目录
文章目录
- 目录
- [NLP 的序列数据与序列模型](#NLP 的序列数据与序列模型)
- RNN(循环神经网络)
- LSTM(长短期记忆网络)
- GRU(门控循环单元)
-
- 模型结构和数据表达
- [LSTM v.s. GRU](#LSTM v.s. GRU)
- [RNN Encoder--Decoder](#RNN Encoder–Decoder)
- [2014 年,RNN-seq2seq](#2014 年,RNN-seq2seq)
NLP 的序列数据与序列模型
序列数据
序列是数据点或事件的有序列表。与独立的图像或表格数据不同,序列数据中的元素具有内在的顺序和时间依赖性。 典型的例子包括:自然语言文本、语音、视频、股票价格、天气读数或传感器数据等。在 NLP 领域,文本翻译、语音识别等场景都离不开对序列数据的处理。
序列模型
传统的 FFN(Feedforward Neural Networks,前馈神经网络)或 CNN(卷积神经网络)在处理这类数据时会遇到根本性的困难,因为它们假设所有输入都是相互独立的,所以无法捕捉到数据点之间的时序关系。比如在处理一个句子时,FNN 会孤立地看待每个单词,从而丢失了至关重要的上下文信息。为了解决这个问题,我们需要一种能够 "记忆过去" 信息的模型,而这正是 RNN 的设计初衷。
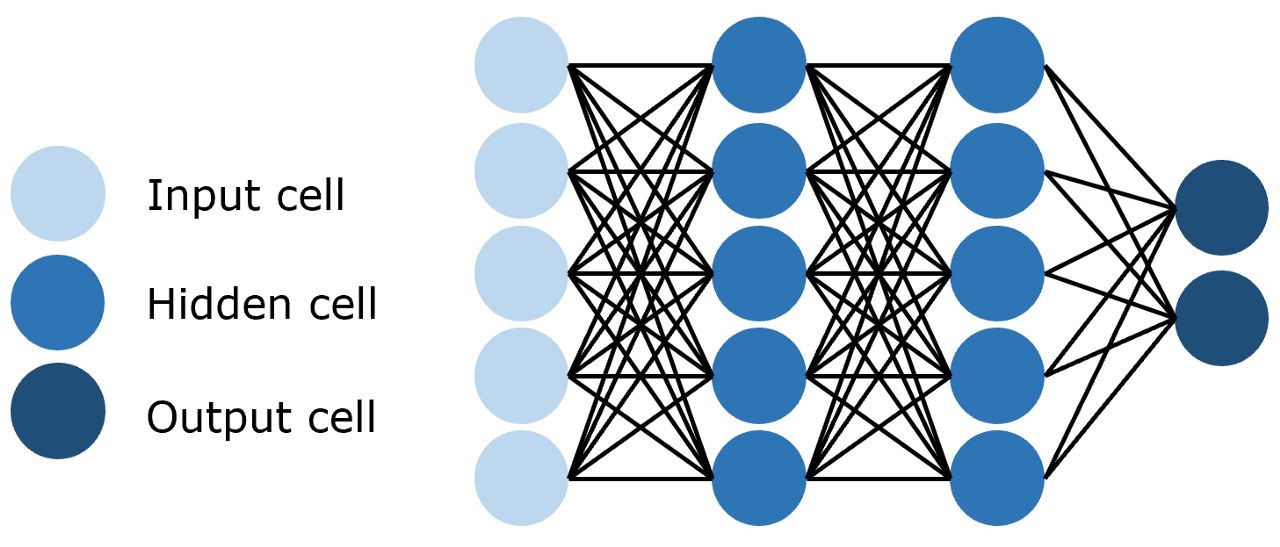
FNN(前馈神经网络)是一种全连接神经网络,每一层的神经元都和上下两层的每一个神经元完全连接。并且信息只能沿着输入到输出的方向单向传播,不存在循环或反馈连接。也就是说,数据从输入层进入,经过中间的隐藏层逐层处理后,最终由输出层输出结果,层与层之间的连接是 "前馈" 的,没有反向的信息流动。
而 Sequence Model(序列模型)就是一种用于处理序列数据的 AI 模型,具有 "历史记忆",能够用于解决输入数据为序列形式的各种问题。在 NLP 领域的应用场景包括:
- 文本处理:单词的顺序决定了句子的含义。如:机器翻译、情感分析、聊天机器人。
- 语音识别:音频转文本。
- 音乐生成:声波是随时间变化的连续信号。
- 视频生成:视频由一系列有序的图像帧组成。
- 时间序列分析:分析按时间顺序排列的数据点序列,如:股票价格、传感器读数、天气预报等,其当前值与历史值密切相关。
值得注意的是,Sequence Model 的 "历史记忆" 和 Hopfield Network 的 "联系记忆" 有本质的区别,"联想记忆" 并不适用于处理序列数据,而 "历史记忆" 的目标是发现序列数据中的模式和依赖关系,从而进行预测、分类,甚至生成新的序列。当下经典的序列模型结构包括:RNN、LSTM、GRU、Transformer 和 GPT。
由于 NLP 任务所需要处理的文本往往是序列,因此专用于处理序列、时序数据的 RNN 往往能够在 NLP 任务上取得最优的效果。事实上,在 Transformer 横空出世之前,RNN 以及 RNN 的衍生架构 LSTM、GRU 是 NLP 领域当之无愧的霸主。
时至今日,虽然像 Transformer 这样的基于 Attention(注意力机制)的新架构在许多 NLP 任务中(尤其是在处理超长序列时)表现出了更强的性能和更好的并行性,但 RNN、LSTM 和 GRU 仍然是序列建模领域不可或缺的基础工具。 它们在计算效率、对实时流数据的处理以及在某些特定任务上的表现依然具有优势。
RNN(循环神经网络)
1990 年,Jeffrey Elman 发表论文《Finding structure in time(在时间中寻找结构)》提出了 SRN(Simple Recurrent Network,简单循环网络),这是世界上第一个 RNN(Recurrent Neural Networks,循环神经网络)序列模型。它开启了对序列数据和序列模型的研究,开创了模型能够 "记忆历史信息" 的先河。
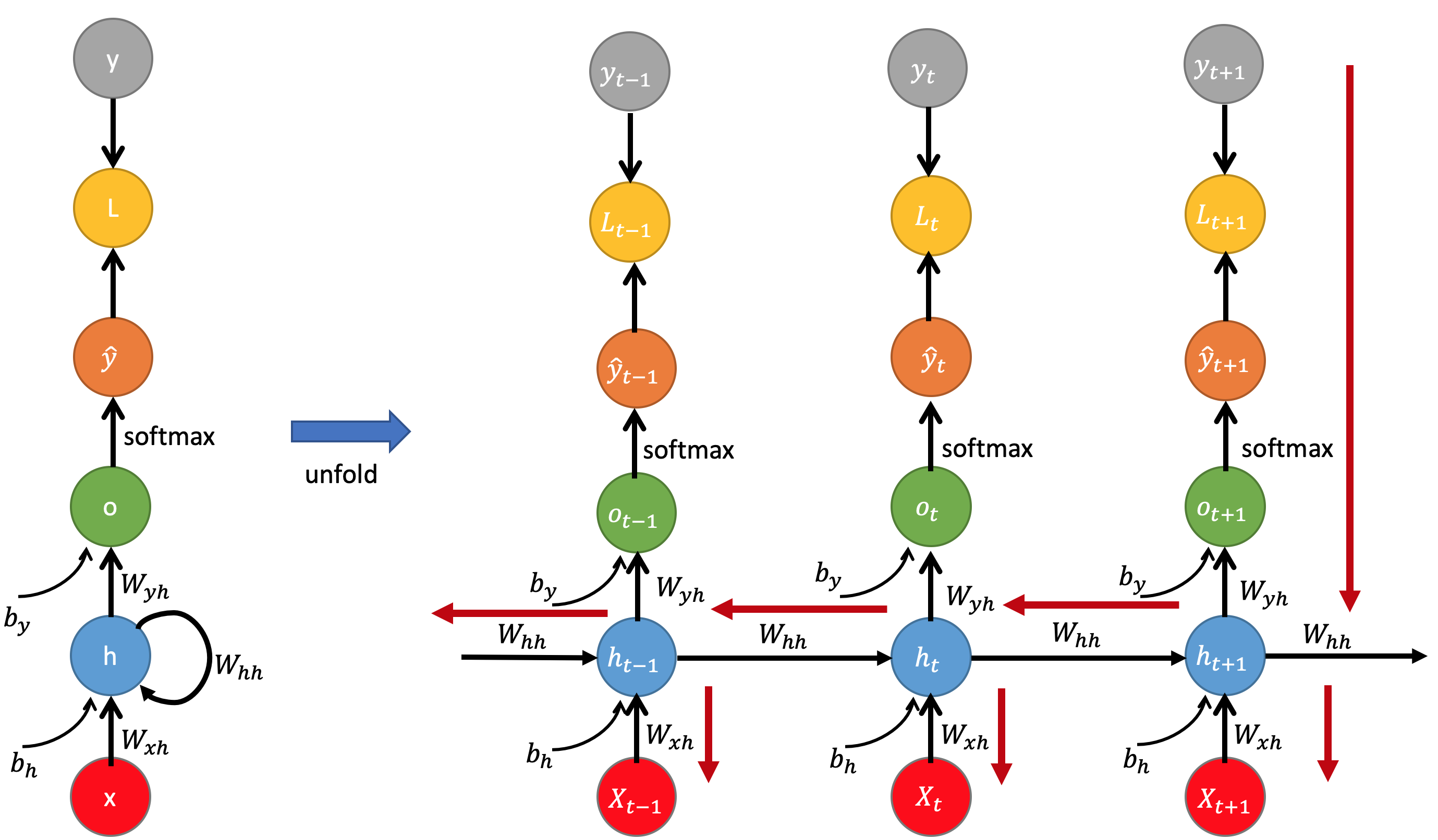
如下图,RNN 和 FFN 的主要区别之一,就是 RNN 神经元中引入了一个循环结构。
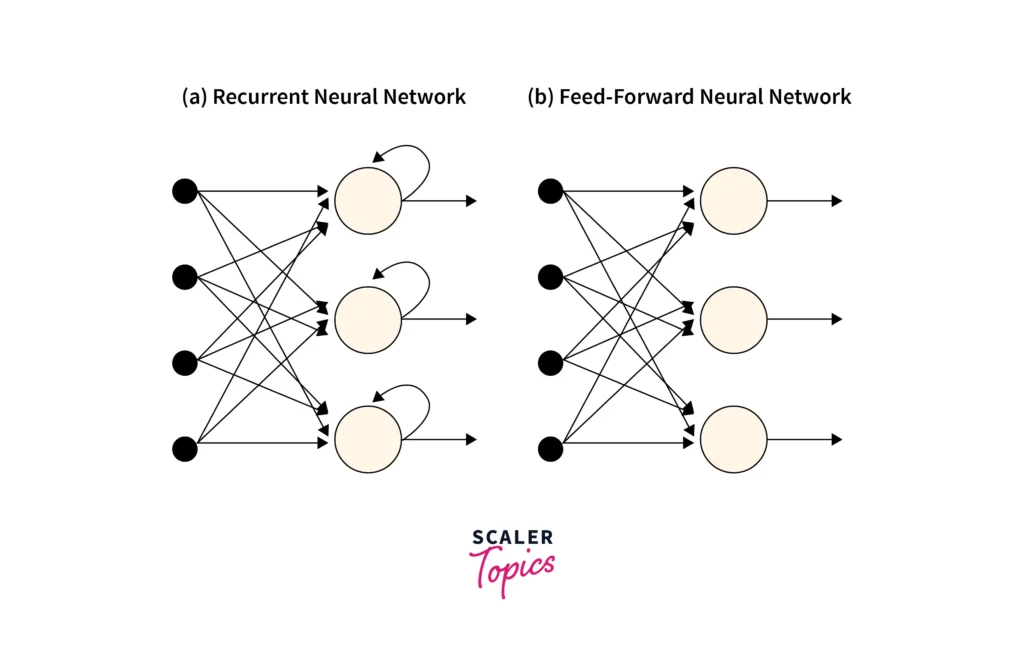
RNN 神经元结构
RNN 的核心是让模型 "记住过去"。为了实现这一能力,RNN 模型结构具有以下 3 个关键特性:
- 信息持久化(Information Persistence):RNN 能够在隐藏层(Hidden Layer)节点中存储 "历史记忆",称之为隐藏状态。通过这个状态 RNN 可以在序列处理的过程中传递 "历史记忆",这是 RNN 能够学习到序列元素之间的长距离依赖关系的前提。
- 反馈循环(Feedback Loop):通过在隐藏层的每个节点上添加一个反馈循环连接,使得它在处理序列中的每个元素(如一个词、一个时间点的数据)时,它不仅要考虑当前的输入,还要考虑它从之前所有步骤中计算并保留下来的 "历史记忆"。所以这个状态会随着网络处理输入序列中的每个元素而更新,就像是不断被刷新的 "记忆",但该 "记忆容量" 有限且无法长期保存。
- 捕捉依赖关系(Captures Dependencies):RNN 的目的是捕捉序列数据中随时间分布的依赖关系和模式。但受限于梯度消失,仅能有效学习短距离依赖,无法处理长序列(如超过 10 个时间步)的长期关联。
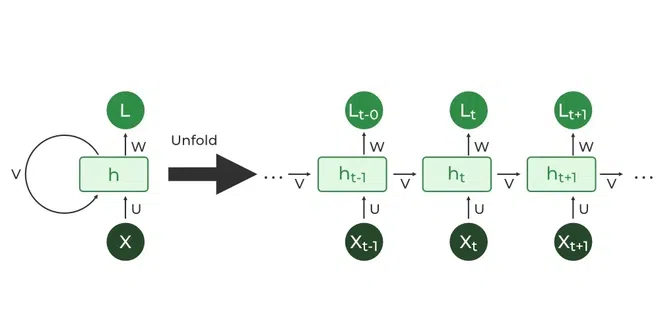
在 RNN 模型中,时间步是处理序列元素的基本单位,一个时间步处理的就是一个序列元素。所以一个序列由多个时间步(元素)组成,每个 RNN 神经元都会在一个序列的多个时间步之间传递 "历史记忆"。
如下图所示,将一个 RNN 神经元展开(Unfold)后,就成为了一个链式的结构,每一个环节表示一个时间步处理一个序列元素。每个时间步(t)不仅会接收当前的输入 x_t(元素),还会接收来自上一个时间步(t-1)的隐藏状态 h_t-1,然后计算出当前时间步的隐藏状态 h_t 和输出 y_t。
其中,隐藏状态(Hidden State)就是 "历史记忆",是 RNN 神经元到目前为止所被处理过的一个序列中的元素数据的 "历史记忆"。可见,RNN 神经元的 "当前记忆" 是由 "当前输入" 和 "历史记忆" 来共同决定的。
数学表达
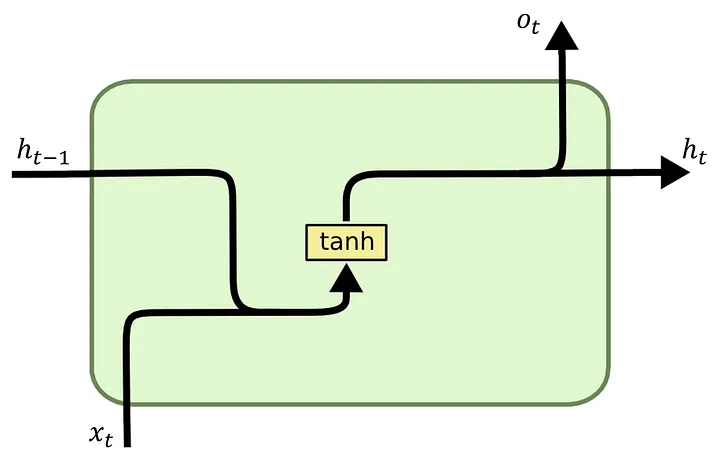
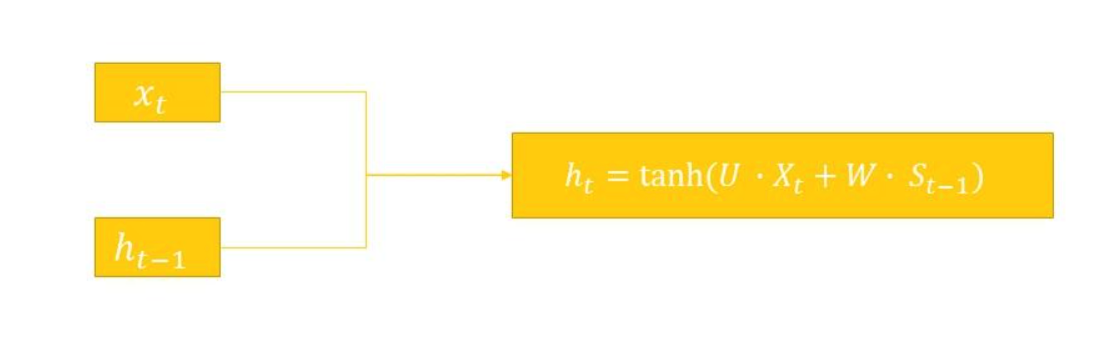
简单 RNN 的核心计算可以用以下两个公式来描述:
- 隐藏状态的计算:
bash
h_t = f(W_hh * h_t-1 + W_xh * x_t + b_h)- 输出的计算:
bash
y_t = W_hy * h_t + b_y其中:
- x_t:在时间步 t 的输入向量,如文本中的词向量。
- h_t, h_t-1:在时间步 h_t 或 t-1 的隐藏状态,即:历史信息,是核心的记忆载体。
- y_t:在时间步 t 的输出。
- W_xh, W_hh, W_hy :分别是输入层到隐藏层、隐藏层到自循环隐藏层、隐藏层到输出层的权重矩阵。作为共享参数,在所有时间步中是共享的。
- W_xh 形状:隐藏层维度 × 输入维度
- W_hh 形状:隐藏层维度 × 隐藏层维度(关键)
- W_hy 形状:输出维度 × 隐藏层维度
- b_h, b_y :分别是隐藏层和输出层的偏置量。
- b_h 形状:隐藏层维度 × 1
- b_y 形状:输出维度 × 1
- f :激活函数
- 隐藏层用 tanh,值缩至 -1,1。
- 输出层用 Softmax(分类)或线性激活(回归)
训练算法
RNN 的训练通过 BPTT(Backpropagation Through Time,时间反向传播)来完成,本质上是标准 BP 反向传播算法在 Unfold 展开后的 RNN 上的具体应用。Loss 损失函数在每个时间步 t 计算,然后将梯度从最后一个时间步开始,沿着时间序列反向传播,并用这些梯度来更新共享的 W_xh, W_hh, W_hy 权重矩阵。
使用 PyTorch 实现一个单层的 RNN
这是一个进行文本情绪分析的 RNN 模型例子,只有 1 层隐藏层。
python
import torch
import torch.nn as nn
import torch.optim as optim
# ---------------------- 1. 定义最简RNN(适配序列级分类) ----------------------
class SimpleRNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(SimpleRNN, self).__init__()
# 权重矩阵
# W_xh, W_hh, W_hy:分别是输入层到隐藏层、隐藏层到自循环隐藏层、隐藏层到输出层的权重矩阵。作为共享参数,在所有时间步中是共享的。
# - W_xh 形状:隐藏层维度 × 输入维度
# - W_hh 形状:隐藏层维度 × 隐藏层维度(关键)
# - W_hy 形状:输出维度 × 隐藏层维度
self.W_xh = nn.Parameter(torch.randn(hidden_dim, input_dim)) # 隐藏层×输入层
self.W_hh = nn.Parameter(torch.randn(hidden_dim, hidden_dim)) # 隐藏层×隐藏层
self.W_hy = nn.Parameter(torch.randn(output_dim, hidden_dim)) # 输出层×隐藏层
# 偏置项
self.b_h = nn.Parameter(torch.randn(hidden_dim, 1))
self.b_y = nn.Parameter(torch.randn(output_dim, 1))
# 维度记录
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.output_dim = output_dim
def forward(self, x_seq):
"""
前向传播(序列级分类:仅用最后一个时间步的隐藏状态输出)
时间步:在序列模型中,时间步是处理序列数据的基本单位。它代表了模型按顺序处理输入数据的一个 "步骤" 或 "瞬间"。
x_seq: 输入序列,形状 [时间步数量, 输入维度]
返回:最终输出(序列级分类结果)、最后一个隐藏状态
"""
# 对于每个序列而言,初始的隐藏状态 h0 设置为 )
h_prev = torch.zeros(self.hidden_dim, 1)
# e.g.
# text = '电影 好看',这个序列只有 2 个元素,对应 2 个时间步
# 向序列进行词汇表的词向量化之后,x_seq 为:
# tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
# [0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
# 逐时间步更新隐藏状态,每次迭代对应一个时间步
for t in range(x_seq.shape[0]):
# e.g.
# t = 电影,[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]
x_t = x_seq[t].unsqueeze(1) # 转为 [输入维度, 1] 适配矩阵乘法
# 计算隐藏状态公式: h_t = tanh(W_hh * h_t-1 + W_xh * x_t + b_h)
h_t = torch.tanh(self.W_hh @ h_prev + self.W_xh @ x_t + self.b_h)
# 传递隐藏状态到下一个时间步
h_prev = h_t
# 计算序列输出,仅使用了最后一个隐藏状态来计算最终输出的分类结果
# 计算输出公式: y_t = W_hy * h_t + b_y
y_final = self.W_hy @ h_prev + self.b_y
y_final = torch.log_softmax(y_final, dim=0) # 归一化函数, 二分类对数概率
return y_final, h_prev
# ---------------------- 2. 数据准备(极短文本情感分类数据集) ----------------------
# 步骤1:词汇表,用于文本的词向量化表示
vocab = {
"电影": 0, "好看": 1, "饭菜": 2, "难吃": 3,
"天气": 4, "糟糕": 5, "音乐": 6, "好听": 7,
"剧情": 8, "一般": 9, "但": 10, "演技": 11, "好": 12,
"难看": 13, "好吃": 14, "心情": 15, "分量": 16, "少": 17
}
vocab_size = len(vocab) # 输入维度=词表大小(One-Hot编码)
# 步骤2:训练数据,使用空格作为词元的分隔符,并且进行了数据的手动标注。
train_data = [
("电影 好看", 1), # 正面
("饭菜 难吃", 0), # 负面
("天气 糟糕", 0), # 负面
("音乐 好听", 1), # 正面
("电影 难看", 0), # 负面
("饭菜 好吃", 1) # 正面
]
# 步骤3:数据编码函数,VSM 文本向量化表示法(文本→One-Hot序列)
def text2onehot(text):
words = text.split() # 按空格拆分词
onehot_seq = []
for word in words:
# 生成One-Hot向量(输入维度=vocab_size)
onehot = torch.zeros(vocab_size)
if word in vocab:
onehot[vocab[word]] = 1.0
onehot_seq.append(onehot)
return torch.stack(onehot_seq)
# ---------------------- 3. 模型初始化与训练配置 ----------------------
# 初始化模型结构、损失函数、优化器
input_dim = vocab_size # 输入维度=词表大小(One-Hot)
hidden_dim = 4 # 只有一层隐藏层,维度为 4
output_dim = 2 # 输出维度=2(二分类:正面/负面)
model = SimpleRNN(input_dim, hidden_dim, output_dim)
# 初始化损失函数和优化器
criterion = nn.NLLLoss() # 使用负对数似然损失计算方法,对应log_softmax的损失函数
optimizer = optim.SGD(model.parameters(), lr=0.1) # 随机梯度下降
# ---------------------- 4. 训练过程 ----------------------
epochs = 1000 # 训练轮次(极简数据需多轮训练)
for epoch in range(epochs):
total_loss = 0.0
for text, label in train_data:
# 1. 数据编码
x_seq = text2onehot(text) # [时间步数量, input_dim]
y_true = torch.tensor([label]) # 真实标签:形状 [1]
# 2. 前向传播
y_pred, _ = model(x_seq) # y_pred 形状:[2, 1]
# 3. 正确修正维度:将 y_pred 从 [2, 1] 转为 [1, 2]
# 关键修改:先squeeze去掉最后一维→[2],再reshape为[1,2](batch_size=1,类别数=2)
y_pred_reshaped = y_pred.squeeze(1).reshape(1, 2)
# 4. 计算损失(现在维度完全匹配:input[1,2],target[1])
# 预测值和标准的真实值对比求 loss 值
loss = criterion(y_pred_reshaped, y_true)
# 5. 反向传播+参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
# 每100轮打印损失
if (epoch + 1) % 100 == 0:
print(f"Epoch {epoch+1}, Loss: {total_loss/len(train_data):.4f}")
# ---------------------- 5. 测试:可用示例 vs 局限示例 ----------------------
def predict(text):
"""
预测函数:输入文本→输出情感分类结果
"""
model.eval() # 评估模式
with torch.no_grad():
x_seq = text2onehot(text)
y_pred, _ = model(x_seq)
# 同步修正维度
y_pred_reshaped = y_pred.squeeze(1).reshape(1, 2)
pred_label = torch.argmax(y_pred_reshaped).item() # 0=负面,1=正面
emotion = "正面" if pred_label == 1 else "负面"
return f"文本:{text} → 预测情感:{emotion}(标签:{pred_label})"
# 5.1 可用示例(2~3个词的极短文本,能正确分类)
print("\n===== 可用示例(极短简单文本) =====")
print(predict("电影 好看")) # 预期:正面
print(predict("饭菜 难吃")) # 预期:负面
print(predict("音乐 好听")) # 预期:正面
# 5.2 局限示例(>5个词/含矛盾语义,分类失败)
print("\n===== 局限示例(长/复杂文本) =====")
print(predict("电影 剧情 一般 但 演技 好")) # 真实情感:偏正面,纯RNN会分类错误
print(predict("天气 糟糕 但 心情 好")) # 真实情感:中性/偏正面,纯RNN会分类错误
print(predict("饭菜 好吃 但 分量 少")) # 真实情感:中性/偏负面,纯RNN会分类错误执行输出:
bash
Epoch 100, Loss: 0.0131
Epoch 200, Loss: 0.0052
Epoch 300, Loss: 0.0032
Epoch 400, Loss: 0.0022
Epoch 500, Loss: 0.0017
Epoch 600, Loss: 0.0014
Epoch 700, Loss: 0.0011
Epoch 800, Loss: 0.0009
Epoch 900, Loss: 0.0008
Epoch 1000, Loss: 0.0007
===== 可用示例(极短简单文本) =====
文本:电影 好看 → 预测情感:正面(标签:1)
文本:饭菜 难吃 → 预测情感:负面(标签:0)
文本:音乐 好听 → 预测情感:正面(标签:1)
===== 局限示例(长/复杂文本) =====
文本:电影 剧情 一般 但 演技 好 → 预测情感:正面(标签:1)
文本:天气 糟糕 但 心情 好 → 预测情感:正面(标签:1)
文本:饭菜 好吃 但 分量 少 → 预测情感:正面(标签:1)使用 PyTorch 实现一个 2 层的 RNN
这是一个 2 层的 RNN,用于进行文本生成的例子。
python
import torch
import torch.nn as nn
import torch.optim as optim
# ===================== 1. 训练数据 =====================
text = """
床前明月光,疑是地上霜。举头望明月,低头思故乡。
白日依山尽,黄河入海流。欲穷千里目,更上一层楼。
春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。
千山鸟飞绝,万径人踪灭。孤舟蓑笠翁,独钓寒江雪。
松下问童子,言师采药去。只在此山中,云深不知处。
红豆生南国,春来发几枝。愿君多采撷,此物最相思。
"""
# 清理文本(去掉换行/空格,只保留有效字符)
text = text.replace("\n", "").replace(" ", "")
# 字符→索引映射(词汇表随文本扩展自动变大)
chars = sorted(list(set(text)))
char2idx = {c: i for i, c in enumerate(chars)}
idx2char = {i: c for i, c in enumerate(chars)}
print(f"词汇表: ", char2idx)
vocab_size = len(chars)
seq_len = 10 # 序列长度
# 构建训练数据(样本量随文本长度大幅增加)
def build_data(text, seq_len):
data = []
# 遍历文本,生成大量输入-目标序列对
for i in range(len(text) - seq_len):
input_seq = text[i:i+seq_len]
target_seq = text[i+1:i+seq_len+1]
x = torch.tensor([char2idx[c] for c in input_seq], dtype=torch.long)
y = torch.tensor([char2idx[c] for c in target_seq], dtype=torch.long)
x_onehot = torch.eye(vocab_size)[x] # One-Hot编码
data.append((x_onehot, y))
return data
train_data = build_data(text, seq_len)
print(f"训练样本总数: ", len(train_data)) # 打印样本数,直观看到增加
# ===================== 2. 两层RNN模型(微调隐藏层适配更多数据) =====================
class SimpleTwoLayerRNN(nn.Module):
def __init__(self, input_dim, hidden_dim1, hidden_dim2, output_dim):
super().__init__()
# 第一层RNN参数
self.W_xh1 = nn.Parameter(torch.randn(hidden_dim1, input_dim) * 0.1)
self.W_hh1 = nn.Parameter(torch.randn(hidden_dim1, hidden_dim1) * 0.1)
self.b_h1 = nn.Parameter(torch.zeros(hidden_dim1, 1))
# 第二层RNN参数
self.W_h1h2 = nn.Parameter(torch.randn(hidden_dim2, hidden_dim1) * 0.1)
self.W_hh2 = nn.Parameter(torch.randn(hidden_dim2, hidden_dim2) * 0.1)
self.b_h2 = nn.Parameter(torch.zeros(hidden_dim2, 1))
# 输出层
self.W_hy = nn.Parameter(torch.randn(output_dim, hidden_dim2) * 0.1)
self.b_y = nn.Parameter(torch.zeros(output_dim, 1))
def forward(self, x_seq):
h1 = torch.zeros(self.W_hh1.shape[0], 1) # 第一层隐藏状态
h2 = torch.zeros(self.W_hh2.shape[0], 1) # 第二层隐藏状态
all_preds = []
# 逐时间步计算两层RNN
for t in range(x_seq.shape[0]):
x_t = x_seq[t].unsqueeze(1)
# 第一层RNN
h1 = torch.tanh(torch.matmul(self.W_hh1, h1) + torch.matmul(self.W_xh1, x_t) + self.b_h1)
# 第二层RNN:第一层的输出 h1 作为第二次的输入
h2 = torch.tanh(torch.matmul(self.W_hh2, h2) + torch.matmul(self.W_h1h2, h1) + self.b_h2)
# 输出层
y_t = torch.matmul(self.W_hy, h2) + self.b_y
y_t = torch.log_softmax(y_t.squeeze(1), dim=0)
all_preds.append(y_t)
return torch.stack(all_preds, dim=0)
# ===================== 3. 训练 =====================
# 2 层 RNN,每层的维度如下
hidden_dim1 = 24
hidden_dim2 = 12
model = SimpleTwoLayerRNN(vocab_size, hidden_dim1, hidden_dim2, vocab_size)
criterion = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.015) # 微调学习率,加速收敛
# 训练轮次500,每100轮打印loss(更清晰看到训练趋势)
print("\n开始训练:")
for epoch in range(500):
total_loss = 0.0
for x, y in train_data:
optimizer.zero_grad()
preds = model(x)
loss = criterion(preds, y)
loss.backward()
optimizer.step()
total_loss += loss.item()
# 每100轮打印一次loss(减少冗余输出,聚焦趋势)
if (epoch+1) % 100 == 0:
avg_loss = total_loss / len(train_data)
print(f"Epoch {epoch+1:3d} | 平均Loss: {avg_loss:.4f}")
# ===================== 4. 文本生成(保留极简逻辑,生成更长文本) =====================
def generate_text(prefix, max_len=20):
model.eval()
with torch.no_grad():
gen = list(prefix)
h1 = torch.zeros(hidden_dim1, 1)
h2 = torch.zeros(hidden_dim2, 1)
# 先跑一遍前缀,初始化隐藏状态
for c in prefix:
x_t = torch.eye(vocab_size)[char2idx[c]].unsqueeze(1)
h1 = torch.tanh(torch.matmul(model.W_hh1, h1) + torch.matmul(model.W_xh1, x_t) + model.b_h1)
h2 = torch.tanh(torch.matmul(model.W_hh2, h2) + torch.matmul(model.W_h1h2, h1) + model.b_h2)
# 逐字符生成(生成长度从10→20,更能体现效果)
while len(gen) < max_len:
last_char = gen[-1]
x_t = torch.eye(vocab_size)[char2idx[last_char]].unsqueeze(1)
h1 = torch.tanh(torch.matmul(model.W_hh1, h1) + torch.matmul(model.W_xh1, x_t) + model.b_h1)
h2 = torch.tanh(torch.matmul(model.W_hh2, h2) + torch.matmul(model.W_h1h2, h1) + model.b_h2)
y_t = torch.matmul(model.W_hy, h2) + model.b_y
next_idx = torch.argmax(y_t).item()
next_char = idx2char[next_idx]
gen.append(next_char)
return "".join(gen)
# 多组前缀测试,验证生成效果
print("\n===== 文本生成结果(多前缀测试) =====")
test_prefixes = ["床前", "白日", "春眠", "千山"]
for prefix in test_prefixes:
gen_result = generate_text(prefix, max_len=20)
print(f"前缀:{prefix} → 生成:{gen_result}")执行输出:
bash
词汇表: {'。': 0, '一': 1, '万': 2, '上': 3, '下': 4, '不': 5, '中': 6, '举': 7, '乡': 8, '云': 9, '人': 10, '低': 11, '依': 12, '光': 13, '入': 14, '几': 15, '前': 16, '千': 17, '南': 18, '去': 19, '发': 20, '只': 21, '君': 22, '啼': 23, '国': 24, '在': 25, '地': 26, '声': 27, '处': 28, '多': 29, '夜': 30, '头': 31, '子': 32, '孤': 33, '寒': 34, '少': 35, '尽': 36, '层': 37, '山': 38, '师': 39, '床': 40, '径': 41, '思': 42, '愿': 43, '撷': 44, '故': 45, '日': 46, '明': 47, '春': 48, '是': 49, '晓': 50, '更': 51, '最': 52, '月': 53, '望': 54, '来': 55, '松': 56, '枝': 57, '楼': 58, '欲': 59, '此': 60, '江': 61, '河': 62, '流': 63, '海': 64, '深': 65, '灭': 66, '物': 67, '独': 68, '生': 69, '疑': 70, '白': 71, '目': 72, '相': 73, '眠': 74, '知': 75, '穷': 76, '童': 77, '笠': 78, '红': 79, '绝': 80, '翁': 81, '舟': 82, '花': 83, '药': 84, '落': 85, '蓑': 86, '觉': 87, '言': 88, '豆': 89, '踪': 90, '采': 91, '里': 92, '钓': 93, '问': 94, '闻': 95, '雨': 96, '雪': 97, '霜': 98, '风': 99, '飞': 100, '鸟': 101, '黄': 102, ',': 103}
训练样本总数: 134
开始训练:
Epoch 100 | 平均Loss: 1.8109
Epoch 200 | 平均Loss: 0.7239
Epoch 300 | 平均Loss: 0.3822
Epoch 400 | 平均Loss: 0.2576
Epoch 500 | 平均Loss: 0.2015
===== 文本生成结果(多前缀测试) =====
前缀:床前 → 生成:床前翁,云深不知处。红豆生南国,春来发几
前缀:白日 → 生成:白日生明中,云深不知处。红豆生南国,春来
前缀:春眠 → 生成:春眠觉知,处。红豆生南国,春来发几枝。愿
前缀:千山 → 生成:千山月月,万径人踪灭。孤舟蓑笠翁,独钓寒一个多层的 RNN 网络中的 RNN 神经元展开后,就像是一个多层的 FFN 网络。其中 RNN 神经元的时间步数量由序列长度决定。
输入-输出结构类型
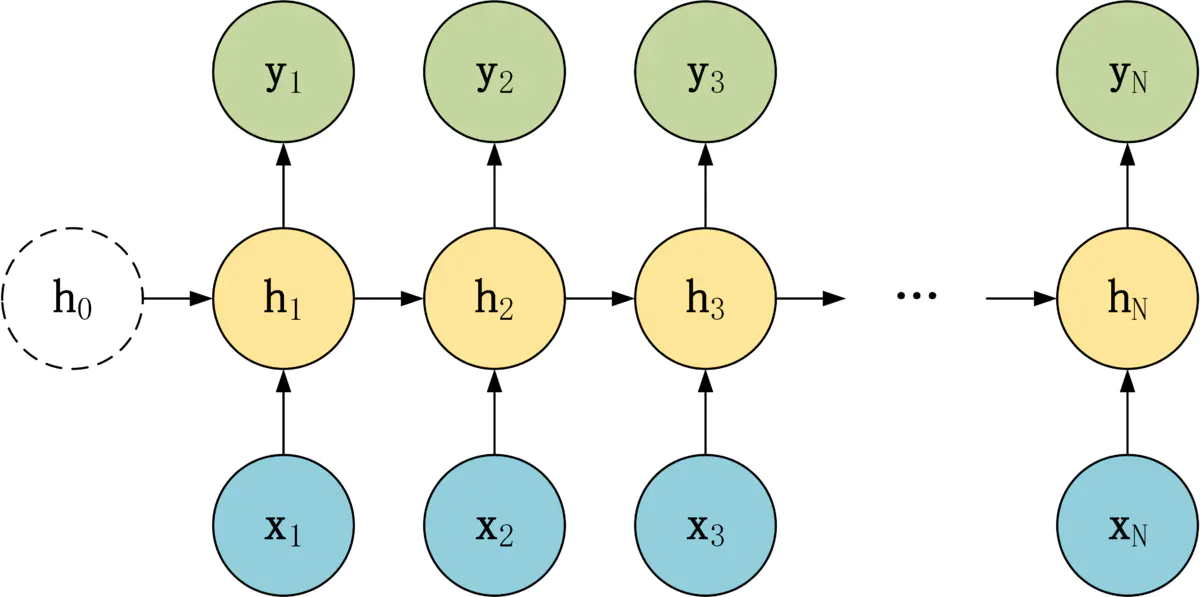
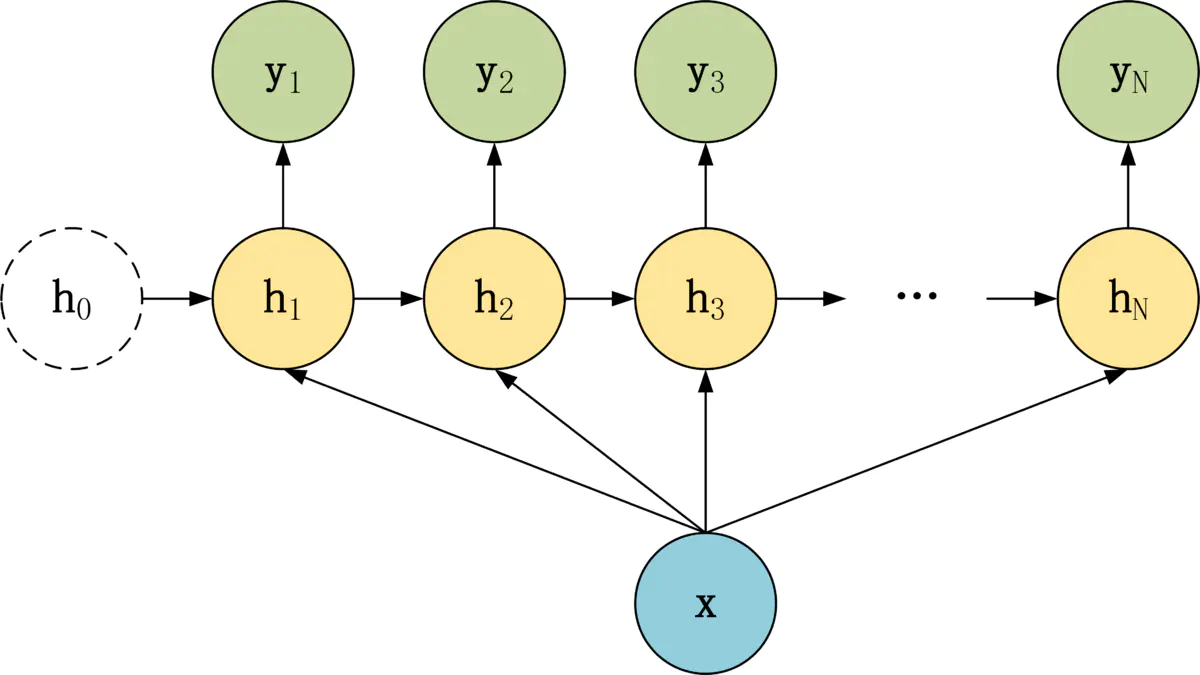
N-N 结构
N-N 结构,包含 N 个输入 x1, x2, ..., xN,和 N 个输出 y1, y2, ..., yN。
N-N 结构,输入和输出序列的长度是相等的。
通常适合用于以下任务:
- 词性标注。
- 训练语言模型,使用之前的词预测下一个词等。
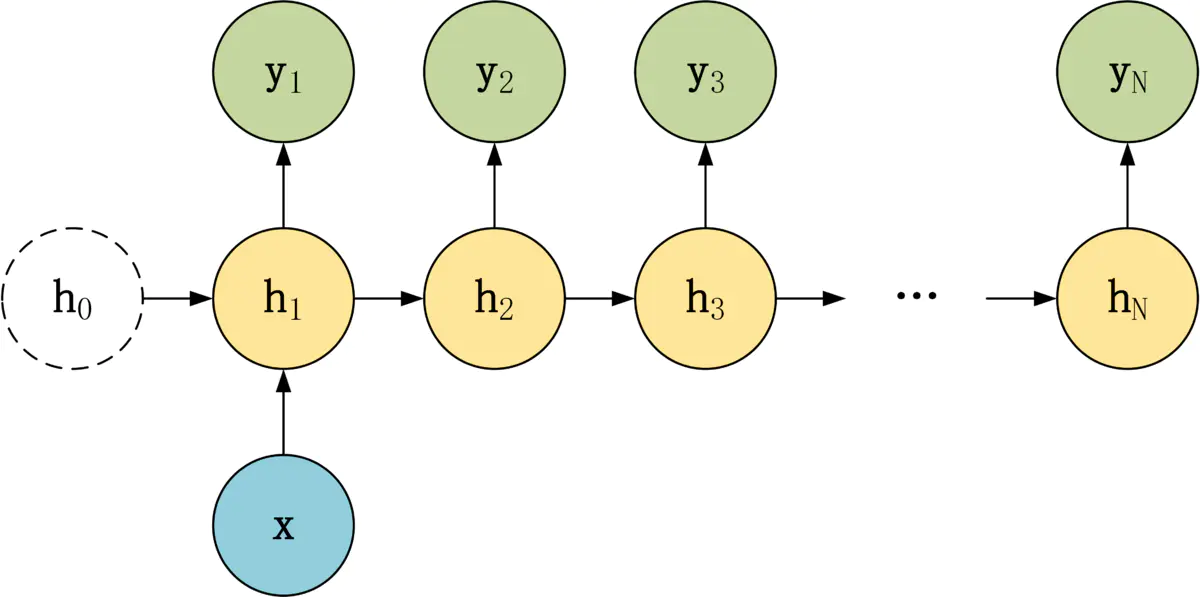
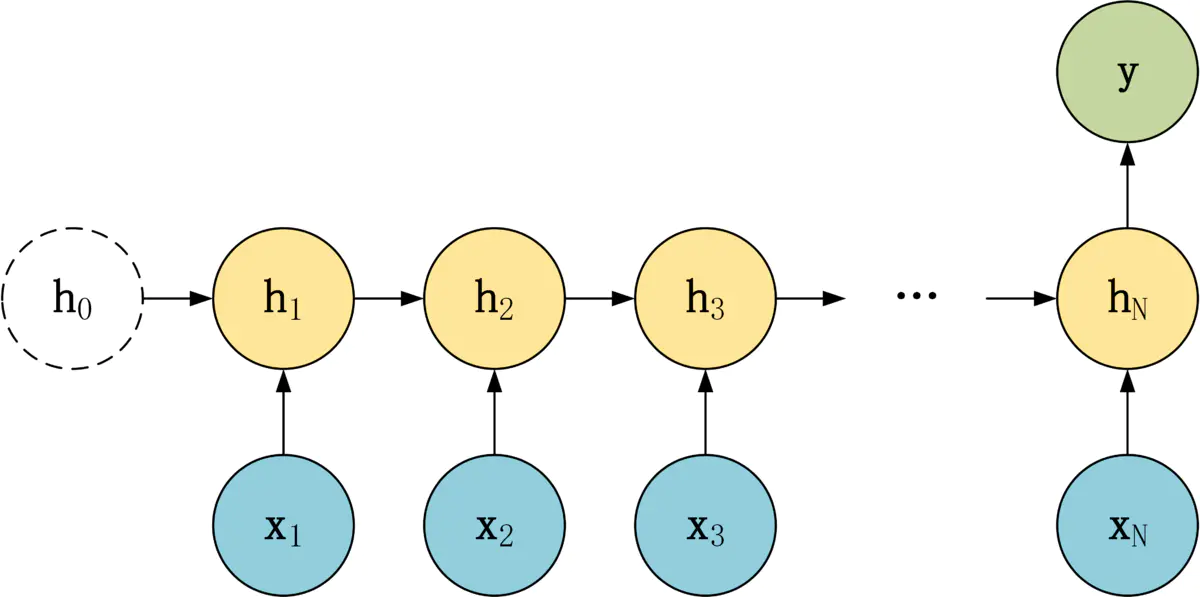
1-N 结构
1-N 结构中,只有一个输入 x,和 N 个输出 y1, y2, ..., yN。
适合用于以下任务:
- 图像生成文字,输入 x 就是一张图片,输出就是一段图片的描述文字。
- 根据音乐类别,生成对应的音乐。
- 根据小说类别,生成相应的小说。
可以有两种方式实现 1-N:
- 只将输入 x 传入第一个 RNN 神经元
- 将输入 x 传入所有的 RNN 神经元。
N-1 结构
N-1 结构中,有 N 个输入 x1, x2, ..., xN,和一个输出 y。
适合用于以下任务:
- 序列分类任务,一段语音、一段文字的类别,句子的情感分析。
RNN 的长序列依赖问题
尽管 RNN 的设计在理论上能够捕捉任意长度的序列依赖关系,但在实践中,它们很难学习到 "长期依赖"(Long-Term Dependencies)。即:当序列过长时,早期信息的梯度会逐渐消失,导致模型无法记住早期信息,例如:在句子 "I grew up in China...(20 个词后)...so I speak fluent Chinese" 中,RNN 难以关联单词 China 和 Chinese。
长期依赖问题主要源于梯度消失(Vanishing Gradients)和梯度爆炸(Exploding Gradients):
-
梯度消失:1991 年,Sepp Hochreiter 在他的毕业论文中阐述了梯度消失问题,当梯度在稍微深一点的网络中(如超过 10 个时间步)进行反向传播时就会发现训练过程中前面层的参数几乎不更新,即梯度几乎为零,核心的原因是 "累乘衰减"。具体而言,在通过 BPTT 反向传播梯度时,如果激活函数(如 tanh)的导数持续小于 1,那么梯度在每一步传播时都会被乘以一个小于 1 的权重矩阵。经过许多时间步后,梯度会变得非常小,几乎接近于零。这导致网络无法有效地更新与早期时间步相关的权重,从而 "忘记" 了久远的信息。
-
梯度爆炸:相反,如果权重矩阵的值很大,梯度在反向传播过程中可能会指数级增长,导致数值溢出和训练过程的不稳定。 虽然梯度爆炸可以通过梯度裁剪(Gradient Clipping)等技术相对容易地解决,但梯度消失问题则更为棘手。
可见,由于梯度消失问题,RNN 的 "历史记忆" 实际上是短暂的,这限制了它在需要理解长篇文本或分析长期时间序列等任务中的应用。
LSTM(长短期记忆网络)
1997 年,Sepp Hochreiter 和 Jürgen Schmidhuber 发表了论文《Long Short-Term Memory》提出了 LSTM(长短期记忆网络)。
LSTM 是一种特殊且复杂的 RNN,它通过使用专门的记忆单元和门控机制来序列数据中的长期依赖关系,能够学习到 "何时" 记忆信息、何时遗忘信息以及何时输出信息。解决了 RNN 的梯度消失问题。
模型结构与数学表达
LSTM 的核心思想是随时间选择性地记住或遗忘信息,通过记忆单元的线性传递路径(类似信息高速公路)和门控机制,避免梯度在长序列中衰减,相当于为梯度传递安装了中继器。
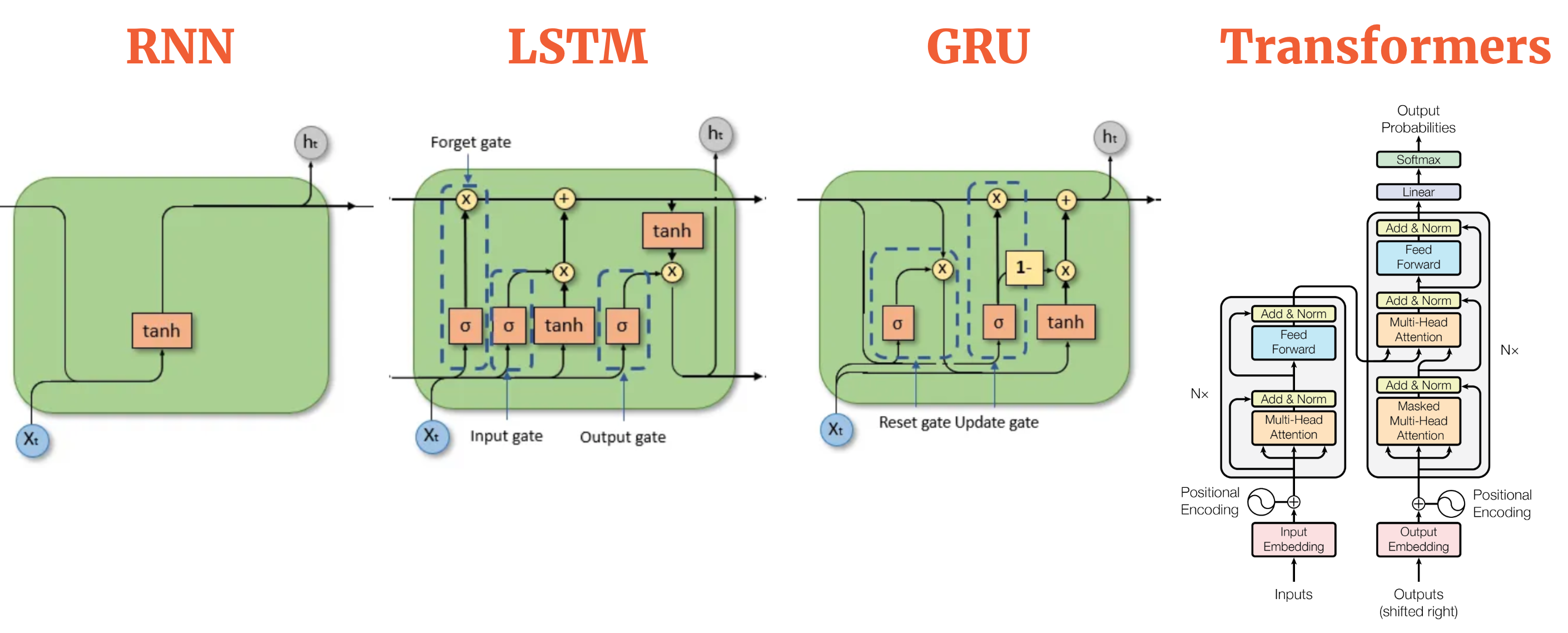
LSTM 将 RNN 中的隐藏层单元换成了一种具有特殊记忆功能的循环体结构,在隐藏层状态 h_t 的基础上增加了记忆单元状态(Memory Cell State) C_t。如下图所示,LSTM 在模型结构的关键创新是引入了一个 Memory Cell(记忆细胞),并在内部实现了 "输入 => 门控 => 输出" 的控制机制,以此来解决梯度消失的问题。
- 输入:包括当前输入、上一时间步的隐藏状态(Hidden State)、上一时间步的记忆单元状态(Cell State)。
- 门控:每个 Cell 包含了 "记忆、遗忘、输出" 这 3 个关键的门,它们互相协作共同更新当前时间步的记忆单元状态(如图最上方连线)。门的本质是一个由 Sigmoid 激活函数和一个点积乘法操作组成的神经网络层。Sigmoid 函数的输出在 0~1 之间,这个值决定了有多少信息可以通过。0 表示 "完全不允许通过",而 1 表示 "完全允许通过",0-1 表示保留部分信息。
- 输出 :包括当前记忆单元状态和当前输出。
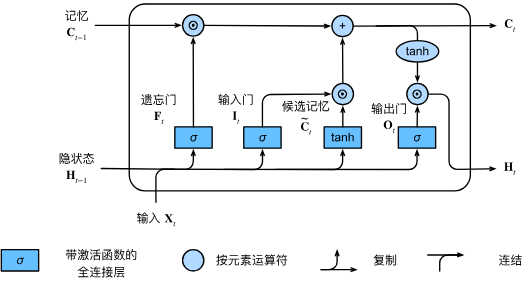
- 遗忘门(Forget Gate):控制历史信息的保留。利用 sigmoid 激活函数,它获取 h_t-1 和 x_t,并为 C_t-1 中的每个数字输出一个 0~1 之间的值。这个值代表了保留或遗忘的程度。
bash
f_t = σ(W_f * [h_t-1, x_t] + b_f)- 输入门(Input Gate):控制当前时刻的输入中有多少信息要被添加到 Cell State 中。首先通过 sigmoid 函数确定需要添加的信息。然后通过 tanh 函数创建一个候选的记忆单元状态向量 C̃_t,该向量可以被添加到记忆单元状态中。
bash
i_t = σ(W_i * [h_t-1, x_t] + b_i)
C̃_t = tanh(W_c * [h_t-1, x_t] + b_c)- 记忆单元状态更新:通过处理要遗忘和要保留的信息,完成上一时刻的记忆单元状态 C_t-1 到当前时刻 C_t 的更新(矩阵乘积)更新。先将 C_t-1* f_t(要遗忘的旧信息),然后 "+" 加上 i_t * C̃_t(要添加的新信息)。
bash
C_t = f_t * C_t-1 + i_t * C̃_t- 输出门 (Output Gate):控制输出的过程。首先 sigmoid 层决定记忆单元状态 C_t 的哪些部分将要输出。然后 C_t 通过 tanh 函数(将其值缩放到 -1~1 之间),并将其与 sigmoid 层的输出相乘,从而只会输出了想要输出的部分。这个输出就是新的隐藏状态 h_t。
bash
o_t = σ(W_o * [h_t-1, x_t] + b_o)
h_t = o_t * tanh(C_t)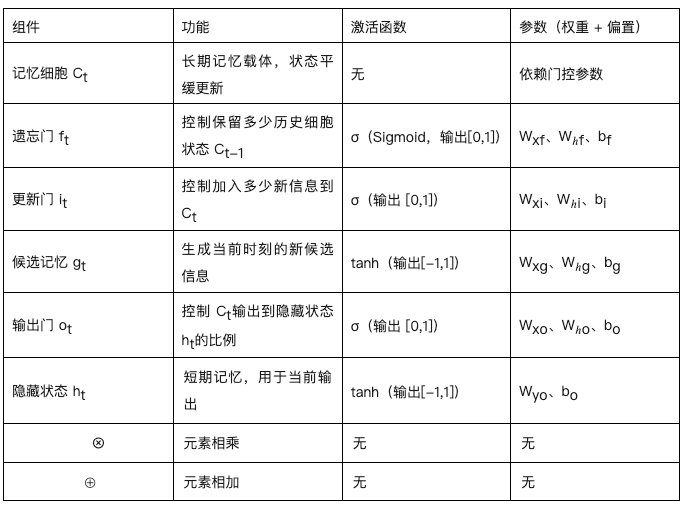
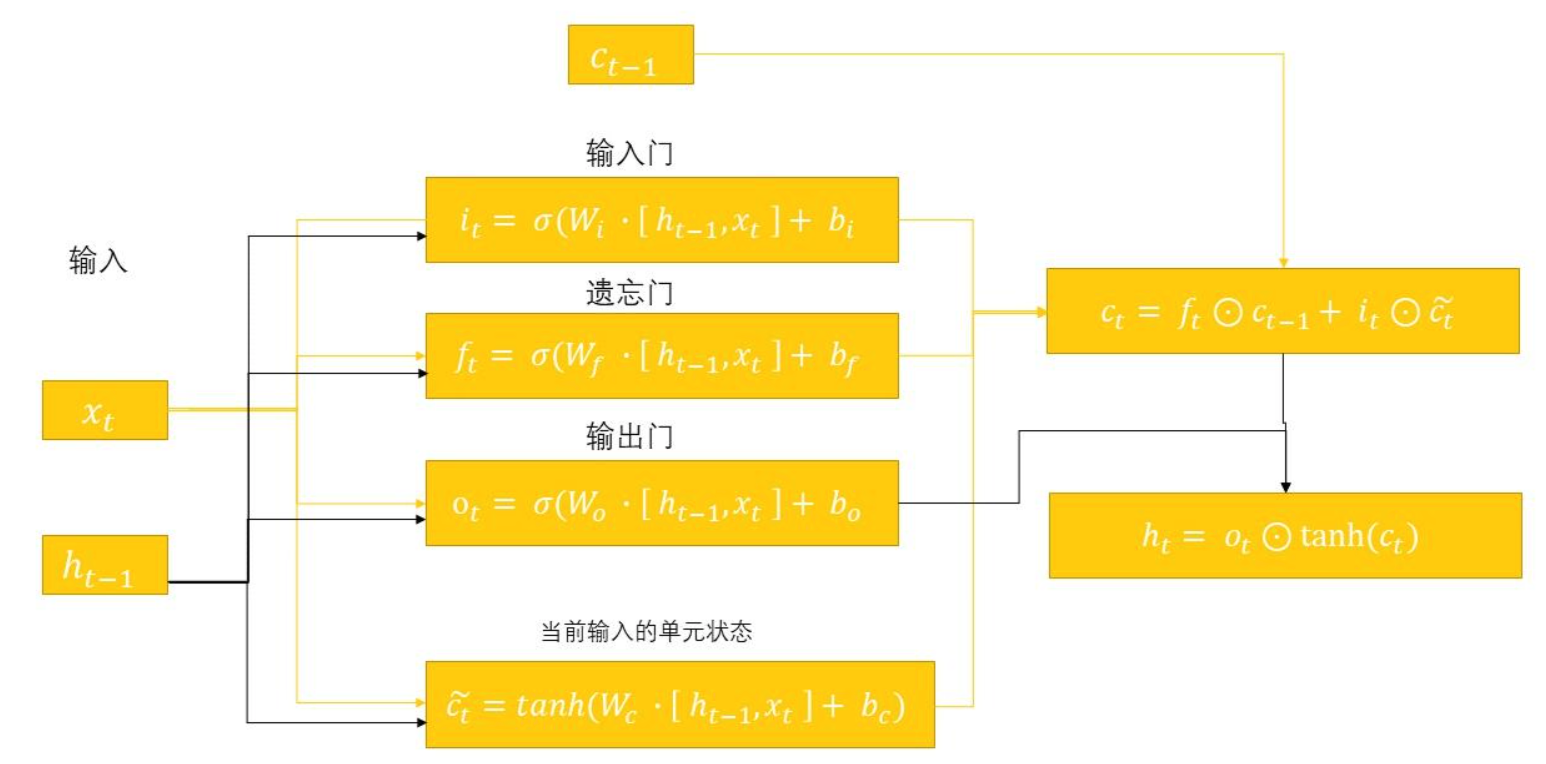
解决梯度消失问题
上述过程可知,LSTM Memory Cell 中的门控机制约束了哪些信息是可以遗忘的、哪些信息是可以记住的、哪些信息是可以输出的。
其独特的 Cell State 更新公式 C_t = f_t * C_t-1 + ...,让 C_t 的梯度包含一个 f_t 因子,通过学习,遗忘门可以设置 f_t 为接近 1 的值,从而允许梯度在许多时间步内几乎无衰减地流动,这样就解决了 RNN "累积衰减" 的问题。这种结构使得网络更容易学习和保持长期依赖关系。
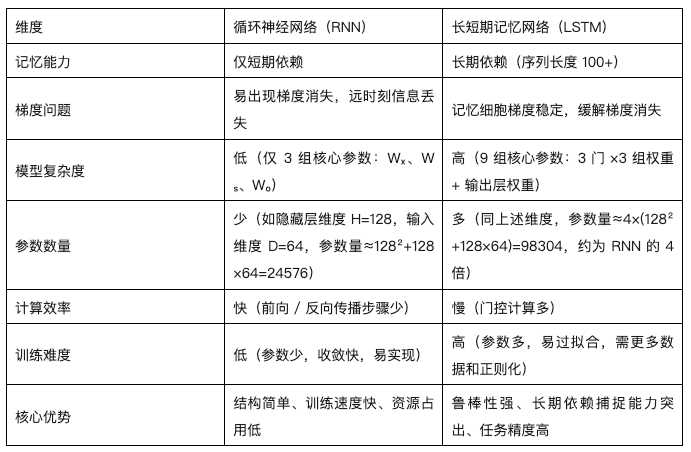
RNN v.s LSTM
RNN 作为序列建模的 "基石",以简单的循环结构开创了历史信息复用的思路,但受限于梯度消失无法处理长序列;LSTM 则通过记忆细胞和门控机制的创新,从梯度传递路径上解决了长期依赖问题,成为长序列任务的经典方案。
RNN 优势:
- 结构简单,参数少;
- 适用于短期依赖序列建模;
- 训练速度快,适合资源受限场景。
RNN 劣势:
- 容易陷入梯度消失/爆炸;
- 长期依赖学习能力弱。
LSTM 优势:
- 通过门控机制保留长期信息;
- 性能更稳定,泛化能力强;
- 适用于文本、语音、金融等长时间序列建模。
LSTM 劣势:
- 参数多,训练成本高;
- 相比 RNN 更复杂,不易调参。
RNN 和 LSTM 代码实现
- RNNModel:使用一个标准的单层 RNN;
- LSTMModel:使用单层 LSTM;
- 都接一个全连接层预测输出;
- Loss 函数为 MSE,优化器为 Adam。
python
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import Dataset, DataLoader
from sklearn.metrics import mean_squared_error
# 设置随机种子
np.random.seed(42)
torch.manual_seed(42)
# 创建一个合成的时间序列数据(正弦波+噪声)
t = np.arange(0, 100, 0.1)
data = np.sin(t) + np.random.normal(scale=0.5, size=len(t))
df = pd.DataFrame(data, columns=['value'])
# 数据归一化
scaler = MinMaxScaler()
df['value'] = scaler.fit_transform(df[['value']])
# 创建数据集类
class TimeSeriesDataset(Dataset):
def __init__(self, data, seq_length):
self.data = data
self.seq_length = seq_length
def __len__(self):
return len(self.data) - self.seq_length
def __getitem__(self, idx):
x = self.data[idx:idx+self.seq_length]
y = self.data[idx+self.seq_length]
return torch.FloatTensor(x), torch.FloatTensor([y])
# 创建训练和测试数据
seq_length = 20
train_size = int(len(df) * 0.8)
train_data = df['value'].values[:train_size]
test_data = df['value'].values[train_size - seq_length:]
train_dataset = TimeSeriesDataset(train_data, seq_length)
test_dataset = TimeSeriesDataset(test_data, seq_length)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)
# 定义 RNN 模型
class RNNModel(nn.Module):
def __init__(self, input_size=1, hidden_size=50):
super(RNNModel, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.rnn(x.unsqueeze(-1))
out = self.fc(out[:, -1, :])
return out
# 定义 LSTM 模型
class LSTMModel(nn.Module):
def __init__(self, input_size=1, hidden_size=50):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x.unsqueeze(-1))
out = self.fc(out[:, -1, :])
return out
# 训练函数
def train_model(model, train_loader, num_epochs=10):
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
losses = []
for epoch in range(num_epochs):
for x_batch, y_batch in train_loader:
optimizer.zero_grad()
output = model(x_batch)
loss = criterion(output, y_batch)
loss.backward()
optimizer.step()
losses.append(loss.item())
return model, losses
# 预测函数
def predict(model, data_loader):
model.eval()
predictions = []
actuals = []
with torch.no_grad():
for x_batch, y_batch in data_loader:
pred = model(x_batch)
predictions.append(pred.item())
actuals.append(y_batch.item())
return np.array(predictions), np.array(actuals)
# 初始化模型并训练
rnn_model = RNNModel()
lstm_model = LSTMModel()
rnn_model, rnn_losses = train_model(rnn_model, train_loader, num_epochs=20)
lstm_model, lstm_losses = train_model(lstm_model, train_loader, num_epochs=20)
# 模型预测
rnn_preds, rnn_actuals = predict(rnn_model, test_loader)
lstm_preds, lstm_actuals = predict(lstm_model, test_loader)
# 反归一化预测值
rnn_preds_inv = scaler.inverse_transform(rnn_preds.reshape(-1, 1)).flatten()
lstm_preds_inv = scaler.inverse_transform(lstm_preds.reshape(-1, 1)).flatten()
actuals_inv = scaler.inverse_transform(lstm_actuals.reshape(-1, 1)).flatten()
# 绘制图像
plt.figure(figsize=(16, 12))
# 图1: 损失函数曲线
plt.subplot(2, 2, 1)
plt.plot(rnn_losses, label='RNN Loss', color='crimson')
plt.plot(lstm_losses, label='LSTM Loss', color='mediumseagreen')
plt.title('训练损失随Epoch变化图')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
# 图2: 测试集预测结果比较
plt.subplot(2, 2, 2)
plt.plot(actuals_inv, label='Actual', color='black')
plt.plot(rnn_preds_inv, label='RNN Predicted', color='darkorange')
plt.plot(lstm_preds_inv, label='LSTM Predicted', color='dodgerblue')
plt.title('测试集预测结果比较')
plt.xlabel('Time Step')
plt.ylabel('Value')
plt.legend()
plt.grid(True)
# 图3: 预测误差分布直方图
plt.subplot(2, 2, 3)
rnn_error = rnn_preds_inv - actuals_inv
lstm_error = lstm_preds_inv - actuals_inv
plt.hist(rnn_error, bins=30, alpha=0.7, label='RNN Error', color='red')
plt.hist(lstm_error, bins=30, alpha=0.7, label='LSTM Error', color='green')
plt.title('预测误差分布直方图')
plt.xlabel('误差')
plt.ylabel('频率')
plt.legend()
plt.grid(True)
# 图4: 实际 vs 预测散点图
plt.subplot(2, 2, 4)
plt.scatter(actuals_inv, rnn_preds_inv, label='RNN', alpha=0.5, color='purple')
plt.scatter(actuals_inv, lstm_preds_inv, label='LSTM', alpha=0.5, color='cyan')
plt.plot(actuals_inv, actuals_inv, color='black', linestyle='--', label='Ideal')
plt.title('实际值 vs 预测值')
plt.xlabel('实际值')
plt.ylabel('预测值')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()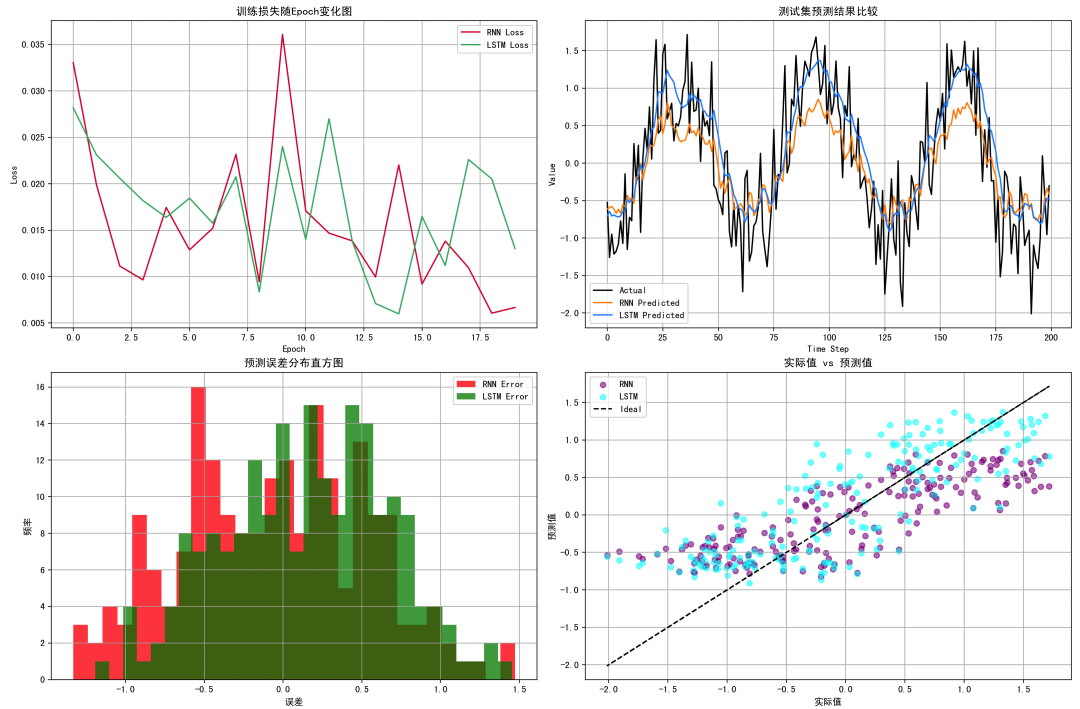
- 训练损失曲线:展示模型随训练过程损失的下降趋势。LSTM 收敛更快,且最终损失更低,表明其对序列建模更有效。
- 测试集预测结果对比:可视化真实值与两种模型的预测值对比。LSTM 更紧密拟合真实趋势,RNN 预测波动性较大。
- 误差分布图:分析两种模型预测误差的分布范围。LSTM 的误差集中度高,波动小;RNN 误差分布更宽,精度低。
- 实际 vs 预测散点图:检查预测值与真实值的一致性。LSTM 点更集中在理想线附近,说明相关性更高。
使用 PyTorch 实现 LSTM 模型
使用 PyTorch 框架构建一个 LSTM 模型,用于进行文本生成。我们将用一段文本来训练模型,然后让它生成新的文本。
python
import torch
import torch.nn as nn
import numpy as np
# --- 1. 数据准备 ---
# 将整个文本作为一个长字符串,并创建了字符与整数之间的双向映射。
# 示例文本
text = """
Recurrent Neural Networks (RNNs) are a class of neural networks that are helpful in modeling sequence data.
Derived from feedforward networks, RNNs are similar to human brains in the way they function.
They are designed to recognize patterns in sequences of data, such as text, handwriting, or time series data.
"""
# 创建字符到整数的映射
chars = sorted(list(set(text)))
char_to_int = {ch: i for i, ch in enumerate(chars)}
int_to_char = {i: ch for i, ch in enumerate(chars)}
n_chars = len(text)
n_vocab = len(chars)
print("总字符数: ", n_chars)
print("词汇表大小: ", n_vocab)
# --- 2. 准备训练数据 ---
# 创建了输入-输出对。输入是一个固定长度(`seq_length`)的字符序列,输出是紧随其后的那个字符。这种方式训练模型根据前面的字符序列来预测下一个字符。
# 将文本转换为整数序列
seq_length = 100
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = text[i:i + seq_length]
seq_out = text[i + seq_length]
dataX.append([char_to_int[char] forchar in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
print("总模式数: ", n_patterns)
# 将输入序列重塑为 [样本数, 时间步长, 特征数]
X = torch.tensor(dataX, dtype=torch.float32).reshape(n_patterns, seq_length, 1)
# 对输入进行归一化
X = X / float(n_vocab)
# one-hot编码输出变量
y = torch.tensor(dataY)
# --- 3. 定义 LSTM 模型 ---
# 定义了一个继承自 `nn.Module` 的类。
# `nn.LSTM` 是 PyTorch 中实现 LSTM 的核心层。`batch_first=True` 参数让输入张量的维度顺序为 `[批量大小, 序列长度, 特征维度]`,这更符合直觉。我们堆叠了两个 LSTM 层 (`num_layers=2`)以增加模型的表达能力。
# `nn.Linear` 是一个标准的全连接层,用于将 LSTM 层的输出映射到我们的词汇表大小,以便为每个字符生成一个分数。
# `forward` 方法定义了数据如何在模型中流动。我们初始化隐藏状态和细胞状态为零,然后将输入传递给 LSTM 层,最后将 LSTM 最后一个时间步的输出传递给全连接层。
class CharLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(CharLSTM, self).__init__()
self.hidden_size = hidden_size
# input_size: 输入特征维度 (这里是1)
# hidden_size: LSTM隐藏层维度
# num_layers: LSTM层数
self.lstm = nn.LSTM(input_size, hidden_size, num_layers=2, batch_first=True)
# 全连接层,将LSTM的输出映射到词汇表大小
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐藏状态和细胞状态
h0 = torch.zeros(2, x.size(0), self.hidden_size) # 2for num_layers
c0 = torch.zeros(2, x.size(0), self.hidden_size)
# LSTM 前向传播
out, _ = self.lstm(x, (h0, c0))
# 我们只关心最后一个时间步的输出
out = self.fc(out[:, -1, :])
return out
model = CharLSTM(input_size=1, hidden_size=256, output_size=n_vocab)
print(model)
# --- 4. 训练模型 ---
# 使用 `CrossEntropyLoss` 作为损失函数(适用于多分类问题)和 Adam 优化器进行训练。
n_epochs = 20
lr = 0.001
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(n_epochs):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{n_epochs}], Loss: {loss.item():.4f}')
# --- 5. 生成文本 ---
# 我们从数据中随机选取一个序列作为"种子",然后循环地让模型预测下一个字符,并将预测出的字符添加到生成文本中,同时更新下一次预测的输入序列。
# 随机选择一个种子序列
start = np.random.randint(0, len(dataX)-1)
pattern = dataX[start]
print("种子序列: ")
print("\"", ''.join([int_to_char[value] for value in pattern]), "\"")
print("\n生成的文本: ")
generated_text = ""
with torch.no_grad():
for i in range(500):
# 准备输入
x = torch.tensor(pattern, dtype=torch.float32).reshape(1, seq_length, 1)
x = x / float(n_vocab)
# 预测
prediction = model(x)
# 获取概率最高的字符索引
index = torch.argmax(prediction).item()
result = int_to_char[index]
generated_text += result
# 更新种子序列
pattern.append(index)
pattern = pattern[1:len(pattern)]
print(generated_text)GRU(门控循环单元)
2014 年,Cho 等人提出了 GRU(门控循环单元),是 LSTM 的一个简化版本。它保持了与 LSTM 相当性能的同时,结构更简单,参数更少,计算效率更高。
模型结构和数据表达
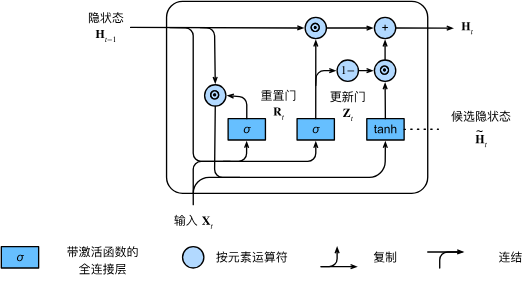
GRU 在模型结构上的主要创新在于它将 LSTM 的遗忘门和输入门合并为了一个单一的更新门(Update Gate),并且它还合并了记忆单元状态和隐藏状态。
GRU 只有两个门:
- 更新门(Update Gate):决定了应该在多大程度上保留前一个时间步的信息,以及在多大程度上接收新生成的信息。 它类似于 LSTM 中遗忘门和输入门的组合。
bash
z_t = σ(W_z * [h_t-1, x_t] + b_z)- 重置门(Reset Gate):决定了在计算新的候选隐藏状态时,应该忽略多少过去的信息。 如果重置门的输出接近 0,那么模型在计算候选状态时将主要依赖于当前输入 x_t。
bash
r_t = σ(W_r * [h_t-1, x_t] + b_r)- 候选隐藏状态与最终隐藏状态:首先,使用重置门计算一个候选隐藏状态 h̃_t 重置门 r_t 作用于 h_{t-1},控制了前一状态对候选状态的影响。然后,更新门 z_t 在 h_{t-1} 和 h̃_t 之间进行线性插值,以产生最终的隐藏状态 h_t。
bash
h̃_t = tanh(W_h * [r_t * h_t-1, x_t] + b_h)
h_t = (1 - z_t) * h_t-1 + z_t * h̃_t当 z_t 接近 1 时,新的隐藏状态 h_t 主要由候选状态 h̃_t 构成;当 z_t 接近 0 时,新的隐藏状态 h_t 则几乎完全保留了前一个状态 h_{t-1}。这种机制使得 GRU 也能有效地捕捉长期依赖。
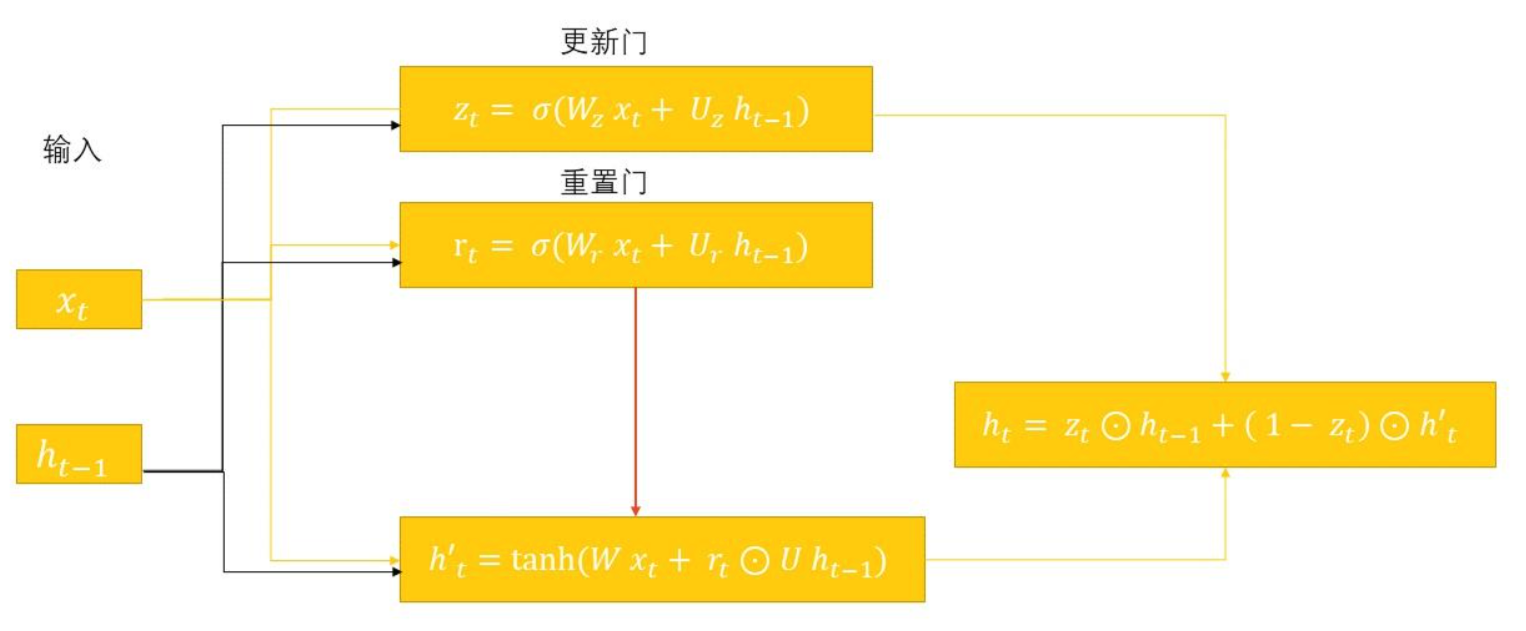
LSTM v.s. GRU
LSTM 解决了 RNN 因长期依赖带来的梯度消失和梯度爆炸问题,但是 LSTM 有三个不同的门,参数较多,训练起来比较困难。而 GRU 只含有两个门控结构,结构更为简单,参数更少,收敛速度更快。但因为 GRU 的参数更小所以理论上精度和表达能力会稍差于 LSTM。
LSTM 和 GRU 的适用场景不同:
- 长文本或复杂依赖:当数据涉及较长的文本,或任务需要理解复杂的上下文依赖时,LSTM 的强大记忆能力可以发挥优势。例如,处理长篇文章的情感分析、机器翻译等任务。例如:我们分析的是一篇长篇博客文章,其中前半部分描述了一个积极的事件,而后半部分充满了负面情感。要准确捕捉这种情感转变,LSTM 可能是更好的选择,因为它能够通过遗忘门和记忆单元,逐步积累并更新情感信息,从而做出更精确的情感判断。
- 短文本或实时性要求:如果你处理的是短文本,如推特、简短评论,或需模型快速响应,GRU 通常是更好的选择。它的计算效率更高,且在短期依赖场景下表现优异。例如:在分析推特或短句子的情感时,GRU的效率优势更加明显。GRU能快速处理短文本的情感特征,并及时提供预测结果,这对实时分析推特流的情感趋势尤其重要。
在某些场景下,可以尝试混合使用 LSTM 和 GRU,取长补短。例如:在情感分析任务中,如果希望获得高效且准确的模型,可以考虑使用 GRU 处理短文本情感,而使用 LSTM 处理长篇文本情感。通过这种组合方式,可以兼顾速度和准确性,提升整体模型表现。
另外,除了适用场景之外,在选择 LSTM 或 GRU 时,需要考虑以下因素:
- 任务复杂度:如果任务需要处理长期依赖关系,LSTM 可能更适合。而如果任务相对简单,GRU 的表现也可以达到满意水平。
- 计算效率:GRU 相较于 LSTM 具有更少的参数和更简洁的结构,因此在计算效率方面更优。
- 数据规模:对于大规模数据,LSTM 可能更适合,因为它具有更强的表达能力。而对于小规模数据,GRU 的表现也可以达到满意水平。
至今为止,GRU 和 LSTM 在序列处理场景中的价值已经得到了验证,它们两者各有优缺点。理解它们的区别和适用场景,能够帮助你在不同任务中做出更优的选择。
RNN Encoder--Decoder
RNN 的 N-N 结构可知,RNN 仅适用于输入和输出等长的任务。但实际中很多任务的序列的长度是不固定的,例如机器翻译中,源语言和目标语言的句子长度是不一样的;再例如对话系统中,问题和答案的句子长度也是不一样的。
2014 年,Bengio 在论文《Learning Phrase Representations using RNN Encoder--Decoder for Statistical Machine Translation》中提出了基于 RNN 的 Encoder--Decoder 模型。
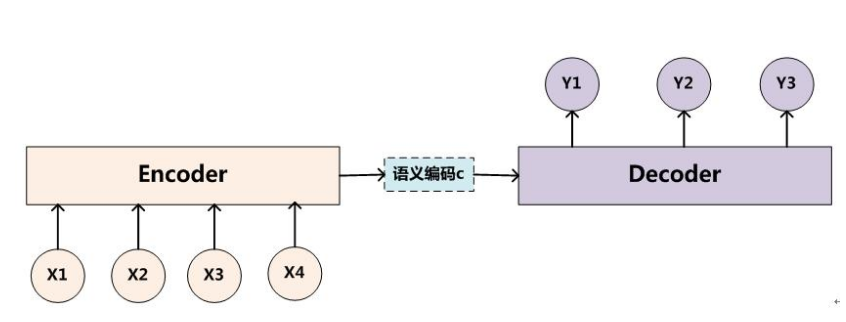
RNN Encoder--Decoder 的核心思想是将输出和输出分离为 2 个 RNN,并引入一个定长的隐状状态(Hidden state)来作为输入和输出之间的桥梁,以此来构建 N-1-M 的输入和输出不等长序列。
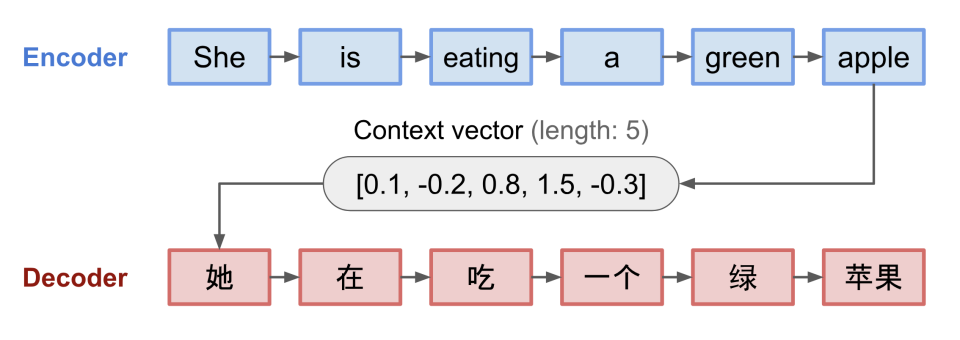
- Encoder(编码器) :用于编码输入序列的信息,将任意长度 N 的序列信息编码到一个定长的向量 c 里。Encoder 把输入句子的所有语义信息压缩成一个固定长度的中间语义向量(也称为上下文向量或隐向量或隐状态),该向量包含了可供计算与学习的、代表句子语言特点和含义的特征信息,是输入的浓缩摘要。具体逻辑为:
- Encoder 会对输入句子的每个词进行处理,处理每个词之后会产生一个隐藏状态。
- 从输入的第二个词开始,Encoder 每个时刻的输入是上一个时刻的隐藏状态和输入的新单词。
- Encoder 输出的最后一个时刻的隐藏状态就是编码了整个句子语义的语义上下文(Context),这是一个固定长度的高维特征向量 c,输入句子每个时间步的信息都包含在了这个上下文中。
- Decoder(解码器) :用于解码输出序列的信息,得到上下文信息向量 c 之后可以将信息解码,并输出为序列。值得注意的是,对于 Decoder 而言,上一轮的 Decoder 输出还会作为下一轮的输入以补充上下文信息。Decoder 会把这个中间语义上下文向量 c 解码成输出句子,即 Decoder 将 Encoder 学习到的特征信息再转化为相应的句子。具体逻辑为:
- 在每个时刻,Decoder 都是自回归的,即上一个时刻的输出 y_t−1 会作为当前时刻 t 的输入之一,生成当前时刻的字符 y_t。
- Decoder 最初的输入是中间语义上下文向量 c,解码器依据 c 计算出第一个输出词和新的隐藏状态,即 Decoder 的每个预测都受到先前输出词和隐藏状态的微妙影响。
- Decoder 接着用新的隐藏状态和第一个输出词作为联合输入来计算第二个输出词,以此类推,直到解码器产生一个 EOS(End Of Service,序列结束)标记或者达到预定序列长度的边界。
- 隐状状态(Hidden state):定长向量 C,把隐状态看成对输入信息的一种编码的话,用于在 Encoder 和 Decoder 之间传递信息。
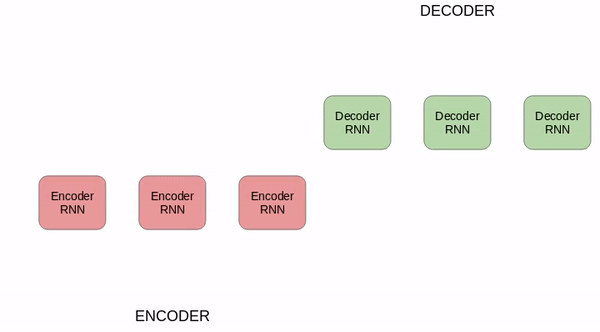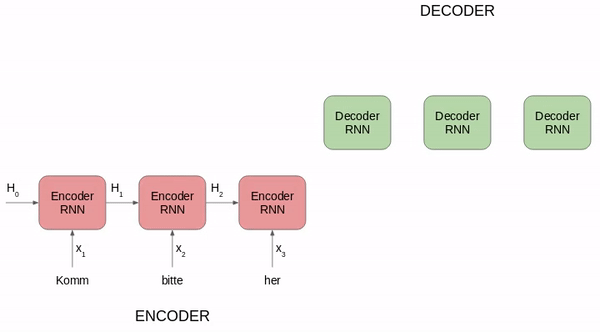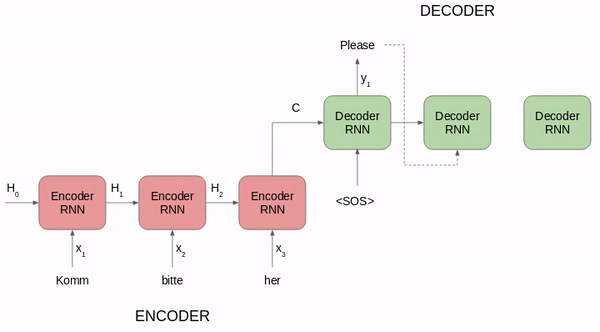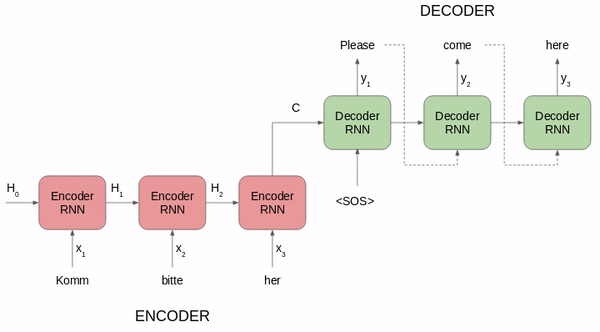
RNN Encoder-Decoder 架构在短句子上有非常好的表现。但是一个关键问题在于,Encoder 需要能够将源句子的所有必要信息压缩到一个固定长度的向量 c 中。这会使 RNN 难以处理长句子,尤其是那些比训练语料中的句子还长的句子。随着输入句子长度的增加,Encoder-Decoder 架构的性能会迅速恶化。
常见结构类型
RNN Encoder--Decoder 模型结构有很多种,下面是几种比较常见的 3 种: 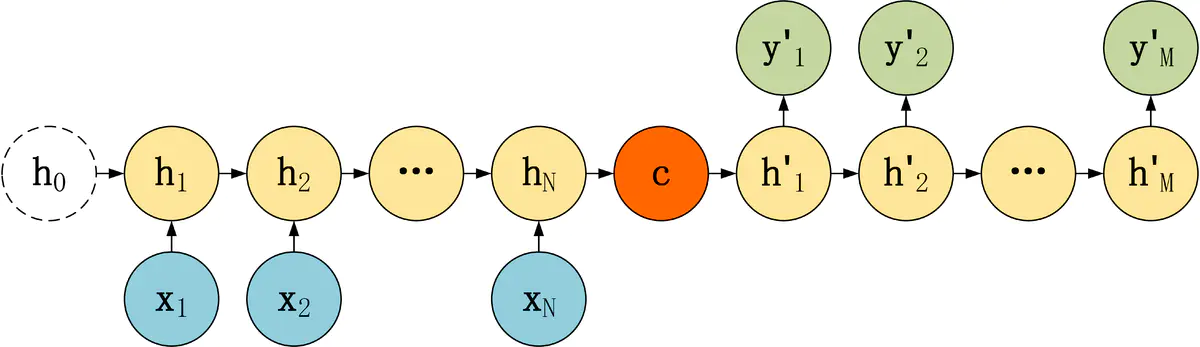
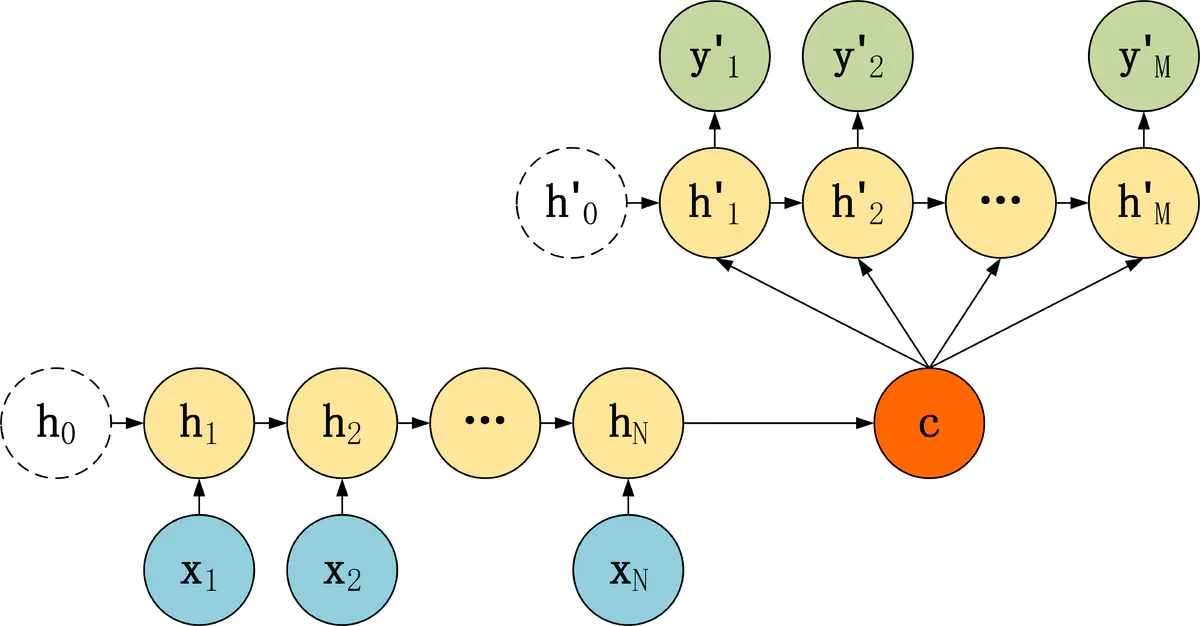
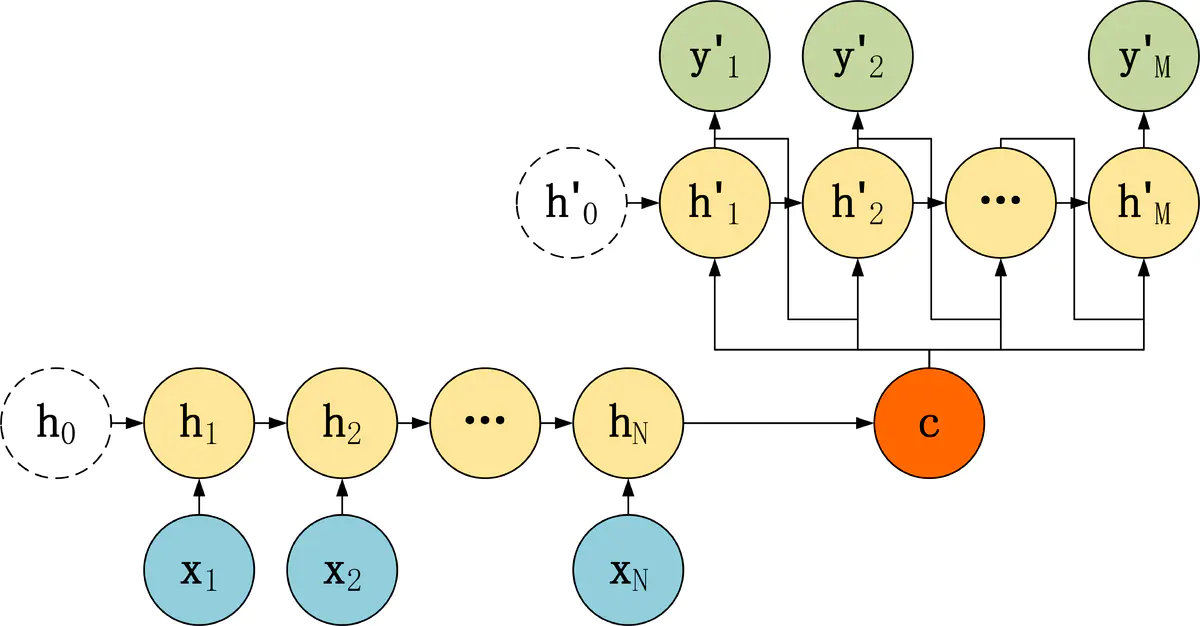
第三种 Decoder 结构和第二种类似,但是在输入的部分多了上一个神经元的输出 y'。即每一个神经元的输入包括:上一个神经元的隐藏层向量 h',上一个神经元的输出 y',当前的输入 c(Encoder 编码的上下文向量)。对于第一个神经元的输入 y'0,通常是句子其实标志位的 embedding 向量。
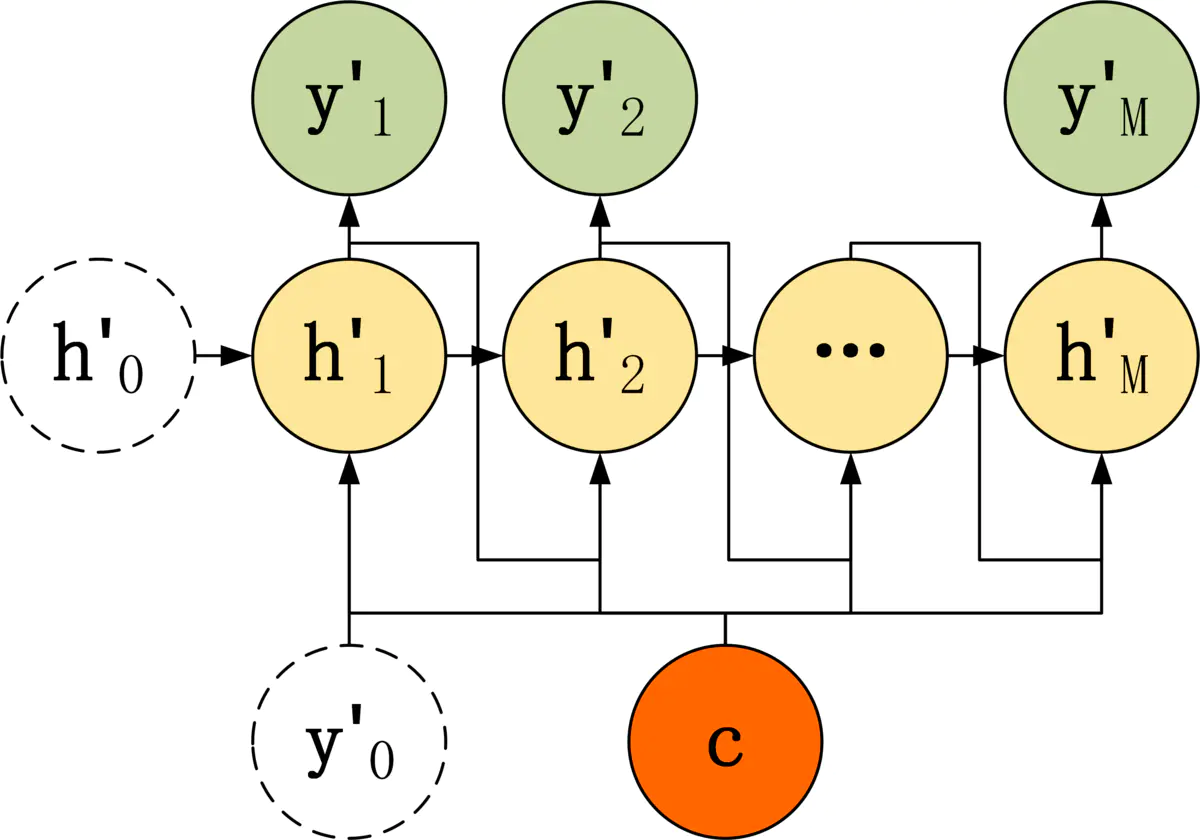
第三种 Decoder 的隐藏层及输出计算公式:
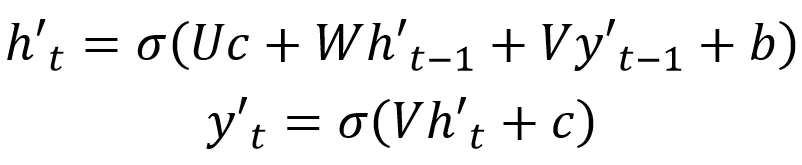
Encoder
上述 RNN Encoder--Decoder 模型结构中的 Encoder 都是一样的,区别在于 Decoder。
Encoder 的 RNN 接受输入 x,最终输出一个编码所有信息的上下文向量 c,中间的神经元没有输出。
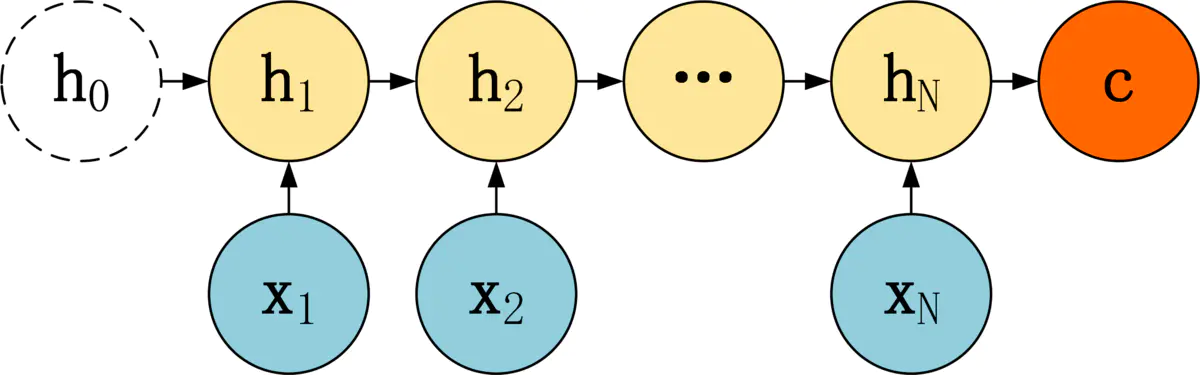
从公式可以看到,c 可以有 3 种计算方式:
- c 可以直接使用最后一个 RNN 神经元的隐藏状态 hN 表示;
- 也可以在最后一个 RNN 神经元的隐藏状态上进行某种变换 hN 而得到,q 函数表示某种变换;
- 还可以使用所有 RNN 神经元的隐藏状态 h1, h2, ..., hN 计算得到。
得到上下文向量 c 之后,需要传递到 Decoder,然后解码出需要的信息。
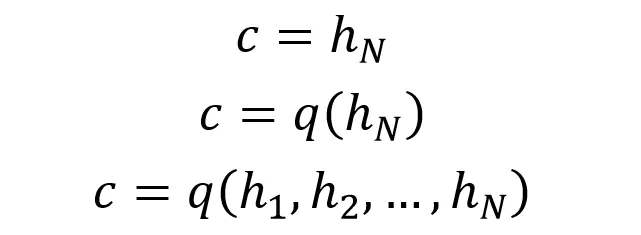
Decoder
第一种 Decoder 结构比较简单,将上下文向量 c 当成是 RNN 的初始隐藏状态,输入到 RNN 中,后续只接受上一个神经元的隐藏层状态 h' 而不接收其他的输入 x。
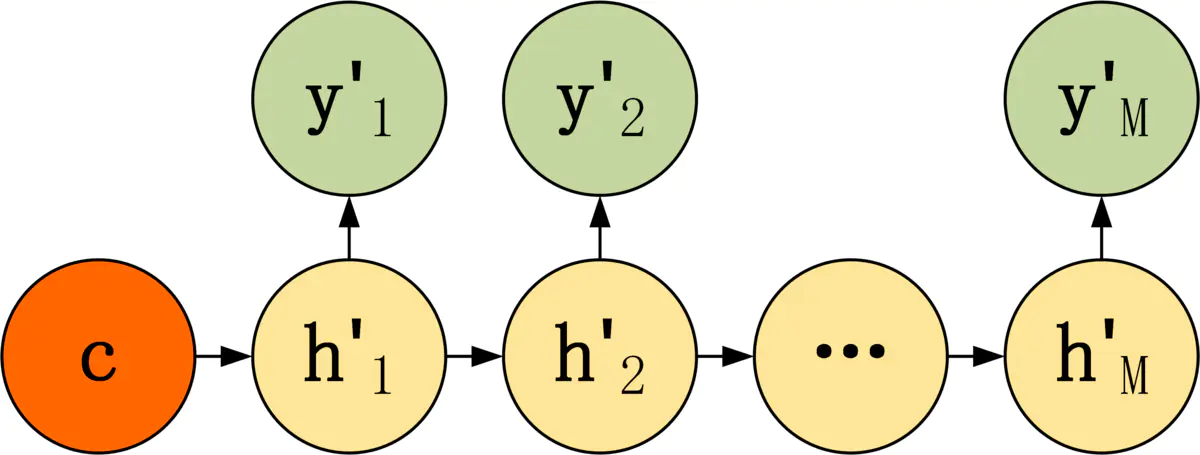
第一种 Decoder 结构的隐藏层及输出的计算公式:
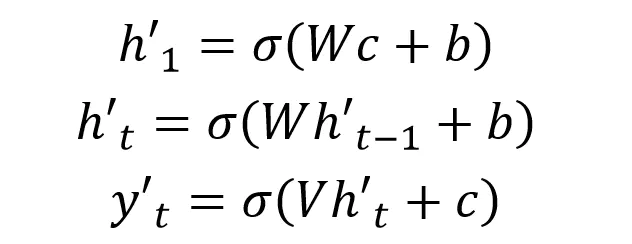
第二种 Decoder 结构有了自己的初始隐藏层状态 h'0,不再把上下文向量 c 当成是 RNN 的初始隐藏状态,而是当成 RNN 每一个神经元的输入。可以看到在 Decoder 的每一个神经元都拥有相同的输入 c。
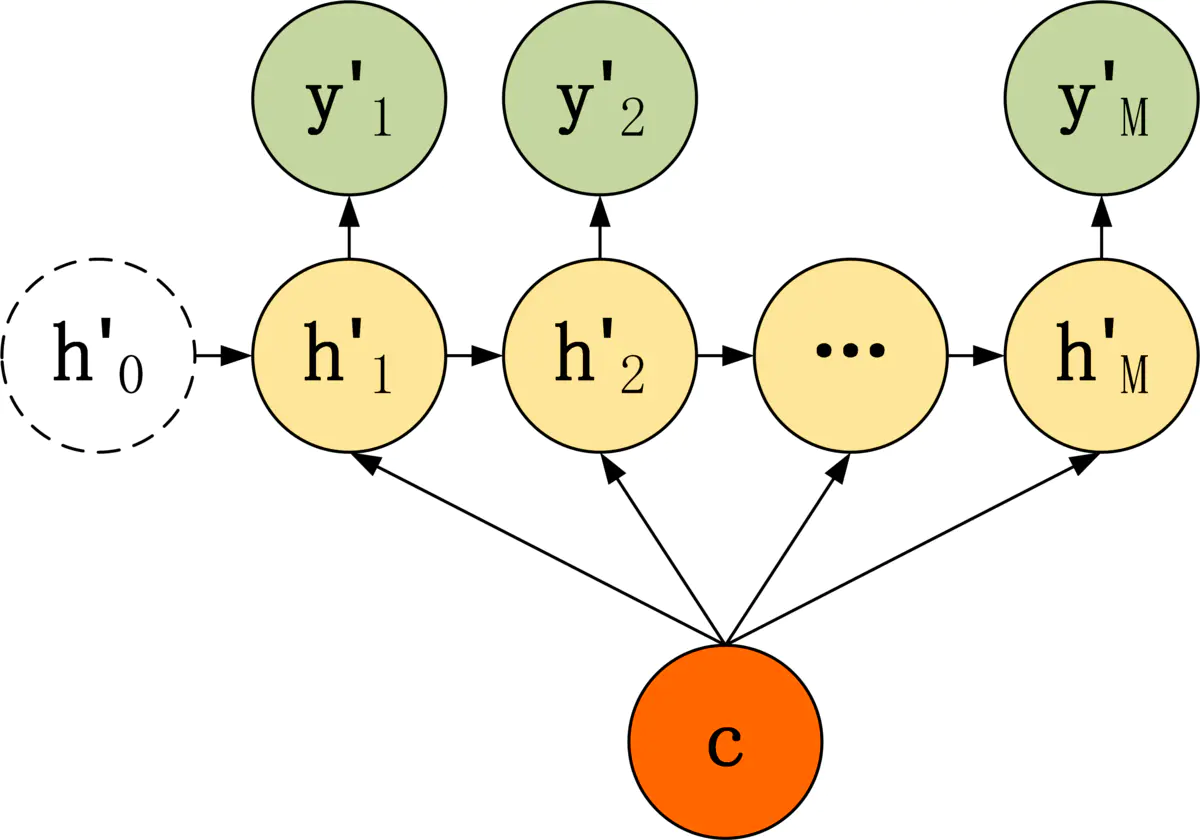
这种 Decoder 的隐藏层及输出计算公式:
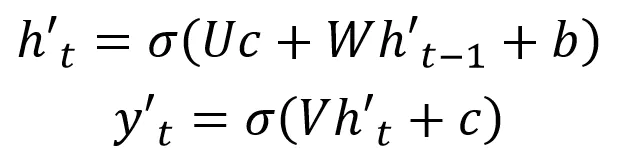
2014 年,RNN-seq2seq
2014 年,Google 在论文《Sequence to Sequence Learning with Neural Networks》也提出了基于 RNN 的 Seq2Seq(Sequence to Sequence,序列到序列)方法,可以实现从一个源序列生成一个目标序列的操作,主要应用在机器翻译领域。由此,深度学习开始在机器翻译领域发挥作用,同时掀起了 NLP(自然语言处理领域)的深度学习浪潮。
Transformer 出现之前,处理文本序列信息主要依靠的是 RNN 和 LSTM 模型。但 RNN 及 LSTM 虽然具有捕捉时序信息、适合序列生成的优点,却有两个难以弥补的缺陷:
- 无法并行化:序列依序计算的模式能够很好地模拟时序信息,但限制了计算机并行计算的能力。由于序列需要依次输入、依序计算,GPU 并行计算的能力受到了极大限制,导致 RNN 为基础架构的模型虽然参数量不算特别大,但计算时间成本却很高;
- 超长距离依赖问题:在 RNN 架构中,距离越远的输入之间的关系就越难被捕捉,同时 RNN 需要将整个序列读入内存依次计算,也限制了序列的长度。第一个词的隐藏状态信息在经过几十个甚至几百个时间步的传递后,会逐渐衰减甚至丢失。虽然 LSTM 中通过门机制对此进行了一定优化,但对于较远距离相关关系的捕捉,RNN 依旧是不如人意的。
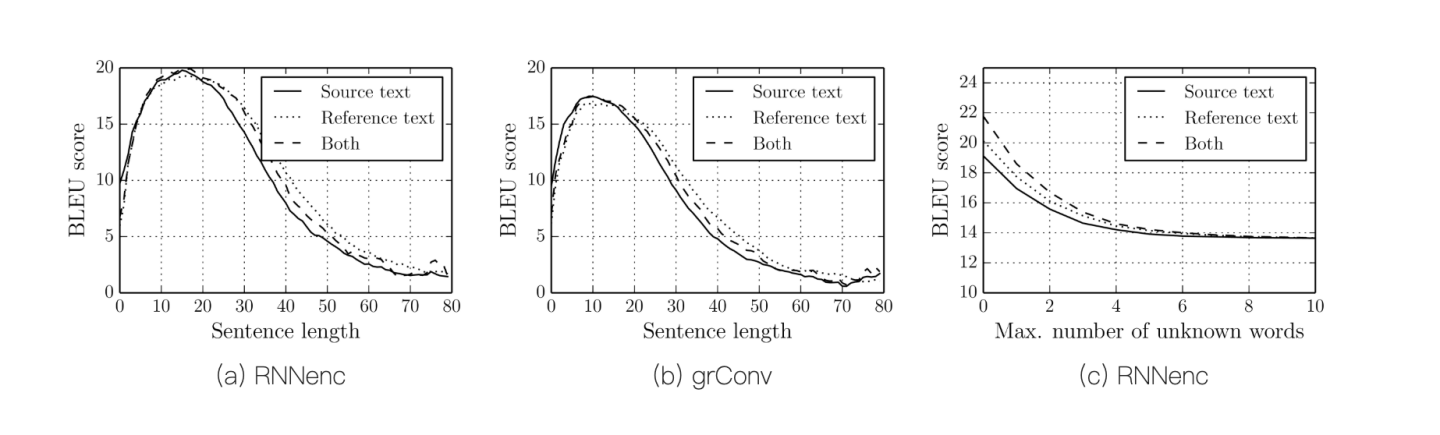
如下图所示,BLEU(Bilingual Evaluation Understudy)是一种自动评价机器翻译质量的指标,得分一般在 0~100 之间。得分越高,表示机器翻译结果与参考翻译越接近,质量越好。可见 RNN 随着 Sentence Length 的加大而减分。