什么是哈希表?
散列表(Hash Table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。它通过把关键码值映射到表中一个位置来访问记录,以加快查找速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
简单来说,哈希表是一种表结构,我们可以直接根据给定的key值计算出目标位置。在工程中这一表结构实现通常采用数组。
与普通的列表不同的地方在于:
普通列表仅能通过下表来获取目标位置的值,而哈希表可以根据给定的key计算得到目标位置的值。
在列表查找中,使用最广泛的二分查找算法,复杂度为O(log2n),但其始终只能用于有序列表。
普通无序列表只能采用遍历查找,复杂度为O(n)。
拥有较为理想的哈希函数实现的哈希表,对其任意元素的查找速度始终为常数级,即O(1)。
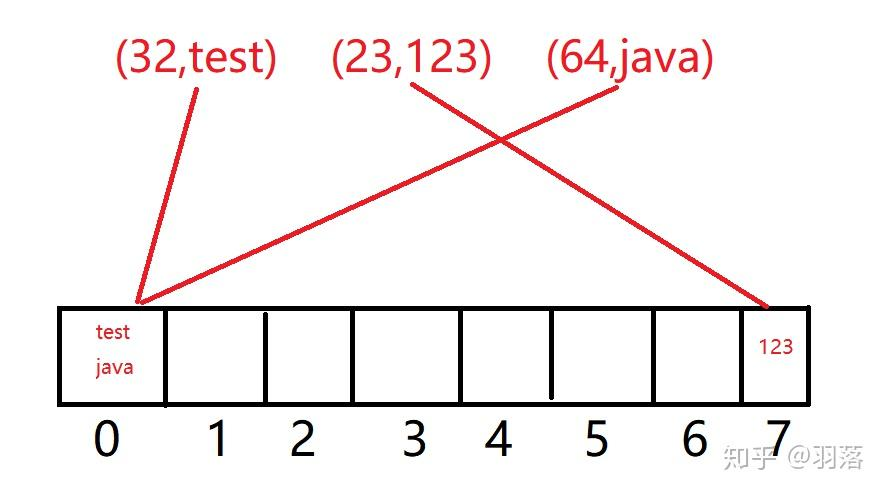
(图摘自参考资料1中链接)
我们将数组总长度设为模数,将key值直接对其取模,所得的值为数组下标。如图所示的三组数据,分别被映射到下标为0和7的位置中,显而易见,第1、3组数据发生了哈希碰撞。
如何解决哈希碰撞?
如果哈希函数设计的不好,就会经常出现哈希碰撞的现象。有两种方法:
方法一:拉链法
所谓拉链法,就是字面意思,将冲突的数据拉开。"链"就是"链表"的意思,将指向索引1的第一个学生的键值之后设计一个next指针,指向下一个学生也是指向索引1的键值,这就形成了一个链表的形状。
需要注意的是,如果遭到恶意哈希碰撞攻击,拉链法会导致哈希表退化为链表,即所有元素都被存储在同一个节点的链表中,此时哈希表的查找速度=链表遍历查找速度=O(n)。
方法二:线性探测法
就是成一个线状的趋势去探测,是否有下一个空位置给冲突的数据暂时存放,如果表中有空位,就不用将他们挤到一起形成一个链状了,链表太长也会浪费空间。注意,只能往后找空位,不能往前找。
哈希表的优势
通过前面的概念了解,哈希表可以通过关键值计算直接获取目标位置,对于海量数据中的精确查找有非常惊人的速度提升,理论上即使有无限的数据量,一个实现良好的哈希表依旧可以保持O(1)的查找速度,而O(n)的普通列表此时已经无法正常执行查找操作。
哈希表的主要应用场景
在工程上,经常用于通过名称指定配置信息,通过关键字传递参数、建立对象与对象的映射关系等。目前最流行的NoSql数据库之一Redis,整体的使用了哈希表思想。所有使用了键值对的地方,都运用到了哈希表的思想。
参考资料:
1、一篇文章教你读懂哈希表-HashMap https://zhuanlan.zhihu.com/p/84327339