Day 1:快慢指针的原理
408 改卷中,线性表的大题往往要求 "时间复杂度 O(n)" 且 "空间复杂度 O(1)"。意味着都是原地解决问题。
1.0 标准静态分配定义
cpp
#define MaxSize 50
typedef struct{
int data[MaxSize]; //存放数据元素
int length; //当前长度
}SqList;注意:
它是
SqList(Sequence List),不是链表。数组下标从
0开始,长度是length,最后一个元素是data[length-1]。
2.0 顺序表的逆置
ps:两种写法都是原地逆置 (不需要额外开辟数组空间),时间复杂度都是 O(n)
题目:将顺序表 L {8,7,9,6,3}中的所有元素原地逆置。(这里的顺序表有分奇数和偶数)
考点:下标控制。
奇数或者偶数这么写行,他们的j指针指向不同。(双指针写法)
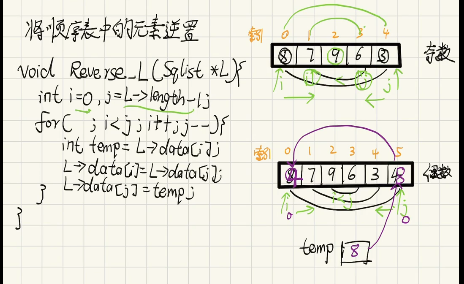
Reverse_L(SqList *L):操作顺序表 L 的逆置函数
同样支持奇数 / 偶数长度:条件就是 Length/2 一半
cpp
// 核心逻辑:首尾交换,向中间靠拢
void Reverse(SqList *L) {
int temp;
// i 控制前半段,L->length - 1 - i 是对应的后半段
for (int i = 0; i < L->length / 2; i++) {
temp = L->data[i];
L->data[i] = L->data[L->length - 1 - i];
L->data[L->length - 1 - i] = temp;
}
}易错点 :循环条件是
i < L->length / 2。如果写成< length,换完又换回去了,等于没变。
3.0 删除值为x的元素(区间)

这边我们心中必须要有抽象的数组画面:
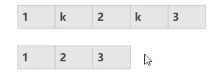
cpp
// 把 k 作为参数传入
void Function(Sqlist &L, int k)
{
int c=0;
for(int i=0; i<L.length; i++)
{
if(L.data[i] != k)
{
L.data[c++] = L.data[i];
}
}
L.length = c;
}这里定义的c实际上就好像拿一个 "空筐",挨个检查顺序表里的元素:是k就扔掉,不是k就放进筐里,放一个就把筐往后挪一位,最后告诉顺序表:"你的有效元素就只有筐里这些,数量是c"。
如果这里我想要;
题目:删除顺序表中值在给定值 s 与 t 之间(包含 s, t)的所有元素。
要求:s< t,若 s, t不合理或表空,显示出错信息。
思考 : 这道题和"删除 k"有区别吗? 本质完全一样! "删除 k"是把 != k的留下来。 "删除 s, t"是把 k < s || k > t 的留下来。
bash
// 删区间的完整函数(基于你的原代码修改)
void Function(Sqlist &L, int s, int t)
{
// 新增:合法性检查(题目要求)
if (L.length == 0) {
printf("错误:顺序表为空!\n");
return;
}
if (s >= t) {
printf("错误:区间不合法(s >= t)!\n");
return;
}
// 核心逻辑(仅改了if条件)
int c=0;
for(int i=0; i<L.length; i++)
{
// 原:if(L.data[i] != k)
// 改:保留不在[s,t]区间的元素
if(L.data[i] < s || L.data[i] > t)
{
L.data[c++] = L.data[i];
}
}
L.length = c;
}4.0 有序顺序表原地去重
题目 :从有序顺序表中删除所有重复的元素,使表中所有元素的值均不同。
难点解析:
因为是有序的,所以相同的元素一定挨在一起(如 1, 2, 2, 3)。
如果是无序表,O(n) 时间内无法原地去重(需要 Hash 表,空间 O(n)),所以考试通常考有序。
其实要我来看有序顺序表去重和之前的删除操作核心思路完全一致 ------ 都是用 "双指针筛选有效元素"
-
处理特殊情况 :如果顺序表为空(
L.length == 0)或只有 1 个元素(L.length == 1),直接返回(本身无重复); -
定义双指针:
-
j:记录已去重后的最后一个元素的下标(初始化为 0,因为第一个元素必然保留); -
i:遍历原顺序表的指针(从 1 开始,因为第 0 个元素已经在去重结果里);
-
-
筛选不重复元素 :遍历过程中,若
L.data[i] != L.data[j](当前元素和已保留的最后一个元素不重复),就把L.data[i]放到j+1的位置,然后j++(更新去重后的最后一个元素下标); -
更新顺序表长度 :遍历结束后,去重后的元素个数是
j+1(因为j是下标),所以L.length = j + 1。
代码实现(和之前删除逻辑的对比)
bash
void RemoveDuplicates(Sqlist &L) {
// 特殊情况:空表或只有1个元素,无需去重
if (L.length <= 1) return;
int j = 0; // 已去重的最后一个元素下标(初始保留第0个元素)
for (int i = 1; i < L.length; i++) {
// 筛选条件:当前元素 != 已保留的最后一个元素(因为有序,重复必连续)
if (L.data[i] != L.data[j]) {
L.data[++j] = L.data[i]; // 放到j的下一个位置,再更新j
}
}
L.length = j + 1; // 去重后的长度是j+1(下标j对应第j+1个元素)
}初始顺序表[1,2,2,3]
- 初始
L.length=4,j=0(保留第 0 个元素1),i从 1 开始遍历:
-
i=1,元素是 2 :对比
L.data[1]=2和L.data[j=0]=1→ 不重复,执行L.data[++j] = 2(j 变成 1),数组变成[1,2,2,3](无变化); -
i=2,元素是 2 :对比
L.data[2]=2和L.data[j=1]=2→ 重复,不操作; -
i=3,元素是 3 :对比
L.data[3]=3和L.data[j=1]=2→ 不重复,执行L.data[++j] = 3(j 变成 2),数组变成[1,2,3,3];
遍历结束后,j=2,所以去重后的长度是j+1=3,最终有效元素就是前 3 个:[1,2,3]