续研究,如CoOp(Zhou et al. 2022),利用可学习的文本嵌入进一步增强了CLIP的灵活性。ReID领域的研究者也探索了基于CLIP的方法(Li, Sun, and Li 2023; Chen et al. 2023; Yang et al. 2024)。例如,CLIP-ReID(Li, Sun, and Li 2023)首先为每个身份学习一组文本嵌入,然后使用学习到的文本嵌入辅助优化图像编码器。CCLNet(Chen et al. 2023)基于UVI-ReID任务中的伪标签优化可学习的文本嵌入,并使用文本表示作为额外的监督信号。提出的ITKM框架同样受益于CLIP的表示能力。与先前工作不同,我们专注于UMS-ReID任务,并明确引入DRU来更新文本表示,解决了先前方法中使用过时离线表示的局限性。
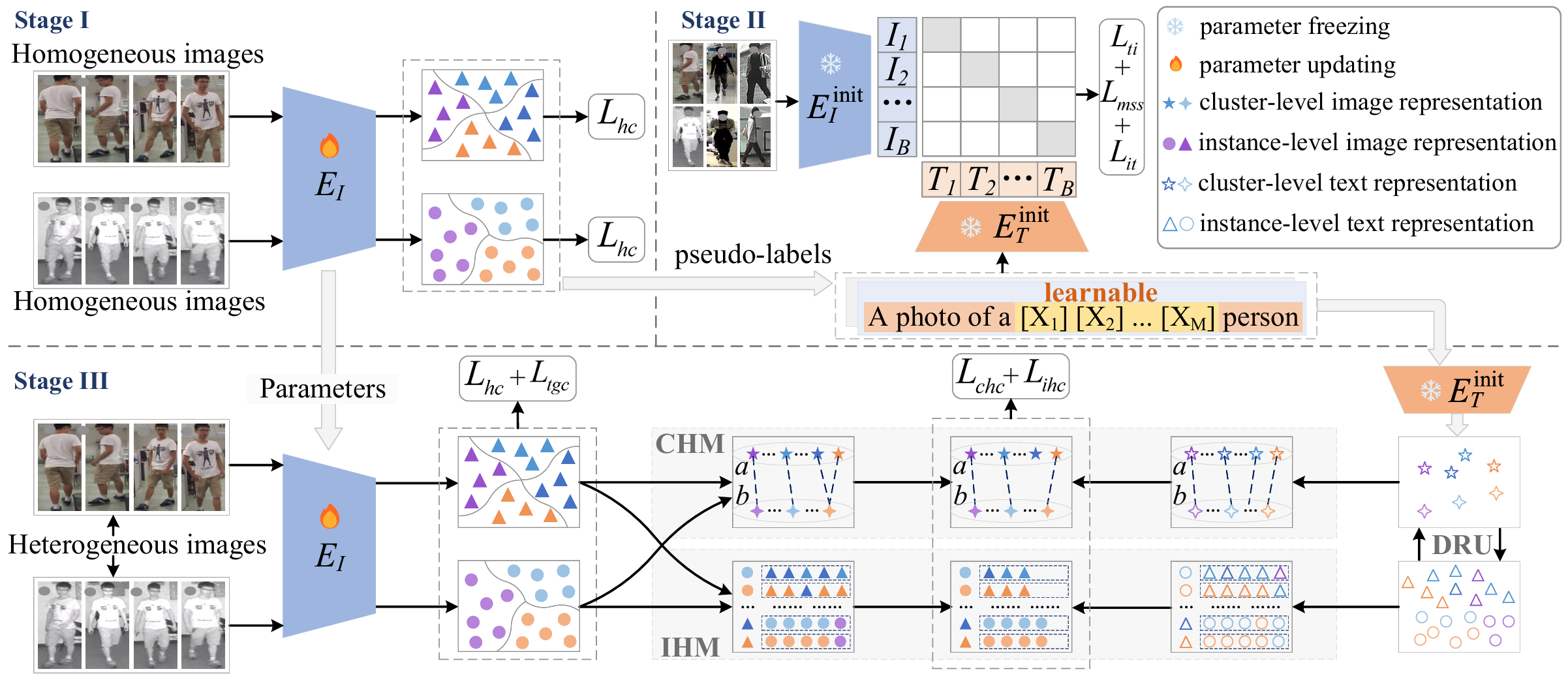
图 2: 针对UMS-ReID提出的ITKM框架包含三个阶段。第一阶段执行无监督同构学习以生成伪标签。第二阶段学习句子"一张X1X2...XMX_{1}X_{2}...X_{M}X1X2...XM的人的照片"中的文本嵌入,通过CLIP使其与具有同构伪标签的图像相关联。第三阶段使用CHM和IHM进行无监督异构学习。在第一和第三阶段,颜色表示伪标签,形状表示同构组。
3 提出的框架
为了说明UMS-ReID任务,我们使用了一个包含UVI-ReID(Yang, Chen, and Ye 2024)、UCC-ReID(Pang, Zhao, and Wang 2024a)和UCR-ReID(Pang, Zhao, and Wang 2024b)的多场景设置。在训练阶段,我们将这三个场景的训练集组合定义为{Xs}s=1S\{X^{s}\}_{s=1}^{S}{Xs}s=1S,其中sss索引S=3S=3S=3个场景。本文旨在展示UMS-ReID的潜力。因此,我们不优先考虑大规模数据集或大量模型参数,这些方面留给未来工作。根据数据分布,我们首先将每个场景内的异构图像划分为两个同构组,标记为aaa和bbb。更多细节在补充材料中提供,完整的ITKM过程也在其中总结为算法1。如图2所示,我们提出的ITKM框架包含三个阶段:无监督同构学习(第一阶段)、文本表示学习(第二阶段)和无监督异构学习(第三阶段)。
3.1 无监督同构学习
在第一阶段,我们采用预训练的CLIP模型中的图像编码器,将输入图像转换为保留身份信息的场景特定表示。具体来说,我们调整构成CLIP图像编码器的视觉变换器(ViT)(Dosovitskiy et al. 2021)EIinitE_{I}^{init}EIinit,引入一个双分支前端,每个分支用于一个同构组,此外,在图像编码器中引入场景嵌入。该过程在图3中使用来自第sss个场景aaa组的输入图像xa,msx_{a,m}^{s}xa,ms进行说明。图像xa,msx_{a,m}^{s}xa,ms被分割成NNN个块,这些块被展平为向量x1,x2,...,xNx_{1}, x_{2}, \ldots, x_{N}x1,x2,...,xN,一个可学习的嵌入矩阵PPP将每个块映射到一个1×D1 \times D1×D向量。类嵌入被连接到向量序列的头部,然后将位置和场景以加法方式加入到结果向量中,以获得一个(N+1)(N+1)(N+1)长度的1×D1 \times D1×D向量序列
z0=za,ms,cls+es;\[x1;x2;⋯ ;xNP]+zp0;⋯ ;zpNz_{0}=\leftz_{a,m}\^{s,c l s}+e_{s};\[x_{1};x_{2};\\cdots;x_{N}P\right]+z_{\\mathbf{p}}\^{0};\\cdots;z_{\\mathbf{p}}\^{N}z0=za,ms,cls+es;\[x1;x2;⋯;xNP]+zp0;⋯;zpN
其中zp0;⋯ ;zpNz_{p}\^{0};\\cdots;z_{p}\^{N}zp0;⋯;zpN表示位置嵌入,ese_{s}es是可学习的场景嵌入。块的展平和投影、za,ms,clsz_{a,m}^{s,cls}za,ms,cls的连接以及位置嵌入基于标准的ViT方法(Dosovitskiy et al. 2021)。场景嵌入是本文为应对我们的UMS-ReID设置而引入的。
如图3所示,z0z_{0}z0经过ViT的一系列变换器层处理,在最后一层的头部产生身份表示fa,ms,if_{a,m}^{s,i}fa,ms,i,在以下描述中称为实例级图像表示。类似地获得bbb组的实例级图像表示fb,ms,if_{b,m}^{s,i}fb,ms,i。然后,在每个同构组内对实例级图像表示进行聚类以获得同构伪标签。
接着,我们计算集群级图像表示。例如,第sss个场景aaa组中第uuu个集群的表示定义为:
ca,us,i=1Na,us∑m=1Na,usfa,ms,i,c_{a,u}^{s,i}=\frac{1}{N_{a,u}^{s}}\sum_{m=1}^{N_{a,u}^{s}}f_{a,m}^{s,i},ca,us,i=Na,us1m=1∑Na,usfa,ms,i,
其中Na,usN_{a,u}^{s}Na,us表示该集群中的图像数量,fa,ms,if_{a,m}^{s,i}fa,ms,i表示该集群中的实例级图像表示。随后,我们基于同构学习优化图像编码器EIinitE_{I}^{init}EIinit,优化后的图像编码器称为EIE_{I}EI。具体而言,引入同构对比损失来基于伪标签优化EIE_{I}EI。对于一个实例级图像表示fa,ms,if_{a,m}^{s,i}fa,ms,i,同构对比损失定义为:
Lhcs,a,m=−logexp(fa,ms,i⋅ca,us,iT/τ)∑v=1Cas,iexp(fa,ms,i⋅ca,vs,iT/τ),L_{h c}^{s,a,m}=-\log\frac{\exp(f_{a,m}^{s,i}\cdot c_{a,u}^{s,i}{}^{T}/\tau)}{\sum_{v=1}^{C_{a}^{s,i}}\exp(f_{a,m}^{s,i}\cdot c_{a,v}^{s,i}{}^{T}/\tau)},Lhcs,a,m=−log∑v=1Cas,iexp(fa,ms,i⋅ca,vs,iT/τ)exp(fa,ms,i⋅ca,us,iT/τ),
其中ca,us,ic_{a,u}^{s,i}ca,us,i与fa,ms,if_{a,m}^{s,i}fa,ms,i来自同一集群,Cas,iC_{a}^{s,i}Cas,i表示第sss个场景aaa组中的集群数量,τ\tauτ是温度超参数。对于bbb组中的实例级表示fb,ms,if_{b,m}^{s,i}fb,ms,i,相应地获得损失Lhcs,b,mL_{hc}^{s,b,m}Lhcs,b,m。总体同构对比损失为:
Lhc=1B⋅S∑s=1S∑m=1B(Lhcs,a,m+Lhcs,b,m),L_{h c}=\frac{1}{B\cdot S}\sum_{s=1}^{S}\sum_{m=1}^{B}(L_{h c}^{s,a,m}+L_{h c}^{s,b,m}),Lhc=B⋅S1s=1∑Sm=1∑B(Lhcs,a,m+Lhcs,b,m),
其中BBB是批次大小。为分配同构伪标签的聚类和优化EIE_{I}EI(最小化公式4的损失)迭代进行。最终的伪标签随后用于第二阶段。
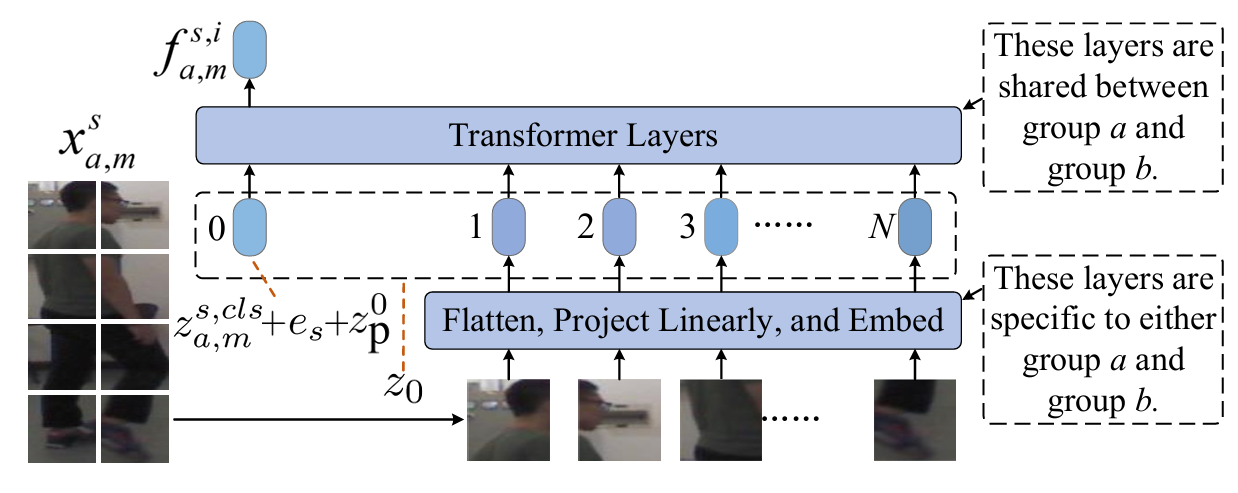
图 3: 用于从输入图像xa,msx_{a,m}^{s}xa,ms获得身份表示fa,ms,if_{a,m}^{s,i}fa,ms,i的图像编码器架构。
3.2 文本表示学习
第二阶段如图2所示,通过使用一个(第二个)预训练的CLIP模型(包含图像编码器EIinitE_{I}^{init}EIinit和文本编码器ETinitE_{T}^{init}ETinit)来学习身份相关的文本表示。具体来说,对于第一阶段保存的每个同构伪标签,学习一组文本嵌入X1X2...XMX{1}X_{2}...X_{M}X1X2...XM,通过最小化一个总体损失来优化伪标签标记句"一张X1X2...XMX{1}X_{2}...X_{M}X1X2...XM的人的照片"与具有该伪标签的图像之间的关联:
Ls2=1B⋅S∑s=1S∑m=1B(Lits,m+Ltis,m)+λmssLmss,L_{s2}=\frac{1}{B\cdot S}\sum_{s=1}^{S}\sum_{m=1}^{B}\left(L_{i t}^{s,m}+L_{t i}^{s,m}\right)+\lambda_{m s s}L_{m s s},Ls2=B⋅S1s=1∑Sm=1∑B(Lits,m+Ltis,m)+λmssLmss,
其中Lits,mL_{it}^{s,m}Lits,m和Ltis,mL_{ti}^{s,m}Ltis,m分别是图像到文本和文本到图像的对比损失,LmssL_{mss}Lmss是一个旨在鼓励场景特定文本表示并使模型有效适应不同场景的多场景分离损失,λmss\lambda_{mss}λmss是一个控制LmssL_{mss}Lmss相对重要性的权重超参数。这些损失的各个组成部分定义如下:
Lits,m=−logexp(fms,i⋅fms,tT)∑v=1Bexp(fms,i⋅fvs,tT),L_{i t}^{s,m}=-\log\frac{\exp(f_{m}^{s,i}\cdot f_{m}^{s,t^{T}})}{\sum_{v=1}^{B}\exp(f_{m}^{s,i}\cdot f_{v}^{s,t^{T}})},Lits,m=−log∑v=1Bexp(fms,i⋅fvs,tT)exp(fms,i⋅fms,tT),
Ltis,m=−1∣φms,t∣∑fus,i∈φms,tlogexp(fms,t⋅fus,iT)∑v=1Bexp(fms,t⋅fvs,iT),L_{t i}^{s,m}=\frac{-1}{\left|\varphi_{m}^{s,t}\right|}\sum_{f_{u}^{s,i}\in\varphi_{m}^{s,t}}\log\frac{\exp(f_{m}^{s,t}\cdot f_{u}^{s,i^{T}})}{\sum_{v=1}^{B}\exp(f_{m}^{s,t}\cdot f_{v}^{s,i^{T}})},Ltis,m= φms,t −1fus,i∈φms,t∑log∑v=1Bexp(fms,t⋅fvs,iT)exp(fms,t⋅fus,iT),
Lmss=∑g=1S∑h=1h≠gSκ−∥1B∑m=1B(fmg,t−fmh,t)∥22+,L_{m s s}=\sum_{g=1}^{S}\sum_{\substack{h=1\\ h\neq g}}^{S}\left\\kappa-\\left\\\|\\frac{1}{B}\\sum_{m=1}\^{B}\\left(f_{m}\^{g,t}-f_{m}\^{h,t}\\right)\\right\\\|_{2}\^{2}\\right_{+},Lmss=g=1∑Sh=1h=g∑S κ− B1m=1∑B(fmg,t−fmh,t) 22 +,
其中fvs,if_{v}^{s,i}fvs,i表示批次中第vvv个图像的表示,fvs,tf_{v}^{s,t}fvs,t是分配给第vvv个图像的伪标签句子的表示,φms,t\varphi_{m}^{s,t}φms,t表示批次中与fms,tf_{m}^{s,t}fms,t共享相同伪标签的图像表示集合,κ\kappaκ是一个确保场景间文本表示有足够分离的边际超参数,ζ+\\zeta{+}ζ+表示(实数)ζ\zetaζ的正部分。注意,可学习的文本嵌入X1X2...XMX{1}X_{2}...X_{M}X1X2...XM通过最小化公式5中的损失进行优化,同时保持编码器EIinitE_{I}^{init}EIinit和ETinitE_{T}^{init}ETinit的参数冻结。由于对所有图像执行相同的操作且不涉及异构图像之间的交互,我们在方程中不对其进行区分。
我们将句子通过ETinitE_{T}^{init}ETinit输出的文本表示称为集群级文本表示。句子的最终集群级文本表示被保存,对于每个集群内的图像,其实例级文本表示初始化为对应的集群级文本表示。保存的文本表示称为离线文本表示。
3.3 无监督异构学习
第三阶段旨在优化来自第一阶段的具有双前端分支的图像编码器,确保其身份表示对于UMS-ReID是有效的。为此,我们采用一种迭代方法,交替更新图像编码器和利用当前文本表示。具体来说,第三阶段的每次迭代首先使用当前图像编码器EIE_{I}EI获取{Xs}s=1S\{X^{s}\}{s=1}^{S}{Xs}s=1S的实例级图像表示。这些表示然后在每个同构组内进行聚类以生成同构伪标签,并类似于公式2计算集群级图像表示。利用DRU来获得由最新伪标签指导的实例级在线文本表示。利用CHM和IHM分别获得集群级异构图像对和实例级异构正样本集。一个包含同构、集群级异构、实例级异构和文本引导对比损失的总体对比损失用于更新EIE{I}EI。DRU、CHM和IHM的细节如下。
动态文本表示更新。 第二阶段保存的离线文本表示的伪标签可能与第三阶段新获得的伪标签不一致,可能会误导优化过程。为了解决这个问题,我们开发了一种动态文本表示更新(DRU)策略来获得在线文本表示。集群级和实例级文本表示之间的相互更新通过DRU实现。具体来说,在第三阶段的每次聚类迭代之后,我们首先计算集群级文本伪表示:
c^ut=1Nus∑m=1Nusfms,t,\hat{c}{u}^{t}=\frac{1}{N{u}^{s}}\sum_{m=1}^{N_{u}^{s}}f_{m}^{s,t},c^ut=Nus1m=1∑Nusfms,t,
其中NusN_{u}^{s}Nus是第sss个场景中第uuu个集群的图像数量,fms,tf_{m}^{s,t}fms,t是相应集群中的实例级文本表示。随后,我们将集群中最接近c^ut\hat{c}{u}^{t}c^ut的、占比为前η\etaη的实例级文本表示定义为邻近表示集ξ(c^ut)\xi(\hat{c}{u}^{t})ξ(c^ut),然后计算新的集群级文本表示:
cut=1∣ξ(c^ut)∣∑fms,t∈ξ(c^ut)fms,t.c_{u}^{t}=\frac{1}{|\xi(\hat{c}{u}^{t})|}\sum{f_{m}^{s,t}\in\xi(\hat{c}{u}^{t})}f{m}^{s,t}.cut=∣ξ(c^ut)∣1fms,t∈ξ(c^ut)∑fms,t.
然后,基于新的集群级文本表示,我们更新每个实例级文本表示:
fms,t←(1−α)fms,t+αcut,f_{m}^{s,t}\gets(1-\alpha)f_{m}^{s,t}+\alpha c_{u}^{t},fms,t←(1−α)fms,t+αcut,
其中α\alphaα是更新率超参数。从上述过程可以看出,DRU允许文本表示随伪标签一起更新。
DRU有效防止了文本与图像监督信号之间的不一致。此外,该策略有潜力确保集群间分离性和集群内紧凑性。一方面,基于公式9和公式10,DRU仅利用内部的实例级文本表示来计算新的集群级文本表示,从而确保集群间分离性。另一方面,DRU使用新的集群级文本表示更新集群内的所有实例级文本表示,增强了集群内紧凑性。
最后,我们设计了一个文本引导的对比损失,为EIE_{I}EI提供来自文本语义的监督信号。对于任意的fms,if_{m}^{s,i}fms,i,文本引导的对比损失定义为:
Ltgc=−1B⋅S∑s=1S∑m=1Blogexp(fms,i⋅fms,tT)∑v=1Bexp(fms,i⋅fvs,tT),L_{t g c}=-\frac{1}{B\cdot S}\sum_{s=1}^{S}\sum_{m=1}^{B}\log\frac{\exp(f_{m}^{s,i}\cdot f_{m}^{s,t^{T}})}{\sum_{v=1}^{B}\exp(f_{m}^{s,i}\cdot f_{v}^{s,t^{T}})},Ltgc=−B⋅S1s=1∑Sm=1∑Blog∑v=1Bexp(fms,i⋅fvs,tT)exp(fms,i⋅fms,tT),
其中fms,if_{m}^{s,i}fms,i和fms,tf_{m}^{s,t}fms,t分别是同一图像的实例级图像和文本表示。
集群级异构匹配。 CHM旨在识别同一身份的集群级异构图像对,每对由一个来自每个同构组的集群组成。每次聚类后,基于集群级图像表示,我们使用图匹配策略(Wu and Ye 2023)匹配集群级异构图像对和集群级异构文本对。例如,在UVI-ReID中,一个集群级异构图像对由一个红外图像组成的集群和一个可见光图像组成的集群构成,两者都被假定包含同一人的图像。接下来,我们评估集群级异构图像对和文本对之间的一致性。对于一致的对,我们直接保留相应的集群级异构图像对;对于每个不一致的对,我们以概率β∈0,1\beta \in 0,1β∈0,1随机保留相应的集群级异构图像对。每个保留的集群级异构图像对对应于两个(推测为)相互异构正样本的集群。最后,我们构建一个集群级异构对比损失以减少场景内异构性。对于任意的fa,ms,if_{a,m}^{s,i}fa,ms,i,集群级异构对比损失定义为:
Lchcs,ab,m=−logexp(fa,ms,i⋅cb,us,iT/τ)∑v=1Cbs,iexp(fa,ms,i⋅cb,vs,iT/τ),L_{c h c}^{s,a b,m}=-\log\frac{\exp(f_{a,m}^{s,i}\cdot c_{b,u}^{s,i}{}^{T}/\tau)}{\sum_{v=1}^{C_{b}^{s,i}}\exp(f_{a,m}^{s,i}\cdot c_{b,v}^{s,i}{}^{T}/\tau)},Lchcs,ab,m=−log∑v=1Cbs,iexp(fa,ms,i⋅cb,vs,iT/τ)exp(fa,ms,i⋅cb,us,iT/τ),
其中cb,us,ic_{b,u}^{s,i}cb,us,i表示与fa,ms,if_{a,m}^{s,i}fa,ms,i对应的异构正样本集群的集群级图像表示,Cbs,iC_{b}^{s,i}Cbs,i表示第sss个场景bbb组中的集群数量。对于任意的fb,ms,if_{b,m}^{s,i}fb,ms,i,集群级异构对比损失Lchcs,ba,mL_{chc}^{s,ba,m}Lchcs,ba,m类似地定义。总体集群级异构对比损失定义为:
Lchc=1B⋅S∑s=1S∑m=1B(Lchcs,ab,m+Lchcs,ba,m).L_{c h c}=\frac{1}{B\cdot S}\sum_{s=1}^{S}\sum_{m=1}^{B}(L_{c h c}^{s,a b,m}+L_{c h c}^{s,b a,m}).Lchc=B⋅S1s=1∑Sm=1∑B(Lchcs,ab,m+Lchcs,ba,m).
实例级异构匹配。 除了匹配异构正样本集群,我们还专注于在实例级获得(推测的)异构正样本集。具体来说,我们首先基于余弦相似度,在图像和文本表示空间中为每个图像搜索异构邻居集。对于任意给定图像xa,msx_{a,m}^{s}xa,ms的实例级图像表示fa,ms,if_{a,m}^{s,i}fa,ms,i,我们定义异构邻居集ψi(xa,ms)\psi_{i}(x_{a,m}^{s})ψi(xa,ms)为bbb组中对应实例级图像表示与fa,ms,if_{a,m}^{s,i}fa,ms,i余弦相似度最高的前kkk个图像集合。类似地,我们定义异构邻居集ψt(xa,ms)\psi_{t}(x_{a,m}^{s})ψt(xa,ms)为bbb组中对应实例级文本表示与图像xa,msx_{a,m}^{s}xa,ms的实例级文本表示fa,ms,tf_{a,m}^{s,t}fa,ms,t余弦相似度最高的前kkk个图像集合。随后,我们将交集ψi(xa,ms)∩ψt(xa,ms)\psi_{i}(x_{a,m}^{s})\cap\psi_{t}(x_{a,m}^{s})ψi(xa,ms)∩ψt(xa,ms)中所有图像对应的实例级图像表示集合作为fa,ms,if_{a,m}^{s,i}fa,ms,i的实例级异构正样本集Ua,ms,i={fb,us,i}U_{a,m}^{s,i}=\{f_{b,u}^{s,i}\}Ua,ms,i={fb,us,i}。类似地,我们也为fb,ms,if_{b,m}^{s,i}fb,ms,i识别一个实例级异构正样本集Ub,ms,i={fa,us,i}U_{b,m}^{s,i}=\{f_{a,u}^{s,i}\}Ub,ms,i={fa,us,i}。最后,我们构建一个实例级异构对比损失以进一步弥合场景内异构性。对于fa,ms,if_{a,m}^{s,i}fa,ms,i,实例级异构对比损失定义为:
Lihcs,ab,m=−1∣Ua,ms,i∣∑fb,us,i∈Ua,ms,ilogexp(fa,ms,i⋅fb,us,iT/τ)∑v=1Nbsexp(fa,ms,i⋅fb,vs,iT/τ),L_{ihc}^{s,ab,m}=\frac{-1}{\left|U_{a,m}^{s,i}\right|}\sum_{f_{b,u}^{s,i}\in U_{a,m}^{s,i}}\log\frac{\exp(f_{a,m}^{s,i}\cdot f_{b,u}^{s,i}{}^{T}/\tau)}{\sum_{v=1}^{N_{b}^{s}}\exp(f_{a,m}^{s,i}\cdot f_{b,v}^{s,i}{}^{T}/\tau)},Lihcs,ab,m= Ua,ms,i −1fb,us,i∈Ua,ms,i∑log∑v=1Nbsexp(fa,ms,i⋅fb,vs,iT/τ)exp(fa,ms,i⋅fb,us,iT/τ),
其中NbsN_{b}^{s}Nbs表示第sss个场景中bbb组的图像数量。对于fb,ms,if_{b,m}^{s,i}fb,ms,i,损失Lihcs,ba,mL_{ihc}^{s,ba,m}Lihcs,ba,m类似地定义。总体实例级异构对比损失为:
Lihc=1B⋅S∑s=1S∑m=1B(Lihcs,ab,m+Lihcs,ba,m).L_{ihc}=\frac{1}{B\cdot S}\sum_{s=1}^{S}\sum_{m=1}^{B}(L_{ihc}^{s,ab,m}+L_{ihc}^{s,ba,m}).Lihc=B⋅S1s=1∑Sm=1∑B(Lihcs,ab,m+Lihcs,ba,m).
对于任意给定图像,我们将该图像与通过CHM获得的异构正样本集群中的任何图像的组合,以及通过IHM获得的实例级异构正样本集中的任何图像的组合,称为一个异构正样本对。
总而言之,第三阶段的总体目标函数定义为:
Ls3=Lhc+Lchc+Lihc+λtgcLtgc,L_{s3}=L_{h c}+L_{c h c}+L_{i h c}+\lambda_{t g c}L_{t g c},Ls3=Lhc+Lchc+Lihc+λtgcLtgc,
其中λtgc\lambda_{tgc}λtgc是LtgcL_{tgc}Ltgc的权重超参数。ITKM的最终训练好的图像编码器EIE_{I}EI通过优化Ls3L_{s3}Ls3获得。
完整的ITKM过程在补充材料中总结为算法1。
4 实验
4.1 数据集和评估指标
我们在常用的SYSU-MM01(Wu et al. 2017)、LTCC(Qian et al. 2020)和MLR-CUHK03(Pang, Zhao, and Wang 2024b)上评估所提出的方法,使用平均精度均值(mAP)和累积匹配特性(CMC)作为评估指标。补充材料中包含数据集和实现细节。
4.2 与最先进方法的比较
在表1中,我们分别评估了在单个场景下训练的ITKM(记为ITKM(S))和在三个场景上联合训练的ITKM(记为ITKM(M))在SYSU-MM01、LTCC和MLR-CUHK03上的性能。
首先,我们发现ITKM(S)优于现有的无监督传统(UT)方法,包括ICE(Chen, Lagadec, and Bremond 2021)、CC(Dai et al. 2022)、Purification(Lan et al. 2023)和DCCC(He et al. 2024)。这是因为UT-ReID未考虑场景内的异构性,难以获得足够的异构正样本对,而ITKM利用CHM和IHM获取了充足的异构正样本对。
接下来,我们将ITKM与针对每个单独场景的无监督场景特定(USS)ReID方法进行比较,包括UVI-ReID方法SDCL(Yang, Chen, and Ye 2024)和TokenMatcher(Wang et al. 2025),UCC-ReID方法CICL(Pang, Zhao, and Wang 2024a)和JAPL(Pang et al. 2025),以及UCR-ReID方法DRFM(Pang, Zhao, and Wang 2024b)。我们发现,在SYSU-MM01和LTCC上,ITKM(S)与最先进的USS-ReID方法具有竞争力,在MLR-CUHK03上显著优于USS-ReID方法DRFM。这些结果不仅验证了ITKM的优越性,也确认了其在多场景中的泛化能力。
最后,我们在结合三个数据集的无监督多场景(UMS)设置下训练和测试了两种现有方法SDCL(Yang, Chen, and Ye 2024)和TokenMatcher(Wang et al. 2025)。这些方法分别记为TokenMatcher(M)和SDCL(M)。如表1所示,跨多个场景的联合训练并未改善TokenMatcher(M)和SDCL(M)的性能;相反,与单场景训练相比,它们的性能更差。这表明这些方法难以适应多个场景。相比之下,跨多场景训练的ITKM(M)在所有三个场景上都比ITKM(S)略有提升,并且显著优于TokenMatcher(M)和SDCL(M)。这是因为ITKM中的场景嵌入和多场景分离损失使图像编码器能够适应不同场景,从而提高了模型的泛化能力。补充材料中提供了进一步比较。
4.3 消融研究
在表2中,我们评估了ITKM内五个组件的有效性,具体为:场景嵌入ese^{s}es、多场景分离损失LmssL_{mss}Lmss、DRU、CHM和IHM。M1使用PGM(Wu and Ye 2023)获取异构正样本对,并采用ACCL(Wu and Ye 2023)以及离线文本表示联合优化图像编码器。其他消融方法依次将上述组件或其替代方案嵌入M1。
ese^{s}es、LmssL_{mss}Lmss和 DRU 的有效性。 如表2所示,引入场景嵌入ese^{s}es后,M2相对于M1取得了显著的性能提升。具体而言,在SYSU-MM01、LTCC和MLR-CUHK03上的Rank-1准确率分别提高了2.3%、2.4%和1.2%。这验证了场景嵌入在UMS-ReID任务中的有效性。此外,M3在M2的基础上引入LmssL_{mss}Lmss进一步提高了识别性能。为了进一步评估LmssL_{mss}Lmss的有效性,我们使用t-SNE(Van der Maaten and Hinton 2008)可视化M2和M3在第二阶段学习到的文本嵌入对应的文本表示。为了避免数据异构性的影响,我们仅可视化对应高分辨率可见光图像的文本表示,排除红外或低分辨率图像对应的部分。如图4所示,与M2相比,M3的文本表示表现出更大的场景间分离性。这证实了LmssL_{mss}Lmss通过鼓励场景特定文本表示来提升模型性能。如表2所示,M4在SYSU-MM01、LTCC和MLR-CUHK03上的Rank-1准确率比M3分别提高了2.3%、1.7%和0.7%。这些结果验证了DRU的有效性。
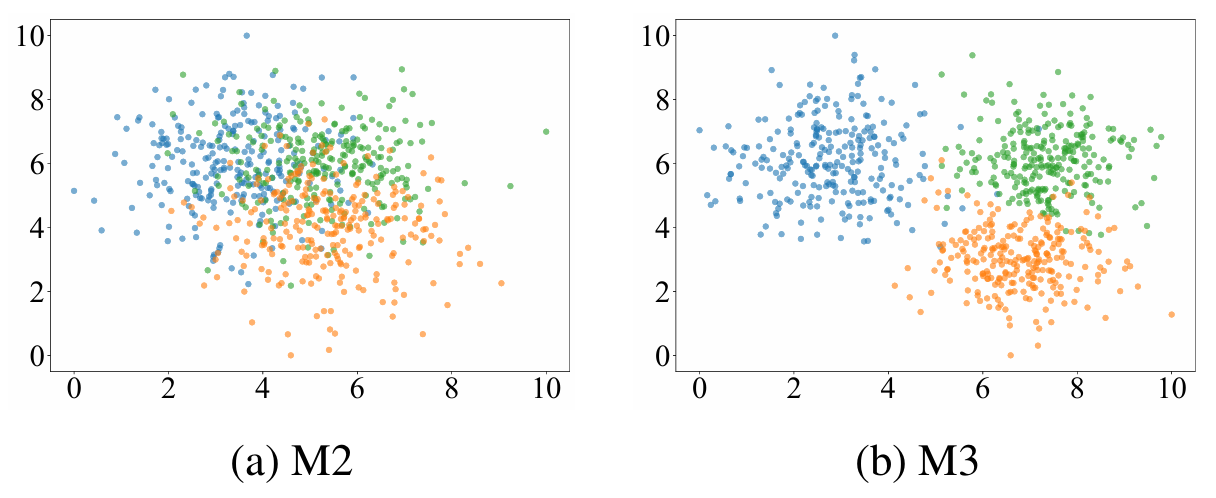
图 4: 消融方法M2和M3的文本表示的二维t-SNE(Van der Maaten and Hinton 2008)可视化。不同颜色代表来自不同场景的文本表示。
CHM 的有效性。 如表2所示,M5相对于M4实现了显著的性能提升。此外,为了评估CHM在获取可靠异构正样本对方面的有效性,我们计算了M4和M5的训练伪标签的F-score(Goutte and Gaussier 2005)。更高的F-score表明伪标签的准确性更高。如图5所示,在整个训练过程中,M5始终获得比M4更高的F-score。这证实了CHM通过提高异构正样本对的准确性来提升模型性能。
IHM 的有效性。 在表2中,M6和M7分别引入CNL(Yang, Chen, and Ye 2024)和IHM基于M5获取实例级异构正样本集,两者都取得了性能提升。这
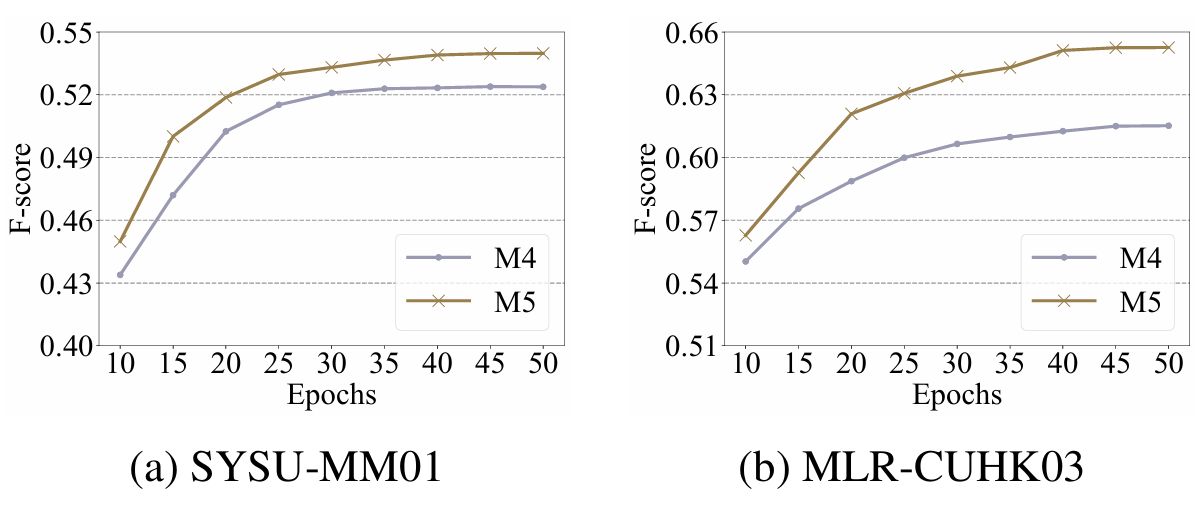
图 5: M4和M5的F-score。
证实了在实例级获取异构正样本对的可行性。此外,我们发现M7优于M6。为了进一步探究,我们在图6中可视化了M6和M7获得的一些实例级异构正样本集。与M6相比,M7有效地排除了一些视觉上相似的假正样本。这可能是由于文本编码器和图像编码器的认知焦点不同,使得IHM能够依靠一致性避免图像编码器的某些误判。相比之下,尽管CNL也依赖一致性,具体是图像编码器的浅层和深层表示之间的一致性,但它本质上是依赖图像编码器内部的知识,难以克服图像编码器固有的局限性。这验证了IHM的有效性。
5 结论
我们提出了UMS-ReID作为一个新任务,并提出了ITKM框架来应对UMS-ReID相关的挑战。消融实验验证了ITKM中各个组件的有效性,即场景嵌入和多场景分离损失有效地鼓励模型适应多个场景,而CHM和IHM则获得可靠的异构正样本对。此外,DRU通过保持文本和图像监督信号之间的一致性有效提升了模型性能。实验结果验证了ITKM的优越性和泛化性,表明它不仅在每个场景内与先进的场景特定方法有效竞争,而且能够利用多场景知识进一步提升性能。
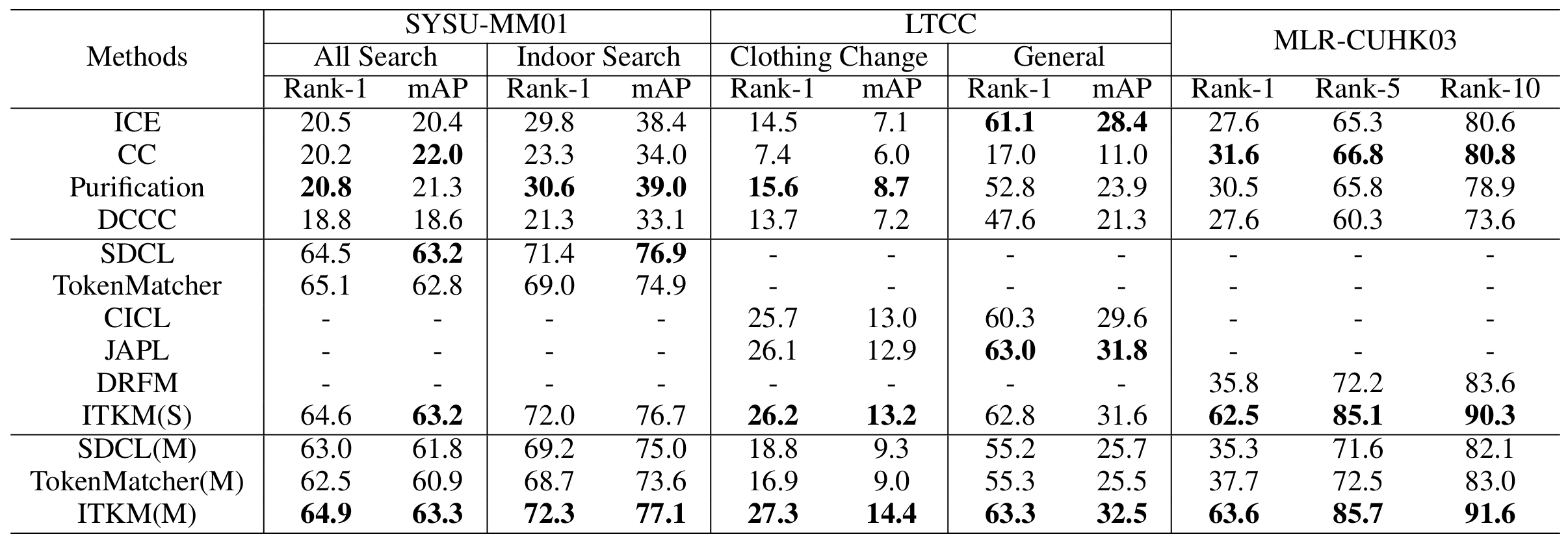
表 1: ITKM与现有方法在SYSU-MM01、LTCC和MLR-CUHK03上的比较。

表 2: 消融研究结果。"Cluster"和"Instance"分别指用于获取异构正样本集群和实例级异构正样本集的方法。

图 6: M6和M7获得的实例级异构正样本集的可视化。真正样本和假正样本分别用绿色和红色框标记。
补充材料
算法1:图像-文本知识建模(ITKM)
输入:未标记的训练集{Xs}s=1S\{X^{s}\}{s=1}^{S}{Xs}s=1S,预训练的CLIP图像和文本编码器EIinitE{I}^{init}EIinit和ETinitE_{T}^{init}ETinit,以及训练轮数。
1:EI←EIinitE_{I} \leftarrow E_{I}^{init}EI←EIinit并添加双前端
2: for i = 1 to epochs do
3: 使用EIE_{I}EI从{Xs}s=1S\{X^{s}\}_{s=1}^{S}{Xs}s=1S提取表示
4: 在每个场景的同构图像组内聚类,生成同构伪标签
5: 基于同构对比损失优化EIE_{I}EI
6: end for
7: for i = 1 to epochs do
8: 优化可学习的文本嵌入X1X2...XMX_{1}X_{2}\ldotsX_{M}X1X2...XM,通过预训练的CLIP模型将每个同构伪标签与句子"一张X1X2...XMX_{1}X_{2}\ldotsX_{M}X1X2...XM的人的照片"相关联。
9: end for
10: 使用ETinitE_{T}^{init}ETinit提取集群级文本表示
11: 使用集群级文本表示初始化实例级文本表示
12: for i = 1 to epochs do
13: 使用EIE_{I}EI从{Xs}s=1S\{X^{s}\}_{s=1}^{S}{Xs}s=1S提取表示
14: 在每个场景的同构图像组内聚类,生成同构伪标签
15: 使用DRU,获得在线集群级文本表示和在线实例级文本表示
16: 使用CHM获得异构正样本集群
17: 使用IHM获得异构正样本集
18: 优化EIE_{I}EI以最小化总体损失Ls3L_{s3}Ls3
19: end for
20: return 训练好的EIE_{I}EI
S1 同构组划分
我们将每个场景内的异构图像划分为两个同构图像组,标记为aaa和bbb。例如,在UVI-ReID中,模态标签易于获取,因此我们可以轻松获得一组可见光图像和一组红外图像。类似地,在UCR-ReID中,分辨率标签也易于获取,因此我们可以轻松地将高分辨率和低分辨率图像分组。对于UCC-ReID,由于图像编码器在初始阶段对颜色和纹理信息高度敏感(Pang, Zhao, and Wang 2024a),同一人穿着不同衣物的图像通常表现出显著的表示差异。因此,我们使用图像编码器提取所有图像的表示,并对所有表示进行K-means聚类(K=2),将图像划分为两个组。
S2 数据集详情
SYSU-MM01(Wu et al. 2017)是一个可见光-红外数据集,由四个可见光摄像头和两个红外摄像头采集。其训练集包含来自395个身份的22,258张可见光图像和11,909张红外图像,而查询集和图库集分别包含来自96个身份的红外和可见光图像。遵循现有方法(Wu and Ye 2023; Yang, Chen, and Ye 2024),我们设置了两个测试设置:All Search和Indoor Search。在All Search设置中,图库集由四个可见光摄像头采集,而在Indoor Search设置中,图库集仅由两个室内可见光摄像头采集。
LTCC(Qian et al. 2020)是一个衣物变化数据集,包含来自152个身份的17,119张图像,由12个摄像头采集,每个身份至少由两个摄像头采集。训练集、查询集和图库集分别包含9576、493和7050张图像。遵循现有方法(Li et al. 2023; Pang, Zhao, and Wang 2024a),我们使用两个测试设置:General和Clothing Change设置。General设置在图库集中同时包含衣物变化和衣物一致的图像,而Clothing Change设置在图库集中仅包含衣物变化的图像。
MLR-CUHK03是一个基于CUHK03(Li et al. 2014)的跨分辨率数据集,包含由两个摄像头采集的1,467个身份的图像。遵循现有工作(Cheng et al. 2020; Pang, Zhao, and Wang 2024b),我们使用1,367个身份进行训练,剩余的100个身份进行测试。我们使用随机下采样率γ∈{2,3,4}\gamma \in \{2, 3, 4\}γ∈{2,3,4}对一个摄像头采集的图像进行下采样以生成低分辨率(LR)图像,而另一个摄像头采集的图像用作高分辨率(HR)图像。查询集和图库集分别仅包含LR图像和HR图像。
S3 实现细节
我们使用来自CLIP(Radford et al. 2021)的预训练图像和文本编码器,并设计图像编码器EIinitE_{I}^{init}EIinit的前端为两个分支以适应所有场景。训练图像的数据增强包括随机翻转和随机擦除。在每个场景中,我们将批次大小设置为B=64。使用DBSCAN在同构组内进行聚类,距离阈值和最小样本数分别设置为0.6和4。对于可学习的文本嵌入X1X2...XMX{1}X_{2}...X_{M}X1X2...XM,我们设置M=4。对于CHM,我们设置β=0.5\beta=0.5β=0.5。对于IHM,我们设置k=200。对于DRU,我们设置η=80%\eta=80\%η=80%和α=0.8\alpha=0.8α=0.8。对于温度超参数,我们设置τ=0.05\tau=0.05τ=0.05。实验中使用超参数值λmss=2.0\lambda{mss}=2.0λmss=2.0和λtgc=1.0\lambda_{tgc}=1.0λtgc=1.0。补充材料第S5节提供了ITKM对λmss\lambda_{mss}λmss和λtgc\lambda_{tgc}λtgc在SYSU-MM01和LTCC数据集上的敏感性分析。每个训练阶段持续50轮。我们使用Adam优化器,初始学习率为0.00035,并在前10轮实现预热阶段。在测试阶段,仅使用最终训练好的图像编码器EIE_{I}EI进行推理。模型训练和评估在配置有四块NVIDIA Tesla V100 GPU的Ubuntu系统上进行。源代码可在 https://github.com/zqpang/ITKM 找到。

表 S1: ITKM与SDCL的比较。"All"、"Indoor"、"Change"、"General"和"MLR"分别代表SYSU-MM01(All Search)、SYSU-MM01(Indoor Search)、LTCC(Clothing Change)、LTCC(General)和MLR-CUHK03的Rank-1准确率。
S4 进一步比较
理论上,现有的无监督场景特定方法,如果分别在三个不同的场景上单独训练,并通过为每个场景选择相应的权重进行测试,也有可能获得与UMS-ReID方法类似的结果。为了验证这个想法,我们将现有的先进方法SDCL(Yang, Chen, and Ye 2024)分别在三个场景上单独训练,并在各自的场景上测试得到的三个模型。我们将这三个模型称为SDCL(S)。如表S1所示,SDCL(S)的性能不仅落后于ITKM(M)的性能,而且在测试阶段所需的参数数量(109)(10^{9})(109)是ITKM(M)的三倍。这是因为ITKM(M)能够将所有三个场景的知识整合到一个单一模型中。这些结果不仅证明了所提出方法的优越性,也确认了UMS-ReID的研究价值。
S5 敏感性分析
图S1展示了模型性能(Rank-1和mAP)如何随λmss\lambda_{mss}λmss从0.0变化到5.0而变化。对于λmss=0.0\lambda_{mss}=0.0λmss=0.0,LmssL_{mss}Lmss不贡献于总体损失。我们观察到,当λmss=0.0\lambda_{mss}=0.0λmss=0.0时,模型性能最差,这初步验证了LmssL_{mss}Lmss的有效性。我们还发现,当λmss=2.0\lambda_{mss}=2.0λmss=2.0时,模型在两个数据集上都获得了最佳性能,从而验证了λmss\lambda_{mss}λmss的泛化能力。
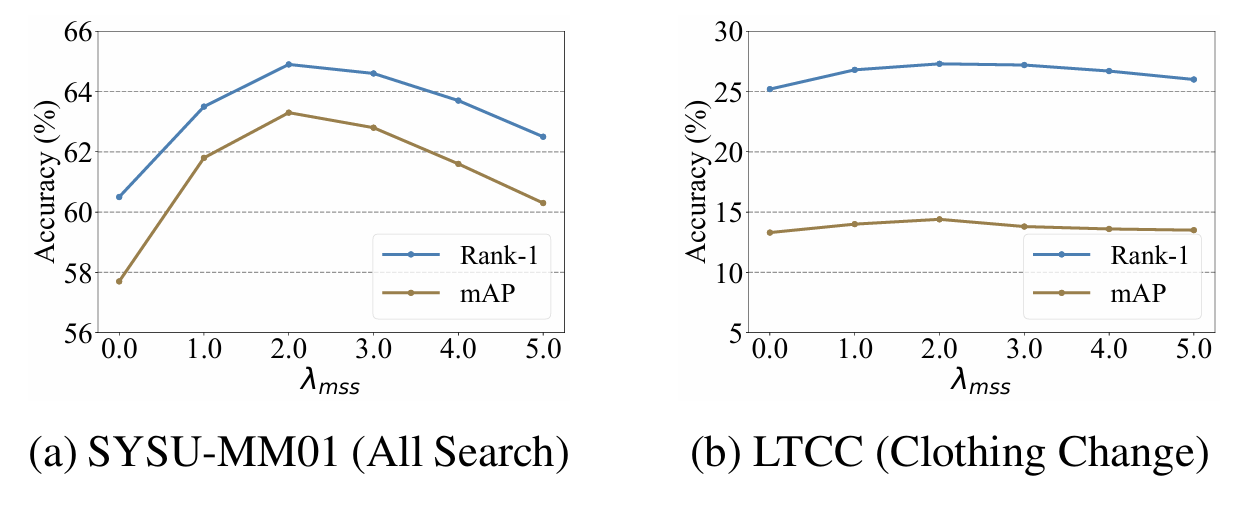
图 S1: 超参数\\lambda_{mss}对性能的影响。
在图S2中,我们研究了在两个数据集上λtgc\lambda_{tgc}λtgc的最优设置。当λtgc=1.0\lambda_{tgc}=1.0λtgc=1.0时,模型获得了最佳性能。当λtgc\lambda_{tgc}λtgc设置为较大或较小的值时,性能下降。这是因为小的λtgc\lambda_{tgc}λtgc降低了LtgcL_{tgc}Ltgc的贡献,而大的λtgc\lambda_{tgc}λtgc则削弱了CHM和IHM的效果。
我们以概率β\betaβ保留不一致的结果,是因为存在大量这样的结果(大约50%),并且并非所有结果都一定是错误的。丢弃所有结果会对数据多样性产生负面影响。如图S3所示,低的β\betaβ导致性能较差,而非常高的β\betaβ也会导致性能下降。这是因为高的β\betaβ保留了大量不可靠的匹配,这会误导优化。
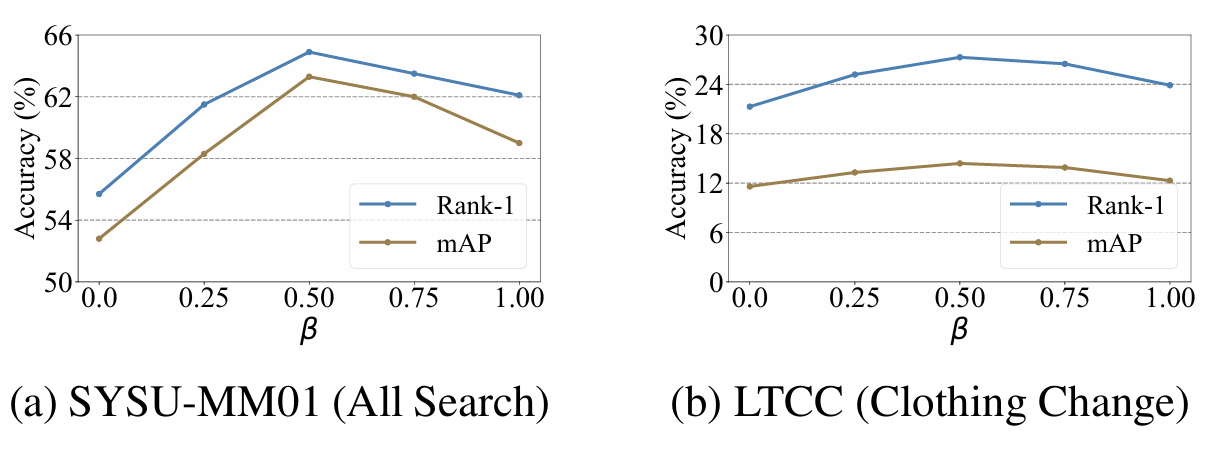
图 S3: 超参数\\beta对性能的影响。
S6 进一步分析
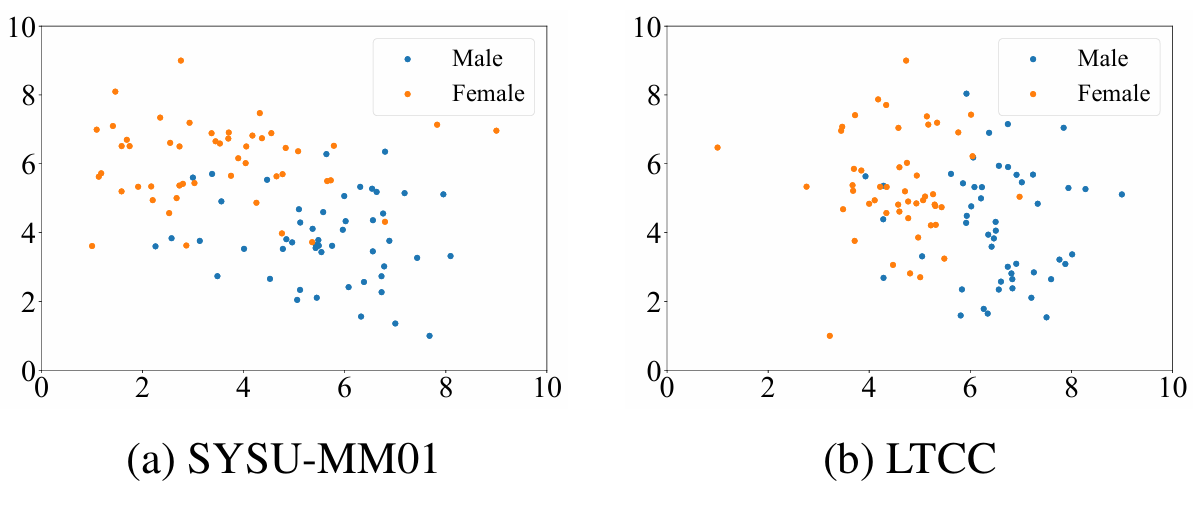
图 S4: 文本表示的二维t-SNE(Van der Maaten and Hinton 2008)可视化。
在ITKM中使用视觉语言模型的动机是利用视觉语言模型强大的表示能力,具体来说,是利用语言在更高级别语义上表示身份相关信息的能力,这些语义可能在异构组间和跨场景中保持不变。因此,我们检查了可学习的文本嵌入,以确定它们是否确实捕获了高级别的身份相关语义信息,并发现确实如此。例如,我们分别在SYSU-MM01和LTCC数据集上可视化了文本表示,如图S4所示。两种场景中的文本表示分布似乎都与性别相关。这验证了文本表示的有效性,表明它们不仅引导图像编码器适应不同场景,而且还编码了身份相关的语义信息,这有潜力促进图像编码器的身份相关学习。
进一步分析以确定学习到的文本表示如何捕获其他高级别语义显然很有趣,这不仅是为了赋予模型可解释性,但已超出本文范围。