Redis 作为高性能缓存中间件,是提升系统性能的核心手段,但多数开发者仅会基础的set/get操作,对缓存更新策略、异常场景(穿透 / 击穿 / 雪崩)处理不足,导致缓存 "失效" 甚至引发系统故障(如缓存雪崩压垮数据库)。
本文从 Redis 缓存核心设计原则出发,讲解缓存更新策略、经典异常场景解决方案、数据一致性保障、避坑要点,结合代码示例与实战场景,帮你设计出 "高性能、高可用、数据一致" 的缓存体系。
一、核心认知:Redis 缓存的价值与核心原则
1. 核心价值
- 降低数据库压力:将高频查询数据缓存到 Redis,减少数据库 IO,提升查询效率(Redis 响应毫秒级,数据库秒级);
- 提升系统吞吐量:Redis 支持高并发读写(单机 QPS 可达 10 万 +),适配高流量场景(如电商秒杀、首页接口);
- 减轻数据库热点:避免单条数据被高频查询(如商品详情)导致数据库热点行锁、CPU 飙升。
2. 核心设计原则
- 缓存更新策略优先:缓存与数据库数据一致性是核心,需选择适配业务的更新策略;
- 异常场景兜底:提前处理缓存穿透、击穿、雪崩,避免缓存失效时压垮数据库;
- 缓存粒度适中:避免缓存全量数据(如整表)或过细数据(如单个字段),平衡内存占用与查询效率;
- 过期时间合理:设置差异化过期时间,避免大量缓存同时失效;
- 降级熔断兜底:Redis 故障时,降级为数据库查询或返回默认数据,保障系统可用。
3. 缓存核心架构(经典 Cache-Aside 模式)
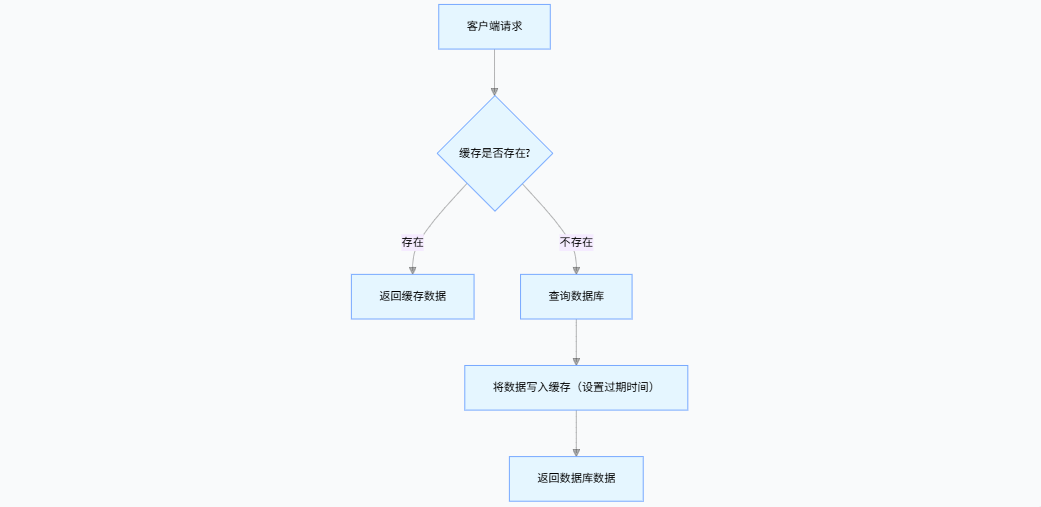
这是最常用的缓存模式,核心是 "先查缓存,缓存未命中查库,查库后回写缓存",需重点处理缓存更新与异常场景。
二、实战:缓存核心问题解决方案
1. 缓存更新策略(保障数据一致性)
缓存与数据库的一致性是缓存设计的核心,需根据业务场景选择更新策略,以下是主流策略对比与实现:
| 策略 | 实现逻辑 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| Cache-Aside(旁路缓存) | 读:先查缓存→缓存空查库→回写缓存;写:先更数据库→再删缓存 | 绝大多数业务场景(如商品详情、用户信息) | 实现简单,一致性可控 | 存在短暂数据不一致(写库后删缓存前,有请求读旧缓存) |
| Write-Through(写穿) | 写:先更缓存→缓存同步更数据库;读:同 Cache-Aside | 数据一致性要求极高的场景(如金融交易) | 一致性强,无脏数据 | 写性能低(两次写操作),Redis 故障导致写阻塞 |
| Write-Back(写回) | 写:先更缓存→缓存标记为脏→异步刷库;读:同 Cache-Aside | 写频繁、一致性要求低的场景(如日志、临时数据) | 写性能极高 | 数据丢失风险(Redis 宕机未刷库),一致性差 |
(1)Cache-Aside 实现(推荐,适配 90% 场景)
java
运行
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class ProductService {
@Resource
private ProductMapper productMapper;
@Resource
private RedisTemplate<String, Object> redisTemplate;
// 缓存Key前缀(规范命名:业务:表:字段:值)
private static final String CACHE_KEY_PRODUCT = "product:info:";
// 缓存过期时间:30分钟(秒)
private static final long CACHE_EXPIRE_SECONDS = 30 * 60;
// 读操作:先查缓存,再查库,回写缓存
public ProductDTO getProductById(Long productId) {
// 1. 构建缓存Key
String cacheKey = CACHE_KEY_PRODUCT + productId;
// 2. 查询缓存
ProductDTO cacheProduct = (ProductDTO) redisTemplate.opsForValue().get(cacheKey);
if (cacheProduct != null) {
return cacheProduct; // 缓存命中,直接返回
}
// 3. 缓存未命中,查询数据库
ProductDO productDO = productMapper.selectById(productId);
if (productDO == null) {
// 处理缓存穿透:空值缓存(避免每次都查库)
redisTemplate.opsForValue().set(cacheKey, null, 5 * 60); // 空值缓存5分钟
return null;
}
ProductDTO productDTO = convertToDTO(productDO);
// 4. 回写缓存(设置过期时间)
redisTemplate.opsForValue().set(cacheKey, productDTO, CACHE_EXPIRE_SECONDS);
return productDTO;
}
// 写操作:先更数据库,再删缓存(而非更新缓存)
public void updateProduct(ProductDTO productDTO) {
// 1. 更新数据库
productMapper.updateById(convertToDO(productDTO));
// 2. 删除缓存(避免更新缓存时的并发问题)
String cacheKey = CACHE_KEY_PRODUCT + productDTO.getId();
redisTemplate.delete(cacheKey);
}
}⚠️ 关键:写操作优先删缓存而非 "更缓存",避免并发场景下的缓存脏数据(如两个线程同时更新,缓存值覆盖错误)。
2. 经典异常场景解决方案
(1)缓存穿透(查询不存在的数据,缓存不命中,持续压库)
- 现象:恶意请求不存在的 Key(如
productId=-1),缓存始终未命中,所有请求直达数据库,导致数据库压力飙升; - 核心原因:缓存中无对应空值,每次都查库;
- 解决方案:
- 空值缓存 :查询到数据库无数据时,将空值写入缓存(设置短过期时间,如 5 分钟),示例见上文
getProductById方法; - 布隆过滤器:提前将所有有效 Key 存入布隆过滤器,请求先经过过滤器校验,无效 Key 直接拒绝(适用于数据量极大场景)。
布隆过滤器实现(Redis 版)
java
运行
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
@Component
public class ProductBloomFilter {
@Resource
private RedissonClient redissonClient;
@Resource
private ProductMapper productMapper;
private RBloomFilter<Long> productIdBloomFilter;
// 布隆过滤器名称
private static final String BLOOM_FILTER_NAME = "product:id:bloom";
// 预计数据量
private static final long EXPECTED_SIZE = 1000000;
// 误判率(越小越精准,占用内存越大)
private static final double FALSE_POSITIVE_RATE = 0.01;
// 初始化布隆过滤器(项目启动时加载所有有效productId)
@PostConstruct
public void initBloomFilter() {
productIdBloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_NAME);
// 初始化过滤器参数(仅第一次初始化时生效)
productIdBloomFilter.tryInit(EXPECTED_SIZE, FALSE_POSITIVE_RATE);
// 批量加载有效productId到过滤器(实际可分批加载)
List<Long> allProductIds = productMapper.selectAllProductIds();
for (Long productId : allProductIds) {
productIdBloomFilter.add(productId);
}
}
// 校验productId是否有效
public boolean isValidProductId(Long productId) {
return productIdBloomFilter.contains(productId);
}
}
// 在Controller层校验
@RestController
@RequestMapping("/products")
public class ProductController {
@Resource
private ProductService productService;
@Resource
private ProductBloomFilter productBloomFilter;
@GetMapping("/{productId}")
public Result<ProductDTO> getProduct(@PathVariable Long productId) {
// 布隆过滤器校验,无效ID直接返回
if (!productBloomFilter.isValidProductId(productId)) {
return Result.fail(40400, "商品不存在", null);
}
ProductDTO product = productService.getProductById(productId);
if (product == null) {
return Result.fail(40400, "商品不存在", null);
}
return Result.success(product);
}
}(2)缓存击穿(热点 Key 过期,大量请求直达数据库)
- 现象:某个高频访问的热点 Key(如秒杀商品)过期瞬间,大量请求同时命中,缓存未命中后直达数据库,导致数据库瞬间压力飙升;
- 核心原因:热点 Key 集中过期,并发请求击穿缓存;
- 解决方案:
- 互斥锁:缓存未命中时,加锁仅允许一个线程查库并回写缓存,其他线程等待后查缓存;
- 热点 Key 永不过期:对热点 Key 不设置过期时间,通过后台异步更新缓存(适用于更新频率低的场景)。
互斥锁实现(Redis 分布式锁)
java
运行
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
@Service
public class ProductService {
// 省略其他依赖...
@Resource
private RedissonClient redissonClient;
// 锁前缀
private static final String LOCK_KEY_PRODUCT = "lock:product:";
public ProductDTO getProductById(Long productId) {
String cacheKey = CACHE_KEY_PRODUCT + productId;
// 1. 查询缓存
ProductDTO cacheProduct = (ProductDTO) redisTemplate.opsForValue().get(cacheKey);
if (cacheProduct != null) {
return cacheProduct;
}
// 2. 缓存未命中,加分布式锁
String lockKey = LOCK_KEY_PRODUCT + productId;
RLock lock = redissonClient.getLock(lockKey);
try {
// 尝试获取锁(最多等3秒,锁持有时长5秒)
if (lock.tryLock(3, 5, TimeUnit.SECONDS)) {
// 3. 拿到锁后,再次查缓存(避免其他线程已回写)
cacheProduct = (ProductDTO) redisTemplate.opsForValue().get(cacheKey);
if (cacheProduct != null) {
return cacheProduct;
}
// 4. 查库并回写缓存
ProductDO productDO = productMapper.selectById(productId);
if (productDO == null) {
redisTemplate.opsForValue().set(cacheKey, null, 5 * 60);
return null;
}
ProductDTO productDTO = convertToDTO(productDO);
redisTemplate.opsForValue().set(cacheKey, productDTO, CACHE_EXPIRE_SECONDS);
return productDTO;
} else {
// 5. 未拿到锁,等待50ms后重试(或直接返回旧数据)
TimeUnit.MILLISECONDS.sleep(50);
return getProductById(productId); // 递归重试
}
} catch (InterruptedException e) {
log.error("获取分布式锁异常", e);
return null;
} finally {
// 释放锁(仅持有锁的线程释放)
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}(3)缓存雪崩(大量缓存同时过期,数据库被压垮)
- 现象:某一时间段内大量缓存 Key 同时过期,所有请求直达数据库,导致数据库连接耗尽、CPU 飙升,甚至宕机;
- 核心原因:缓存过期时间设置为固定值(如全部 30 分钟),导致集中过期;
- 解决方案:
- 过期时间加随机值:为每个 Key 的过期时间增加随机偏移量(如 30±5 分钟),避免集中过期;
- 缓存集群高可用:部署 Redis 集群(主从 + 哨兵 / 集群模式),避免 Redis 单点故障导致缓存全失效;
- 服务降级 / 熔断:Redis 故障时,通过 Sentinel/Resilience4j 熔断,返回默认数据或提示 "服务繁忙"。
过期时间加随机值实现
java
运行
// 原固定过期时间:30分钟
// 优化后:30±5分钟,随机偏移量避免集中过期
private static final long BASE_EXPIRE_SECONDS = 30 * 60;
private static final long RANDOM_EXPIRE_RANGE = 5 * 60;
// 回写缓存时设置随机过期时间
long expireTime = BASE_EXPIRE_SECONDS + new Random().nextLong(RANDOM_EXPIRE_RANGE);
redisTemplate.opsForValue().set(cacheKey, productDTO, expireTime);3. 缓存数据一致性保障(进阶)
对于数据一致性要求高的场景(如金融、订单),需在 Cache-Aside 基础上增加 "双删缓存" 或 "延迟删缓存":
java
运行
// 双删缓存:更新数据库后,先删一次缓存,延迟1秒再删一次(解决并发更新问题)
public void updateProduct(ProductDTO productDTO) {
// 1. 更新数据库
productMapper.updateById(convertToDO(productDTO));
String cacheKey = CACHE_KEY_PRODUCT + productDTO.getId();
// 2. 第一次删缓存
redisTemplate.delete(cacheKey);
// 3. 延迟1秒再次删缓存(避免更新前的请求读取旧数据并回写缓存)
CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(1);
redisTemplate.delete(cacheKey);
} catch (InterruptedException e) {
log.error("延迟删缓存异常", e);
}
});
}三、避坑指南
1. 坑点 1:缓存与数据库数据不一致
- 表现:缓存中数据与数据库不一致,返回脏数据;
- 原因:1. 写操作先更缓存后更数据库,并发场景下覆盖;2. 删缓存失败未处理;
- 解决方案:1. 严格遵循 "先更库,后删缓存";2. 删缓存失败增加重试机制(如 MQ 异步重试);3. 核心数据增加缓存更新校验。
2. 坑点 2:缓存 Key 命名混乱
- 表现:Key 命名无规范(如
product123、user_456),难以维护、易冲突; - 解决方案:统一 Key 命名规范:
业务模块:表名:字段名:值(如product:info:123、user:token:456),用冒号分隔,清晰易懂。
3. 坑点 3:缓存大对象导致内存溢出
- 表现:缓存整表数据、大 JSON 对象(如 10MB 以上),导致 Redis 内存占用过高,触发 OOM;
- 解决方案:1. 缓存粒度拆分(如仅缓存商品核心字段,而非所有字段);2. 设置 Redis 内存上限(
maxmemory),配置淘汰策略(如volatile-lru);3. 定期清理无用缓存。
4. 坑点 4:忽略 Redis 序列化问题
- 表现:缓存数据序列化 / 反序列化失败(如默认 JDK 序列化导致乱码、性能低);
- 解决方案:使用 JSON 序列化(Jackson/Gson),配置 RedisTemplate:
java
运行
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
// JSON序列化配置
Jackson2JsonRedisSerializer<Object> jacksonSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL);
jacksonSerializer.setObjectMapper(objectMapper);
// 设置Key/Value序列化方式
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(jacksonSerializer);
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(jacksonSerializer);
template.afterPropertiesSet();
return template;
}
}5. 坑点 5:Redis 故障导致系统不可用
- 表现:Redis 宕机后,所有请求直达数据库,导致数据库崩溃,系统整体不可用;
- 解决方案:1. 部署 Redis 集群(主从 + 哨兵),保证高可用;2. 增加缓存降级逻辑,Redis 故障时返回默认数据或提示;3. 数据库增加连接池限制,避免连接耗尽。
四、终极总结:Redis 缓存设计的核心是 "平衡与兜底"
优秀的 Redis 缓存设计,本质是在 "性能" 与 "数据一致性" 之间找平衡,同时为异常场景做好兜底。核心逻辑是:
- 选择适配业务的缓存更新策略(优先 Cache-Aside);
- 提前处理穿透 / 击穿 / 雪崩三大异常场景;
- 控制缓存粒度与过期时间,避免内存溢出、集中过期;
- 做好 Redis 高可用与降级兜底,避免单点故障。
记住:缓存是 "加速器" 而非 "银弹",需结合业务场景合理使用,同时做好监控(如 Redis 内存、命中率、过期 Key 数量),持续优化。