一、 总体研究思路
本研究遵循 "成分测定-差异分析-指标筛选-综合评价" 的逻辑链:
- 定量测定: 测定不同产地、批次、等级四季青中多种活性成分(及潜在有害成分)的含量。
- 差异分析: 利用PCA、OPLS-DA等无监督和有监督模型,分析不同等级样品间的整体差异,并筛选导致差异的关键标志物。
- 指标赋权: 利用因子分析(FA)降维和熵权法,客观确定各评价指标的权重。
- 等级预测: 构建熵权TOPSIS模型,对四季青样本进行综合评价与排序,实现等级的定量化预测。
二、 具体步骤与方法
第一步:样品收集与多指标定量测定
- 样品收集: 系统收集不同产地(道地与非道地)、不同商品等级(如一等、二等、统货等)或不同采收期的四季青样本。样本量需满足统计分析要求(通常N>30)。
- 指标选择: 选择与四季青药效(清热解毒、收敛止血)相关的化学成分作为指标。
- 主要活性成分: 如冬青素、原儿茶酸、鞣质、黄酮类(如槲皮素、山奈酚)等。
- 特征成分: 四季青的特征性成分。
- 安全指标(可选): 重金属、农残、霉菌毒素等。这将使评价体系更全面。
- 测定方法: 建立高效、准确的定量分析方法,如HPLC、UPLC-MS/MS等。确保方法学(精密度、准确度、稳定性)符合要求。
第二步:数据预处理与多元统计分析(PCA & OPLS-DA)
- 数据标准化: 由于各指标量纲不同,需进行标准化处理(如Z-score标准化)。
- 主成分分析(PCA):
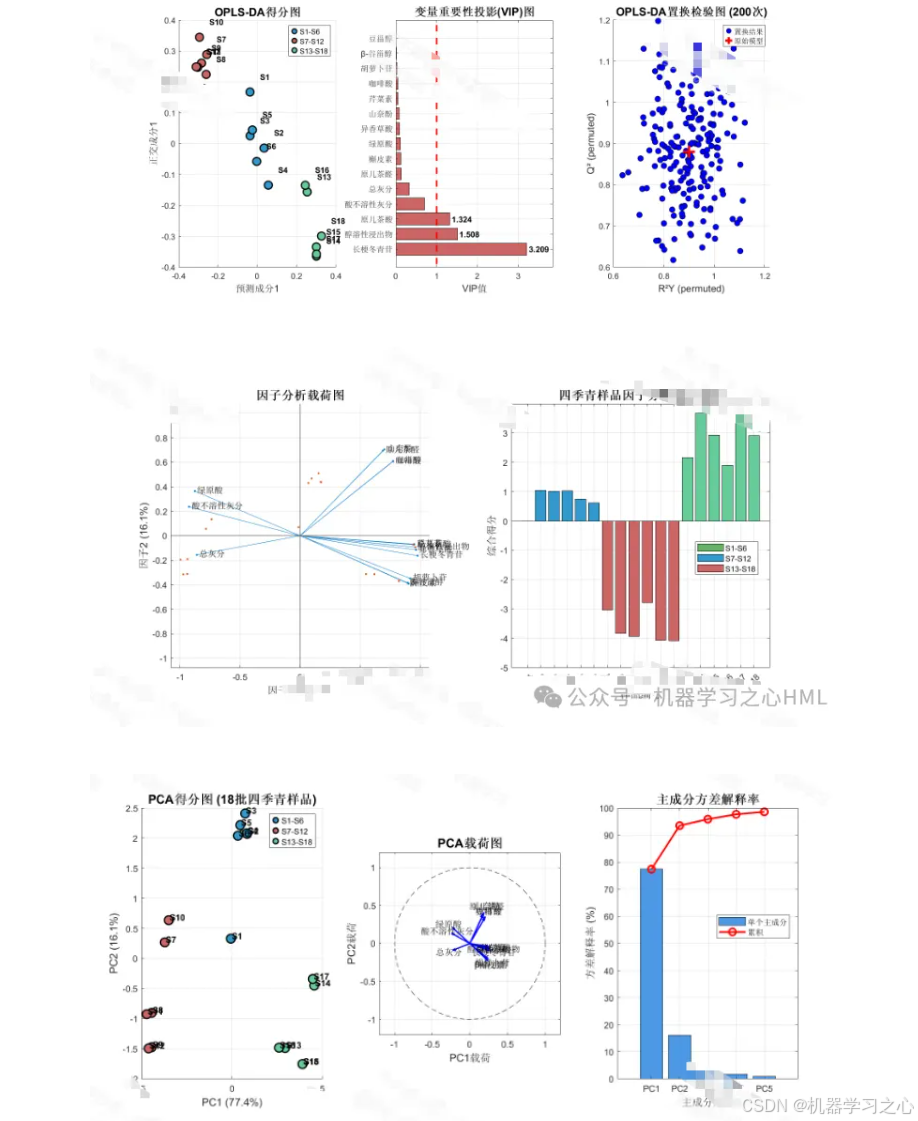
- 目的: 无监督地观察所有样本在整体上的自然聚集情况,初步判断不同等级样品是否存在分离趋势,检查异常值。
- 输出: 得分图(观察样本分布)、载荷图(观察指标贡献)。
- 正交偏最小二乘判别分析(OPLS-DA):
- 目的: 有监督地最大化组间差异(不同等级),并筛选导致等级差异的关键变量(标志物)。
- 操作: 以已知的样本等级作为Y变量,化学成分数据作为X变量。
- 关键产出:
- 模型验证: 必须使用置换检验来防止模型过拟合,确保模型可靠。
- 变量重要性投影(VIP值): VIP > 1.0 的变量通常被认为是区分等级的关键标志物。这些标志物将作为后续FA和TOPSIS的重要候选指标。
第三步:因子分析(FA)与熵权法结合确定权重
此步骤旨在解决指标间相关性并客观赋权。
- 因子分析(FA):
- 目的: 对原始指标进行降维,提取少数几个互不相关的公共因子(如"活性因子"、"安全因子"),用因子得分代替原始指标,消除多重共线性。
- 操作: 对标准化后的数据进行KMO和Bartlett球形检验,确认适合做FA。提取公因子,并进行方差最大化旋转。
- 结果: 获得各样本的因子得分。
- 熵权法确定权重:
- 目的: 基于数据的离散程度,客观地确定各指标(或各因子)的权重。信息熵越小,指标变异程度越大,提供信息越多,权重越大。
- 操作: 可以直接对原始指标 计算熵权,也可以对FA提取出的因子得分计算熵权。后者更优,因为它基于的是消除了相关性的综合因子。
- 输出: 每个评价维度(因子或原始指标)的客观权重
W_j。
第四步:构建熵权TOPSIS模型进行等级预测与验证
- 构建决策矩阵: 以样本为行,以FA因子(或筛选后的关键指标)为列,形成决策矩阵。
- 加权标准化: 将决策矩阵标准化后,乘以熵权法得到的权重,构成加权标准化矩阵。
- 确定正/负理想解: 找出每个指标(因子)上的最优值(正理想解
A+)和最劣值(负理想解A-)。 - 计算贴近度: 计算每个样本与正/负理想解的欧氏距离
D+和D-,进而计算相对贴近度C_i。C_i = \\frac{D_i^-}{D_i^+ + D_i\^-}
C_i值介于0到1之间,值越大,表示样本质量越优,等级越高。 - 等级预测与划分:
- 根据
C_i值对所有样本进行排序。 - 可以采用 K-means聚类 或 百分位数法 ,将
C_i值划分为几个区间,对应不同的质量等级(如优、良、中、差)。
- 根据
- 模型验证:
- 内部验证: 与已知的商品等级进行对比,计算预测准确率。
- 外部验证: 预留一部分未参与建模的样本作为测试集,验证模型的预测能力。
- 方法对比: 将熵权TOPSIS的结果与单一指标评价法、等权TOPSIS法的结果进行对比,展示本模型的优越性。
三、 预期结果与可视化
- PCA/OPLS-DA得分图: 展示等级分离趋势。
- OPLS-DA的VIP图: 条形图,清晰展示关键标志物。
- 因子载荷图: 展示原始指标与公因子的关系。
- TOPSIS贴近度排序图: 柱状图或雷达图,直观显示各样本的综合评价得分及等级归属。
- 模型验证混淆矩阵: 展示预测等级与实际等级的匹配情况。
四、 技术路线图(框架)
四季青样本收集 → 多指标成分定量测定 → 数据矩阵构建
↓
数据标准化与预处理
↓
┌───────────────┐
│ PCA (无监督探索) │
└───────────────┘
↓
┌───────────────┐
│ OPLS-DA (有监督判别) │
│ 1. 模型验证(置换检验) │
│ 2. 筛选VIP>1标志物 │
└───────────────┘
↓
┌─────────────────────────┐
│ 因子分析(FA) + 熵权法(EWM) │
│ 1. FA提取综合因子,消除共线性│
│ 2. EWM计算各因子客观权重 │
└─────────────────────────┘
↓
┌──────────────────┐
│ 构建熵权TOPSIS模型 │
│ 1. 计算贴近度Ci │
│ 2. 排序与等级划分 │
└──────────────────┘
↓
模型验证与等级预测 → 结果讨论与结论