前言
昨天,给小伙伴们介绍了一下如何下载ollama和具体的命令有哪些,也告诉了大家下载模型的具体方法,今天就给大家介绍一下如何简单的构建一个聊天智能体,前端页面咱们就暂时模拟一下,后端咱们就可以正常和大模型交流,我们开始启程!
一、前期准备
今天,而我们就要利用以下两个库完成机器人的制作。先来简单说一下,它们都有哪些作用。
1.1 Streamlit和ollama的介绍
Streamlit是面向数据科学和机器学习开发者的轻量级Python Web框架,无需前端开发知识即可快速搭建交互式Web应用,支持热重载和丰富的交互组件,适合快速实现数据成果、AI应用原型的可视化演示。
ollama是Ollama工具的官方Python客户端,核心用于调用本地部署的大语言模型(如Llama 3、Phi 3等),可完成模型拉取、管理及单/多轮对话交互,无需联网调用第三方API,能保障数据隐私,常与Streamlit结合搭建本地化AI Web应用。
1.2 安装步骤
1. 前置准备:
确保PyCharm已配置好Python解释器和环境(建议conda环境,我之前的博客分享过详细的步骤和注意事项);
安装ollama Python库前,需先从https://ollama.com/download下载对应系统的**Ollama客户端并完成安装**,安装后默认自动启动本地Ollama服务。
2. 安装方式一:
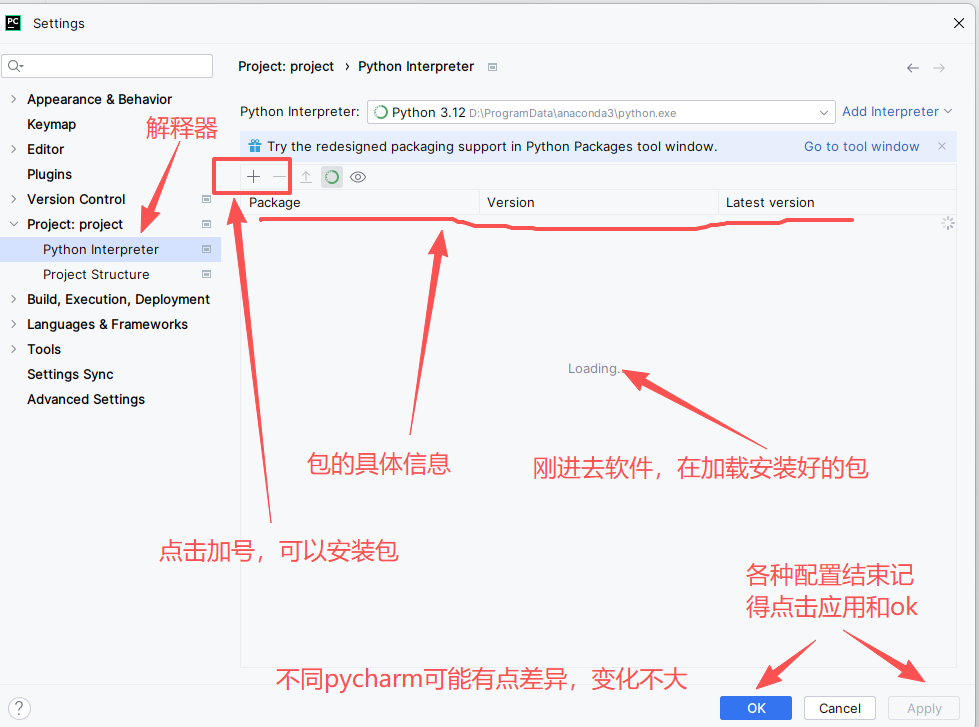
打开PyCharm项目,依次进入File(右上角)→ Settings → Project: 项目名 → Python Interpreter」,点击右侧「+」号,在搜索框分别输入streamlit、ollama,选中对应结果后点击「Install Package」,等待安装完成即可。

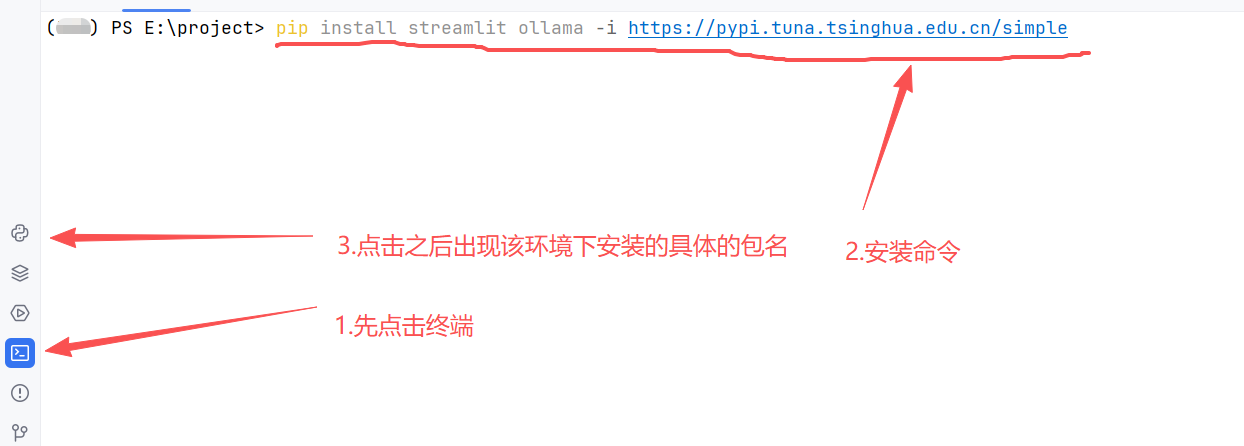
3. 安装方式二(终端):
打开PyCharm底部的Terminal终端,执行命令 pip install streamlit ollama**-i https://pypi.tuna.tsinghua.edu.cn/simple(加粗的是镜像源,加快下载速度,也可以不加)**,安装完成后可通过以下命令验证ollama。
python
import ollama
print(ollama.__version__)安装步骤:
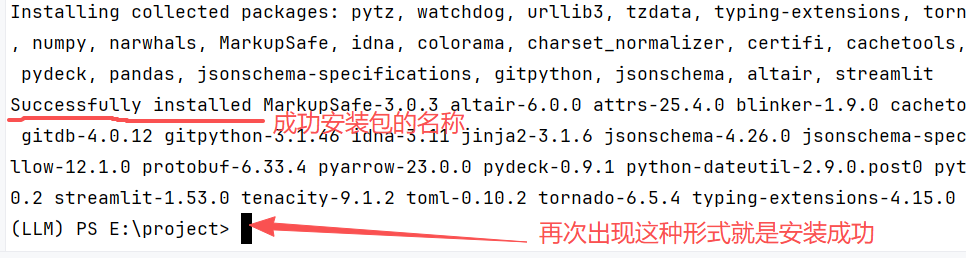
注意: 镜像源并不是一定要配置的,因为默认pip安装库都是从国外服务器下载,导致非常慢,所以需要改为从国内镜像源下载,毕竟,大家也清楚有时候下载国外的数据需要科学上网。所以更换国内的镜像源,可以加快下载速度,图中用的是清华的镜像源。
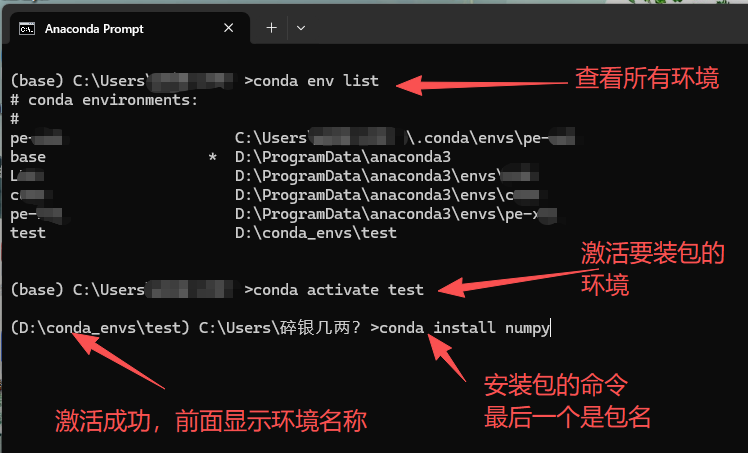
3. 安装方式三(conda)推荐:
利用conda安装包我们之前在环境配置里面详细讲解过,所以我这里就简单说一下,conda安装包比较稳定,不建议conda和pip混合使用。
二、前端页面制作
2.1 AI工具创作前端页面(后面会专门介绍)
介绍一款国内的免费AI代码写作助手---Trae
官网链接: Trae
Trae是字节跳动推出的AI原生IDE,深度集成大模型,专为提升开发效率而生,尤其适合前端页面创作。
核心能力包括:用自然语言描述需求即可生成HTML/CSS/JS及React/Vue组件;支持Figma设计稿一键转像素级还原的响应式页面;内置实时预览与热重载,边改边看交互效果。它对中文指令有深度优化,能自动补全代码、修复Bug并添加注释,显著降低前端开发门槛,让零基础也能快速产出专业页面。
特别适合零基础小白创作代码,使用简单,想要尝试的小伙伴可以试试,后面我会专门讲解,今天咱们主要利用第二种方式完成前端页面。
2.2 streamlit创作前端代码
官网地址: https://streamlit.io
前面介绍了,我就不再次重复了。
2.2.1 登录页面代码展示
基于我们刚开始学习python,并且今天只是体验一下具体的效果,所以我就不讲解知识点了,大家可以通过注释学习,复制代码或者模仿代码自己试试。相关的知识点后续都会系统性的分享。
python
import streamlit as st
from datetime import date
import pandas as pd
# 记得安装pandas,终端执行:pip install pandas
# 页面基础配置
st.set_page_config(page_title="AI机器人", page_icon="🤖", layout="centered")
# 全局存储用户提交的信息(实际场景建议用数据库,此处用列表临时存储)
if "user_submissions" not in st.session_state:
st.session_state.user_submissions = []
# 页面标题与样式优化
st.title("🤖 AI机器人 ")
st.divider()
# 表单容器(优化布局结构)
with st.form(key="ai_robot_user_form", clear_on_submit=True):
# 用户名输入(必填,限制长度1-50字符)
username = st.text_input(
label="用户名",
max_chars=50,
key="username",
placeholder="请输入1-50位用户名"
)
# 密码输入(必填,限制长度6-50字符)
password = st.text_input(
label="密码",
type="password",
max_chars=50,
key="password",
placeholder="请输入6-50位密码"
)
# 密码确认(避免输入错误)
confirm_password = st.text_input(
label="确认密码",
type="password",
max_chars=50,
key="confirm_password",
placeholder="请再次输入密码"
)
# 年龄输入(合理范围1-120岁,默认值18)
age = st.number_input(
label="年龄",
min_value=1,
max_value=120,
step=1,
value=18,
key="age"
)
# 性别选择(必选,去除不合理选项,默认提示选择)
gender = st.selectbox(
label="性别",
options=["请选择", "男", "女", "其他"],
index=0,
key="gender"
)
# 是否已婚单选框(保存选择结果,横向布局更紧凑)
married = st.radio(
label="是否已婚",
options=["是", "否"],
horizontal=True,
key="married",
index=1 # 默认选择"否"
)
# 出生日期选择器(合理时间范围,默认当前日期前20年)
default_birthdate = date(date.today().year - 20, date.today().month, date.today().day)
birthdate = st.date_input(
label="出生日期",
min_value=date(1900, 1, 1),
max_value=date.today(),
value=default_birthdate,
key="birthdate"
)
# 身高滑块(单位cm,默认175cm,优化步长)
height = st.slider(
label="身高 (cm)",
min_value=80.0,
max_value=220.0,
value=175.0,
step=0.5,
key="height"
)
# 提交按钮
submit_button = st.form_submit_button(label="🤖 提交信息", type="primary")
# 表单提交逻辑处理
if submit_button:
# 表单验证:检查必填项是否为空
if not username or not password or not confirm_password or gender == "请选择":
st.error("❌ 请完善所有必填项(用户名、密码、确认密码、性别不能为空)!")
# 验证密码一致性
elif password != confirm_password:
st.error("❌ 两次输入的密码不一致,请重新输入!")
# 验证密码长度
elif len(password) < 6:
st.error("❌ 密码长度不能少于6位,请修改!")
else:
# 整理用户提交信息
user_info = {
"用户名": username,
"年龄": age,
"性别": gender,
"是否已婚": married,
"出生日期": birthdate.strftime("%Y-%m-%d"),
"身高(cm)": height
}
# 存储用户信息(实际场景替换为数据库写入)
st.session_state.user_submissions.append(user_info)
# 页面显示提交成功信息
st.success("🎉 信息提交成功!AI机器人已记录您的信息:")
with st.expander("查看提交信息", expanded=True):
for key, value in user_info.items():
st.write(f"**{key}**:{value}")
# 终端打印日志(仅开发调试用)
print(f"\n【AI机器人 - 信息提交成功】\n用户名:{username}\n年龄:{age}\n性别:{gender}\n"
f"是否已婚:{married}\n出生日期:{birthdate}\n身高:{height}cm")
# 可选:添加已提交信息用户查看功能
with st.sidebar:
st.subheader("📊 已提交信息用户")
if st.session_state.user_submissions:
df = pd.DataFrame(st.session_state.user_submissions)
st.dataframe(df, use_container_width=True)
else:
st.text("暂无用户提交信息")运行:需要在终端运行
python
#建议路径使用绝对路径,相对路径也行
streamlit run E:\project\test_博客\test.py运行结果:
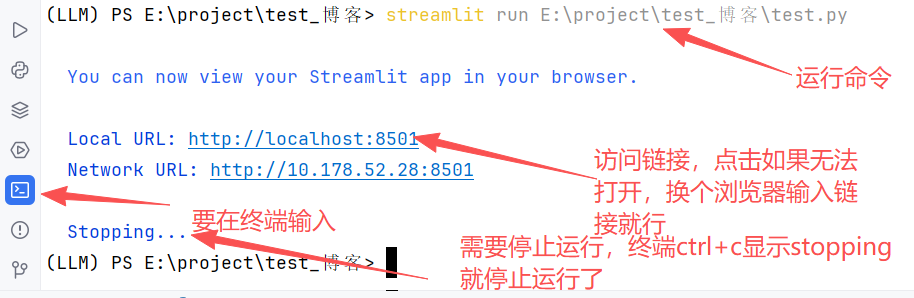
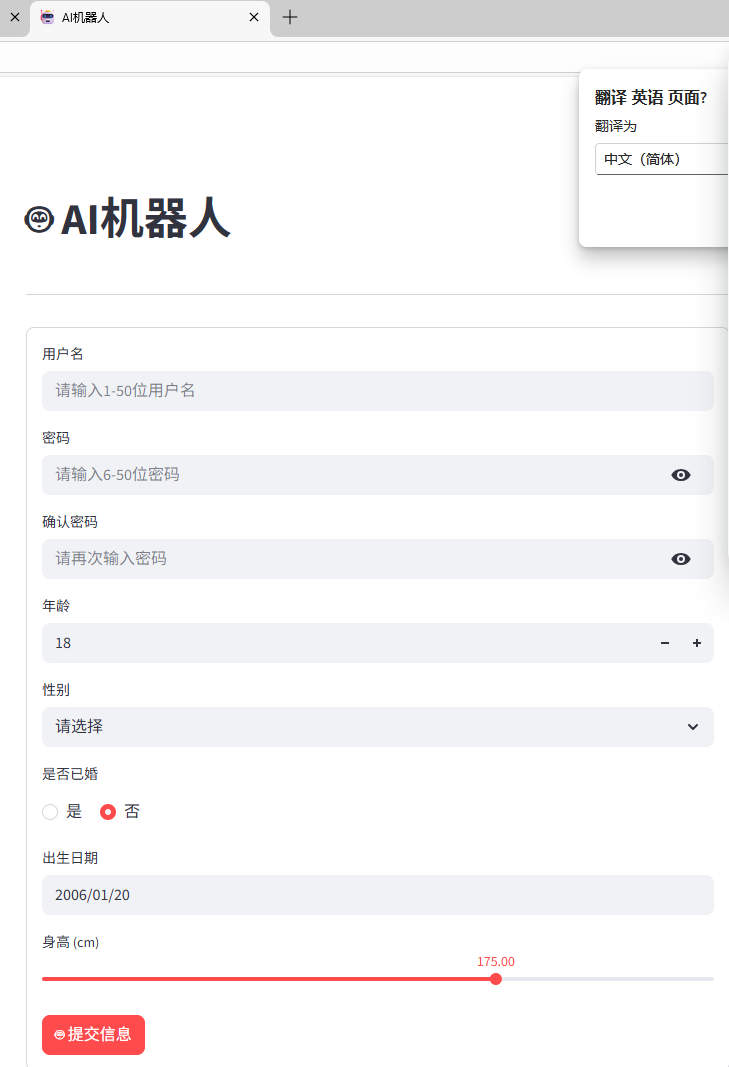
2.2.2 聊天机器人页面构建
前面登录页面已经实现了,现在我们来构建基础的聊天页面
注意:为了简化操作,因为好多知识点还没分享,下面的内容只是模拟AI和用户的会话,后面会系统性的分享具体的大模型部署操作。
python
# 导入Streamlit库,用于快速构建交互式Web应用
import streamlit as st
# 设置网页应用的主标题,展示机器人名称
st.title("AI智能机器人")
# 添加水平分隔线,分割标题与聊天区域,优化界面视觉结构
st.divider()
# 初始化助手(AI)的首次消息,提升用户首次进入的交互体验
st.chat_message("assistant").write("你好,我是AI智能机器人,请问有什么可以帮你的?")
# 创建聊天输入框,提示用户输入问题,输入内容会赋值给prompt变量
prompt = st.chat_input('请您输入您的问题:')
# 模拟用户发送消息(TODO:后续替换为从prompt变量获取用户真实输入内容)
st.chat_message("user").write('你好')
# 模拟AI回复消息(TODO:后续替换为调用大语言模型API获取的真实回答内容)
st.chat_message("assistant").write('你好,很高兴与你聊天!')运行命令:
python
streamlit run E:\project\test_博客\chat_web.py效果:
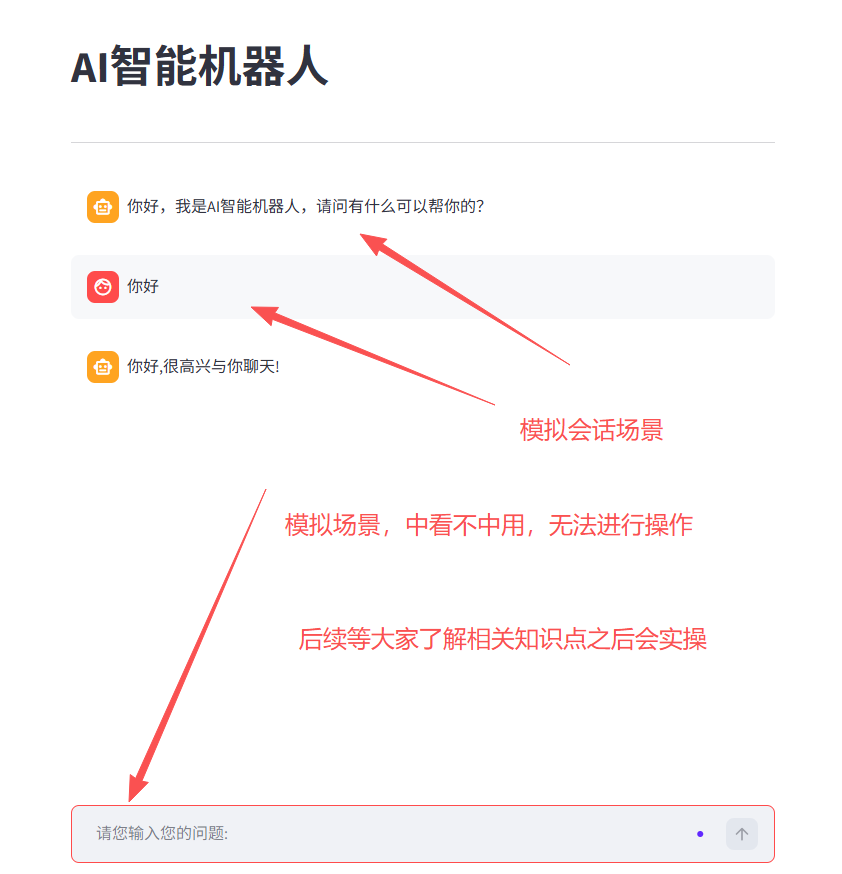
三、后端python代码
代码:一定要记得把里面的模型改为自己本地下载好的模型名称,ollama list查看自己的模型,没有的话下载一个,建议5b以内。
python
# 1. 导入ollama库(需提前安装:pip install ollama)
import ollama
# 2. 初始化Ollama客户端(
ollama_client = ollama.Client(host="http://127.0.0.1:11434")
# 3. 初始化历史对话列表,核心:保存所有轮次的用户/助手消息,实现上下文记忆。
chat_history = []
# 4. 定义多轮对话主循环
def multi_turn_chat():
print("===== AI多轮对话助手 =====")
print("输入 'quit' 或 'exit' 可退出对话\n")
while True:
# 4.1 获取用户输入,支持多轮连续提问
user_input = input("你: ")
# 4.2 退出条件:输入quit/exit则终止循环
if user_input.strip().lower() in ["quit", "exit"]:
print("AI: 再见!有问题随时再来~")
break
# 4.3 空输入处理:避免传入空消息导致模型报错
if not user_input.strip():
print("AI: 你还没输入问题哦,请说点什么吧!")
continue
# 4.4 将当前用户输入加入历史对话列表
chat_history.append({"role": "user", "content": user_input})
try:
# 4.5 调用本地大模型,传入完整历史消息,实现上下文对话
response = ollama_client.chat(
model="qwen2.5:0.5b", # 替换为你本地部署的模型名(如llama3、gemma等)
messages=chat_history, # 核心:传入历史消息列表
stream=False # 非流式响应,直接获取完整回复
)
# 4.6 解析模型回复
ai_reply = response["message"]["content"]
# 4.7 将AI回复加入历史对话列表(供下一轮上下文使用)
chat_history.append({"role": "assistant", "content": ai_reply})
# 4.8 打印AI回复
print(f"AI: {ai_reply}\n")
except Exception as e:
# 异常处理:捕获网络/模型调用错误
print(f"AI: 抱歉,对话出错了!错误信息:{str(e)}\n")
# 出错时移除本次用户输入(避免历史消息污染)
chat_history.pop()
# 5. 启动多轮对话
if __name__ == "__main__":
# 先检查Ollama服务是否启动(可选:增强鲁棒性)
try:
ollama_client.list() # 调用list接口验证服务连通性
except:
print(" 未检测到Ollama本地服务!请先执行:ollama serve 启动服务,并确保已拉取模型(ollama pull qwen2.5:7b)")
else:
multi_turn_chat()具体效果展示:模型参数量越大效果越好,我用的qwen2.5:0.5b的模型,参数量越大,模型越大,都是GB起步,需要一定的电脑性能。

四、总结
今天,就让大家简单体验一下简单的大模型对话,大家可以试试不同的模型回复同一个问题,看看有哪些差别。后期大家都可以按照我的分享内容系统性学习,实现大模型部署,训练,微调等操作,可以利用深度学习,自己手搓一个属于自己的模型,感受一下未知的神秘知识。
上述内容会根据大家的评论和实际情况进行实时更新和改进。
麻烦小伙伴们动一动发财的小手,给小弟点个赞和收藏,如果能获得小伙伴的关注将是我无上的荣耀和前进的动力。
小伙伴们,我是AI大佬的小弟,希望大家喜欢!!!
晚安,兄弟们。