目录
第一部分:思想与基石------万法归宗,筑基问道
第1章:初探智慧之境------机器学习世界观
- 1.1 何为学习?从人类学习到机器智能
- 1.2 机器学习的"前世今生":一部思想与技术的演进史
- 1.3 为何是Python?------数据科学的"通用语"
- 1.4 破除迷思:AI是"神"还是"器"?
第2章:工欲善其事------Python环境与核心工具链
- 2.1 "乾坤在握":Anaconda与Jupyter Notebook的安装与配置
- 2.2 "数据之舟":NumPy数值计算基础
- 2.3 "数据之魂":Pandas数据分析利器
- 2.4 "眼见为实":Matplotlib与Seaborn数据可视化
第3章:数据的心法------预处理与特征工程
- 3.1 "相数据":理解你的数据
- 3.2 "净数据":数据清洗的修行
- 3.3 "点石成金":特征工程的科学与艺术
第4章:模型的罗盘------评估与选择
- 4.1 "度量衡":分类、回归与聚类模型的评估指标
- 4.2 "执其两端而用中":偏差与方差的权衡
- 4.3 "他山之石":交叉验证的智慧
- 4.4 "寻路":网格搜索与超参数调优
第二部分:术法万千------主流机器学习模型详解
第5章:监督学习之"判别"------分类算法
- 5.1 逻辑回归:看似回归,实为分类的智慧
- 5.2 K-近邻(KNN):"物以类聚,人以群分"的朴素哲学
- 5.3 支撑向量机(SVM):"一划开天"的数学之美
- 5.4 决策树与随机森林:"集思广益"的集成智慧
- 5.5 朴素贝叶斯:"执果索因"的概率思维
第6章:监督学习之"预测"------回归算法
- 6.1 线性回归:从简单到多元,探寻变量间的线性关系
- 6.2 岭回归与Lasso回归:正则化下的"中庸之道"
- 6.3 多项式回归:用曲线拟合复杂世界
- 6.4 回归树与集成回归模型(例如 GBDT, XGBoost)
第7章:无监督学习之"归纳"------聚类与降维
- 7.1 K-均值聚类(K-Means):寻找数据中的"引力中心"
- 7.2 层次聚类:构建数据的"家族谱系"
- 7.3 DBSCAN:基于密度的"社区发现"
- 7.4 主成分分析(PCA):在纷繁中见本质的降维之道
第8章:集成学习------从"三个臭皮匠"到"诸葛亮"
- 8.1 Bagging思想:随机森林的再思考
- 8.2 Boosting思想:从AdaBoost到梯度提升树(GBDT)
- 8.3 Stacking/Blending:模型的"圆桌会议"
- 8.4 XGBoost与LightGBM:工业界的"大杀器"详解
第9章:神经网络入门------通往深度学习的桥梁
- 9.1 从生物神经元到感知机模型
- 9.2 多层感知机(MLP)与反向传播算法
- 9.3 激活函数:为神经网络注入"灵魂"
- 9.4 使用Scikit-Learn与Keras/TensorFlow构建你的第一个神经网络
第三部分:登堂入室------高级专题与实战演练
第10章:实战项目一:金融风控------信用卡欺诈检测
- 10.1 问题定义与数据探索:理解不平衡数据
- 10.2 特征工程与采样技术(SMOTE)
- 10.3 模型选择、训练与评估
- 10.4 解释性分析:模型为何做出这样的决策? (SHAP/LIME)
第11章:实战项目二:自然语言处理------文本情感分析
- 11.1 文本数据的预处理:分词、停用词与向量化(TF-IDF, Word2Vec)
- 11.2 从传统模型到简单神经网络的情感分类
- 11.3 主题模型(LDA):挖掘文本背后的隐藏主题
第12章:模型部署与工程化------让模型"活"起来
- 12.1 模型持久化:序列化与保存
- 12.2 使用Flask/FastAPI构建API服务
- 12.3 Docker容器化:为模型打造一个"家"
- 12.4 MLOps初探:自动化、监控与再训练
第13章:超越经典------未来展望与进阶路径
- 13.1 深度学习概览:CNN、RNN的世界
- 13.2 强化学习:与环境交互的智能体
- 13.3 图神经网络、联邦学习等前沿简介
- 13.4 "知行合一":如何持续学习与成长
附录
- A. 数学基础回顾(线性代数、微积分、概率论核心概念)
- B. 常用工具与库速查手册
- C. 术语表(中英对照)
- D. 推荐阅读与资源列表
第一部分:思想与基石------万法归宗,筑基问道
核心目标: 建立学习者的宏观认知,不仅知其然,更要知其所以然。将机器学习置于科学、哲学乃至东方智慧的广阔背景下,培养学习者的"数据直觉"与"模型思维"。
第一章:初探智慧之境------机器学习世界观
- 1.1 何为学习?从人类学习到机器智能
- 1.2 机器学习的"前世今生":一部思想与技术的演进史
- 1.3 为何是Python?------数据科学的"通用语"
- 1.4 破除迷思:AI是"神"还是"器"?
欢迎您,未来的数据探索者。在您正式踏入这个由数据、算法与代码构成的迷人世界之前,我们希望与您一同稍作停留,登高望远。本章并非一本技术手册的常规开篇,它不急于展示纷繁的代码或深奥的公式。相反,它是一张地图,一幅星图,旨在为您建立一个宏大的时空坐标,让您清晰地看到"机器学习"这片新大陆在人类智慧版图中的位置。
我们将从最本源的问题开始:何为"学习"?我们将借助婴儿认知世界的过程,以及自然界演化的宏伟篇章,来类比机器学习的三种基本范式。随后,我们将穿越时空,回顾这段波澜壮阔的技术思想史,从图灵的深邃构想,到今日深度学习的璀璨成就,并向那些推动时代前行的巨匠们致敬。我们还将探讨为何Python能够成为这门"新学问"的通用语言,并深入其设计哲学与强大的生态系统。
最后,也是至关重要的一点,我们将共同思辨:人工智能究竟是无所不能的"神",还是我们手中强大的"器"?我们将直面其能力边界与深刻的伦理挑战,并提出一种"以出世之心,做入世之事"的从业心法。
这不仅是知识的铺陈,更是一场思想的洗礼。当您建立起这样的世界观后,未来学习道路上的每一个技术细节,都将不再是孤立的碎片,而是这幅宏大画卷中和谐的一部分。
现在,让我们一同启程!
1.1 何为学习?从人类学习到机器智能
"学习"一词,于我们而言再熟悉不过。从呱呱坠地到白发苍苍,我们的一生便是学习的一生。我们学习语言、学习骑车、学习一门手艺、学习与人相处。但我们是否曾静心深思,这个过程的本质是什么?
从信息论的角度看,学习是一个系统(如人类大脑)通过与环境的交互,获取信息并优化自身内部模型,以期在未来更好地完成特定任务或适应环境的过程。 这个定义中包含几个关键要素:系统、环境、交互、信息、模型优化、未来任务。这恰恰构成了机器学习的核心框架。机器,作为我们创造的"系统",通过我们提供的"数据"(源于环境的信息),进行"训练"(交互与模型优化),最终目的是为了在新的、未见过的数据上做出精准的"预测"或"决策"(完成未来任务)。
因此,理解机器学习的最佳途径,便是回溯我们自身最熟悉、最本源的学习过程。
1.1.1 婴儿如何认识世界?------类比监督、无监督、强化学习
想象一个婴儿,她/他认识世界的过程,正是机器学习三大范式最生动、最本源的体现。
1. 监督学习(Supervised Learning):有"标签"的教导
当父母指着一个红色的、圆圆的物体,对婴儿说:"宝宝,这是'苹果'。"然后又指着一个黄色的、弯弯的物体说:"这是'香蕉'。"这个过程在不断重复。每一次,婴儿都接收到两样东西:一个感官输入 (物体的形状、颜色、气味)和一个明确的标签(它的名字叫"苹果")。
- 感官输入 ,在机器学习中被称为"特征(Features)"。
- 明确的标签 ,被称为"标签(Label) "或"目标(Target)"。
婴儿的大脑在做什么?它在努力寻找"特征"与"标签"之间的关联。它会逐渐归纳出:"哦,红色的、圆形的、有特定香味的,很可能就是'苹果'。"当父母下次拿出一个新的、她从未见过的苹果时,她能够根据已经建立的内部模型,正确地识别出:"苹果!"
这就是监督学习的本质。我们为机器提供一大批已经"标注好"的数据(例如,一堆邮件,每封都标好了"是垃圾邮件"或"不是垃圾邮件";一堆房产数据,每套都标好了"最终成交价格"),然后让算法去寻找特征和标签之间的映射关系。算法学成之后,我们给它一封新的邮件,它就能判断是否为垃圾邮件;给它一套新的房产特征,它就能预测其可能的价格。
监督学习的核心在于"有答案的输入"。 它主要解决两类问题:
- 分类(Classification):预测一个离散的标签。例如,判断图片是猫还是狗,判断邮件是否为垃圾邮件。婴儿认识水果,就是一个分类任务。
- 回归(Regression):预测一个连续的数值。例如,预测明天的气温,预测房屋的价格。
2. 无监督学习(Unsupervised Learning):无言的探索
现在,想象一下,没有人明确告诉婴儿每样东西的名字。桌上放着一堆玩具:一些是积木(方的、硬的、彩色的),一些是毛绒娃娃(软的、形状不规则的),还有一些是塑料小球(圆的、光滑的)。
婴儿会做什么?她会自己去探索。她会发现,这些东西可以分成几堆。她可能会把所有硬邦邦、有棱有角的东西放在一起,把所有软绵绵的东西放在另一边,把所有能滚来滚去的东西归为一类。她并不知道这些类别叫"积木"、"娃娃"或"球",但她通过观察物体自身的特性,自发地完成了"聚类(Clustering)"。
这就是无监督学习的精髓。我们只给机器一堆数据,没有任何标签,然后让算法自己去发现数据中隐藏的结构、模式或关系。
无监督学习的核心在于"发现内在结构"。 它的典型应用包括:
- 聚类(Clustering):将相似的数据点分组。例如,根据用户的购买行为,将他们划分为不同的客户群体,以便进行精准营销。
- 降维(Dimensionality Reduction):在保留大部分信息的前提下,减少数据的特征数量。好比我们描述一个人,与其罗列上百个细节,不如抓住"高、瘦、戴眼镜"这几个核心特征,这便是降维的思想。
- 关联规则挖掘(Association Rule Mining):发现数据项之间的有趣关系。经典的"啤酒与尿布"的故事,就是通过挖掘购物篮数据发现,购买尿布的顾客很可能同时购买啤酒。
3. 强化学习(Reinforcement Learning):试错与奖惩
再来看婴儿学习走路的过程。这个过程没有人能给她一个明确的"标签"。没有一个"正确"的姿势可以一步到位地教会她。
她只能自己尝试。她试着晃晃悠悠地站起来,迈出一步,然后"啪"地摔倒了。这次尝试的结果是"摔倒",这是一个负向的反馈(惩罚) 。她的大脑接收到这个信号:"刚才那样做,结果不好。" 于是,她下次会微调自己的策略,可能身体更前倾一点,或者腿迈得小一点。某一次,她成功地走了两步而没有摔倒,内心充满了喜悦和成就感。这是一个正向的反馈(奖励)。她的大脑会记住:"这样做,结果是好的!"
通过无数次的"尝试-反馈-调整策略 "循环,她最终学会了如何平稳地行走。在这个过程中,她不是被动地接收知识,而是作为一个意识体/智能体 ,在与环境的互动中**** ,通过试错 ,来学习一套能让自己获得最大累积奖励的策略。
这就是强化学习。它与监督学习的关键区别在于,反馈信号不是一个正确的"标签",而是一个评价性的"奖励"或"惩罚"信号,并且这个信号往往是延迟的(摔倒是迈出那一步之后的结果)。
强化学习的核心在于"通过与环境交互学习最优策略"。 它的应用场景极具魅力:
- 游戏AI:AlphaGo击败人类顶尖棋手,其核心就是强化学习。它通过自我对弈,不断探索能赢得棋局的策略。
- 机器人控制:控制机械臂抓取物体,让无人机自主飞行。
- 资源调度:优化数据中心的能源消耗,智能调度城市交通信号灯。
小结:三种学习范式的关系
| 学习范式 | 数据形式 | 学习目标 | 核心思想 | 人类类比 |
|---|---|---|---|---|
| 监督学习 | (特征, 标签) | 学习从特征到标签的映射 | 有师指导,模仿范例 | 父母教婴儿识物 |
| 无监督学习 | 只有特征 | 发现数据内在的结构与模式 | 无师自通,归纳总结 | 婴儿自己给玩具分类 |
| 强化学习 | (状态, 动作, 奖励) | 学习在环境中最大化奖励的策略 | 实践出真知,趋利避害 | 婴儿学走路 |
这三种范式并非泾渭分明,现实世界的问题往往需要融合多种思想。例如,半监督学习(Semi-supervised Learning)就结合了监督和无监督学习,利用少量有标签数据和大量无标签数据进行学习。但理解这三大支柱,是理解整个机器学习大厦的基石。
1.1.2 道法自然:从自然界的演化看学习的本质
如果说婴儿学步是"个体学习"的缩影,那么地球生命长达数十亿年的演化史,则是"群体学习"最宏伟、最深刻的篇章。《道德经》有云:"人法地,地法天,天法道,道法自然。" 机器学习的许多深刻思想,尤其是那些被称为"遗传算法"、"进化策略"的分支,其灵感正是源于对自然演化这一"终极学习过程"的模拟。
1. 适应度函数(Fitness Function):环境的选择压力
在自然界,不存在一个绝对的"最优"生物。在冰河世纪,长毛象的厚皮毛是巨大的生存优势;而当气候变暖,这身皮毛反而成了累赘。环境,就是那个最终的"裁判",它通过生存和繁衍的压力,来"评估"每一个生物体对其的适应程度。这种适应程度,在进化计算中被称为适应度(Fitness)。一个物种能否将基因传递下去,取决于其适应度的高低。
这与机器学习中的损失函数(Loss Function) 或**目标函数(Objective Function)**异曲同工。我们定义一个函数来评估我们的模型"好不好"。例如,在预测房价时,损失函数可能就是"预测价与真实价的差距",差距越小,模型的"适应度"就越高。整个模型训练的过程,就是不断调整参数,以期在损失函数上取得最优值的过程,正如生物演化是在环境的适应度函数下,不断"优化"自身基因的过程。
2. 遗传与变异(Inheritance and Mutation):探索与利用的平衡
演化有两个核心驱动力:
-
遗传(Inheritance) :父母的优秀性状(高适应度的基因)通过繁殖传递给后代。这保证了已经获得的成功经验不会轻易丢失。在机器学习中,这类似于一种"利用(Exploitation)"策略------我们倾向于在当前已知效果好的模型参数附近进行微调,希望能获得更好的结果。
-
变异(Mutation) :基因在复制过程中会发生随机的、微小的错误,即基因突变。绝大多数突变是有害或无意义的,但极少数突变可能会带来意想不到的生存优势(例如,某种蛾子产生了更接近树皮的保护色)。这种不确定性,为物种提供了跳出局部最优、适应全新环境的可能性。这正是一种"探索(Exploration)"策略。
机器学习算法,尤其是强化学习和优化算法,也必须精妙地平衡"利用"与"探索"。如果一个算法只懂得"利用",它可能会很快陷入一个"局部最优解"(比如一个只会在家附近找食物的原始人,他可能永远发现不了远处食物更丰富的山谷)。如果一个算法只懂得"探索",它将永远在随机尝试,无法收敛到一个有效的解决方案。遗传算法通过模拟交叉、变异等操作,在解空间中进行高效的探索和利用,寻找问题的最优解。
3. 物竞天择(Natural Selection):迭代优化的过程
"物竞天择,适者生存。"这八个字精准地描述了演化的核心机制。每一代生物中,适应环境的个体有更大的概率存活下来并繁殖后代,不适应的个体则被淘汰。经过一代又一代的筛选,整个种群的基因库会朝着越来越适应环境的方向"进化"。
这不就是机器学习中**迭代优化(Iterative Optimization)**的过程吗?以梯度下降算法为例,我们从一组随机的初始参数开始,计算当前参数下的"损失"(不适应度),然后沿着能让损失下降最快的方向(梯度方向)微调参数。然后,在新的参数位置上,重复这个过程。一步一步,一次一次迭代,模型参数就像生物种群的基因一样,被不断"选择"和"优化",最终达到一个损失极小(适应度极高)的状态。
因此,当我们思考机器学习时,不妨将视野拉远。我们所做的,无非是借鉴了宇宙间最古老、最强大的学习法则------演化。我们创造的算法,是我们对"道法自然"的一次次笨拙而又充满敬意的模仿。理解了这一点,我们便能以更谦卑、更宏大的视角,看待我们即将学习的每一个模型和技术。
1.2 机器学习的"前世今生":一部思想与技术的演进史
任何一门学科的诞生,都不是一蹴而就的,它必然是思想的河流长期冲刷、积淀的结果。机器学习的发展史,更是一部交织着数学、计算机科学、神经科学、哲学乃至运筹学等多个领域的英雄史诗。了解这段历史,能让我们明白今日的技术从何而来,为何如此,以及未来可能走向何方。
1.2.1 从图灵的构想到今天的深度学习:关键里程碑
这段历史犹如一条奔腾的河流,有涓涓细流的源头,有波澜壮阔的转折,也有过冰封潜行的低谷。
源头与古典时期(20世纪40-60年代):思想的播种
-
1943年,麦卡洛克-皮茨神经元(MCP Neuron):神经生理学家沃伦·麦卡洛克和逻辑学家沃尔特·皮茨,首次提出了一个形式化的神经元数学模型。它接收多个二进制输入,通过一个阈值函数,产生一个二进制输出。这虽然是一个极其简化的模型,但它第一次从计算的角度,建立了连接生物大脑与机器智能的桥梁。它是神经网络大厦的第一块砖。
-
1950年,图灵测试与《计算机器与智能》:艾伦·图灵,这位计算机科学的奠基人,在他划时代的论文中,没有直接定义"机器能否思考",而是提出了一个可操作的测试------"模仿游戏",即后人所称的"图灵测试"。他将焦点从哲学的思辨转向了行为的判断,并预言了"学习机器"的可能性。这篇文章,是人工智能领域的思想"开山之作"。
-
1952年,亚瑟·萨缪尔的跳棋程序:IBM的工程师亚瑟·萨缪尔编写了一个可以学习下西洋跳棋的程序。这个程序可以通过自我对弈来提升棋力,其水平最终甚至超过了萨缪尔本人。这是机器学习的第一个广为人知的成功案例,它生动地展示了"让计算机自己学习"是可行的。萨缪尔也是第一个提出并普及"Machine Learning"这个词的人。
-
1957年,感知机(Perceptron):弗兰克·罗森布拉特基于MCP模型,提出了"感知机"。与MCP不同,感知机模型的权重参数是可以通过学习算法自动调整的。他甚至制造了硬件"Mark I Perceptron",用于图像识别。这引发了第一次AI热潮,人们对"会思考的机器"充满了乐观的幻想。
第一次AI寒冬(20世纪70-80年代):理性的沉淀
-
1969年,《感知机》一书的冲击:AI领域的两位领军人物马文·明斯基和西摩尔·派普特,出版了《感知机》一书。书中通过严谨的数学证明,指出了单层感知机无法解决"异或(XOR)"这类线性不可分问题。这一结论虽然是针对单层结构的,但在当时被许多人误读为整个神经网络方法的根本性缺陷。这本著作如一盆冷水,浇灭了当时过于狂热的期望,直接导致了神经网络研究的资金被大量削减,AI进入了第一个"冬天"。
-
寒冬中的火种 :尽管神经网络研究进入低谷,但其他机器学习流派仍在悄然发展。决策树 算法(如ID3)、专家系统等符号主义AI方法在这一时期取得了重要进展。寒冬并未熄灭所有火种,反而促使研究者们进行更深刻的理性和基础性思考。
复兴与连接主义的回归(20世纪80年代末-90年代):柳暗花明
-
1986年,反向传播算法(Backpropagation)的重新发现:虽然反向传播的思想早已存在,但由戴维·鲁姆哈特、杰弗里·辛顿和罗纳德·威廉姆斯等人的工作,使其得到了广泛传播和应用。该算法有效地解决了多层神经网络的权重训练问题,攻克了《感知机》一书中提出的核心难题,让神经网络研究重获新生。
-
20世纪90年代,统计学习的崛起 :在神经网络复兴的同时,另一股强大的力量正在形成。以弗拉基米尔·瓦普尼克等人提出的支撑向量机(SVM) 为代表的,基于严格统计学习理论(VC维理论)的方法论开始大放异彩。SVM以其优美的数学理论、出色的泛化能力和高效的凸优化求解,在许多中小型数据集的分类和回归任务上,其表现常常优于当时的神经网络。同时期,决策树的集成方法,如随机森林(Random Forest) 和**梯度提升机(Gradient Boosting Machine)**也开始崭露头角。这个时代,是"统计机器学习"的黄金时代,各种精巧的浅层模型百花齐放。
第二次AI寒冬(2000年前后):瓶颈与酝酿
进入21世纪初,尽管机器学习在特定领域应用广泛,但其发展似乎又遇到了瓶颈。当时的神经网络虽然理论上可以很深,但实际训练中面临着梯度消失/爆炸等问题,导致深层网络的训练极为困难。而SVM等模型虽然理论优美,但在处理如图像、语音这类拥有海量、高维原始特征的任务时,显得力不从心。整个领域似乎在等待一次新的突破。
深度学习革命(2006年至今):王者归来
-
2006年,深度信念网络与逐层预训练:杰弗里·辛顿等人提出了"深度信念网络(DBN)",并开创性地使用了"无监督逐层预训练+有监督微调"的方法。这种方法像搭积木一样,先让网络的每一层自己进行无监督学习,理解数据的基本特征,然后再用有标签的数据对整个网络进行精调。这巧妙地缓解了深度网络训练的困难,为"深度学习"一词的诞生拉开了序幕。
-
2012年,AlexNet在ImageNet竞赛中取得历史性突破:由辛顿的学生亚历克斯·克里热夫斯基设计的深度卷积神经网络AlexNet,在当年的ImageNet大规模视觉识别挑战赛(ILSVRC)中,以远超第二名(基于传统方法)的惊人准确率夺冠。这一事件的冲击力,不亚于深蓝计算机战胜卡斯帕罗夫。它无可辩驳地证明了,在处理复杂模式识别任务时,深度学习(特别是卷积神经网络CNN)的强大威力。这一胜利,点燃了延续至今的深度学习革命之火。
-
至今:黄金时代 :自2012年以来,我们见证了技术的爆炸式发展。从用于序列数据的循环神经网络(RNN)及其变体LSTM ,到解决其长程依赖问题的Transformer架构 ;从生成以假乱真图像的生成对抗网络(GAN) ,到驱动AlphaGo和ChatGPT的深度强化学习 与大规模预训练语言模型。深度学习不仅统一了人工智能的诸多领域,更以前所未有的深度和广度,渗透到我们生活的方方面面。
这段历史告诉我们,科学的发展从不是一条直线。它充满了螺旋式的上升和周期性的起伏。思想的火花可能需要数十年的沉寂才能燎原,而看似不可逾越的瓶颈,也终将被新的智慧所突破。
1.2.2 群星闪耀时:那些塑造了AI纪元的大师们
技术史的宏大叙事,最终是由一个个鲜活的人来书写的。在AI的殿堂里,有几位巨匠的名字,我们必须铭记。他们的思想与贡献,如北极星般指引着整个领域的前行。
-
艾伦·图灵(Alan Turing):如前所述,他是计算机科学与人工智能的"思想教父"。他提出的图灵机模型定义了"可计算"的边界,而图灵测试则开启了"机器智能"的哲学与实践探索。
-
杰弗里·辛顿(Geoffrey Hinton):被誉为"深度学习之父"之一。从80年代共同推广反向传播算法,到21世纪初用深度信念网络开启深度学习革命,再到培养出AlexNet的作者等一众英才,辛顿以其数十年的坚持和洞察力,将神经网络从寒冬带入了盛夏。他因在深度学习领域的开创性贡献,与另外两位学者共同获得了2018年的图灵奖。
-
杨立昆(Yann LeCun):另一位2018年图灵奖得主,卷积神经网络(CNN)的缔造者。早在上世纪90年代,他就开发了LeNet-5,成功应用于银行的支票手写数字识别。CNN架构模拟了生物的视觉皮层机制,其"局部连接"和"权值共享"的设计,对于处理图像等网格状数据具有天然的优势,是当今计算机视觉领域的基石。
-
约书亚·本吉奥(Yoshua Bengio):2018年图灵奖的第三位得主。他在深度学习的多个领域都做出了奠基性贡献,尤其是在语言模型、注意力机制等方面。他与团队的工作,为后来Transformer架构的诞生和自然语言处理的革命性突破铺平了道路。同时,他也是一位极具人文关怀的科学家,持续关注AI的社会影响与伦理问题。
这三位学者常被并称为"深度学习三巨头",他们的合作与良性竞争,共同塑造了我们今天所知的深度学习版图。
- 弗拉基米尔·瓦普尼克(Vladimir Vapnik):统计学习理论的巨擘,支撑向量机(SVM)的发明人。他的工作为机器学习提供了坚实的理论基础(VC维理论),强调了控制模型复杂度、追求泛化能力的重要性。在深度学习浪潮之前,SVM是学术界和工业界最受推崇的监督学习算法之一。他的思想提醒我们,即使在经验主义大行其道的今天,深刻的数学理论依然是指引我们前行的灯塔。
当然,群星闪耀,远不止于此。从"人工智能"一词的提出者约翰·麦卡锡 ,到决策树算法的先驱罗斯·昆兰 ,再到强化学习领域的泰斗理查德·萨顿......正是这一代代研究者的智慧接力,才汇聚成了今日人工智能的滔滔江河。向他们致敬的最好方式,就是站在他们的肩膀上,继续探索这片智慧的星辰大海。
1.3 为何是Python?------数据科学的"通用语"
在开启具体的编程学习之前,一个自然的问题是:为什么是Python?在众多编程语言中,为何Python能够脱颖而出,成为机器学习和数据科学领域事实上的"标准语言"?这并非偶然,而是其内在哲学与外在生态共同作用的结果。
1.3.1 Python的哲学:"禅"与"道"
任何一门成功的语言,背后都有一种独特的设计哲学。Python的哲学,被精炼地总结在"Python之禅(The Zen of Python)"中。你可以在任何安装了Python的环境中,通过在解释器里输入import this来一睹其真容。其中几条,与数据科学的精神内核不谋而合:
- 优美胜于丑陋(Beautiful is better than ugly.)
- 明了胜于晦涩(Explicit is better than implicit.)
- 简单胜于复杂(Simple is better than complex.)
- 可读性很重要(Readability counts.)
这不仅仅是编程美学,更是科学研究的方法论。机器学习项目往往不是一次性的"代码冲锋",而是一个需要反复实验、迭代、验证和与他人协作的探索过程。
-
可读性与简洁性:Python的语法非常接近自然语言,这使得代码的阅读和编写都变得异常轻松。对于科学家、分析师这些可能并非计算机科班出身的使用者来说,学习曲线极为平缓。他们可以将更多的精力聚焦于问题本身和算法思想,而不是纠结于繁琐的语法细节(如C++的指针或Java的样板代码)。一段Python代码,往往更像是在描述解决问题的"伪代码",这使得团队协作和知识分享变得极为高效。
-
"胶水语言"的特质 :Python被誉为"胶水语言",因为它能轻易地将其他语言(特别是C/C++)编写的高性能模块"粘合"在一起。机器学习的核心计算,如图形处理、大规模矩阵运算,对性能要求极高。这些计算通常由底层的、用C++或CUDA编写的高性能库来完成。Python则扮演了一个优雅的"指挥官"角色:我们用Python来定义模型结构、组织数据流、进行实验管理,而将真正的计算密集型任务交给后台的C++引擎。这就实现了"开发效率 "与"运行效率"的完美结合。我们享受着Python的简洁,却没有牺牲关键任务的性能。
这种设计哲学,使得Python成为一座理想的桥梁,它连接了思想与实现,连接了研究与工程,连接了专家与初学者。
1.3.2 生态系统概览:为何它能成为最优选择
如果说哲学是Python的"灵魂",那么其无与伦比的开源生态系统,就是它强健的"体魄"。围绕着数据科学和机器学习,Python社区自发地构建起了一套完整、强大且高度协同的"工具链"。这套工具链覆盖了从数据获取、清洗、分析、建模到可视化的整个工作流。
让我们来巡礼一下这个生态中的几颗璀璨明珠,这些也是我们后续章节将会深入学习的核心工具:
-
NumPy (Numerical Python) :数据科学的基石。它提供了一个强大的N维数组对象(
ndarray),以及对这些数组进行操作的大量高效函数。几乎所有Python中的高级数据分析和机器学习库,其底层都构建在NumPy之上。它将Python从一门通用脚本语言,变成了能够与MATLAB等专业科学计算软件相媲美的强大工具。 -
Pandas :数据分析与处理的瑞士军刀。Pandas提供了两种核心数据结构:
Series(一维)和DataFrame(二维)。DataFrame可以被想象成一个内存中的、功能极其强大的Excel表格。它使得数据的读取、清洗、转换、筛选、聚合、分组等操作变得异常简单直观。可以说,在机器学习项目中,80%的时间花在数据预处理上,而Pandas正是让这80%的时间变得高效而愉快的关键。 -
Matplotlib & Seaborn:数据可视化的双璧。Matplotlib是Python中最基础、最灵活的可视化库,它提供了强大的底层绘图接口,让你可以定制几乎任何类型的静态、动态、交互式图表。而Seaborn则是基于Matplotlib构建的更高级的统计图形库,它提供了更多美观且面向统计分析的图表模板,用更少的代码就能生成信息含量丰富的可视化结果。"一图胜千言",这两个库是我们洞察数据、展示模型结果的"眼睛"。
-
Scikit-learn:传统机器学习的集大成者。Scikit-learn是进入机器学习领域最重要、最友好的库。它用一套高度一致、简洁优雅的API,实现了绝大多数经典的机器学习算法(分类、回归、聚类、降维等)。无论是初学者学习算法,还是从业者快速搭建基线模型,Scikit-learn都是不二之选。它的文档极为完善,堪称技术文档的典范。本书的第二部分将重点围绕Scikit-learn展开。
-
深度学习框架:TensorFlow & PyTorch:当问题复杂度超越了传统机器学习的范畴,我们就需要进入深度学习的世界。在这个世界里,TensorFlow(由Google开发)和PyTorch(由Facebook开发)是两大主流框架。它们提供了构建、训练和部署大规模神经网络所需的全部工具,包括自动微分、GPU加速、丰富的预置模型层等。虽然它们在设计哲学上有所不同(TensorFlow 2.x后也采纳了PyTorch的动态图思想),但都已成为驱动当今AI革命的核心引擎。
-
Jupyter Notebook / Lab:交互式科学计算的理想环境。Jupyter提供了一个基于Web的交互式计算环境,允许你将代码、文本(Markdown)、数学公式(LaTeX)、可视化结果等组合在一个文档中。这种"文学编程"的范式,极大地促进了探索性数据分析和研究过程的记录与分享。它是数据科学家和机器学习研究者的"数字实验室"和"工作台"。
这套生态系统的力量在于其"网络效应":每一个库都构建在其他库之上,彼此无缝集成。你用Pandas清洗数据,得到的DataFrame可以直接喂给Scikit-learn进行建模,然后用Matplotlib将结果画出来。这种流畅的体验,是其他任何语言生态都难以比拟的。正是这个原因,最终使得Python战胜了R、MATLAB、Java等竞争者,成为了数据科学的"通用语"。
1.4 破除迷思:AI是"神"还是"器"?
随着AlphaGo的胜利和ChatGPT的惊艳表现,人工智能(AI)以前所未有的姿态进入了公众视野。媒体的渲染、科幻作品的想象,使得AI的形象在人们心中变得模糊、甚至两极分化:一些人视之为无所不能、即将取代人类的"神";另一些人则忧心忡忡,将其视为可能失控的"潘多拉魔盒"。
作为即将踏入这个领域的实践者,我们必须建立一个清醒、理性的认知:在可预见的未来,我们今天所谈论和实践的AI,本质上是一种"器",而非"神"。 它是一种由人类设计,基于数学和数据,用于放大人类智慧、解决特定问题的强大工具。
1.4.1 机器学习的能力边界与伦理挑战
承认AI是"器",意味着我们要清醒地认识到它的能力边界。
-
数据依赖性:机器学习模型的能力,完全取决于其"喂养"的数据。模型的"智慧"是数据中蕴含模式的反映,其"偏见"也是数据中固有偏见的折射。如果训练数据存在偏差(例如,在招聘模型中,历史数据里男性工程师远多于女性),那么模型就会学习并放大这种偏差,做出歧视性的判断。模型无法创造数据中不存在的知识。
-
泛化能力的局限 :模型在训练数据上表现好,不代表在全新的、分布差异巨大的现实世界数据上依然表现好。这种从已知到未知的推广能力,被称为泛化(Generalization)。提升泛化能力是机器学习的核心挑战之一。一个在加州房价数据上训练得很好的模型,直接拿到中国市场来用,结果几乎必然是灾难性的。
-
缺乏常识与因果推理:目前的机器学习,尤其是深度学习,本质上是一种基于相关性的"模式匹配"。它擅长发现"A和B经常一起出现",但通常无法理解"是不是因为A导致了B"。它缺乏人类与生俱来的大量背景知识和常识。一个能识别图片中"马"的模型,并不知道马是一种动物,不能穿过墙壁。这种能力的缺失,使其在需要深度理解和推理的复杂决策场景中,依然非常脆弱。
-
可解释性(Interpretability)的挑战:特别是对于深度神经网络这类复杂的"黑箱"模型,我们往往很难理解它为什么会做出某个具体的决策。一个模型拒绝了你的贷款申请,但它无法像人类信贷员那样,给你一个清晰、合乎逻辑的理由。这种"知其然,而不知其所以然"的特性,在金融、医疗、司法等高风险领域,是不可接受的。
认识到这些边界,自然会引出我们必须面对的伦理挑战:
-
偏见与公平性(Bias and Fairness):如何确保算法不会对特定人群产生系统性的歧视?这不仅仅是技术问题,更是社会正义问题。我们需要开发能够检测、量化并缓解偏见的算法,并在模型设计之初就将公平性作为核心目标之一。
-
隐私(Privacy) :在利用海量个人数据训练模型的同时,如何保护用户的隐私权?像联邦学习(Federated Learning) 和**差分隐私(Differential Privacy)**这样的技术正在为此努力,它们旨在让模型在不接触原始敏感数据的情况下完成学习,或者在数据发布时加入数学上可保证的"噪声"来保护个体信息。
-
责任(Accountability):当一个自动驾驶汽车发生事故,或一个AI医疗诊断系统出现误诊时,责任该由谁来承担?是用户、开发者、公司,还是AI本身?这需要建立清晰的法律法规和问责框架,确保技术的每一个环节都有明确的责任主体。
-
安全与鲁棒性(Safety and Robustness):如何防止AI系统被恶意攻击(例如,通过在停车标志上贴一个不起眼的贴纸,就让自动驾驶的识别系统将其误判为限速标志)?研究模型的"脆弱性",发展"对抗性训练"等防御技术,是确保AI系统在现实世界中安全可靠的关键。
-
失业与社会结构:AI自动化将在多大程度上取代人类工作,我们应如何应对由此带来的社会结构性变迁?这需要政策制定者、教育家和全社会共同思考,如何进行教育改革、建立社会保障体系,以及创造新的工作岗位,以适应人机协作的新时代。
这些挑战提醒我们,机器学习的实践者,绝不能仅仅是一个埋头于代码和模型的"技术工匠"。我们必须成为一个负责任的"思考者",时刻审视我们创造的技术可能带来的深远影响。
1.4.2 心法:以"出世"之心,做"入世"之事
面对机器学习的强大能力与深刻挑战,我们应秉持怎样的心态和原则来从事这项事业?在此,奶奶想与你分享一种"心法",一种融合了东方智慧与科学精神的从业态度------以"出世"之心,做"入世"之事。
何为"出世"之心?
"出世",并非消极避世,而是指一种超越具体事务、追求事物本源和规律的超然心态。它要求我们在精神层面保持高度的清醒、客观与谦卑。
-
保持对知识的敬畏:要认识到我们所学的不过是沧海一粟。机器学习领域日新月异,没有任何人能宣称自己掌握了全部。保持空杯心态,持续学习,对未知保持好奇与敬畏,这是避免技术傲慢的根本。
-
追求真理,而非迎合指标:在项目中,我们常常会为了提升某个评估指标(如准确率)而无所不用其极。但"出世"之心提醒我们,要时刻反思这个指标是否真正反映了我们想要解决的现实问题。有时,0.1%的准确率提升可能伴随着对某一群体公平性的巨大损害。我们的目标是解决问题,而不仅仅是优化数字。
-
旁观者清,审视全局:在埋头于特征工程和模型调优的"入世"状态中,要时常抽离出来,像一个"出世"的旁观者一样审视自己的工作。问自己:我做的事情是否有潜在的负面影响?我的模型是否可能被滥用?我是否考虑了所有相关的利益方?这种自我审视,是技术伦理的第一道防线。
-
不执于"我":不执着于"我"的模型、"我"的方法。科学的进步在于开放与协作。要乐于分享,敢于承认自己方法的局限,并积极吸收他人的智慧。一个算法、一个模型的价值,在于它能解决问题,而不在于它属于谁。
何为"入世"之事?
"入世",就是积极地投身于现实世界,用我们所学的知识去解决具体、实际的问题,创造真实的价值。它要求我们脚踏实地,精益求精。
-
问题驱动,而非技术驱动:要从真实的需求出发,而不是拿着"锤子"(某个炫酷的新模型)到处找"钉子"。深刻理解业务场景,与领域专家紧密合作,让技术真正服务于目的。
-
动手实践,精益求精:机器学习终究是一门实践科学。"纸上得来终觉浅,绝知此事要躬行。" 必须亲手处理数据,编写代码,训练模型,分析结果。在每一个细节上追求卓越,代码要清晰,实验要严谨,结果要可复现。这是工匠精神的体现。
-
创造价值,勇于担当:我们的最终目标,是利用机器学习技术,在医疗、教育、环保、科研等领域做出积极的贡献。同时,也要勇于为自己创造的技术成果负责。如果发现它带来了意想不到的负面后果,要有勇气站出来承认并努力修正。
"出世"与"入世"的辩证统一
"出世"之心是"体",是我们的世界观和价值观,它为我们指明方向,设定底线,让我们不迷失在技术的洪流中。"入世"之事是"用",是我们的方法论和行动力,它让我们将理想转化为现实,将智慧落地为价值。
只"出世"而无"入世",则易流于空谈,成为"坐而论道"的清谈客。只"入世"而无"出世",则易陷于"术"而忘了"道",成为一个高效但可能盲目的"工具人",甚至可能在不经意间"作恶"。
因此,真正的大家,必然是"出世"与"入世"的完美结合。他们既有仰望星空的深邃思考,又有脚踏实地的精湛技艺。
结语
亲爱的读者,本章即将结束。我们一同探讨了学习的本质,回顾了AI的壮阔历史,明确了Python的生态优势,并最终落脚于从业者的内心修为。
希望这番"务虚"的讨论,能为您接下来的"务实"学习,打下坚实的地基。因为最高明的技术,永远由最清醒的头脑和最正直的心灵所驾驭。
从下一章开始,我们将正式卷起袖子,进入Python与机器学习工具的实践世界。请带着这份对全局的认知和内心的准则,开始我们真正的筑基之旅。
第二章:工欲善其事------Python环境与核心工具链
- 2.1 "乾坤在握":Anaconda与Jupyter Notebook的安装与配置
- 2.2 "数据之舟":NumPy数值计算基础
- 2.3 "数据之魂":Pandas数据分析利器
- 2.4 "眼见为实":Matplotlib与Seaborn数据可视化
在上一章,我们探讨了机器学习的宏大世界观。现在,我们要将这些思想付诸实践。实践的第一步,便是构建一个稳定、可靠且功能强大的工作环境。本章将引导您完成从环境安装到核心工具掌握的全过程,为您后续的学习扫清障碍。
我们将首先介绍并安装Anaconda,这个被誉为数据科学"全家桶"的发行版,它能一站式解决Python环境管理和包安装的难题。接着,我们将学习使用Jupyter Notebook,一个交互式的"数字实验室",它将成为我们探索、实验和展示工作的主要平台。
随后,我们将深入学习三个数据科学的"奠基石"库:
- NumPy:我们的"数据之舟",它为Python提供了强大的多维数组和高效的数值计算能力。
- Pandas:我们的"数据之魂",它提供了灵活的数据结构,让处理和分析结构化数据变得轻而易举。
- Matplotlib & Seaborn:我们的"眼睛",它们能将枯燥的数据转化为富有洞察力的可视化图表。
请务必对本章内容投入足够的时间和耐心。熟练掌握这些工具,您会发现后续的学习将事半功倍。
2.1 "乾坤在握":Anaconda与Jupyter Notebook的安装与配置
在编程世界里,环境配置往往是劝退新手的"第一道坎"。不同项目可能需要不同版本的Python或依赖库,如果将所有东西都装在系统的主Python环境中,很快就会导致版本冲突和混乱,犹如一个堆满了各种工具、零件却杂乱无章的车库。
为了解决这个问题,我们需要一个专业的"车库管理员"------Anaconda。
什么是Anaconda?
Anaconda并不仅仅是Python,它是一个专注于数据科学的Python发行版。你可以把它理解为一个"大礼包",里面包含了:
- 特定版本的Python解释器。
- Conda :一个强大的包管理器 和环境管理器。
- 预装好的数百个常用科学计算包:如NumPy, Pandas, Matplotlib, Scikit-learn等。你无需再一个个手动安装,省去了大量的配置麻烦。
为何选择Anaconda?------环境管理的智慧
Anaconda最核心的价值在于其附带的conda工具,它能让我们轻松创建相互隔离的虚拟环境(Virtual Environments)。
想象一下,你要同时进行两个项目:
- 项目A,是一个老项目,需要使用Python 3.7和一个旧版的库X (版本1.0)。
- 项目B,是一个新项目,你想使用最新的Python 3.11和库X的新版本 (版本2.0)。
如果没有环境隔离,这两个项目根本无法在同一台电脑上共存。而有了conda,你可以:
- 创建一个名为
project_a_env的环境,在里面安装Python 3.7和库X 1.0。 - 再创建一个名为
project_b_env的环境,在里面安装Python 3.11和库X 2.0。
这两个环境如同两个独立的平行宇宙,互不干扰。你可以随时通过一条简单的命令在它们之间切换。这种"分而治之"的智慧,是专业开发实践的基石。
安装Anaconda
安装过程非常直观,与安装普通软件无异。
- 访问官网:在浏览器中打开Anaconda的官方下载页面 (anaconda.com/download)。网站通常会自动检测你的操作系统(Windows, macOS, Linux)并推荐合适的版本。
- 选择版本:选择与你操作系统对应的最新Python 3.x版本的图形化安装包(Graphical Installer)进行下载。
- 执行安装 :
- 双击下载好的安装包。
- 按照提示点击"Next"或"Continue"。
- 在许可协议页面,同意协议。
- 安装类型选择"Just Me"即可(除非你有特殊需求为电脑所有用户安装)。
- 关键步骤(Windows) :在"Advanced Options"界面,建议不要勾选"Add Anaconda to my PATH environment variable"(将Anaconda添加到系统环境变量)。虽然勾选看似方便,但长期来看容易引起与其他Python安装的冲突。官方推荐使用"Anaconda Prompt"来启动和管理conda。另一个选项"Register Anaconda as my default Python"可以勾选。
- 选择安装路径(通常保持默认即可),然后开始安装。过程可能需要几分钟。
- 验证安装 :
- Windows: 在开始菜单中找到并打开"Anaconda Prompt (anaconda3)"。
- macOS/Linux: 打开你的终端(Terminal)。
- 在打开的命令行窗口中,输入
conda --version并回车。如果成功显示出conda的版本号(如conda 23.7.4),则证明Anaconda已安装成功。
使用Conda创建和管理环境
现在,让我们来实践一下环境管理的威力。打开你的Anaconda Prompt或终端。
-
创建一个新的环境 : 我们为本书创建一个专属的学习环境,命名为
ml_book,并指定使用Python 3.9(一个稳定且兼容性好的版本)。conda create --name ml_book python=3.9Conda会询问你是否要安装一些基础包,输入
y并回车。 -
激活环境: 创建好后,需要"进入"这个环境才能使用它。
conda activate ml_book激活后,你会发现命令行提示符前面多了
(ml_book)的字样,这表示你当前正处于这个独立的环境中。 -
在环境中安装库 : 现在,我们在这个环境中安装本书需要的核心库。由于Anaconda的base环境已经自带,我们这里仅作演示。例如,安装
seaborn。conda install seabornConda会自动处理依赖关系,一并安装好所有需要的其他库。
-
查看已安装的库:
conda list -
退出环境: 当你完成工作,可以退回到基础环境。
conda deactivate提示符前面的
(ml_book)会消失。
Jupyter Notebook:你的交互式实验室
环境搭好了,我们还需要一个好用的"工作台"。Jupyter Notebook 就是这样一个理想的工具。它是一个基于Web的应用程序,允许你创建和共享包含实时代码、公式、可视化和叙述性文本的文档。
启动Jupyter Notebook
-
确保你已经激活了你的工作环境(
conda activate ml_book)。 -
在命令行中输入:
jupyter notebook -
执行后,你的默认浏览器会自动打开一个新标签页,地址通常是
http://localhost:8888/tree。这就是Jupyter的文件浏览器界面。命令行窗口不要关闭,因为它是Jupyter服务的后台。
Jupyter Notebook核心概念
- Notebook文件 (
.ipynb) :你创建的每一个Jupyter文档都是一个.ipynb文件,它用一种特殊格式(JSON)保存了你所有的代码、文本和输出。 - 单元格(Cell) :Notebook由一个个单元格组成。单元格主要有两种类型:
- Code Cell(代码单元格):用来编写和执行代码(如Python代码)。
- Markdown Cell(文本单元格):用来编写格式化的文本,就像你现在正在阅读的这些文字一样,可以包含标题、列表、链接、图片等。
- 内核(Kernel):每个Notebook都有一个独立的"内核"在后台运行。这个内核是你激活的conda环境的体现,它负责接收你在Code Cell中写的代码,执行它,然后将结果返回并显示在单元格下方。
基本操作
- 新建Notebook:在Jupyter的文件浏览器页面,点击右上角的"New",然后选择"Python 3 (ipykernel)"或类似选项,即可创建一个新的Notebook。
- 切换单元格类型 :在选中一个单元格后,可以在顶部的工具栏下拉菜单中选择
Code或Markdown。 - 执行单元格 :选中一个单元格,按下
Shift + Enter,Jupyter会执行该单元格,并自动跳转到下一个单元格。这是最常用的快捷键。 - 保存 :点击左上角的保存图标,或使用快捷键
Ctrl + S(Windows/Linux) /Cmd + S(macOS)。
现在,请你亲手尝试:
- 创建一个新的Notebook。
- 在第一个单元格中,输入
print("Hello, Machine Learning World!"),然后按Shift + Enter执行。 - 将第二个单元格的类型改为Markdown,输入
# 这是我的第一个Notebook标题,然后按Shift + Enter渲染文本。
恭喜!你已经成功搭建了专业的开发环境,并掌握了与它交互的基本方式。这个环境如同一片沃土,我们接下来要学习的NumPy、Pandas等工具,就是将要在这片土地上茁壮成长的参天大树。
2.2 "数据之舟":NumPy数值计算基础
如果说数据是海洋,那NumPy (Numerical Python) 就是我们在这片海洋上航行的第一艘坚固快船。它是Python科学计算生态的绝对核心,几乎所有上层库(包括Pandas和Scikit-learn)都构建于它之上。
Python原生的列表(list)虽然灵活,但对于大规模数值运算,其性能不堪一击。NumPy的核心是其ndarray(N-dimensional array)对象,这是一个由相同类型元素组成的多维数组。它的优势在于:
- 性能 :
ndarray在内存中是连续存储的,并且其核心运算由C语言编写的底层代码执行,速度远超Python原生列表。 - 便捷:提供了大量用于数组操作的数学函数和线性代数运算,语法简洁。
安装NumPy
如果你遵循了上一节使用Anaconda,那么NumPy已经被预装好了。如果没有,只需在激活的环境中运行:
conda install numpy导入NumPy
在代码中,我们遵循一个广泛接受的惯例,将NumPy导入并简写为np。
import numpy as np2.2.1 从标量到张量:维度的哲学
在NumPy中,我们用不同的术语来描述不同维度的数据,这与物理学和深度学习中的"张量(Tensor)"概念一脉相承。理解维度,是理解数据结构的第一步。
-
标量(Scalar) :一个单独的数字,如
7。在NumPy中,它是一个0维数组。s = np.array(7) print(s) print("维度:", s.ndim) # ndim属性查看维度数量 # 输出: # 7 # 维度: 0 -
向量(Vector) :一列有序的数字,如
[1, 2, 3]。它是一个1维数组。v = np.array([1, 2, 3]) print(v) print("维度:", v.ndim) print("形状:", v.shape) # shape属性查看每个维度的大小 # 输出: # [1 2 3] # 维度: 1 # 形状: (3,) -
矩阵(Matrix) :一个二维的数字表格,如
[[1, 2], [3, 4]]。它是一个2维数组。m = np.array([[1, 2, 3], [4, 5, 6]]) print(m) print("维度:", m.ndim) print("形状:", m.shape) # 输出: # [[1 2 3] # [4 5 6]] # 维度: 2 # 形状: (2, 3) (代表2行3列) -
张量(Tensor):一个超过二维的数组。例如,一张彩色图片可以表示为一个3维张量(高度,宽度,颜色通道RGB)。
t = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]]) print(t) print("维度:", t.ndim) print("形状:", t.shape) # 输出: # [[[1 2] # [3 4]] # # [[5 6] # [7 8]]] # 维度: 3 # 形状: (2, 2, 2)
ndim(维度数)、shape(形状)和dtype(数据类型)是ndarray最重要的三个属性。在处理数据时,时刻关注这三个属性,能帮你避免很多错误。
创建数组的常用方法
除了直接从列表创建,NumPy还提供了多种便捷的创建方式:
# 创建一个3行4列,所有元素为0的数组
zeros_arr = np.zeros((3, 4))
# 创建一个2x3x2,所有元素为1的数组
ones_arr = np.ones((2, 3, 2))
# 创建一个从0到9的数组(不包含10)
range_arr = np.arange(10)
# 创建一个从0到1,包含5个等间距元素的数组
linspace_arr = np.linspace(0, 1, 5)
# 创建一个3x3的单位矩阵
eye_arr = np.eye(3)
# 创建一个2x3,元素为随机数的数组(0到1之间)
rand_arr = np.random.rand(2, 3)
# 创建一个2x3,元素为符合标准正态分布的随机数
randn_arr = np.random.randn(2, 3)2.2.2 核心操作:索引、切片、广播机制
1. 索引与切片(Indexing and Slicing)
这与Python列表类似,但扩展到了多维。
# 以一个1维数组为例
a = np.arange(10) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 获取单个元素
print(a[5]) # 输出: 5
# 切片:获取从索引2到索引7(不含)的元素
print(a[2:7]) # 输出: [2 3 4 5 6]
# 以一个2维数组为例
m = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 获取单个元素:第1行(索引从0开始),第2列
print(m[1, 2]) # 输出: 6
# 获取整行
print(m[0, :]) # 输出: [1 2 3] (:代表该维度的所有元素)
# 或者简写为
print(m[0])
# 获取整列
print(m[:, 1]) # 输出: [2 5 8]
# 获取子矩阵:第0、1行,和第1、2列
print(m[0:2, 1:3])
# 输出:
# [[2 3]
# [5 6]]布尔索引(Boolean Indexing) 这是一个极其强大的功能,允许我们根据条件来选择元素。
data = np.array([[1, 2], [3, 4], [5, 6]])
# 找到data中所有大于3的元素
bool_idx = data > 3
print(bool_idx)
# 输出:
# [[False False]
# [False True]
# [ True True]]
# 使用这个布尔数组来索引,会返回所有对应位置为True的元素
print(data[bool_idx]) # 输出: [4 5 6]
# 也可以直接写成一行
print(data[data > 3])2. 数组运算
NumPy的数组运算是按元素进行的,这使得代码非常简洁。
x = np.array([[1, 2], [3, 4]])
y = np.array([[5, 6], [7, 8]])
# 按元素加法
print(x + y)
# [[ 6 8]
# [10 12]]
# 按元素乘法
print(x * y)
# [[ 5 12]
# [21 32]]
# 矩阵乘法(点积)
print(np.dot(x, y))
# 或者使用@符号 (Python 3.5+)
print(x @ y)
# [[19 22]
# [43 50]]NumPy还提供了全套的通用函数(ufunc),如np.sqrt(), np.sin(), np.exp()等,它们也都按元素作用于整个数组。
3. 广播机制(Broadcasting)
广播是NumPy最神奇也最重要的特性之一。它描述了NumPy在处理不同形状的数组进行算术运算时的规则。简单来说,如果两个数组的形状不完全匹配,NumPy会尝试"广播"那个较小的数组,将其"拉伸"以匹配较大数组的形状,从而使运算成为可能。
规则:从两个数组的尾部维度开始逐一比较它们的size:
- 如果两个维度size相同,或其中一个为1,则该维度兼容。
- 如果所有维度都兼容,则运算可以进行。
- 如果任一维度不兼容(size不同且没有一个是1),则会报错。
示例:
# 一个2x3的矩阵
a = np.array([[1, 2, 3], [4, 5, 6]])
# 一个1x3的向量(或说行向量)
b = np.array([10, 20, 30])
# a的形状是(2, 3),b的形状是(3,)。
# NumPy会将b广播,想象成把它复制了一遍,变成了[[10, 20, 30], [10, 20, 30]]
# 然后再与a进行按元素加法
print(a + b)
# 输出:
# [[11 22 33]
# [14 25 36]]
# 另一个例子:给矩阵的每一列加上一个不同的值
# a的形状是(2, 3)
# c的形状是(2, 1)
c = np.array([[100], [200]])
# NumPy会将c的第1维(列)进行广播,变成[[100, 100, 100], [200, 200, 200]]
print(a + c)
# 输出:
# [[101 102 103]
# [204 205 206]]广播机制极大地提升了代码的简洁性和效率,避免了我们手动写循环去扩展数组。理解并善用广播,是衡量一个NumPy使用者是否熟练的重要标志。
2.3 "数据之魂":Pandas数据分析利器
Pandas的名字来源于"Panel Data"(面板数据),这是一个计量经济学术语,指多维度的结构化数据集。这个库由Wes McKinney在2008年开发,初衷是为了解决金融数据分析中的实际问题。如今,它已成为Python数据分析的代名词。
Pandas的核心价值在于,它提供了一套直观、灵活且功能强大的数据结构,专门用于处理表格型(tabular) 和**异构(heterogeneous)**数据。在真实世界中,我们遇到的大部分数据,如Excel表格、数据库查询结果、CSV文件,都是这种形式。
安装Pandas
同样,如果你使用Anaconda,Pandas已为你准备就绪。否则,请运行:
##########################
### 导入Pandas
### 社区惯例是将其导入为`pd`
##########################
conda install pandas
import pandas as pd2.3.1 Series与DataFrame:结构化数据的"阴阳"
Pandas有两个核心的数据结构,理解它们是掌握Pandas的关键。
1. Series:带标签的一维数组
你可以将Series想象成一个加强版的NumPy一维数组 。它与ndarray的主要区别在于,Series有一个与之关联的标签数组 ,称为索引(Index)。
# 从列表创建一个基本的Series
s = pd.Series([10, 20, 30, 40])
print(s)
# 输出:
# 0 10
# 1 20
# 2 30
# 3 40
# dtype: int64左边的一列(0, 1, 2, 3)是默认生成的整数索引。右边是我们的数据值。
Series的强大之处在于我们可以自定义索引:
# 创建一个带有自定义索引的Series
sales = pd.Series([250, 300, 450], index=['北京', '上海', '深圳'])
print(sales)
# 输出:
# 北京 250
# 上海 300
# 深圳 450
# dtype: int64
# 可以像字典一样通过标签进行索引
print(sales['上海']) # 输出: 300
# 也可以像NumPy数组一样进行切片和布尔索引
print(sales[sales > 280])
# 输出:
# 上海 300
# 深圳 450
# dtype: int64Series的index和values属性可以分别访问其索引和值(值为一个NumPy数组)。
2. DataFrame:二维的"超级表格"
DataFrame是Pandas最核心、最常用的数据结构。你可以把它看作:
-
一个共享相同索引的
Series的集合。 -
一个带有行索引(index) 和**列索引(columns)**的二维表格。
-
一个功能极其强大的Excel电子表格或SQL数据表。
####################
从字典创建DataFrame,字典的key会成为列名
####################
data = {
'城市': ['北京', '上海', '广州', '深圳'],
'年份': [2020, 2020, 2021, 2021],
'人口(万)': [2154, 2428, 1867, 1756]
}
df = pd.DataFrame(data)
print(df)输出:
城市 年份 人口(万)
0 北京 2020 2154
1 上海 2020 2428
2 广州 2021 1867
3 深圳 2021 1756
####################
DataFrame
既有行索引(左边的0, 1, 2, 3),也有列索引('城市', '年份', '人口(万)')
####################
####################
查看DataFrame基本信息
在进行任何分析前,先"体检"一下数据是个好习惯:
####################
查看前5行
print(df.head())
查看后5行
print(df.tail())
查看索引、列名和数据类型
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 城市 4 non-null object
1 年份 4 non-null int64
2 人口(万) 4 non-null int64
dtypes: int64(2), object(1)
memory usage: 224.0+ bytes
获取描述性统计信息(对数值列)
print(df.describe())
年份 人口(万)
count 4.000000 4.000000
mean 2020.500000 2051.250000
std 0.577350 302.491322
min 2020.000000 1756.000000
25% 2020.000000 1839.250000
50% 2020.500000 2010.500000
75% 2021.000000 2222.500000
max 2021.000000 2428.000000
2.3.2 数据的"增删改查"与"聚合分离"
Pandas的威力体现在它对数据进行复杂操作的简洁性上。
1. 查(选择数据)
这是最频繁的操作。Pandas提供了两种主要的索引方式:
-
.loc:**基于标签(label)**的索引。 -
.iloc:**基于位置(integer position)**的索引。假设我们给df设置一个更有意义的索引
df.index = ['BJ', 'SH', 'GZ', 'SZ']
--- 使用 .loc ---
选择单行 (返回一个Series)
print(df.loc['SH'])
选择多行 (返回一个DataFrame)
print(df.loc[['BJ', 'SZ']])
选择行和列
print(df.loc['GZ', '人口(万)']) # 输出: 1867
选择多行多列
print(df.loc[['SH', 'GZ'], ['城市', '人口(万)']])
--- 使用 .iloc ---
选择第2行(索引为1)
print(df.iloc[1])
选择第0行和第3行
print(df.iloc[[0, 3]])
选择第2行、第1列的元素
print(df.iloc[2, 1]) # 输出: 2021
--- 条件选择 ---
选择年份为2020的所有行
print(df[df['年份'] == 2020])
选择人口超过2000万的城市名
print(df[df['人口(万)'] > 2000]['城市'])
记住.loc用名字,.iloc用数字,是避免混淆的关键。
2. 增(添加数据)
# 添加新列
df['GDP(万亿)'] = [3.6, 3.9, 2.5, 3.0]
print(df)
# 添加新行 (使用.loc)
df.loc['HZ'] = ['杭州', 2022, 1200, 1.8]
print(df)3. 删(删除数据)
使用.drop()方法。它默认返回一个新对象,不修改原始DataFrame。
# 删除列 (axis=1代表列)
df_no_gdp = df.drop('GDP(万亿)', axis=1)
# 删除行 (axis=0代表行)
df_no_hz = df.drop('HZ', axis=0)4. 改(修改数据)
可以直接通过索引赋值来修改。
# 修改单个值
df.loc['BJ', '人口(万)'] = 2189
# 修改整列
df['年份'] = 2022
# 根据条件修改
df.loc[df['城市'] == '上海', '人口(万)'] = 24875. 聚合与分组(Groupby)
这是Pandas的"大杀器",对应于SQL中的GROUP BY操作。它实现了**"分离-应用-合并"(Split-Apply-Combine)**的强大模式。
过程:
-
分离(Split):根据某个或某些键将数据拆分成组。
-
应用(Apply):对每个组独立地应用一个函数(如求和、求平均)。
-
合并(Combine):将结果合并成一个新的数据结构。
按"年份"分组,并计算每年的平均人口
avg_pop_by_year = df.groupby('年份')['人口(万)'].mean()
print(avg_pop_by_year)按"年份"分组,并应用多个聚合函数
stats_by_year = df.groupby('年份')['人口(万)'].agg(['mean', 'sum', 'count'])
print(stats_by_year)
groupby操作是探索性数据分析的核心,能帮助我们快速发现不同类别数据之间的关系。
Pandas的功能远不止于此,还包括处理缺失数据、合并/连接多个DataFrame、时间序列分析等高级功能,我们将在后续章节的实战中不断遇到和学习。
2.4 "眼见为实":Matplotlib与Seaborn数据可视化
数据分析的最终目的之一是获得洞察(Insight)。而人类的大脑天生就对图形信息比对数字表格更敏感。"一图胜千言",数据可视化正是连接数据与洞察的桥梁。
在Python生态中,Matplotlib 是"教父"级别的可视化库,它功能强大、可定制性极高。而Seaborn则是基于Matplotlib构建的、更侧重于统计图形的"美颜相机",它能用更简洁的代码生成更美观、信息更丰富的图表。
导入
import matplotlib.pyplot as plt
import seaborn as sns
# 在Jupyter Notebook中,通常会加上这行魔法命令,让图像直接内嵌在Notebook中显示
%matplotlib inline2.4.1 从点线图到热力图:选择合适的"画笔"
不同的数据关系,需要用不同的图表类型来呈现。
1. 折线图(Line Plot) :最适合展示数据随连续变量(尤其是时间)变化的趋势。
# 假设我们有一周的销售数据
days = np.arange(1, 8)
sales = np.array([50, 55, 47, 62, 60, 70, 68])
plt.figure(figsize=(8, 4)) # 创建一个8x4英寸的画布
plt.plot(days, sales, marker='o', linestyle='--') # marker是数据点的样式,linestyle是线的样式
plt.title("周销售额趋势") # 添加标题
plt.xlabel("天数") # 添加x轴标签
plt.ylabel("销售额") # 添加y轴标签
plt.grid(True) # 显示网格
plt.show() # 显示图像2. 散点图(Scatter Plot) :用于探索两个数值变量之间的关系。
# 假设我们有房屋面积和价格的数据
area = np.random.randint(50, 150, size=100)
price = area * 1.2 + np.random.randn(100) * 20
# 使用Seaborn绘制散点图,更美观
sns.scatterplot(x=area, y=price)
plt.title("房屋面积与价格关系")
plt.xlabel("面积 (平方米)")
plt.ylabel("价格 (万元)")
plt.show()3. 柱状图(Bar Plot) :用于比较不同类别的数据。
# 使用我们之前的城市人口DataFrame
sns.barplot(x='城市', y='人口(万)', data=df)
plt.title("主要城市人口对比")
plt.show()4. 直方图(Histogram) :用于观察单个数值变量的分布情况。
# 观察价格数据的分布
sns.histplot(price, kde=True) # kde=True会同时绘制一条核密度估计曲线
plt.title("房价分布直方图")
plt.show()5. 热力图(Heatmap) :用颜色深浅来展示一个矩阵的值,非常适合展示变量之间的相关性。
# 计算df中数值列的相关系数矩阵
corr_matrix = df[['年份', '人口(万)', 'GDP(万亿)']].corr()
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm') # annot=True在格子上显示数值, cmap是颜色主题
plt.title("特征相关性热力图")
plt.show()2.4.2 可视化之道:美学、信息与洞察
一幅好的数据可视化作品,应遵循几个原则:
-
数据-墨水比(Data-Ink Ratio) :由可视化大师爱德华·塔夫特提出。核心思想是,一幅图中绝大部分的"墨水"都应该用来展示数据本身,而应删去所有无益于理解数据的装饰性元素(如花哨的背景、3D效果等)。追求简约 和清晰。
-
选择正确的图表 :明确你要表达的关系------是比较、分布、构成还是联系?然后选择最适合的图表类型。用折线图去比较类别数据,或者用饼图去展示超过5个类别的构成,都是常见的错误。
-
清晰的标注 :一幅图必须是自包含的。它应该有明确的标题、坐标轴标签(包含单位)、图例等,让读者无需阅读正文就能理解图表的基本含义。
-
利用视觉编码:除了位置(x, y坐标),我们还可以利用颜色、形状、大小、透明度等视觉元素来编码更多的信息维度。但要避免过度使用,以免造成视觉混乱。
-
讲一个故事(Tell a Story):最好的可视化不仅仅是呈现数据,它还在讲述一个故事,引导读者发现模式、得出结论。你的标题、注解和高亮显示,都应该服务于这个故事。
结语
本章,我们从零开始,搭建了坚实的Python数据科学环境,并掌握了NumPy、Pandas、Matplotlib和Seaborn这四大金刚。这套工具链,是您未来探索广阔数据世界的"标准装备"。
请务必花时间亲手实践本章的所有代码。尝试读取你自己的CSV文件,用Pandas进行清洗和分析,再用Matplotlib/Seaborn将其可视化。当你能自如地运用这些工具时,你就已经完成了从门外汉到数据科学"准入者"的蜕变。
从下一章开始,我们将正式进入机器学习的核心地带,开始学习如何利用这些工具,去构建、训练和评估真正的机器学习模型。我们的地基已经打好,是时候开始建造大厦了。
第三章:数据的心法------预处理与特征工程
- 3.1 "相数据":理解你的数据
- 3.2 "净数据":数据清洗的修行
- 3.3 "点石成金":特征工程的科学与艺术
在机器学习的宏伟蓝图中,数据预处理与特征工程扮演着承前启后的关键角色。它们是连接原始数据与机器学习模型的桥梁,其质量直接决定了模型最终所能达到的高度。一个经过精心处理和设计的特征,其价值往往胜过一个复杂模型的微小调优。
本章,我们将秉持一种"格物致知"的精神,深入数据的内在肌理。我们将学习:
- "相数据":如何通过探索性数据分析(EDA)与数据进行初次"对话",理解其脾性。
- "净数据":如何像一位耐心的工匠,清理数据中的"杂质"------缺失值与异常值。
- "点石成金":如何施展特征工程的"魔法",从现有数据中创造出更具信息量的特征,并将其转化为模型能够"消化"的格式。
这个过程,既有章法可循的科学,也有依赖经验直觉的艺术。它是一场修行,考验的是我们的耐心、细致与创造力。
3.1 "相数据":理解你的数据
在拿到一个数据集后,最忌讳的就是不假思索地直接将其扔进模型。这好比医生不经问诊,就给病人开药,是极其危险和不负责任的。我们的第一步,永远是理解数据 。这个过程,我们称之为探索性数据分析(Exploratory Data Analysis, EDA)。
3.1.1 探索性数据分析(EDA):与数据对话的艺术
EDA是由统计学大师约翰·图基(John Tukey)提倡的一种数据分析方法论。它的核心思想是,在进行任何正式的假设检验之前,通过多种手段(主要是可视化和汇总统计)对数据进行开放式的探索,以发现其结构、异常、模式和关系。
这是一种侦探般的工作,我们的目标是回答关于数据的基本问题:
- 这个数据集中有多少行(样本)和多少列(特征)?
- 每个特征是什么数据类型(数值型、类别型、文本、日期)?
- 数据中是否存在缺失值?比例如何?
- 数据的分布是怎样的?(是正态分布,还是偏态分布?)
- 不同特征之间是否存在关联?(例如,身高和体重是否正相关?)
让我们以一个经典的"泰坦尼克号幸存者"数据集为例,来演示EDA的基本流程。首先,加载数据并进行初步检视。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据 (Seaborn自带了这个数据集)
df = sns.load_dataset('titanic')
# 1. 查看数据维度
print("数据形状:", df.shape)
# 2. 查看前几行,对数据有个直观印象
print(df.head())
# 3. 查看各列的数据类型和非空值数量
print(df.info())从df.info()的输出中,我们能立刻获得大量信息:
- 共有891个样本(行),15个特征(列)。
age(年龄)、deck(甲板号)、embarked(登船港口)等列存在缺失值(因为它们的非空计数少于891)。survived,pclass,sex,embarked等是类别型特征,而age,fare是数值型特征。
这就是与数据的第一轮"对话",我们已经对它的"家底"有了大致了解。
3.1.2 描述性统计与分布可视化
接下来,我们要更深入地探查数据的内在特征。
1. 描述性统计
对于数值型特征,describe()方法是我们的得力助手。
print(df.describe())这会输出数值列的计数、平均值、标准差、最小值、四分位数和最大值。从中我们可以快速发现:
- 年龄(age):乘客平均年龄约29.7岁,但年龄跨度很大(从0.42岁到80岁),且存在缺失值(count为714)。
- 票价(fare):票价分布极不均匀,75%的乘客票价低于31美元,但最高票价竟达512美元,这暗示可能存在极端值(异常值)。
对于类别型特征,我们可以使用value_counts()来查看其取值分布。
# 查看性别分布
print(df['sex'].value_counts())
# 查看生还情况分布
print(df['survived'].value_counts(normalize=True)) # normalize=True显示比例我们发现,乘客中男性远多于女性,且总体生还率只有约38.4%。
2. 分布可视化
数字是抽象的,图形是直观的。我们将使用Matplotlib和Seaborn将统计结果可视化。
-
观察单个数值变量的分布(直方图/核密度图)
sns.histplot(df['age'].dropna(), kde=True) # dropna()去掉缺失值 plt.title('乘客年龄分布') plt.show()从图中可以看到,乘客以年轻人为主,呈右偏态分布。
-
观察单个类别变量的分布(计数图/柱状图)
sns.countplot(x='pclass', data=df) plt.title('各船舱等级人数') plt.show()三等舱乘客数量最多。
-
探索特征与目标变量的关系 这是EDA的核心目的之一。例如,我们想知道"船舱等级"和"生还率"有何关系。
sns.barplot(x='pclass', y='survived', data=df) plt.title('各船舱等级的生还率') plt.ylabel('生还率') plt.show()一目了然,船舱等级越高(1等舱),生还率越高。这是一个极具信息量的发现。
-
探索两个数值变量的关系(散点图)
sns.scatterplot(x='age', y='fare', data=df) plt.title('年龄与票价的关系') plt.show() -
探索多个变量间的关系(热力图/配对图)
# 计算数值特征的相关性矩阵 corr = df[['survived', 'pclass', 'age', 'sibsp', 'parch', 'fare']].corr() sns.heatmap(corr, annot=True, cmap='coolwarm') plt.title('特征相关性热力图') plt.show() ``` 热力图显示,`pclass`和`survived`有显著的负相关(-0.34),`fare`和`survived`有正相关(0.26),这与我们之前的发现一致。
通过这一系列"望、闻、问、切",我们对数据的特性、潜在的问题(缺失值、异常值)以及特征间的关系有了深刻的理解。这份理解,将指导我们下一步的"净数据"和"点石成金"工作。
3.2 "净数据":数据清洗的修行
现实世界的数据是"肮脏"的。数据录入错误、传感器故障、用户不愿填写......种种原因导致了数据中充满了缺失值(Missing Values)和异常值(Outliers)。数据清洗,就是将这些"杂质"处理掉的过程,它是一项细致且关键的修行。
3.2.1 缺失值的"舍"与"得":删除、插补与预测
处理缺失值,我们需要权衡利弊,做出"舍"与"得"的决策。
1. 识别缺失值
# 查看每列的缺失值数量
print(df.isnull().sum())
# 查看缺失值比例
print(df.isnull().sum() / len(df) * 100)在泰坦尼克数据中,age缺失约19.8%,deck缺失高达77.4%,embarked只缺失2个。
2. 处理策略
-
删除(Dropping):"舍"的决断
-
删除整列 :如果一个特征的缺失比例过高(如
deck的77%),它所能提供的信息已经非常有限,强行填充反而可能引入噪声。此时,可以考虑直接删除该列。df_dropped_col = df.drop('deck', axis=1) -
删除整行 :如果某个样本(行)缺失了多个关键特征,或者数据集非常大而缺失的行数很少(如
embarked只缺失2行),那么直接删除这些行是简单有效的做法。df_dropped_row = df.dropna(subset=['embarked'])
优点 :简单直接,不会引入偏误。 缺点:会损失数据,如果缺失数据不是随机的,可能会导致分析结果产生偏见。
-
-
插补(Imputation):"得"的智慧 插补是用一个估算值来代替缺失值。这是更常用的方法。
-
用均值/中位数/众数填充 :这是最简单的插补方法。
-
对于数值型 特征,如果数据分布比较对称,可以用**均值(mean)填充;如果数据存在偏态或有异常值,用中位数(median)**更为稳健。
-
对于类别型 特征,可以用众数(mode)(出现次数最多的值)来填充。
用年龄的中位数填充age列的缺失值
age_median = df['age'].median()
df['age'].fillna(age_median, inplace=True) # inplace=True直接在原DataFrame上修改用登船港口的众数填充embarked列
embarked_mode = df['embarked'].mode()[0] # mode()返回一个Series,取第一个
df['embarked'].fillna(embarked_mode, inplace=True)
-
-
分组插补 :简单的全局均值/中位数忽略了数据内部的结构。我们可以做得更精细。例如,我们知道不同船舱等级的乘客年龄可能有差异,可以按
pclass分组,用各组的中位数来填充。# 伪代码演示思想 # df['age'] = df.groupby('pclass')['age'].transform(lambda x: x.fillna(x.median()))
优点 :保留了样本,充分利用了数据。 缺点:可能会低估数据的方差,引入一定偏误。
-
-
预测模型插补 这是一种更高级的方法。我们可以将含有缺失值的列作为目标变量(y),其他列作为特征(X),训练一个机器学习模型(如线性回归、K近邻)来预测缺失值。 优点 :通常是最准确的插补方法。 缺点:实现复杂,计算成本高。
选择哪种方法? 这取决于缺失的比例、特征的重要性、数据的内在关系以及你愿意投入的成本。没有绝对的"最优解",只有"最合适"的解。
3.2.2 异常值的"辨"与"融":识别与处理
异常值(Outliers)是指那些与数据集中其余数据点显著不同的数据点。它们可能是录入错误,也可能是真实但极端的情况。
1. 识别异常值("辨")
-
可视化识别:**箱形图(Box Plot)**是识别异常值的利器。箱体外的点通常被认为是潜在的异常值。
sns.boxplot(x=df['fare']) plt.show()泰坦尼克票价的箱形图清楚地显示了大量的高价异常点。
-
统计方法识别:
- 3σ法则(3-Sigma Rule):对于近似正态分布的数据,约99.7%的数据点会落在距离均值3个标准差的范围内。超出这个范围的点可被视为异常值。
- IQR法则(Interquartile Range) :这是箱形图背后的数学原理。IQR = Q3(上四分位数) - Q1(下四分位数)。通常将小于
Q1 - 1.5 * IQR或大于Q3 + 1.5 * IQR的点定义为异常值。
2. 处理异常值("融")
-
删除:如果确定异常值是由于错误(如年龄输入为200岁),可以直接删除。但如果异常值是真实的(如CEO的超高薪水),删除它们可能会丢失重要信息。
-
转换(Transformation) :对数据进行数学转换,如对数转换(log transform) ,可以"压缩"数据的尺度,减小异常值的影响。这对于处理右偏分布(如收入、票价)的数据特别有效。
df['fare_log'] = np.log1p(df['fare']) # log1p(x) = log(1+x),避免log(0) sns.histplot(df['fare_log'], kde=True) plt.show()可以看到,对数转换后的票价分布更接近正态分布。
-
盖帽(Capping/Winsorization) :将超出特定阈值(如99百分位数)的异常值,替换为该阈值。这既限制了异常值的极端影响,又保留了它们作为"高值"的信息。
p99 = df['fare'].quantile(0.99) df_capped = df.copy() df_capped.loc[df_capped['fare'] > p99, 'fare'] = p99
处理异常值同样需要审慎。要结合业务理解,判断一个"异常"点究竟是噪声还是有价值的信号。
3.3 "点石成金":特征工程的科学与艺术
如果说数据清洗是"打扫屋子",那么特征工程就是"精心装修"。特征工程是指利用领域知识和技术手段,从原始数据中提取、创造出对预测模型更有用的新特征的过程。 它是决定机器学习项目成败的最关键因素。
3.3.1 特征提取与创造:从原始数据中提炼真金
-
从现有特征组合 : 在泰坦尼克数据中,有
sibsp(兄弟姐妹/配偶数)和parch(父母/子女数)两个特征。它们都代表了亲人。我们可以将它们组合成一个更有意义的新特征------family_size(家庭成员总数)。df['family_size'] = df['sibsp'] + df['parch'] + 1 # +1是加上自己我们还可以根据家庭规模,创造一个类别特征,如
is_alone(是否独自一人)。df['is_alone'] = (df['family_size'] == 1).astype(int) # astype(int)将布尔值转为0/1 -
从复杂数据中提取:
-
日期时间 :从一个日期
2025-07-18,可以提取出年份、月份、星期几、是否为周末等多个特征。 -
文本数据:从一段文本中,可以提取词频(TF-IDF)、情感倾向、关键词等。
-
乘客姓名(Name) :看似无用,但仔细观察,姓名中包含了
Mr.,Mrs.,Miss.,Master.等称谓(Title)。这些称谓反映了乘客的性别、年龄、婚姻状况和社会地位,可能是非常有用的特征。df['title'] = df['name'].str.extract(' ([A-Za-z]+)\.', expand=False) print(df['title'].value_counts())
-
3.3.2 特征缩放与编码:为模型准备"素食"
大多数机器学习模型都像"挑食的孩子",它们无法直接"吃"下原始的、五花八门的数据。我们需要将所有特征都处理成它们喜欢的格式------数值型。
1. 类别特征编码
-
独热编码(One-Hot Encoding) :这是处理名义类别特征(Nominal Feature)(类别间没有顺序关系,如"颜色":红、绿、蓝)最常用的方法。它会为每个类别创建一个新的二进制(0/1)特征。
# 对'embarked'列进行独热编码 embarked_dummies = pd.get_dummies(df['embarked'], prefix='embarked') df = pd.concat([df, embarked_dummies], axis=1)pd.get_dummies是Pandas中实现独热编码的便捷函数。 -
标签编码(Label Encoding)/ 序数编码(Ordinal Encoding) :用于处理有序类别特征(Ordinal Feature)(类别间有明确的顺序,如"学历":学士、硕士、博士)。它将每个类别映射到一个整数。
# 假设有学历特征 # mapping = {'学士': 1, '硕士': 2, '博士': 3} # df['education_encoded'] = df['education'].map(mapping)注意:绝对不能对名义类别特征使用标签编码,因为这会错误地给模型引入一个不存在的顺序关系(例如,模型会认为"蓝色"比"红色"大)。
2. 数值特征缩放(Scaling)
许多模型(如线性回归、SVM、神经网络)对特征的尺度非常敏感。如果一个特征的范围是0-10000(如薪水),另一个是0-100(如年龄),模型会不成比例地被薪水这个特征所主导。特征缩放就是将所有特征调整到相似的尺度。
-
标准化(Standardization / Z-score Normalization) :将特征缩放到均值为0,标准差为1 的分布。计算公式为
(x - mean) / std。这是最常用、最通用的缩放方法。from sklearn.preprocessing import StandardScaler scaler = StandardScaler() df['age_scaled'] = scaler.fit_transform(df[['age']]) -
归一化(Normalization / Min-Max Scaling) :将特征缩放到一个固定的范围,通常是****。计算公式为
(x - min) / (max - min)。当数据分布不符合高斯分布,或者你想保留0值时比较有用。from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() df['fare_scaled'] = scaler.fit_transform(df[['fare']])
3.3.3 特征选择与降维:去芜存菁,大道至简
当我们创造了大量特征后,可能会引入冗余或不相关的特征,这会增加模型复杂度,降低泛化能力,甚至导致"维度灾难"。因此,我们需要"去芜存菁"。
1. 特征选择(Feature Selection)
目标是从所有特征中,选出一个最优的子集。
- 过滤法(Filter Methods):独立于模型,根据特征本身的统计特性(如相关系数、卡方检验、信息增益)来打分和排序,然后选择得分最高的特征。速度快,但没有考虑特征间的组合效应。
- 包装法(Wrapper Methods) :将特征选择过程"包装"在模型训练中。它把特征子集的选择看作一个搜索问题,用模型的性能作为评估标准来寻找最优子集。例如,递归特征消除(Recursive Feature Elimination, RFE)。效果好,但计算成本高。
- 嵌入法(Embedded Methods):将特征选择嵌入到模型构建的过程中。例如,**L1正则化(如Lasso回归)**在训练时会自动将不重要特征的系数惩罚为0,从而实现了自动的特征选择。这是目前非常推崇的方法。
2. 降维(Dimensionality Reduction)
降维不是简单地"选择"特征,而是通过线性或非线性变换,将高维数据投影到低维空间,同时尽可能多地保留原始数据的信息,创造出全新的、更少的特征。
- 主成分分析(Principal Component Analysis, PCA):这是最经典的线性降维方法。它的思想是,寻找一个新的坐标系,使得数据在第一个新坐标轴(第一主成分)上的方差最大,在第二个新坐标轴(第二主成分)上的方差次之,且与第一个正交,以此类推。然后我们只保留前k个方差最大的主成分,就实现了降维。 PCA在数据可视化(将高维数据降到2D或3D进行观察)和消除多重共线性方面非常有用。我们将在后续章节中更详细地学习和实践它。
结语
本章,我们完成了一次从"原始数据"到"精炼特征"的完整修行。我们学会了如何与数据对话(EDA),如何为数据"沐浴更衣"(清洗),以及如何为其"梳妆打扮"(特征工程)。
请牢记,特征工程是机器学习中创造力和领域知识价值最大的体现。好的特征,能让简单的模型大放异彩;而差的特征,即使是再强大的模型也无力回天。
现在,我们的数据已经准备就绪,可以随时"喂"给模型了。下一章,我们将正式开启各类主流机器学习模型的学习之旅,将这些精心准备的"食材",烹饪成一道道美味的"算法大餐"。
第四章:模型的罗盘------评估与选择
- 4.1 "度量衡":分类、回归与聚类模型的评估指标
- 4.2 "执其两端而用中":偏差与方差的权衡
- 4.3 "他山之石":交叉验证的智慧
- 4.4 "寻路":网格搜索与超参数调优
经过前三章的修炼,我们已经学会了搭建环境、驾驭工具,并掌握了数据的"心法"。我们手中已经有了经过精心提炼的"燃料"------干净、规整的特征。现在,是时候将这些燃料注入各种强大的"引擎"------机器学习模型了。
但在我们一头扎进形形色色的算法海洋之前,一个至关重要的问题摆在面前:我们如何判断一个模型是好是坏?
在两个模型之间,我们如何客观地选择那个更好的?一个模型在训练数据上表现完美,我们就能相信它在未来的新数据上同样出色吗?如何为模型选择最佳的"配置参数",让其发挥最大潜能?
本章,便是解答这些问题的"罗盘"。我们将系统地学习模型评估与选择的完整框架。首先,我们会为不同类型的任务(分类、回归、聚类)建立一套精确的"度量衡",即评估指标。接着,我们将深入探讨所有模型都无法回避的两个核心矛盾------偏差与方差,并学习如何通过学习曲线来诊断它们。随后,我们将掌握交叉验证这一强大的技术,以获得对模型性能更稳定、更可靠的评估。最后,我们将学习如何像一位经验丰富的工程师一样,系统地为模型寻找最优的超参数。
掌握本章内容,您将拥有一双"慧眼",能够洞悉模型的内在状态,科学地评估其优劣,并自信地做出选择。这是从"会用模型"到"用好模型"的关键一步。
4.1 "度量衡":分类、回归与聚类模型的评估指标
没有度量,就无法优化。评估指标,就是我们衡量模型性能的尺子。不同的任务,需要用不同的尺子来量。我们不能用量身高的尺子去量体重,同样,我们也不能用回归的指标去评估分类模型。
4.1.1 分类任务的"是非题":混淆矩阵的深层解读
分类任务是最常见的机器学习问题之一。其输出是离散的类别,如"是/否"、"猫/狗/鸟"、"A/B/C类"。对于最基础的二元分类问题(例如,判断一封邮件是否为垃圾邮件),模型的所有预测结果可以归入四种情况。这四种情况共同构成了一个名为**混淆矩阵(Confusion Matrix)**的表格,它是几乎所有分类评估指标的基石。
基本概念:真正例(TP)、假正例(FP)、真负例(FN)、假负例(TN)
我们以一个"AI医生"判断病人是否患有某种疾病("阳性"为患病,"阴性"为健康)的场景为例来理解这四个概念:
- 真正例 (True Positive, TP) :病人确实 患病(真实为正),AI医生也正确 地预测其为阳性(预测为正)。------ 判断正确
- 假正例 (False Positive, FP) :病人其实 很健康(真实为负),但AI医生却错误 地预测其为阳性(预测为正)。这是"误报",也称为第一类错误 (Type I Error) 。------ 判断错误
- 真负例 (True Negative, TN) :病人确实 很健康(真实为负),AI医生也正确 地预测其为阴性(预测为负)。------ 判断正确
- 假负例 (False Negative, FN) :病人其实 患有该病(真实为正),但AI医生却错误 地预测其为阴性(预测为负)。这是"漏报",也称为第二类错误 (Type II Error) 。------ 判断错误
这四者可以用一个2x2的矩阵清晰地展示出来:
| 预测为正 (Predicted: 1) | 预测为负 (Predicted: 0) | |
|---|---|---|
| 真实为正 (Actual: 1) | TP (真正例) | FN (假负例) |
| 真实为负 (Actual: 0) | FP (假正例) | TN (真负例) |
在Scikit-learn中,我们可以轻松计算混淆矩阵:
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 使用上一章处理过的泰坦尼克数据(假设已完成缺失值填充和编码)
# 为了演示,我们简化一下特征
df = sns.load_dataset('titanic')
# ... (此处省略上一章的数据清洗和特征工程代码) ...
# 假设我们得到了一个可用的df_processed,包含特征X和目标y
# X = df_processed[['pclass', 'age_scaled', 'fare_scaled', 'is_alone', ...]]
# y = df_processed['survived']
# 伪代码演示流程
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# model = LogisticRegression()
# model.fit(X_train, y_train)
# y_pred = model.predict(X_test)
# 假设我们有真实值y_test和预测值y_pred
y_test = pd.Series([1, 0, 0, 1, 0, 1, 0, 1, 1, 0]) # 真实标签
y_pred = pd.Series([1, 0, 1, 1, 0, 0, 0, 1, 1, 0]) # 模型预测
cm = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", cm)
# 可视化混淆矩阵
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()混淆矩阵本身信息量巨大,但不够直观,我们需要从中提炼出更易于比较的单一数值指标。
从混淆矩阵到核心指标:准确率、精确率、召回率、F1分数
-
准确率 (Accuracy)
- 定义:预测正确的样本数占总样本数的比例。
- 公式 :
(TP + TN) / (TP + TN + FP + FN) - 解读:这是最直观的指标,衡量了模型"整体上做对了多少"。
- 陷阱 :在数据不平衡的场景下,准确率具有极大的误导性。例如,在一个99%的邮件都是正常邮件的数据集中,一个无脑地将所有邮件都预测为"正常"的模型,其准确率高达99%,但它毫无用处,因为它一个垃圾邮件都找不出来。
-
精确率 (Precision)
- 定义 :在所有被预测为正例 的样本中,有多少是真正的正例。
- 公式 :
TP / (TP + FP) - 解读 :它衡量的是模型的"查准率"。高精确率意味着"我预测你是正例,你大概率真的是正例"。它关心的是预测结果的质量。
- 应用场景:对"误报"惩罚很高的场景。例如,垃圾邮件过滤,我们不希望把重要的正常邮件(如面试通知)错误地判为垃圾邮件(FP),此时精确率比召回率更重要。
-
召回率 (Recall / Sensitivity / True Positive Rate)
- 定义 :在所有真实为正例 的样本中,有多少被模型成功地预测了出来。
- 公式 :
TP / (TP + FN) - 解读 :它衡量的是模型的"查全率"。高召回率意味着"所有真实的正例,我基本都找出来了"。它关心的是对真实正例的覆盖能力。
- 应用场景:对"漏报"惩罚很高的场景。例如,在疾病诊断或金融欺诈检测中,我们宁可"误报"一些健康人或正常交易(FP较高,精确率下降),也绝不希望"漏掉"一个真正的病人或欺诈行为(FN很低,召回率高)。
-
F1分数 (F1-Score)
- 定义 :精确率和召回率的调和平均数。
- 公式 :
2 * (Precision * Recall) / (Precision + Recall) - 解读:它是一个综合性指标,试图在精确率和召回率之间找到一个平衡。只有当两者都比较高时,F1分数才会高。
- 应用场景:当你希望同时关注精确率和召回率,或者当两者存在矛盾时,F1分数是一个很好的参考。
在Scikit-learn中,这些指标都可以轻松计算:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Precision:", precision_score(y_test, y_pred))
print("Recall:", recall_score(y_test, y_pred))
print("F1 Score:", f1_score(y_test, y_pred))
# 或者使用classification_report一次性输出所有指标
print("\nClassification Report:\n", classification_report(y_test, y_pred))精确率与召回率的权衡:在"宁可错杀"与"绝不放过"之间
精确率和召回率通常是一对"矛盾"的指标。
想象一下,模型在内部并不是直接输出"0"或"1",而是输出一个"是正例的概率"(0到1之间)。我们通过设定一个**阈值(Threshold)**来做出最终判断,例如,默认阈值是0.5,概率>0.5就判为1,否则为0。
-
如果我们提高阈值 (例如,提高到0.9),模型会变得非常"谨慎"。只有非常有把握的才判为正例。这样,FP会减少,精确率会提高 ;但同时,很多"有点像但把握不大"的正例会被漏掉(FN增加),导致召回率下降。这对应了"宁可错杀一千,绝不放过一个(敌人)"的反面,即"宁可放过(漏掉)一些可疑分子,也要保证抓到的都是铁证如山的真凶"。
-
如果我们降低阈值 (例如,降低到0.1),模型会变得非常"激进"。只要有一点点像正例,就判为正例。这样,FN会减少,召回率会提高 ;但同时,很多负例会被误判为正例(FP增加),导致精确率下降。这对应了"宁可错杀一千,绝不放过一个"的策略。
理解这种权衡关系至关重要。在实际应用中,我们需要根据业务需求,选择一个合适的阈值,来平衡精确率和召回率。而**精确率-召回率曲线(P-R Curve)**正是可视化这种权衡的工具。
精确率与召回率的权衡:在"宁可错杀"与"绝不放过"之间
精确率和召回率通常是一对"矛盾"的指标,它们之间存在一种此消彼长的权衡关系。理解这种权衡,是做出有效业务决策的关键。
想象一下,大多数分类模型(如逻辑回归、神经网络)在内部并不是直接输出"0"或"1"的硬性类别,而是输出一个"样本属于正例的概率",这是一个介于0和1之间的连续值。我们最终看到的"0"或"1"的预测结果,是这个概率值与一个我们设定的**决策阈值(Decision Threshold)**比较得来的。默认情况下,这个阈值通常是0.5。
- 如果
模型输出概率 > 阈值,则预测为正例(1)。- 如果
模型输出概率 <= 阈值,则预测为负例(0)。
现在,让我们看看调整这个阈值会发生什么:
-
提高决策阈值(例如,从0.5提高到0.9):
- 影响:模型会变得非常"保守"或"挑剔"。只有当它"极度确信"一个样本是正例时(概率高达90%以上),才会将其预测为正例。
- 结果 :
- 大量的"疑似"正例会被划为负例,导致假负例(FN)增加 ,从而召回率(Recall)急剧下降。
- 由于标准严苛,被预测为正例的样本,其"含金量"会很高,假正例(FP)会减少 ,从而精确率(Precision)会提高。
- 类比:"宁可放过一千,不可错杀一人"。适用于对误报(FP)容忍度极低的场景,如向用户推送高价值但打扰性强的广告。
-
降低决策阈值(例如,从0.5降低到0.1):
- 影响:模型会变得非常"激进"或"敏感"。只要有一点点可能是正例的迹象(概率超过10%),它就会将其预测为正例。
- 结果 :
- 大量的"疑似"正例会被成功捕获,假负例(FN)会减少 ,从而召回率(Recall)会提高。
- 由于标准宽松,很多负例会被错误地划入正例,假正例(FP)会增加 ,从而精确率(Precision)会下降。
- 类比:"宁可错杀一千,不可放过一个"。适用于对漏报(FN)容忍度极低的场景,如癌症筛查。
精确率-召回率曲线(Precision-Recall Curve, P-R Curve) 为了系统地观察这种权衡关系,我们可以绘制P-R曲线。该曲线的横坐标是召回率,纵坐标是精确率。它是通过从高到低移动决策阈值,在每个阈值下计算一组(Recall, Precision)值,然后将这些点连接而成。
from sklearn.metrics import precision_recall_curve
# 假设model已经训练好,并且可以输出概率
# y_scores = model.predict_proba(X_test)[:, 1] # 获取正例的概率
# 伪代码演示
y_test = pd.Series([1, 0, 0, 1, 0, 1, 0, 1, 1, 0])
y_scores = pd.Series([0.9, 0.4, 0.6, 0.8, 0.3, 0.45, 0.2, 0.85, 0.7, 0.1]) # 模型输出的概率
precisions, recalls, thresholds = precision_recall_curve(y_test, y_scores)
plt.figure(figsize=(8, 6))
plt.plot(recalls, precisions, marker='.')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.grid(True)
plt.show()一根理想的P-R曲线会尽可能地靠近右上角(即在相同的召回率下,精确率尽可能高)。曲线下方的面积(AUC-PR)也可以作为一个综合评估指标,面积越大,模型性能越好。
4.1.2 超越单一阈值:ROC曲线与AUC值的"全局观"
P-R曲线非常适合评估在不平衡数据集上的模型性能。但还有一个更常用、更通用的评估工具------ROC曲线(Receiver Operating Characteristic Curve)。
ROC曲线的绘制:真正例率(TPR) vs. 假正例率(FPR)
ROC曲线描绘了两个关键指标之间的关系:
- 真正例率 (True Positive Rate, TPR) :这其实就是我们已经学过的召回率(Recall) 。它衡量模型"抓住了多少真病人"。
TPR = TP / (TP + FN)
- 假正例率 (False Positive Rate, FPR) :它衡量的是,在所有真实的负例 中,有多少被模型错误地预测 为了正例。
FPR = FP / (FP + TN)
ROC曲线的绘制过程与P-R曲线类似,也是通过不断移动决策阈值,在每个阈值下计算一组(FPR, TPR)值,然后将这些点连接而成。
AUC的含义:模型整体排序能力的量化
-
ROC曲线解读:
- 曲线上的每个点代表一个特定的决策阈值。
- 左下角(0,0)点:阈值设为1,模型将所有样本都预测为负,TPR和FPR都为0。
- 右上角(1,1)点:阈值设为0,模型将所有样本都预测为正,TPR和FPR都为1。
- 左上角(0,1)点:理想的完美模型,FPR为0(没有误报),TPR为1(没有漏报)。
- 对角线(y=x):代表一个"随机猜测"模型。一个有价值的模型,其ROC曲线必须在对角线上方。
- 曲线越靠近左上角,说明模型在相同的"误报成本"(FPR)下,能获得更高的"查全率"(TPR),性能越好。
-
AUC (Area Under the Curve): AUC值就是ROC曲线下方的面积。它是一个介于0和1之间的数值。
- AUC = 1:完美分类器。
- AUC = 0.5:随机猜测模型。
- AUC < 0.5:模型性能差于随机猜测(可能把标签搞反了)。
- 0.5 < AUC < 1:模型具有一定的预测价值,值越大越好。
AUC有一个非常直观的统计学解释:它等于从所有正例中随机抽取一个样本,再从所有负例中随机抽取一个样本,该模型将正例的预测概率排在负例之前的概率。 因此,AUC衡量的是模型整体的排序能力,而不依赖于某个特定的决策阈值。
from sklearn.metrics import roc_curve, auc
# y_scores 同样是模型输出的正例概率
fpr, tpr, thresholds = roc_curve(y_test, y_scores)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') # 绘制对角线
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.grid(True)
plt.show()何时关注ROC/AUC,何时关注P-R曲线
- 当正负样本分布相对均衡时,ROC/AUC是一个非常稳定且全面的评估指标。
- 当处理严重的数据不平衡问题时,P-R曲线通常能提供更多的信息。因为在极不平衡的数据中,FPR的分母(FP+TN)由于TN数量巨大,即使FP显著增加,FPR的变化也可能不明显,导致ROC曲线呈现出过于"乐观"的结果。而P-R曲线的两个指标(Precision和Recall)都聚焦于正例,对正例的预测变化更为敏感。
4.1.3 回归任务的"度量尺":衡量预测的"远近"
回归任务的目标是预测一个连续值,如房价、气温。评估回归模型,就是衡量预测值 与真实值之间的"距离"或"误差"。
误差的基本度量:MAE, MSE, RMSE
假设真实值为 y,预测值为 ŷ。
-
平均绝对误差 (Mean Absolute Error, MAE)
- 公式 :
1/n * Σ|y - ŷ| - 解读:计算每个样本的预测误差的绝对值,然后取平均。它直接反映了预测误差的平均大小,单位与目标变量相同,易于理解。
- 公式 :
-
均方误差 (Mean Squared Error, MSE)
- 公式 :
1/n * Σ(y - ŷ)² - 解读 :计算每个样本的预测误差的平方,然后取平均。由于平方的存在,MSE对较大的误差(离群点)给予了更高的权重。如果你的业务场景中,大的误差是不可接受的,那么MSE是一个很好的惩罚指标。但其单位是目标变量单位的平方,不易解释。
- 公式 :
-
均方根误差 (Root Mean Squared Error, RMSE)
-
公式 :
sqrt(MSE) -
解读:它就是MSE开根号。这样做的好处是,其单位与目标变量恢复一致,同时保留了MSE对大误差敏感的特性。RMSE可能是回归任务中最常用的评估指标。
from sklearn.metrics import mean_absolute_error, mean_squared_error
y_true_reg = [3, -0.5, 2, 7]
y_pred_reg = [2.5, 0.0, 2, 8]mae = mean_absolute_error(y_true_reg, y_pred_reg)
mse = mean_squared_error(y_true_reg, y_pred_reg)
rmse = np.sqrt(mse)print(f"MAE: {mae}")
print(f"MSE: {mse}")
print(f"RMSE: {rmse}")
-
相对度量:R² (决定系数)的解释与误区
- R² (R-squared / Coefficient of Determination)
- 公式 :
1 - (Σ(y - ŷ)²) / (Σ(y - ȳ)²),其中ȳ是真实值的平均值。 - 解读 :R²衡量的是模型所解释的因变量方差的比例 。通俗地说,它表示你的模型在多大程度上"解释"了数据的变动。
- R² = 1:模型完美预测了所有数据。
- R² = 0:模型的表现等同于一个"基准模型",这个基准模型总是预测所有样本的值为真实值的平均数。
- R² < 0:模型表现比基准模型还差。
- 优点:提供了一个相对的性能度量(0%到100%),不受目标变量尺度的影响。
- 误区 :R²有一个致命缺陷------当你向模型中添加任何新的特征时,即使这个特征毫无用处,R²的值也几乎总是会增加或保持不变,绝不会下降。这使得它在比较包含不同数量特征的模型时具有误导性。为此,**调整R² (Adjusted R-squared)**被提出,它对特征的数量进行了惩罚,是一个更公允的指标。
- 公式 :
4.1.4 无监督任务的"内省":聚类效果的评估
评估聚类(Clustering)这类无监督任务比监督学习更具挑战性,因为我们通常没有"正确答案"(真实标签)。评估方法分为两类:
有真实标签时(外部评估)
在某些特殊情况(如学术研究或验证算法),我们手头有数据的真实类别。此时,我们可以比较聚类结果和真实标签的吻合程度。
- 兰德指数 (Rand Index, RI):衡量两组聚类(预测的和真实的)中,所有"点对"分类一致性的比例。
- 互信息 (Mutual Information, MI):从信息论角度衡量两组聚类共享的信息量。
无真实标签时(内部评估)
这是更常见的情况。内部评估仅利用数据本身和聚类结果来进行。
-
轮廓系数 (Silhouette Coefficient) :这是最常用、最直观的内部评估指标。它为每一个样本计算一个轮廓分数,该分数衡量:
a: 该样本与其所在簇内其他所有点的平均距离(簇内凝聚度)。b: 该样本与距离它最近的下一个簇 内所有点的平均距离(簇间分离度)。- 轮廓分数 =
(b - a) / max(a, b) - 解读 :
- 分数接近 +1:说明样本远离相邻簇,很好地被分配到了当前簇(凝聚度和分离度都好)。
- 分数接近 0:说明样本位于两个簇的边界上。
- 分数接近 -1:说明样本可能被分配到了错误的簇。
- 整个数据集的轮廓系数是所有样本轮廓分数的平均值。
-
Calinski-Harabasz指数 (CH Index) :通过计算簇间散度 与簇内散度的比值来评估。比值越大,意味着簇间分离得越远,簇内凝聚得越紧,聚类效果越好。
from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans假设X_cluster是待聚类的数据
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
labels = kmeans.fit_predict(X_cluster)
score = silhouette_score(X_cluster, labels)
print(f"Silhouette Score: {score}")
4.2 "执其两端而用中":偏差与方差的权衡
掌握了评估指标,我们就有了一把尺子。但有时我们会发现,模型在一个数据集上表现优异,换个数据集就一塌糊涂。这背后,是所有监督学习模型都必须面对的一对核心矛盾------偏差(Bias)与方差(Variance)。
4.2.1 模型的两种"原罪":偏差(Bias)与方差(Variance)
想象我们用不同的训练数据集(来自同一数据源)多次训练同一个模型,然后去预测同一个测试点。
- 偏差 :描述的是模型所有预测值的平均值 与真实值之间的差距。高偏差意味着模型系统性地偏离了真相。
- 方差 :描述的是模型不同次预测值之间的离散程度或散布范围。高方差意味着模型对训练数据的微小变化极其敏感。
一个好的模型,应该既没有系统性的偏离(低偏差),又对数据的扰动不那么敏感(低方差)。
偏差:模型对真相的"固有偏见"
高偏差的根本原因是模型过于简单,无法捕捉数据中复杂的真实规律。它就像一个固执的"老学究",脑子里只有几条简单的规则(如一条直线),试图用它去解释一个复杂的世界(如一条曲线)。无论给他多少数据,他都坚持自己的"偏见"。
方差:模型对数据的"过度敏感"
高方差的根本原因是模型过于复杂 ,它不仅学习了数据中普适的规律,还把训练数据中的噪声和随机性也当作了"真理"来学习。它就像一个"书呆子",把训练集这本"教科书"背得滚瓜烂熟,每一个细节都记得清清楚楚,但缺乏举一反三的能力。换一本"模拟试卷"(测试集),他就傻眼了。
4.2.2 欠拟合与过拟合:模型学习的"执念"与"妄念"
偏差和方差的概念,最终体现在模型的两种常见状态上:
欠拟合(Underfitting):学得太少,想得太简单(高偏差)
- 表现 :模型在训练集 上的表现就很差,在测试集上的表现同样很差。
- 原因:通常是模型复杂度太低(如用线性模型去拟合非线性数据),或者特征太少。
过拟合(Overfitting):学得太细,想得太复杂(高方差)
- 表现 :模型在训练集 上表现极好,甚至接近完美,但在测试集上的表现却大幅下降。训练集和测试集性能之间存在巨大鸿沟。
- 原因:通常是模型复杂度过高(如一个深度很深的决策树),或者数据量相对于模型复杂度来说太少。
偏差-方差权衡(Bias-Variance Trade-off): 模型复杂度与这两者之间存在一个U型关系。
- 非常简单的模型:高偏差,低方差。
- 非常复杂的模型:低偏差,高方差。 我们的目标,是在这个U型曲线的谷底找到一个平衡点,使得总误差(约等于 偏差² + 方差)最小。
4.2.3 诊断之道:学习曲线的可视化解读
如何判断我们的模型正处于欠拟合、过拟合还是理想状态?**学习曲线(Learning Curves)**是一个强大的诊断工具。
学习曲线展示的是,随着训练样本数量的增加 ,模型的训练集得分 和验证集得分如何变化。
绘制学习曲线:训练集与验证集得分随样本量变化的轨迹
from sklearn.model_selection import learning_curve
# model = LogisticRegression() # 或其他任何模型
# train_sizes, train_scores, validation_scores = learning_curve(
# estimator=model,
# X=X, y=y,
# train_sizes=np.linspace(0.1, 1.0, 10), # 训练样本的比例
# cv=5, # 交叉验证折数
# scoring='accuracy' # 评估指标
# )
# # 计算均值和标准差
# train_scores_mean = np.mean(train_scores, axis=1)
# validation_scores_mean = np.mean(validation_scores, axis=1)
# # 绘制曲线
# plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")
# plt.plot(train_sizes, validation_scores_mean, 'o-', color="g", label="Cross-validation score")
# plt.title("Learning Curve")
# plt.xlabel("Training examples")
# plt.ylabel("Score")
# plt.legend(loc="best")
# plt.grid()
# plt.show()从曲线形态诊断模型是"欠"还是"过"
-
理想状态:
- 随着样本增加,训练得分和验证得分都逐渐升高并最终收敛。
- 收敛时,两条曲线靠得很近,且得分都很高。
-
高偏差(欠拟合):
- 两条曲线很早就收敛了,且收敛到一个比较低的得分水平。
- 两条曲线靠得很近。
- 解读:模型太简单了,即使给它再多的数据,它也学不到更多东西了。性能的瓶颈在于模型本身。
-
高方差(过拟合):
- 训练得分一直很高,而验证得分一直比较低。
- 两条曲线之间存在明显的、持续的差距(Gap)。
- 解读 :模型在训练集上"死记硬背",但泛化能力差。好消息是,随着样本量的增加,这个差距有缩小的趋势,说明增加数据量可能有助于缓解过拟合。
4.2.4 应对之策:降低偏差与方差的常用策略
-
解决高偏差(欠拟合):
- 增加模型复杂度:换用更强大的模型(如从线性模型换到梯度提升树或神经网络)。
- 获取或创造更多特征:让模型有更多的信息来源来学习。
- 减少正则化:正则化是用来对抗过拟合的,如果模型已经欠拟合,应减小正则化强度。
-
解决高方差(过拟合):
- 增加数据量:这是最有效但往往也最昂贵的方法。
- 降低模型复杂度:使用更简单的模型,或者减少现有模型的参数(如降低决策树的深度)。
- 正则化(Regularization):在损失函数中加入一个惩罚项,对模型的复杂性(如大的权重)进行惩罚。L1和L2正则化是经典方法。
- 特征选择/降维:移除不相关或冗余的特征。
- 集成学习(Ensemble Methods):如Bagging(随机森林),通过平均多个不同模型的结果来降低方差。
- Dropout(主要用于神经网络):在训练过程中随机"丢弃"一部分神经元,强迫网络学习更鲁棒的特征。
4.3 "他山之石":交叉验证的智慧
在诊断模型的过程中,我们反复提到了"验证集"。一个常见的做法是将数据一次性划分为训练集、验证集和测试集。但这种方法存在一个严重问题。
4.3.1 为何需要交叉验证?简单"训练/测试集"划分的陷阱
- 数据划分的偶然性:你碰巧分到验证集里的数据可能特别"简单"或特别"困难",导致你对模型性能的评估过于乐观或悲观。换一种随机划分方式,结果可能截然不同。
- 评估结果的不稳定:基于一次划分的评估结果,其随机性太大,不够可靠。
- 数据浪费:在数据量本就不多的情况下,留出一部分数据只用于验证,是一种浪费。
**交叉验证(Cross-Validation, CV)**正是为了解决这些问题而生的智慧。
4.3.2 K-折交叉验证(K-Fold Cross-Validation):让每一份数据都发光
K-折交叉验证是应用最广泛的交叉验证技术。
K-折的执行流程:分割、训练、验证、取平均
- 分割:将整个训练数据集随机地、不重复地划分为K个大小相似的子集(称为"折",Fold)。
- 循环 :进行K次循环,在每一次循环中:
- 取其中1个折 作为验证集。
- 取其余的K-1个折 合并作为训练集。
- 在该训练集上训练模型,并在该验证集上进行评估,得到一个性能得分。
- 取平均:将K次循环得到的K个性能得分进行平均,得到最终的、更稳健的交叉验证得分。
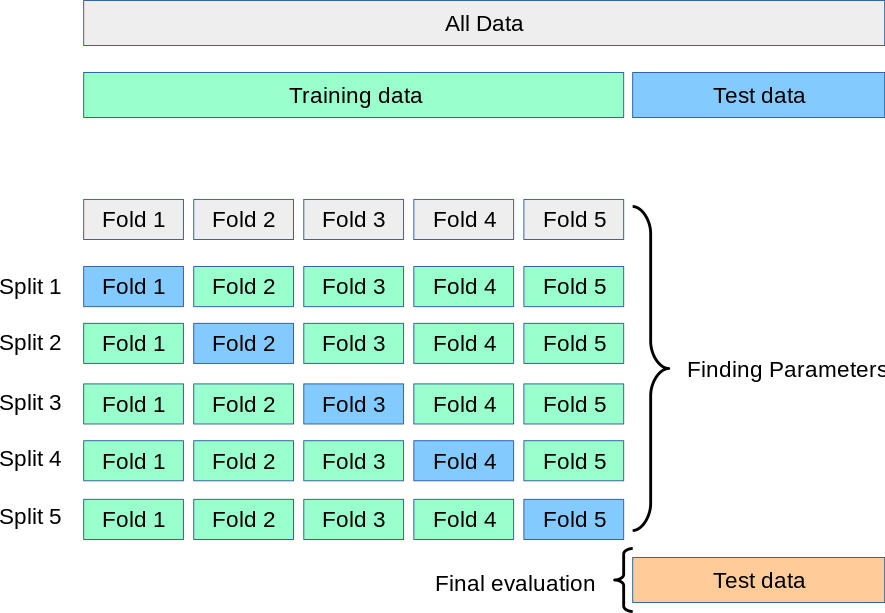
优点:
- 所有数据都参与了训练和验证,数据利用率高。
- 得到的评估结果是K次评估的平均值,大大降低了偶然性,更为稳定和可靠。
如何选择合适的K值?
K的常用取值是5 或10。
- K值较小(如3):每次训练的数据量较少(2/3),验证集较大(1/3)。偏差较高,方差较低,计算成本也低。
- K值较大(如10):每次训练的数据量较多(9/10),更接近于在全部数据上训练。偏差较低,但由于不同折的训练集重合度高,K个模型会比较相似,导致最终评估结果的方差可能较高。计算成本也更高。
4.3.3 特殊场景下的变体:分层K-折与留一法
分层K-折(Stratified K-Fold):处理不平衡分类问题的利器
在分类问题中,如果直接用标准K-Fold,可能会出现某个折中正例或负例的比例与整体数据集差异很大的情况,甚至某个折中完全没有某个类别的样本。
分层K-折 在进行数据划分时,会确保每一个折中各个类别的样本比例都与原始数据集中相应类别的比例大致相同。在处理不平衡分类问题时,这几乎是必须使用的交叉验证方法。
留一法(Leave-One-Out, LOO):K-折的极端形式及其优缺点
留一法是K-折交叉验证的一个特例,即K=N(N为样本总数)。每次只留下一个样本作为验证集,其余N-1个样本都作为训练集。
- 优点:数据利用率最高,评估结果的偏差最低。
- 缺点:计算成本极高(需要训练N个模型),且评估结果的方差通常也较高。一般只在数据集非常小的情况下使用。
4.4 "寻路":网格搜索与超参数调优
我们已经知道如何可靠地评估一个模型了。但一个模型的性能,还受到另一类参数的深刻影响------超参数。
4.4.1 参数 vs. 超参数:模型自身的"修行"与我们施加的"点化"
- 参数 (Parameters) :模型从数据中学习 得到的值。例如,线性回归的权重
w和偏置b。我们无法手动设置它们,它们是训练过程的结果。 - 超参数 (Hyperparameters) :我们在模型训练之前手动设置 的参数。它们是模型的"配置选项",控制着学习过程的行为。例如:
- K近邻算法中的
K值。 - 决策树的
max_depth(最大深度)。 - SVM中的惩罚系数
C和核函数kernel。 - 神经网络的学习率
learning_rate。
- K近邻算法中的
**超参数调优(Hyperparameter Tuning)**的目的,就是为我们的模型找到一组能使其性能最佳的超参数组合。
4.4.2 传统的寻路者:网格搜索(Grid Search)
网格搜索是一种简单粗暴但有效的超参数搜索方法。
定义参数网格与暴力搜索
- 定义网格:为每一个你想要调优的超参数,定义一个候选值列表。这些列表组合在一起,就形成了一个多维的"网格"。
- 暴力搜索:遍历网格中每一个可能的超参数组合。对每一个组合,使用交叉验证来评估其性能。
- 选择最优:选择那个在交叉验证中平均得分最高的超参数组合。
网格搜索与交叉验证的结合(GridSearchCV)
Scikit-learn提供了GridSearchCV这个强大的工具,将网格搜索和交叉验证完美地结合在了一起。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
# 1. 定义模型
model = SVC()
# 2. 定义超参数网格
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': [1, 0.1, 0.01, 0.001],
'kernel': ['rbf', 'linear']
}
# 3. 创建GridSearchCV对象
# cv=5表示使用5折交叉验证
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy', verbose=2)
# 4. 执行搜索 (在训练数据上)
# grid_search.fit(X_train, y_train)
# 5. 查看最佳参数和最佳得分
# print("Best Parameters:", grid_search.best_params_)
# print("Best Score:", grid_search.best_score_)
# 6. 获取最佳模型
# best_model = grid_search.best_estimator_网格搜索的"维度诅咒"
网格搜索的主要缺点是计算成本高。如果超参数数量增多,或者每个超参数的候选值增多,需要尝试的组合数量会呈指数级增长,这就是所谓的"维度诅咒"。
4.4.3 更聪明的探索者:随机搜索(Random Search)
随机搜索是对网格搜索的一个简单而又常常更高效的替代方案。
从"地毯式"到"撒胡椒面式"的转变
随机搜索不再尝试所有可能的组合,而是在指定的参数分布(如一个列表或一个连续分布)中,随机地采样 固定数量(由n_iter参数指定)的超参数组合。
为何随机搜索常常更高效?
研究表明,对于很多模型来说,其性能主要由少数几个"关键"超参数决定。
- 网格搜索可能会在那些不重要的超参数上浪费大量时间进行精细的、不必要的尝试。
- 随机搜索则更有可能在相同的计算预算内,在那些"关键"超参数上探索到更多样化的值,从而有更大几率找到一个优秀的组合。
在Scikit-learn中,使用RandomizedSearchCV,其用法与GridSearchCV非常相似。
4.4.4 前沿的向导:贝叶斯优化等高级方法简介
当超参数搜索的成本极高时(例如,训练一个深度学习模型可能需要数天),网格搜索和随机搜索这种"盲目"的探索就显得效率低下了。
贝叶斯优化的思想:利用先验信息指导下一次尝试
贝叶斯优化是一种更智能的搜索策略。它将超参数与模型性能的关系看作一个需要学习的函数。
- 它首先尝试几个随机点。
- 然后,它根据已有的(超参数组合,性能得分)结果,建立一个概率模型(代理模型),来"猜测"这个未知函数的样子。
- 接着,它利用这个代理模型,去选择下一个最有可能带来性能提升的超参数组合进行尝试(而不是随机选)。
- 不断重复2和3,直到达到预设的迭代次数。
它就像一个聪明的探矿者,会根据已经挖到的矿石信息,来判断下一铲子应该挖在哪里,而不是到处乱挖。
何时考虑使用更高级的调优方法
当单次模型评估的成本非常高昂,且超参数空间复杂时,就应该考虑使用贝叶斯优化(如hyperopt, scikit-optimize等库)或其更先进的变体。
结语
本章,我们打造了一套完整的模型评估与选择的"罗盘"。我们学会了如何用精确的"度量衡"来衡量模型,如何洞察"偏差与方差"这对核心矛盾,如何用"交叉验证"的智慧获得可靠的评估,以及如何用"网格/随机搜索"的策略为模型找到最佳的"配置"。
这套框架是独立于任何具体模型的通用方法论。掌握了它,您就拥有了在算法海洋中自信航行的能力。从下一章开始,我们将正式扬帆起航,逐一探索那些主流的机器学习模型。届时,本章所学的一切,都将成为我们评估、诊断和优化这些模型的强大武器。
第二部分:术法万千------主流机器学习模型详解
核心目标: 深入剖析各类主流算法的原理、数学基础和代码实现。强调每个模型的适用场景、优缺点,并结合实例进行"庖丁解牛"式的讲解。
第五章:监督学习之"判别"------分类算法
- 5.1 逻辑回归:看似回归,实为分类的智慧
- 5.2 K-近邻(KNN):"物以类聚,人以群分"的朴素哲学
- 5.3 支撑向量机(SVM):"一划开天"的数学之美
- 5.4 决策树与随机森林:"集思广益"的集成智慧
- 5.5 朴素贝叶斯:"执果索因"的概率思维
欢迎来到机器学习的核心腹地。从本章开始,我们将学习具体的算法,将前几章的理论、工具与方法论付诸实践。我们将从监督学习中的**分类(Classification)**任务开始。分类,顾名思义,就是让机器学会"分辨类别",它旨在预测一个离散的目标变量。
生活中的分类问题无处不在:判断一封邮件是否为垃圾邮件,识别一张图片中的动物是猫还是狗,评估一笔交易是否存在欺诈风险,或者预测一位客户是否会流失。这些都是分类算法大显身手的舞台。
本章将介绍五种最经典、最基础、也是应用最广泛的分类算法。它们各自代表了一种独特的解决问题的哲学:逻辑回归的概率建模 、K-近邻的类比推理 、支撑向量机的几何间隔 、决策树的逻辑规则 以及朴素贝叶斯的概率推断。
学习这些算法时,请重点关注:
- 它的核心思想是什么?
- 它是如何学习和预测的?
- 它的关键超参数有哪些,分别控制什么?
- 它的优缺点是什么,适用于哪些场景?
掌握了这些,您便能像一位经验丰富的工匠,为不同的任务选择最合适的工具。
5.1 逻辑回归:看似回归,实为分类的智慧
逻辑回归(Logistic Regression)是您在分类领域遇到的第一个,也可能是最重要的算法之一。它的名字里虽然带有"回归",但请不要被误导,它是一个地地道道的分类算法。它因其简单、高效、可解释性强且输出结果为概率而备受青睐,常常被用作解决实际问题的首选基线模型。
5.1.1 从线性回归到逻辑回归:跨越"预测值"到"预测概率"的鸿沟
要理解逻辑回归,最好的方式是从我们熟悉的线性回归出发。线性回归的目标是拟合一条直线(或超平面)来预测一个连续值,其公式为: ŷ = w₀ + w₁x₁ + w₂x₂ + ... + wₙxₙ
线性回归的局限性 那我们能否直接用它来做分类呢?比如,我们规定 ŷ > 0.5 就判为类别1,否则为类别0。这样做有两个致命问题:
- 输出范围不匹配 :线性回归的输出
ŷ是一个实数,范围是(-∞, +∞)。而我们想要的分类结果,最好是一个表示"概率"的、在(0, 1)区间内的值。直接比较ŷ和0.5,物理意义不明确。 - 对离群点敏感:如果在数据中加入一个x值很大的离群点,线性回归的拟合直线会被严重"拉偏",可能导致原本正确的决策边界发生巨大偏移,造成错误的分类。
我们需要一个"转换器",能将线性回归 (-∞, +∞) 的输出,优雅地"压缩"到 (0, 1) 的概率区间内。
Sigmoid函数的引入 这个神奇的"转换器"就是Sigmoid函数 (也称Logistic函数),它的数学形式如下: σ(z) = 1 / (1 + e⁻ᶻ)
这里的 z 就是我们线性回归的输出 w₀ + w₁x₁ + ...。Sigmoid函数具有非常优美的S型曲线形态:
- 无论输入
z多大或多小,其输出σ(z)始终在(0, 1)区间内。 - 当
z = 0时,σ(z) = 0.5。 - 当
z -> +∞时,σ(z) -> 1。 - 当
z -> -∞时,σ(z) -> 0。
通过将线性回归的输出 z 作为Sigmoid函数的输入,我们就构建了逻辑回归的核心模型: P(y=1 | X) = σ(z) = 1 / (1 + e⁻(wᵀX + b)) 这个公式的含义是:在给定特征 X 的条件下,样本类别 y 为1的概率。
5.1.2 模型解读:概率、决策边界与损失函数
概率的解释 逻辑回归的输出 P(y=1|X) 是一个真正的概率值,这极具价值。例如,一个癌症预测模型输出0.9,意味着它有90%的把握认为该病人患有癌症。这个概率值本身就可以用于风险排序、设定不同的告警级别等。 有了概率,分类就变得顺理成章:
- 如果
P(y=1|X) > 0.5,则预测为类别1。 - 如果
P(y=1|X) <= 0.5,则预测为类别0。
决策边界(Decision Boundary) 决策边界是模型在特征空间中将不同类别分开的那条"线"或"面"。对于逻辑回归,当 P(y=1|X) = 0.5 时,分类结果处于临界状态。这对应于 σ(z) = 0.5,也就是 z = wᵀX + b = 0。 所以,逻辑回归的决策边界就是由 wᵀX + b = 0 这条方程所定义的线性边界。
- 在二维空间中,它是一条直线。
- 在三维空间中,它是一个平面。
- 在高维空间中,它是一个超平面。
重要 :逻辑回归本身是一个线性分类器,它的决策边界是线性的。如果数据的真实边界是非线性的,基础的逻辑回归模型将表现不佳。(当然,通过特征工程,如添加多项式特征,可以使其学习非线性边界)。
损失函数 模型如何学习到最优的权重 w 和偏置 b 呢?它需要一个**损失函数(Loss Function)**来衡量当前模型的预测与真实标签之间的"差距",然后通过优化算法(如梯度下降)来最小化这个损失。
对于逻辑回归,我们不能使用线性回归的均方误差(MSE),因为它会导致一个非凸的损失函数,优化起来非常困难。我们使用的是对数损失(Log Loss) ,也称为二元交叉熵损失(Binary Cross-Entropy Loss)。
对于单个样本,其损失定义为:
- 如果真实标签
y = 1:Loss = -log(p),其中p是模型预测为1的概率。 - 如果真实标签
y = 0:Loss = -log(1-p)。
直观理解:
- 当真实标签是1时,我们希望预测概率
p越接近1越好。如果p趋近于1,-log(p)就趋近于0,损失很小。如果模型错误地预测p趋近于0,-log(p)会趋近于无穷大,给予巨大的惩罚。 - 当真实标签是0时,情况正好相反。
这个分段函数可以优雅地写成一个统一的式子: Loss = -[y * log(p) + (1 - y) * log(1 - p)] 整个训练集的总损失就是所有样本损失的平均值。模型训练的目标,就是找到一组 w 和 b,使得这个总损失最小。
5.1.3 Scikit-learn实战与正则化
代码实现 在Scikit-learn中,使用逻辑回归非常简单。我们将以一个标准流程来展示其应用,这个流程也适用于后续将要学习的大多数模型。
# 导入必要的库
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.preprocessing import StandardScaler
import pandas as pd
import seaborn as sns
import numpy as np
# --- 准备数据 (假设使用泰坦尼克数据集) ---
# 为了代码能独立运行,我们快速进行一次极简的数据预处理
df = sns.load_dataset('titanic')
df.drop(['deck', 'embark_town', 'alive', 'who', 'adult_male', 'class'], axis=1, inplace=True)
df['age'].fillna(df['age'].median(), inplace=True)
df['embarked'].fillna(df['embarked'].mode()[0], inplace=True)
df = pd.get_dummies(df, columns=['sex', 'embarked'], drop_first=True)
df.drop('name', axis=1, inplace=True) # 名字暂时不用
df.drop('ticket', axis=1, inplace=True) # 票号暂时不用
X = df.drop('survived', axis=1)
y = df['survived']
# 1. 划分数据
# stratify=y 确保训练集和测试集中,目标变量y的类别比例与原始数据一致,这在分类问题中很重要
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# 2. 特征缩放 (对于逻辑回归,特别是带正则化的,这是个好习惯)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 3. 初始化并训练模型
# penalty='l2'表示使用L2正则化,C是正则化强度的倒数
# solver='liblinear' 是一个适用于小数据集的优秀求解器
model = LogisticRegression(penalty='l2', C=1.0, solver='liblinear', random_state=42)
model.fit(X_train_scaled, y_train)
# 4. 预测与评估
y_pred = model.predict(X_test_scaled)
print("--- 逻辑回归基础模型评估 ---")
print("混淆矩阵:\n", confusion_matrix(y_test, y_pred))
print("\n分类报告:\n", classification_report(y_test, y_pred))
# 查看模型学习到的系数
# feature_names = X.columns
# coefs = pd.Series(model.coef_[0], index=feature_names).sort_values()
# print("\n模型系数:\n", coefs)正则化参数(C) 逻辑回归很容易过拟合,特别是当特征数量很多时。为了对抗过拟合,我们引入正则化 。LogisticRegression类中最关键的超参数就是C和penalty。
penalty:指定使用哪种正则化,通常是'l1'或'l2'。- L2正则化(默认):惩罚那些值很大的权重,使得所有权重都趋向于变小,但不会变为0。它让模型的决策边界更平滑。
- L1正则化 :同样惩罚大权重,但它有一个特性,就是能将一些不重要的特征的权重直接惩罚为0,从而实现特征选择。
C:正则化强度的倒数 。它是一个正浮点数。- C值越小 ,代表正则化惩罚越强,模型会更简单,有助于防止过拟合(增加偏差,降低方差)。
- C值越大 ,代表正则化惩罚越弱,模型会更努力地去拟合训练数据,可能导致过拟合(降低偏差,增加方差)。
C是我们需要通过交叉验证来调优的最重要的超参数。下面我们使用GridSearchCV来寻找最优的C值。
# --- 使用GridSearchCV进行超参数调优 ---
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100]}
grid_search = GridSearchCV(LogisticRegression(penalty='l2', solver='liblinear', random_state=42),
param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train_scaled, y_train)
print("\n--- 逻辑回归超参数调优 ---")
print("最佳超参数:", grid_search.best_params_)
print("交叉验证最佳得分:", grid_search.best_score_)
# 使用最佳模型进行最终评估
best_model = grid_search.best_estimator_
y_pred_best = best_model.predict(X_test_scaled)
print("\n最佳模型在测试集上的分类报告:\n", classification_report(y_test, y_pred_best))优缺点与适用场景
- 优点 :
- 简单快速:训练速度快,计算成本低,易于实现。
- 可解释性强 :可以查看每个特征的权重
coef_,理解特征对结果的影响方向和大小,便于向业务方解释。 - 输出概率:结果为概率,而不仅仅是类别,这在很多场景下(如风险评估)非常有用。
- 应用广泛:是许多工业界应用(如广告点击率预测、金融风控)的基石和首选基线模型。
- 缺点 :
- 线性模型:模型假设是线性的,容易欠拟合,无法直接捕捉数据中的非线性关系。
- 对特征工程依赖高:需要手动创造特征(如多项式特征)来帮助模型学习非线性。
- 对多重共线性敏感:如果特征之间高度相关,模型权重的解释性会下降。
适用场景:
- 作为任何分类问题的首选基线模型(Baseline Model)。在尝试复杂模型前,先用逻辑回归跑一个结果,可以帮你判断问题的难度,并为后续优化提供一个比较的基准。
- 当需要一个可解释的模型时。
- 当需要预测概率时。
- 对于大规模稀疏数据(如文本分类后的词袋模型),逻辑回归配合L1正则化常常表现出色。
5.2 K-近邻(KNN):"物以类聚,人以群分"的朴素哲学
K-近邻(K-Nearest Neighbors, KNN)算法是机器学习中最简单、最直观的算法之一。它的核心思想完美地诠释了中国的一句古话:"物以类聚,人以群分"。要判断一个未知样本的类别,只需看看它在特征空间中的"邻居"们都属于哪个类别即可。
5.2.1 算法核心思想:近朱者赤,近墨者黑
"懒惰学习"的代表 KNN是一种**懒惰学习(Lazy Learning)或称基于实例的学习(Instance-based Learning)**算法。它与其他我们即将学习的算法(如逻辑回归、SVM)有一个根本区别:
- 它没有传统意义上的"训练"过程。所谓的"训练",仅仅是把所有训练数据加载到内存中而已。它不会从数据中学习一个判别函数或模型参数。
- 真正的计算发生在"预测"阶段。当一个新样本需要被预测时,KNN才会开始工作。
三个核心要素 KNN的预测过程由三个核心要素决定:
- K值的选择:我们要看新样本周围的多少个"邻居"。K是一个正整数。
- 距离度量:我们如何定义和计算样本之间的"远近"。
- 决策规则 :根据K个邻居的类别,如何做出最终的判决。最常见的是多数表决(Majority Voting)。
预测步骤:
- 计算未知样本与训练集中每一个样本之间的距离。
- 找出距离最近的K个训练样本(即K个"邻居")。
- 统计这K个邻居的类别。
- 将出现次数最多的那个类别,作为未知样本的预测结果。
5.2.2 距离的度量与K值的选择
常见的距离公式 距离度量是KNN的基石。最常用的距离是欧氏距离(Euclidean Distance) ,也就是我们初中就学过的两点间直线距离公式。 对于两个n维向量 x 和 y: d(x, y) = sqrt(Σ(xᵢ - yᵢ)²)
此外,还有其他距离度量方式,如:
- 曼哈顿距离(Manhattan Distance) :
d(x, y) = Σ|xᵢ - yᵢ|,想象在城市街区中只能沿格线行走时的距离。 - 闵可夫斯基距离(Minkowski Distance):是欧氏距离和曼哈顿距离的推广。
K值选择的艺术 K值的选择对KNN的性能至关重要,它直接影响着模型的偏差和方差。
- 较小的K值 (如 K=1):
- 模型非常"敏感",容易受到噪声点的影响。
- 决策边界会变得非常复杂、不规则。
- 这会导致低偏差 ,但高方差 ,容易过拟合。
- 较大的K值 (如 K=N,N为训练样本总数):
- 模型非常"迟钝",无论新样本在哪里,都会被预测为训练集中数量最多的那个类别。
- 决策边界会变得非常平滑。
- 这会导致高偏差 ,但低方差 ,容易欠拟合。
因此,选择一个合适的K值是在偏差和方差之间做权衡。通常,我们会通过交叉验证来寻找一个最优的K值。一个经验法则是,K值通常选择一个较小的奇数(以避免投票时出现平局)。
5.2.3 Scikit-learn实战与数据标准化的重要性
代码实现
from sklearn.neighbors import KNeighborsClassifier
# 假设X_train_scaled, X_test_scaled, y_train, y_test已准备好
# 初始化并训练模型 (fit只是存储数据)
knn = KNeighborsClassifier(n_neighbors=5) # 先选择一个经验值K=5
knn.fit(X_train_scaled, y_train)
# 预测与评估
y_pred_knn = knn.predict(X_test_scaled)
print("--- KNN基础模型评估 (K=5) ---")
print(classification_report(y_test, y_pred_knn))
# 使用GridSearchCV寻找最优K值
param_grid_knn = {'n_neighbors': np.arange(1, 31, 2)} # 尝试1到30之间的所有奇数
grid_search_knn = GridSearchCV(KNeighborsClassifier(), param_grid_knn, cv=5, scoring='accuracy')
grid_search_knn.fit(X_train_scaled, y_train)
print("\n--- KNN超参数调优 ---")
print("最佳K值:", grid_search_knn.best_params_)
print("交叉验证最佳得分:", grid_search_knn.best_score_)数据标准化的必要性 对于KNN这类基于距离度量的模型,进行特征缩放(如标准化)是至关重要的,甚至是强制性的。
想象一个场景,我们有两个特征:年龄(范围20-80)和薪水(范围5000-50000)。在计算欧氏距离时,薪水这个特征的数值差异会远远大于年龄的差异,从而在距离计算中占据绝对主导地位。这会使得年龄这个特征几乎不起作用,这显然是不合理的。
通过标准化(StandardScaler),我们将所有特征都转换到同一个尺度下(均值为0,标准差为1),使得每个特征在距离计算中都有平等"话语权"。
优缺点与适用场景
- 优点 :
- 思想简单,易于理解和实现。
- 模型灵活:可以学习任意复杂的决策边界。
- 无需训练:对于需要快速上线、数据不断更新的场景有优势。
- 缺点 :
- 计算成本高昂:预测一个新样本需要与所有训练样本计算距离,当训练集很大时,非常耗时。
- 对内存需求大:需要存储整个训练集。
- 对不平衡数据敏感:数量多的类别在投票中占优势。
- 对维度诅咒敏感:在高维空间中,所有点之间的距离都趋向于变得遥远且相近,"邻居"的概念变得模糊。
适用场景:
- 小到中等规模的数据集。
- 当问题的决策边界高度非线性时。
- 作为一种快速的基线模型。
5.3 支撑向量机(SVM):"一划开天"的数学之美
支撑向量机(Support Vector Machine, SVM)是机器学习领域最强大、最优雅的算法之一。它诞生于上世纪90年代,在深度学习浪潮来临之前,曾一度被认为是监督学习中效果最好的"大杀器"。SVM的核心思想是基于几何间隔,寻找一个"最优"的决策边界。
5.3.1 核心思想:寻找最大间隔的"最优"决策边界
对于一个线性可分的二分类问题,能将两类样本分开的直线(或超平面)有无数条。逻辑回归会找到其中一条,但SVM追求的是最好的那一条。
什么是"最好"? SVM认为,最好的决策边界应该是那条离两边最近的样本点最远的边界。这条边界就像在两军对垒的战场中央划下的一道"停火线",它使得双方(不同类别的样本)都离这条线有尽可能大的"缓冲地带"。
间隔(Margin)与支持向量(Support Vectors)
- 决策边界 :就是中间那条实线的超平面
wᵀx + b = 0。 - 间隔(Margin) :是决策边界与两侧距离它最近的样本点之间的垂直距离。SVM的目标就是最大化这个间隔。
- 支持向量(Support Vectors) :那些恰好落在间隔边界上 的样本点。它们就像支撑起整个间隔的"桩子"。一个惊人的事实是:最终的决策边界完全由这些支持向量决定,与其他样本点无关。即使移动或删除非支持向量的样本点,决策边界也不会改变。这使得SVM非常高效且鲁棒。
从线性可分到线性不可分:软间隔(Soft Margin) 现实世界的数据往往不是完美线性可分的,总会有一些噪声点或"越界"的样本。为了处理这种情况,SVM引入了**软间隔(Soft Margin)**的概念。
软间隔允许一些样本点"犯规",即可以处在间隔之内,甚至可以被错误分类。但这种"犯规"是要付出代价的。SVM引入了一个惩罚系数超参数 C:
C控制了我们对"犯规"的容忍程度。- 较大的C值 :代表对犯规的惩罚很重,SVM会努力将所有样本都正确分类,这可能导致间隔变窄,模型变得复杂,容易过拟合。
- 较小的C值 :代表对犯规比较宽容,允许一些错误分类,以换取一个更宽的间隔。这会使模型更简单,泛化能力可能更强,但可能欠拟合。
C是在偏差和方差之间进行权衡的关键。
5.3.2 核技巧(Kernel Trick):低维到高维的"乾坤大挪移"
SVM最强大的武器是核技巧(Kernel Trick) 。对于那些在原始特征空间中线性不可分的数据(例如,一个环形分布),SVM可以通过核技巧,巧妙地将其映射到一个更高维度的空间,使得数据在这个高维空间中变得线性可分。
核函数的魔力 想象一下,我们把二维平面上的一张纸(数据),通过某种方式向上"弯曲",变成一个三维的碗状。原本在纸上无法用一条直线分开的同心圆,在三维空间中就可以用一个水平面轻易地分开了。
核函数的神奇之处在于:它让我们无需真正地去计算数据在高维空间中的坐标,就能得到数据点在高维空间中的内积结果。这极大地节省了计算量,使得在高维空间中寻找决策边界成为可能。
常见的核函数
- 线性核(Linear Kernel) :
kernel='linear'。实际上就是不做任何映射,在原始空间中寻找线性边界。 - 多项式核(Polynomial Kernel) :
kernel='poly'。可以将数据映射到多项式空间。 - 高斯径向基核(Gaussian Radial Basis Function, RBF) :
kernel='rbf'。这是最常用、最强大 的核函数。它可以将数据映射到无限维空间,能够学习任意复杂的非线性决策边界。
5.3.3 Scikit-learn实战与关键超参数
代码实现
from sklearn.svm import SVC
# 假设X_train_scaled, X_test_scaled, y_train, y_test已准备好
# 初始化并训练模型 (使用RBF核)
svm_model = SVC(kernel='rbf', C=1.0, gamma='scale', random_state=42)
svm_model.fit(X_train_scaled, y_train)
# 预测与评估
y_pred_svm = svm_model.predict(X_test_scaled)
print("--- SVM基础模型评估 ---")
print(classification_report(y_test, y_pred_svm))
# 使用GridSearchCV进行超参数调优
param_grid_svm = {
'C': [0.1, 1, 10],
'gamma': ['scale', 0.1, 0.01],
'kernel': ['rbf', 'linear']
}
grid_search_svm = GridSearchCV(SVC(random_state=42), param_grid_svm, cv=3, scoring='accuracy') # cv=3以加快速度
grid_search_svm.fit(X_train_scaled, y_train)
print("\n--- SVM超参数调优 ---")
print("最佳超参数:", grid_search_svm.best_params_)
print("交叉验证最佳得分:", grid_search_svm.best_score_)关键超参数 对于使用RBF核的SVM,有两个至关重要的超参数需要调优:
C(惩罚系数):如前所述,控制着对错误分类的惩罚力度,权衡着间隔宽度和分类准确性。gamma(核系数) :它定义了单个训练样本的影响范围。- 较小的
gamma值 :意味着影响范围大,决策边界会非常平滑,模型趋向于欠拟合(高偏差)。 - 较大的
gamma值 :意味着影响范围小,只有靠近的样本点才会对决策边界产生影响,这会导致决策边界非常曲折、复杂,模型趋向于过拟合(高方差)。
- 较小的
C和gamma通常需要一起进行网格搜索来寻找最优组合。
优缺点与适用场景
- 优点 :
- 在高维空间中非常有效,甚至当维度数大于样本数时。
- 内存效率高,因为它只使用一部分训练点(支持向量)来做决策。
- 非常通用,通过选择不同的核函数,可以适应各种数据和决策边界。
- 缺点 :
- 当样本数量远大于特征数量时,性能和速度通常不如一些集成模型(如随机森林)。
- 对缺失数据敏感。
- 结果不易解释,特别是使用非线性核时,它不像逻辑回归或决策树那样直观。
- 没有直接的概率输出(虽然可以通过一些方法间接计算)。
适用场景:
- 复杂但中小型的数据集。
- 高维数据,如图像识别、文本分类。
- 当需要一个非线性分类器时,SVM(特别是RBF核)是一个强大的选择。
5.4 决策树与随机森林:"集思广益"的集成智慧
决策树(Decision Tree)是一种非常符合人类直觉的分类模型。它通过学习一系列"if-then"规则,来构建一个树形的决策结构。而随机森林(Random Forest)则是通过"集体智慧",将许多棵决策树组合起来,形成一个更强大、更稳健的模型。
5.4.1 决策树:像人一样思考的树形结构
构建过程 决策树的构建是一个递归的过程,目标是生成一棵泛化能力强、不纯度低的树。
- 选择根节点:从所有特征中,选择一个"最好"的特征作为树的根节点。
- 分裂:根据这个最优特征的取值,将数据集分裂成若干个子集。
- 递归:对每个子集,重复步骤1和2,即选择该子集下的最优特征进行分裂,生成新的子节点。
- 停止:当满足停止条件时(如节点下的所有样本都属于同一类别,或达到预设的树深),该节点成为叶子节点,不再分裂。
如何选择最优特征进行分裂 "最好"的特征,是指那个能让分裂后的数据集**"不纯度"下降最大**的特征。我们希望每次分裂后,各个子集内部的类别尽可能地"纯粹"(即大部分样本属于同一个类别)。 衡量不纯度的常用指标有:
- 基尼不纯度(Gini Impurity):Scikit-learn中的默认选择。它衡量的是从数据集中随机抽取两个样本,其类别标签不一致的概率。基尼不纯度越小,数据集越纯。
- 信息增益(Information Gain):基于信息熵(Entropy)的概念。信息熵衡量的是数据的不确定性。信息增益就是父节点的信息熵减去所有子节点信息熵的加权平均。信息增益越大,说明这次分裂带来的"确定性"提升越大。
可视化与可解释性 决策树最大的优点之一就是高度的可解释性。我们可以将训练好的决策树可视化出来,清晰地看到它的每一个决策规则。这使得它成为一个"白盒"模型,非常便于向非技术人员解释。
剪枝(Pruning) 如果不加限制,决策树会一直生长,直到每个叶子节点都只包含一个样本,这会导致严重的过拟合。为了防止这种情况,我们需要对树进行"剪枝"。
- 预剪枝(Pre-pruning) :在树的生长过程中,通过设定一些条件提前停止分裂。常用的超参数包括:
max_depth:树的最大深度。min_samples_split:一个节点要分裂,至少需要包含的样本数。min_samples_leaf:一个叶子节点至少需要包含的样本数。
- 后剪枝(Post-pruning):先生成一棵完整的决策树,然后自底向上地考察非叶子节点,如果将该节点替换为叶子节点能提升模型的泛化性能,则进行剪枝。
5.4.2 集成学习入门:从"一个好汉"到"三个臭皮匠"
**集成学习(Ensemble Learning)**是一种强大的机器学习范式,它不依赖于单个模型,而是将多个弱学习器(weak learners)组合起来,形成一个强大的强学习器。俗话说"三个臭皮匠,顶个诸葛亮",这就是集成学习的核心思想。
Bagging思想 Bagging(Bootstrap Aggregating的缩写)是集成学习中最基础的思想之一。它的目标是降低模型的方差。
- 自助采样(Bootstrap) :从原始训练集中,进行有放回地随机抽样,生成多个大小与原始数据集相同的自助样本集。由于是有放回抽样,每个自助样本集中会包含一些重复样本,也有些原始样本未被抽到。
- 独立训练:在每个自助样本集上,独立地训练一个基学习器(如一棵决策树)。
- 聚合(Aggregating) :对于分类任务,使用多数表决的方式,将所有基学习器的预测结果进行投票,得出最终的集成预测。对于回归任务,则取所有基学习器预测结果的平均值。
5.4.3 随机森林(Random Forest):决策树的"集体智慧"
随机森林就是以决策树为基学习器的Bagging集成模型,并且在Bagging的基础上,引入了进一步的"随机性"。
"双重随机"的核心
- 样本随机(行抽样):继承自Bagging,每个基决策树都在一个自助样本集上训练。
- 特征随机(列抽样) :这是随机森林的独创。在每个节点进行分裂时,不是从所有特征中选择最优特征,而是先从所有特征中随机抽取一个子集(通常是sqrt(n_features)个),然后再从这个子集中选择最优特征进行分裂。
为何随机森林通常优于单棵决策树
- 降低方差:Bagging的聚合过程本身就能有效降低方差。
- 增加模型多样性 :"特征随机"这一步,使得森林中的每棵树都长得"各不相同",因为它们在每个节点上看到的"世界"(特征子集)都不同。这降低了树与树之间的相关性,使得投票结果更加稳健,进一步降低了整体模型的方差,有效防止了过拟合。
5.4.4 Scikit-learn实战与特征重要性
代码实现
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# --- 决策树 ---
dt_model = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train) # 决策树对缩放不敏感,可以直接用原始数据
y_pred_dt = dt_model.predict(X_test)
print("--- 决策树模型评估 ---")
print(classification_report(y_test, y_pred_dt))
# --- 随机森林 ---
rf_model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42, n_jobs=-1)
rf_model.fit(X_train, y_train)
y_pred_rf = rf_model.predict(X_test)
print("\n--- 随机森林模型评估 ---")
print(classification_report(y_test, y_pred_rf))n_estimators是森林中树的数量,n_jobs=-1表示使用所有CPU核心并行计算。
特征重要性(Feature Importance) 随机森林还有一个非常有用的副产品------特征重要性。模型可以评估每个特征在所有树的决策中所做的贡献大小(通常是基于该特征带来的不纯度下降总量)。这为我们理解数据和筛选特征提供了极佳的洞察。
importances = rf_model.feature_importances_
feature_importances = pd.Series(importances, index=X.columns).sort_values(ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(x=feature_importances, y=feature_importances.index)
plt.title('Feature Importances in Random Forest')
plt.show()优缺点与适用场景
- 优点 :
- 性能强大:通常能获得非常高的准确率,是许多竞赛和工业应用中的主力模型。
- 抗过拟合能力强:双重随机性使其非常稳健。
- 对缺失值和异常值不敏感。
- 无需特征缩放。
- 能处理高维数据,并能输出特征重要性。
- 缺点 :
- 可解释性差:相比单棵决策树,随机森林是一个"黑盒"模型,难以解释其内部决策逻辑。
- 计算和内存开销大:需要训练和存储数百棵树。
- 在某些噪声很大的数据集上,可能会过拟合。
适用场景:
- 几乎适用于任何分类(或回归)问题,是工具箱中必备的"瑞士军刀"。
- 当需要一个高性能、开箱即用的模型时。
- 用于特征选择和数据探索。
5.5 朴素贝叶斯:"执果索因"的概率思维
朴素贝叶斯(Naive Bayes)是一类基于贝叶斯定理 和特征条件独立性假设的简单概率分类器。尽管它的假设非常"朴素",但在许多现实场景,尤其是文本分类中,其表现却出人意料地好。
5.5.1 贝叶斯定理:概率论的基石
贝叶斯定理描述了两个条件概率之间的关系。它的核心思想是根据"结果"来反推"原因"的概率 。 P(A|B) = [P(B|A) * P(A)] / P(B)
在分类任务中,我们可以将其改写为: P(类别 | 特征) = [P(特征 | 类别) * P(类别)] / P(特征)
P(类别 | 特征):后验概率(Posterior)。这是我们想求的,即在看到这些特征后,样本属于某个类别的概率。P(特征 | 类别):似然(Likelihood)。在某个类别下,出现这些特征的概率。这是模型需要从训练数据中学习的。P(类别):先验概率(Prior)。在不看任何特征的情况下,某个类别本身出现的概率。可以从训练数据中直接统计。P(特征):证据(Evidence)。这些特征出现的概率。在预测时,对于所有类别,它是一个常数,因此可以忽略。
所以,朴素贝叶斯的预测过程就是:对于一个新样本,计算它属于每个类别的后验概率,然后选择后验概率最大的那个类别作为预测结果。
5.5.2 "朴素"在何处?特征条件独立性假设
计算P(特征 | 类别),即P(特征₁, 特征₂, ... | 类别),是非常困难的。为了简化计算,朴素贝叶斯做出了一个非常强的假设:
特征条件独立性假设 :它假设在给定类别的情况下,所有特征之间是相互独立 的。 P(特征₁, 特征₂, ... | 类别) = P(特征₁ | 类别) * P(特征₂ | 类别) * ...
这个假设就是"朴素"一词的来源。在现实中,特征之间往往是有关联的(例如,在文本中,"机器学习"和"算法"这两个词就经常一起出现)。但这个看似不合理的假设,却极大地简化了计算,并使得朴素贝叶斯在实践中依然表现良好。
不同类型的朴素贝叶斯 根据特征数据的不同分布,朴素贝叶斯有几种常见的变体:
- 高斯朴素贝叶斯(GaussianNB):假设连续型特征服从高斯分布(正态分布)。
- 多项式朴素贝叶斯(MultinomialNB):适用于离散型特征,特别是文本分类中的词频计数。
- 伯努利朴素贝叶斯(BernoulliNB):适用于二元特征(特征出现或不出现),也是文本分类的常用模型。
5.5.3 Scikit-learn实战与文本分类应用
朴素贝叶斯最经典、最成功的应用领域莫过于文本分类 。我们将以一个经典的垃圾邮件过滤为例,展示其工作流程。在文本处理中,我们通常使用MultinomialNB或BernoulliNB。
代码实现 为了处理文本,我们首先需要将文字转换成机器可以理解的数值形式。最常用的方法是词袋模型(Bag-of-Words) ,它将每篇文档表示为一个向量,向量的每个维度代表一个词,值可以是该词在文档中出现的次数(词频)。Scikit-learn的CountVectorizer可以帮我们完成这个转换。
make_pipeline是一个非常有用的工具,它可以将"特征提取"(如CountVectorizer)和"模型训练"(如MultinomialNB)这两个步骤串联成一个无缝的处理流程。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import pandas as pd
# 假设我们有一个包含邮件文本和标签的数据集
# 为了演示,我们创建一个简单的数据集
data = {
'text': [
"SPECIAL OFFER! Buy now and get a 50% discount!",
"Hi Bob, can we schedule a meeting for tomorrow?",
"Congratulations! You've won a free cruise trip!",
"Please find the attached document for your review.",
"Limited time offer: exclusive access to cheap viagra.",
"Project update and next steps for our meeting.",
"URGENT: Your account has been compromised! Click here to secure it.",
"Thanks for your email, I will look into the document."
],
'label': ['spam', 'ham', 'spam', 'ham', 'spam', 'ham', 'spam', 'ham']
}
df_mail = pd.DataFrame(data)
X_mail = df_mail['text']
y_mail = df_mail['label']
# 划分训练集和测试集
X_train_mail, X_test_mail, y_train_mail, y_test_mail = train_test_split(X_mail, y_mail, test_size=0.25, random_state=42)
# 1. 创建一个处理流程管道
# CountVectorizer: 将文本转换为词频计数向量。
# MultinomialNB: 使用多项式朴素贝叶斯分类器。
pipeline = make_pipeline(CountVectorizer(), MultinomialNB())
# 2. 训练模型 (管道会自动先对X_train_mail做transform,然后用转换后的数据训练模型)
pipeline.fit(X_train_mail, y_train_mail)
# 3. 预测与评估
y_pred_mail = pipeline.predict(X_test_mail)
print("--- 朴素贝叶斯在测试集上的评估 ---")
print(classification_report(y_test_mail, y_pred_mail))
# 4. 预测新邮件
print("\n--- 预测新邮件 ---")
new_emails = [
"Dear customer, your invoice is attached.",
"Claim your free prize now!"
]
predictions = pipeline.predict(new_emails)
proba_predictions = pipeline.predict_proba(new_emails)
for email, pred, proba in zip(new_emails, predictions, proba_predictions):
# pipeline.classes_ 可以查看类别的顺序
class_order = pipeline.classes_
print(f"邮件: '{email}'")
print(f"预测结果: {pred}")
print(f"属于各类的概率: {dict(zip(class_order, proba))}\n")优缺点与适用场景
-
优点:
- 算法简单,训练速度极快:计算开销小,因为它只需要做一些计数和概率计算,没有复杂的迭代优化过程。
- 对小规模数据表现很好:在数据量不大的情况下,依然能获得不错的性能。
- 能处理多分类问题,且表现稳定。
- 在特征条件独立性假设成立或近似成立时(如文本分类中,词与词的关联性被简化),效果甚至可以媲美复杂模型。
-
缺点:
- "朴素"的假设在现实中几乎不成立,这限制了其预测精度的上限。如果特征之间存在很强的关联性,模型的表现会大打折扣。
- 对输入数据的表达形式很敏感。
- 零概率问题:由于概率是连乘的,如果某个特征在训练集的某个类别中从未出现过,会导致其条件概率为0,从而使得整个后验概率计算结果为0,无论其他特征如何。这个问题需要通过**拉普拉斯平滑(Laplace Smoothing)**来解决(Scikit-learn中的实现已默认处理)。
适用场景:
- 文本分类:这是朴素贝叶斯最经典、最成功的应用场景,如垃圾邮件过滤、新闻主题分类、情感分析等。
- 作为一种快速、简单的基线模型:与逻辑回归类似,它可以为更复杂的模型提供一个性能参考基准。
- 适用于特征之间关联性较弱的问题。
结语
本章,我们系统地学习了五种主流的监督学习分类算法。我们从逻辑回归的概率视角出发,感受了其作为基线模型的稳健与可解释性;接着,我们体会了K-近邻"近朱者赤"的朴素哲学,并认识到数据标准化的重要性;然后,我们领略了支撑向量机在线性与非线性世界中寻找"最大间隔"的数学之美;随后,我们深入探索了决策树与随机森林如何从"个体智慧"走向"集体智慧",并见识了集成学习的强大威力;最后,我们回归概率的本源,理解了朴素贝叶斯"执果索因"的推断逻辑及其在文本世界的卓越表现。
这五种算法,如同五位性格迥异的武林高手,各有其独门绝技和适用之地。没有哪一个算法是永远的"天下第一",真正的"高手"在于能够洞悉问题的本质,为之匹配最合适的"招式"。
至此,我们完成了对"判别"类任务的探索。在下一章,我们将转向监督学习的另一个重要分支------"预测"类任务,深入学习各类回归算法,探索如何精准地预测连续的数值。请带着本章的收获,准备好进入新的智慧之境。
第六章:监督学习之"预测"------回归算法
- 6.1 线性回归:从简单到多元,探寻变量间的线性关系
- 6.2 岭回归与Lasso回归:正则化下的"中庸之道"
- 6.3 多项式回归:用曲线拟合复杂世界
- 6.4 回归树与集成回归模型(例如 GBDT, XGBoost)
在前一章,我们探索了如何让机器学会"判别"事物的类别。本章,我们将开启监督学习的另一扇大门------回归(Regression) 。回归任务的目标是预测一个连续的数值型输出。它构成了现代数据科学和机器学习的基石,应用场景无处不在:
- 经济金融:预测股票价格、GDP增长率、公司营收。
- 房地产:根据房屋特征(面积、位置、房龄)预测其售价。
- 气象学:预测明天的最高温度、降雨量。
- 商业运营:预测网站的访问量、产品的销量、广告的点击率。
本章,我们将从最经典、最基础的线性回归出发,理解变量间线性关系的建模方式。接着,我们将学习如何通过正则化技术(岭回归与Lasso回归)来约束和优化线性模型,使其更加稳健。然后,我们会看到如何利用多项式特征,让线性模型也能拟合复杂的非线性关系。最后,我们将迈向当今最强大的一类回归工具------以回归树为基础的集成模型,如随机森林、GBDT和XGBoost,它们是无数数据科学竞赛和工业应用中的性能王者。
准备好,让我们一起探寻预测连续变量的奥秘,学习如何为复杂世界建立精准的量化模型。
6.1 线性回归:从简单到多元,探寻变量间的线性关系
线性回归是回归算法家族的"开山鼻祖"。它的思想简单而强大:假设目标变量与一个或多个特征变量之间存在线性关系。尽管简单,但它至今仍是应用最广泛的模型之一,并且是理解更复杂回归算法的重要基础。
6.1.1 简单线性回归:一元一次方程的"机器学习"视角
简单线性回归只涉及一个特征变量(自变量 x)和一个目标变量(因变量 y)。
模型形式 我们试图找到一条直线,来最好地拟合数据点。这条直线的方程,就是我们初中数学学过的一元一次方程: ŷ = wx + b 在机器学习语境下:
ŷ(y-hat) 是模型的预测值。x是输入的特征值。w(weight) 是权重 或系数 ,代表特征x的重要性,几何上是直线的斜率。b(bias) 是偏置 或截距 ,代表当所有特征为0时模型的基准输出,几何上是直线在y轴上的截距。
机器学习的"训练"过程,就是要根据已有的 (x, y) 数据点,自动地找到最优的 w 和 b。
损失函数:最小二乘法(Least Squares) 如何评判一组 w 和 b 是不是"最优"的?我们需要一个标准来衡量模型的"好坏"。对于回归问题,最直观的想法是看真实值 y 和预测值 ŷ 之间的差距。
最小二乘法 就是这个标准。它定义了模型的损失函数(Loss Function)或 成本函数(Cost Function)为所有样本的预测误差的平方和 。这个值通常被称为残差平方和(Residual Sum of Squares, RSS) 。 Loss(w, b) = Σ(yᵢ - ŷᵢ)² = Σ(yᵢ - (wxᵢ + b))²
几何意义 :这个损失函数代表了所有数据点到拟合直线的垂直距离的平方和 。 代数意义 :我们的目标是找到一组 w 和 b,使得这个 Loss 值最小。
求解方法简介 如何找到最小化损失函数的 w 和 b?主要有两种方法:
- 正规方程(Normal Equation) :一种纯数学的解法。通过对损失函数求偏导并令其为零,可以直接解出一个封闭形式的数学公式,一次性计算出最优的
w和b。它的优点是精确,无需迭代;缺点是当特征数量非常大时,矩阵求逆的计算成本极高。 - 梯度下降(Gradient Descent) :一种迭代式的优化算法。它就像一个蒙着眼睛下山的人,从一个随机的
(w, b)点出发,每次都沿着当前位置**最陡峭的下坡方向(梯度的反方向)**走一小步,不断迭代,直到走到山谷的最低点(损失函数的最小值点)。它是绝大多数机器学习模型(包括深度学习)的核心优化算法。
6.1.2 多元线性回归:从"线"到"面"的扩展
现实世界中,一个结果往往由多个因素共同决定。例如,房价不仅与面积有关,还与地段、房龄、楼层等多个特征有关。这时,我们就需要使用多元线性回归(Multiple Linear Regression)。
模型形式 它只是简单线性回归的直接扩展,从一个特征扩展到 n 个特征: ŷ = w₁x₁ + w₂x₂ + ... + wₙxₙ + b或者用更简洁的向量形式表示: ŷ = wᵀX + b 这里的 w 是一个权重向量,X 是一个特征向量。在三维空间中,它拟合的是一个平面;在更高维的空间中,它拟合的是一个超平面。
核心假设 为了让多元线性回归的结果可靠且具有良好的解释性,它依赖于几个核心假设,常被总结为**"LINE"**原则:
- 线性(Linearity):特征和目标变量之间存在线性关系。
- 独立性(Independence):样本的误差(残差)之间相互独立。
- 正态性(Normality):误差服从正态分布。
- 同方差性(Equal variance / Homoscedasticity):误差的方差在所有预测值水平上是恒定的。
在实际应用中,这些假设不一定能完美满足,但了解它们有助于我们诊断模型的问题。
6.1.3 Scikit-learn实战与模型解读
代码实现 Scikit-learn让使用线性回归变得异常简单。我们将使用经典的波士顿房价数据集进行演示。这个数据集包含了影响房价的多种因素(如犯罪率、房间数、学生教师比等),我们的目标是建立一个模型来预测房价。
# 导入必要的库
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# --- 数据准备 ---
# 加载数据 (Scikit-learn 1.2后,波士顿房价数据集因伦理问题被移除,我们从其他源加载)
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None )
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
X = pd.DataFrame(data, columns=feature_names)
y = pd.Series(target, name='PRICE')
# 1. 划分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. 初始化并训练模型
# Scikit-learn的LinearRegression默认使用正规方程求解
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
# 3. 预测
y_pred = lr_model.predict(X_test)
# 4. 评估
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print("--- 线性回归模型评估 ---")
print(f"均方误差 (MSE): {mse:.2f}")
print(f"均方根误差 (RMSE): {rmse:.2f}")
print(f"R^2 分数: {r2:.2f}")系数解读(Coefficients) 线性回归的一大优点是其可解释性。我们可以直接查看模型学习到的权重(系数),来理解每个特征对预测结果的影响。
# 查看截距和系数
print(f"\n截距 (b): {lr_model.intercept_:.2f}")
coefficients = pd.Series(lr_model.coef_, index=X.columns).sort_values()
print("系数 (w):\n", coefficients)
# 可视化系数
plt.figure(figsize=(10, 6))
coefficients.plot(kind='bar')
plt.title('Coefficients of the Linear Regression Model')
plt.show()如何解读系数? 以RM(平均每户住宅的房间数)为例,其系数为正数(约2.94),则意味着在其他所有特征保持不变 的情况下,房间数每增加1个单位,预测的房价平均会增加约2.94万美元。反之,LSTAT(低地位人口比例)的系数为负数(约-0.55),则说明该比例越高,预测的房价越低。
重要提示 :只有当所有特征处于相同或相似的尺度 时,我们才能直接比较系数的绝对值大小来判断特征的相对重要性。否则,一个单位变化很大的特征(如总资产)即使系数很小,其影响力也可能超过一个单位变化很小的特征(如年龄)。因此,在解读系数重要性之前,通常需要对数据进行标准化。
评估指标 除了在第四章学过的MAE, MSE, RMSE ,回归任务中最常用的相对评估指标是R² (R-squared)。
- R²,即决定系数,衡量的是模型能够解释的目标变量方差的百分比。R²越接近1,说明模型的拟合效果越好。一个R²为0.67的模型,意味着它能解释67%的房价变动。剩下的33%则是由模型未包含的其他因素引起的。
6.2 岭回归与Lasso回归:正则化下的"中庸之道"
普通线性回归(也称OLS,Ordinary Least Squares)虽然简单,但它有两个主要的"烦恼":过拟合 和多重共线性。正则化回归就是为了解决这些问题而生的。
6.2.1 线性回归的"烦恼":过拟合与多重共线性
- 过拟合现象 :当特征数量很多,特别是相对于样本数量而言时,线性回归模型会变得过于复杂。它会试图去完美拟合训练数据中的每一个点,包括噪声。这会导致模型的系数(权重
w)变得异常大,模型在训练集上表现很好,但在测试集上表现很差。 - 多重共线性(Multicollinearity):当两个或多个特征高度相关时(例如,"房屋面积"和"房间数"),线性回归的系数会变得非常不稳定。稍微改变一下训练数据,系数的值就可能发生剧烈变化,甚至正负颠倒。这使得我们无法再信任系数的解释性。
正则化通过在损失函数中加入一个惩罚项,来对模型的复杂度(即系数的大小)进行约束,从而缓解这些问题。
6.2.2 岭回归(Ridge Regression):在"山岭"上保持平衡
岭回归在线性回归的原始损失函数(RSS)的基础上,增加了一个L2正则化项。
L2正则化 Loss_Ridge = Σ(yᵢ - ŷᵢ)² + α * Σ(wⱼ)²
Σ(wⱼ)²是所有特征系数的平方和。α(alpha) 是一个超参数,用于控制正则化的强度。
超参数Alpha(α)
- 当
α = 0时,岭回归就退化为普通的线性回归。 - 当
α增大时,对大系数的惩罚就越强,模型会迫使所有系数都向0收缩,但不会完全等于0。 - 当
α -> ∞时,所有系数都将无限趋近于0,模型变为一条水平线(只剩下截距)。
效果 通过惩罚大系数,岭回归可以有效地防止模型过拟合。同时,在处理多重共线性问题时,它倾向于将相关特征的系数"均分"权重,而不是像普通线性回归那样随意地给一个很大的正系数和另一个很大的负系数,从而使模型更加稳定。
6.2.3 Lasso回归(Least Absolute Shrinkage and Selection Operator):稀疏性的力量
Lasso回归与岭回归非常相似,但它使用的是L1正则化项。
L1正则化 Loss_Lasso = Σ(yᵢ - ŷᵢ)² + α * Σ|wⱼ|
Σ|wⱼ|是所有特征系数的绝对值之和。
稀疏解与特征选择 L1正则化与L2正则化有一个关键的区别:L1正则化能够将一些不重要的特征的系数完全压缩到0。
- 几何上,L2的惩罚项是圆形,而L1是菱形。损失函数的等高线在与菱形的顶点相交时,更容易使得某些坐标轴上的系数为0。
- 这个特性使得Lasso回归具有自动进行特征选择的能力。训练完一个Lasso模型后,那些系数不为0的特征,就是模型认为比较重要的特征。这种产生"稀疏解"(大部分系数为0)的能力在特征数量庞大的场景中非常有用。
6.2.4 Scikit-learn实战与弹性网络(Elastic Net)
代码实现 使用正则化回归时,对数据进行标准化是至关重要的,因为惩罚项是基于系数的大小的,如果特征尺度不同,惩罚就会不公平。
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn.model_selection import GridSearchCV
# 标准化数据
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# --- 岭回归 ---
ridge = Ridge(alpha=1.0)
ridge.fit(X_train_scaled, y_train)
print(f"岭回归在测试集上的R^2: {ridge.score(X_test_scaled, y_test):.2f}")
# --- Lasso回归 ---
lasso = Lasso(alpha=0.1)
lasso.fit(X_train_scaled, y_train)
print(f"Lasso回归在测试集上的R^2: {lasso.score(X_test_scaled, y_test):.2f}")
print(f"Lasso选出的特征数量: {np.sum(lasso.coef_ != 0)}")
# --- 使用GridSearchCV寻找最优alpha ---
param_grid = {'alpha': [0.001, 0.01, 0.1, 1, 10, 100]}
ridge_cv = GridSearchCV(Ridge(), param_grid, cv=5)
ridge_cv.fit(X_train_scaled, y_train)
print(f"\n岭回归最优alpha: {ridge_cv.best_params_['alpha']}")弹性网络(Elastic Net) 弹性网络是岭回归和Lasso回归的结合体,它同时使用了L1和L2两种正则化。 Loss_ElasticNet = RSS + α * [ l1_ratio * Σ|wⱼ| + (1 - l1_ratio) * 0.5 * Σ(wⱼ)² ]
- 它有两个超参数:
alpha控制整体正则化强度,l1_ratio控制L1和L2惩罚的比例。 - 当
l1_ratio = 1时,它就是Lasso;当l1_ratio = 0时,它就是Ridge。
何时选择
- 岭回归:是默认的首选。当你知道大部分特征都有用时,它通常表现更好。
- Lasso回归:当你怀疑很多特征是无用或冗余的,并希望模型能帮你自动筛选特征时,Lasso是绝佳选择。
- 弹性网络:当存在高度相关的特征群组时,Lasso倾向于只随机选择其中一个特征,而弹性网络则能像岭回归一样,将这个群组的特征都选入模型。因此,在有共线性且需要特征选择时,弹性网络是最好的选择。
6.3 多项式回归:用曲线拟合复杂世界
6.3.1 超越线性:当关系不再是直线
线性回归有一个很强的假设:特征和目标变量之间是线性关系。但现实世界中,很多关系是曲线形的。例如,施肥量与作物产量之间的关系,可能一开始是正相关的,但施肥过多后,产量反而会下降,形成一个抛物线关系。
6.3.2 "伪装"的线性回归:特征工程的力量
多项式回归并不是一种新的回归算法,它本质上仍然是线性回归 。它的巧妙之处在于,通过特征工程的手段,对原始数据进行"升维",从而让线性模型能够拟合非线性数据。
多项式特征生成 假设我们有一个特征 x。我们可以手动创造出它的高次项,如 x², x³ 等,并将这些新特征加入到模型中。 y = w₁x + w₂x² + w₃x³ + b 这个模型对于 y 和 x 来说是非线性的,但如果我们把 x₁_new = x, x₂_new = x², x₃_new = x³ 看作是三个新的、独立的特征 ,那么模型就变成了: y = w₁x₁_new + w₂x₂_new + w₃x₃_new + b 这又回到了我们熟悉的多元线性回归的形式!
Scikit-learn的PolynomialFeatures可以自动帮我们完成这个特征生成的过程。
6.3.3 Scikit-learn实战与过拟合的风险
代码实现
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
# 为了可视化,我们创建一个简单的非线性数据集
np.random.seed(42)
X_poly = np.sort(5 * np.random.rand(80, 1), axis=0)
y_poly = np.sin(X_poly).ravel() + np.random.randn(80) * 0.1
plt.scatter(X_poly, y_poly)
plt.title("Simple Non-linear Data")
plt.show()
# 使用不同阶数的多项式回归进行拟合
plt.figure(figsize=(12, 8))
for degree in [1, 3, 10]:
# 创建一个包含多项式特征生成和线性回归的管道
poly_reg = make_pipeline(PolynomialFeatures(degree=degree), LinearRegression())
poly_reg.fit(X_poly, y_poly)
X_fit = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_fit = poly_reg.predict(X_fit)
plt.plot(X_fit, y_fit, label=f'degree={degree}')
plt.scatter(X_poly, y_poly, edgecolor='b', s=20, label='data points')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()阶数(Degree)的选择
degree=1:就是普通的线性回归,无法拟合曲线,出现欠拟合。degree=3:较好地拟合了数据的真实趋势。degree=10:模型变得异常扭曲,试图穿过每一个数据点,包括噪声点。这在训练集上误差会很小,但在新数据上表现会很差,是典型的过拟合。
阶数是多项式回归中最重要的超参数,需要通过交叉验证来选择。通常,我们很少使用超过4或5阶的多项式,因为高阶多项式非常容易过拟合,且模型会变得不稳定。
6.4 回归树与集成回归模型:从规则到智慧的升华
线性模型家族虽然强大,但它们都基于一个固定的函数形式。而基于树的模型,则提供了一种完全不同的、非参数化的解决思路。
6.4.1 回归树(Regression Tree):用树形结构做预测
回归树的结构与我们在分类任务中学到的决策树完全相同,但在两个关键点上有所区别:
- 分裂准则 :分类树使用基尼不纯度或信息增益来选择分裂点,目标是让分裂后的节点类别更"纯粹"。而回归树的目标是让分裂后的每个节点内的预测误差最小化 。最常用的分裂准则就是均方误差(MSE)。在每个节点,树会遍历所有特征的所有可能分裂点,选择那个能使分裂后的两个子节点的MSE之和最小的分裂方式。
- 叶节点输出 :分类树的叶节点输出是该节点样本的众数类别。而回归树的叶节点输出是落在该叶节点所有训练样本的目标值的平均值。
模型特点 回归树的预测函数是一个分段常数函数。它将特征空间划分为若干个矩形区域,在每个区域内,预测值都是一个固定的常数。
6.4.2 随机森林回归(Random Forest Regressor)
单棵回归树同样存在容易过拟合的问题。随机森林通过Bagging的思想,将多棵回归树集成起来,极大地提升了模型的性能和稳定性。
- 工作原理:与分类随机森林完全一致,通过"样本随机"和"特征随机"构建一个由多棵"各不相同"的回归树组成的森林。
- 预测方式 :对于一个新的样本,森林中的每棵树都会给出一个预测值。随机森林的最终预测结果是所有树预测值的平均值。
Scikit-learn实战
from sklearn.ensemble import RandomForestRegressor
# 使用波士顿房价数据
rf_reg = RandomForestRegressor(n_estimators=100, random_state=42, n_jobs=-1)
rf_reg.fit(X_train, y_train) # 树模型对数据缩放不敏感
print(f"\n随机森林回归在测试集上的R^2: {rf_reg.score(X_test, y_test):.2f}")6.4.3 梯度提升决策树(GBDT):在"错误"中不断进步
梯度提升决策树(Gradient Boosting Decision Tree, GBDT)是另一种强大的集成方法,它采用的是Boosting思想。
Boosting思想 与Bagging并行训练不同,Boosting是一种串行的、循序渐进的集成方式。
- 首先,训练一个简单的基学习器(如一棵很浅的决策树)。
- 计算当前模型在所有样本上的残差(Residuals) ,即
真实值 - 预测值。这些残差就是模型尚未学好的"错误"。 - 接下来,训练第二棵树 ,但这棵树的学习目标不再是原始的
y,而是上一轮的残差。它专门学习如何弥补第一棵树的不足。 - 将第二棵树的预测结果(按一定比例,即学习率)加到第一棵树的预测结果上,形成一个新的集成模型。
- 不断重复步骤2-4,每一棵新树都在学习前面所有树集成起来的模型的残差。
最终,GBDT的预测结果是所有树的预测结果的加权和。它通过这种"在错误中不断进步"的方式,逐步构建出一个非常精准的模型。
Scikit-learn实战
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
gbrt.fit(X_train, y_train)
print(f"GBDT回归在测试集上的R^2: {gbrt.score(X_test, y_test):.2f}")6.4.4 XGBoost:极致的工程实现与性能王者
XGBoost(eXtreme Gradient Boosting)是GBDT的一种高效、灵活且可移植的工程实现。它在算法和工程层面都做了大量的优化,使其成为数据科学竞赛和工业界最受欢迎的模型之一。
核心优势
- 正则化:XGBoost在损失函数中直接加入了对树的复杂度的正则化项(如叶子节点的数量和叶子节点输出值的L2范数),这比GBDT单纯依靠学习率和剪枝来控制过拟合要更胜一筹。
- 高效的并行处理:虽然树的生成是串行的,但在每个节点寻找最佳分裂点时,XGBoost可以高效地进行并行计算。
- 内置交叉验证:可以在训练过程中直接进行交叉验证。
- 处理稀疏数据和缺失值:有专门的优化算法来处理稀疏数据和自动处理缺失值。
- 缓存感知和核外计算:在工程上做了很多优化,使得它能处理超出内存的大规模数据集。
代码实现 XGBoost是一个独立的库,需要单独安装 (pip install xgboost)。
import xgboost as xgb
xgb_reg = xgb.XGBRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42,
objective='reg:squarederror')
xgb_reg.fit(X_train, y_train)
print(f"XGBoost回归在测试集上的R^2: {xgb_reg.score(X_test, y_test):.2f}")结语
本章,我们从最基础的线性回归出发,一路探索了回归算法的广阔天地。我们学习了如何用正则化来约束线性模型,如何用多项式特征来捕捉非线性,最终登上了以随机森林、GBDT和XGBoost为代表的集成模型的性能高峰。
您现在已经掌握了解决两类最核心的监督学习问题------分类与回归------的强大工具集。线性模型家族为我们提供了良好的可解释性和基准,而树的集成模型则为我们追求极致性能提供了保障。
到目前为止,我们所学的都是"监督学习",即数据都带有明确的"答案"(标签)。在下一章,我们将进入一个全新的、更具探索性的领域------无监督学习。在那里,数据没有标签,我们的任务是从数据本身发现隐藏的结构、模式和群体。这将是一场全新的智慧探险。
第七章:无监督学习之"归纳"------聚类与降维
- 7.1 K-均值聚类(K-Means):寻找数据中的"引力中心"
- 7.2 层次聚类:构建数据的"家族谱系"
- 7.3 DBSCAN:基于密度的"社区发现"
- 7.4 主成分分析(PCA):在纷繁中见本质的降维之道
至此,我们旅程的前半段始终有一位"向导"------数据标签。它告诉我们什么是对的,什么是错的,我们的模型则努力学习这位向导的智慧。然而,在浩瀚的数据宇宙中,绝大多数的"星辰"(数据)都是未经标注的。如何从这些看似混沌的数据中发现秩序、归纳结构、提炼精华?这便是无监督学习的使命。
无监督学习,是一场没有标准答案的探索。它要求我们放弃对"预测"的执念,转而拥抱对"发现"的热情。本章,我们将聚焦于无日志学习的两大核心任务:
- 聚类(Clustering):旨在将数据集中的样本划分为若干个内部相似、外部相异的"簇"(Cluster)。它帮助我们回答"数据可以被自然地分成哪些群体?"这个问题。
- 降维(Dimensionality Reduction):旨在用一组数量更少的变量来概括原始数据中的主要信息。它帮助我们回答"数据的核心本质是什么?"这个问题。
掌握无监督学习,意味着您将拥有一双能够穿透数据表象、洞察其内在结构的"慧眼"。这不仅是数据预处理的关键步骤,其本身就能带来深刻的商业洞察,如客户分群、异常检测、文本主题挖掘等。
7.1 K-均值聚类(K-Means):寻找数据中的"引力中心"
K-均值(K-Means)是聚类算法中最著名、最简单、也是应用最广泛的算法之一。它是一种基于原型(Prototype-based)的聚类方法,试图找到每个簇的"原型"------即质心(Centroid),然后将每个样本划分给离它最近的质心所代表的簇。
7.1.1 核心思想:物以类聚,迭代为王
算法目标 K-Means的最终目标,是将 n 个样本划分为 K 个簇,并使得所有簇的**簇内平方和(Within-Cluster Sum of Squares, WCSS)**最小。WCSS衡量的是每个簇内所有样本点到其质心的距离平方之和。这个值越小,说明簇内的样本越紧密,聚类效果越好。
迭代步骤 K-Means通过一个简单而优美的迭代过程来逼近这个目标:
- 初始化 :随机选择
K个数据点作为初始的质心。 - 分配(Assignment) :遍历每一个数据点,计算它到所有
K个质心的距离,并将其分配给距离最近的那个质心所代表的簇。 - 更新(Update) :对于每一个簇,重新计算其质心。新的质心是该簇内所有数据点的平均值。
- 重复:不断重复步骤2和步骤3,直到质心的位置不再发生显著变化(或达到预设的迭代次数),算法收敛。
这个过程就像在数据平原上寻找 K 个"引力中心",数据点不断被最近的中心吸引,而中心的位置又根据被吸引来的点的分布而调整,最终达到一个稳定的平衡状态。
7.1.2 算法的"阿喀琉斯之踵":K值选择与初始点敏感性
K-Means虽然强大,但它有两个著名的"软肋"。
K值的确定 算法开始前,我们必须手动指定簇的数量 K 。这个 K 值应该如何确定?
- 肘部法则(Elbow Method) :我们可以尝试多个不同的
K值(例如从2到10),并计算每个K值下最终的WCSS。然后,将K值作为横坐标,WCSS作为纵坐标,绘制一条曲线。通常,这条曲线会像一个手臂,随着K的增加,WCSS会迅速下降,但到某个点后,下降速度会变得非常平缓。这个"拐点",即"肘部",通常被认为是比较合适的K值。 - 轮廓系数(Silhouette Score) :这是一个更严谨的指标(我们在第四章已经介绍过)。它同时衡量了簇的内聚度 和分离度 。我们可以为每个
K值计算其轮廓系数的平均值,然后选择那个使得轮廓系数最大 的K值。
初始点敏感性 K-Means的最终结果在一定程度上依赖于初始质心的选择。不同的随机初始化可能会导致完全不同的聚类结果,甚至陷入一个局部最优解。
K-Means++ 为了解决这个问题,**K-Means++**被提了出来。它是一种更智能的初始化策略,其核心思想是:初始的 K 个质心应该尽可能地相互远离 。Scikit-learn中的KMeans默认使用的就是K-Means++初始化(init='k-means++'),这在很大程度上缓解了初始点敏感性的问题。
7.1.3 Scikit-learn实战与模型假设
代码实现 在Scikit-learn中,实现K-Means聚类非常直观。我们将通过一个完整的流程,包括寻找最优K值、训练模型和可视化结果,来展示其应用。
# 导入必要的库
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.metrics import silhouette_score
import numpy as np
# 1. 生成模拟数据
# 我们创建一些符合K-Means假设的数据,即球状、大小相似的簇
X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.8, random_state=42)
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.title("Simulated Data for Clustering")
plt.show()
# 2. 使用肘部法则和轮廓系数寻找最优K
wcss = []
silhouette_scores = []
k_range = range(2, 11) # K值至少为2才有意义
for k in k_range:
# n_init=10 表示算法会用10个不同的初始质心运行10次,并选择WCSS最小的结果
kmeans = KMeans(n_clusters=k, init='k-means++', random_state=42, n_init=10)
kmeans.fit(X)
wcss.append(kmeans.inertia_) # inertia_ 属性就是WCSS
# 计算轮廓系数
score = silhouette_score(X, kmeans.labels_)
silhouette_scores.append(score)
# 绘制肘部法则图
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(k_range, wcss, marker='o')
plt.title('Elbow Method')
plt.xlabel('Number of clusters (K)')
plt.ylabel('WCSS')
# 绘制轮廓系数图
plt.subplot(1, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o')
plt.title('Silhouette Score for each K')
plt.xlabel('Number of clusters (K)')
plt.ylabel('Silhouette Score')
plt.tight_layout()
plt.show()
# 从图中我们可以清晰地看到,K=4是最佳选择(肘部点,轮廓系数最高)
# 3. 训练最终的K-Means模型
best_k = 4
kmeans_final = KMeans(n_clusters=best_k, init='k-means++', random_state=42, n_init=10)
y_kmeans = kmeans_final.fit_predict(X)
# 4. 结果可视化
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans_final.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75, marker='X', label='Centroids')
plt.title(f'K-Means Clustering Result (K={best_k})')
plt.legend()
plt.show()
# 5. 打印最终的轮廓系数
final_score = silhouette_score(X, y_kmeans)
print(f"Final Silhouette Score for K={best_k}: {final_score:.3f}")模型假设 理解K-Means的隐含假设至关重要,因为它决定了算法的适用范围:
- 簇是凸形的、球状的(Isotropic):由于K-Means使用基于欧氏距离的质心来定义簇,它天然地倾向于发现球状的簇。
- 所有簇的大小(样本量)和密度大致相同。
- 每个样本都属于某个簇:K-Means会将所有点都分配给一个簇,它无法识别离群点或噪声。
如果数据的真实簇结构是细长的、环形的,或者大小、密度差异巨大,K-Means的表现就会很差。这时,我们就需要求助于下面将要介绍的其他聚类算法。
7.2 层次聚类:构建数据的"家族谱系"
层次聚类(Hierarchical Clustering)提供了一种与K-Means完全不同的视角。它不要求我们预先指定簇的数量,而是通过构建一个嵌套的簇的层次结构,来展现数据点之间的亲疏关系,就像一个家族的族谱一样。
7.2.1 两种策略:自底向上(凝聚)与自顶向下(分裂)
- 凝聚型层次聚类(Agglomerative Clustering) :这是最常用的方法。
- 开始:将每一个数据点都视为一个独立的簇。
- 合并 :找到最接近的两个簇,将它们合并成一个新的簇。
- 重复:不断重复合并步骤,直到所有数据点都合并成一个唯一的、巨大的簇。
- 分裂型层次聚类(Divisive Clustering) :过程正好相反。
- 开始:所有数据点都在一个大簇里。
- 分裂:以某种方式将当前最"不协调"的簇分裂成两个子簇。
- 重复:不断重复分裂步骤,直到每个数据点都自成一簇。
我们将重点关注更主流的凝聚型方法。
7.2.2 核心要素:链接标准(Linkage Criteria)
在凝聚型聚类的合并步骤中,我们如何定义两个簇 之间的"距离"?这就是链接标准要解决的问题。
- Ward链接(Ward's Linkage) :Scikit-learn中的默认选项。它会合并那两个能使总的簇内方差增加最小的簇。它倾向于产生大小相似的球状簇,通常表现非常稳健。
- 完全链接(Complete Linkage) :簇间距离定义为两个簇中最远的两个点之间的距离。它倾向于产生紧凑的球状簇。
- 平均链接(Average Linkage) :簇间距离定义为两个簇中所有点对之间距离的平均值。
- 单一链接(Single Linkage) :簇间距离定义为两个簇中最近的两个点之间的距离。它可以处理非球状的簇,但对噪声非常敏感。
7.2.3 Scikit-learn实战与树状图(Dendrogram)解读
代码实现 层次聚类的美妙之处在于,我们可以通过树状图(Dendrogram)来可视化整个合并过程。
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import dendrogram, linkage
# 使用之前的数据X
# 1. 生成链接矩阵
# 'ward'链接方法计算的是簇间方差,而不是距离,所以它通常与欧氏距离配合使用
linked = linkage(X, method='ward')
# 2. 绘制树状图
plt.figure(figsize=(12, 7))
dendrogram(linked,
orientation='top',
labels=None, # 如果样本少,可以传入标签
distance_sort='descending',
show_leaf_counts=True)
plt.title('Hierarchical Clustering Dendrogram (Ward Linkage)')
plt.xlabel('Sample index')
plt.ylabel('Distance (Ward)')
plt.show()树状图解读
- 横轴代表数据样本。
- 纵轴代表簇之间的距离或不相似度。
- 每一条竖线代表一个簇。
- 连接两条竖线的横线表示一次合并,横线的高度就是这次合并时两个簇的距离。
如何根据树状图决定簇的数量? 我们可以画一条水平线横切整个树状图。这条水平线与多少条竖线相交,就意味着我们将数据分成了多少个簇。一个常用的方法是,寻找那段最长的、没有被横线穿过的竖线,然后在这段中间画一条水平线。
# 3. 训练AgglomerativeClustering模型
# 假设我们从树状图中决定n_clusters=4
agg_cluster = AgglomerativeClustering(n_clusters=4, linkage='ward')
y_agg = agg_cluster.fit_predict(X)
# 4. 结果可视化
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y_agg, s=50, cmap='viridis')
plt.title('Agglomerative Clustering Result (K=4)')
plt.show()7.3 DBSCAN:基于密度的"社区发现"
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种完全不同的聚类范式。它不基于距离中心或层次关系,而是基于密度。
7.3.1 超越几何中心:从"密度"出发看世界
核心思想 DBSCAN认为,一个簇是由密度可达(density-reachable)的点的集合。通俗地说,一个点属于某个簇,是因为它周围"足够稠密"。
两个关键参数
- 邻域半径 (
eps):定义了一个点的"邻域"范围。它是一个距离值。 - 最小点数 (
min_samples):要成为一个"稠密"区域,一个点的邻域内至少需要包含多少个其他点(包括它自己)。
点的分类 根据这两个参数,DBSCAN将所有点分为三类:
- 核心点(Core Point) :在其
eps邻域内,至少有min_samples个点的点。它们是簇的"心脏"。 - 边界点(Border Point) :它不是核心点,但它落在了某个核心点的
eps邻域内。它们是簇的"边缘"。 - 噪声点(Noise Point / Outlier):既不是核心点,也不是边界点。它们是离群的、孤独的点。
算法流程:从一个任意点开始,如果它是核心点,就以它为中心,通过密度可达关系不断扩张,形成一个簇。然后继续处理下一个未被访问的点。
7.3.2 DBSCAN的独特优势:发现任意形状的簇与识别噪声
- 处理非球形簇:由于DBSCAN不关心点到中心的距离,只关心密度,因此它可以轻松地发现任意形状的簇,如环形、月牙形、蛇形等,这是K-Means和层次聚类难以做到的。
- 自动识别离群点:DBSCAN不需要预先指定簇的数量。它会根据密度自动确定簇的数量,并将任何不属于任何簇的点标记为噪声(通常标签为-1)。
7.3.3 Scikit-learn实战与参数选择的挑战
代码实现
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
# 生成月牙形数据
X_moon, y_moon = make_moons(n_samples=200, noise=0.05, random_state=42)
# 训练DBSCAN模型
# eps和min_samples的选择非常关键,需要调试
dbscan = DBSCAN(eps=0.3, min_samples=5)
y_db = dbscan.fit_predict(X_moon)
# 结果可视化
plt.figure(figsize=(8, 6))
plt.scatter(X_moon[:, 0], X_moon[:, 1], c=y_db, s=50, cmap='viridis')
plt.title('DBSCAN Clustering on Moons Dataset')
plt.show()参数选择的挑战 DBSCAN的性能高度依赖于eps和min_samples的选择。
min_samples通常根据领域知识设定,一个经验法则是将其设为2 * D,其中D是数据的维度。eps的选择更具挑战性。一个常用的辅助方法是K-距离图(K-distance plot) :- 计算每个点到其第
k个最近邻的距离(这里的k就是min_samples-1)。 - 将这些距离从大到小排序,并绘制出来。
- 图形中同样会出现一个"肘部",这个肘部对应的距离值,就是一个很好的
eps候选值。
- 计算每个点到其第
7.4 主成分分析(PCA):在纷繁中见本质的降维之道
主成分分析(Principal Component Analysis, PCA)是无监督学习中应用最广泛的降维 技术。它旨在将高维数据投影到一个低维空间中,同时尽可能多地保留原始数据的方差(信息)。
7.4.1 降维的意义:为何我们需要"化繁为简"
- 克服维度诅咒:当特征维度非常高时,数据会变得异常稀疏,模型性能下降,计算成本剧增。降维可以有效缓解这个问题。
- 数据可视化:我们的肉眼只能感知二维或三维空间。PCA可以将上百维的数据降到2D或3D,让我们能够直观地观察数据的分布、结构和聚类趋势。
- 降低计算成本与噪声:去除冗余和次要的特征,可以加快模型训练速度,并可能通过滤除噪声来提升模型性能。
7.4.2 PCA的核心思想:寻找最大方差的方向
PCA的本质是进行一次坐标系的旋转。它要找到一个新的坐标系,使得数据在这个新坐标系下的表示具有两个特点:
- 方差最大化 :第一个新坐标轴(即第一主成分 )的方向,必须是原始数据方差最大的方向。因为方差越大,代表数据在该方向上携带的信息越多。第二个新坐标轴(第二主成分)则是在与第一个轴正交(垂直)的前提下,方差次大的方向,以此类推。
- 不相关性:所有新的坐标轴(主成分)之间都是线性无关(正交)的。
主成分(Principal Components)就是这些新的坐标轴。它们是原始特征的线性组合。
可解释方差比(Explained Variance Ratio) PCA完成后,我们可以计算每个主成分"解释"了多少原始数据的方差。例如,如果前两个主成分的累计可解释方差比为0.95,就意味着我们用这两个新的特征,保留了原始数据95%的信息。
7.4.3 Scikit-learn实战与应用
代码实现 PCA对特征的尺度非常敏感 。如果一个特征的方差远大于其他特征,那么PCA会主要被这个特征所主导。因此,在使用PCA之前,对数据进行标准化(StandardScaler)是一个至关重要的预处理步骤。Scikit-learn的PCA实现会自动对数据进行中心化(减去均值),但标准化的步骤需要我们自己完成。
我们将使用一个经典的手写数字数据集(Digits)来演示PCA的应用。这个数据集的每个样本有64个特征(一个8x8像素的图像),我们的目标是将其降维以便于可视化。
# 导入必要的库
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
import numpy as np
# 1. 加载数据
# Digits数据集,每个样本是64维的向量
digits = load_digits()
X_digits = digits.data
y_digits = digits.target
print(f"Original data shape: {X_digits.shape}")
# 2. 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_digits)
# 3. 应用PCA进行降维 (目标是降到2维以便可视化)
# n_components可以是一个整数,也可以是一个(0,1)之间的浮点数
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
print(f"Data shape after PCA: {X_pca.shape}")
# 4. 查看可解释方差比
# explained_variance_ratio_ 属性是一个数组,包含了每个主成分解释的方差比例
print(f"\nExplained variance ratio of the first component: {pca.explained_variance_ratio_[0]:.3f}")
print(f"Explained variance ratio of the second component: {pca.explained_variance_ratio_[1]:.3f}")
print(f"Total explained variance by 2 components: {np.sum(pca.explained_variance_ratio_):.3f}")
# 这个结果告诉我们,仅用2个主成分,就保留了原始64维数据约28.7%的方差(信息)。
# 5. 可视化降维后的数据
plt.figure(figsize=(10, 8))
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y_digits, cmap='jet', alpha=0.7, s=40)
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')
plt.title('PCA of Digits Dataset (64D -> 2D)')
plt.legend(handles=scatter.legend_elements()[0], labels=digits.target_names)
plt.colorbar(label='Digit Label')
plt.grid(True)
plt.show()从可视化结果中,我们可以清晰地看到,即使只用了两个主成分,不同数字的类别也已经在二维平面上呈现出了明显的分离趋势。这就是PCA在数据探索和可视化方面的强大威力。
选择主成分数量 在实际应用中,我们不一定总想降到2维。如何选择一个既能显著降维、又能保留足够信息的维度 k?
-
根据累计可解释方差比:这是最常用的方法。我们可以设定一个阈值(例如,希望保留95%的方差),然后运行PCA,让它自动选择能达到这个阈值的最小组件数。
-
碎石图(Scree Plot):将所有主成分按其解释的方差大小排序并绘制出来。图形中通常也会出现一个"肘部",肘部之前的主成分通常被认为是重要的,可以保留。
方法一:设定可解释方差比阈值
n_components=0.95 表示选择能保留95%方差的最少数量的主成分
pca_95 = PCA(n_components=0.95)
X_pca_95 = pca_95.fit_transform(X_scaled)
print(f"\nNumber of components to explain 95% variance: {pca_95.n_components_}")方法二:绘制碎石图来辅助决策
pca_full = PCA().fit(X_scaled) # 不指定n_components,计算所有主成分
plt.figure(figsize=(8, 6))
plt.plot(np.cumsum(pca_full.explained_variance_ratio_), marker='o', linestyle='--')
plt.xlabel('Number of Components')
plt.ylabel('Cumulative Explained Variance Ratio')
plt.title('Scree Plot for PCA')
plt.axhline(y=0.95, color='r', linestyle='-', label='95% threshold')
plt.legend()
plt.grid(True)
plt.show()
从碎石图中,我们可以看到,大约需要28个主成分才能保留95%的方差,这依然实现了超过一半的维度约减。
应用案例
- 数据可视化:如上例所示,将高维数据投影到2D或3D空间,以洞察其内在结构。
- 作为机器学习模型的预处理步骤 :先用PCA对数据降维,再将降维后的数据输入到分类或回归模型中。
- 优点:可以显著加快模型训练速度,并可能通过滤除噪声和共线性来提升模型性能。
- 缺点:降维后的新特征是原始特征的线性组合,失去了原有的物理意义,导致模型的可解释性下降。
结语
本章,我们踏入了无监督学习的奇妙世界。这是一片充满未知与惊喜的土地,在这里,我们不再是跟随"标签"的学徒,而是成为了主动发现数据奥秘的"探险家"。
我们学会了三种主流的聚类方法:
- K-Means,以其简洁高效,为我们寻找数据的"引力中心"。
- 层次聚类,通过构建数据的"家族谱系",为我们展现了样本间由近及远的完整亲缘关系。
- DBSCAN,则独辟蹊径,从"密度"的视角出发,发现了隐藏在数据中的任意形状的"社区",并智慧地识别出了离群的"独行者"。
同时,我们还掌握了PCA这一强大的降维"神器"。它教会我们如何在纷繁复杂的数据中,通过寻找最大方差的方向,抓住其主要矛盾,提炼其核心本质,实现"化繁为简"的智慧。
至此,您已经构建了机器学习知识体系的"四梁八柱":监督学习的分类 与回归 ,无监督学习的聚类 与降维。这为您解决绝大多数现实世界中的机器学习问题打下了坚实的基础。您已经从一个求知者,成长为了一位拥有完整工具箱的实践者。
在本书的最后一章,我们将把目光投向更远的地平线,简要介绍一些更前沿、更令人兴奋的领域,如深度学习的神经网络、模型部署的工程实践等,为您的持续学习与成长之旅点亮前行的灯塔。
第八章:集成学习------从"三个臭皮匠"到"诸葛亮"
- 8.1 Bagging思想:随机森林的再思考
- 8.2 Boosting思想:从AdaBoost到梯度提升树(GBDT)
- 8.3 Stacking/Blending:模型的"圆桌会议"
- 8.4 XGBoost与LightGBM:工业界的"大杀器"详解
在我们的机器学习探索之旅中,我们已经结识了众多各具特色的算法模型。它们如同身怀绝技的侠客,在各自擅长的领域里表现出色。然而,一个自然而然的问题是:我们能否将这些"个体英雄"的力量集结起来,形成一个战无不胜的"梦之队"?
集成学习(Ensemble Learning)正是对这个问题最响亮的回答。它并非一种具体的算法,而是一种强大的元算法框架(Meta-algorithm Framework)。其核心思想是,通过构建并结合多个学习器来完成学习任务,以期获得比任何单个学习器都显著优越的泛化性能。
本章,我们将深入探讨集成学习的三大主流思想:
- Bagging:通过并行训练多个独立模型并取其平均,来降低方差,追求"稳定压倒一切"。随机森林是其最杰出的代表。
- Boosting:通过串行训练,让模型在前辈的"错误"中不断学习和进化,来降低偏差,追求"精益求精"。GBDT是其核心思想的体现。
- Stacking:通过分层结构,让不同模型各司其职,再由一个"元模型"来学习如何最好地融合它们的智慧,追求"博采众长"。
最后,我们将详细拆解在当今工业界和数据科学竞赛中叱咤风云的两大"神器"------XGBoost和LightGBM,看看它们是如何将Boosting思想推向工程和算法的极致。准备好,让我们一起见证"三个臭皮-匠"如何通过智慧的组织,升华为运筹帷幄的"诸葛亮"。
8.1 Bagging思想:随机森林的再思考
Bagging是集成学习中最基础、最直观的思想之一。它的策略简单而有效:通过引入随机性来构建多个略有不同的模型,然后通过"民主投票"的方式汇集它们的预测,以获得一个更稳定、更可靠的最终结果。
8.1.1 核心思想:通过"随机"降低"方差"
Bagging是集成学习中最基础、最直观的思想之一。它的策略简单而有效:通过引入随机性来构建多个略有不同的模型,然后通过"民主决策"的方式汇集它们的预测,以获得一个更稳定、更可靠的最终结果。
自助采样法(Bootstrap Aggregating) Bagging这个词本身就是B ootstrap Agg regating的缩写,完美地概括了其两个核心步骤:
- 自助采样(Bootstrap) :这是Bagging引入随机性的关键手段。假设我们有
N个样本的原始训练集。我们进行有放回的随机抽样N次,得到一个同样大小为N的"自助样本集"。由于是有放回抽样,这个新的数据集中会不可避免地包含一些重复样本,同时,原始数据中约有36.8%(数学上趋近于1/e)的样本从未被抽到。这个过程模拟了从原始数据分布中多次采样的过程,创造了数据的多样性。 - 聚合(Aggregating) :我们重复上述自助采样过程
M次,得到M个不同的自助样本集。然后,我们在这M个数据集上独立地、并行地训练M个基学习器(例如,M棵决策树)。
并行训练与投票/平均
- 并行训练 :由于
M个基学习器的训练过程互不依赖,它们可以完全并行进行,这使得Bagging的训练效率很高。 - 决策方式 :
- 对于分类任务 ,最终结果由
M个基学习器进行多数投票(Majority Voting)决定。 - 对于回归任务 ,最终结果是
M个基学习器预测值的平均值。
- 对于分类任务 ,最终结果由
方差降低的直观解释 Bagging的主要作用是降低模型的方差。方差衡量的是模型在不同训练数据集上的预测结果的波动性。高方差模型(如未剪枝的决策树)容易过拟合,对训练数据的微小变化非常敏感。
Bagging通过在略有不同的数据子集上训练出多个这样的高方差模型,每个模型都从一个略微不同的"视角"来看待数据。虽然单个模型可能仍然存在过拟合,但它们的"错误"是各不相同的、不相关的。通过投票或平均,这些五花八门的错误在很大程度上被相互抵消了,最终留下的是数据中稳定、普适的规律,从而使得集成模型的整体方差大大降低。这就像投资组合一样,通过持有多个不完全相关的资产来分散风险。
8.1.2 随机森林(Random Forest)的再审视
我们在第五章已经学习过随机森林,现在我们可以从Bagging的视角来更深刻地理解它。随机森林是以决策树为基学习器的Bagging集成模型,并且在Bagging的基础上,更进了一步,引入了更强的随机性。
超越普通Bagging:特征随机化 随机森林引入了"双重随机性":
- 行采样(样本随机):继承自Bagging的自助采样。
- 列采样(特征随机) :这是随机森林的独创。在构建每棵决策树的每个节点时,并不是从全部特征中选择最优分裂点,而是先从全部特征中随机抽取一个子集 (例如,对于分类问题,通常是
sqrt(n_features)个),然后再从这个子集中选择最优特征。
这个"特征随机化"的步骤,进一步降低了森林中树与树之间的相关性。如果不用特征随机化,那么在每个自助样本集上,那些强特征很可能总是被优先选中,导致森林中的树长得"千篇一律",相关性很高。而引入特征随机化后,即使是弱特征也有机会在某些树的某些节点上成为最优选择,这使得森林中的树更加"多样化"。更多样化的模型,在聚合时能更有效地抵消误差,从而带来更强的泛化能力。
包外(Out-of-Bag, OOB)估计 由于自助采样平均约有36.8%的数据未被用于训练某一棵特定的树,这些数据被称为该树的包外(Out-of-Bag)数据。我们可以利用这些"免费"的、未被模型见过的数据来评估模型的性能,而无需再单独划分一个验证集或进行交叉验证。
对于每个样本,找到所有没有用它来训练的树,让这些树对它进行预测,然后将这些预测结果聚合起来,得到该样本的OOB预测。最后,用所有样本的OOB预测和真实标签来计算模型的OOB得分。在Scikit-learn中,只需在创建RandomForestClassifier或RandomForestRegressor时设置oob_score=True即可。
8.1.3 Scikit-learn实战与Bagging的泛化
代码实现 Scikit-learn提供了通用的BaggingClassifier和BaggingRegressor,它们允许我们将任何基学习器进行Bagging集成。
from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成数据
X, y = make_classification(n_samples=500, n_features=20, n_informative=15, n_redundant=5, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 1. 单个决策树模型
tree = DecisionTreeClassifier(random_state=42)
tree.fit(X_train, y_train)
y_pred_tree = tree.predict(X_test)
print(f"单个决策树模型的准确率: {accuracy_score(y_test, y_pred_tree):.4f}")
# 2. 使用Bagging集成决策树模型 (这实际上就是随机森林的简化版,没有特征随机)
bagging_tree = BaggingClassifier(
estimator=DecisionTreeClassifier(random_state=42),
n_estimators=100,
max_samples=1.0, # 使用全部样本大小的自助采样
bootstrap=True,
random_state=42,
n_jobs=-1
)
bagging_tree.fit(X_train, y_train)
y_pred_bagging = bagging_tree.predict(X_test)
print(f"Bagging决策树模型的准确率: {accuracy_score(y_test, y_pred_bagging):.4f}")通常,我们会看到集成后的模型性能比单个模型更加稳定和优越。
基学习器的选择 Bagging的核心是降低方差,因此它对于那些本身是低偏差、高方差的模型(即容易过拟合的复杂模型)效果最好。这就是为什么它与决策树(特别是未剪枝的决策树)是"天作之合"。将Bagging应用于本身就是高偏差的简单模型(如逻辑回归),通常不会带来显著的性能提升。
8.2 Boosting思想:从AdaBoost到梯度提升树(GBDT)
如果说Bagging是"群策群力、民主决策",那么Boosting就是"精英培养、迭代优化"。Boosting家族的算法通过一种串行的方式,让模型在前辈的"错误"中不断学习和进化,最终将一群"弱学习器"提升为一个强大的"强学习器"。
8.2.1 核心思想:在"错误"中迭代,化"弱"为"强"
串行训练的哲学 Boosting的训练过程是串行的,这意味着基学习器必须一个接一个地、按顺序进行训练。
- 首先,训练一个初始的基学习器。
- 然后,根据这个基学习器的表现,调整数据的权重或学习目标 ,使得那些被错分或预测误差大的样本在下一轮训练中受到更多的"关注"。
- 接着,在调整后的数据上训练第二个基学习器。
- 不断重复这个过程,每一轮都致力于弥补前一轮模型的"短板"。
- 最终,将所有基学习器进行加权组合,得到最终的强学习器。
Boosting与Bagging的根本区别
- 训练方式 :Bagging是并行 的,模型间独立;Boosting是串行的,模型间相互依赖。
- 核心目标 :Bagging主要降低方差 (variance),通过平均来平滑模型的波动;Boosting主要降低偏差(bias),通过不断修正错误来提升模型的准确度。
- 样本权重:Bagging中样本权重不变;Boosting中样本权重会动态调整。
8.2.2 AdaBoost(Adaptive Boosting):关注被错分的样本
AdaBoost(自适应提升)是Boosting家族的早期代表,其思想非常直观。
- 初始化:为每个训练样本分配相等的权重。
- 迭代 :在每一轮中:
- 在带权的训练数据上训练一个弱学习器(通常是决策树桩,即深度为1的决策树)。
- 计算这个弱学习器的错误率。
- 根据错误率计算该学习器的权重(错误率越低,权重越大)。
- 更新样本权重 :提升 那些被当前弱学习器错分 的样本的权重,降低 那些被正确分类的样本的权重。
- 组合 :最终的模型是所有弱学习器的加权投票结果,表现好的学习器拥有更大的"话语权"。
8.2.3 梯度提升树(GBDT):拟合残差的智慧
梯度提升树(Gradient Boosting Decision Tree)是Boosting思想更通用、更强大的体现。它不再像AdaBoost那样通过调整样本权重,而是通过一种更巧妙的方式来关注"错误"------直接拟合错误的本身。
残差(Residuals)作为学习目标 对于回归问题,GBDT的流程非常清晰:
- 用一个简单的模型(如所有样本的均值)作为初始预测。
- 计算当前模型的残差 ,即
真实值 - 预测值。 - 训练一棵新的决策树,但这棵树的学习目标不再是原始的
y,而是上一轮的残差。 - 将这棵"残差树"的预测结果乘以一个学习率(learning_rate),然后加到上一轮的预测结果上,得到新的预测。
- 不断重复步骤2-4,每一棵新树都在努力修正前面所有树留下来的"集体错误"。
梯度下降的视角 为何叫"梯度"提升?因为从更数学化的角度看,上述拟合残差的过程,等价于在函数空间中,让模型沿着损失函数的负梯度方向进行优化。对于回归问题常用的MSE损失函数,其负梯度恰好就是残差。这个视角将Boosting统一到了梯度下降的框架下,使其可以推广到任何可微分的损失函数,从而也能处理分类问题。
学习率(Learning Rate) 学习率(也称shrinkage)是一个非常关键的超参数(通常设为一个小值,如0.1)。它控制了每一棵树对最终结果的贡献度,即每次"进步"的步长。较小的学习率意味着需要更多的树(n_estimators)才能达到好的效果,但通常能让模型具有更好的泛化能力,防止过拟合。
8.3 Stacking/Blending:模型的"圆桌会议"
如果说Bagging是"一人一票",Boosting是"老师带学生",那么Stacking(堆叠)就是一场"圆桌会议"。它邀请不同领域的"专家"(异构的基学习器),让他们各自发表意见,最后由一位更高级的"主席"(元学习器)来综合所有意见,做出最终的裁决。
8.3.1 核心思想:让模型"各抒己见",再由"主席"定夺
分层结构 Stacking通常包含两层模型:
- 基学习器层(Level 0):包含多个(通常是不同类型的)基学习器。例如,我们可以同时使用逻辑回归、SVM、随机森林和KNN作为基学习器。
- 元学习器(Meta-learner, Level 1):只有一个模型,它的任务是学习如何最好地组合基学习器的预测结果。元学习器通常选择一个相对简单的模型,如逻辑回归或岭回归。
Stacking的工作流程
- 将训练集划分为训练子集和测试子集。
- 在训练子集上训练多个基学习器。
- 让这些训练好的基学习器对测试子集进行预测,这些预测结果将构成元学习器的新特征。
- 元学习器就以这些新特征作为输入,以测试子集的真实标签作为目标,进行训练。
- 在预测新数据时,先将数据输入到所有基学习器中得到预测,再将这些预测作为新特征输入到元学习器中,得到最终的预测结果。
8.3.2 避免"信息泄露":交叉验证在Stacking中的妙用
上述简单流程有一个严重的问题:基学习器在预测时看到了它们用来训练的数据,这会导致"信息泄露",使得元学习器过拟合。
K-折交叉预测 为了解决这个问题,标准的Stacking流程使用了K-折交叉验证的思想:
- 将原始训练集划分为
K折。 - 进行
K次循环。在第i次循环中:- 用除了第
i折之外 的K-1折数据来训练所有的基学习器。 - 让训练好的基学习器对第
i折 数据进行预测。这K次循环下来,我们就得到了对整个原始训练集的一个"干净"的预测,这些预测将作为元学习器的训练特征。
- 用除了第
- 在生成元学习器的训练数据后,还需要用完整的原始训练集重新训练一遍所有的基学习器,以便它们在未来预测新数据时能利用所有信息。
Blending Blending是Stacking的一种简化形式。它不再使用复杂的K-折交叉,而是直接将原始训练集划分为一个更小的训练集和一个留出集(hold-out set)。基学习器在训练集上训练,然后在留出集上进行预测,用这些预测来训练元学习器。Blending更简单,但数据利用率较低。
8.3.3 Scikit-learn实战与模型多样性的重要性
代码实现 Scikit-learn 0.22版本后,提供了官方的StackingClassifier和StackingRegressor,使得实现Stacking变得非常方便。
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
# 定义基学习器
estimators = [
('rf', RandomForestClassifier(n_estimators=10, random_state=42)),
('svr', SVC(random_state=42, probability=True)) # probability=True很重要
]
# 定义元学习器
final_estimator = LogisticRegression()
# 构建Stacking模型
# cv=5表示使用5折交叉验证来生成元学习器的训练数据
stacking_clf = StackingClassifier(
estimators=estimators,
final_estimator=final_estimator,
cv=5
)
# 训练和预测
stacking_clf.fit(X_train, y_train)
y_pred_stacking = stacking_clf.predict(X_test)
print(f"\nStacking模型的准确率: {accuracy_score(y_test, y_pred_stacking):.4f}")"和而不同" Stacking成功的关键在于基学习器的多样性。如果所有的基学习器都是同质的,或者它们的预测结果高度相关,那么元学习器就学不到什么有用的组合信息。因此,在选择基学习器时,我们应该尽量选择那些"思考方式"不同、错误模式也不同的模型。例如,将线性模型(逻辑回归)、基于距离的模型(KNN)和基于树的模型(随机森林)组合在一起,通常会比组合三个不同参数的随机森林效果更好。
8.4 XGBoost与LightGBM:工业界的"大杀器"详解
XGBoost和LightGBM都是对GBDT思想的极致工程实现和算法优化,它们凭借卓越的性能和效率,成为了当今数据科学领域应用最广泛的模型。
8.4.1 XGBoost(eXtreme Gradient Boosting):GBDT的极致进化
XGBoost在GBDT的基础上,从算法和工程两个层面都进行了深度优化。
- 算法层面的优化 :
- 正则化 :XGBoost在损失函数中直接加入了对树的复杂度的正则化项,包括对叶子节点数量(T)和叶子节点输出值(w)的L2正则化。这使得XGBoost能更好地控制过拟合。
- 二阶泰勒展开 :传统的GBDT只利用了损失函数的一阶梯度信息,而XGBoost对损失函数进行了二阶泰勒展开,同时利用了一阶和二阶梯度信息,使得模型能更精准地向最优解逼近。
- 工程层面的革新 :
- 并行化 :虽然树的生成是串行的,但在每个节点寻找最佳分裂点时,XGBoost可以高效地对特征进行并行计算。
- 缓存感知与核外计算:在工程上做了很多优化,使得它能处理超出内存的大规模数据集。
- 内置稀疏数据处理:能自动处理缺失值和稀疏特征。
为何称王:XGBoost通过这些优化,实现了速度与精度的完美结合,使其在很长一段时间内统治了各大机器学习竞赛。
8.4.2 LightGBM(Light Gradient Boosting Machine):更快、更轻、更强
LightGBM是微软推出的一个GBDT框架,它的目标是"更快、更轻"。
- 基于直方图的算法 :传统的GBDT在寻找分裂点时需要遍历所有数据点。LightGBM则先将连续的浮点数特征离散化为K个整数箱(bins),并构建一个宽度为K的直方图。后续寻找分裂点时,只需在这些箱的边界上进行,极大地提升了效率和降低了内存消耗。
- 带深度限制的Leaf-wise生长策略 :传统的GBDT和XGBoost大多采用Level-wise (按层)的生长策略,它对同一层的所有叶子节点进行无差别分裂,容易产生很多不必要的分裂。LightGBM则采用Leaf-wise (按叶子)的生长策略,每次都从当前所有叶子中,找到那个分裂增益最大 的叶子进行分裂。这种策略在分裂次数相同时,能获得更高的精度,但可能导致树的深度过深而过拟合,因此需要通过
max_depth来限制。
应用场景 :由于其卓越的效率,LightGBM在处理大规模数据集时,通常比XGBoost更快,性能也极具竞争力。
8.4.3 实战对比与选择之道
代码实现 XGBoost和LightGBM都是独立的库,需要单独安装 (pip install xgboost lightgbm)。它们的API与Scikit-learn高度兼容。
import xgboost as xgb
import lightgbm as lgb
# XGBoost
xgb_clf = xgb.XGBClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42, use_label_encoder=False, eval_metric='logloss')
xgb_clf.fit(X_train, y_train)
y_pred_xgb = xgb_clf.predict(X_test)
print(f"\nXGBoost模型的准确率: {accuracy_score(y_test, y_pred_xgb):.4f}")
# LightGBM
lgb_clf = lgb.LGBMClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
lgb_clf.fit(X_train, y_train)
y_pred_lgb = lgb_clf.predict(X_test)
print(f"LightGBM模型的准确率: {accuracy_score(y_test, y_pred_lgb):.4f}")何时用哪个
- 数据规模 :
- 对于中小规模的数据集(几万到几十万行),XGBoost和LightGBM性能相近,XGBoost的社区和文档更成熟。
- 对于大规模的数据集(百万行以上),LightGBM的速度优势会非常明显。
- 调参:两者都有大量的超参数可以调优。XGBoost的参数更直观一些,而LightGBM由于其独特的生长策略,调参时需要特别注意控制过拟合。
- 一般建议 :在新的项目中,可以优先尝试LightGBM,因为它通常能以更快的速度获得一个非常有竞争力的基线模型。如果对精度有极致要求,可以再精调XGBoost进行比较。
结语
本章,我们深入探索了集成学习的宏伟殿堂。我们理解了Bagging如何通过并行和随机来追求稳定,领悟了Boosting如何通过串行和迭代来追求卓越,也见识了Stacking如何通过分层和融合来追求协同。最后,我们拆解了XGBoost和LightGBM这两柄工业界的"神兵利器"。
掌握集成学习,意味着您不再将模型视为孤立的个体,而是学会了如何成为一名运筹帷幄的"将军",将不同的兵种(模型)排兵布阵,以集体的智慧去攻克最艰难的堡垒。
至此,我们已经完成了对主流机器学习算法的全面学习。在本书的最后一章,我们将把视野投向更广阔的未来,探讨如何将我们学到的知识付诸实践,并为您的下一步学习指明方向。
第九章:神经网络入门------通往深度学习的桥梁
- 9.1 从生物神经元到感知机模型
- 9.2 多层感知机(MLP)与反向传播算法
- 9.3 激活函数:为神经网络注入"灵魂"
- 9.4 使用Scikit-Learn与Keras/TensorFlow构建你的第一个神经网络
在我们迄今为止的旅程中,我们已经探索了众多强大的机器学习算法。这些算法在处理结构化数据、进行分类、回归和聚类任务时表现出色。然而,当面对如图像、声音、自然语言等极其复杂、高维且非结构化的数据时,传统机器学习算法往往会遇到瓶颈。为了应对这些挑战,一个源于生物学灵感、拥有强大表征学习能力的领域应运而生------人工神经网络(Artificial Neural Networks, ANN),它构成了现代深度学习(Deep Learning)的基石。
本章是您从经典机器学习迈向深度学习的关键桥梁。我们将追本溯源,从模拟生物神经元的最简单模型"感知机"开始,逐步揭示神经网络如何通过增加层次("深度")来获得学习复杂模式的能力。我们将深入探讨驱动其学习的"灵魂"算法------反向传播,并巡礼那些为网络注入非线性"活力"的激活函数。
最后,我们将从我们熟悉的Scikit-Learn平稳过渡到工业界标准的深度学习框架Keras/TensorFlow,亲手搭建、训练并评估您的第一个神经网络。这不仅是学习一种新的模型,更是开启一种全新的、以"端到端"学习为核心的解决问题的思维方式。
9.1 从生物神经元到感知机模型
人工神经网络的最初构想,是对人脑基本处理单元------神经元------的一次大胆而简化的模仿。理解这个灵感之源,能帮助我们更好地把握其核心设计哲学。
9.1.1 灵感之源:大脑神经元的工作机制
一个典型的生物神经元由以下几个部分组成:
- 树突(Dendrites):像天线一样,接收来自其他成千上万个神经元的信号。
- 细胞体(Soma):将所有接收到的信号进行整合处理。
- 轴突(Axon) :如果整合后的信号强度超过了一个特定的激活阈值(Activation Threshold),细胞体就会产生一次电脉冲(动作电位),并通过轴突将这个信号传递出去。
- 突触(Synapse):轴突的末梢,通过释放化学物质(神经递质)将信号传递给下一个神经元的树突。突触的连接强度是可以变化的,这被认为是学习和记忆的生物学基础。
这个过程可以被高度简化为:多个输入信号被加权求和,当总和超过一个阈值时,神经元被"激活"并产生一个输出信号。
9.1.2 感知机(Perceptron):最早的神经网络模型
1957年,心理学家弗兰克·罗森布拉特(Frank Rosenblatt)受生物神经元的启发,提出了感知机模型。这不只是一个抽象的概念,而是第一个用算法精确定义的、可学习的神经网络模型,是人工神经网络领域的"开山鼻祖"。
数学形式 一个接收 n 个输入的感知机,其工作流程可以分解为以下几步:
- 输入与权重 :模型接收一个输入向量
x = (x₁, x₂, ..., xₙ)。每个输入xᵢ都被赋予一个相应的权重wᵢ,这个权重代表了该输入信号的重要性。此外,还有一个偏置项b(bias),可以理解为一个可学习的激活阈值。 - 加权和(Net Input) :将所有输入信号与其对应的权重相乘,然后求和,最后加上偏置项。这个过程计算出一个净输入值
z。z = (w₁x₁ + w₂x₂ + ... + wₙxₙ) + b = w · x + b - 激活函数(Activation Function) :将净输入值
z传递给一个激活函数 。在经典的感知机中,这个函数是一个简单的单位阶跃函数(Heaviside Step Function) 。y = f(z) = 1如果z ≥ 0y = f(z) = 0如果z < 0最终的输出y就是模型的预测结果(通常是类别1或类别0)。
学习规则 感知机的学习过程非常直观:对于一个训练样本,如果预测错误,就调整权重。
- 如果真实标签是1,但模型预测为0(即
z < 0),说明权重太小了,需要增大。更新规则为:w_new = w_old + η * x,b_new = b_old + η。(η是学习率) - 如果真实标签是0,但模型预测为1(即
z ≥ 0),说明权重太大了,需要减小。更新规则为:w_new = w_old - η * x,b_new = b_old - η。 这个过程会一直迭代,直到模型能正确分类所有训练样本。
几何意义 w · x + b = 0 这个方程在二维空间中定义了一条直线,在三维空间中定义了一个平面,在更高维空间中则定义了一个超平面(Hyperplane) 。这个超平面恰好是决策的边界。感知机的任务,就是通过学习调整权重 w 和偏置 b,来找到这样一个超平面,将特征空间一分为二,使得一边的点被预测为一类,另一边的点被预测为另一类。因此,感知机本质上是一个线性二分类器。
感知机的局限性 感知机的辉煌是短暂的。1969年,人工智能领域的两位巨擘马文·明斯基(Marvin Minsky)和西摩尔·佩珀特(Seymour Papert)在他们的著作《感知机》中,系统地指出了其致命缺陷:感知机只能解决线性可分问题。
最著名的反例就是**"异或(XOR)"问题**。对于输入(0,0)和(1,1),XOR输出0;对于(0,1)和(1,0),XOR输出1。你无法在二维平面上用一条直线 将这两组点((0,0),(1,1) vs (0,1),(1,0))分开。这个看似简单的问题,却成了单层感知机的"滑铁卢"。这一发现极大地打击了当时对神经网络的热情,使其研究进入了长达十余年的"寒冬"。然而,也正是这个局限性,迫使研究者们思考:单个神经元不行,那多个神经元组合起来呢?
9.2 多层感知机(MLP)与反向传播算法
要突破线性枷锁,就需要构建更复杂的模型。解决方案是将多个感知机(或更通用的神经元)堆叠起来,形成多层感知机(Multi-Layer Perceptron, MLP)。
9.2.1 突破线性枷锁:从单层到多层
网络结构 一个MLP至少包含三层:
- 输入层(Input Layer):接收原始的特征数据。它不算作真正的计算层,只是数据的入口。
- 隐藏层(Hidden Layers):位于输入层和输出层之间,可以有一层或多层。这些层对输入数据进行一系列非线性的变换,是神经网络"魔力"的核心所在。
- 输出层(Output Layer):产生最终的预测结果。
"深度"的由来 当一个神经网络包含一个或多个隐藏层时,我们就开始称其为深度神经网络(Deep Neural Network, DNN),这也是"深度学习"一词的来源。每一层隐藏层都可以看作是对前一层输出的特征进行更高层次、更抽象的组合与表达。例如,在图像识别中,第一层可能学习到边缘和角点,第二层可能将边缘组合成眼睛、鼻子等部件,第三层则可能将这些部件组合成一张人脸。正是这种层次化的特征学习能力,使得深度网络能够解决像XOR这样复杂的非线性问题。
通用近似定理(Universal Approximation Theorem) 这个重要的理论指出:一个包含单个隐藏层 、且该隐藏层有足够多神经元 并使用非线性激活函数的MLP,可以以任意精度近似任何连续函数。这从理论上保证了神经网络的强大表达能力。它告诉我们,只要网络"足够宽",它就能拟合出任意复杂的形状。而"深度"学习则进一步表明,增加网络的深度(层数)通常比增加宽度(神经元数量)更有效率。
9.2.2 反向传播(Backpropagation):神经网络的"灵魂"算法
有了多层结构,我们如何有效地训练这个包含成千上万个权重的复杂网络呢?答案就是反向传播算法,它与梯度下降法相结合,构成了现代神经网络训练的基石。
核心思想 反向传播的核心是微积分中的链式法则(Chain Rule)。它是一种高效计算复杂函数梯度的方法。
- 前向传播(Forward Pass):将一个训练样本输入网络,信号从输入层逐层向前传播,经过每一层的计算,最终在输出层得到一个预测值。
- 计算损失(Loss Calculation) :将预测值与真实标签进行比较,通过一个损失函数(如分类任务的交叉熵损失,回归任务的均方误差损失)来量化模型的"错误"程度。
- 反向传播(Backward Pass) :
- 首先,计算损失函数对输出层权重的梯度。
- 然后,利用链式法则,将这个"误差信号"逐层向后(反向)传播。在每一层,我们都计算出损失对该层权重的梯度。
- 这个过程就像是在"追究责任":输出层的误差有多大"责任"应该由倒数第二层承担?倒数第二层的误差又该如何分配给更前一层的权重?反向传播完美地解决了这个"责任分配"问题。
梯度下降的再次登场 一旦通过反向传播计算出了网络中所有权重 相对于总损失的梯度,接下来的步骤就和我们熟悉的梯度下降完全一样了:用这些梯度来更新每一个权重,使得总损失向着减小的方向移动一小步。 w_new = w_old - η * (∂Loss / ∂w) 这个"前向传播 -> 计算损失 -> 反向传播 -> 更新权重"的循环,会通过成千上万个训练样本不断迭代,最终将网络训练到一个能够很好地完成任务的状态。
9.3 激活函数:为神经网络注入"灵魂"
在MLP的讨论中,我们提到了"非线性激活函数"。它是将简单的线性模型转变为强大的非线性学习机器的关键。
9.3.1 为何需要非线性激活函数?
想象一下,如果我们使用的激活函数是线性的(例如 f(z) = z)。那么,一个隐藏层的输出就是其输入的线性组合。当这个输出再作为下一层的输入时,最终整个网络的输出仍然只是原始输入的某种线性组合。这意味着,无论你堆叠多少层,整个网络本质上等价于一个单层的线性模型。它将失去学习复杂非线性关系的能力,退化成一个普通的线性分类器或回归器。
因此,非线性激活函数是赋予神经网络深度和表达能力的"灵魂"。
9.3.2 常用激活函数巡礼
- Sigmoid :
f(z) = 1 / (1 + e⁻ᶻ)- 特点 :将任意实数压缩到
(0, 1)区间,常用于二分类问题的输出层(表示概率)。 - 缺点:当输入值非常大或非常小时,其导数(梯度)趋近于0,这会导致**梯度消失(Vanishing Gradients)**问题,使得深层网络的训练非常困难。
- 特点 :将任意实数压缩到
- Tanh(双曲正切) :
f(z) = (eᶻ - e⁻ᶻ) / (eᶻ + e⁻ᶻ)- 特点 :将任意实数压缩到
(-1, 1)区间,是"以0为中心"的,通常比Sigmoid收敛更快。 - 缺点:同样存在梯度消失问题。
- 特点 :将任意实数压缩到
- ReLU(Rectified Linear Unit) :
f(z) = max(0, z)- 特点 :现代神经网络最常用的激活函数。它计算非常简单(一个阈值判断),并且在正数区间的梯度恒为1,极大地缓解了梯度消失问题,使得训练深层网络成为可能。
- 缺点:当输入为负数时,其梯度为0,可能导致某些神经元永远无法被激活,即**"死亡ReLU问题"(Dying ReLU Problem)**。
- Leaky ReLU, PReLU, ELU:这些都是对ReLU的改进,试图解决"死亡ReLU问题"。例如,Leaky ReLU在输入为负数时,会给一个非常小的正斜率(如0.01),而不是0。
- Softmax :
f(zᵢ) = eᶻᵢ / Σⱼ(eᶻⱼ)- 特点 :它不是作用于单个神经元,而是作用于整个输出层 。它能将输出层的一组任意实数值,转换为一个和为1的概率分布。因此,它是多分类问题输出层的标准选择。
9.4 使用Scikit-Learn与Keras/TensorFlow构建你的第一个神经网络
理论学习之后,最好的消化方式就是动手实践。我们将从我们熟悉的Scikit-Learn开始,然后迈向更专业的深度学习框架。
9.4.1 Scikit-Learn中的MLPClassifier与MLPRegressor
Scikit-Learn为我们提供了一个易于使用的MLP实现,非常适合进行快速的原型验证。
代码实现
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 使用月牙形数据,这是一个典型的非线性可分问题
X, y = make_moons(n_samples=200, noise=0.2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 神经网络对特征尺度敏感,标准化是重要步骤
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 构建和训练MLP
# hidden_layer_sizes=(10, 5) 表示两个隐藏层,第一个10个神经元,第二个5个
mlp = MLPClassifier(hidden_layer_sizes=(10, 5), max_iter=1000, random_state=42)
mlp.fit(X_train_scaled, y_train)
print(f"Scikit-Learn MLP Accuracy: {mlp.score(X_test_scaled, y_test):.4f}")核心超参数
hidden_layer_sizes: 一个元组,定义了每个隐藏层的神经元数量。activation: 激活函数,默认为'relu'。solver: 权重优化的求解器,默认为'adam',一个高效的梯度下降变体。alpha: L2正则化的强度。
局限性:Scikit-Learn的MLP实现功能相对基础,不支持GPU加速,也无法方便地构建如卷积神经网络(CNN)、循环神经网络(RNN)等复杂的网络结构。当我们需要更大的灵活性和性能时,就需要转向专业的深度学习框架。
9.4.2 迈向专业框架:TensorFlow与Keras简介
- TensorFlow:由Google开发的开源深度学习平台。它是一个强大的底层引擎,提供了构建和部署大规模机器学习模型所需的全套工具。
- Keras:一个高级神经网络API,以其用户友好、模块化和可扩展性而闻名。它现在已经正式成为TensorFlow项目的官方高级API。
它们的关系可以理解为:Keras是"前端",负责以简单直观的方式定义网络结构;TensorFlow是"后端",负责在底层高效地执行计算。
9.4.3 Keras实战:序贯模型(Sequential API)入门
Keras最简单的模型是序贯模型(Sequential Model),它允许我们像堆叠积木一样,一层一层地构建网络。
代码实现
# 需要先安装tensorflow: pip install tensorflow
import tensorflow as tf
from tensorflow import keras
# 1. 构建模型
# Sequential模型是一个线性的层堆栈
model = keras.Sequential([
# Dense层就是全连接层。input_shape只需在第一层指定。
keras.layers.Dense(10, activation='relu', input_shape=(X_train_scaled.shape[1],)),
keras.layers.Dense(5, activation='relu'),
# 输出层,因为是二分类,用一个sigmoid神经元
keras.layers.Dense(1, activation='sigmoid')
])
# 2. 编译模型
# 在这里我们定义损失函数、优化器和评估指标
model.compile(optimizer='adam',
loss='binary_crossentropy', # 二分类交叉熵
metrics=['accuracy'])
# 打印模型概览
model.summary()
# 3. 训练模型
# epochs: 训练轮数; batch_size: 每批次样本数
history = model.fit(X_train_scaled, y_train, epochs=100, batch_size=16, verbose=0) # verbose=0不打印过程
# 4. 评估模型
loss, accuracy = model.evaluate(X_test_scaled, y_test)
print(f"\nKeras MLP Accuracy: {accuracy:.4f}")代码对比 :通过与Scikit-Learn的对比,我们可以看到Keras的实现更加清晰和模块化。每一层都是一个独立的对象,我们可以自由地组合它们。compile和fit的步骤也让我们对训练过程有了更精细的控制。这种设计哲学,为我们未来构建更复杂的深度学习模型铺平了道路。
结语
本章,我们成功地搭建了从经典机器学习通往深度学习的桥梁。我们从生物学的灵感出发,理解了感知机的诞生与局限,见证了多层感知机如何通过"深度"和"非线性"打破枷锁。我们揭开了反向传播算法的神秘面纱,并熟悉了激活函数这个神经网络的"灵魂"家族。
最重要的是,我们跨出了从使用便捷工具到掌握专业框架的关键一步。您现在已经具备了使用Keras/TensorFlow构建和训练神经网络的基本能力。
这并非我们旅程的终点,而是一个更宏大、更激动人心的起点。深度学习的世界广阔无垠,卷积神经网络在计算机视觉中叱咤风云,循环神经网络在自然语言处理中大放异彩。愿本章所学,能成为您探索这个新世界的坚实基石和不竭动力。
第三部分:登堂入室------高级专题与实战演练
核心目标: 将理论知识应用于真实世界的复杂问题。提供从数据获取到模型部署的全流程项目指导,并介绍更前沿的领域,开拓学习者视野。
第十章:实战项目一:金融风控------信用卡欺诈检测
- 10.1 问题定义与数据探索:理解不平衡数据
- 10.2 特征工程与采样技术(SMOTE)
- 10.3 模型选择、训练与评估
- 10.4 解释性分析:模型为何做出这样的决策? (SHAP/LIME)
欢迎来到我们的第一个综合实战项目。在本章中,我们将化身为一名金融科技公司的数据科学家,直面一个极具挑战性且价值巨大的任务:构建一个信用卡欺诈检测模型。这个项目将不再是孤立地学习某个算法,而是要求我们综合运用数据探索、特征工程、模型训练、评估和解释等一系列技能,来解决一个真实的商业问题。
我们将要处理的数据有一个非常显著的特点------严重的类别不平衡。在现实世界中,绝大多数的信用卡交易都是合法的,欺诈交易只占极小的一部分。这种不平衡性给模型训练带来了巨大的挑战,也使得我们必须重新审视和选择合适的评估指标。
本章的目标不仅是构建一个高精度的模型,更是要经历一个完整的、端到端的数据科学项目流程。我们将学习如何处理不平衡数据,如何在多个模型和策略中进行权衡,以及如何利用先进的工具来"打开"模型的黑箱,理解其决策背后的逻辑。这对于在金融、医疗等高风险领域建立可信赖的AI系统至关重要。
10.1 问题定义与数据探索:理解不平衡数据
在动手写代码之前,首要任务是清晰地理解问题和我们手中的数据。
10.1.1 业务背景与问题定义
-
业务目标:银行或金融机构的核心诉求是,在不影响绝大多数正常用户交易体验的前提下,尽可能准确、快速地识别出欺诈交易,以减少资金损失。这里存在一个天然的权衡:
- 漏报(False Negative):将欺诈交易误判为正常交易。这是最严重的错误,直接导致资金损失。
- 误报(False Positive):将正常交易误判为欺诈交易。这会给用户带来不便(如交易被拒,需电话核实),影响用户体验。
- 我们的模型需要在降低漏报率(即提高召回率 )和控制误报率(即提高精确率)之间找到一个最佳平衡点。
-
机器学习问题定性 :这是一个典型的二分类问题 。输入是交易的各项特征,输出是两个类别之一:
0(正常)或1(欺诈)。其核心难点在于"欺诈"这个类别是极少数类。
10.1.2 数据集介绍与探索性数据分析(EDA)
我们将使用Kaggle上一个非常经典的"信用卡欺诈检测"数据集。
数据加载与初步观察
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
df = pd.read_csv('creditcard.csv')
# 查看数据基本信息
print(df.head())
print(df.info())
print(df.describe())
# 检查缺失值
print("\n缺失值检查:")
print(df.isnull().sum().max())- 特征分析 :数据包含31列。
Time是自第一笔交易以来的秒数。Amount是交易金额。Class是我们的目标变量(1表示欺诈,0表示正常)。V1到V28是经过**主成分分析(PCA)**处理后的特征,这是为了保护用户隐私和数据安全。PCA处理过后的特征已经去除了原始意义,并且尺度相对统一,但Time和Amount还保留着原始尺度。
不平衡性可视化 这是理解本问题的关键第一步。
# 查看类别分布
class_counts = df['Class'].value_counts()
print("\n类别分布:")
print(class_counts)
# 绘制计数图
plt.figure(figsize=(8, 6))
sns.countplot(x='Class', data=df)
plt.title(f'Class Distribution \n (0: Normal || 1: Fraud)')
plt.show()
# 计算比例
fraud_percentage = (class_counts[1] / class_counts.sum()) * 100
print(f"欺诈交易占比: {fraud_percentage:.4f}%")我们会发现,欺诈交易的数量(492笔)相对于正常交易(284,315笔)来说微乎其微,占比仅为约0.1727%。这种悬殊的比例是我们在后续所有工作中都必须牢记的核心背景。
Amount和Time特征的分布
我们来观察一下这两个未经PCA处理的特征与欺诈行为的关系。
fig, axes = plt.subplots(1, 2, figsize=(18, 4))
# 交易金额分布
sns.histplot(df['Amount'], ax=axes[0], bins=50, kde=True)
axes[0].set_title('Distribution of Transaction Amount')
# 交易时间分布
sns.histplot(df['Time'], ax=axes[1], bins=50, kde=True)
axes[1].set_title('Distribution of Transaction Time')
plt.show()
# 查看欺诈交易和正常交易在Amount上的差异
print("\n交易金额描述 (正常 vs 欺诈):")
print(df.groupby('Class')['Amount'].describe())通过对Amount的描述性统计,我们可能会发现欺诈交易的平均金额与正常交易有所不同。同时,我们也可以绘制欺诈交易和正常交易在Time和Amount上的分布图,来更直观地寻找差异。
# 欺诈和正常交易的金额与时间分布对比
fig, axes = plt.subplots(2, 1, figsize=(12, 10), sharex=True)
sns.histplot(df.loc[df['Class'] == 1, 'Amount'], bins=30, ax=axes[0], color='r', label='Fraud')
axes[0].set_title('Amount Distribution for Fraudulent Transactions')
axes[0].legend()
sns.histplot(df.loc[df['Class'] == 0, 'Amount'], bins=30, ax=axes[1], color='b', label='Normal')
axes[1].set_title('Amount Distribution for Normal Transactions')
axes[1].legend()
plt.xlim((0, 5000)) # 限制x轴范围以便观察
plt.show()我们已经看到了Amount和Time的整体分布,现在让我们更细致地比较一下正常交易与欺诈交易在这两个维度上的差异。
# 欺诈和正常交易的金额与时间分布对比
fig, axes = plt.subplots(2, 2, figsize=(18, 10))
# --- Amount 对比 ---
sns.kdeplot(df.loc[df['Class'] == 0, 'Amount'], ax=axes[0, 0], label='Normal', fill=True)
sns.kdeplot(df.loc[df['Class'] == 1, 'Amount'], ax=axes[0, 1], label='Fraud', fill=True, color='r')
axes[0, 0].set_title('Amount Distribution (Normal)')
axes[0, 1].set_title('Amount Distribution (Fraud)')
axes[0, 0].set_xlim(-50, 500) # 限制范围以便观察
axes[0, 1].set_xlim(-50, 500)
# --- Time 对比 ---
# 时间特征以秒为单位,跨度为两天,可能存在昼夜模式
sns.kdeplot(df.loc[df['Class'] == 0, 'Time'], ax=axes[1, 0], label='Normal', fill=True)
sns.kdeplot(df.loc[df['Class'] == 1, 'Time'], ax=axes[1, 1], label='Fraud', fill=True, color='r')
axes[1, 0].set_title('Time Distribution (Normal)')
axes[1, 1].set_title('Time Distribution (Fraud)')
plt.tight_layout()
plt.show()观察与发现:
- 金额(Amount):正常交易的金额分布非常广泛,而欺诈交易的金额似乎更集中在较小的数值区域。这可能是一个有用的信号。
- 时间(Time):正常交易的时间分布呈现出明显的周期性,有两个低谷,这很可能对应着深夜交易量减少的模式。而欺诈交易的时间分布则显得更加均匀,似乎全天候都在发生。
这些初步的EDA(探索性数据分析)给了我们信心,说明这些特征中确实包含了可以用于区分两类交易的信息。
10.2 特征工程与采样技术
在将数据喂给模型之前,我们需要进行一些必要的准备工作。
10.2.1 特征标准化
Amount和Time特征的数值范围(Amount可以上万,Time可以达到十几万)与其他经过PCA处理的V1-V28特征(大多集中在0附近)差异巨大。如果直接使用,可能会导致那些数值范围大的特征在模型训练中占据主导地位,特别是对于那些对尺度敏感的算法(如逻辑回归、SVM、神经网络)。因此,标准化是必不可少的步骤。
RobustScaler是一个不错的选择,因为它使用四分位数进行缩放,对于异常值不那么敏感,而金融数据中往往存在一些极端的大额交易。
from sklearn.preprocessing import RobustScaler
# 创建RobustScaler实例
rob_scaler = RobustScaler()
# 对Amount和Time进行缩放
df['scaled_amount'] = rob_scaler.fit_transform(df['Amount'].values.reshape(-1,1))
df['scaled_time'] = rob_scaler.fit_transform(df['Time'].values.reshape(-1,1))
# 删除原始的Time和Amount列
df.drop(['Time','Amount'], axis=1, inplace=True)
# 将scaled_amount和scaled_time移动到前面,方便查看
scaled_amount = df['scaled_amount']
scaled_time = df['scaled_time']
df.drop(['scaled_amount', 'scaled_time'], axis=1, inplace=True)
df.insert(0, 'scaled_amount', scaled_amount)
df.insert(1, 'scaled_time', scaled_time)
print("标准化后的数据头部:")
print(df.head())10.2.2 应对类别不平衡:采样技术
这是本项目最核心的挑战。如果直接在原始的不平衡数据上训练,大多数模型会学到一个"偷懒"的策略:将所有交易都预测为正常。这样做虽然能达到99.8%以上的准确率,但它完全没有识别出任何欺诈交易,对于我们的业务目标来说毫无价值。
下采样(Undersampling) 最简单的方法是随机删除多数类(正常交易)的样本,使其数量与少数类(欺诈交易)相匹配。
- 优点:速度快,数据集变小,训练成本降低。
- 缺点 :会丢失大量信息。被删除的正常交易样本中可能包含了区分正常与欺诈的重要模式。
过采样(Oversampling) 与下采样相反,我们可以增加少数类样本的数量,通常通过随机复制来实现。
- 优点:没有信息丢失。
- 缺点 :由于是简单复制,容易导致模型对特定的少数类样本过拟合。
10.2.3 SMOTE:更智能的过采样
为了解决简单过采样的过拟合问题,**SMOTE(Synthetic Minority Over-sampling Technique)**被提了出来。
- 核心思想 :SMOTE不是简单地复制少数类样本,而是合成 新的、看起来很真实的少数类样本。其过程是:
- 随机选择一个少数类样本
A。 - 找到它在少数类样本中的
k个最近邻(k通常为5)。 - 从这
k个近邻中随机选择一个样本B。 - 在
A和B之间的连线上随机取一点,作为新的合成样本。这个新样本的计算公式是A + λ * (B - A),其中λ是一个0到1之间的随机数。
- 随机选择一个少数类样本
- 效果:通过这种方式,SMOTE为少数类生成了新的、多样化的样本,扩大了少数类的决策区域,有助于模型学习到更鲁棒的分类边界。
代码实现
我们将使用一个非常流行的库 imbalanced-learn 来实现SMOTE。如果尚未安装,请先运行:
pip install -U imbalanced-learn现在,让我们在代码中实际应用SMOTE。关键在于,SMOTE只能应用于训练集,绝不能应用于测试集。因为测试集必须保持其原始的、真实的数据分布,以公正地评估模型的泛化能力。
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
import pandas as pd
# 假设 df 是我们已经完成特征标准化的DataFrame
# X 是特征, y 是标签
X = df.drop('Class', axis=1)
y = df['Class']
# 1. 首先,划分训练集和测试集
# 使用 stratify=y 来确保训练集和测试集中的类别比例与原始数据集一致
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
print("--- 数据划分后 ---")
print("原始训练集中的类别分布:")
print(y_train.value_counts())
print("\n原始测试集中的类别分布:")
print(y_test.value_counts())
# 2. 创建SMOTE实例并应用于训练集
print("\n--- 应用SMOTE ---")
smote = SMOTE(random_state=42)
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
# 3. 检查SMOTE处理后训练集的类别分布
print("\nSMOTE处理后训练集的类别分布:")
print(y_train_smote.value_counts())代码解读:
- 我们首先将整个数据集划分为训练集和测试集。这是至关重要的一步。
- 然后,我们创建了一个
SMOTE对象。 - 最关键的一行是
smote.fit_resample(X_train, y_train)。fit_resample方法会学习训练数据中少数类的分布,并生成新的合成样本,最终返回一个类别完全平衡 的新训练集X_train_smote和y_train_smote。 - 从输出可以看到,经过SMOTE处理后,训练集中的少数类(欺诈)样本数量被提升到与多数类(正常)相同,而测试集则保持原样,这完全符合我们的要求。
现在,我们拥有了一个经过SMOTE处理、类别平衡的训练集 (X_train_smote, y_train_smote),以及一个原始的、不平衡的测试集 (X_test, y_test)。接下来,我们就可以放心地使用这个新的训练集来训练我们的模型了。
10.3 模型选择、训练与评估
现在,我们准备好进入模型构建阶段了。
10.3.1 选择合适的评估指标
正如之前所说,**准确率(Accuracy)**在这里是完全不可信的。我们需要关注那些能真实反映模型在不平衡数据上表现的指标:
- 精确率(Precision) :
TP / (TP + FP)。在所有被模型预测为"欺诈"的交易中,真正是欺诈的比例。它衡量了模型的查准率,高精确率意味着低的误报率。 - 召回率(Recall) :
TP / (TP + FN)。在所有真正的欺诈交易中,被模型成功识别出来的比例。它衡量了模型的查全率,高召回率意味着低的漏报率。 - F1-Score:精确率和召回率的调和平均数,是两者的综合考量。
- PR曲线(Precision-Recall Curve) :以召回率为横轴,精确率为纵轴绘制的曲线。曲线下的面积(AUC-PR)是衡量模型整体性能的优秀指标,尤其是在不平衡场景下。一个理想模型的PR曲线会尽可能地靠近右上角。
10.3.2 模型训练与比较
我们将进行一个对比实验,看看不同数据处理策略对模型性能的影响。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, precision_recall_curve, auc
from imblearn.over_sampling import SMOTE
# 准备数据
X = df.drop('Class', axis=1)
y = df['Class']
# 划分原始数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# --- 1. 在原始不平衡数据上训练 ---
print("--- 1. 训练于原始不平衡数据 ---")
lr_original = LogisticRegression(solver='liblinear')
lr_original.fit(X_train, y_train)
y_pred_original = lr_original.predict(X_test)
print(classification_report(y_test, y_pred_original, target_names=['Normal', 'Fraud']))
# --- 2. 使用SMOTE处理数据并训练 ---
print("\n--- 2. 训练于SMOTE处理后的数据 ---")
smote = SMOTE(random_state=42)
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
print("SMOTE处理后训练集类别分布:")
print(y_train_smote.value_counts())
lr_smote = LogisticRegression(solver='liblinear')
lr_smote.fit(X_train_smote, y_train_smote)
y_pred_smote = lr_smote.predict(X_test)
print(classification_report(y_test, y_pred_smote, target_names=['Normal', 'Fraud']))结果分析:
- 在原始数据上训练的模型,其对欺诈类(Fraud)的**召回率(recall)**会非常低,这意味着它漏掉了大量的欺诈交易。
- 在SMOTE处理过的数据上训练的模型,其对欺诈类的召回率会显著提升,但**精确率(precision)**可能会有所下降。这是一种典型的权衡。
10.3.3 精调与决策
仅仅得到预测类别是不够的,我们还需要利用预测概率来做更精细的决策。
阈值移动(Threshold Moving) 大多数分类器默认使用0.5作为分类阈值。我们可以通过调整这个阈值,来主动地在精确率和召回率之间进行权衡。
# 获取SMOTE模型在测试集上的预测概率
y_proba_smote = lr_smote.predict_proba(X_test)[:, 1]
# 计算PR曲线
precision, recall, thresholds = precision_recall_curve(y_test, y_proba_smote)
auc_pr = auc(recall, precision)
# 绘制PR曲线
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, label=f'Logistic Regression (AUC-PR = {auc_pr:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc='best')
plt.grid(True)
plt.show()通过观察PR曲线,业务决策者可以选择一个最符合他们风险偏好的点。例如,如果银行对漏报的容忍度极低,他们可能会选择一个高召回率、中等精确率的阈值点。
10.4 解释性分析:模型为何做出这样的决策?
一个模型即使表现再好,如果它是一个完全的"黑箱",在金融风控这样的高风险领域也很难被完全信任和采纳。我们需要知道模型做出决策的依据。
10.4.1 模型可解释性的重要性
- 建立信任:让业务人员和监管机构相信模型是可靠的。
- 模型调试:理解模型的错误,发现其决策逻辑的漏洞。
- 发现新知:从模型的决策模式中,可能会发现一些人类专家未曾注意到的欺诈模式。
- 满足合规:很多地区的法规(如GDPR)要求对算法决策给出解释。
10.4.2 SHAP(SHapley Additive exPlanations)简介
SHAP是一个基于博弈论中沙普利值(Shapley Value)的、强大的模型解释框架。
- 核心思想:它将模型的单次预测结果看作是所有特征共同协作完成的"收益",而SHAP值则公平地将这份"收益"(即预测值与基准值的差异)分配给每一个特征,量化了每个特征的贡献。
- SHAP值的含义:对于某个预测,一个特征的SHAP值为正,表示该特征将预测推向了正类(欺诈);为负,则表示推向了负类(正常)。
10.4.3 使用SHAP进行模型解释
我们将使用shap库来解释我们训练的LightGBM或XGBoost模型(因为它们通常性能更好,也更值得解释)。
pip install shap
import lightgbm as lgb
import shap
# 在SMOTE数据上训练一个LightGBM模型
lgbm = lgb.LGBMClassifier(random_state=42)
lgbm.fit(X_train_smote, y_train_smote)
# 1. 创建SHAP解释器
explainer = shap.TreeExplainer(lgbm)
# 2. 计算测试集的SHAP值
shap_values = explainer.shap_values(X_test)
# 3. 全局解释:特征重要性图 (Summary Plot)
# shap_values[1] 对应正类(欺诈)的SHAP值
shap.summary_plot(shap_values[1], X_test, plot_type="dot")Summary Plot解读:
- 每一行代表一个特征,按其全局重要性排序。
- 每个点代表一个样本。
- 点的颜色表示该样本上该特征的原始值(红色高,蓝色低)。
- 点在横轴上的位置表示该样本上该特征的SHAP值。
- 从图中我们可以看到,例如,
V14特征值较低(蓝色)时,其SHAP值为正,强烈地将预测推向"欺诈";而V12特征值较高(红色)时,其SHAP值为负,将预测推向"正常"。
个体解释:力图(Force Plot) 我们还可以对单个预测进行解释。
# 解释第一个测试样本
shap.initjs() # 初始化JS环境以便在notebook中绘图
shap.force_plot(explainer.expected_value[1], shap_values[1][0,:], X_test.iloc[0,:])Force Plot解读:
- 基准值(base value):是模型在整个数据集上的平均预测概率。
- 红色部分 :是将预测概率推高的特征。
- 蓝色部分 :是将预测概率拉低的特征。
- 这个图清晰地展示了对于这一个特定的交易,是哪些特征以及它们的取值,共同作用导致了最终的预测结果。
结语
通过这个实战项目,我们走完了一个完整的数据科学流程。我们从理解一个充满挑战的业务问题开始,通过细致的数据探索发现了核心难点------类别不平衡。我们学习并应用了SMOTE技术来处理这个问题,并选择了合适的评估指标来公正地评价我们的模型。最后,我们还利用SHAP这一强大工具,打开了模型的"黑箱",窥探了其决策的内在逻辑。
这不仅仅是一次技术的演练,更是一次思维的升华。您现在所掌握的,已经不再是零散的知识点,而是一套可以迁移到其他领域的、解决实际问题的完整方法论。
第十一章:实战项目二:自然语言处理------文本情感分析
- 11.1 文本数据的预处理:分词、停用词与向量化(TF-IDF, Word2Vec)
- 11.2 从传统模型到简单神经网络的情感分类
- 11.3 主题模型(LDA):挖掘文本背后的隐藏主题
在完成了对结构化数字世界的探索之后,我们的实战旅程将转向一个更贴近人类智慧核心的领域------自然语言处理(Natural Language Processing, NLP) 。本项目中,我们将挑战一个NLP中最经典、也最具商业价值的任务之一:文本情感分析(Sentiment Analysis)。
我们的目标是教会机器去"阅读"一段文本(例如一条电影评论、一条产品反馈),并判断其中蕴含的情感是积极的、消极的还是中性的。这项技术是构建智能客服、进行舆情监控、分析用户反馈等众多应用的核心。
与上一个项目不同,我们这次面对的不再是整齐的、数值化的数据,而是由词语、句子和段落组成的非结构化文本。因此,本章的重点将首先聚焦于如何将这些人类语言"翻译"成机器能够理解的数学语言------即文本向量化。我们将探索从经典的TF-IDF到更现代的Word2Vec词嵌入技术。
随后,我们将分别使用传统机器学习模型和简单的神经网络来构建情感分类器,并比较它们的性能。最后,我们还将学习一种强大的无监督技术------主题模型(LDA),它能帮助我们自动地从海量文本中挖掘出人们正在讨论的核心话题,为我们提供超越情感分类的更深层次洞察。
11.1 文本数据的预处理:分词、停用词与向量化
在NLP中,原始文本数据往往是"嘈杂"的,需要经过一系列精心的预处理和转换,才能被机器学习模型所用。这个过程的好坏,直接决定了整个项目的成败。
11.1.1 NLP的第一步:文本清洗与规范化
我们将以一个IMDb电影评论数据集为例,这个数据集中包含了5万条带有正面或负面标签的电影评论。
数据加载与清洗流程
import pandas as pd
import re
# 假设数据已加载到DataFrame df 中,包含 'review' 和 'sentiment' 两列
# df = pd.read_csv('IMDB_Dataset.csv')
# 示例数据
data = {'review': ["This movie was awesome! The acting was great.",
"A truly TERRIBLE film. 1/10. Don't waste your time.",
"<br /><br />What a masterpiece!"],
'sentiment': ['positive', 'negative', 'positive']}
df = pd.DataFrame(data)
def clean_text(text):
# 1. 转换为小写
text = text.lower()
# 2. 移除HTML标签
text = re.sub(r'<.*?>', '', text)
# 3. 移除标点符号和数字
text = re.sub(r'[^a-z\s]', '', text)
# 4. 移除多余的空格
text = re.sub(r'\s+', ' ', text).strip()
return text
df['cleaned_review'] = df['review'].apply(clean_text)
print(df[['review', 'cleaned_review']])11.1.2 分词(Tokenization)与停用词(Stop Words)
清洗完成后,我们需要将连续的文本切分成独立的单元,即"词元"(Token)。
-
分词 :对于英文,分词相对简单,通常按空格和标点来切分。对于中文等没有明确单词边界的语言,则需要使用专门的分词算法库(如
jieba)。 -
停用词:文本中有很多词,如"a", "the", "is", "in"等,它们频繁出现但几乎不携带任何情感信息。这些词被称为"停用词",通常需要被移除,以减少噪声和计算量。
import nltk
nltk.download('stopwords') # 首次使用需要下载
nltk.download('punkt')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenizestop_words = set(stopwords.words('english'))
def tokenize_and_remove_stopwords(text):
tokens = word_tokenize(text)
filtered_tokens = [word for word in tokens if word not in stop_words]
return filtered_tokensdf['tokens'] = df['cleaned_review'].apply(tokenize_and_remove_stopwords)
print("\n分词与移除停用词后:")
print(df[['cleaned_review', 'tokens']])
11.1.3 将文本转化为向量:从词袋到词嵌入
这是最关键的一步:将词元列表转换为数值向量。
TF-IDF(Term Frequency-Inverse Document Frequency) TF-IDF是词袋模型(BoW)的一种经典升级。它认为一个词的重要性与它在**当前文档中出现的频率(TF)成正比,与它在所有文档中出现的频率(IDF)**成反比。一个词在当前文档里出现次数多,但在其他文档里很少出现,那么它很可能就是当前文档的关键词,应该被赋予高权重。
from sklearn.feature_extraction.text import TfidfVectorizer
# 为了使用TfidfVectorizer,我们需要将词元列表重新组合成字符串
df['processed_text'] = df['tokens'].apply(lambda x: ' '.join(x))
tfidf_vectorizer = TfidfVectorizer(max_features=5000) # 限制最大特征数为5000
X_tfidf = tfidf_vectorizer.fit_transform(df['processed_text'])
print("\nTF-IDF向量的维度:")
print(X_tfidf.shape) # (文档数, 特征数)
# 这是一个稀疏矩阵词嵌入(Word Embeddings) TF-IDF虽然经典,但它有一个重大缺陷:它无法理解词与词之间的语义关系。在TF-IDF看来,"good", "excellent", "superb"是三个完全不同的、毫无关联的词。
词嵌入技术解决了这个问题。
- 核心思想 :它将每个词映射到一个低维(如100维或300维)、稠密的浮点数向量。这个映射是通过在大量文本上训练一个神经网络来学习的,其学习目标是让上下文相似的词,其对应的向量在向量空间中也相互靠近。例如,"king"的向量会和"queen"的向量很接近。
- Word2Vec :是Google在2013年推出的一个里程碑式的词嵌入模型。它有两种主要的训练算法:
- CBOW (Continuous Bag-of-Words):根据上下文词来预测中心词。
- Skip-gram:根据中心词来预测上下文词。
- 使用预训练模型 :训练一个高质量的Word2Vec模型需要海量的文本和巨大的计算资源。幸运的是,我们可以直接使用Google、Facebook等机构在大规模语料库(如维基百科、新闻文章)上训练好的预训练词嵌入模型。
11.2 从传统模型到简单神经网络的情感分类
现在我们有了两种将文本表示为向量的方法,可以开始构建分类模型了。
11.2.1 使用TF-IDF与传统机器学习模型
TF-IDF产生的高维稀疏向量,与逻辑回归、朴素贝叶斯等线性模型是"天作之合"。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.preprocessing import LabelEncoder
# 准备标签
le = LabelEncoder()
y = le.fit_transform(df['sentiment'])
# 划分数据
X_train, X_test, y_train, y_test = train_test_split(X_tfidf, y, test_size=0.2, random_state=42)
# 训练逻辑回归模型
lr_model = LogisticRegression(solver='liblinear', random_state=42)
lr_model.fit(X_train, y_train)
# 评估
y_pred = lr_model.predict(X_test)
print("--- TF-IDF + 逻辑回归 模型评估 ---")
# 由于我们的示例数据太少,这里只展示流程,真实数据集上才能看到有意义的结果
# print(classification_report(y_test, y_pred, target_names=le.classes_))
print("模型训练完成。在真实数据集上,此方法通常能获得非常好的基线性能。")11.2.2 使用Word2Vec与神经网络
使用词嵌入时,我们需要先将一条评论中的所有词向量聚合成一个能代表整条评论的句子向量。最简单的方法是取平均值。
# 假设我们已经加载了一个预训练的Word2Vec模型 (例如 gensim.models.KeyedVectors.load_word2vec_format)
# word2vec_model = ...
# embedding_dim = word2vec_model.vector_size
# 此处为演示,我们创建一个假的Word2Vec模型
embedding_dim = 100
vocab = set(word for tokens_list in df['tokens'] for word in tokens_list)
word2vec_model = {word: np.random.rand(embedding_dim) for word in vocab}
def sentence_to_vector(tokens, model, embedding_dim):
# 将句子中所有词的向量相加,然后除以词数
vectors = [model[word] for word in tokens if word in model]
if not vectors:
return np.zeros(embedding_dim)
return np.mean(vectors, axis=0)
# 为每条评论创建句子向量
X_w2v = np.array([sentence_to_vector(tokens, word2vec_model, embedding_dim) for tokens in df['tokens']])
print("\nWord2Vec句子向量的维度:")
print(X_w2v.shape)
# 划分数据
X_train_w2v, X_test_w2v, y_train_w2v, y_test_w2v = train_test_split(X_w2v, y, test_size=0.2, random_state=42)
# 使用Keras构建一个简单的MLP
import tensorflow as tf
from tensorflow import keras
model = keras.Sequential([
keras.layers.Dense(64, activation='relu', input_shape=(embedding_dim,)),
keras.layers.Dropout(0.5), # Dropout层用于防止过拟合
keras.layers.Dense(1, activation='sigmoid') # 二分类输出
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 训练
# model.fit(X_train_w2v, y_train_w2v, epochs=10, batch_size=32, validation_split=0.1)
print("\n--- Word2Vec + 神经网络 模型 ---")
print("模型构建完成。这种方法能捕捉词汇的语义信息,在更复杂的NLP任务中潜力巨大。")性能对比:在简单的情感分析任务中,精心调优的TF-IDF+逻辑回归模型有时甚至不输于简单的神经网络。但词嵌入+神经网络的架构具有更强的扩展性,是通往更高级NLP模型(如RNN、LSTM、Transformer)的必经之路。
11.3 主题模型(LDA):挖掘文本背后的隐藏主题
情感分析告诉我们人们的评价是"好"是"坏",但我们还想知道,他们到底在讨论什么?
11.3.1 无监督的探索:什么是主题模型?
主题模型是一种无监督学习技术,它能在不知道任何标签的情况下,自动地从大量文档中发现隐藏的"主题"结构。
- LDA(Latent Dirichlet Allocation) 是最著名的主题模型。它的核心思想非常符合直觉:
- 一篇文章 被看作是多个主题的概率混合。例如,一篇影评可能是70%的"剧情"主题 + 20%的"演员"主题 + 10%的"配乐"主题。
- 一个主题 被看作是多个词语的概率分布。例如,"剧情"主题下,"plot", "story", "character"这些词出现的概率会很高。
11.3.2 LDA的实现与结果解读
LDA的输入不能是TF-IDF,而必须是基于词频计数的词袋模型矩阵。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# 1. 创建词频计数向量器
count_vectorizer = CountVectorizer(max_df=0.95, min_df=2, max_features=1000, stop_words='english')
X_counts = count_vectorizer.fit_transform(df['cleaned_review']) # 使用清洗后的文本
# 2. 训练LDA模型
# n_components 就是我们想要发现的主题数量
num_topics = 5
lda = LatentDirichletAllocation(n_components=num_topics, random_state=42)
lda.fit(X_counts)
# 3. 结果解读:打印每个主题下最重要的词
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
message = f"Topic #{topic_idx}: "
message += " ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]])
print(message)
print("\n--- LDA 主题发现结果 ---")
feature_names = count_vectorizer.get_feature_names_out()
print_top_words(lda, feature_names, 10)结果解读:通过观察每个主题下的高频词,我们可以人为地去"命名"和理解这个主题。例如,如果一个主题下都是"action", "fight", "explosion",我们就可以将其标记为"动作场面"主题。
11.3.3 应用场景与洞察
- 商业洞察:对于一个手机厂商,通过对海量用户评论运行LDA,可以自动发现用户最关心的几个方面是"电池续航"、"拍照效果"、"屏幕质量"还是"系统流畅度",从而指导产品改进。
- 内容聚合与推荐:将新闻文章按主题进行分类,为用户推荐他们感兴趣主题下的其他文章。
- 舆情监控:分析社交媒体上关于某个事件的讨论,看公众的讨论焦点在哪些方面。
结语
在本章中,我们成功地进入了自然语言处理的世界。我们掌握了处理文本数据的一整套流程:从清洗、分词,到使用TF-IDF和Word2Vec进行向量化。我们构建了能够判断文本情感的分类模型,并体验了从传统方法到神经网络的演进。最后,我们还学习了如何使用LDA这一无监督利器,从文本中挖掘出更深层次的、人类难以直接发现的主题结构。
您现在已经具备了分析文本数据的基本能力,为您打开了通往智能问答、机器翻译、文本生成等更高级NLP领域的大门。
第十二章:模型部署与工程化------让模型"活"起来
- 12.1 模型持久化:序列化与保存
- 12.2 使用Flask/FastAPI构建API服务
- 12.3 Docker容器化:为模型打造一个"家"
- 12.4 MLOps初探:自动化、监控与再训练
经过前面章节的艰苦跋涉,我们已经成功训练出了能够解决特定问题的机器学习模型。它们在我们的开发环境中表现优异,但这只是万里长征的第一步。一个真正有价值的模型,必须能够走出实验室,被集成到实际的应用程序中,为用户提供持续、可靠的服务。这个过程,就是模型部署与工程化。
本章,我们将聚焦于如何将我们精心训练的模型,从一个静态的文件,转变为一个动态的、可交互的、健壮的在线服务。我们将学习如何保存和加载模型,如何用Web框架为其创建一个API接口,如何用Docker将其打包成一个标准化的、可移植的"集装箱",最后,我们还将初步探讨MLOps的理念,了解如何对"活"起来的模型进行持续的生命周期管理。
掌握本章内容,意味着您将打通从数据到价值的"最后一公里",让您的算法真正落地生根,开花结果。
12.1 模型持久化:序列化与保存
12.1.1 为何需要持久化?
模型持久化,就是将内存中训练好的模型对象,以文件的形式保存到硬盘上。这是模型部署的绝对前提。
- 保存劳动成果:许多复杂的模型(尤其是深度学习模型)训练过程可能需要数小时甚至数天。将训练好的模型保存下来,我们就可以在任何时候重新加载它,而无需再次进行耗时耗力的训练。
- 实现部署迁移:我们通常在一个环境(如配备GPU的开发服务器)中训练模型,而在另一个或多个环境(如生产服务器集群)中使用模型。持久化使得我们可以轻松地将模型文件从一个地方复制到另一个地方。
12.1.2 Python中的序列化工具:pickle与joblib
序列化是将Python对象结构转换为字节流的过程,以便将其存储在文件中或通过网络传输。
pickle:是Python标准库中内建的序列化模块。它功能强大,可以序列化几乎任何Python对象。joblib:是一个由Scikit-learn社区维护的库,其序列化功能(joblib.dump和joblib.load)在处理包含大型NumPy数组的对象时,比pickle更高效。因此,对于Scikit-learn训练出的模型,官方推荐使用joblib。
12.1.3 实战演练:保存与加载Scikit-learn模型
让我们以之前训练的信用卡欺诈检测模型(例如,在SMOTE数据上训练的LightGBM模型)为例。
保存模型 在一个训练脚本(例如train.py)的末尾,我们可以添加如下代码:
# train.py
import joblib
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
import pandas as pd
# ... (此处省略数据加载、预处理、SMOTE和模型训练的代码) ...
# 假设 lgbm_model 是我们已经训练好的模型对象
# df = pd.read_csv('creditcard.csv')
# ... (预处理) ...
# X_train_smote, y_train_smote = ... (SMOTE) ...
# lgbm_model = lgb.LGBMClassifier(random_state=42)
# lgbm_model.fit(X_train_smote, y_train_smote)
# 定义保存路径和文件名
model_filename = 'fraud_detection_lgbm.joblib'
# 使用joblib.dump保存模型
# compress=3 是一个可选参数,表示压缩级别,可以减小文件大小
joblib.dump(lgbm_model, model_filename, compress=3)
print(f"模型已保存到: {model_filename}")加载并使用模型 现在,我们可以在一个全新的Python脚本(例如predict.py)中,加载这个模型并用它来进行预测,完全脱离原始的训练数据和训练过程。
# predict.py
import joblib
import numpy as np
# 加载模型
try:
loaded_model = joblib.load('fraud_detection_lgbm.joblib')
print("模型加载成功!")
except FileNotFoundError:
print("错误:找不到模型文件。请先运行训练脚本。")
exit()
# 准备一条新的、待预测的数据样本
# 特征维度和顺序需要与训练时严格一致
# 这里的new_data是一个示例,实际应用中它会来自API请求
# 假设有 scaled_time, scaled_amount, V1-V28,共30个特征
new_data = np.random.rand(1, 30)
# 使用加载的模型进行预测
prediction = loaded_model.predict(new_data)
prediction_proba = loaded_model.predict_proba(new_data)
print(f"\n对新数据的预测类别: {'欺诈' if prediction[0] == 1 else '正常'}")
print(f"预测为'正常'的概率: {prediction_proba[0][0]:.4f}")
print(f"预测为'欺诈'的概率: {prediction_proba[0][1]:.4f}")重要注意事项:版本依赖 序列化和反序列化(加载)过程对库的版本非常敏感。如果在Python 3.8和LightGBM 3.2版本下保存的模型,尝试在Python 3.9和LightGBM 4.0的环境下加载,很可能会失败。因此,在部署时,确保生产环境的库版本与训练环境的库版本严格一致是至关重要的。我们稍后将看到的Docker,正是解决这个问题的利器。
12.2 使用Flask/FastAPI构建API服务
模型文件本身还不能对外提供服务。我们需要一个程序,它能监听网络请求,接收传入的数据,调用模型进行预测,然后将结果返回给请求方。这个程序就是API服务。
12.2.1 API:模型与外界沟通的"窗口"
- API(Application Programming Interface):应用程序编程接口。它定义了不同软件组件之间如何相互通信。对于我们的模型,就是定义一个接收输入数据、返回预测结果的标准化网络接口。
- RESTful API :一种流行的API设计风格,它使用标准的HTTP方法(如GET, POST, PUT, DELETE)来操作资源。我们的预测服务通常会使用
POST方法,因为客户端需要向服务器发送包含特征数据的请求体。数据交换格式通常是JSON。
12.2.2 轻量级Web框架简介
- Flask:经典、灵活、易于上手的Python Web框架,是许多人入门Web开发和API构建的首选。
- FastAPI :一个现代、高性能的Web框架。它基于Python 3.6+的类型提示 ,并因此获得了两大"杀手级"特性:
- 极高的性能:可与NodeJS和Go相媲美。
- 自动生成交互式API文档 :基于OpenAPI(以前称为Swagger)和JSON Schema标准,极大地方便了API的测试和协作。 基于这些优点,我们选择FastAPI来构建我们的服务。
12.2.3 实战演练:使用FastAPI包装我们的模型
首先,安装FastAPI和其运行所需的ASGI服务器Uvicorn: pip install fastapi "uvicorn[standard]"
然后,我们创建一个名为main.py的文件。
# main.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
import joblib
import numpy as np
from typing import List
# 1. 创建FastAPI应用实例
app = FastAPI(title="信用卡欺诈检测API", description="一个使用LightGBM模型进行欺诈检测的API")
# 2. 定义输入数据的模型 (数据契约)
# 使用pydantic的BaseModel来定义请求体的数据结构和类型
class Transaction(BaseModel):
features: List[float] = Field(..., example=[0.1, -0.2, ..., 1.5], description="包含30个特征的列表")
class Config:
schema_extra = {
"example": {
"features": list(np.random.rand(30))
}
}
# 3. 加载我们训练好的模型
try:
model = joblib.load('fraud_detection_lgbm.joblib')
except FileNotFoundError:
# 在实际应用中,如果模型加载失败,服务应该无法启动
# 这里为了简单起见,我们只打印错误
model = None
print("错误:模型文件未找到!API将无法工作。")
# 4. 创建API端点 (endpoint)
@app.post("/predict", summary="进行欺诈检测预测")
def predict_fraud(transaction: Transaction):
"""
接收一笔交易的特征数据,返回其是否为欺诈的预测结果和概率。
- **transaction**: 包含特征列表的JSON对象。
- **返回**: 包含预测类别和概率的JSON对象。
"""
if model is None:
raise HTTPException(status_code=503, detail="模型当前不可用,请联系管理员。")
# 将输入的列表转换为NumPy数组,并reshape成(1, n_features)的形状
features_array = np.array(transaction.features).reshape(1, -1)
if features_array.shape[1] != 30: # 假设我们的模型需要30个特征
raise HTTPException(status_code=400, detail=f"输入特征数量错误,需要30个,但收到了{features_array.shape[1]}个。")
# 使用模型进行预测
prediction = model.predict(features_array)
probability = model.predict_proba(features_array)
# 准备返回结果
return {
"is_fraud": int(prediction[0]), # 预测类别 (0: 正常, 1: 欺诈)
"probability_normal": float(probability[0][0]),
"probability_fraud": float(probability[0][1])
}
# 创建一个根端点,用于健康检查
@app.get("/", summary="API健康检查")
def read_root():
return {"status": "ok", "message": "欢迎来到欺诈检测API!"}运行API服务 在终端中,切换到main.py所在的目录,然后运行: uvicorn main:app --reload
main: 指的是main.py文件。app: 指的是我们在main.py中创建的FastAPI对象app。--reload: 这个参数会让服务器在代码文件被修改后自动重启,非常适合开发阶段。
测试API 服务运行后,打开浏览器访问 http://127.0.0.1:8000/docs 。你会看到FastAPI自动生成的交互式API文档(Swagger UI)。你可以在这个页面上直接测试你的/predict端点,输入示例数据,然后点击"Execute",就能看到服务器返回的预测结果。这极大地提高了开发和调试的效率。
12.3 Docker容器化:为模型打造一个"家"
我们的API服务现在可以在本地运行了,但如果想把它部署到另一台服务器或云上,就会遇到"在我电脑上能跑"的经典困境。Docker正是为了解决这个问题而生的。
12.3.1 "在我电脑上能跑"的困境
问题的根源在于环境依赖的差异:
- Python版本不同。
scikit-learn,lightgbm,fastapi等库的版本不同。- 甚至操作系统底层的一些依赖库也可能不同。
12.3.2 Docker的核心思想:集装箱式的标准化
Docker通过"容器化"技术,将我们的应用程序及其所有依赖(代码、运行时、库、环境变量)打包到一个标准化的、可移植的单元中,这个单元就是容器。
- 镜像(Image):一个只读的模板,是容器的"蓝图"。
- 容器(Container):镜像的一个可运行实例。它与宿主系统和其他容器相互隔离,拥有自己独立的文件系统和网络空间。
- Dockerfile:一个文本文件,像一份"菜谱",定义了构建一个Docker镜像所需的所有步骤。
12.3.3 实战演练:将我们的FastAPI服务打包成Docker镜像
-
创建
requirements.txt文件 这个文件列出了我们项目的所有Python依赖。fastapi uvicorn[standard] scikit-learn lightgbm joblib numpy -
编写
Dockerfile在项目根目录下创建一个名为Dockerfile(没有扩展名)的文件。# 1. 选择一个官方的Python运行时作为基础镜像 FROM python:3.9-slim # 2. 设置工作目录 WORKDIR /app # 3. 复制依赖文件到工作目录 COPY requirements.txt . # 4. 安装依赖 RUN pip install --no-cache-dir -r requirements.txt # 5. 复制项目的所有文件到工作目录 COPY . . # 6. 暴露端口,让容器外的世界可以访问 EXPOSE 8000 # 7. 定义容器启动时要执行的命令 CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"] -
构建与运行 确保你的机器上已经安装了Docker。在终端中,确保你在
Dockerfile所在的目录下,然后执行:-
构建镜像 :
docker build -t fraud-detection-api .(-t参数为镜像命名,.表示使用当前目录的Dockerfile) -
运行容器 :
docker run -p 8000:8000 fraud-detection-api(-p 8000:8000将宿主机的8000端口映射到容器的8000端口)
-
现在,你的API服务就在一个隔离的、标准化的容器中运行了。你可以再次访问http://127.0.0.1:8000/docs来验证它 。这个容器可以被轻松地部署到任何安装了Docker的服务器或云平台上,完美地解决了环境依赖问题。
12.4 MLOps初探:自动化、监控与再训练
我们已经成功部署了模型,但这只是一个静态的部署。在真实世界中,数据是不断变化的,模型的生命周期管理是一个持续的过程。
12.4.1 超越一次性部署:模型的生命周期管理
- 模型退化(Model Decay):随着时间的推移,现实世界的数据分布可能会发生变化(例如,欺诈手段更新了),导致模型的预测性能逐渐下降。这就是"模型退化"。
- MLOps(Machine Learning Operations):它借鉴了软件工程中DevOps的理念,是一套旨在实现机器学习模型开发(Dev)、部署和运维(Ops)自动化与标准化的实践和原则。其目标是缩短模型迭代周期,提高部署质量和可靠性。
12.4.2 MLOps的核心理念
- CI/CD for ML :将持续集成/持续部署的思想应用于机器学习。
- CI(持续集成):代码(包括数据处理、模型训练代码)的任何变更都会自动触发测试和验证。
- CD(持续交付/部署):一旦模型通过所有测试,就会被自动部署到生产环境。
- 自动化流水线(Pipeline):将数据获取、预处理、特征工程、模型训练、评估、版本控制、部署等环节串联成一个自动化的工作流。
- 监控(Monitoring) :持续监控线上模型的性能。
- 技术指标:API的延迟、QPS、错误率。
- 模型指标 :预测结果的分布是否稳定?输入特征的分布是否发生了数据漂移(Data Drift)?如果能获取到真实标签,模型的准确率、召回率是否下降?
- 再训练(Retraining):建立触发机制(如性能下降到某个阈值,或定期如每周/每月),自动使用最新的数据对模型进行再训练,并生成新版本的模型,然后通过流水线进行评估和部署。
12.4.3 工具与展望
MLOps是一个庞大而复杂的领域,通常需要专门的工具和平台来支撑。
- 开源工具 :
- 实验追踪与模型注册 :
MLflow,DVC - 工作流编排 :
Kubeflow,Airflow - 模型服务 :
Seldon Core,KServe
- 实验追踪与模型注册 :
- 云平台服务 :各大云厂商都提供了端到端的MLOps解决方案,如
Amazon SageMaker,Google AI Platform (Vertex AI),Azure Machine Learning。它们将上述许多功能集成在了一起,降低了实施MLOps的门槛。
结语
本章,我们完成了从算法到服务的关键一跃。我们学会了如何保存和加载模型,如何用FastAPI为其穿上API的"外衣",如何用Docker为其打造一个标准化的"家",并最终将视野投向了MLOps这片更广阔的星辰大海。
至此,我们已经走完了一名数据科学家从入门到实践的全过程。您不仅掌握了机器学习的核心理论与算法,更具备了将模型付诸实践、创造真实价值的工程能力。这并非终点,而是一个全新的、激动人心的起点。愿您带着这份完整的知识体系,在数据科学的道路上,不断探索,不断创造,行稳致远。
第十三章:超越经典------未来展望与进阶路径
- 13.1 深度学习概览:CNN、RNN的世界
- 13.2 强化学习:与环境交互的智能体
- 13.3 图神经网络、联邦学习等前沿简介
- 13.4 "知行合一":如何持续学习与成长
亲爱的读者,当您抵达本书的终章,您已不再是旁观者,而是身怀绝技的入局者。您所掌握的经典机器学习理论与实践,是理解这个数据驱动时代的坚固基石。然而,技术的地平线总在不断向远方延伸,引领浪潮之巅的,正是深度学习那璀璨的群星。
本章,我们将以一种前所未有的深度,去探索深度学习的核心分支。我们不再满足于概念的罗列,而是要深入其设计的哲学,剖析其数学的肌理,追溯其演化的逻辑。我们将探讨每一个模型诞生的**"动机"** ------它解决了前辈的何种"困境"?我们还将提供一份详尽的"进阶路线图"**,**包含必读的"圣经级"论文及可上手的"里程碑式"项目和值得关注的"前沿方向"。
这不仅是知识的传递,更是一次思维的淬炼。愿您在本章的引领下,完成从"模型使用者"到"算法思想家"的蜕变。
13.1 深度学习进阶:从"万金油"到"特种兵"的架构演化
我们在第九章学习的多层感知机(MLP),本质上是一种强大的"通用函数拟合器"。它将输入数据"一视同仁"地展平为一维向量,并通过全连接层进行变换。这种"万金油"式的设计,在处理缺乏内在结构的数据时表现尚可。但当面对具有精巧结构的数据------如图像中像素的空间排列、语言中词语的时间序列------MLP的"一视同仁"就变成了它的"阿喀琉斯之踵"。它不仅会因参数量爆炸而陷入"维度灾难",更会粗暴地破坏掉数据中最宝贵的结构信息。
深度学习的革命性突破,正在于它发展出了一系列"特种兵"式的网络架构。这些架构内置了针对特定数据结构的归纳偏置(Inductive Bias),即一种基于先验知识的"世界观"假设。正是这些"偏见",让模型能更高效、更深刻地学习。
13.1.1 卷积神经网络(CNN):为"空间"而生的视觉大师
1. 动机与哲学:为何卷积?
-
困境 :用MLP处理一张仅为224x224x3的彩色图像(ImageNet竞赛的经典尺寸),输入层神经元数量高达150,528个。若第一个隐藏层有4096个神经元(AlexNet的配置),仅这一层的权重参数就将达到惊人的 6亿(150528 * 4096)!这在计算上难以承受,在数据上极易过拟合。更致命的是,它完全忽略了图像的两个基本先验:
- 局部相关性(Locality):一个像素的含义,与其紧邻的像素关系最密切。远隔千里的两个像素几乎没有直接关联。
- 平移不变性(Translation Invariance):一只猫,无论出现在图像的左上角还是右下角,它仍然是一只猫。我们寻找的特征(如猫的耳朵)应该与位置无关。
-
哲学突破:引入"空间"的归纳偏置 CNN的设计哲学,就是将这两个"先验"硬编码到网络结构中。它不再将图像看作扁平的向量,而是看作一个有长、宽、深(通道)的三维张量。
2. 核心武器库:CNN的两大基石
-
基石一:局部感受野(Local Receptive Fields)与卷积(Convolution)
- 机制 :CNN不再进行全连接,而是定义了一个个小的、共享的卷积核(Kernel/Filter) 。每个神经元只"看"输入图像的一小块区域(即局部感受野 ),这个区域的大小就是卷积核的大小(如3x3, 5x5)。卷积核内包含一组可学习的权重,它在整个输入图像上按步长(Stride)滑动,每滑动到一个位置,就与该位置的局部图像块进行点积运算 ,从而得到一个输出值。所有输出值共同构成一张特征图(Feature Map)。
- 意义:这完美地体现了"局部相关性"。每个输出值都只由一小片局部信息计算而来。一个卷积核,就像一个可学习的"模式探测器",专门负责寻找一种特定的微观模式,如水平边缘、绿色斑块或某个特定的纹理。
-
基石二:参数共享(Parameter Sharing)与池化(Pooling)
- 机制 :
- 参数共享 :用于生成同一张特征图的那个卷积核,其内部的权重在滑动到图像的任何位置时都是完全相同 的。这意味着,网络用同一套参数去寻找图像中所有位置的同一种特征。
- 池化:在卷积层之后,通常会接一个池化层(如最大池化Max Pooling)。它将特征图划分为若干个不重叠的区域(如2x2),并从每个区域中取最大值作为输出。
- 意义 :
- 参数共享是CNN最天才的设计。它直接将"平移不变性"的假设注入了模型,并使得模型的参数量从"亿"级别骤降到"万"甚至"千"级别,极大地提高了模型的泛化能力和训练效率。
- 池化操作则提供了另一种形式的平移不变性,并实现了对特征图的降采样,既减少了后续计算量,又增大了上层神经元的"感受野"(即它能看到的原始图像区域范围)。
- 机制 :
3. 架构演化与进阶路径
-
阶段一:奠基与验证 (LeNet-5, AlexNet)
- 必读论文:无需读LeCun 1998年的论文,可以直接看Krizhevsky等人2012年的《ImageNet Classification with Deep Convolutional Neural Networks》(AlexNet)。这篇论文是引爆深度学习革命的"宇宙大爆炸"奇点。
- 学习要点:理解经典的"卷积-激活-池化"堆叠模式。注意AlexNet如何使用ReLU激活函数代替Sigmoid/Tanh来解决梯度消失问题,以及如何使用Dropout来对抗过拟合。
- 实践项目 :在PyTorch或TensorFlow中,从零开始搭建一个类似LeNet-5或简化版AlexNet的结构,在MNIST或CIFAR-10数据集上进行训练。目标是亲手实现卷积层、池化层、全连接层的连接,并观察模型从随机权重开始学习到有效特征的过程。
-
阶段二:走向深度 (VGG, GoogLeNet)
- 必读论文:《Very Deep Convolutional Networks for Large-Scale Image Recognition》(VGG) 和 《Going Deeper with Convolutions》(GoogLeNet)。
- 学习要点 :
- VGG:探索了"深度"的力量。它证明了通过堆叠非常小的(3x3)卷积核,可以构建出比使用大卷积核更深、更有效的网络。其结构非常规整,易于理解。
- GoogLeNet :引入了创新的Inception模块,在一个网络层中并行地使用不同尺寸的卷积核和池化操作,然后将结果拼接起来。这让网络可以自适应地选择最合适的感受野来捕捉特征,实现了"宽度"和"深度"的结合。
- 实践项目 :学习使用Keras或PyTorch的API,加载一个预训练(Pre-trained)的VGG16或InceptionV3模型。然后,替换掉其顶部的全连接层,换上你自己定义的分类头,在一个新的、较小的数据集上(如猫狗分类)进行迁移学习(Transfer Learning)。这是工业界应用CNN最核心、最高效的范式。
-
阶段三:跨越瓶颈 (ResNet)
- 必读论文:何恺明等人的《Deep Residual Learning for Image Recognition》(ResNet),这是计算机视觉领域引用量最高的论文之一,思想深刻而优美。
- 学习要点 :当网络堆得非常深时,会出现"退化"现象(Deeper is not better)。ResNet天才地引入了残差连接(Residual Connection)/快捷连接(Shortcut Connection) 。它允许输入信号可以"跳过"一个或多个层,直接加到后续层的输出上。这使得网络需要学习的不再是完整的映射
H(x),而是一个更容易学习的残差F(x) = H(x) - x。如果某个层是多余的,网络只需将F(x)学习为0即可,这比让它学习一个恒等映射H(x)=x要容易得多。这一结构极大地缓解了深度网络的梯度消失和退化问题,使得训练成百上千层的网络成为可能。 - 实践项目:在代码中亲手实现一个"残差块(Residual Block)"。然后,尝试将你之前搭建的"平原网络(Plain Network)"改造为"残差网络",并比较两者在更深层数下的训练收敛性和最终性能。
-
前沿方向:
- 轻量化网络:MobileNet, ShuffleNet等,为在移动端和嵌入式设备上高效运行而设计。
- 注意力机制:Squeeze-and-Excitation Networks (SENet)等,让网络学习不同通道特征的重要性。
- 新架构探索:Vision Transformer (ViT) 将Transformer架构成功应用于视觉,挑战了CNN的统治地位。
13.1.2 循环神经网络(RNN)及其变体:为"时间"而生的序列诗人
1. 动机与哲学:为何循环?
-
困境 :无论是MLP还是CNN,它们都内含一个根本性的假设------输入数据(或特征)之间是相互独立的(i.i.d. assumption) 。这个假设在处理如语言、语音、金融时间序列等数据时,是完全错误的。对于序列数据,**顺序(Order)和上下文(Context)**是其灵魂。一个词的意义,严重依赖于它前面的词;今天的股价,与昨天的股价息息相关。CNN虽然能捕捉局部空间模式,但其固定大小的卷积核无法灵活处理长短不一、依赖关系复杂的序列。
-
哲学突破:引入"时间"的归纳偏置 RNN的设计哲学,是将"时间"和"记忆"的概念,直接编码到其网络结构中。它不再将序列视为一个静态的整体,而是将其视为一个随时间演化的动态过程。
2. 核心武器库:循环、状态与门控
-
基石一:循环连接(Recurrent Connection)与隐藏状态(Hidden State)
- 机制 :RNN的核心在于其神经元(或一层神经元)拥有一个自连接的循环边 。在处理序列的第
t个元素x_t时,RNN的计算单元不仅接收x_t作为输入,还接收来自上一个时间步t-1的输出 ,即隐藏状态h_{t-1}。它将两者结合起来,计算出当前时间步的隐藏状态h_t。这个过程可以用公式表达为:h_t = f(W * x_t + U * h_{t-1} + b),其中W和U是可学习的权重矩阵,f是激活函数(通常是tanh)。 - 意义 :隐藏状态
h_t成为了网络的**"记忆"。它理论上编码了从序列开始到当前时刻t的所有历史信息。在整个序列处理过程中,权重矩阵W和U是共享**的,这与CNN中卷积核的参数共享异曲同工,极大地减少了参数量,并使得模型能处理任意长度的序列。
- 机制 :RNN的核心在于其神经元(或一层神经元)拥有一个自连接的循环边 。在处理序列的第
-
基石二:门控机制(Gating Mechanism)------对抗遗忘的智慧
- 困境:长期依赖问题(Long-Term Dependencies Problem) 经典的RNN在实践中难以学习到相隔较远的词之间的依赖关系。这是因为在反向传播(BPTT)过程中,梯度需要穿越很长的时间步进行连乘。如果激活函数的导数长期小于1,梯度会指数级衰减,导致梯度消失(Vanishing Gradients) ;反之则会导致梯度爆炸(Exploding Gradients)。这使得网络几乎无法根据遥远未来的误差来调整遥远过去的权重。
- 解决方案:长短期记忆网络(LSTM) LSTM并非简单地用一个更复杂的激活函数,而是设计了一套精巧的内部记忆管理系统 。其核心是一个独立的细胞状态(Cell State, C_t) ,可以看作是一条信息高速公路,信息在上面可以很顺畅地流动而不发生剧烈变化。同时,LSTM引入了三个"门 "结构(本质上是带有Sigmoid激活函数的全连接层,输出0到1之间的值,代表信息的通过率)来精密地控制这条高速公路:
- 遗忘门(Forget Gate) :决定应该从上一个细胞状态
C_{t-1}中遗忘掉哪些旧信息。 - 输入门(Input Gate) :决定当前时刻有哪些新信息
x_t应该被存入到细胞状态中。 - 输出门(Output Gate) :决定当前细胞状态
C_t的哪些部分应该被输出 为当前时刻的隐藏状态h_t。 这种设计使得LSTM能够有选择地、动态地遗忘、记忆和输出信息,从而有效地捕捉长期依赖。
- 遗忘门(Forget Gate) :决定应该从上一个细胞状态
- 简化方案:门控循环单元(GRU) GRU是LSTM的一个流行变体。它将遗忘门和输入门合并为单一的更新门(Update Gate),并融合了细胞状态和隐藏状态。GRU的参数更少,计算效率更高,在许多任务上能取得与LSTM相当的性能,是实践中一个值得尝试的优秀替代方案。
3. 架构演化与进阶路径
-
阶段一:理解循环与记忆
- 必读文献:Chris Olah的博客文章《Understanding LSTM Networks》是全世界公认的、图文并茂的最佳入门材料,比直接阅读原始论文更直观。
- 学习要点 :不要满足于API调用,必须亲手在纸上或白板上画出LSTM单元的内部数据流图。清晰地理解输入
x_t和h_{t-1}是如何通过三个门和细胞状态,最终计算出h_t和C_t的。这是后续所有学习的基础。 - 实践项目:使用Keras或PyTorch,搭建一个字符级的RNN/LSTM语言模型。在一段文本(如莎士比亚的著作)上进行训练,然后让它从一个种子字符开始,自动生成新的文本。观察它是否能学习到单词拼写、空格、换行等语法规则,这是检验你是否真正理解序列建模的"试金石"。
-
阶段二:序列到序列(Seq2Seq)与注意力机制
- 必读论文:《Sequence to Sequence Learning with Neural Networks》和《Neural Machine Translation by Jointly Learning to Align and Translate》。
- 学习要点 :
- Seq2Seq架构:理解其经典的**编码器-解码器(Encoder-Decoder)**结构。编码器(一个RNN/LSTM)将整个输入序列压缩成一个固定长度的上下文向量(Context Vector),解码器(另一个RNN/LSTM)则以这个向量为初始状态,逐个生成输出序列的元素。
- 瓶颈:这个固定长度的上下文向量成为了信息瓶颈,难以承载长输入序列的全部信息。
- 注意力机制(Attention) :这是解决瓶颈的天才之举 。它允许解码器在生成每一个输出词时,不再只依赖那个固定的上下文向量,而是可以"回顾"编码器的所有隐藏状态,并为它们计算一个"注意力权重",然后对这些隐藏状态进行加权求和。这样,解码器在每一步都能动态地、有选择地聚焦于输入序列中最相关的部分。
- 实践项目:实现一个带注意力机制的Seq2Seq模型,用于完成一个简单的任务,如日期格式转换("2024-07-21" -> "July 21, 2024")或简单的机器翻译。
-
阶段三:Transformer的崛起(详见下一节) RNN及其变体虽然强大,但其固有的顺序计算特性使其难以在现代GPU上高效并行化,限制了其处理超长序列和构建超大规模模型的能力。这直接催生了下一代革命性架构的诞生。
13.1.3 注意力机制与Transformer:并行时代的NLP王者
1. 动机与哲学:为何抛弃循环?
-
困境 :RNN的"循环"既是其优点(记忆),也是其致命弱点。
t时刻的计算必须等待t-1时刻完成,这种顺序依赖使其无法利用GPU强大的并行计算能力。在处理长文档时,这种串行计算的效率低下问题尤为突出。此外,即使有LSTM/GRU,信息在序列中传递的路径依然很长,捕捉超长距离依赖仍然是一个挑战。 -
哲学突破:将"重要性"的计算并行化 注意力机制的成功启发了研究者们:如果模型可以直接计算出序列中任意两个位置之间的依赖关系,而无需通过循环结构逐步传递信息,那么是否可以完全抛弃循环?Transformer的回答是:可以! 它的核心哲学是,序列中一个元素的表示,应该由整个序列 中所有元素根据其重要性进行加权求和来定义。
2. 核心武器库:自注意力机制
- 机制:缩放点积注意力(Scaled Dot-Product Attention) 这是Transformer的灵魂。对于输入序列中的每一个元素(Token),我们都通过线性变换为其生成三个可学习的向量:
- 查询(Query, Q):代表了当前元素为了理解自己,需要去"查询"其他元素的信息。
- 键(Key, K):代表了序列中每个元素所携带的、可供"查询"的"标签"信息。
- 值(Value, V):代表了序列中每个元素实际包含的"内容"信息。 计算过程分为三步:
- 计算注意力分数 :将当前元素的Q向量,与所有 元素的K向量进行点积。这个分数直观地衡量了"查询"与"键"的匹配程度。
- 缩放与归一化 :将得到的分数除以一个缩放因子(通常是K向量维度的平方根),以防止梯度过小,然后通过Softmax函数将其归一化为和为1的概率分布。这就是"注意力权重"。
- 加权求和 :用得到的注意力权重,去加权求和所有元素的V向量。最终的结果,就是当前元素融合了全局上下文信息后的新表示。
- 关键增强 :
- 多头注意力(Multi-Head Attention):并行地运行多次独立的自注意力计算。每一"头"都学习将Q, K, V投影到不同的表示子空间中,从而让模型能够同时关注来自不同方面、不同位置的信息。这就像我们读书时,可以同时关注一句话的语法结构、语义内涵和情感色彩。
- 位置编码(Positional Encoding):由于自注意力机制本身不包含任何关于顺序的信息(它是一个"集合"操作),我们需要显式地为输入序列添加"位置编码"向量,将词的位置信息注入模型。
3. 架构演化与进阶路径
-
阶段一:奠基与理解
- 必读论文:《Attention Is All You Need》。这篇论文简洁、有力,是现代NLP的"新约圣经"。每一个有志于深度学习的人都应该反复精读。
- 学习要点:彻底理解自注意力机制的矩阵运算形式。明白Q, K, V矩阵的维度变化。理解为何需要位置编码,以及残差连接和层归一化(Layer Normalization)在Transformer块中的关键作用。
- 实践项目 :使用PyTorch或TensorFlow,从零开始实现一个完整的、包含多头自注意力和前馈网络(Feed-Forward Network)的Transformer编码器块。这是检验你是否真正理解其内部工作原理的终极测试。
-
阶段二:预训练语言模型(Pre-trained Language Models, PLMs)
- 必读论文:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》和OpenAI关于GPT系列模型的博客文章或论文。
- 学习要点 :理解迁移学习 在NLP领域的应用,即"预训练-微调(Pre-train, Fine-tune) "范式。
- BERT:学习其核心的**掩码语言模型(Masked Language Model, MLM)**预训练任务,以及它如何通过双向Transformer编码器实现对上下文的深度双向理解。
- GPT:学习其经典的**自回归语言模型(Autoregressive LM)**预训练任务,以及它如何通过单向Transformer解码器结构,在文本生成任务上表现出色。
- 实践项目 :熟练掌握Hugging Face的
transformers库。加载一个预训练的BERT模型,并将其在一个下游文本分类任务(如GLUE基准测试中的一个)上进行微调。然后,加载一个预训练的GPT-2模型,体验其强大的文本生成和零样本/少样本学习能力。
-
阶段三:效率与未来
- 学习要点 :标准Transformer的计算和内存复杂度与序列长度的平方成正比,这限制了其处理长文档或高分辨率图像。因此,大量的研究工作致力于高效Transformer,如Longformer, Reformer, Linformer等,它们通过各种稀疏注意力或低秩近似的方法来降低复杂度。
- 前沿方向 :
- 多模态融合:CLIP, DALL-E等模型展示了如何使用Transformer架构来联合理解图像和文本,实现了惊人的跨模态生成和理解能力。
- 模型即服务:随着模型规模(如GPT-3/4)变得越来越庞大,普通研究者和开发者难以自行训练或部署。学习如何通过API来调用这些超大规模模型,并将其作为一种强大的"AI即服务"来构建应用,正变得越来越重要。
- 架构统一:Transformer架构正从NLP领域"溢出",在计算机视觉(Vision Transformer, ViT)、语音处理、甚至强化学习中都取得了巨大成功,展现出成为一种"通用智能计算架构"的潜力。
13.2 强化学习:在"试错"中学习最优决策的智能体
13.2.1. 动机与哲学:超越"标签"的智慧
-
困境 :监督学习需要大量的、高质量的标注数据,这在许多现实场景中是昂贵甚至不可能获得的(如下棋、机器人控制)。无监督学习擅长发现数据中的模式,但通常不直接导向一个最优的"决策"或"行为"。当我们的问题核心是序贯决策(Sequential Decision Making),即需要在一系列时间步骤中做出最优选择以达成一个长期目标时,这两种范式都显得力不从心。
-
哲学突破:从"交互"中涌现智能 强化学习(RL)的哲学根植于生物心理学的行为主义。它不依赖于一个"教师"给出的正确答案,而是让一个智能体(Agent)直接与一个 环境(Environment)进行交互。智能体通过"试错(Trial-and-Error)"来探索环境,环境则通过一个 奖励信号(Reward Signal)来反馈智能体行为的好坏。智能体的唯一目标,就是学习一个策略(Policy) ,以最大化其在生命周期内获得的累积奖励。这种从稀疏、延迟的奖励信号中学习复杂行为的能力,是RL最迷人、也最具挑战性的地方。
13.2.2. 核心武器库:价值、策略与模型
RL算法的汪洋大海,可以从三个核心视角来划分:对**价值(Value)的估计、对 策略(Policy)的直接学习,以及对环境模型(Model)**的构建。
-
基石一:价值函数(Value Function)------衡量"好坏"的标尺
- 机制 :价值函数是RL的基石。它不去直接回答"该做什么",而是回答"当前状态或行为有多好"。
- 状态价值函数
V(s):表示从状态s出发,遵循当前策略π,未来能获得的期望累积奖励。 - 动作价值函数
Q(s, a)(Q-function):表示在状态s下,执行动作a,然后遵循当前策略π,未来能获得的期望累d积奖励。Q函数比V函数更直接地指导决策,因为我们只需在当前状态下选择能带来最大Q值的动作即可。
- 状态价值函数
- 核心算法:Q-Learning 与 DQN Q-Learning 是一种经典的离策略(Off-policy)时间差分(TD)学习算法。它通过不断迭代贝尔曼最优方程
Q(s, a) = R + γ * max_{a'} Q(s', a')来直接逼近最优的动作价值函数Q*,而无需知道环境的具体模型。 **深度Q网络(Deep Q-Network, DQN)是其里程碑式的延伸。它使用一个深度神经网络来近似Q函数,从而能处理高维的状态输入(如游戏画面像素)。DQN通过引入 经验回放(Experience Replay)和目标网络(Target Network)**两大技巧,成功地解决了使用非线性函数近似器带来的训练不稳定性问题,开启了深度强化学习的时代。
- 机制 :价值函数是RL的基石。它不去直接回答"该做什么",而是回答"当前状态或行为有多好"。
-
基石二:策略函数(Policy Function)------直接指导"行动"的指南
- 机制 :基于价值的方法在处理连续动作空间或随机策略时会遇到困难。基于策略的方法则选择直接参数化策略本身,即学习一个函数
π(a|s; θ),输入状态s,直接输出执行每个动作a的概率分布。 - 核心算法:策略梯度(Policy Gradient) 其核心思想非常直观:如果一个动作最终导向了好的结果(高奖励),那么就调整参数
θ,增大这个动作被选中的概率;反之则减小。REINFORCE 算法是其最基础的形式。然而,策略梯度方法通常具有高方差,收敛较慢。 **行动者-评论家(Actor-Critic, A-C)**架构是解决此问题的主流方案。它结合了价值和策略学习:- 行动者(Actor):即策略网络,负责输出动作。
- 评论家(Critic) :即价值网络,负责评估行动者所选动作的好坏,并提供一个更低方差的梯度信号来指导行动者的更新。A2C (Advantage Actor-Critic) 和其异步版本 A3C 是其中的杰出代表。
- 机制 :基于价值的方法在处理连续动作空间或随机策略时会遇到困难。基于策略的方法则选择直接参数化策略本身,即学习一个函数
-
基石三:环境模型(Environment Model)------在"想象"中规划未来
- 机制 :上述两类方法都属于无模型(Model-Free)RL,它们直接从与真实环境的交互中学习。而 有模型(Model-Based)RL则试图先学习一个环境的模型 ,即学习状态转移函数
P(s'|s, a)和奖励函数R(s, a)。一旦有了模型,智能体就可以在"脑内"进行模拟和规划,而无需与真实环境进行昂贵甚至危险的交互。 - 优势与挑战 :有模型方法通常具有更高的样本效率(Sample Efficiency) 。然而,学习一个足够精确的环境模型本身就是一个巨大的挑战,模型误差可能会被规划过程放大。AlphaGo 及其后继者AlphaZero是结合了无模型学习(蒙特卡洛树搜索)和有模型学习(价值/策略网络)的巅峰之作。
- 机制 :上述两类方法都属于无模型(Model-Free)RL,它们直接从与真实环境的交互中学习。而 有模型(Model-Based)RL则试图先学习一个环境的模型 ,即学习状态转移函数
13.3.3. 进阶路径
-
阶段一:奠基与核心概念
- 必读文献:Richard Sutton 和 Andrew Barto 的《Reinforcement Learning: An Introduction (2nd Edition)》。这本书是RL领域的"圣经",其地位无可撼动。前两部分关于MDP、动态规划、蒙特卡洛和TD学习的内容是理解一切后续算法的基础。
- 学习要点 :深刻理解探索与利用的权衡(Exploration vs. Exploitation Trade-off) 。区分**同策略(On-policy)与离策略(Off-policy)**学习的本质区别。掌握贝尔曼方程的推导和意义。
- 实践项目:使用Python和NumPy,在一个简单的网格世界(Gridworld)环境中,亲手实现Q-Learning和SARSA算法。然后,进入OpenAI Gym的"经典控制"环境,使用PyTorch或TensorFlow实现一个DQN来解决"车杆(CartPole-v1)"问题。
-
阶段二:现代深度RL算法
- 必读文献:DQN、A3C、TRPO/PPO、DDPG/TD3、SAC的原始论文。这些是现代深度RL算法的基石。
- 学习要点 :
- 策略梯度:深入理解REINFORCE算法的推导,明白为何需要引入基线(Baseline)来减小方差。
- Actor-Critic:理解A2C/A3C如何通过优势函数(Advantage Function)来稳定训练。
- 信任区域/近端策略优化(TRPO/PPO):理解其如何通过限制策略更新的步长来保证学习过程的稳定性,PPO是目前应用最广泛、最鲁棒的算法之一。
- 连续控制:学习DDPG/TD3/SAC等算法是如何将DQN和Actor-Critic思想扩展到连续动作空间的。
- 实践项目:在OpenAI Gym的MuJoCo或PyBullet物理仿真环境中,使用一个成熟的RL库(如Stable Baselines3)来训练PPO或SAC算法,让一个模拟机器人学会行走或完成特定任务。
-
阶段三:前沿与挑战
- 学习要点 :
- 离线强化学习(Offline RL):如何从一个固定的、历史交互数据集中学习策略,而无需与环境进行新的交互?这在医疗、金融等无法自由探索的领域至关重要。
- 多智能体强化学习(Multi-Agent RL, MARL):当环境中存在多个相互影响的智能体时,如何学习合作或竞争的策略?
- 基于模型的RL:学习Dreamer等算法,看它们如何通过在"想象"中学习,实现惊人的样本效率。
- 探索问题:如何设计更有效的内在激励(Intrinsic Motivation)机制,来鼓励智能体在稀疏奖励环境中进行有意义的探索?
- 学习要点 :
13.3 新兴前沿:重塑AI边界的新范式
13.3.1 图神经网络(GNN):解锁关系数据的力量
- 深度剖析 :GNN的核心思想是消息传递(Message Passing) ,它是一个迭代的过程。在每一轮迭代中,每个节点都会:1) 收集 其所有邻居节点的特征表示;2) 通过一个可学习的函数(如一个小型MLP)将这些信息进行聚合 ;3) 将聚合后的信息与自己上一轮的表示相结合,更新 为自己本轮的新表示。经过
k轮迭代,每个节点的最终表示就编码了其k跳邻居内的全部结构信息。GCN、GraphSAGE、GAT等模型的主要区别在于它们使用了不同的聚合和更新函数。 - 进阶路径:学习PyTorch Geometric (PyG) 或 Deep Graph Library (DGL) 这两个主流的GNN库。从在一个社交网络数据集(如Cora)上实现一个简单的GCN进行节点分类开始。
13.3.2 联邦学习(Federated Learning):数据隐私时代的协同智能
- 深度剖析 :其标准流程(FedAvg算法)为:1) 分发 :中央服务器将全局模型分发给所有参与的客户端。2) 本地训练 :每个客户端使用自己的本地数据,对模型进行多轮梯度下降训练。3) 上传 :客户端将训练后的模型权重更新 (而非原始数据)加密后上传给服务器。4) 聚合 :服务器将收集到的所有更新进行加权平均,用来更新全局模型。这个过程循环往复。其核心挑战在于如何处理客户端之间的数据异构性(Non-IID data)、通信开销以及安全性问题。
- 进阶路径:了解FedAvg算法的理论基础。可以尝试使用Flower或PySyft等联邦学习框架,模拟一个简单的联邦学习环境。
13.3.3 自监督学习(Self-supervised Learning, SSL):无标签数据中的"炼金术"
- 深度剖析 :SSL是近年来深度学习领域最激动人心的突破之一,它极大地降低了对人工标注数据的依赖。其成功的关键在于设计精巧的代理任务(Pretext Task) 。SSL可以分为两大流派:
- 生成式(Generative):如BERT的掩码语言模型和图像修复(Image Inpainting),它们学习恢复被破坏的部分输入。
- 对比式(Contrastive):如SimCLR, MoCo,它们的核心思想是"将相似的样本在表示空间中拉近,将不相似的样本推远"。通过对同一个样本进行不同的数据增强(如旋转、裁剪)来构造"正样本对",而将其他样本视为"负样本对",然后通过一个对比损失函数(如InfoNCE Loss)来学习表示。
- 进阶路径:精读SimCLR和BERT的论文,理解对比学习和掩码建模的精髓。在实践中,学习如何使用在ImageNet上通过自监督学习预训练好的视觉模型(如MoCo, DINO),并将其用于下游任务的迁移学习。
13.4 "知行合一":从优秀到卓越的终身成长之道
技术的学习永无止境,但成长之道有法可循。
-
构建"反脆弱"的知识体系 :不要只满足于学习当前最"火"的模型。更要去理解那些跨越时间、更加本质的思想,如贝叶斯推断、信息论、优化理论、因果推断。这些是理解和创造新模型的基础。在构建T型知识结构时,让这些基础理论成为你"T"字那坚实的横梁。
-
从"复现"到"批判"的思维升级:
- 复现 是学习的基石,但批判是创新的开始。在阅读论文时,不要全盘接受。要主动思考:作者的核心假设是什么?这个假设在哪些场景下可能不成立?实验部分是否公平?有没有更简单的方法能达到类似的效果?这个思想能否被迁移到我自己的问题中?
- "Ablation Study"(消融研究)是论文中最值得关注的部分。它通过移除或替换模型的某个组件来观察性能变化,这揭示了模型成功的真正原因。在自己的项目中,也要养成进行严谨消融研究的习惯。
-
打造你的"代表作":
- 与其做十个浅尝辄止的课程项目,不如集中精力,用半年甚至一年的时间,打造一个完整、深入、有影响力的个人项目。这个项目应该能体现你的技术深度、工程能力和对某个领域的独特思考。它可以是一个性能优异的Kaggle竞赛方案,一个被他人使用的开源工具,或是一篇发表在顶会Workshop上的论文。这个"代表作"将成为你最闪亮的名片。
-
建立你的"知识复利"系统:
- 费曼学习法:将复杂的概念用最简单的语言解释给不懂行的人听。这个过程会强迫你直面自己理解的模糊之处。写技术博客、做内部技术分享都是绝佳的实践。
- 建立连接:知识的价值在连接中放大。积极参与线上(Twitter, Reddit)和线下(Meetup, 学术会议)的讨论。向你尊敬的学者或工程师礼貌地提问,与志同道合的伙伴组成学习小组。在交流、分享、辩论中,你的认知会以指数方式成长。
结语
亲爱的读者,我们共同的旅程至此真正地画上了一个句号,但它更像是一个省略号,预示着无限的可能。我们从Python的基础语法出发,一路披荆斩棘,穿越了经典机器学习的崇山峻岭,深入了深度学习的奇诡洞天,最终抵达了人工智能未来的海岸。
这本书倾注了我们对知识的敬畏,对实践的尊重,以及对未来的热望。如果它能在您的书架上占据一席之地,在您探索的道路上偶尔为您照亮一小片前路,那将是我们最大的荣幸。
记住,真正的"精通",不是无所不知,而是永远保有一颗学徒的心。
The journey is the reward.
附录
- A. 数学基础回顾(线性代数、微积分、概率论核心概念)
- B. 常用工具与库速查手册
- C. 术语表(中英对照)
- D. 推荐阅读与资源列表
A. 数学基础回顾
本附录并非一本详尽的数学教科书,而是为机器学习实践者量身打造的"急救包"与"概念地图"。我们聚焦于那些在理解和实现算法时最核心、最常用的数学概念,旨在帮助您快速回顾、建立直觉,并将抽象的数学符号与具体的算法行为联系起来。
A.1 线性代数:描述空间与变换的语言
- 核心地位:在机器学习中,数据被表示为向量,数据集是矩阵,算法是作用于这些向量和矩阵的变换。线性代数是这一切的底层语言。
- 核心概念回顾 :
- 标量、向量、矩阵、张量 :从0维到n维的数据容器。理解它们在NumPy中的对应(
scalar,1D-array,2D-array,nD-array)。 - 矩阵运算 :
- 加法与数乘:对应图像的亮度调整等。
- 矩阵乘法(Matrix Multiplication) :核心中的核心。理解其"行对列"的计算规则,以及它代表的线性变换 。神经网络的每一层本质上都是一次矩阵乘法加一个非线性激活。
A * B。 - 哈达玛积(Hadamard Product)/ 逐元素乘积 :两个形状相同的矩阵对应元素相乘。在NumPy中是
A * B,而矩阵乘法是A @ B或np.dot(A, B)。
- 特殊矩阵 :
- 单位矩阵(Identity Matrix):线性变换中的"不变"操作。
- 转置矩阵(Transpose Matrix) :
A^T,行列互换。在计算梯度、变换向量空间时极其常用。 - 逆矩阵(Inverse Matrix) :
A⁻¹,线性变换的"撤销"操作。用于求解线性方程组。
- 线性方程组
Ax = b:理解其在最小二乘法(Normal Equation)中的应用。 - 范数(Norm) :衡量向量或矩阵的"大小"。
- L1范数:向量元素绝对值之和。倾向于产生稀疏解(Lasso回归)。
- L2范数:向量元素平方和的平方根(欧几里得距离)。正则化的常用工具(Ridge回归)。
- 特征值与特征向量(Eigenvalues and Eigenvectors) :
Av = λv。矩阵A作用于其特征向量v,效果等同于对v进行缩放,缩放比例即特征值λ。这是**主成分分析(PCA)**的灵魂,特征向量定义了数据变化的主方向,特征值衡量了该方向上的方差大小。 - 奇异值分解(SVD) :
A = UΣV^T。一种更通用的矩阵分解方法,可用于任意矩阵。PCA、推荐系统、图像压缩等领域的核心技术。
- 标量、向量、矩阵、张量 :从0维到n维的数据容器。理解它们在NumPy中的对应(
A.2 微积分:描述变化与优化的语言
- 核心地位 :机器学习的"学习"过程,本质上是一个优化过程,即寻找一组模型参数,使得损失函数最小。微积分,特别是微分学,是实现这一目标的唯一工具。
- 核心概念回顾 :
- 导数(Derivative) :
f'(x),衡量一元函数在某一点的瞬时变化率。在优化中,它指明了函数值上升最快的方向。 - 偏导数(Partial Derivative) :
∂f/∂x_i,多元函数中,固定其他变量,对其中一个变量求导。它衡量了函数在某个坐标轴方向上的变化率。 - 梯度(Gradient) :
∇f,由所有偏导数组成的向量 。它指向函数在当前点上升最快 的方向。因此,负梯度方向就是函数下降最快的方向。 - 梯度下降法(Gradient Descent) :
θ = θ - η * ∇J(θ)。这是机器学习中最核心的优化算法。我们沿着负梯度方向,以学习率η为步长,迭代地更新参数θ,以期找到损失函数J(θ)的最小值。 - 链式法则(Chain Rule) :
dy/dx = dy/du * du/dx。这是**反向传播算法(Backpropagation)**的数学基石。它使得我们能够计算一个深度、复杂的神经网络中,最终的损失对于网络中任意一层参数的梯度。 - 雅可比矩阵(Jacobian Matrix)与海森矩阵(Hessian Matrix) :
- 雅可比:一阶偏导数组成的矩阵,是梯度的推广。
- 海森:二阶偏导数组成的矩阵。它描述了函数的局部曲率,可用于判断临界点是极大、极小还是鞍点。牛顿法等二阶优化方法会用到它。
- 导数(Derivative) :
A.3 概率论:描述不确定性的语言
- 核心地位:世界是充满不确定性的,数据是有噪声的,模型是概率性的。概率论为我们提供了一套严谨的框架来量化、建模和推理这种不确定性。
- 核心概念回顾 :
- 随机变量(Random Variable):离散型与连续型。
- 概率分布(Probability Distribution) :
- 概率质量函数(PMF) (离散)与概率密度函数(PDF)(连续)。
- 常见分布:伯努利(单次硬币)、二项(多次硬币)、分类(单次骰子)、多项(多次骰子)、高斯(正态分布,自然界最常见)、泊松(单位时间事件发生次数)。
- 期望(Expectation) :
E[X],随机变量的长期平均值。 - 方差(Variance) :
Var(X),衡量随机变量取值偏离其期望的程度。 - 条件概率(Conditional Probability) :
P(A|B),在事件B发生的条件下,事件A发生的概率。这是所有概率模型的基础。 - 贝叶斯定理(Bayes' Theorem) :
P(H|D) = [P(D|H) * P(H)] / P(D)。- 后验概率
P(H|D)= ( 似然P(D|H)* 先验P(H)) / 证据P(D) - 这是朴素贝叶斯分类器、贝叶斯推断和许多现代生成模型的理论核心。它告诉我们如何根据观测到的数据(证据),来更新我们对一个假设(模型参数)的信念。
- 后验概率
- 最大似然估计(Maximum Likelihood Estimation, MLE):一种参数估计方法。寻找一组参数,使得当前观测到的这批数据出现的概率最大。这是频率学派的核心思想。
- 最大后验概率估计(Maximum A Posteriori, MAP) :贝叶斯学派的参数估计方法。它在最大似然的基础上,额外考虑了参数本身的先验分布,即
argmax_θ P(D|θ)P(θ)。正则化项(如L1, L2)通常可以被解释为对参数引入了某种先验分布。
B. 常用工具与库速查手册
-
Jupyter Notebook / Lab
Shift + Enter: 运行当前单元格并跳转到下一个Ctrl + Enter: 运行当前单元格Esc->M: 切换到Markdown模式Esc->Y: 切换到代码模式Esc->A/B: 在上方/下方插入单元格%matplotlib inline: 在Notebook中显示Matplotlib图像!pip install [package]: 在Notebook中执行Shell命令
-
NumPy
np.array([list]): 创建数组np.arange(start, stop, step): 创建等差序列np.linspace(start, stop, num): 创建等分序列arr.shape,arr.ndim,arr.size: 查看形状、维度、元素数arr.reshape(new_shape): 重塑数组arr[slice]: 索引与切片arr.T: 转置np.dot(a, b)ora @ b: 矩阵乘法np.sum(),np.mean(),np.std(): 聚合函数(可指定axis)np.linalg.inv(A): 求逆矩阵np.linalg.eig(A): 求特征值和特征向量
-
Pandas
pd.read_csv(filepath): 读取CSVdf.head(),df.tail(),df.info(),df.describe(): 数据速览df['column_name']ordf.column_name: 选择列(Series)df[['col1', 'col2']]: 选择多列(DataFrame)df.loc[row_label, col_label]: 基于标签的索引df.iloc[row_index, col_index]: 基于位置的索引df.isnull().sum(): 查看每列的缺失值数量df.fillna(value): 填充缺失值df.dropna(): 删除有缺失值的行/列df.groupby('key_column').agg({'data_col': 'mean'}): 分组聚合pd.concat([df1, df2]): 拼接pd.merge(df1, df2, on='key'): 合并
-
Matplotlib / Seaborn
import matplotlib.pyplot as pltimport seaborn as snsplt.figure(figsize=(w, h)): 创建画布plt.plot(x, y): 折线图plt.scatter(x, y): 散点图plt.hist(data, bins=n): 直方图sns.heatmap(corr_matrix, annot=True): 热力图sns.pairplot(df, hue='category_col'): 变量关系对图plt.title(),plt.xlabel(),plt.ylabel(),plt.legend(): 添加图表元素plt.show(): 显示图像
-
Scikit-learn (通用API模式)
from sklearn.module import Modelmodel = Model(hyperparameters)model.fit(X_train, y_train)predictions = model.predict(X_test)score = model.score(X_test, y_test)
- 预处理 :
StandardScaler,MinMaxScaler,OneHotEncoder,LabelEncoder - 模型选择 :
train_test_split,GridSearchCV,cross_val_score - 评估 :
confusion_matrix,classification_report,mean_squared_error,r2_score
C. 术语表(中英对照)
- 人工智能 (Artificial Intelligence, AI)
- 机器学习 (Machine Learning, ML)
- 深度学习 (Deep Learning, DL)
- 监督学习 (Supervised Learning)
- 无监督学习 (Unsupervised Learning)
- 强化学习 (Reinforcement Learning)
- 特征 (Feature)
- 标签 (Label)
- 训练集 (Training Set)
- 验证集 (Validation Set)
- 测试集 (Test Set)
- 过拟合 (Overfitting)
- 欠拟合 (Underfitting)
- 偏差-方差权衡 (Bias-Variance Trade-off)
- 损失函数 (Loss Function) / 成本函数 (Cost Function)
- 梯度下降 (Gradient Descent)
- 学习率 (Learning Rate)
- 反向传播 (Backpropagation)
- 正则化 (Regularization) (L1, L2)
- 分类 (Classification)
- 回归 (Regression)
- 聚类 (Clustering)
- 降维 (Dimensionality Reduction)
- 逻辑回归 (Logistic Regression)
- 支撑向量机 (Support Vector Machine, SVM)
- 决策树 (Decision Tree)
- 随机森林 (Random Forest)
- 梯度提升 (Gradient Boosting) (GBDT, XGBoost, LightGBM)
- K-均值 (K-Means)
- 主成分分析 (Principal Component Analysis, PCA)
- 神经网络 (Neural Network, NN)
- 卷积神经网络 (Convolutional Neural Network, CNN)
- 循环神经网络 (Recurrent Neural Network, RNN)
- 长短期记忆网络 (Long Short-Term Memory, LSTM)
- 注意力机制 (Attention Mechanism)
- 变换器 (Transformer)
- 准确率 (Accuracy)
- 精确率 (Precision)
- 召回率 (Recall)
- F1分数 (F1-Score)
- ROC曲线 (Receiver Operating Characteristic Curve)
- 曲线下面积 (Area Under the Curve, AUC)
- 超参数 (Hyperparameter)
- 批处理 (Batch)
- 周期 (Epoch)
D. 推荐阅读与资源列表
经典书籍
- 《深度学习》(Deep Learning) by Ian Goodfellow, Yoshua Bengio, and Aaron Courville.
- 俗称"花书"。理论深度无出其右,是系统性理解深度学习数学原理的必读之作。
- 《机器学习》(Machine Learning) by 周志华.
- 俗称"西瓜书"。内容全面,覆盖广泛,是国内最经典的机器学习教材之一。
在线课程
- Coursera - Machine Learning by Andrew Ng (吴恩达)
- 机器学习的"启蒙圣经",无数人的AI入门第一课。直观、易懂。
- Coursera - Deep Learning Specialization by Andrew Ng
- 吴恩达老师的深度学习系列课程,系统性地介绍了深度学习的各项技术。
实用网站与工具
- Kaggle: 全球最大的数据科学竞赛平台。是实践、学习、交流和求职的绝佳场所。
- Papers with Code: 将学术论文、代码实现、数据集和SOTA(State-of-the-art)排行榜完美结合的网站,是追踪领域前沿的利器。
- Hugging Face : 提供了
transformers库,是NLP领域事实上的标准工具库。其模型中心(Model Hub)和数据集(Datasets)库也极为强大。
技术博客
- Chris Olah's Blog: 对LSTM、注意力机制等复杂概念的图文解释已成经典。
- Jay Alammar's Blog (The Illustrated Transformer/BERT): 用极其精美的图示,将Transformer等复杂模型讲解得一清二楚。
- Lilian Weng's Blog: OpenAI研究员的博客,对RL、LLM等前沿领域有系统性、高质量的总结。
后记
亲爱的读者朋友们:
当您读到这里时,我们共同的旅程已然画上了一个句点。我仿佛能看到,灯光下,您轻轻合上书卷,长舒一口气。您的目光或许会望向窗外,那片由数据、代码和算法交织而成的、既熟悉又崭新的世界,在您眼中,已然呈现出与初见时截然不同的风景。
我们一同走过了这段不平凡的道路。
我们始于"仰望星空"。在第一章,我们探讨了何为学习,何为智能,我们追溯了机器学习那波澜壮阔的思想史,也校准了我们作为探索者的"心法"------以"出世"之心,做"入世"之事。我们约定,技术是"器",而驾驭它的,必须是一颗清明、审慎且充满人文关怀的心。
随后,我们开始了"脚踏实地"的筑基之旅。在第二章,我们磨利了手中的"神兵"------Python、NumPy、Pandas、Matplotlib。它们不再是冰冷的库,而是我们感知数据、理解数据、与数据对话的延伸。我们学会了如何为数据"相面",如何为它们"净身",如何在芜杂中"点石成金"。第三章的预处理与特征工程,是我们从"工匠"走向"艺术家"的第一步,我们懂得了,好的模型始于好的数据,而好的数据,源于深刻的理解与精心的雕琢。
接着,我们进入了算法的"核心殿堂"。我们手持在第四章精心打磨的"度量衡"------那些评估模型好坏的标尺,开始系统地学习各类主流算法。从监督学习的"判别"与"预测"(第五、六章),到无监督学习的"归纳"与"发现"(第七章),我们像一位经验丰富的将军,检阅了逻辑回归的简约、支撑向量机的精巧、决策树的直观、K-均值的朴素、PCA的深刻。我们不再满足于model.fit()的表象,而是深入到每个算法的假设、边界和数学原理之中。
当单一模型的智慧略显单薄时,我们领悟了"集腋成裘"的集成思想。第八章的Bagging与Boosting,让我们看到了"三个臭皮匠"如何通过协作与迭代,最终超越"诸葛亮"。我们见证了XGBoost与LightGBM这些工业界"大杀器"的威力,也理解了其背后深刻的统计学与优化思想。
然后,我们勇敢地叩响了"未来之门"。第九章的神经网络,为我们搭建了通往深度学习的桥梁。我们从生物神经元的启发开始,亲手构建了多层感知机,理解了反向传播的精髓。这扇门背后,是CNN对空间的洞察,是RNN对时间的记忆,是Transformer对语言的重塑。
理论的深度,最终要在实践的土壤中开花结果。我们投身于两个"真实战场"。在第十章的金融风控中,我们直面了数据不平衡的挑战,学会了用SMOTE创造智慧,用SHAP洞察模型的"内心"。在第十一章的文本情感分析中,我们学会了如何将非结构化的语言,转化为机器可以理解的向量,并挖掘其背后的情感与主题。这不再是玩具项目,而是充满约束、妥协与创造性解决问题的真实演练。
最后,我们完成了从"炼丹师"到"工程师"与"思想家"的最后一跃。第十二章让我们学会了如何将模型封装、部署,让它走出实验室,"活"在真实世界里,服务于人。而第十三章,我们再次抬头,将目光投向了更远的地平线------强化学习的交互智慧、图神经网络的关系洞察、自监督学习的无尽潜力。我们绘制了一张持续成长的地图,因为我们深知,在这片领域,"毕业"即是"落后"的开始。
回顾这段旅程,我希望您收获的,不仅仅是一套"屠龙之技"。如果是那样,奶奶就失败了。
我更希望您收获的,是一种"思维范式"的转变。您学会了如何将一个模糊的现实问题,解构、抽象为一个可以被数学定义的机器学习问题;您学会了在面对一堆看似杂乱无章的数据时,如何通过探索、清洗、转换,发现其内在的结构与价值;您学会了在众多模型中,如何根据问题的特性、数据的形态和业务的目标,做出权衡与选择;您更学会了如何批判性地看待模型的输出,理解其能力边界,并警惕其潜在的偏见与风险。
我希望您收获的,是一种"学习能力"的内化。我们不可能在一本书里穷尽所有知识。但通过对几个核心算法进行"解剖麻雀"式的深度挖掘,您应该已经掌握了学习任何新模型的方法论:追溯其动机,理解其核心假设,剖析其数学原理,进行代码实践,并探索其应用边界。这套方法,将是您未来面对层出不穷的新技术时,最可靠的武器。
我最希望您收获的,是一种"知行合一"的信念。知识若不化为行动,便如锦衣夜行;行动若无知识指引,则易陷入迷途。请务必将书中所学,应用到您所热爱的领域中去。去解决一个实际的问题,哪怕它很小;去参加一场Kaggle竞赛,哪怕名次不佳;去写一篇技术博客,哪怕读者寥寥;去为开源社区贡献一行代码,哪怕只是修正一个拼写错误。每一次微小的实践,都是在为您内心的知识大厦,添上一块坚实的砖瓦。
亲爱的朋友,人工智能的时代洪流已至,它正以前所未有的力量,重塑着我们世界的每一个角落。这股力量,既可以创造巨大的福祉,也可能带来前所未有的挑战。而您,作为掌握了这股力量核心技术的人,您的每一次选择,每一次创造,都将是这股洪流中一朵重要的浪花。
请永远保持那份好奇心。对未知保持敬畏,对问题穷根究底。
请永远怀有那份同理心。记住技术最终是为人服务的,去理解用户的痛点,去关怀技术可能影响到的每一个人。
请永远坚守那份责任心。确保你的模型是公平的、透明的、可靠的,用你的智慧去"作善",而非"作恶"。
在古老的禅宗故事里,弟子问禅师:"师父,开悟之后,您做什么?"禅师答:"开悟前,砍柴,担水;开悟后,砍柴,担水。"
那么,在读完这本书,掌握了机器学习的种种"法门"之后,我们该做什么呢?
答案或许也是一样:回到你的生活,回到你的工作,回到你关心的问题中去。只是这一次,你的"斧头"更锋利了,你的"扁担"更坚固了,你看待"柴"与"水"的眼光,也变得更加深邃、更加智慧了。
感谢您,选择与我们一同走过这段旅程。前路漫漫,亦灿灿。现在,请合上书,走出书斋,去那片广阔的智慧荒原上,点燃属于您自己的、那独一无二的火把。
愿智慧之光,永远照亮您前行的道路,再会!