一、什么是大语言模型(LLM)
1.1 大语言模型的基本定义
近年来,"大语言模型(Large Language Model,LLM)"成为人工智能领域中出现频率最高的关键词之一。
从技术角度看,LLM 通常指参数规模达到数百亿甚至更高数量级的语言模型。它们在海量文本数据上进行训练,通过学习词与词之间的统计规律、上下文依赖关系以及隐含的语义结构,从而具备理解和生成自然语言的能力。
与早期语言模型相比,LLM 的"大 "并不仅仅体现在参数数量上,更体现在模型能力的整体跃迁:当模型规模跨过某个临界点后,其表现不再是线性变好,而是出现了能力层面的质变。
目前,国外具有代表性的 LLM 包括 GPT、LLaMA、Gemini、Claude 和 Grok;国内则有 DeepSeek、通义千问、文心一言、Kimi、GLM、豆包等模型体系。尽管这些模型在工程实现和训练策略上各有差异,但它们背后遵循的是一套相对统一的技术范式。
1.2 从"小模型"到"大模型":能力为何会发生断层?
如果只看模型结构,大语言模型与早期模型并没有本质差异。
例如,拥有 15 亿参数的 GPT-2 与 1750 亿参数的 GPT-3 在架构设计和训练目标上高度相似,二者都属于自回归 Transformer 语言模型。然而,在实际使用中,两者的能力差距却异常明显。
GPT-2 几乎无法在不微调的情况下完成新任务;而 GPT-3 却可以仅通过提示词和少量示例 ,在翻译、分类、推理等任务上给出合理结果。这种"只靠上下文就能学会新任务 "的能力,被称为少样本学习(Few-shot Learning)或上下文学习(In-context Learning)。
这种能力的出现,并非来自新的模块或算法,而是随着模型规模扩大而自然"浮现"出来的,因此被称为涌现能力(Emergent Abilities)。
这正是"大语言模型"之所以被单独划分为一类模型的核心原因。
1.3 ChatGPT:LLM 走向大众的转折点
LLM 的这些能力,真正被大规模验证和感知,是从 ChatGPT 开始的。
从技术角度看,ChatGPT 并不是一种全新的模型结构,而是基于 GPT 系列大语言模型,通过指令微调与人类反馈强化学习(RLHF)对齐得到的对话系统。
但从应用角度看,它第一次让普通用户直观地感受到:一个语言模型,可以作为通用的人机交互接口存在。
这也直接推动了 LLM 从"研究模型"走向"平台级基础设施"。
-
下图展示了自 2018 年以来语言模型相关研究的增长趋势:
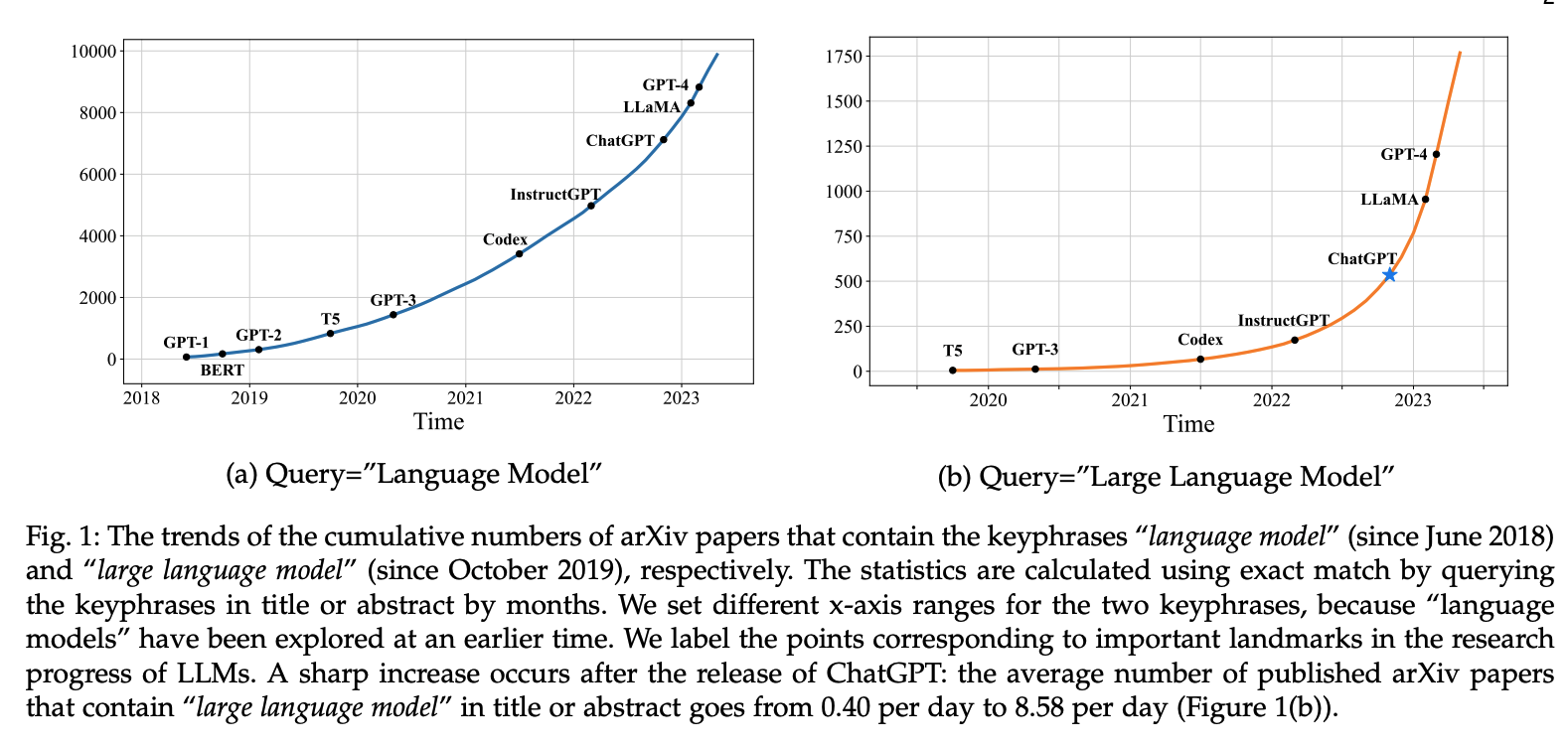
可以看出,包含关键词"language model"(自 2018 年 6 月起)和"large language model"(自 2019 年 10 月起)的 arXiv 论文累计数量在chartgpt发布后显著上升。
二、语言模型的发展历程:从统计方法到通用模型
语言模型相关研究按其发展历程可分为四个主要阶段:
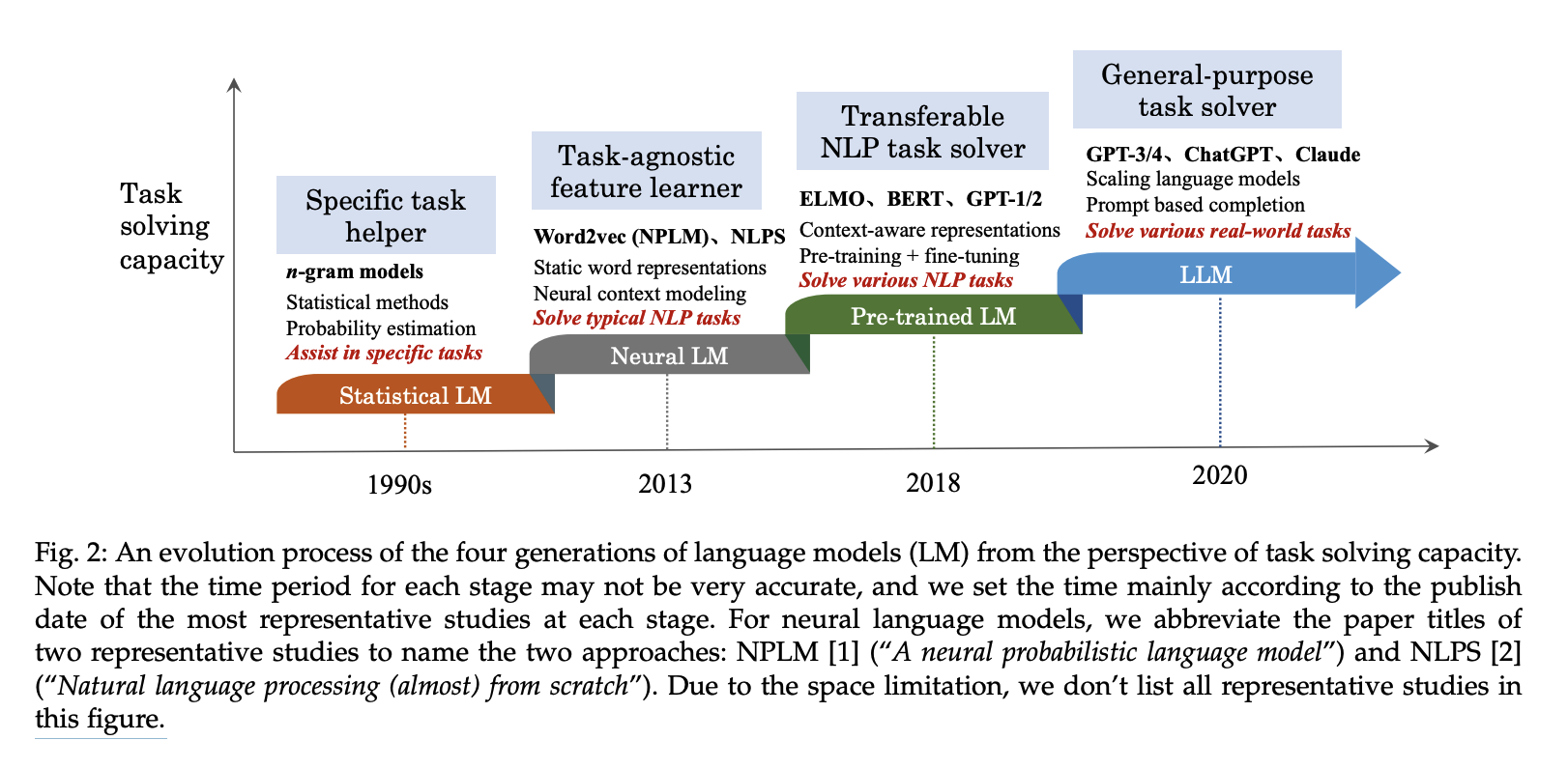
-
最初,统计语言模型主要辅助某些特定任务(例如检索或语音任务),其中预测或估计的概率可以增强特定任务方法的性能。
-
随后,神经语言模型专注于学习与任务无关的表征(例如特征),旨在减少人工特征工程的工作量。
-
此外,预训练的语言模型学习了上下文感知的表示,这些表示可以根据下游任务进行优化。
-
最新一代语言模型通过探索扩展对模型容量的影响来增强LLM,LLM可以被视为通用的任务求解器。
总而言之,在演化过程中,语言模型能够解决的任务范围得到了极大的扩展,其任务性能也得到了显著提升。
2.1 统计语言模型SLM:语言建模的起点
statistical language model
-
时间:语言模型的研究最早可以追溯到 20 世纪 90 年代。
-
核心思路:非常直接,通过统计词序列在语料中的出现频率,来预测下一个词。
这类方法通常基于马尔可夫假设 ,即假设一个词只依赖于前面有限数量的词。在固定上下文长度为n−1n-1n−1的情况下,模型被称为 n-gram 语言模型,其中二元语法(bigram)和三元语法(trigram)最为常见。
-
特点:
统计语言模型在早期的语音识别、机器翻译和信息检索任务中发挥了重要作用,但它们存在两个难以回避的问题:
- 无法建模长距离依赖
- 高阶模型面临严重的数据稀疏与维数灾难(由于需要估计大量的转移概率,高阶语言模型难以精确建模)
尽管研究者提出了诸如 Back-off、Good-Turing 等平滑方法来缓解这些问题,但统计模型在语义建模上的能力始终有限。这些方法在一定程度上提升了模型的泛化能力,但仍**无法捕捉语言中的长距离依赖与深层语义关系**,为后续的**神经语言模型(Neural LM)**铺平了道路。
2.2 神经语言模型NLM:语言第一次开始理解语义
Neural Language Model
-
时间:真正的转折点出现在 2003 年。
Bengio 在论文《A Neural Probabilistic Language Model》中首次系统性地将神经网络引入语言建模任务,提出用连续向量空间中的分布式表示来建模词和上下文。
-
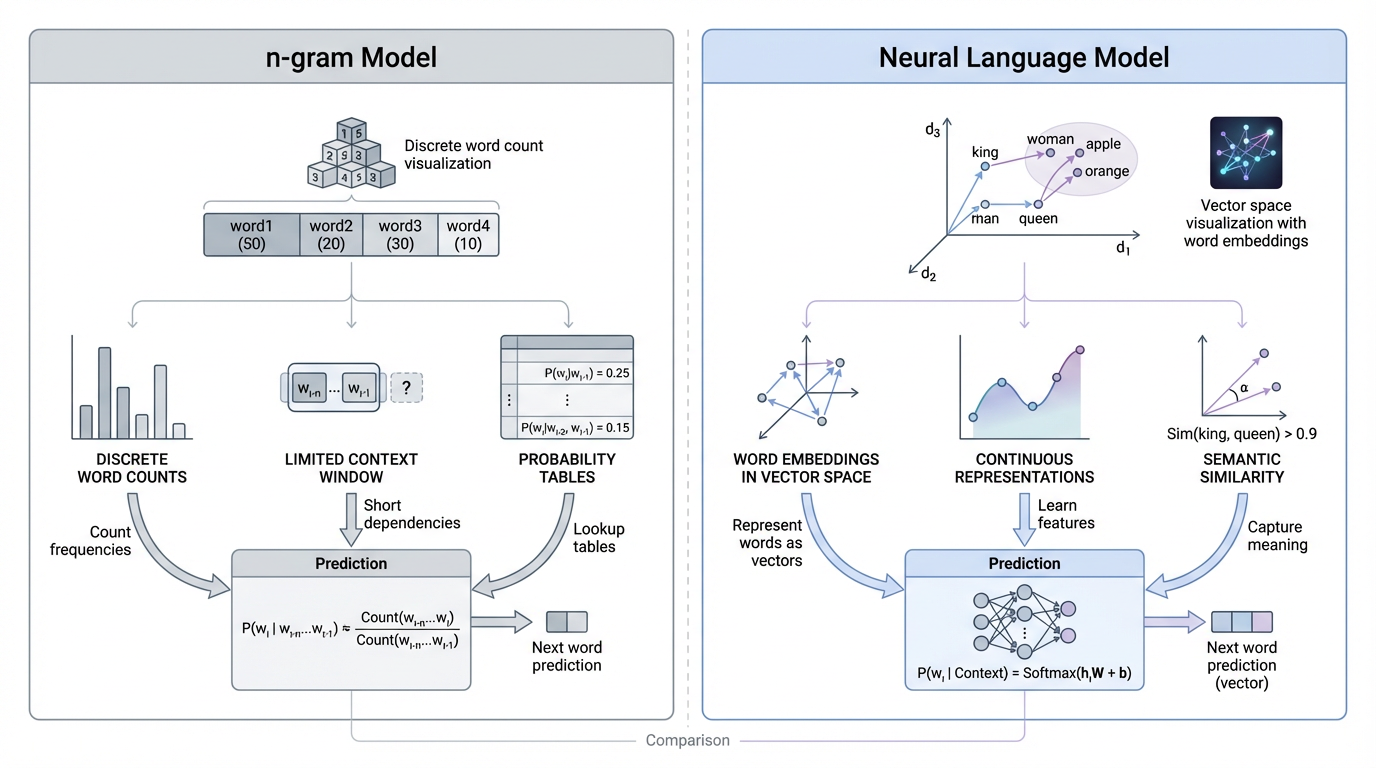
核心思想:
与统计模型不同,神经语言模型不再直接估计离散概率表,而是通过神经网络学习词向量,并在高维连续空间中捕捉语义关系。这一思想显著缓解了数据稀疏问题,也为后续模型的发展奠定了基础。
-
特点:使用神经网络(尤其 RNN/LSTM)对语言进行建模,能学习连续语义空间,减少稀疏问题,但训练困难、长文本建模差
-
里程碑研究:
2013 年,Mikolov 提出的 word2vec(CBOW 与 Skip-gram)进一步降低了词向量训练成本,使"词嵌入"成为 NLP 的标准配置。
这些研究工作开创了语言模型在语义表征学习(Representation Learning)领域的应用,使语言模型不再局限于词序列概率预测,而能够捕捉词汇间的深层语义关系 ,为后续的 Transformer 预训练语言模型(BERT、GPT 等) 奠定了理论与技术基础。
-
然而,受限于 RNN/LSTM 等结构,神经语言模型在长文本建模与并行计算方面仍然存在明显瓶颈。
2.3 预训练语言模型PLM:范式的改变
Pre-trained language model
-
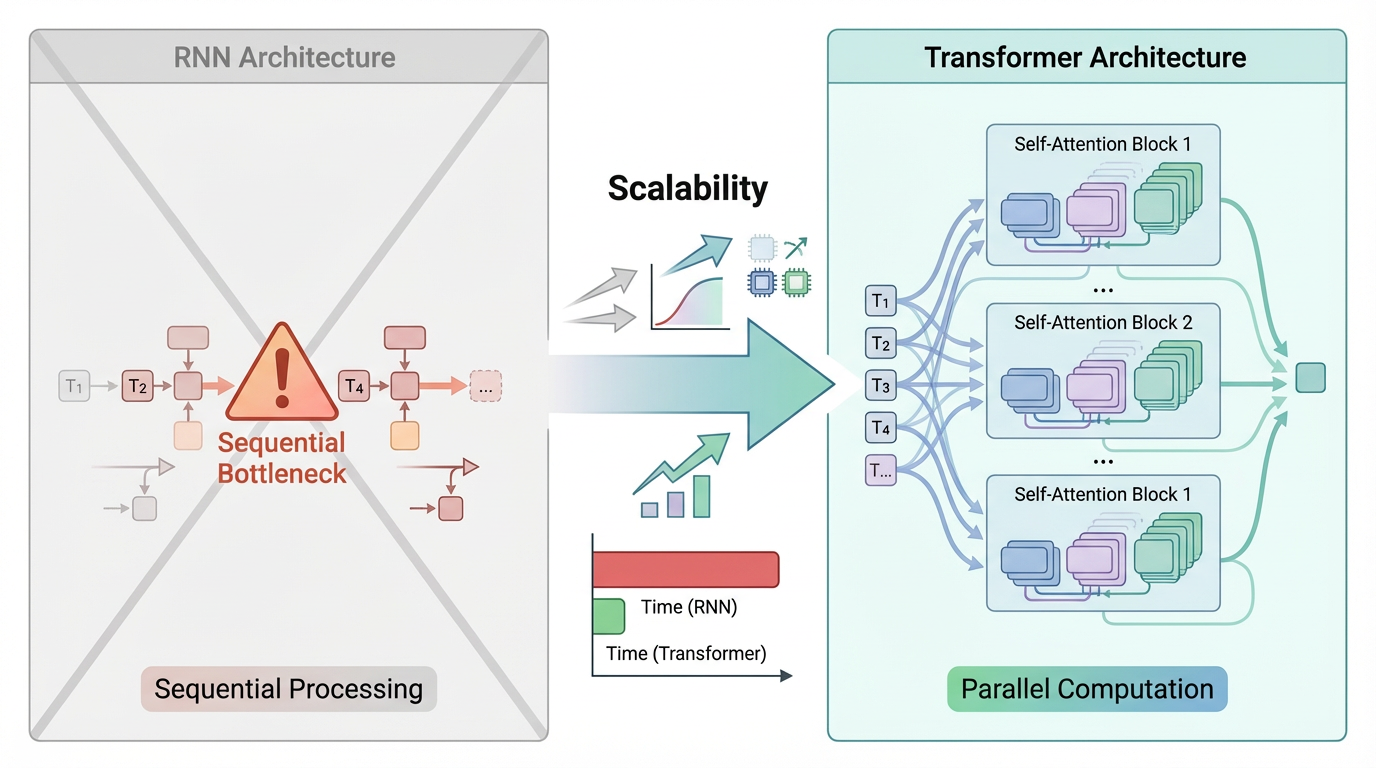
时间:2018 年,Transformer 架构的提出,彻底改变了语言模型的发展轨迹。
-
核心思想:
- 通过大规模无监督语料进行预训练(Pre-training),再针对特定任务进行微调(Fine-tuning),实现迁移学习。
- 基于自注意力机制,模型可以并行建模全局上下文,从而在效率和效果上同时取得突破。在此基础上,预训练 + 微调范式逐渐成为 NLP 的主流。
-
特点:使用 Transformer 结构,通过自监督学习进行大规模预训练
以 BERT 为代表的预训练语言模型,通过在大规模无标注语料上进行自监督学习,获得通用语言知识,再通过少量标注数据适配下游任务,使几乎所有 NLP 任务的性能都得到了显著提升。
BERT(2018)
随着 Transformer 架构 的出现,研究者提出了 BERT(Bidirectional Encoder Representations from Transformers),它采用了基于**自注意力机制(Self-Attention)**的双向语言建模方法,并在海量无标注语料上通过预训练任务(如 Masked LM、Next Sentence Prediction)学习语言规律。BERT 的出现使 NLP 各项任务性能全面刷新纪录。
-
但这一阶段的模型,本质上仍然是"任务适配器"(这类模型仍需针对每个下游任务进行微调,无法直接实现通用智能),距离真正的通用能力尚有距离。
2.4 大语言模型LLM:规模带来的质变
Large Language Models
当模型规模继续扩大时,研究者发现了一件重要的事情: 模型能力的提升,并非无限平滑,而是存在明显的跃迁区间。
GPT-3、PaLM 等模型的出现,系统性地验证了这一点。随着参数规模、训练数据和计算资源的同步增长,模型开始表现出复杂推理、跨任务迁移和通用生成能力。
-
核心思想 :**大规模参数 + 大规模数据 + 指令微调,出现"能力涌现"。**通过极大规模的模型参数与训练数据,挖掘语言建模的性能极限,涌现出通用智能与复杂推理能力。
-
特点:通用性强,具推理、生成、多模态等能力,是 AGI 的早期形态
-
代表模型:GPT-3, PaLM, LLaMA, Claude, Gemini 等
-
GPT-3(OpenAI, 2020)
-
拥有 1750 亿参数(175B),在架构与任务上与 GPT-2 类似,但性能表现出现质变;
首次展示了强大的 少样本学习(Few-shot Learning) 与 上下文学习(In-context Learning) 能力。例如,GPT-3 能通过输入示例理解任务模式,而 GPT-2 无法做到。
-
PaLM(Google, 2022)
参数规模达 5400 亿(540B) ,验证了 Scaling Law(扩展规律) 在超大模型下依旧成立;具备跨任务、跨语言的强泛化能力。
-
这些现象表明:随着模型规模的增加(即使架构与任务相似),模型会出现全新的认知与推理行为。
-
-
代表性应用:ChatGPT
LLM 的一个重要应用是 ChatGPT ------ 基于 GPT 系列 LLM 的对话式系统。ChatGPT 展现出流畅的语言生成与上下文理解能力,能够进行开放式交互和知识问答, 标志着 LLM 从通用语言建模迈向**自然人机对话与通用智能(AGI)**的阶段性突破。
-
大语言模型由此不再只是"更强的预训练模型",而逐渐演化为通用任务求解器。
三、Scaling Law:为什么模型越大越强
3.1 Scaling Law:为什么规模本身会变成一种能力
Scaling Law 指的是:在模型架构基本不变的前提下,模型性能会随着参数规模、数据规模和计算量的增加而呈现可预测的提升趋势。
这一规律为"大模型路线"提供了坚实的经验基础。
3.2 LLM中的体现
在大语言模型中,Scaling Law 表现为:
-
模型参数增加 → 性能提升
例如,GPT-3(1750 亿参数)比 GPT-2(15 亿参数)在复杂任务上表现更好
-
训练数据增加 → 泛化能力提升
更多文本让模型理解语言的能力更深、更广
-
计算量增加 → 整体性能提升
更长的训练时间和更多算力可以显著提升模型在各种任务中的表现
3.3 从预训练到推理阶段的 Scaling Law
通常大模型由三个阶段构成:预训练、后训练和在线推理。
-
在 2024 年 9 月之前,大模型领域仅存在预训练阶段的 Scaling Law:模型越大、数据越多,语言建模误差越低。
-
然而,随着 OpenAI o1 的推出,后训练和在线推理阶段也各自拥有了 Scaling Law,即后训练阶段的强化学习 Scaling Law(RL Scaling Law)和在线推理阶段的 Inference Scaling Law(Test Time Scaling Law)。 随着各阶段计算量的增加,大模型的性能不断增长。
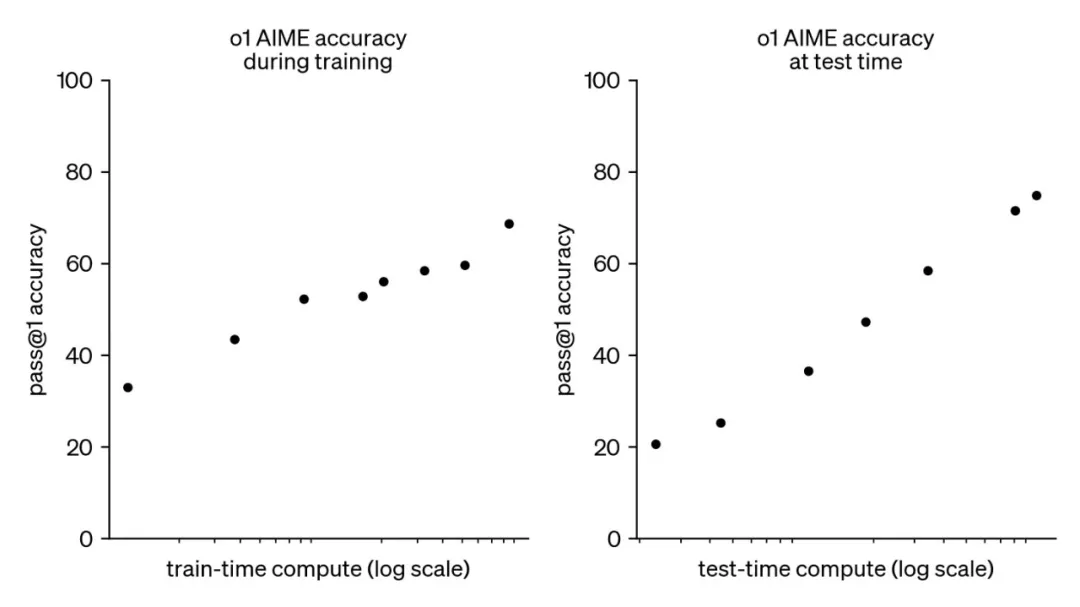
-
这意味着,Scaling Law 已不再局限于"训练阶段",而是贯穿了 LLM 的完整生命周期。
- 预训练阶段(Pre-training Scaling Law):模型在大规模文本上预训练时,性能随模型和数据增加而提升
- 后训练阶段(Fine-tuning / RL Scaling Law):经过强化学习或微调后,性能随计算量增加也有规律性提升
- 在线推理阶段(Inference / Test Time Scaling Law):即使在推理阶段,增加上下文长度或计算资源,也能带来性能提升
-
这也意味着,大模型能力的提升,已经不再完全依赖"再训练一个更大的模型",而开始向训练后与推理阶段扩展。
四、大语言模型的影响与意义
大语言模型正在重塑整个人工智能技术栈。
在 NLP 领域,它们从根本上改变了"为任务设计模型"的传统范式;在更广泛的 AI 系统中,LLM 正逐渐成为连接感知、推理与决策的中枢模块。
更重要的是,LLM 的出现,使"通用人工智能(AGI)"不再只是哲学讨论,而成为可以持续逼近的工程目标。
从这个意义上说,大语言模型并非终点,但它们很可能是通往通用智能道路上的第一个真正拐点。
五、总结:从语言模型到智能系统的分水岭
回顾语言模型的发展历程可以发现,大语言模型的出现并不是某一次结构创新带来的突变,而是在统一建模范式下,通过规模、数据与训练策略不断叠加后产生的阶段性结果 。从统计语言模型到神经语言模型,再到基于 Transformer 的预训练模型,模型"在做的事情"始终一致,但能学到的东西发生了质变。
这种质变并非线性提升,而是呈现出明显的跃迁特征。当参数规模、训练数据和优化目标同时扩展时,模型开始表现出跨任务泛化、上下文理解和指令遵循等能力,这些能力并非被显式编程,而是作为规模化学习的副产物自然涌现。Scaling Law 在这一过程中扮演的角色,并不是给出精确预测,而是将经验规律转化为可执行的工程路径。
也正因如此,当前阶段关于大语言模型的核心问题,已经不再只是"如何训练一个更大的模型",而是逐步转向如何对齐、如何控制、以及如何在推理阶段进一步释放模型能力。理解这一演化逻辑,有助于我们在面对新一代模型时,不被表象能力所迷惑,而能更清晰地判断其边界与潜力。