📖标题:Rank4Gen: RAG-Preference-Aligned Document Set Selection and Ranking
🌐来源:arXiv, 2601.11273v1
🌟摘要
在 RAG 范式中,信息检索模块通过检索和排序多个文档来支持证据的聚合来为生成器提供上下文。然而,现有的排名模型主要针对查询-文档相关性进行了优化,这通常与生成器对证据选择和引用的偏好不一致,限制了它们对响应质量的影响。此外,大多数方法没有考虑生成器之间的偏好差异,导致交叉生成器性能不稳定。我们提出了Rank4Gen,一种用于RAG的生成器感知排序器,它针对生成器的排名目标。Rank4Gen 引入了两个关键偏好建模策略:(1)从排名与响应质量的相关性中,它优化了下游响应质量的排名,而不是查询-文档相关性; (2) 特定于生成器的偏好建模,它在不同的生成器上调节单个排序器以捕获它们不同的排名偏好。为了实现这种建模,我们构建了 PRISM,这是一个从多个开源语料库和多样化的下游生成器构建的数据集。在五个具有挑战性和最近的 RAG 基准上的实验表明,RRank4Gen 在 RAG 中对复杂证据组合实现了强大且有竞争力的性能。
🛎️文章简介
🔸研究问题:如何通过针对生成器的偏好来改进检索增强生成(RAG)系统中的文档选择和排序问题。
🔸主要贡献:论文提出了一种新的生成器感知排序模型Rank4Gen,旨在通过建模文档子集的响应质量以及特定生成器的偏好来优化文档选择与排序。
📝重点思路
🔸构建PRISM数据集,通过多阶段的管道进行数据收集和偏好对齐,为生成器感知的文档选择和排序提供统一的监督。
🔸引入两种偏好建模策略:第一,从排名相关性转向响应质量,以提高生成器输出的质量;第二,生成器特定偏好建模,通过条件化单一排序模型,使其能够适应不同生成器的偏好。
🔸通过Rank4Gen采用集合选择的范式,输出特定于生成器的文档子集,而不是简单地排列所有候选文档。
🔸模型训练采用了两阶段程序,首先通过监督学习进行相关性初始化,然后通过直接偏好优化训练以提高模型适应不同生成器的能力。
🔎分析总结
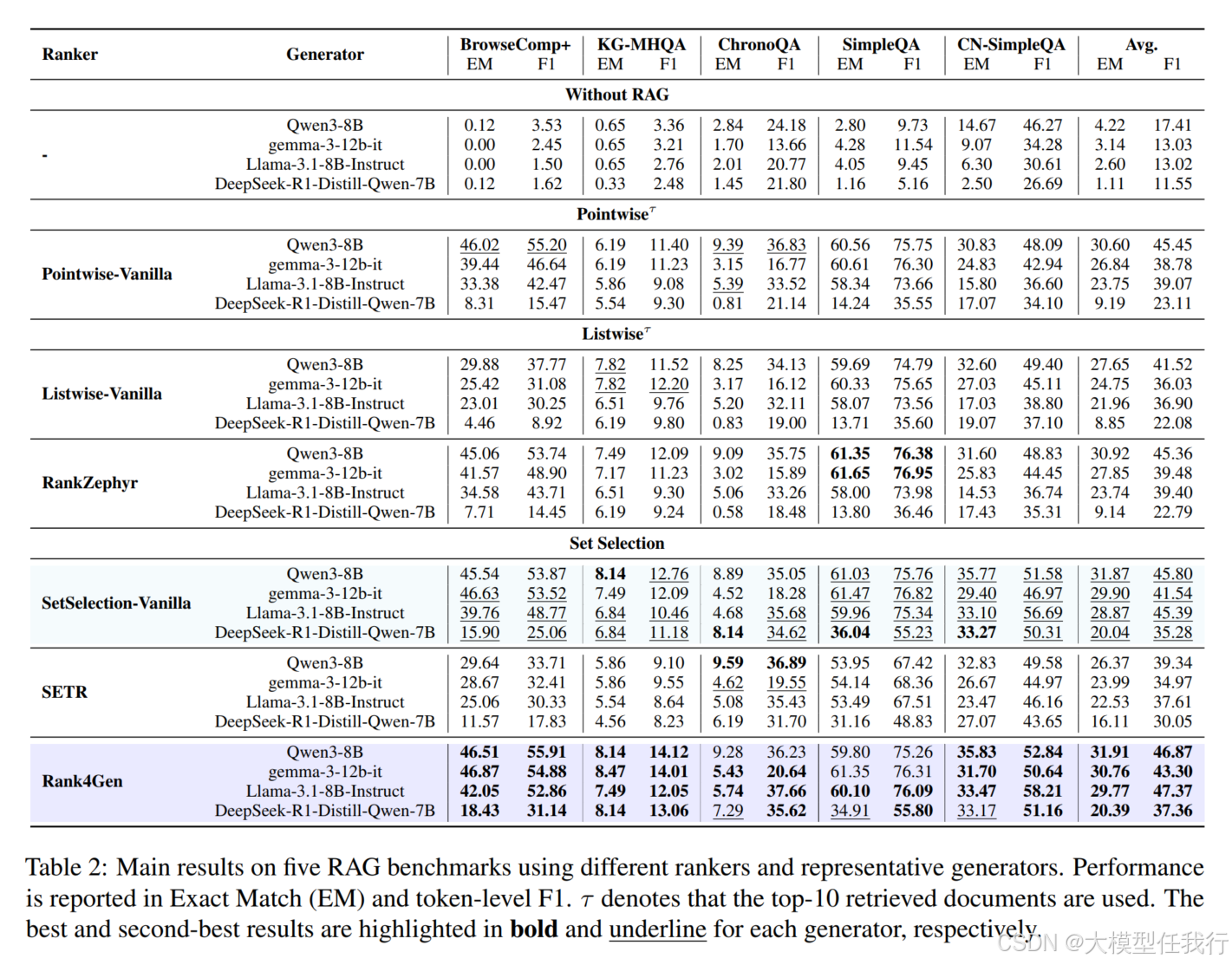
🔸实验结果表明,Rank4Gen在多个挑战性RAG基准测试中表现优异,尤其是在生成质量和生成器鲁棒性方面。
🔸通过对比不同排序方法,发现基于集合选择的方法相较于常规的点对点和列表排序方法在适应性和生成质量上更具优势。
🔸引入的偏好优化显著提高了通过多个文档归纳生成的质量,强调了文档组成和排序对生成效果的重要性。
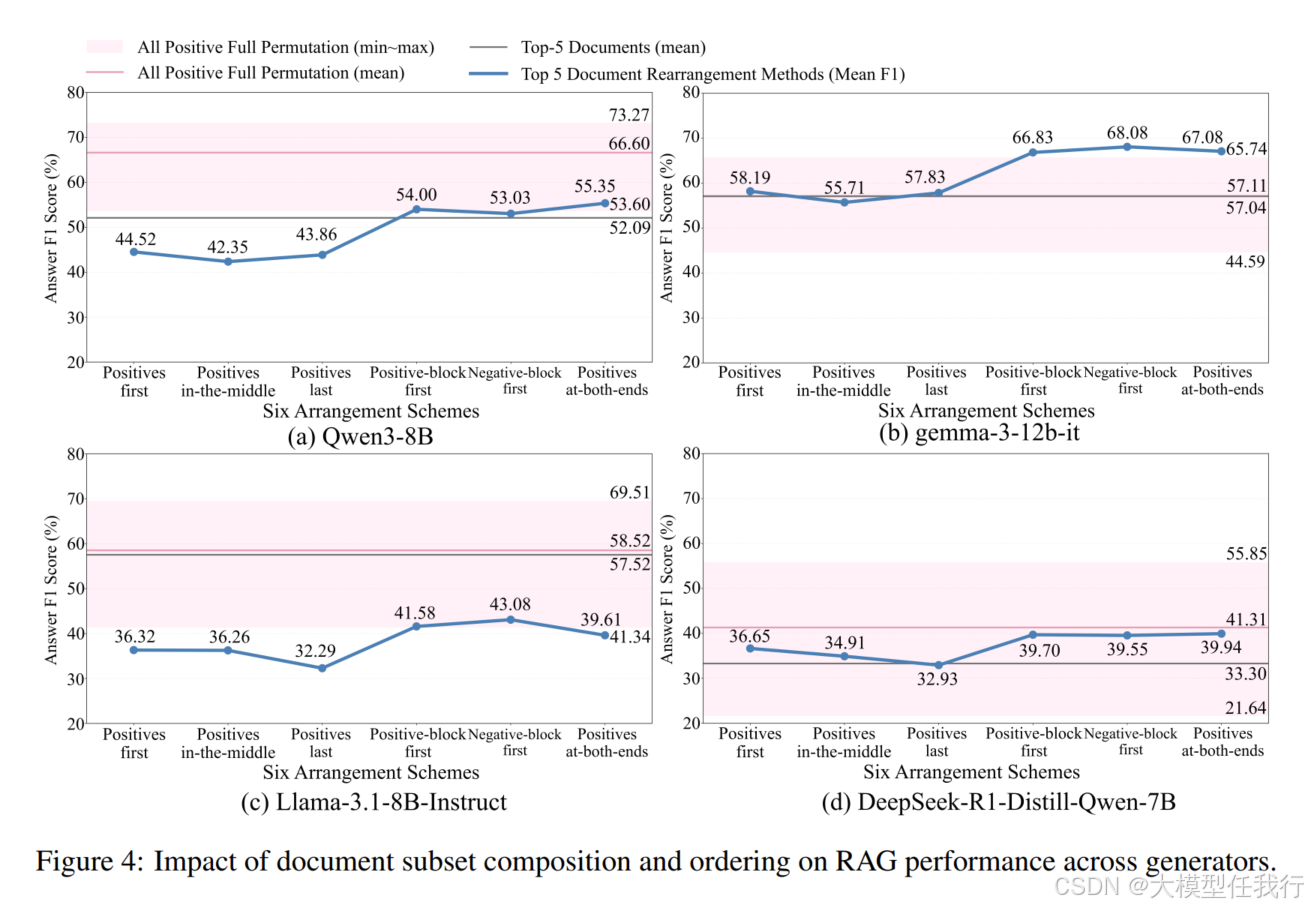
🔸尽管在某些生成器上,在Exact Match(EM)衡量标准上有所下降,但在F1分数上表现提高,表明生成器选择更大的或更具多样性的文档集可以促进更全面的答案生成。
💡个人观点
论文强调端到端的响应质量作为奖励信号,检索要与生成器特征相匹配。
🧩附录