摘要:
机器学习分类是一种监督学习技术,通过训练带标签数据预测新数据的类别。摘要要点:
- 分类类型:包括二元分类(如垃圾邮件检测)和多类分类
- 学习器类型:
- 懒惰学习者(如KNN)
- 积极学习者(如决策树、神经网络)
- 常用算法:逻辑回归、SVM、决策树、随机森林等
- 模型构建步骤:数据准备→特征选择→模型训练→评估调优→部署
- 评估指标:准确率、精确率、召回率、特异性等
- 应用实例:使用Python的scikit-learn库构建乳腺癌分类器,准确率达95.17%
分类算法广泛应用于垃圾邮件过滤、图像识别、欺诈检测等领域。
目录
[1. 数据准备](#1. 数据准备)
[2. 特征提取/选择](#2. 特征提取/选择)
[3. 模型选择](#3. 模型选择)
[4. 模范培训](#4. 模范培训)
[5. 模型评估](#5. 模型评估)
[5. 超参数调谐](#5. 超参数调谐)
[6. 模型部署](#6. 模型部署)
[用 Python 构建分类模型](#用 Python 构建分类模型)
机器学习中的分类
分类可以定义为根据观察值或给定数据点预测类别或类别的过程。分类输出可以是"黑色"、"白色"、"垃圾邮件"或"无垃圾邮件"等形式。
机器学习中的分类是一种监督式学习技术,通过训练算法,利用带标签的数据来预测新数据的类别。
数学上,分类是将输入变量(X)到输出变量(Y)的映射函数(f)近似的任务。它基本上属于监督机器学习,同时提供目标和输入数据集。
分类问题的一个例子是电子邮件中的垃圾邮件检测。输出只能分为两类,"垃圾邮件"和"无垃圾邮件";因此,这是一种二元类型分类。
为了实现这种分类,我们首先需要训练分类器。在这个例子中,"垃圾邮件"和"无垃圾邮件"作为训练数据。成功训练分类器后,可以用来检测未知邮件。
分类中的学习者类型
我们有两种学习者类型,分别针对分类问题------
- 懒惰学习者------顾名思义,这类学习者在存储训练数据后等待测试数据出现。分类只有在获得测试数据后才进行。他们花在训练上的时间更少,而更多时间在预测上。懒惰学习者的例子有K最近邻和基于案例的推理。
- 积极学习者------与懒惰学习者相反,积极学习者在存储训练数据后,无需等待测试数据出现,就能构建分类模型。他们花更多时间训练,但预测时间较少。积极学习者的例子包括决策树、内叶贝叶斯和人工神经网络(ANN)。
机器学习中的分类算法
分类算法是一种监督式学习技术,涉及基于一组输入特征预测一个类别目标变量。它常用于解决垃圾邮件检测、欺诈检测、图像识别、情感分析等问题。
分类模型的目标是学习输入特征(X)与目标变量(Y)之间的映射函数(f)。该映射函数通常表示为决策边界,用于区分输入特征空间中不同的类别。模型训练完成后,可以用来预测新的、未见过的实例类别。
以下是一些重要的机器学习分类算法------
我们将在后续章节详细讨论所有这些分类算法。不过,我们简要讨论这些算法如下 −
逻辑回归
逻辑回归是一种常用的二元分类算法,其中目标变量是具有两个类别的类别变量。它对输入特征下的目标变量的概率进行建模,并预测概率最高的类别。
逻辑回归是一种广义线性模型,其中目标变量遵循伯努利分布。该模型由输入特征的线性函数组成,通过逻辑函数变换,生成介于0到1之间的概率值。
K-最近邻(KNN)
K最近邻(KNN)是一种监督学习算法,可用于分类和回归问题。KNN的核心思想是找到与给定测试数据点最近的k个数据点,并利用这些最近邻进行预测。k 的值是一个需要调优的超参数,它代表需要考虑的邻居数量。
对于分类问题,KNN算法将测试数据点分配给k最近邻中出现频率最高的类别。换句话说,邻居数量最多的类就是预测类。
对于回归问题,KNN算法将k个最近邻取值的平均值分配给测试数据点。
支持向量机(SVM)
支持向量机(SVM)是一种强大且灵活的监督式机器学习算法,既可用于分类,也可用于回归分析。但通常它们用于分类问题。1960年代,最早引入了SVM,但后来在1990年进行了改进。与其他机器学习算法相比,SVM有其独特的实现方式。如今,它们因能够处理多个连续变量和类别变量而极受欢迎。
决策树
决策树算法是一种基于层次的树状算法,用于根据一套规则对结果进行分类或预测。它的工作原理是根据输入特征的值将数据拆分为子集。该算法递归地拆分数据,直到达到一个点,使每个子集的数据属于同一类或目标变量的值相同。由此生成的树是一组决策规则,可用于进行预测或分类新数据。
贝叶斯中殿
纳夫贝叶斯算法是一种基于贝叶斯定理的分类算法。该算法假设这些特征彼此独立,因此被称为"天真"。它根据样本特征的概率计算属于特定类别的概率。例如,如果手机具备触摸屏、互联网功能、良好的摄像头等,就可能被认为是智能的。即使这些特征彼此依赖,但这些特征独立地增加了手机是智能手机的概率。
随机森林
随机森林是一种机器学习算法,利用一组决策树进行预测。该算法最早由Leo Breiman于2001年提出。该算法的核心思想是创建大量决策树,每个决策树训练于不同的数据子集。这些单独树的预测随后被合并,生成最终预测。
分类在机器学习中的应用
分类算法的一些最重要的应用如下 −
- 语音识别
- 手写识别
- 生物识别
- 文件分类
- 图像分类
- 垃圾邮件过滤
- 欺诈检测
- 面部识别
构建机器学习中的经典化模型
现在让我们看看构建分类模型所涉及的步骤 −
1. 数据准备
第一步是收集和预处理数据。这包括清理数据、处理缺失值以及将类别变量转换为数值。
2. 特征提取/选择
下一步是从数据中提取或选择相关特征。这是一个重要步骤,因为特征质量会极大影响模型的性能。一些常见的特征选择技术包括相关分析、特征重要性排名和主成分分析。
3. 模型选择
选定特征后,下一步是选择合适的分类算法。有许多不同的算法可供选择,每种都有其优缺点。一些流行的算法包括逻辑回归、决策树、随机森林、支持向量机和神经网络
4. 模范培训
选择合适算法后,下一步是用带标签的训练数据训练模型。在训练过程中,模型学习输入特征与目标变量之间的映射函数。模型参数会通过迭代调整,以最小化预测输出与实际输出之间的差异。
5. 模型评估
模型训练完成后,下一步是评估其在一组独立验证数据上的表现。这样做是为了估算模型的准确性和泛化性能。常见的评估指标包括准确性、精度、召回率、F1分数以及接收者工作特征(ROC)曲线下的面积。
5. 超参数调谐
在许多情况下,通过调整超参数可以进一步提升模型的性能。超参数是在训练模型和控制方面(如学习率、正则化强度和神经网络隐藏层数)之前选择的设置。网格搜索、随机搜索和贝叶斯优化是超参数调优常用的一些技术。
6. 模型部署
模型训练和评估完成后,最后一步是将其部署到生产环境中。这包括将模型集成到更大的系统中,在真实世界数据上进行测试,并随时间监控其性能。
用 Python 构建分类模型
Scikit-learn,一个用于机器学习的Python库,可以用来构建Python分类器。在Python中构建分类器的步骤如下 −
步骤1:导入必要的Python包
使用 scikit-learn 构建分类器时,我们需要导入它。我们可以通过以下脚本 − 导入它
python
import sklearn步骤2:导入数据集
导入必要的软件包后,我们需要一个数据集来构建分类预测模型。我们可以从sklearn数据集导入,也可以根据需求使用其他数据集。我们将使用sklearns威斯康星乳腺癌诊断数据库。我们可以通过以下脚本导入它 −
python
from sklearn.datasets import load_breast_cancer以下脚本将加载数据集;
python
data = load_breast_cancer()我们还需要组织数据,这可以通过以下脚本完成------
python
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']以下命令将打印标签名称,在我们的数据库中为恶性 和**"良性"**。
python
print(label_names)上述命令的输出是标签的名称 −
python
['malignant' 'benign']这些标签映射为二进制值0和1。恶性 癌症代表0,良性癌症代表1。
这些标签的特征名称和特征值可以通过以下命令查看 −
python
print(feature_names[0])上述命令的输出是标签0的特征名称,即恶性癌症 −
python
mean radius类似地,标签特征的名称可以如下表示 −
python
print(feature_names[1])上述命令的输出是标签1的特征名称,即良性癌症 −
python
mean texture我们可以通过以下命令 − 打印这些标签的特征
python
print(features[0])这将得到以下输出−
[1.799e+01 1.038e+01 1.228e+02 1.001e+03 1.184e-01 2.776e-01 3.001e-01 1.471e-01 2.419e-01 7.871e-02 1.095e+00 9.053e-01 8.589e+00 1.534e+02 6.399e-03 4.904e-02 5.373e-02 1.587e-02 3.003e-02 6.193e-03 2.538e+01 1.733e+01 1.846e+02 2.019e+03 1.622e-01 6.656e-01 7.119e-01 2.654e-01 4.601e-01 1.189e-01]
我们可以通过以下命令 − 打印这些标签的特征
python
print(features[1])这将得到以下输出−
[2.057e+01 1.777e+01 1.329e+02 1.326e+03 8.474e-02 7.864e-02 8.690e-02 7.017e-02 1.812e-01 5.667e-02 5.435e-01 7.339e-01 3.398e+00 7.408e+01 5.225e-03 1.308e-02 1.860e-02 1.340e-02 1.389e-02 3.532e-03 2.499e+01 2.341e+01 1.588e+02 1.956e+03 1.238e-01 1.866e-01 2.416e-01 1.860e-01 2.750e-01 8.902e-02]
步骤3:将数据组织为训练和测试集
由于我们需要在未见数据上测试模型,我们将数据集分为两部分:训练集和测试集。我们可以用sklearn 的python包*train_test_split()*函数将数据拆分成集合。以下命令将导入函数 −
python
from sklearn.model_selection import train_test_split接下来,下一个命令会将数据拆分为训练数据和测试数据。在这个例子中,我们使用了40%的数据用于测试,60%的数据用于训练------
python
train, test, train_labels, test_labels =
train_test_split(features,labels,test_size = 0.40, random_state = 42)步骤4:模型评估
将数据分为训练和测试后,我们需要构建模型。我们将为此使用Nave Bayes 算法。以下命令将导入高斯NB模块 −
python
from sklearn.naive_bayes import GaussianNB现在,初始化模型如下 −
python
gnb = GaussianNB()接下来,借助 following 命令,我们可以训练模型 −
python
model = gnb.fit(train, train_labels)现在,为了评估目的,我们需要做出预测。可以通过使用预测函数实现,具体如下 −
python
preds = gnb.predict(test)
print(preds)这将得到以下输出−
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0
1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0
1 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0
1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0
1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0
0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1
0 0 1 1 0 1]上述输出中的0和1系列是恶性 肿瘤和良性肿瘤类别的预测值。
步骤5:寻找准确性
我们可以通过比较两个数组------test_labels 和preds ,来确定前一步构建模型的准确性。我们将使用*accuracy_score()*函数来确定准确性。
python
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965上述输出显示NaveBayes分类器的准确率为95.17%。
分类模型的评估指标
即使你已经完成了机器学习应用或模型的实现,工作也还没完成。我们必须弄清楚我们的模式有多有效?评估/性能指标可以不同,但我们必须谨慎选择,因为指标的选择会影响机器学习算法性能的测量和比较方式。
以下是一些重要的分类评估指标,您可以根据您的数据集和问题类型选择------
混淆矩阵
混淆矩阵是衡量分类问题性能的最简单方法,当输出可以是两种或更多类型的类别时。混淆矩阵不过是一个具有两个维度的表格,即"实际"和"预测",而且这两个维度都有"真阳性(TP)"、"真阴性(TN)"、"假阳性(FP)"、"假阴性(FN)",如下所示 −
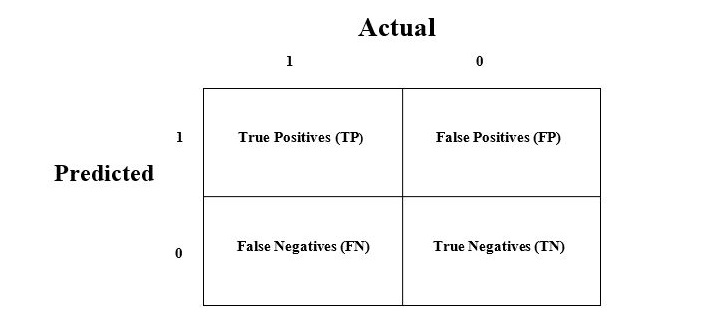
与混淆矩阵相关的术语解释如下 −
- 真阳性(TP)− 当实际类别和预测类别数据点皆为1时,情况即为真阳性。
- 真负(TN)− 当实际类别和预测类别数据点均为0时,情况即为真负。
- 假阳性(FP)− 当实际数据点类别为0,预测类别为1时,即为假阳性。
- 假阴性(FN)− 当实际数据类别为1,预测类别为0时,即为假阴性。
我们可以借助 sklearn 的 confusion_matrix() 函数找到混淆矩阵。借助以下脚本,我们可以找到上述构建的二元分类器的混淆矩阵 −
python
from sklearn.metrics import confusion_matrix
preds = gnb.predict(test)
cm = confusion_matrix(test, preds)
print(cm)输出
[ [ 73 7] [ 4 144] ]
准确性
它可以定义为我们的机器学习模型所做出的正确预测数量。我们可以通过以下公式 − 的帮助,通过混淆矩阵轻松计算
对于上述构建的二进制分类器,TP + TN = 73+144 = 217,TP+FP+FN+TN = 73+7+4+144=228。
因此,准确率 = 217/228 = 0.951754385965,与我们创建二元分类器后计算的结果相同。
精度
精确度在文档检索中使用,可以定义为我们的机器学习模型返回的正确文档数量。我们可以通过以下公式 − 的帮助,通过混淆矩阵轻松计算
对于上述构建的二进制分类器,TP = 73,TP+FP = 73+7 = 80。
因此,精度 = 73/80 = 0.915
召回还是敏感
回忆可以定义为我们的机器学习模型返回的正向数量。我们可以通过以下公式 − 的帮助,通过混淆矩阵轻松计算
对于上述构建的二进制分类器,TP = 73,TP+FN = 73+4 = 77。
因此,精度 = 73/77 = 0.94805
特异性
与回忆不同,特异性可定义为我们的机器学习模型返回的阴性数量。我们可以通过以下公式 − 的帮助,通过混淆矩阵轻松计算
对于上述构建的二进制分类器,TN = 144,TN+FP = 144+7 = 151。
因此,精度 = 144/151 = 0.95364
在接下来的章节中,我们将详细讨论机器学习中一些最受欢迎的分类算法。