🔥 本期专栏《Python爬虫实战》已收录,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~持续更新中!!

全文目录:
-
-
- 🌟开篇语
- [📌 上期回顾](#📌 上期回顾)
- [🎯 本节目标](#🎯 本节目标)
- [一、JSON 是什么?为什么它这么重要?](#一、JSON 是什么?为什么它这么重要?)
-
- [1.1 从 HTML 到 JSON 的演变](#1.1 从 HTML 到 JSON 的演变)
- [1.2 JSON 基础语法](#1.2 JSON 基础语法)
- [二、Python 解析 JSON 的方法](#二、Python 解析 JSON 的方法)
-
- [2.1 基本解析](#2.1 基本解析)
- [2.2 提取嵌套数据](#2.2 提取嵌套数据)
- [2.3 处理常见异常](#2.3 处理常见异常)
- [2.4 字段缺失的优雅处理](#2.4 字段缺失的优雅处理)
- 三、分页机制详解(核心重点)
-
- [3.1 为什么需要分页?](#3.1 为什么需要分页?)
- [3.2 三种常见分页模式](#3.2 三种常见分页模式)
- [3.3 分页模式对比](#3.3 分页模式对比)
- [四、用 Postman 测试接口(实战必备)](#四、用 Postman 测试接口(实战必备))
-
- [4.1 Postman 基础操作](#4.1 Postman 基础操作)
- [4.2 实战演练:分析真实接口](#4.2 实战演练:分析真实接口)
- 五、从浏览器找到数据接口(实用技巧)
-
- [5.1 识别接口的特征](#5.1 识别接口的特征)
- [5.2 实战案例:找到新浪新闻的接口](#5.2 实战案例:找到新浪新闻的接口)
- [5.3 接口参数逆向分析](#5.3 接口参数逆向分析)
- [六、JSON 数据的清洗与转换](#六、JSON 数据的清洗与转换)
-
- [6.1 时间格式处理](#6.1 时间格式处理)
- [6.2 数组字段处理](#6.2 数组字段处理)
- [6.3 布尔值和空')](#6.3 布尔值和空'))
- 七、本节小结
- [📝 课后作业(必做,验收进入下一节)](#📝 课后作业(必做,验收进入下一节))
-
- [任务1:Postman 接口测试](#任务1:Postman 接口测试)
- 任务2:分页采集脚本
- 任务3:真实网站接口分析
- [🔮 下期预告](#🔮 下期预告)
- 🌟文末
-
- [📌 专栏持续更新中|建议收藏 + 订阅](#📌 专栏持续更新中|建议收藏 + 订阅)
- [✅ 互动征集](#✅ 互动征集)
-
🌟开篇语
哈喽,各位小伙伴们你们好呀~我是【喵手】。
运营社区: C站 / 掘金 / 腾讯云 / 阿里云 / 华为云 / 51CTO
欢迎大家常来逛逛,一起学习,一起进步~🌟
我长期专注 Python 爬虫工程化实战 ,主理专栏 👉 《Python爬虫实战》:从采集策略 到反爬对抗 ,从数据清洗 到分布式调度 ,持续输出可复用的方法论与可落地案例。内容主打一个"能跑、能用、能扩展 ",让数据价值真正做到------抓得到、洗得净、用得上。
📌 专栏食用指南(建议收藏)
- ✅ 入门基础:环境搭建 / 请求与解析 / 数据落库
- ✅ 进阶提升:登录鉴权 / 动态渲染 / 反爬对抗
- ✅ 工程实战:异步并发 / 分布式调度 / 监控与容错
- ✅ 项目落地:数据治理 / 可视化分析 / 场景化应用
📣 专栏推广时间 :如果你想系统学爬虫,而不是碎片化东拼西凑,欢迎订阅/关注专栏《Python爬虫实战》
订阅后更新会优先推送,按目录学习更高效~
📌 上期回顾
在上一节《你要抓的到底是什么:HTML、CSS 选择器、XPath 入门?》中,我们学习了如何从 HTML 文档中精准定位和提取数据。你已经掌握了用 CSS 选择器和 XPath 解析网页结构的技能。
但实际工作中,你会发现:很多网站的数据不是直接写在 HTML 里,而是通过接口动态加载的 JSON 数据!
这一节,我们将学习现代网站最常见的数据传输格式------JSON,以及如何处理分页数据。掌握这个技能后,你的爬虫效率将提升 10 倍以上!
🎯 本节目标
通过本节学习,你将能够:
- 理解 JSON 数据格式的结构(对象、数组、嵌套)
- 掌握 Python 解析 JSON 的方法
- 识别三种常见的分页模式(page/offset/cursor)
- 使用 Postman 测试和分析接口
- 从 Network 面板找到数据接口
- 交付验收:用 Postman 请求一个 JSON 接口并解释字段含义
一、JSON 是什么?为什么它这么重要?
1.1 从 HTML 到 JSON 的演变
传统方式(服务器渲染):
json
用户请求 → 服务器生成完整HTML → 浏览器显示现代方式(前后端分离):
json
用户请求 → 服务器返回JSON数据 → JavaScript渲染页面对爬虫的影响:
- ✅ 好消息:JSON 结构清晰,比 HTML 解析更简单
- ⚠️ 挑战:需要找到正确的接口 URL 和参数
1.2 JSON 基础语法
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。
基本数据类型:
json
{
"string": "这是字符串",
"number": 12345,
"float": 3.14,
"boolean": true,
"null_value": null,
"array": [1, 2, 3, "混合类型"],
"object": {
"nested_key": "嵌套对象"
}
}实际案例:新闻接口返回的 JSON
json
{
"code": 0,
"message": "success",
"data": {
"total": 150,
"page": 1,
"page_size": 20,
"list": [
{
"id": 12345,
"title": "重大科技突展",
"author": "张三",
"publish_time": "2025-01-21 10:00:00",
"timestamp": 1705824000,
"category": "科技",
"url": "/news/12345",
"views": 12500,
"tags": ["量子计算", "科学"],
"is_hot": true
},
{
"id": 12346,
"title": "经济政策解读:2025年展望",
"author": "李四",
"publish_time": "2025-01-21 09:30:00",
"timestamp": 1705822200,
"category": "财经",
"url": "/news/12346",
"views": 8900,
"tags": ["经济", "政策"],
"is_hot": false
}
]
}
}结构解读:
python
# 顶层结构(通用格式)
{
"code": 0, # 状态码(0 通常表示成功)
"message": "...", # 提示信息
"data": { ... } # 实际数据载体
}
# 分页信息
"total": 150, # 总记录数
"page": 1, # 当前页码
"page_size": 20, # 每页条数
# 数据列表
"list": [ ... ] # 数组,包含多条记录
# 单条记录
{
"id": 12345, # 唯一标识(重要!)
"title": "...", # 标题
"timestamp": 1705824000, # Unix时间戳
"tags": ["tag1", "tag2"], # 数组类型字段
"is_hot": true # 布尔类型字段
}二、Python 解析 JSON 的方法
2.1 基本解析
python
import json
import requests
# 方法1:从字符串解析
json_str = '{"name": "张三", "age": 28}'
data = json.loads(json_str)
print(data['name']) # 输出:张三
# 方法2:从文件读取
with open('data.json', 'r', encoding='utf-8') as f:
data = json.load(f)
# 方法3:从 requests 响应直接解析(最常用)
response = requests.get('https://api.example.com/news')
data = response.json() # 自动解析 JSON2.2 提取嵌套数据
python
# 假设我们请求到了前面示例的 JSON 数据
response = requests.get('https://api.example.com/news?page=1')
json_data = response.json()
# 1. 检查请求是否成功
if json_data['code'] != 0:
print(f"请求失败: {json_data['message']}")
exit()
# 2. 获取分页信息
total = json_data['data']['total']
page = json_data['data']['page']
page_size = json_data['data']['page_size']
print(f"共 {total} 条数据,当前第 {page} 页,每页 {page_size} 条")
# 3. 遍历新闻列表
news_list = json_data['data']['list']
for news in news_list:
print(f"标题: {news['title']}")
print(f"作者: {news['author']}")
print(f"发布时间: {news['publish_time']}")
print(f"标签: {', '.join(news['tags'])}") # 数组转字符串
print(f"热门: {'是' if news['is_hot'] else '否'}")
print("-" * 50)2.3 处理常见异常
python
import json
def safe_parse_json(response):
"""安全解析 JSON,处理常见错误"""
try:
return response.json()
except json.JSONDecodeError as e:
print(f"JSON 解析失败: {e}")
print(f"响应内容前500字符: {response.text[:500]}")
return None
except Exception as e:
print(f"未知错误: {e}")
return None
# 使用示例
response = requests.get(url)
data = safe_parse_json(response)
if data is None:
# 处理解析失败的情况
pass2.4 字段缺失的优雅处理
python
# ❌ 不好的做法(可能报 KeyError)
title = news['title']
author = news['author']
# ✅ 方法1:使用 get() 方法(推荐)
title = news.get('title', '无标题')
author = news.get('author', '佚名')
# ✅ 方法2:使用 try-except
try:
title = news['title']
except KeyError:
title = '无标题'
# ✅ 方法3:提前检查
if 'title' in news:
title = news['title']
else:
title = '无标题'三、分页机制详解(核心重点)
3.1 为什么需要分页?
场景:某网站有 10000 条新闻,如果一次性返回:
- 响应数据太大(几十 MB)
- 加载时间长,用户体验差
- 服务器压力大
解决方案:分页返回,每次只返回 20-50 条
3.2 三种常见分页模式
模式1:基于页码(page-based)
这是最常见的分页方式。
python
# 接口 URL 示例
https://api.example.com/news?page=1&size=20
https://api.example.com/news?page=2&size=20
https://api.example.com/news?page=3&size=20
# 参数说明
# page: 页码(从 1 或 0 开始,看具体接口)
# size/limit/per_page: 每页条数采集代码:
python
import requests
import time
def fetch_all_pages(base_url, total_pages):
"""基于页码的全量采集"""
all_data = []
for page in range(1, total_pages + 1):
params = {
'page': page,
'size': 20
}
print(f"正在采集第 {page}/{total_pages} 页...")
response = requests.get(base_url, params=params, timeout=10)
data = response.json()
if data['code'] == 0:
news_list = data['data']['list']
all_data.extend(news_list)
print(f" 本页获取 {len(news_list)} 条数据")
else:
print(f" 请求失败: {data['message']}")
time.sleep(1) # 礼貌延迟
return all_data
# 使用示例
base_url = 'https://api.example.com/news'
# 先请求第一页获取总页数
first_page = requests.get(base_url, params={'page': 1, 'size': 20}).json()
total = first_page['data']['total']
page_size = first_page['data']['page_size']
total_pages = (total + page_size - 1) // page_size # 向上取整
all_news = fetch_all_pages(base_url, total_pages)
print(f"\n共采集 {len(all_news)} 条新闻")模式2:基于偏移量(offset-based)
类似数据库的 LIMIT/OFFSET 查询。
python
# 接口 URL 示例
https://api.example.com/news?offset=0&limit=20 # 第1页
https://api.example.com/news?offset=20&limit=20 # 第2页
https://api.example.com/news?offset=40&limit=20 # 第3页
# 参数说明
# offset: 跳过的记录数
# limit: 返回的记录数采集代码:
python
def fetch_by_offset(base_url, total):
"""基于偏移量的全量采集"""
all_data = []
limit = 20
offset = 0
while offset < total:
params = {
'offset': offset,
'limit': limit
}
print(f"正在采集 offset={offset}...")
response = requests.get(base_url, params=params, timeout=10)
data = response.json()
news_list = data['data']['list']
if not news_list: # 没有更多数据
break
all_data.extend(news_list)
offset += limit
time.sleep(1)
return all_data模式3:基于游标(cursor-based)
适用于实时数据流、社交媒体等场景。
python
# 接口 URL 示例
https://api.example.com/feed?cursor=initial
https://api.example.com/feed?cursor=abc123xyz # 下一页的游标
# 特点:
# - 第一次请求不需要 cursor(或使用特殊值如 "initial")
# - 响应中包含 next_cursor 字段
# - 用 next_cursor 请求下一页响应示例:
json
{
"code": 0,
"data": {
"list": [ ... ],
"next_cursor": "abc123xyz",
"has_more": true
}
}采集代码:
python
def fetch_by_cursor(base_url):
"""基于游标的采集"""
all_data = []
cursor = None # 或 "initial"
while True:
params = {'cursor': cursor} if cursor else {}
response = requests.get(base_url, params=params, timeout=10)
data = response.json()
news_list = data['data']['list']
all_data.extend(news_list)
# 检查是否还有更多数据
if not data['data'].get('has_more', False):
break
cursor = data['data'].get('next_cursor')
if not cursor:
break
print(f"已采集 {len(all_data)} 条,继续...")
time.sleep(1)
return all_data3.3 分页模式对比
| 特性 | 页码分页 | 偏移量分页 | 游标分页 |
|---|---|---|---|
| 实现难度 | 简单 | 简单 | 中等 |
| 跳页能力 | ✅ 支持 | ✅ 支持 | ❌ 不支持 |
| 性能 | 页码大时慢 | offset 大时慢 | ✅ 始终高效 |
| 实时数据 | ⚠️ 可能遗漏 | ⚠️ 可能遗漏 | ✅ 不遗漏 |
| 适用场景 | 普通列表 | 搜索结果 | 社交动态 |
四、用 Postman 测试接口(实战必备)
4.1 Postman 基础操作
步骤1:创建新请求
- 打开 Postman
- 点击 "New" → "HTTP Request"
- 输入 URL
步骤2:设置请求参数
json
URL: https://api.example.com/news
Method: GET
Query Params:
page: 1
size: 20步骤3:添加请求头(如果需要)
json
Headers:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Referer: https://example.com/
Cookie: session_id=abc123步骤4:发送请求并查看响应
点击 "Send",查看:
- Status: 200 OK(状态码)
- Body: JSON 格式响应数据
- Headers: 响应头信息
- Time: 响应时间
4.2 实战演练:分析真实接口
任务:测试 httpbin.org 的 JSON 接口
json
GET https://httpbin.org/get?page=1&category=tech观察要点:
- 状态码是否为 200
- 响应格式是否为 JSON
- 参数是否正确传递(在
args字段中)
Postman 实用功能:
javascript
// Tests 标签页(自动化测试)
pm.test("Status code is 200", function () {
pm.response.to.have.status(200);
});
pm.test("Response is JSON", function () {
pm.response.to.be.json;
});
// 提取字段到变量
var jsonData = pm.response.json();
pm.environment.set("next_cursor", jsonData.data.next_cursor);五、从浏览器找到数据接口(实用技巧)
5.1 识别接口的特征
在 Network 面板中,数据接口通常有以下特点:
类型特征:
- Type 列显示为 xhr 或 fetch
- Response 标签页显示 JSON 格式数据
**命名特、feed` 等关键词
- 例如:
/api/v1/news/list、/ajax/getArticles
参数特征:
- URL 中包含
page、offset、limit、cursor等分页参数 - 可能包含
category、keyword、date等筛选参数
5.2 实战案例:找到新浪新闻的接口
步骤:
- 访问 https://news.sina.com.cn/
- 打开 Network 面板,筛选 XHR
- 刷新页面或滚动加载
- 观察请求列表,找到包含新闻数据的请求
识别技巧:
python
# 在 Preview 标签页查看响应内容
# 如果看到类似这样的结构,就是数据接口:
{
"result": {
"status": {"code": 0},
"data": [
{
"title": "新闻标题",
"url": "https://...",
...
}
]
}
}5.3 接口参数逆向分析
常见参数类型:
python
# 1. 明文参数(最简单)
?page=1&size=20&category=tech
# 2. 时间戳参数(防缓存)
?page=1&_t=1705824000
# 3. 签名参数(需要算法)
?page=1&sign=abc123def456
# 4. 加密参数(最复杂)
?data=encrypted_string分析方法:
python
# 1. 对=1705824000
# 第二次:?page=2×tamp=1705824001
# 结论:timestamp 是当前时间戳
# 2. 删除可疑参数,测试是否必需
# 删除 sign 后请求失败 → sign 是必需的
# 3. 在浏览器源码中搜索参数名
# 按 Ctrl+Shift+F 全局搜索 "sign"
# 找到生成 sign 的 JavaScript 代码六、JSON 数据的清洗与转换
6.1 时间格式处理
python
from datetime import datetime
# 1. Unix 时间戳转日期
timestamp = 1705824000
dt = datetime.fromtimestamp(timestamp)
date_str = dt.strftime('%Y-%m-%d %H:%M:%S')
# 结果:"2025-01-21 10:00:00"
# 2. 日期字符串转时间戳
date_str = "2025-01-21 10:00:00"
dt = datetime.strptime(date_str, '%Y-%m-%d %H:%M:%S')
timestamp = int(dt.timestamp())
# 3. 处理多种日期格式
def parse_date(date_input):
"""智能解析日期"""
if isinstance(date_input, int):
# Unix 时间戳
return datetime.fromtimestamp(date_input)
elif isinstance(date_input, str):
# 尝试多种格式
formats = [
'%Y-%m-%d %H:%M:%S',
'%Y-%m-%d',
'%Y/%m/%d',
'%Y年%m月%d日'
]
for fmt in formats:
try:
return datetime.strptime(date_input, fmt)
except ValueError:
continue
return None6.2 数组字段处理
python
# 标签数组转字符串
tags = ["量子计算", "科学", "前沿技术"]
tag_str = ', '.join(tags)
# 结果:"量子计算, 科学, 前沿技术"
# 提取嵌套对象中的字段
comments = [
{"user": "张三", "content": "很有意思"},
{"user": "李四", "content": "学习了"}
]
usernames = [c['user'] for c in comments]
# 结果:['张三', '李四']6.3 布尔值和空')
python
clean_value = value if value else "暂无描述"
# 或使用 or 操作符
clean_value = news.get('description') or "暂无描述"
# 数值类型的空值
views = news.get('views', 0) # 默认为 0七、本节小结
本节我们系统学习了 JSON 数据处理的核心技能:
✅ JSON 结构 :理解对象、数组、嵌套的数据组织方式
✅ Python 解析 :使用 json.loads()、response.json() 提取数据
✅ 分页机制 :掌握页码、偏移量、游标三种分页模式
✅ Postman 测试 :独立测试接口,分析请求响应
✅ 接口发现 :从 Network 面板找到真实数据接口
✅ 数据清洗:处理时间、数组、空值等常见场景
核心原则:
- 优先寻找 JSON 接口,比解析 HTML 简单 10 倍
- 理解分页逻辑,避免遗漏或重复数据
- 用 Postman 先测试,确认接口可用再写代码
- 字段缺失要优雅处理,不要让程序崩溃
📝 课后作业(必做,验收进入下一节)
任务1:Postman 接口测试
测试以下公开接口,并截图保存结果:
json
GET [https://httpbin.org/get?page=2&size=10&category=tech](https://httpbin.org/get?page=2&size=10&category=tech)要求:
- 截图包含完整的请求 URL、参数、响应数据
- 解释响应 JSON 中的各个字段含义
- 尝试修改参数值,观察响应变化
任务1答案
1)Postman 怎么发请求(你照做并截图)
-
打开 Postman → New → HTTP Request
-
方法选 GET
-
URL 填:
https://httpbin.org/get?page=2&size=10&category=tech -
点 Send
-
截图要求:把下面三块都截进去
- 请求 URL(包含 query 参数)
- Params 面板(page/size/category)
- 响应 Body(JSON)
httpbin 的
/get会把你发过去的 query、headers、来源 IP 等"原样回显",非常适合练接口调试。 (彼得朱网站1)
2)响应 JSON 字段含义(你可以直接写进作业)
httpbin 的 /get 响应里常见字段:
- args :你在 URL 里带的查询参数(query string),例如
page/size/category会在这里出现 - headers :请求头回显(比如
User-Agent、Accept等) - origin:你的出口公网 IP(有时会显示代理链)
- url:服务器收到的完整 URL(含参数)
这些字段本质上是"服务器把你的请求内容回显给你看",用于检查请求是否按预期发送。 (彼得朱网站1)
3)修改参数,观察变化(给你3个建议,最好都试一遍)
你可以在 Postman 里改 Params,再 Send,对比两次响应:
- 把
page=2改成page=99→ 看 args.page 与 url 是否同步变化 - 把
category=tech改成category=sports→ 看 args.category - 把
size=10改成size=3→ 看 args.size
截图建议:两次请求的响应并排截图(或连续两张),并用红框标出 args/url 的变化点
任务2:分页采集脚本
创建 pagination_demo.py,实现基于页码的批量采集:
python
import requests
import time
import json
def fetch_multiple_pages(base_url, start_page, end_page):
"""
采集多页数据
Args:
base_url: 接口基础URL
start_page: 起始页码
end_page: 结束页码
Returns:
list: 所有采集到的数据
"""
all_data = []
for page in range(start_page, end_page + 1):
# TODO: 实现采集逻辑
pass
return all_data
# 测试用例
url = "https://httpbin.org/get"
result = fetch_multiple_pages(url, 1, 3)
print(f"共采集 {len(result)} 页数据")任务1答案
下面这份脚本满足:
-
按页码循环请求
-
把每页返回的 JSON 收集到 list
-
加了超时、异常处理、sleep 防止过快
-
支持把 page/size/category 作为参数传入
如下任务2代码仅供参考:
json
# pagination_demo.py
import requests
import time
import json
from typing import List, Dict, Any, Optional
def fetch_multiple_pages(
base_url: str,
start_page: int,
end_page: int,
size: int = 10,
category: str = "tech",
sleep_seconds: float = 0.5,
timeout: int = 15,
) -> List[Dict[str, Any]]:
"""
采集多页数据(基于页码 page)
Args:
base_url: 接口基础URL,例如 "https://httpbin.org/get"
start_page: 起始页码(含)
end_page: 结束页码(含)
size: 每页条数(示例参数)
category: 分类(示例参数)
sleep_seconds: 每次请求间隔,避免请求过快
timeout: 请求超时秒数
Returns:
list: 每一页的响应 JSON(dict)组成的列表
"""
all_data: List[Dict[str, Any]] = []
headers = {
"User-Agent": "Mozilla/5.0 (pagination-demo)"
}
for page in range(start_page, end_page + 1):
params = {
"page": page,
"size": size,
"category": category,
}
try:
resp = requests.get(base_url, params=params, headers=headers, timeout=timeout)
resp.raise_for_status()
data = resp.json()
# 你可以在这里做"抽取/清洗",此处先把整页 JSON 存起来
all_data.append(data)
print(f"[OK] page={page} url={resp.url}")
except requests.RequestException as e:
print(f"[ERR] page={page} error={e}")
time.sleep(sleep_seconds)
return all_data
if __name__ == "__main__":
url = "https://httpbin.org/get"
result = fetch_multiple_pages(url, 1, 3, size=10, category="tech")
print(f"\n共采集 {len(result)} 页数据\n")
# 运行截图建议:把下面这段输出截进去(证明你拿到了 args/url)
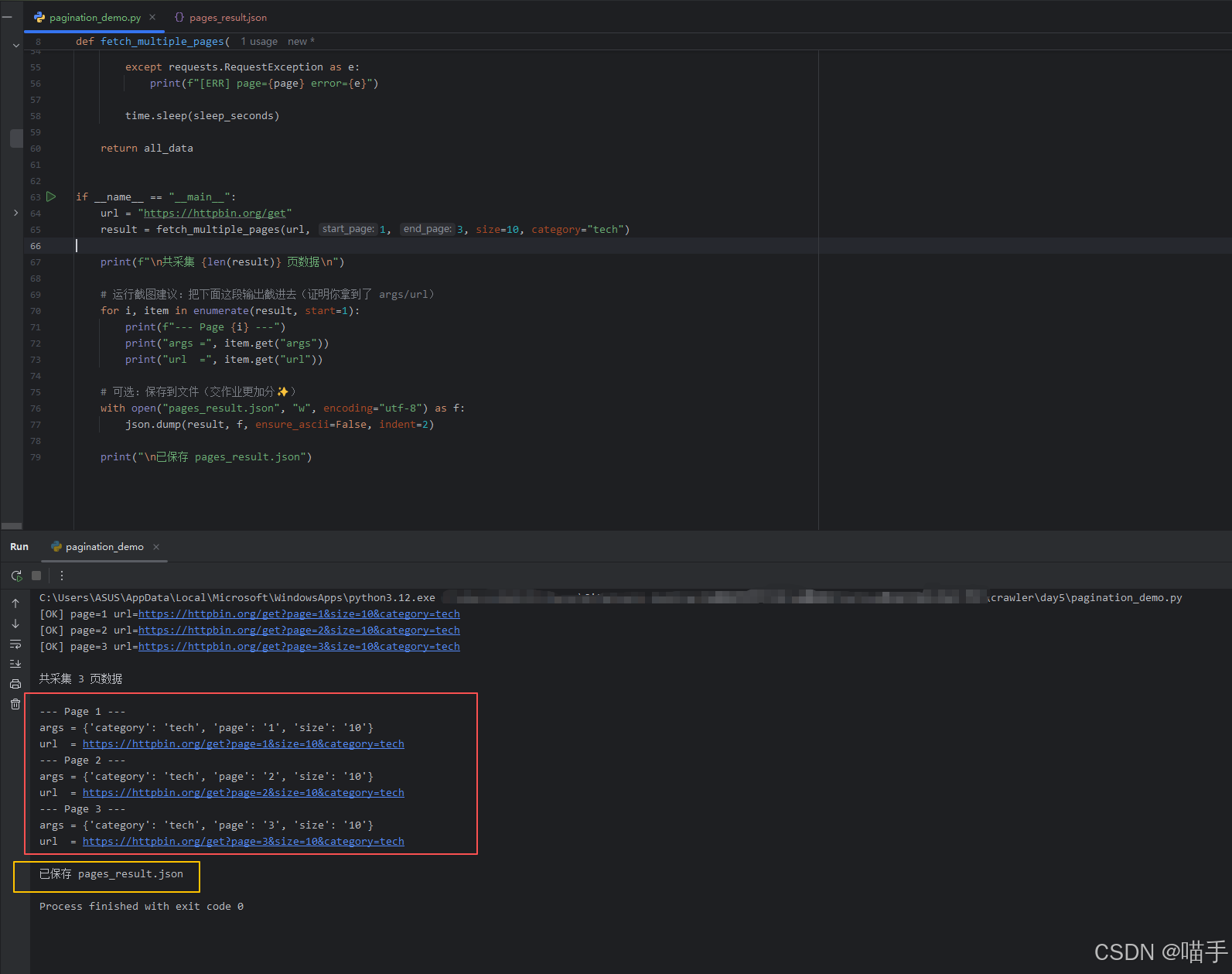
for i, item in enumerate(result, start=1):
print(f"--- Page {i} ---")
print("args =", item.get("args"))
print("url =", item.get("url"))
# 可选:保存到文件(交作业更加分✨)
with open("pages_result.json", "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print("\n已保存 pages_result.json")如下是实际运行结果展示:
任务3:真实网站接口分析
选择一个真实网站(推荐:知乎、微博、豆瓣),完成:
-
打开 Network 面板,找到数据接口
-
分析接口的:
- 完整 URL 和参数
- 分页方式(page/offset/cursor)
- 响应 JSON 的数据结构
-
用 Postman 复现请求
-
截图保存并标注关键信息
验收方式:在留言区提交:
- 任务1的 Postman 测试截图和字段解释
- 任务2的代码和运行结果截图
- 任务3的接口分析报告(含截图)
- 学习心得和遇到的问题
任务3答案
给大家一个"豆瓣电影列表接口"的示例(更容易成功、支持分页),很多豆瓣电影的列表数据来自一个 JSON 接口(XHR),常见形式类似:
https://movie.douban.com/j/search_subjects?...&page_start=0&page_limit=20
其中 page_start 相当于 offset,page_limit 相当于每页条数。
1)你在浏览器 Network 里怎么找(豆瓣示例)
-
打开一个豆瓣电影页面(比如"热门/榜单/分类"相关页面)
-
F12 → Network → 过滤 XHR / Fetch
-
滚动/切换分类/翻页
-
找到类似
j/search_subjects的请求 -
点开看:
- Headers:Request URL、Query String Parameters
- Preview/Response:JSON 数据结构
2)Postman 复现(豆瓣示例参数)
你可以在 Postman 用 GET 复现,并尝试翻页:
- 第 1 页:
page_start=0&page_limit=20 - 第 2 页:
page_start=20&page_limit=20 - 第 3 页:
page_start=40&page_limit=20
3)附:一个"豆瓣接口翻页采集"示例脚本(可选加分)
如果你任务3选豆瓣,这段脚本可以当作"复现请求"的代码补充(当然你仍需 Postman 截图)。
json
import requests
import time
def fetch_douban_pages(tag="热门", page_limit=20, pages=3, sleep_seconds=1.0):
base_url = "https://movie.douban.com/j/search_subjects"
headers = {
"User-Agent": "Mozilla/5.0 (douban-demo)",
"Referer": "https://movie.douban.com/"
}
all_items = []
for i in range(pages):
page_start = i * page_limit
params = {
"type": "movie",
"tag": tag,
"sort": "recommend",
"page_limit": page_limit,
"page_start": page_start
}
r = requests.get(base_url, params=params, headers=headers, timeout=15)
r.raise_for_status()
data = r.json()
subjects = data.get("subjects", [])
all_items.extend(subjects)
print(f"[OK] start={page_start} got={len(subjects)} url={r.url}")
time.sleep(sleep_seconds)
return all_items
if __name__ == "__main__":
items = fetch_douban_pages(tag="热门", page_limit=20, pages=3)
print("total items:", len(items))
if items:
print("sample item keys:", list(items[0].keys()))如下为实际运行结果展示:

✅ 注意:不同网站可能有反爬策略/频率限制,脚本里加 sleep、带 Referer/UA 是基本礼貌操作~
你作业重点是"会分析接口 + 会用 Postman 复现 + 看懂分页参数",不是追求采到海量数据
🔮 下期预告
下一节《新手最常栽的坑:编码、时区值、脏数据》,我们将学习:
- 字符编码问题(UTF-8、GBK、乱码)
- 时区转换和夏令时陷阱
- 空值、None、NaN 的区别和处理
- 脏数据识别与清洗策略
- 编写清洗函数工具包
预习建议 :
回顾你之前采集的数据,是否遇到过:
- 中文显示乱码?
- 时间不对或差了几个小时?
- 某些字段为空导致程序报错?
下节课我们会系统解决这些问题!😊
💬 JSON 是现代爬虫的核心!掌握好这一节,效率提升 10 倍! 🚀✨
记住:先找接口,再考虑解析 HTML。接口采集更稳定、更高效、更易维护。工程师要学会"偷懒"!
🌟文末
好啦~以上就是本期 《Python爬虫实战》的全部内容啦!如果你在实践过程中遇到任何疑问,欢迎在评论区留言交流,我看到都会尽量回复~咱们下期见!
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦~
三连就是对我写作道路上最好的鼓励与支持! ❤️🔥
📌 专栏持续更新中|建议收藏 + 订阅
专栏 👉 《Python爬虫实战》,我会按照"入门 → 进阶 → 工程化 → 项目落地"的路线持续更新,争取让每一篇都做到:
✅ 讲得清楚(原理)|✅ 跑得起来(代码)|✅ 用得上(场景)|✅ 扛得住(工程化)
📣 想系统提升的小伙伴:强烈建议先订阅专栏,再按目录顺序学习,效率会高很多~

✅ 互动征集
想让我把【某站点/某反爬/某验证码/某分布式方案】写成专栏实战?
评论区留言告诉我你的需求,我会优先安排更新 ✅
⭐️ 若喜欢我,就请关注我叭~(更新不迷路)
⭐️ 若对你有用,就请点赞支持一下叭~(给我一点点动力)
⭐️ 若有疑问,就请评论留言告诉我叭~(我会补坑 & 更新迭代)
免责声明:本文仅用于学习与技术研究,请在合法合规、遵守站点规则与 Robots 协议的前提下使用相关技术。严禁将技术用于任何非法用途或侵害他人权益的行为。