一、I/O 功能的发展阶段与技术演进
I/O 功能的发展划分为 6 个阶段,本质是 逐步降低 CPU 对 I/O 的干预,让 I/O 子系统从 "CPU 附庸" 走向 "高度自治" 的过程,下面详细拆解每个阶段的技术细节、问题与突破。
技术演进的核心脉络
| 阶段 | 核心变化 | 关键收益 | 典型硬件 |
|---|---|---|---|
| 1 | CPU 直接控制 | 实现简单 | 早期打孔卡设备 |
| 2 | 引入控制器与 I/O 模块 | 硬件细节解耦 | 串口控制器 |
| 3 | 中断控制 | CPU 与 I/O 并行 | 中断控制器 |
| 4 | DMA 直接访存 | 减少 CPU 数据传输开销 | DMA 控制器 |
| 5 | I/O 通道处理器 | I/O 模块增加了单独的处理器, I/O 任务完全自治 | 大型机通道 |
| 6 | 智能 I/O 模块(局部存储 + 多核) | I/O 模块有自己的局部存储器,硬件卸载与零拷贝 | 智能网卡、NVMe SSD |
1.1. 阶段 1:处理器直接控制外围设备
- 核心逻辑:CPU 通过指令直接读写设备寄存器,全程轮询(Polling)设备状态。
- 技术特点 :
无专用 I/O 硬件,CPU 与设备串行执行。
设备就绪前,CPU 持续空等,利用率极低(通常 < 20%)。 - 典型场景:早期大型机、打孔卡 / 纸带输入机等低速设备。
- 核心问题:CPU 被 I/O 完全阻塞,系统整体吞吐量受限。
1.2. 阶段 2:增加了控制器和 I/O 模块
- 核心逻辑:引入设备控制器(如磁盘控制器、串口控制器)和独立 I/O 模块,负责设备与主机的信号转换、数据缓冲。
- 技术特点 :
控制器承担电气适配、数据格式转换等硬件细节,CPU 只需与 I/O 模块交互。
模块内置缓冲,可暂存少量数据,缓解 CPU与设备的速度差。 - 典型场景:早期小型机、PC 的串口 / 并口设备。
- 核心突破:CPU 无需直接处理设备底层硬件细节,但仍需主动轮询 I/O 模块状态。
1.3. 阶段 3:中断控制
-
核心逻辑:设备完成 I/O 后,通过中断信号主动通知 CPU,替代轮询机制。
-
技术特点:
CPU 发出 I/O 指令后可继续执行其他任务,设备就绪时触发中断,CPU 再处理数据。
中断控制器(如 PIC/APIC)管理多设备中断优先级,避免冲突。
-
典型场景:键盘、鼠标等低速交互设备,以及早期磁盘。
-
核心突破:首次实现 CPU 与 I/O 并行执行,CPU 利用率显著提升。
-
局限:频繁中断会导致上下文切换开销,高 I/O 负载下性能下降。
1.4. 阶段 4:I/O 模块通过 DMA 直接控制存储器
-
核心逻辑:引入 DMA(Direct Memory Access,直接存储器访问)控制器,让设备绕过 CPU 直接读写内存。
-
技术特点:
CPU 仅需向 DMA 控制器发送 "源地址、目标地址、传输长度 " 等参数,后续传输由 DMA 自动完成。
传输完成后,DMA 发送中断通知 CPU ,全程 CPU 仅参与初始化和收尾。
-
典型场景:磁盘、网卡等块设备 / 高速设备。
-
核心突破:大幅减少 CPU 对数据传输的干预,I/O 吞吐量提升 10 倍以上。
1.5. 阶段 5:I/O 模块增加了单独的处理器(I/O 通道)
-
核心逻辑:为 I/O 模块配备专用处理器(通道处理器),执行独立的通道指令集,管理多设备批量 I/O。
-
技术特点:
通道具备完整的指令执行能力,可自主解析 I/O 请求、调度设备传输、处理错误。
CPU 只需下发 "通道程序"(一系列通道指令),无需干预具体传输过程。
-
典型场景:大型机、企业级存储阵列(如 IBM z 系列主机)。
-
核心突破:复杂 I/O 任务完全自治,CPU 从 I/O 管理中彻底解放,支持大规模设备并行。
1.6. 阶段 6:I/O 模块有自己的局部存储器(智能 I/O 模块)
-
核心逻辑:I/O 模块内置局部存储器(缓存 / 内存)和多核处理器,实现 "存储 - 计算 - 传输" 一体化。
-
技术特点:
局部存储器用于缓存设备数据,减少与主机内存的交互次数,降低延迟。
内置处理器支持硬件卸载(如数据压缩、加密、校验和计算),进一步减轻 CPU 负担。
-
典型场景:现代智能网卡(Smart NIC)、NVMe SSD、RDMA 设备。
-
核心突破:I/O 子系统具备完整的本地处理能力,可实现 "零拷贝""内核旁路" 等极致性能优化,是云计算、AI 集群的核心支撑。
二、I/O缓冲
I/O 缓冲是操作系统中用来缓解 CPU 与外设速度不匹配、减少 I/O 次数、提升系统并发性能的核心技术。
各类缓冲技术对比
| 缓冲类型 | 并行性 | 适用场景 | 核心优势 |
|---|---|---|---|
| 无缓冲 | 无 | 低速字符设备(早期) | 实现简单 |
| 预读缓冲 | 部分并行 | 顺序读操作 | 利用局部性减少 I/O 次数 |
| 单缓冲 | 部分并行 | 单次块传输、终端交互 | 实现简单,成本低 |
| 双缓冲 | 设备与 CPU 并行 | 高吞吐量块设备 | 消除复制等待时间 |
| 循环缓冲 | 多生产者 / 消费者并行 | 高并发流式 I/O | 动态调度,适配实时场景 |
| 缓冲池 | 全局并行 | 通用操作系统 I/O | 资源复用,高效管理 |
2.1 无缓冲的弊端
在没有缓冲的情况下,I/O 操作会直接与用户内存交互,存在以下问题:
- 程序阻塞:进程必须等待慢速 I/O 完成才能继续执行,CPU 利用率低。
- 内存锁定风险:若 I/O 操作与内存交换(页换入 /换出)同时发生,会导致内存数据不一致甚至死锁,因此需要锁定进程对应的内存页,这会干扰操作系统的交换决策。
- 效率低下:每次 I/O 仅传输少量数据,频繁的设备启停和总线占用会大幅降低系统吞吐量。
2.2 预读缓冲(在系统内存中预先读取数据)
-
核心思想:操作系统在用户进程发起 I/O 请求前,主动将设备上的连续数据预读到系统缓冲区,利用局部性原理减少后续 I/O 次数。
-
关键特点:
系统需要记录每个用户进程分配的缓冲区信息,以便管理和回收。
如果 I/O 目标磁盘与交换分区磁盘相同,写缓冲会失去意义(数据可能被交换操作覆盖)。
-
适用场景:文件系统的顺序读操作(如视频播放、日志分析),可显著提升读性能。
2.3 单缓冲(Single Buffer)
面向块的单缓冲
-
原理:输入数据先被一次性写入系统缓冲区(块大小通常与磁盘扇区对齐),传输完成后再整块移动到用户空间。
-
性能公式:总耗时 = max(C, T) + M
C :CPU 处理数据时间
T :设备传输数据到缓冲区时间
M:数据从缓冲区复制到用户空间时间 -
特点:CPU 与设备可以部分并行(如设备传输时 CPU 可处理前一块数据),但复制到用户空间的阶段会阻塞。
面向流的单缓冲
- 原理:每次仅传输一行数据(如终端输入),缓冲区仅保存单行内容。
- 缺点:设备与设备之间无法并行,且频繁的小数据传输会增加开销。
适用场景
- 面向块:磁盘、磁带等块设备的单次传输。
- 面向流:终端、串口等字符设备的交互场景。
2.4 双缓冲(Double Buffer)
面向块的双缓冲
-
原理:使用两个缓冲区交替工作,当设备向一个缓冲区写数据时,CPU 可以从另一个缓冲区读数据,实现设备与 CPU 的完全并行。
-
性能公式:总耗时 = max(C, T)
当一个缓冲区传输时,另一个缓冲区可被处理,消除了单缓冲中 M 的复制等待时间。
面向流的双缓冲
- 原理:两个缓冲区交替处理流式数据(如网络包),但性能提升与单缓冲相比并不明显,仅适合低速字符设备。
优缺点
- ✅ 优点:实现设备与 CPU 的并行,吞吐量比单缓冲更高。
- ❌ 缺点:仅能匹配设备与处理器的速度,无法支持多设备并行;缓冲区数量固定,灵活性不足。
适用场景
- 需要高吞吐量的块设备(如磁盘备份、视频采集)。
2.5 循环缓冲(Circular Buffer)
-
核心原理:使用多个缓冲区组成环形队列,采用生产者 - 消费者模型:
生产者(设备)向缓冲区写入数据。
消费者(CPU / 应用)从缓冲区读取数据。
缓冲区满时生产者等待,缓冲区空时消费者等待。
-
关键特点:
输入与输出的缓冲结构分离,避免单缓冲的阻塞问题。
支持多生产者 / 多消费者并发访问,适合高并发 I/O 场景。
-
适用场景:网络通信(如 TCP 接收队列)、音视频实时处理、多线程数据交互。
2.6 缓冲池(Buffer Pool)
-
核心原理:管理一组统一大小的缓冲区,通过链表或队列进行动态分配与回收,是现代操作系统的主流缓冲实现。
-
关键特点:
输入与输出的缓冲结构相连,可灵活分配给不同的 I/O 任务。
支持缓冲复用,减少内存碎片和分配开销。
通常包含空闲队列、输入队列、输出队列,由操作系统统一调度。
-
适用场景:通用操作系统(如 Linux、Windows)的文件系统、块设备驱动、网络协议栈。
三、磁盘调度
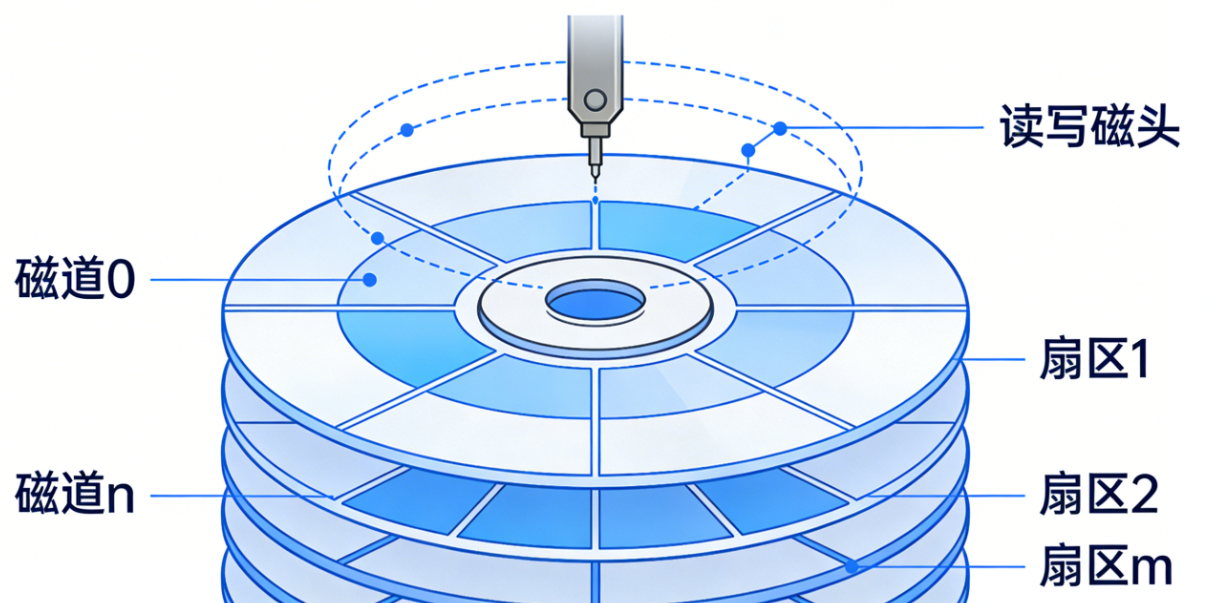
3.1 磁盘存取时间与性能参数
磁盘存取时间是衡量磁盘 I/O 性能的核心指标,它由多个延迟环节构成,理解这些参数的来源和优化思路,是掌握磁盘性能调优的基础。
| 时间类型 | 含义与说明 | 优化思路 |
|---|---|---|
| 寻道时间(Ts) | 磁头移动到目标磁道的时间,是延迟的主要来源(通常占比 70% 以上),很难通过软件优化。 | 合理的磁盘调度算法可以减少磁头移动距离,从而降低平均寻道时间。 |
| 旋转延迟 | 磁盘旋转,使目标扇区转到磁头下方的时间。公式:T旋转 = 1/(2r) (r为转速,单位 r/s) | 转速越高的磁盘(如 15000 转 SAS 盘),旋转延迟越小。 |
| 传输时间 | 数据从磁盘传输到内存的时间。公式:T传输 = b/(rN) (b为传输字节数,N为磁道字节数) | 提升磁盘接口带宽(如从 SATA 到 NVMe)可缩短传输时间。 |
| 排队延迟 | 进程在设备队列中等待磁盘空闲的时间。 | 通过 I/O 调度算法(如合并相邻请求)减少队列长度,降低等待时间。 |
- 总存取时间公式
T=Ts+12r+brNT=T_{s} +\frac{1}{2r} +\frac{b}{rN} T=Ts+2r1+rNb
-
寻道时间(Ts)
定义 :磁头从当前位置移动到目标磁道所需要的时间。
特点 :这是磁盘延迟的最主要来源,通常占总存取时间的 70% 以上。寻道时间的长短取决于磁头移动的距离,且很难通过软件优化,主要由磁盘硬件的机械性能决定。
典型值 :普通消费级 HDD 约为 5~10ms,企业级 SAS 盘约为 3~5ms,SSD 因无机械结构,寻道时间趋近于 0(<0.1ms)。
优化思路:通过磁盘调度算法(如 SCAN、C-SCAN)减少磁头的平均移动距离,从而降低平均寻道时间。 -
旋转延迟(Rotational Latency)
定义 :磁头到达目标磁道后,等待目标扇区旋转到磁头下方的时间。
公式 :T旋转=1/2r(r为磁盘转速,单位为转 / 秒)。例如,7200 转 / 分钟的磁盘转速为 120 转 / 秒,平均旋转延迟为1/(2×120)≈4.17 ms。
典型值 :7200 转 HDD 约为 4~5ms,15000 转 HDD 约为 2~3ms。
优化思路:选择更高转速的磁盘,或通过调度算法(如 SSTF)让磁头优先处理当前旋转位置附近的请求。 -
传输时间(Transfer Time)
定义 :数据从磁盘表面传输到内存的时间。
公式 :T传输=b/rN(b为需要传输的字节数,N为每个磁道的字节数)。该公式的含义是:磁盘每旋转一圈(耗时1/r)可以读出一个磁道的数据(N字节),因此传输b字节所需时间为(b/N)×(1/r)。
典型值 :取决于磁盘接口带宽(如 SATA 3.0 为 6Gbps,NVMe 4.0 为 32Gbps)和磁道密度。
优化思路:提升磁盘接口带宽(如从 SATA 升级到 NVMe)、增加磁道存储密度,或通过预读技术合并相邻请求,减少传输次数。 -
排队延迟(Tq)
定义 :I/O 请求在磁盘队列中等待磁盘空闲的时间。
特点 :延迟长短取决于系统的 I/O 负载和调度算法。当磁盘繁忙时,队列长度增加,排队延迟会显著上升。
优化思路:通过 I/O 调度算法合并请求、调整队列长度,或增加磁盘数量(如 RAID)分散负载。
3.2 经典磁盘调度算法
磁盘调度算法的核心目标是减少磁头移动距离,从而降低平均寻道时间,提升磁盘 I/O 的整体性能。
| 算法名称 | 核心思想 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 随机调度(Random) | 随机选择队列中的请求 | 实现简单 | 磁头移动距离大,性能最差 | 无实际应用,仅作为性能对比基准 |
| 先进先出(FIFO) | 按请求到达顺序处理 | 公平、无饥饿问题 | 磁头频繁往返移动,寻道时间长 | 请求量小或 I/O 负载低的场景 |
| 优先级调度(PRI) | 优先处理高优先级请求 | 满足紧急业务需求 | 低优先级请求可能长期饥饿 | 实时业务场景(如数据库日志写入) |
| 后进先出(LIFO) | 优先处理最新到达的请求 | 利用局部性原理,提升缓存命中率 | 早期请求可能饥饿 | 局部性强的场景(如文件服务器) |
| 最短服务时间优先(SSTF) | 选择与当前磁头位置距离最近的请求 | 显著减少平均寻道时间 | 可能导致饥饿问题(偏远磁道请求长期无法被处理) | 中小规模 I/O 请求场景 |
| 扫描算法(SCAN,电梯算法) | 磁头沿一个方向移动,处理所有沿途请求,到达端点后反向 | 性能稳定,无饥饿问题 | 对最近端点的请求更友好,中间磁道请求延迟较高 | 高负载、请求分布均匀的场景(如存储服务器) |
| 循环扫描(C-SCAN) | 磁头沿一个方向移动,处理完后直接跳转到另一端起点,而非反向 | 使不同磁道的请求延迟更均匀 | 磁头移动距离略大于 SCAN | 对延迟均匀性要求高的场景(如视频流服务) |
| N 步 SCAN | 将请求队列分成长度为 N 的子队列,对每个子队列执行 SCAN | 避免长队列导致的饥饿问题 | 实现复杂度较高 | 高并发、请求量大的场景 |
| FSCAN | 使用两个子队列:处理老请求时,新请求进入另一个队列,处理完老队列再处理新队列 | 进一步保证公平性,避免饥饿 | 对新请求的响应延迟略高 | 对公平性要求高的多用户场景 |
3.3 磁盘高速缓存(Disk Cache)
磁盘高速缓存(Disk Cache)是内存中专门划分的一块连续区域 ,用于临时存储磁盘中被频繁访问或即将被访问的数据 / 指令,核心利用程序的局部性原理(时间局部性、空间局部性),减少磁盘物理 I/O 次数、降低存取延迟,是提升磁盘 I/O 性能的核心技术之一。
磁盘高速缓存的核心原理
基于程序运行的局部性原理,这是磁盘缓存能提升性能的根本原因:
- 时间局部性:某一时刻被访问的磁盘数据,在短期内大概率会被再次访问(如程序循环读取同一文件);
- 空间局部性:某一位置被访问的磁盘数据,其相邻位置的数据大概率会被紧接着访问(如顺序读取文件、遍历数据库表)。
基于此,操作系统会做两个核心操作:
- 缓存命中:进程请求的数据已在缓存中,直接从内存读取,无需访问物理磁盘,耗时仅为微秒级;
- 缓存未命中:进程请求的数据不在缓存中,先从磁盘读取数据到缓存,再从缓存传递给进程,同时利用空间局部性预读相邻数据到缓存,为后续请求做准备。
缓存命中率(命中次数 / 总请求次数)是衡量磁盘缓存性能的核心指标,命中率越高,磁盘 I/O 性能提升越显著(一般命中率达到 90% 以上时,磁盘 I/O 延迟会大幅降低)。
磁盘高速缓存的核心组成与关键策略
操作系统对磁盘缓存的管理核心围绕缓存块分配、替换策略、写策略 展开,缓存的基本单位为缓存块 (与磁盘的物理块 / 扇区大小对齐,通常为 4KB、8KB),且缓存块与磁盘块为映射关系。
-
缓存替换策略
当缓存空间被占满,新数据需要写入缓存时,需淘汰部分旧缓存块,替换策略决定淘汰哪些块,直接影响缓存命中率,以下是主流策略(按实用性排序):
| 替换策略 | 核心思想 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| LRU(最近最少使用) | 淘汰最久未被访问的缓存块 | 符合局部性原理,命中率最高,实现简单 | 需记录块的访问时间,有轻微时间开销 | 绝大多数场景(操作系统默认首选) |
| LFU(最不常用) | 淘汰访问次数最少的缓存块 | 适配长期高频访问的热点数据 | 对突发访问模式不友好(低频新数据易被淘汰),需统计访问次数 | 热点数据固定的场景(如静态资源服务器) |
| FIFO(先进先出) | 按缓存块写入顺序,淘汰最早写入的块 | 实现极简单,无额外开销 | 可能淘汰仍在使用的高频块(Belady 异常:缓存空间增大,命中率反而降低) | 对性能要求低、资源受限的轻量系统 |
| 随机替换 | 随机淘汰任意缓存块 | 实现最简单,开销最小 | 完全不遵循局部性原理,命中率最低 | 仅作性能对比基准,无实际应用 |
| Clock(时钟算法) | LRU 的轻量实现,为块加访问位,指针循环扫描,遇访问位为 0 则淘汰,为 1 则置 0 并跳过 | 兼顾 LRU 的高命中率和 FIFO 的低开销,无需记录时间 | 命中率略低于纯 LRU | 嵌入式系统、内存资源紧张的场景 |
缓存写策略
进程向磁盘写入数据时,并非直接写入物理磁盘,而是先写入磁盘缓存(缓存块标记为脏块 :缓存块数据与磁盘块数据不一致),写策略 决定脏块何时同步到物理磁盘,核心平衡写入性能和数据安全性。
| 写策略 | 核心思想 | 性能 | 数据安全性 | 适用场景 |
|---|---|---|---|---|
| 写回(Write Back) | 仅当脏块被淘汰或系统主动刷盘时,才将脏块数据同步到磁盘 | 最高(减少 90% 以上的磁盘物理写操作) | 较低(系统崩溃时,未刷盘的脏块数据会丢失) | 写操作频繁的场景(如数据库、日志服务器),需配合 UPS 保障电源 |
| 写通(Write Through) | 数据写入缓存的同时,立即同步到物理磁盘,缓存块无脏块 | 最低(每次写都触发物理 I/O) | 最高(缓存与磁盘数据实时一致,无丢失风险) | 对数据安全性要求极高的场景(如金融、医疗数据存储) |
| 延迟写(Write Delay) | 写回策略的优化,为脏块设置超时时间,超时后自动同步到磁盘;若超时前脏块被再次修改,仅更新缓存,无需多次刷盘 | 比纯写回性能更高,脏块刷盘频率更低 | 安全性略低于写回(超时时间内系统崩溃会丢失数据),可配置超时时间(通常 1~5s) | 海量写操作、对实时性无要求的场景(如文件下载、数据备份) |
数据预读与传送优化
操作系统会基于空间局部性做额外优化,进一步提升缓存利用率和数据传输效率:
- 数据预读:当进程读取某一磁盘块时,操作系统自动将相邻的若干个磁盘块一并读取到缓存中,进程后续读取相邻数据时可直接命中缓存,预读大小可配置(如Linux 默认预读 128KB);
- 指针传递:缓存命中时,无需将缓存块数据拷贝到用户进程地址空间,而是直接将缓存块的内存指针映射到用户空间,减少一次数据拷贝,提升传输效率;
- 脏块批量刷盘:系统空闲时,会将多个脏块批量同步到磁盘,替代单次刷盘,减少磁盘寻道和旋转延迟,提升刷盘效率。
3.4 Linux I/O 调度器
Linux I/O 调度器(I/O Scheduler)是内核块设备层 的核心组件,位于用户进程 I/O 请求与磁盘硬件驱动之间,核心作用是对磁盘 I/O 请求队列进行重排、合并、延迟处理,优化磁头移动轨迹(针对机械硬盘 HDD)或提升请求并行度(针对固态硬盘 SSD/NVMe),最终降低磁盘 I/O 延迟、提升整体吞吐量。
| 调度器名称 | 核心思想 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 电梯调度器(Elevator) | 最基础的调度器,实现请求合并 + 磁道升序重排,磁头沿磁道升序处理请求,到达最外侧磁道后反向,完全遵循电梯算法逻辑。 | 实现简单;有效减少磁头往返移动;性能远优于无调度的原生请求队列。 | 无优先级区分、无请求延迟优化;对随机 I/O 处理差;未考虑读 / 写请求的延迟敏感性差异。 | 早期低负载 HDD 场景;目前被替代,仅作基础实现参考。 |
| 完全公平调度器(CFQ) | Linux 2.6.18 后默认调度器,基于进程级公平性设计,为每个 I/O 进程创建独立请求队列,按时间片轮询处理,队列内执行电梯算法重排 + 合并;支持 ionice 设置 0~7 级 I/O 优先级(0 最高),高优先级进程获更多时间片。 |
保证多进程 I/O 公平性,避免单进程占满磁盘 I/O;支持 I/O 优先级,适配业务级资源调度;兼顾顺序 / 随机 I/O,综合性能均衡。 | 进程队列管理和轮询存在内核开销;延迟敏感的读请求可能因公平性被写请求阻塞;对 SSD 无优化,公平性设计收益低于开销。 | 多用户、多进程的 HDD 通用场景(通用服务器、桌面系统);HDD 的 "万能调度器"。 |
| 最后期限调度器(Deadline) | Linux 2.6 后推出,针对读请求延迟敏感设计,核心避免请求饥饿,兼顾顺序优化;维护 3 个队列(电梯队列 + 读 FIFO 队列 + 写 FIFO 队列),读超时默认 500ms、写超时默认 5s,超时请求优先处理;遵循读优先原则(读同步、写异步)。 | 严格控制请求最大延迟,彻底避免饥饿;读请求优先,适配读延迟敏感场景;开销低于 CFQ,性能更稳定。 | 多进程场景下公平性略差于 CFQ;对纯顺序写场景的优化略逊于 CFQ。 | HDD 为主的延迟敏感型场景(MySQL/Oracle 数据库、KVM 虚拟机、大数据计算节点);企业级 HDD 服务器主流选择。 |
| 预期调度器(Anticipatory,AS) | 在 Deadline 基础上优化顺序读性能,核心为 "预期相邻读请求";处理完一个读请求后延迟 6ms,等待相邻磁道的读请求,直接处理以避免磁头频繁移动。 | 对纯顺序读密集的 HDD 场景优化效果极致,吞吐量提升显著。 | 延迟机制导致随机 I/O 性能下降,对混合 I/O 不友好;无相邻请求时延迟会产生额外开销;Linux 3.10 版本已被移除。 | 纯顺序读的 HDD 专用场景(静态资源服务器、日志服务器);目前被 Deadline 替代(可调优实现近似效果)。 |
| noop 调度器(No Operation) | 极简调度器,仅实现请求合并,无请求重排、无延迟,按请求到达顺序直接透传至磁盘驱动。 | 内核开销极低,几乎无性能损耗。 | 对 HDD 无优化效果,磁头随机移动,性能极差。 | 早期 SSD 测试场景;目前被先进 SSD 调度器替代,仅作调度器性能对比基准。 |
拓展 :现代 SSD固态硬盘 无机械运动,寻道时间趋近于 0,因此 Linux 提供了mq-deadline、kyber等多队列调度器,以及none调度器(直接提交请求),以充分发挥 SSD 的性能。