🔥本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~持续更新中!!

全文目录:
-
-
- [🌟 开篇语](#🌟 开篇语)
- [📌 上期回顾](#📌 上期回顾)
- [🎯 本节目标](#🎯 本节目标)
- [一、Python 环境安装与验证](#一、Python 环境安装与验证)
-
- [1.1 检查现有 Python 版本](#1.1 检查现有 Python 版本)
- [1.2 全新安装 Python(按操作系统)](#1.2 全新安装 Python(按操作系统))
- [1.3 常见问题排查](#1.3 常见问题排查)
- 二、虚拟环境配置(核心重点)
-
- [2.1 为什么需要虚拟环境?](#2.1 为什么需要虚拟环境?)
- [2.2 创建项目目录和虚拟环境](#2.2 创建项目目录和虚拟环境)
- [2.3 虚拟环境的日常使用](#2.3 虚拟环境的日常使用)
- [三、配置 pip 国内镜像源(必做!)](#三、配置 pip 国内镜像源(必做!))
-
- [3.1 为什么要配置镜像源?](#3.1 为什么要配置镜像源?)
- [3.2 临时使用镜像源](#3.2 临时使用镜像源)
- [3.3 永久配置镜像源(推荐)](#3.3 永久配置镜像源(推荐))
- [3.4 常用国内镜像源(任选其一)](#3.4 常用国内镜像源(任选其一))
- [3.5 验证镜像配置](#3.5 验证镜像配置)
- 四、安装爬虫核心依赖库
-
- [4.1 升级 pip 本身](#4.1 升级 pip 本身)
- [4.2 创建 requirements.txt](#4.2 创建 requirements.txt)
- [4.3 批量安装依赖](#4.3 批量安装依赖)
- [4.4 验证安装成功](#4.4 验证安装成功)
- 五、开发工具配置
-
- [5.1 VSCode 配置(推荐新手)](#5.1 VSCode 配置(推荐新手))
- [5.2 PyCharm 配置(专业用户)](#5.2 PyCharm 配置(专业用户))
- [5.3 推荐的编辑器设置](#5.3 推荐的编辑器设置)
- 六、抓包工具配置(重要!)
-
- [6.1 浏览器开发者工具(必会)](#6.1 浏览器开发者工具(必会))
- [6.2 Postman 安装(可选但推荐)](#6.2 Postman 安装(可选但推荐))
- 七、常见安装错误排查
-
- [7.1 错误:`pip install` 超时](#7.1 错误:
pip install超时) - [7.2 错误:权限不足](#7.2 错误:权限不足)
- [7.3 错误:缺少编译工具(lxml 安装失败)](#7.3 错误:缺少编译工具(lxml 安装失败))
- [7.4 错误:Playwright 初始化失败](#7.4 错误:Playwright 初始化失败)
- [7.1 错误:`pip install` 超时](#7.1 错误:
- 八、文件结构规范(养成好习惯)
-
- [8.1 推荐的初始目录结构](#8.1 推荐的初始目录结构)
- [8.2 创建 .gitignore 文件](#8.2 创建 .gitignore 文件)
- [8.3 初始化 Git 仓库(可选)](#8.3 初始化 Git 仓库(可选))
- 九、本节小结
- [📝 课后作业(必做,验收进入下一章)](#📝 课后作业(必做,验收进入下一章))
- [🔮 下期预告](#🔮 下期预告)
- [🌟 文末](#🌟 文末)
-
- [📌 专栏持续更新中|建议收藏 + 订阅](#📌 专栏持续更新中|建议收藏 + 订阅)
- [✅ 互动征集](#✅ 互动征集)
-
🌟 开篇语
哈喽,各位小伙伴们你们好呀~我是【喵手】。
运营社区: C站 / 掘金 / 腾讯云 / 阿里云 / 华为云 / 51CTO
欢迎大家常来逛逛,一起学习,一起进步~🌟
我长期专注 Python 爬虫工程化实战 ,主理专栏 👉 《Python爬虫实战》:从采集策略 到反爬对抗 ,从数据清洗 到分布式调度 ,持续输出可复用的方法论与可落地案例。内容主打一个"能跑、能用、能扩展 ",让数据价值真正做到------抓得到、洗得净、用得上。
📌 专栏食用指南(建议收藏)
- ✅ 入门基础:环境搭建 / 请求与解析 / 数据落库
- ✅ 进阶提升:登录鉴权 / 动态渲染 / 反爬对抗
- ✅ 工程实战:异步并发 / 分布式调度 / 监控与容错
- ✅ 项目落地:数据治理 / 可视化分析 / 场景化应用
📣 专栏推广时间 :如果你想系统学爬虫,而不是碎片化东拼西凑,欢迎订阅/关注专栏《Python爬虫实战》
订阅后更新会优先推送,按目录学习更高效~
📌 上期回顾
在上一节《专栏导读:你会得到什么?怎么学不掉队?》内容中,我们明确了学习目标、路线图和验收机制。现在,你已经了解了这门课程的整体框架,也建立了学习日志。接下来,我们要做的第一件事就是:搭建一个稳定、规范的开发环境。
一个好的开发环境就像厨师的工作台------工具齐全、摆放有序,才能专注于"做菜"本身,而不是找工具。
🎯 本节目标
通过本节学习,你将完成:
- 安装并验证 Python 环境(3.8+ 版本)
- 创建独立的虚拟环境(避免依赖冲突)
- 配置国内镜像源(pip 安装提速)
- 安装爬虫核心依赖库
- 配置 VSCode/PyCharm 开发环境
- 熟悉浏览器开发者工具和 Postman
- 交付验收:运行一个测试脚本,输出环境信息截图
⚠️ 重要提醒:本节可能会遇到各种安装问题,这是正常的!按照故障排查部分逐步解决,不要放弃。
一、Python 环境安装与验证
1.1 检查现有 Python 版本
打开终端(Windows 用 cmd 或 PowerShell,Mac/Linux 用 Terminal),输入:
json
python --version
# 或者
python3 --version期望输出:
json
Python 3.8.10 # 或 3.9、3.10、3.11、3.12 都可以如果版本低于 3.8 :需要安装新版本
如果提示"命令不存在":需要全新安装
1.2 全新安装 Python(按操作系统)
Windows 用户:
- 访问官网:https://www.python.org/downloads/
- 下载 Python 3.11(推荐稳定版)
- 安装时务必勾选"Add Python to PATH"
- 安装完成后重启终端,验证版本
Mac 用户:
bash
# 推荐使用 Homebrew 安装
brew install python@3.11
# 验证
python3 --versionLinux 用户(Ubuntu/Debian):
bash
sudo apt update
sudo apt install python3.11 python3.11-venv python3-pip
# 验证
python3 --version1.3 常见问题排查
问题1:Windows 提示"找不到 python 命令"
解决方案:
- 找到 Python 安装目录(通常在
C:\Users\你的用户名\AppData\Local\Programs\Python\Python311) - 将该目录和
Scripts子目录添加到系统环境变量 PATH - 重启终端
问题2:Mac 提示权限错误
解决方案:
bash
# 使用 sudo 运行
sudo python3 -m pip install --upgrade pip问题3:有多个 Python 版本共存
解决方案:
- 明确使用
python3而不是python - 或使用完整路径如
/usr/bin/python3.11
二、虚拟环境配置(核心重点)
2.1 为什么需要虚拟环境?
类比:就像你的电脑上装了多个游戏,每个游戏有自己的存档目录,互不干扰。
没有虚拟环境的问题:
- 项目A需要 requests 2.28,项目B需要 requests 2.31
- 全局安装会冲突,导致某个项目无法运行
- 依赖库越装越多,系统环境混乱
使用虚拟环境的好处:
- ✅ 每个项目独立的依赖环境
- ✅ 便于依赖管理和版本控制
- ✅ 不污染系统全局环境
2.2 创建项目目录和虚拟环境
步骤1:创建项目文件夹
bash
# 在你习惯的位置创建(比如桌面或文档)
mkdir spider_course
cd spider_course步骤2:创建虚拟环境
bash
# Windows 和 Linux/Mac 通用
python -m venv venv
# 如果上面不行,Mac/Linux 用户试试:
python3 -m venv venv说明:
venv是 Python 自带的虚拟环境模块- 第二个
venv是虚拟环境的文件夹名(可自定义,但建议统一用 venv)
步骤3:激活虚拟环境
bash
# Windows (cmd)
venv\Scripts\activate
# Windows (PowerShell)
venv\Scripts\Activate.ps1
# Mac/Linux
source venv/bin/activate成功标志 :命令行前面出现 (venv) 标记
bash
(venv) C:\Users\YourName\spider_course>步骤4:验证虚拟环境
bash
# 查看 pip 位置(应该在 venv 目录下)
which pip # Mac/Linux
where pip # Windows
# 期望输出类似:
# /path/to/spider_course/venv/bin/pip2.3 虚拟环境的日常使用
每次开始工作:
bash
cd spider_course
source venv/bin/activate # 或 Windows 的激活命令退出虚拟环境:
bash
deactivate删除虚拟环境(如果要重建):
json
# 先退出虚拟环境,然后
rm -rf venv # Mac/Linux
rmdir /s venv # Windows三、配置 pip 国内镜像源(必做!)
3.1 为什么要配置镜像源?
默认情况 :pip 从国外服务器下载依赖,速度慢、经常超时
配置镜像:从国内服务器下载,速度提升 10 倍以上 🚀
3.2 临时使用镜像源
json
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple3.3 永久配置镜像源(推荐)
Windows 用户:
-
在用户目录创建
pip文件夹:jsonC:\Users\你的用户名\pip\ -
在该文件夹创建
pip.ini文件,内容:ini[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple [install] trusted-host = pypi.tuna.tsinghua.edu.cn
Mac/Linux 用户:
bash
# 创建配置目录
mkdir -p ~/.pip
# 创建配置文件
cat > ~/.pip/pip.conf << EOF
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = pypi.tuna.tsinghua.edu.cn
EOF3.4 常用国内镜像源(任选其一)
| 镜像源 | 地址 |
|---|---|
| 清华大学 | https://pypi.tuna.tsinghua.edu.cn/simple |
| 阿里云 | https://mirrors.aliyun.com/pypi/simple/ |
| 豆瓣 | https://pypi.douban.com/simple/ |
| 中科大 | https://pypi.mirrors.ustc.edu.cn/simple/ |
3.5 验证镜像配置
bash
pip config list
# 期望输出:
# global.index-url='https://pypi.tuna.tsinghua.edu.cn/simple'四、安装爬虫核心依赖库
4.1 升级 pip 本身
bash
pip install --upgrade pip4.2 创建 requirements.txt
在项目根目录创建 requirements.txt 文件:
txt
# HTTP 请求库
requests==2.31.0
# HTML 解析库
beautifulsoup4==4.12.2
lxml==4.9.3
# 动态页面库(后续章节用)
playwright==1.40.0
# 数据处理库
pandas==2.1.4
# 实用工具
python-dateutil==2.8.24.3 批量安装依赖
bash
pip install -r requirements.txt安装过程说明:
- 会显示下载进度和安装信息
- 如果某个库安装失败,记下错误信息(后续排查)
- 整个过程大约 2-5 分钟
4.4 验证安装成功
创建测试脚本 test_env.py:
python
"""
环境验证脚本
运行后截图保存,作为验收凭证
"""
import sys
import requests
import bs4
import pandas as pd
from datetime import datetime
def check_environment():
"""检查开发环境配置"""
print("=" * 50)
print("🔧 Python 爬虫环境检查")
print("=" * 50)
# 1. Python 版本
print(f"\n✅ Python 版本: {sys.version}")
# 2. 核心库版本
print(f"\n📦 已安装的核心库:")
print(f" - requests: {requests.__version__}")
print(f" - beautifulsoup4: {bs4.__version__}")
print(f" - pandas: {pd.__version__}")
# 3. 简单测试
print(f"\n🧪 功能测试:")
# 测试 requests
try:
response = requests.get("https://httpbin.org/get", timeout=5)
print(f" - HTTP 请求: ✅ 成功 (状态码 {response.status_code})")
except Exception as e:
print(f" - HTTP 请求: ❌ 失败 ({e})")
# 测试 BeautifulSoup
try:
html = "<html><body><h1>测试</h1></body></html>"
soup = bs4.BeautifulSoup(html, 'lxml')
print(f" - HTML 解析: ✅ 成功")
except Exception as e:
print(f" - HTML 解析: ❌ 失败 ({e})")
# 4. 环境信息
print(f"\n📍 环境信息:")
print(f" - Python 路径: {sys.executable}")
print(f" - 当前时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("\n" + "=" * 50)
print("✨ 环境检查完成!请截图保存此结果")
print("=" * 50)
if __name__ == "__main__":
check_environment()运行测试:
json
python test_env.py期望输出示例:
json
==================================================
🔧 Python 爬虫环境检查
==================================================
✅ Python 版本: 3.11.5 (main, Sep 11 2023, 13:54:46)
📦 已安装的核心库:
- requests: 2.31.0
- beautifulsoup4: 4.12.2
- pandas: 2.1.4
🧪 功能测试:
- HTTP 请求: ✅ 成功 (状态码 200)
- HTML 解析: ✅ 成功
📍 环境信息:
- Python 路径: /path/to/spider_course/venv/bin/python
- 当前时间: 2025-01-21 10:30:45
==================================================
✨ 环境检查完成!请截图保存此结果
==================================================📸 验收要求:将这个输出截图保存,作为本节作业提交!
实际运行结果展示如下:
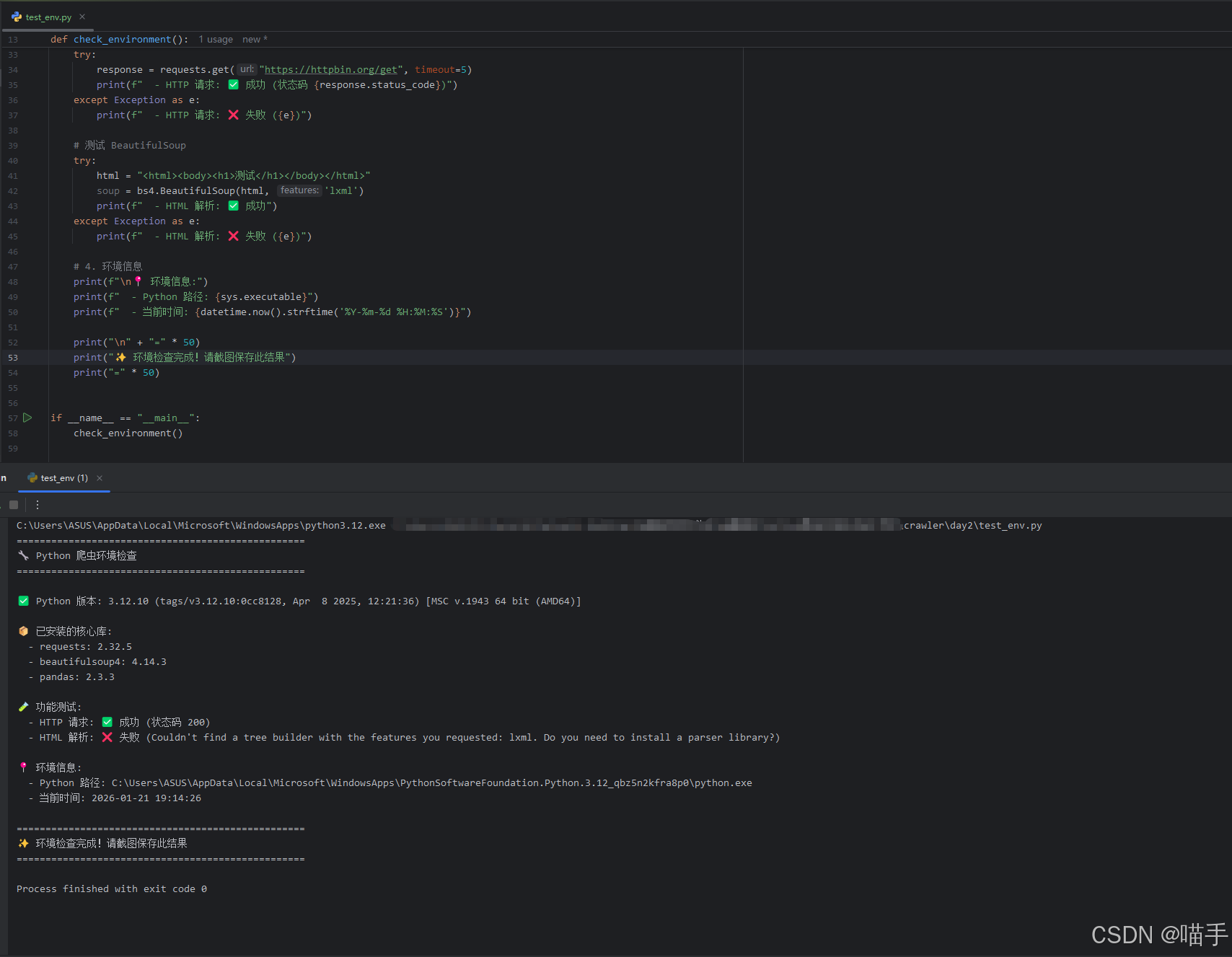
但看如上控制台输出,是出现了一个插曲,解析HTML报错,其实也很好解决。
你只需要本地安装lxml,即可:
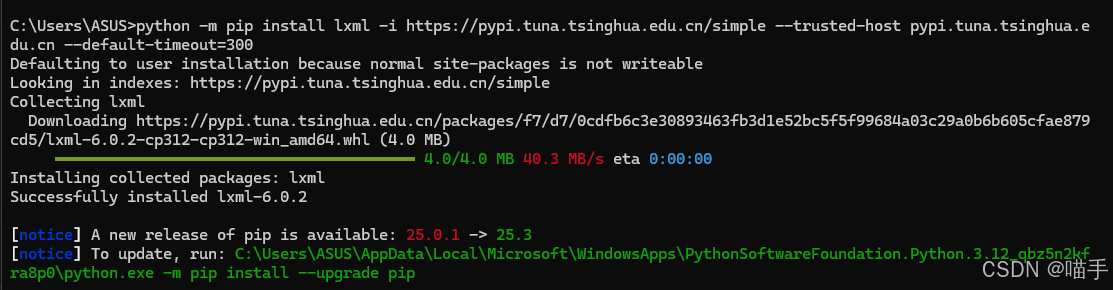
cmd执行命令:pip install lxml 如果报错,请换成:python -m pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn --default-timeout=300,临时使用清华镜像安装。
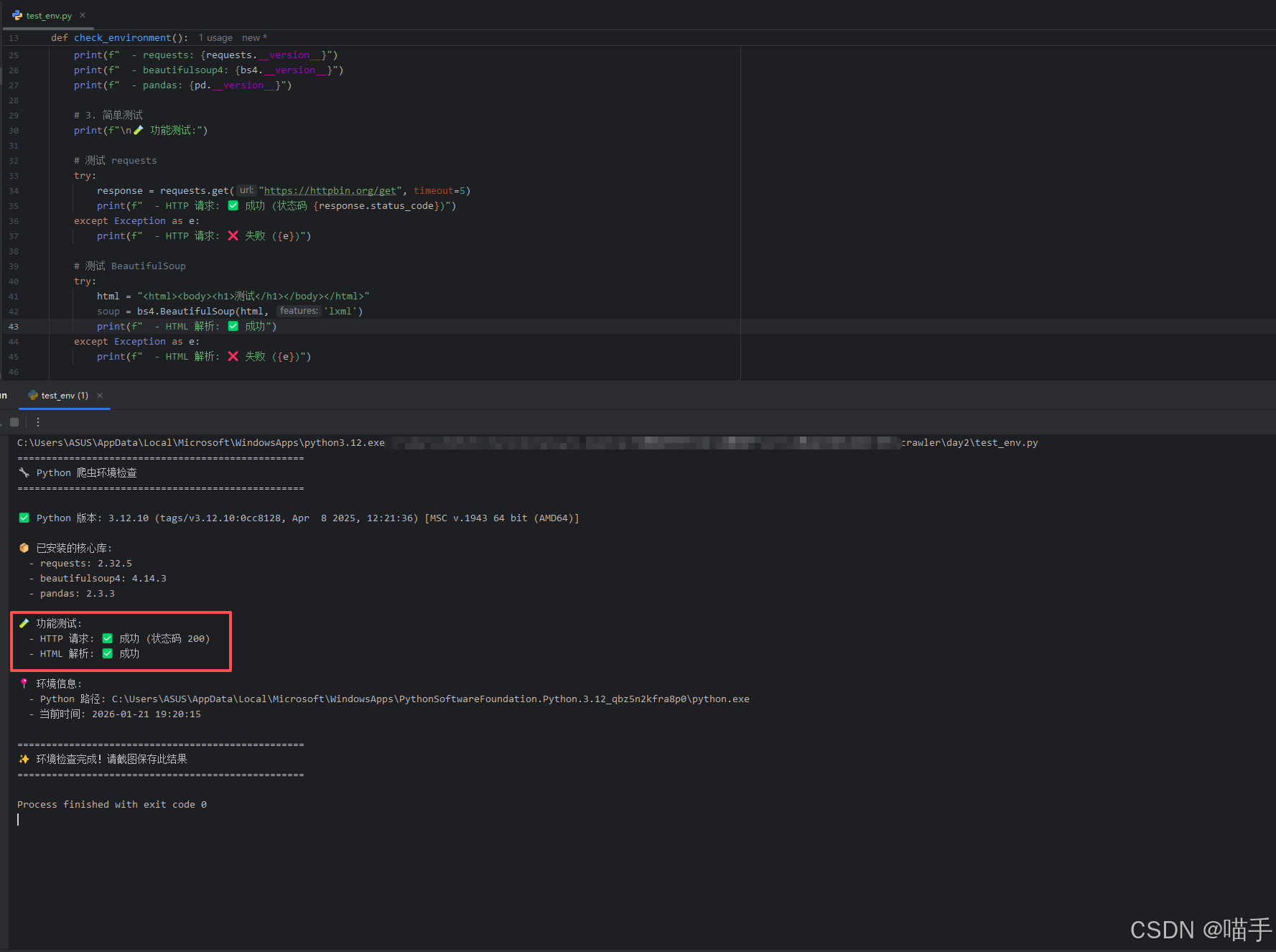
然后我们再重新运行:test_env.py
实际结果运行如下:
五、开发工具配置
5.1 VSCode 配置(推荐新手)
安装 VSCode :https://code.visualstudio.com/
必装插件:
-
Python(Microsoft 官方)
- 提供代码补全、调试、格式化
-
Pylance(自动安装)
- 更强的类型检查和智能提示
配置虚拟环境:
- 在 VSCode 中打开项目文件夹
- 按
Ctrl+Shift+P(Mac:Cmd+Shift+P) - 输入 "Python: Select Interpreter"
- 选择
./venv/bin/python(你的虚拟环境)
验证配置:
- 左下角应显示
Python 3.11.5 ('venv') - 新建
.py文件时有代码提示
5.2 PyCharm 配置(专业用户)
社区版(免费)下载 :https://www.jetbrains.com/pycharm/download/
配置虚拟环境:
- File → Settings → Project → Python Interpreter
- 点击齿轮图标 → Add
- 选择 "Existing environment"
- 浏览到
venv/bin/python(或 Windows 的venv\Scripts\python.exe)
5.3 推荐的编辑器设置
VSCode settings.json 配置:
json
{
"python.linting.enabled": true,
"python.linting.pylintEnabled": false,
"python.formatting.provider": "black",
"editor.formatOnSave": true,
"files.autoSave": "afterDelay",
"files.autoSaveDelay": 2000
}六、抓包工具配置(重要!)
6.1 浏览器开发者工具(必会)
Chrome/Edge 使用方法:
- 打开任意网页
- 按
F12或右键 → 检查 - 切换到 Network 标签页
- 刷新页面(F5)
核心功能区域:
json
┌─────────────────────────────────────┐
│ All XHR JS CSS Img Media Font │ ← 请求类型筛选
├─────────────────────────────────────┤
│ Name Status Type Size │ ← 请求列表
│ example.com 200 document 23KB │
│ api/data 200 xhr 5KB │
├─────────────────────────────────────┤
│ Headers Preview Response Timing │ ← 详情面板
└─────────────────────────────────────┘实战演练:
- 访问 https://news.sina.com.cn/
- 在 Network 面板找到类型为
xhr或fetch的请求 - 点击查看 Headers(请求头)和 Response(响应数据)
- 尝试找到包含新闻列表的 JSON 接口
6.2 Postman 安装(可选但推荐)
用途:独立测试 API 接口,不需要写代码
下载安装 :https://www.postman.com/downloads/
快速上手:
- 新建 Request
- 输入 URL:
https://httpbin.org/get - 点击 Send
- 查看响应结果(JSON 格式)
实战任务 :
用 Postman 请求以下接口,观察返回数据:
json
GET https://httpbin.org/get?page=1&size=10七、常见安装错误排查
7.1 错误:pip install 超时
现象:
json
ERROR: Could not install packages due to an OSError: Read timed out解决方案:
json
# 增加超时时间并使用镜像
pip install requests --timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple7.2 错误:权限不足
现象(Mac/Linux):
json
ERROR: Could not install packages due to an OSError: [Errno 13] Permission denied解决方案:
bash
# 方法1:使用虚拟环境(推荐)
source venv/bin/activate
pip install requests
# 方法2:用户安装(不推荐)
pip install --user requests7.3 错误:缺少编译工具(lxml 安装失败)
现象:
json
error: Microsoft Visual C++ 14.0 is required解决方案(Windows):
-
下载 Visual Studio Build Tools
-
或安装预编译版本:
bashpip install lxml-4.9.3-cp311-cp311-win_amd64.whl
解决方案(Linux):
bash
sudo apt-get install python3-dev libxml2-dev libxslt1-dev
pip install lxml7.4 错误:Playwright 初始化失败
现象:
json
playwright install # 执行后失败解决方案:
bash
# 安装浏览器驱动(后续章节会用)
python -m playwright install chromium
# 如果失败,使用国内镜像
export PLAYWRIGHT_DOWNLOAD_HOST=https://npmmirror.com/mirrors/playwright/
python -m playwright install chromium八、文件结构规范(养成好习惯)
8.1 推荐的初始目录结构
json
spider_course/
├── venv/ # 虚拟环境(不上传Git)
├── .gitignore # Git忽略文件
├── requirements.txt # 依赖清单
├── test_env.py # 环境测试脚本
├── README.md # 项目说明
└── chapter_01/ # 第1章代码
└── lesson_01/8.2 创建 .gitignore 文件
bash
# 创建 .gitignore
cat > .gitignore << EOF
# 虚拟环境
venv/
env/
# Python 缓存
__pycache__/
*.pyc
*.pyo
# IDE 配置
.vscode/
.idea/
# 数据文件
*.csv
*.db
*.sqlite
# 日志文件
*.log
# 系统文件
.DS_Store
Thumbs.db
EOF8.3 初始化 Git 仓库(可选)
bash
git init
git add .gitignore requirements.txt README.md
git commit -m "初始化项目环境"九、本节小结
恭喜完成环境搭建!🎉 让我们回顾一下关键步骤:
✅ Python 环境 :安装 3.8+ 版本并验证
✅ 虚拟环境 :创建独立的 venv,避免依赖冲突
✅ 镜像配置 :使用国内源加速 pip 安装
✅ 核心依赖 :安装 requests、beautifulsoup4 等库
✅ 开发工具 :配置 VSCode/PyCharm
✅ 抓包工具 :熟悉浏览器 Network 面板和 Postman
✅ 环境验证:运行测试脚本并截图
核心原则:
- 永远在虚拟环境中工作
- 依赖库统一管理在 requirements.txt
- 遇息,再查找解决方案
📝 课后作业(必做,验收进入下一章)
任务1:运行环境测试脚本
- 在虚拟环境中运行
test_env.py - 截图保存输出结果(必须全部显示 ✅)
- 如果有 ❌ 失败项,排查并解决
任务2:创建第一个测试脚本
创建 hello_spider.py:
python
import requests
# 测试一个简单的HTTP请求
response = requests.get("https://httpbin.org/get")
print(f"状态码: {response.status_code}")
print(f"响应内容: {response.json()}")运行并截图输出。
任务3:浏览器抓包练习
- 访问 https://news.sina.com.cn/
- 打开 Network 面板
- 找到至少 3 个不同类型的请求(document、xhr、image)
- 截图保存,并标注每个请求的类型和用途
验收方式:在留言区提交:
test_env.py的运行截图hello_spider.py的运行截图- Network 面板的分析截图
- 遇到的问题和解决过程
🔮 下期预告
下一节《网页是怎么工作的:URL、请求、响应、状态码》,我们将深入理解:
- URL 的组成结构和参数规律
- HTTP 请求方法(GET/POST)和请求头
- 响应状态码的含义(200/404/403/429/500)
- Cookie 和 Session 的作用
- 如何用 Network 面板分析完整的请求流程
预习建议 :
观察你常访问的网站(如知乎、微博),思考:
- 列表页的 URL 有什么规律?
- 点击"下一页"时 URL 如何变化?
- 数据是直接在 HTML 里,还是通过接口加载?
💬 环境搭建完成了吗?在留言区分享你的第一个成功时刻! 🚀✨
记住:环境搭建虽然繁琐,但这是后续学习的基石。遇到问题不要慌,按照错误提示逐步排查,你一定能搞定!💪😊
🌟 文末
好啦~以上就是本期 《Python爬虫实战》的全部内容啦!如果你在实践过程中遇到任何疑问,欢迎在评论区留言交流,我看到都会尽量回复~咱们下期见!👋😄
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦~
三连就是对我写作道路上最好的鼓励与支持! ❤️🔥
📌 专栏持续更新中|建议收藏 + 订阅
专栏 👉 《Python爬虫实战》,我会按照"入门 → 进阶 → 工程化 → 项目落地"的路线持续更新,争取让每一篇都做到:
✅ 讲得清楚(原理)|✅ 跑得起来(代码)|✅ 用得上(场景)|✅ 扛得住(工程化)
📣 想系统提升的小伙伴:强烈建议先订阅专栏,再按目录顺序学习,效率会高很多~

✅ 互动征集
想让我把【某站点/某反爬/某验证码/某分布式方案】写成专栏实战?
评论区留言告诉我你的需求,我会优先安排更新 ✅
⭐️ 若喜欢我,就请关注我叭~(更新不迷路)
⭐️ 若对你有用,就请点赞支持一下叭~(给我一点点动力)
⭐️ 若有疑问,就请评论留言告诉我叭~(我会补坑 & 更新迭代)
免责声明:本文仅用于学习与技术研究,请在合法合规、遵守站点规则与 Robots 协议的前提下使用相关技术。严禁将技术用于任何非法用途或侵害他人权益的行为。