序列到序列模型,即 seq2seq,是一类深度学习模型:将一个序列数据作为输入,然后输出另一个序列数据。seq2seq 模型在自然语言处理,机器翻译,以及时间序列数据的预测中具有广泛应用。
seq2seq 的结构类似下图:
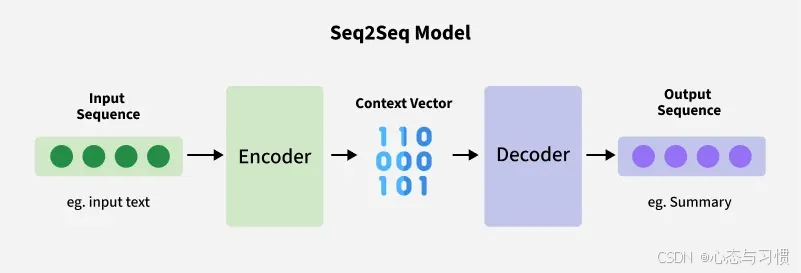
1. Encoder
编码器,依次处理序列数据中的每一个 token(词元),生成一个固定长度的 contex vector.
- token 是模型处理的最小文本或时间步单位
2. Convex vector
- 标准 seq2seq 模型的 encoder 一般是 RNN, LSTM 或 GRU,convex vector 是输入序列产生的隐藏状态
- 在引入 Attention(注意力) 后,Transformer 模型中的 context vector 的定义变得更加灵活、强大。
3. Decoder
- 解码器,将 convex vector 作为输入,并生成一个序列数据的输出
- 根据 contex vector 以及之前的 token,预测并输出下一个 token
4. 一个例子
下面的例子使用 seq2seq 调用了 lstm 作为编码器与解码器,预测 air passengers 数据.
python
"""
Python version: 3.12.7
Author: Zhen Chen, chen.zhen5526@gmail.com
Date: 2025/12/2 12:58
Description:
"""
import numpy as np
import pandas as pd
import torch
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 读取 AirPassengers 数据
from statsmodels.datasets import get_rdataset
data = get_rdataset("AirPassengers").data
ts = data["value"].values
# 归一化
scaler = MinMaxScaler()
ts_scaled = scaler.fit_transform(ts.reshape(-1, 1))
# 构建序列
def create_sequences(data, input_len=12, output_len=1):
X, y = [], []
for i in range(len(data) - input_len - output_len + 1):
X.append(data[i : i + input_len])
y.append(data[i + input_len : i + input_len + output_len])
return np.array(X), np.array(y)
input_len = 12
output_len = 1
X, y = create_sequences(ts_scaled, input_len, output_len)
# PyTorch 训练时,输入数据类型一般都是 torch.float32 类型
# 多分类数据时才是 torch.long 类型
X = torch.tensor(X, dtype=torch.float32) # [N, 12, 1]
y = torch.tensor(y, dtype=torch.float32) # [N, 12, 1]
# 对于这种时间序列数据,不能随机打乱划分训练数据
train_size = int(len(X) * 0.8)
X_train = X[:train_size]
X_test = X[train_size:]
y_train = y[:train_size]
y_test = y[train_size:]
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, input_dim=1, hidden_dim=64, num_layers=1):
super().__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
def forward(self, x):
outputs, (h, c) = self.lstm(x) # outputs 为每个所有时间步的隐藏状态
return h, c
class Decoder(nn.Module):
def __init__(self, output_len=1, hidden_dim=64, output_dim=1, num_layers=1):
super().__init__()
self.output_len = output_len
self.lstm = nn.LSTM(output_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(
hidden_dim, output_dim
) # nn.Linear 对输入张量的最后一维做线性变换,hidden_dim, output_dim 分别是输入数据
# 和输出数据的最后一个维度
# 改为 self.linear 也可以,则下面 forward 中也得叫 self.linear
def forward(self, h, c):
# decoder 输入初始化:用 0 向量作为起点
# h 的形状: [num_layers * num_directions, batch_size, hidden_dim]
# PyTorch 的 LSTM 输入必须是 3 维张量,格式是:
# [batch_size, seq_len, input_size]
decoder_input = torch.zeros(
(h.size(1), 1, output_len) # 中间是 1 表示为 1 个时间步
) # [batch, seq=1, feature=1]
outputs = []
for _ in range(self.output_len):
# 第一个输入为 decoder_input
out, (h, c) = self.lstm(decoder_input, (h, c))
pred = self.fc(out) #
outputs.append(pred)
decoder_input = pred # 下一个时间步用前一步预测
outputs = torch.cat(outputs, dim=1) # outputs 的维度 [batch, 1, 1]
return outputs
class Seq2Seq(nn.Module):
def __init__(self):
super().__init__()
self.encoder = Encoder()
self.decoder = Decoder(output_len=output_len)
def forward(self, x):
h, c = self.encoder(x)
out = self.decoder(h, c)
return out
model = Seq2Seq()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
epochs = 300
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
output = model(X_train)
loss = criterion(output, y_train)
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f"Epoch {epoch+1}/{epochs} Loss = {loss.item():.6f}")
model.eval() # 切换到评估模式
with torch.no_grad():
pred_scaled = model(X_test)
pred_np = pred_scaled.detach().cpu().numpy()
pred_np = pred_np.reshape(-1, 1) # (-1, 1) 第一个 -1 表示推断
prediction = scaler.inverse_transform(pred_np)
y_test_np = y_test.detach().cpu().numpy()
y_test_np = y_test_np.reshape(-1, 1) # (-1, 1) 第一个 -1 表示推断
y_test_true = scaler.inverse_transform(y_test_np)
# 平均绝对误差 MAE
mae = np.mean(np.abs(prediction - y_test_true))
# 总绝对误差 SAE(sum of absolute errors)
sae = np.sum(np.abs(prediction - y_test_true))
# (可选)均方根误差 RMSE
rmse = np.sqrt(np.mean((prediction - y_test_true) ** 2))
print(f"平均绝对误差 (MAE): {mae:.6f}")
print(f"总绝对误差 (SAE): {sae:.6f}")
print(f"均方根误差 (RMSE): {rmse:.6f}")
plt.figure(figsize=(10, 5))
plt.plot(ts, label="real")
plt.plot(range(len(ts) - len(prediction), len(ts)), prediction, label="Predicted")
plt.legend()
plt.title("Seq2Seq LSTM Forecast - AirPassengers")
plt.show()参考文献[1](#1):