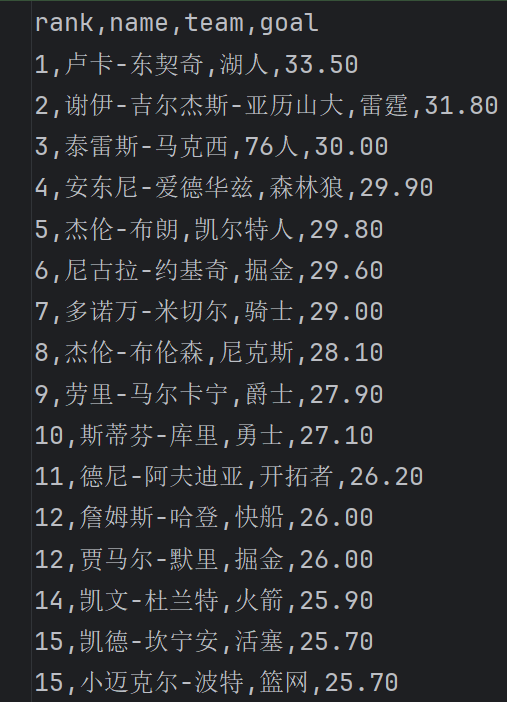
代码
python
NBA_URL = 'https://nba.hupu.com/stats/players/pts'
HEADERS = {'User-Agent': 'Mozilla/5.0'}
python
from global_parameters import NBA_URL, HEADERS
import requests
from lxml import etree
response = requests.get(NBA_URL, headers=HEADERS) # <Response [200]>
html_txt = response.text
html_element = etree.HTML(html_txt) # <Element html at 0x253a77aa540>
ranks = html_element.xpath('//table[@class="players_table"]//tr[position()>1]/td[1]/text()')
names = html_element.xpath('//table[@class="players_table"]//tr[position()>1]/td[2]/a/text()')
teams = html_element.xpath('//table[@class="players_table"]//tr[position()>1]/td[3]/a/text()')
goals = html_element.xpath('//table[@class="players_table"]//tr[position()>1]/td[4]/text()')
with open('nba_data.txt', 'w', encoding='utf-8') as f:
f.write('rank,name,team,goal\n')
for rank, name, team, goal in zip(ranks, names, teams, goals):
f.write(f'{rank},{name},{team},{goal}\n')效果