作者:来自 Elastic Chris Hegarty, Matthew Alp 及 Nik Everet
瑞士风格启发的哈希和 SIMD 友好的设计如何在 Elasticsearch Query Language ( ES|QL ) 中提供稳定且可衡量的性能提升。
动手使用 Elasticsearch:深入我们的示例 notebooks,开始免费 cloud trial,或现在在你的本地机器上试用 Elastic。
我们最近将 Elasticsearch 的哈希表实现的关键部分替换为瑞士风格设计,并在均匀、高基数的工作负载上观察到构建和迭代时间提高了 2--3 倍。结果是更低的延迟、更高的吞吐量,以及 Elasticsearch Query Language ( ES|QL ) 统计和分析操作更可预测的性能。
为什么这很重要
大多数典型的分析工作流最终归结为对数据进行分组。无论是计算每个 host 的平均字节数、统计每个用户的事件,还是跨维度聚合指标,核心操作都是相同的 ------ 将 keys 映射到组并更新运行中的 aggregates。
在小规模下,几乎任何合理的哈希表都能正常工作。在大规模下(数亿文档和数百万个不同组),细节开始重要。负载因子、探测策略、内存布局和缓存行为可能决定性能是线性的还是满是缓存未命中的墙。
Elasticsearch 多年来一直支持这些工作负载,但我们始终在寻找现代化核心算法的机会。因此,我们评估了一种受瑞士表启发的新方法,并将其应用于 ES|QL 计算统计的方式。
瑞士表到底是什么?
瑞士表是一类现代哈希表,由 Google 的 SwissTable 推广,后来被 Abseil 和其他库采用。
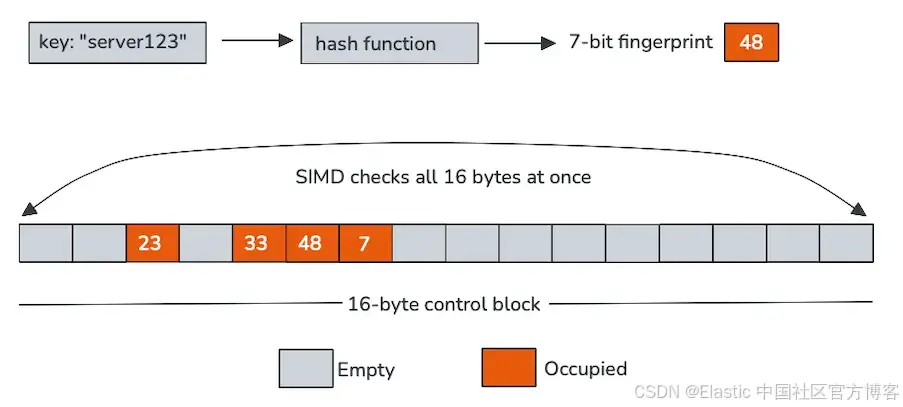
传统哈希表在追踪指针或加载 keys 时花费大量时间,结果却发现不匹配。瑞士表的定义特征是能够使用一个小型驻缓存数组结构来拒绝大多数探测,该结构与 keys 和 values 分开存储,称为 control bytes,从而显著减少内存流量。
每个控制 byte 表示一个 slot,在我们的例子中编码两件事:该 slot 是否为空,以及从 hash 派生的短 fingerprint。这些控制 bytes 在内存中连续排列,通常以 16 个为一组,非常适合单指令多数据 (SIMD) 处理。
瑞士表不是一次探测一个 slot,而是使用向量指令扫描整个 control-byte 块。在一次操作中,CPU 将进入的 key 的 fingerprint 与 16 个 slots 比较,并过滤掉空条目。只有少数通过此快速路径的候选项需要加载和比较实际 keys。
这种设计用少量额外的元数据换取更好的缓存局部性和更少的随机加载。随着表的增长和探测链的延长,这些特性变得越来越有价值。
SIMD是核心
真正的主角是 SIMD。
控制 bytes 不仅紧凑,而且专门设计为可以使用向量指令处理。一次 SIMD 比较可以同时检查 16 个 fingerprints,将原本的循环变成少量的宽操作。例如:
在实践中,这意味着:
- 更少的分支
- 更短的探测链
- 更少从 key 和 value 内存的加载
- CPU 执行单元的利用率大幅提高
大多数查找从未超过控制-byte 扫描阶段。当查找超过时,剩余工作集中且可预测。这正是现代 CPU 擅长处理的工作负载类型。
SIMD底层原理
对于喜欢深入了解底层的读者,以下是将新 key 插入表时发生的情况。我们使用 Panama Vector API 和 128 位向量,因此可以并行处理 16 个控制 bytes。
下面的代码片段显示了在带 AVX-512 的 Intel Rocket Lake 上生成的代码。虽然指令反映了该环境,但设计并不依赖于 AVX-512。在其他平台上使用等效指令(例如 AVX2、SSE 或 NEON)也会生成相同的高层向量操作。
; Load 16 control bytes from the control block
vmovdqu xmm0, XMMWORD PTR [r9+r10*1+0x10]
; Broadcast the 7-bit fingerprint of the new key across the vector
vpbroadcastb xmm1, r11d
; Compare all 16 control bytes to the new fingerprint
vpcmpeqb k7, xmm0, xmm1
kmovq rbx, k7
; Check if any matches were found
test rbx, rbx
jne <handle_match>每条指令在插入过程中都有明确作用:
- vmovdqu:将 16 个连续的控制 bytes 加载到 128 位 xmm0 寄存器中
- vpbroadcastb:将新 key 的 7 位 fingerprint 在 xmm1 寄存器的所有通道中复制
- vpcmpeqb:将每个控制 byte 与广播的 fingerprint 比较,生成潜在匹配的掩码
- kmovq + test:将掩码移动到通用寄存器,并快速检查是否存在匹配
最后,使用更宽的寄存器和相应指令在我们的基准测试中未显示出明显的性能提升。
ES|QL中的集成
在 Elasticsearch 中采用瑞士风格哈希并不是直接替换。ES|QL 对内存计算、安全性以及与其他计算引擎的集成有严格要求。
我们将新的哈希表与 Elasticsearch 的内存管理紧密集成,包括页面回收器和 circuit breaker 计数,确保分配保持可见且受限。Elasticsearch 的聚合数据密集存储,并按 group ID 索引,使内存布局紧凑、迭代快速,同时通过允许随机访问实现某些性能优化。
对于可变长度的字节 keys,我们将完整 hash 与 group ID 一起缓存。这避免了在探测过程中重新计算昂贵的 hash 码,并通过将相关元数据靠近存放来提高缓存局部性。在 rehash 过程中,我们可以依赖缓存的 hash 和控制 bytes,而无需检查值本身,从而保持调整大小成本低。
我们实现中的一个重要简化是条目从不删除。这消除了 tombstones(标记以前占用的 slots)的需求,使空 slot 保持真正空闲,进一步改善探测行为并保持控制-byte 扫描高效。
结果是一个自然适应 Elasticsearch 执行模型的设计,同时保留了瑞士表吸引人的性能特性。
性能如何?
在小基数下,瑞士表的性能大致与现有实现相当。这是预期的:当表较小时,缓存效应影响较小,几乎没有需要优化的探测。
随着基数增加,情况会迅速变化。
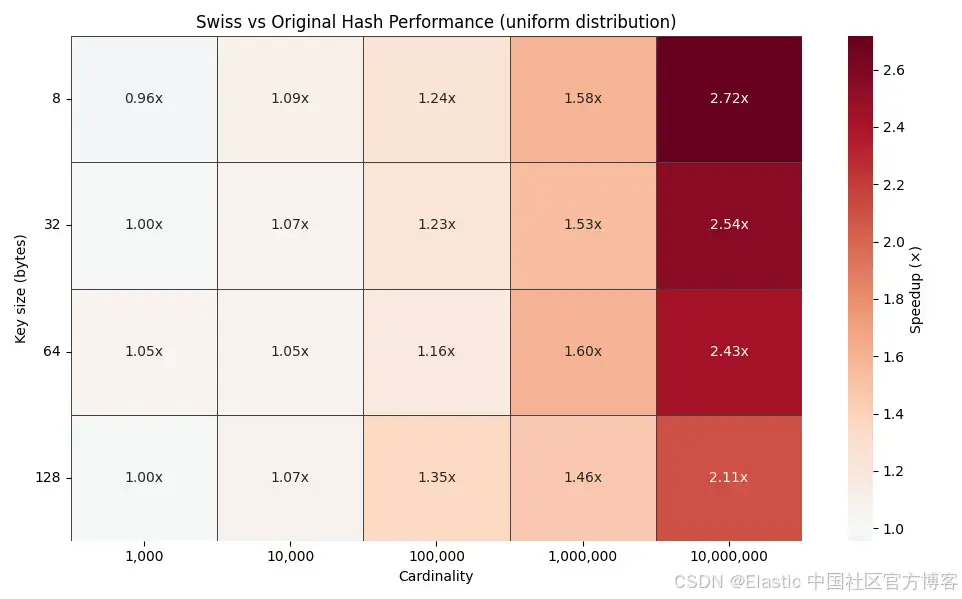
上方的热图显示了不同 key 大小(8、32、64 和 128 bytes)在基数从 1,000 到 10,000,000 组下的时间提升因子。随着基数增加,提升因子稳步上升,在均匀分布下可达到 2--3 倍。
这一趋势正是设计所预测的。传统哈希表中基数越高,探测链越长,而瑞士风格探测则继续在 SIMD 友好的控制-byte 块中解决大多数查找。
缓存行为说明一切
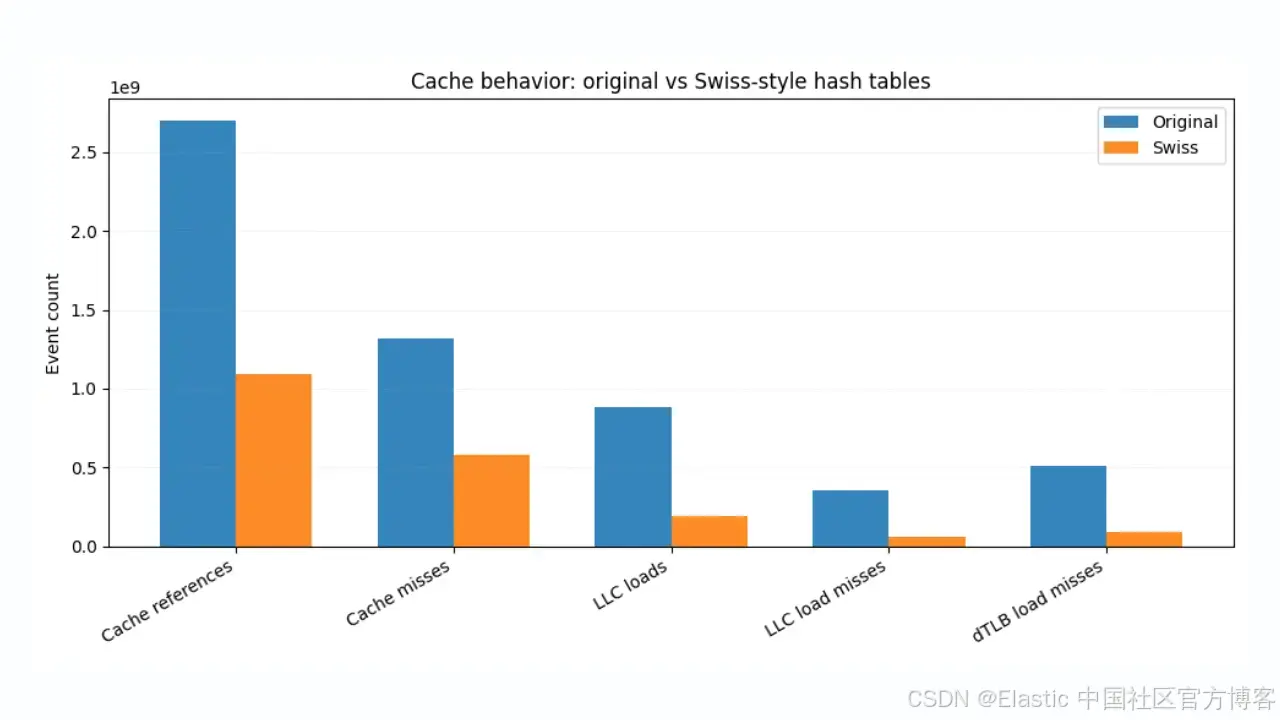
为了更好理解速度提升,我们在 Linux perf 下运行相同的 JMH 基准测试,并捕获缓存和 TLB 统计数据。
与原实现相比,瑞士版本总体缓存引用减少约 60%。最后一级缓存(LLC)加载下降超过 4 倍,LLC 加载未命中下降超过 6 倍。由于 LLC 未命中通常直接转化为主内存访问,仅这一减少就解释了端到端性能提升的大部分。
靠近 CPU 层面,我们看到 L1 数据缓存未命中减少,数据 TLB 未命中几乎减少 6 倍,显示出更紧密的空间局部性和更可预测的内存访问模式。
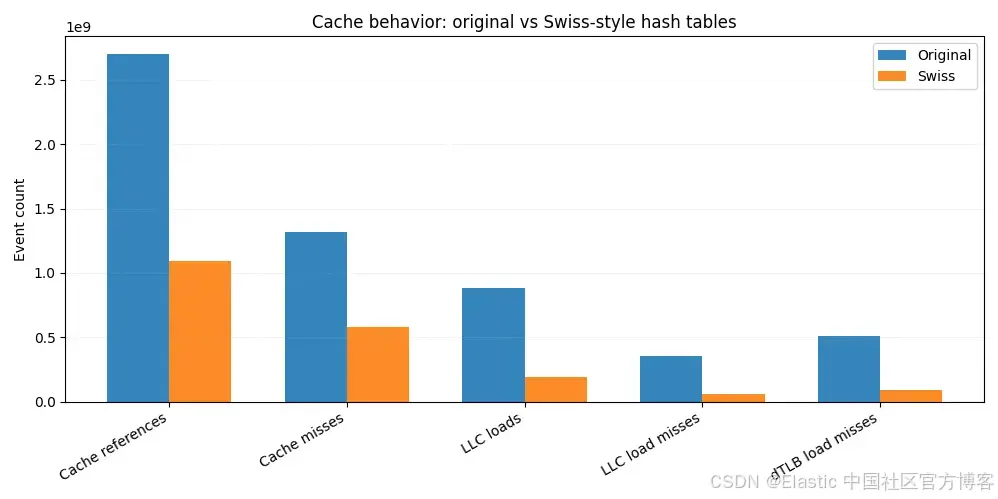
这就是 SIMD 友好控制 bytes 的实际收益。大多数探测通过扫描紧凑、驻缓存的结构即可解决,而无需反复从分散的内存位置加载 keys 和 values。访问的内存越少,未命中越少,未命中越少,查询就越快。
总结
通过采用瑞士风格哈希表设计,并充分利用 SIMD 友好探测,我们在高基数 ES|QL 统计工作负载上实现了 2--3 倍的加速,同时性能更加稳定且可预测。
这项工作强调了现代 CPU 感知数据结构如何释放可观的性能增益,即使是针对哈希表等已被广泛研究的问题。这里还有更多探索空间,例如额外的基本类型特化,以及在其他高基数路径(如 joins)中的应用,这些都只是持续现代化 Elasticsearch 内部的更广泛努力的一部分。
如果你对细节感兴趣或想跟踪这项工作,可以查看 Github 上的这个 pull request 和 meta issue。
祝哈希愉快!
原文:https://www.elastic.co/search-labs/blog/esql-swiss-hash-stats