目录
前言
书接上文【Linux】进程概念(四):(命令行参数和环境变量)详情请点击查看,今天继续介绍【Linux】进程概念(五)(虚拟地址空间----建立宏观认知)
一、铺垫知识
C/C++内存布局
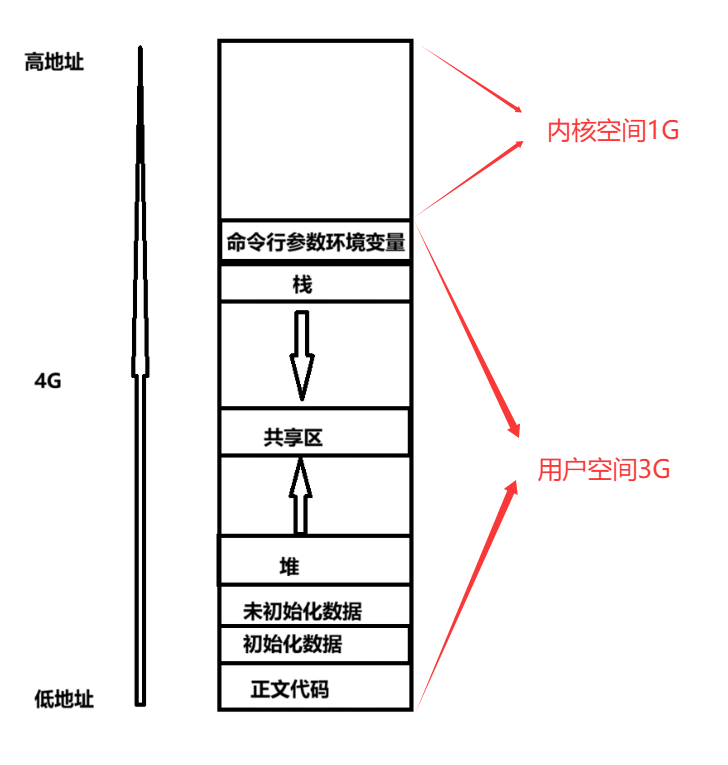
- 在学习C/C++的时候,我们了解过堆区、栈区、静态区等等,如下图所示
- 验证C/C++内存布局情况
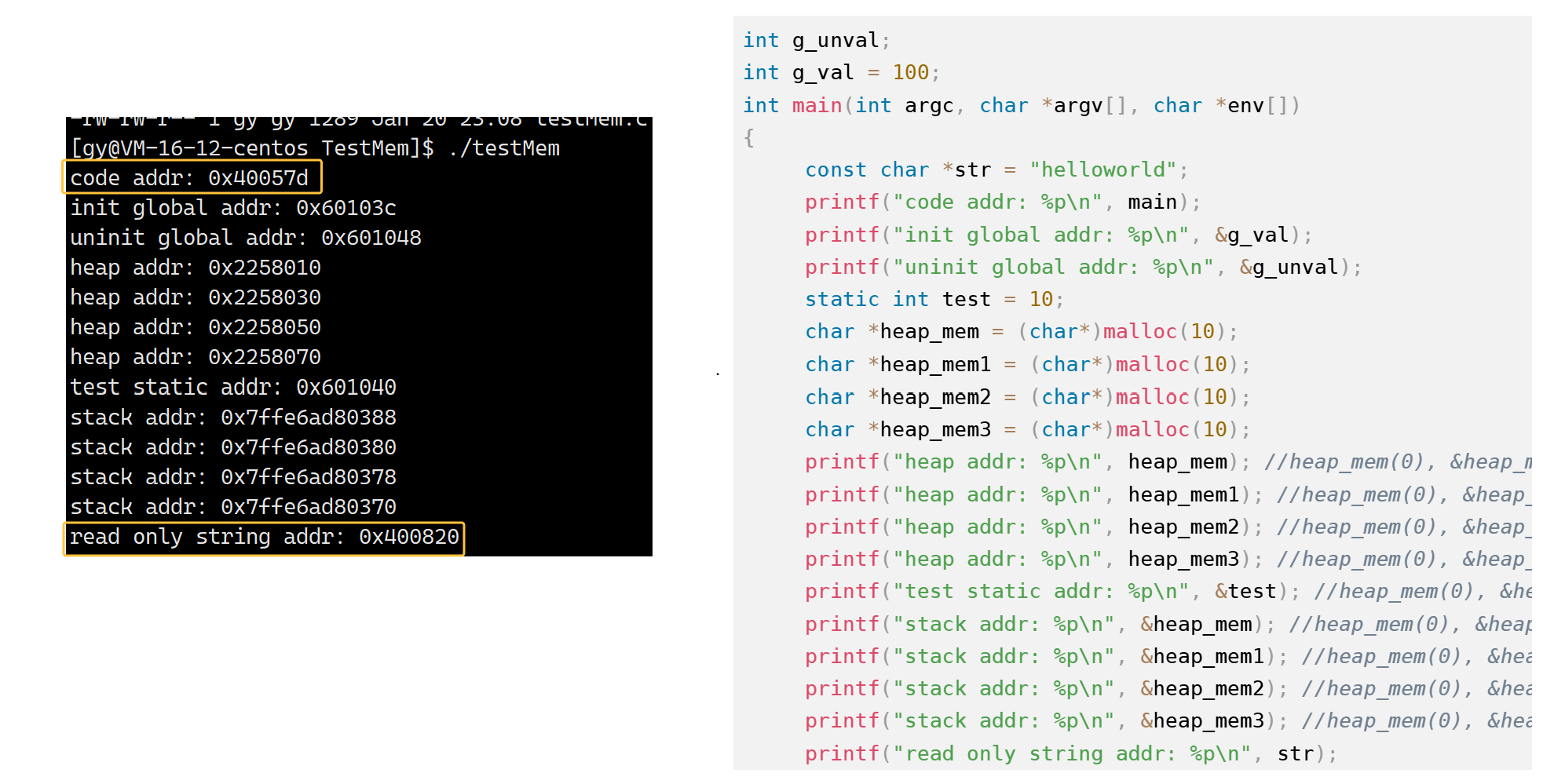
- 定义一个未初始化的全局变量以及初始化了的全局变量;在main函数内使用malloc申请空间,定义静态成员变量
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{
const char *str = "helloworld";
printf("code addr: %p\n", main);
printf("init global addr: %p\n", &g_val);
printf("uninit global addr: %p\n", &g_unval);
static int test = 10;
char *heap_mem = (char*)malloc(10);
char *heap_mem1 = (char*)malloc(10);
char *heap_mem2 = (char*)malloc(10);
char *heap_mem3 = (char*)malloc(10);
printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)
printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)
return 0;
}
二、虚拟地址空间
进程地址空间(虚拟地址空间)的引入
- 上面我们获得的地址是物理地址空间吗?答案是上面我们打印获得的地址不是物理地址,而是进程地址空间,也就是我们后面要主要介绍的虚拟地址空间
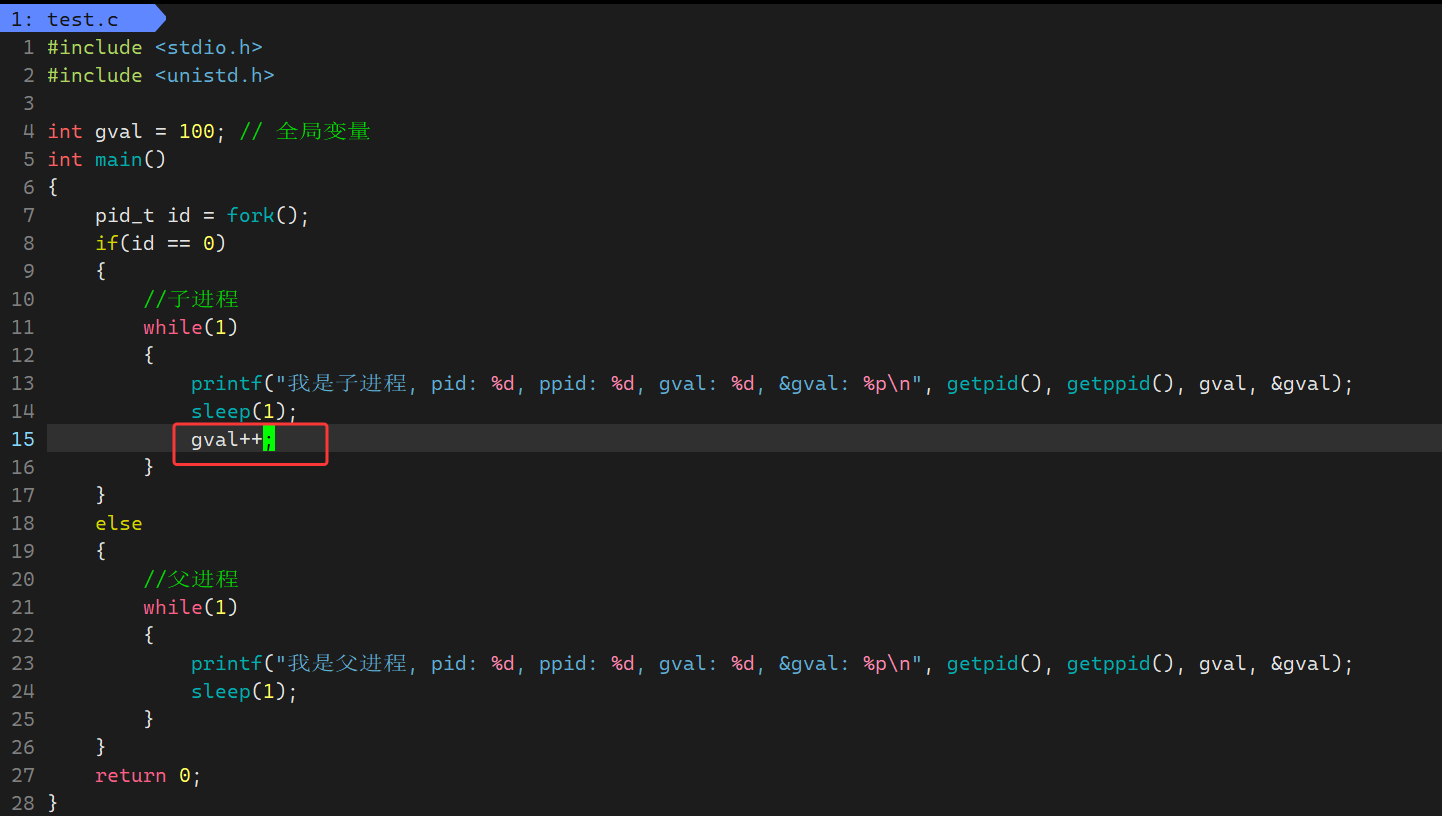
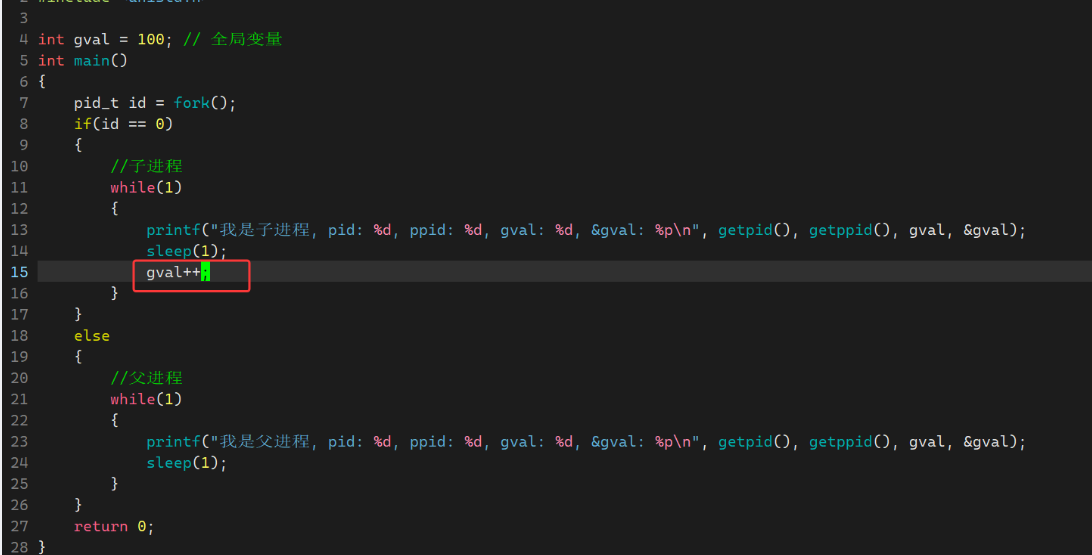
- 现在我们编写一段代码:使用fork创建子进程,并定义全局变量,在父子进程中访问这个全局变量,已经打印该全局变量的地址
cpp
#include <stdio.h>
#include <unistd.h>
int gval = 100; // 全局变量
int main()
{
pid_t id = fork();
if(id == 0)
{
//子进程
while(1)
{
printf("我是子进程, pid: %d, ppid: %d, gval: %d, &gval: %p\n", getpid(), getppid(), gval, &gval);
sleep(1);
}
}
else
{
//父进程
while(1)
{
printf("我是父进程, pid: %d, ppid: %d, gval: %d, &gval: %p\n", getpid(), getppid(), gval, &gval);
sleep(1);
}
}
return 0;
}
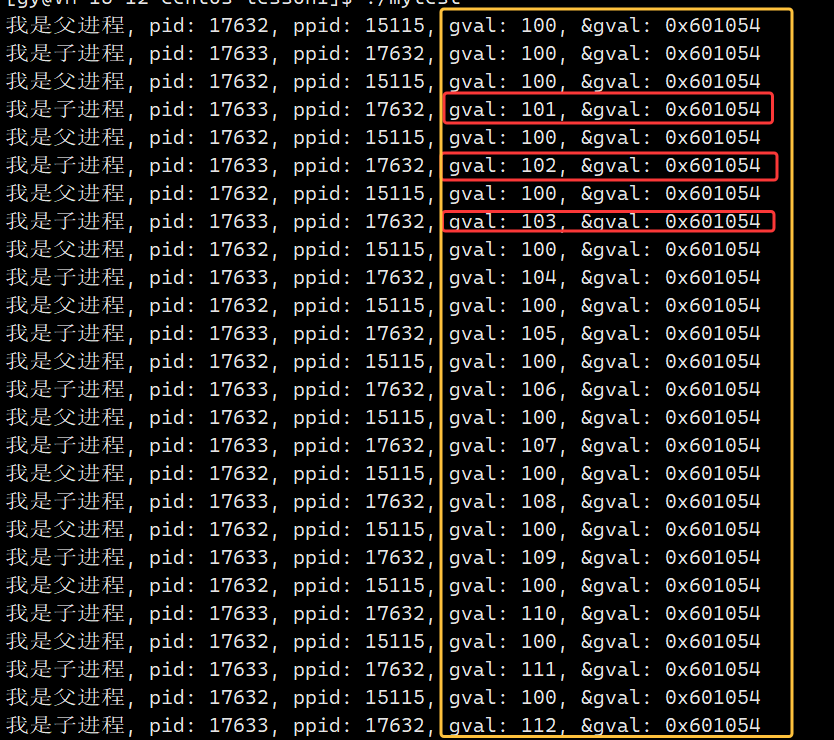
- 从下面打印结果我们可以看到,父子进程都能访问到gval全局变量,且它们打印的地址是完全一样的。fork之后,父子进程代码、数据共享,默认情况下父子进程都能访问
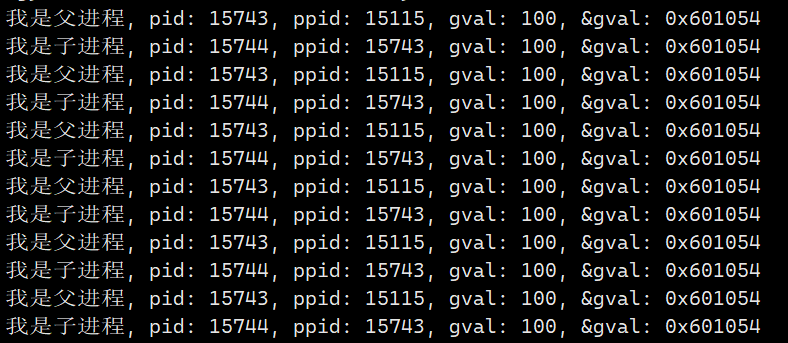
- 下面我们修改一下代码,子进程不仅仅是访问打印全局变量地址,还对全局变量进行修改,现在再观察打印结果
- 我们可以看到父进程打印的gval一直是100,子进程打印是100、101、102...这是符合进程独立性原则的,一个进程运行时是不能影响另一个进程的运行的 ,但是它们
打印的地址竟然是一样的- 读取同一个gval变量,地址也是一样的,怎么会父进程读取是100,子进程读取是100、101...呢,怎么会读取出来不同的值呢?
- 因此我们可以确定这个地址一定不是物理内存的地址 ,这个地址就是
虚拟地址,在我们学习C语言、C++中打印出来的地址都是虚拟地址,我们是无法看到物理地址的
对虚拟地址的理解
-
我们以32位机器为例,虚拟地址空间范围0,2\^32,从000...000到FFF...FFF
-
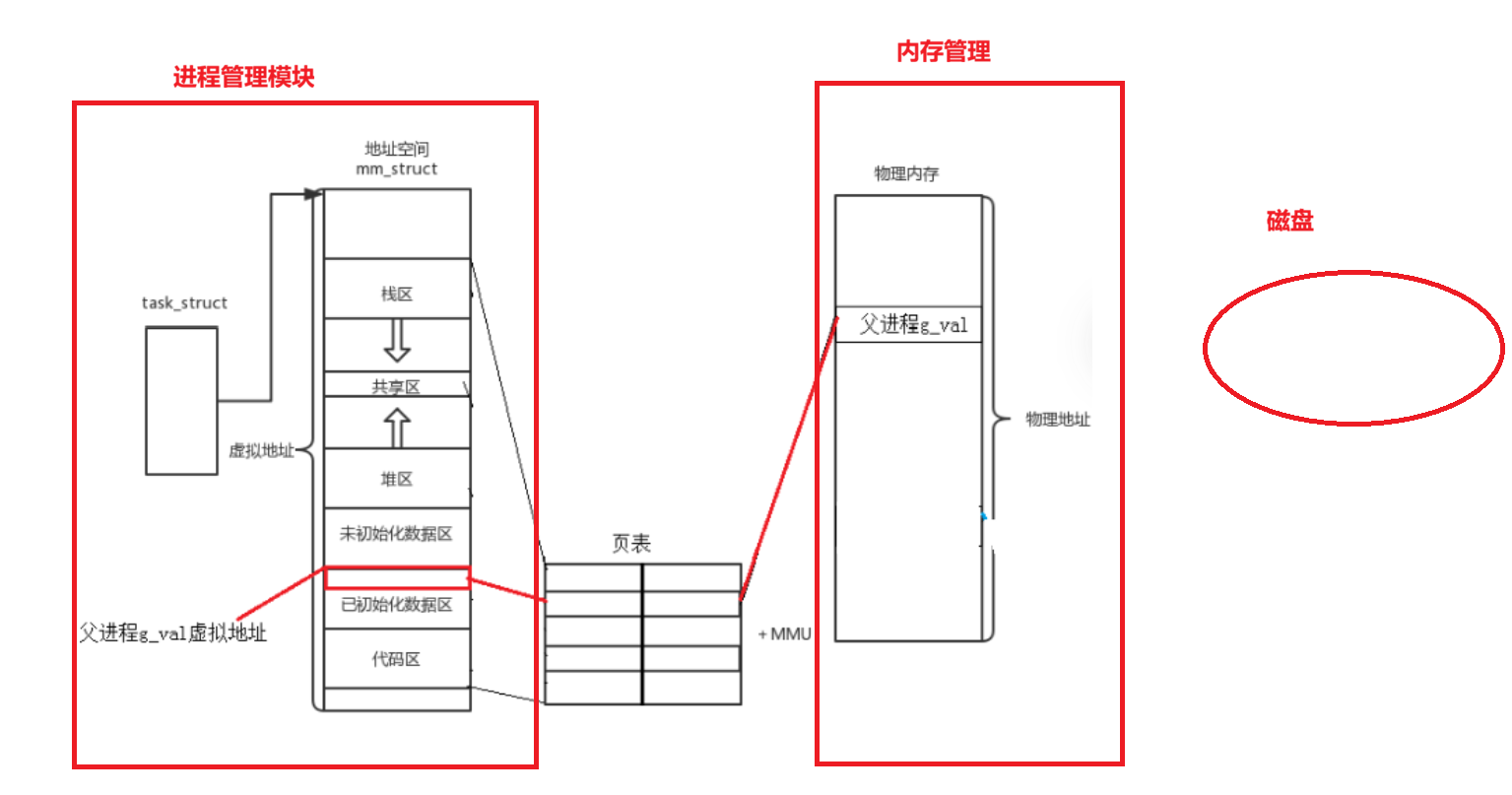
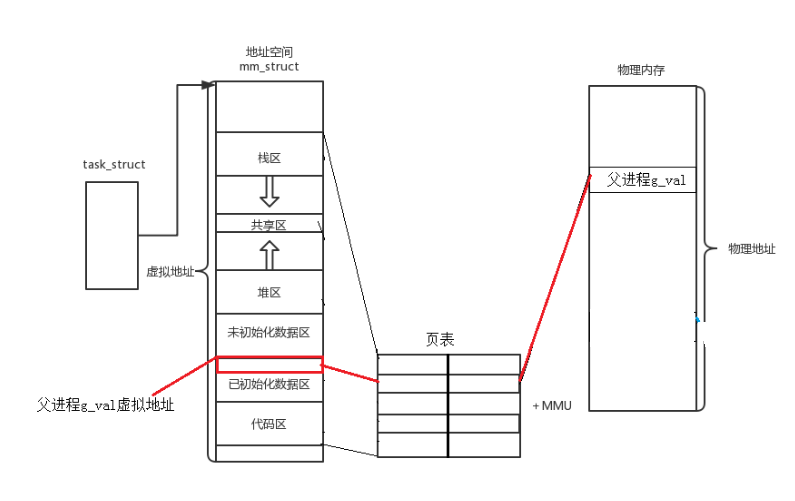
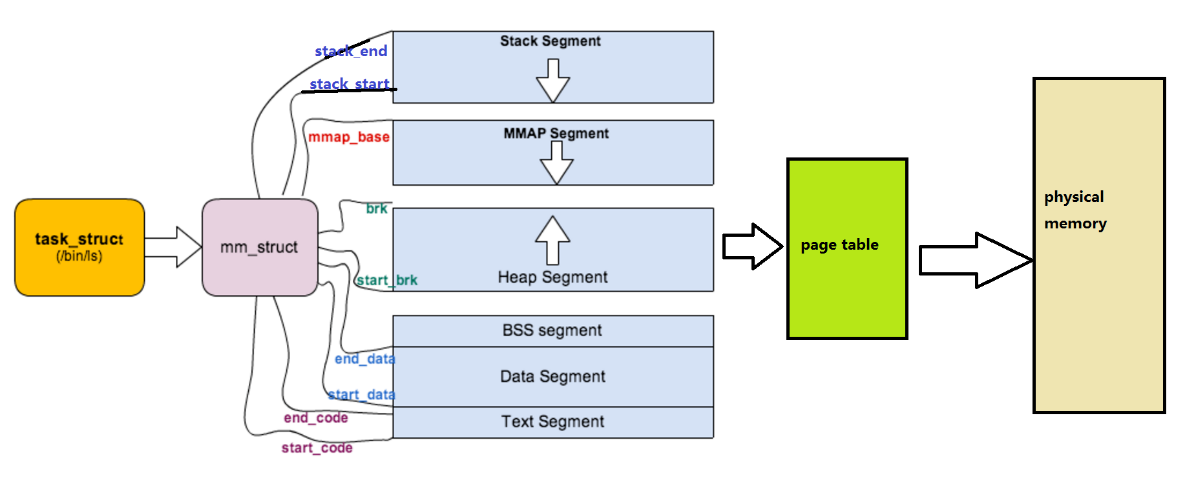
我们执行一个程序时,代码和数据加载到内存中(物理内存),创建进程就会创建task_struct,task_struct会保存进程的属性,上下文等数据,并指向虚拟地址空间----C/C++学习的地址(包括代码区、栈区、堆区等),同时通过页表将虚拟地址映射到物理地址 ,找到物理内存,这样才能访问到数据,如下图所示:
-
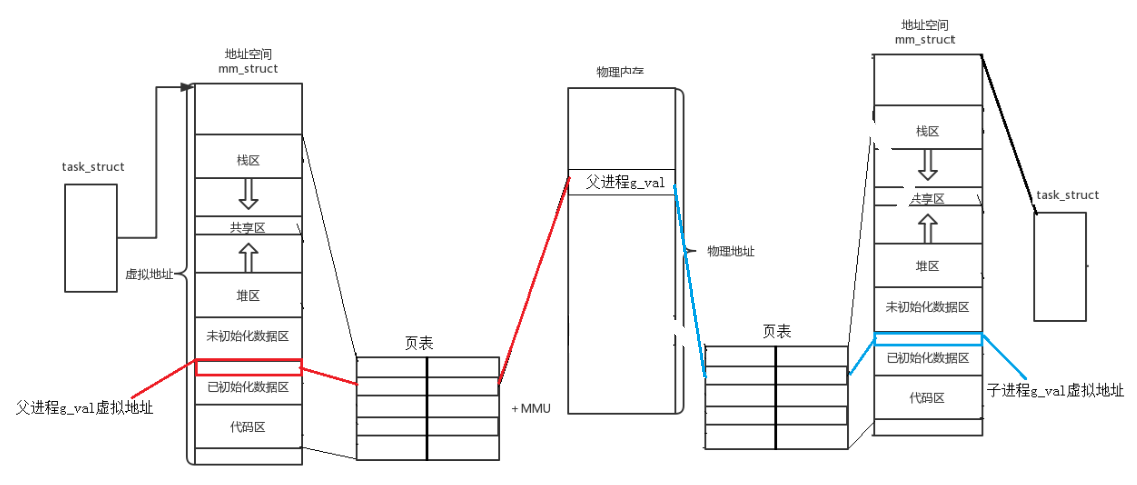
当创建子进程后,子进程会以父进程的task_struct、虚拟地址空间、页表为模板拷贝为子进程的task_struct、虚拟地址空间、页表(会修改部分属性,比如:pid、ppid等),这样父子进程有一样的g_val的虚拟地址空间,映射到物理内存也是和父进程指向同一个物理地址上
-
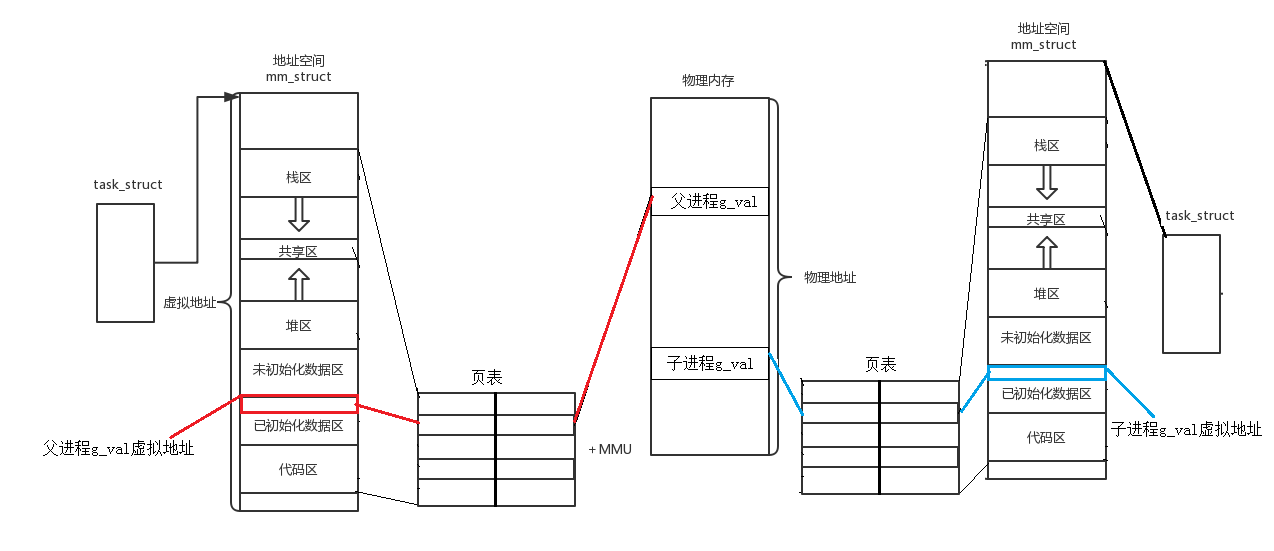
当父子进程要对数据进行修改时,由于进程间是独立的,所以当进程尝试对共享的数据进行修改时,操作系统会重新开辟一个空间(新的物理地址),将全局变量的值拷贝到新空间中,修改页表中虚拟地址到物理地址的映射,这样的一个过程叫做
写时拷贝 -
整个写时拷贝的过程全部由操作系统完成,用户不知道,这整个过程虚拟地址空间是没有变化的,但是底层物理地址已经是不一样的了。(同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了不同的物理地址)
- 上述知识点就能解释我们代码中id为什么既能等于0,又能大于0:id是父进程创建的变量,fork创建子进程,fork的返回值:return xxx,其本质就是对id变量进行修改写入,所以就会发生写时拷贝,所以同一个变量父进程看到的就是子进程pid,子进程看到的就是0,其本质都是同一个变量,虚拟地址空间相同,但是映射到底层的物理地址空间已经不一样了
理解空间划分
- 每个进程的虚拟地址都是从000...000到FFF...FFF,但是进程并不是真的有这么多空间能使用,虚拟地址是虚拟的(就类似画大饼一样,操作系统虽然告诉你你有000...000到FFF...FFF这么多空间,但是如果操作系统本身只有4G,某个进程直接申请4G空间,操作系统是不会划分给该进程4G空间的)
- 每个进程都会有虚拟地址空间,那么每个进程的虚拟地址空间需要操作系统进行管理,操作系统进行管理:先描述,再组织
- 虚拟地址空间是操作系统给进程画的饼,本质是一个内核数据结构
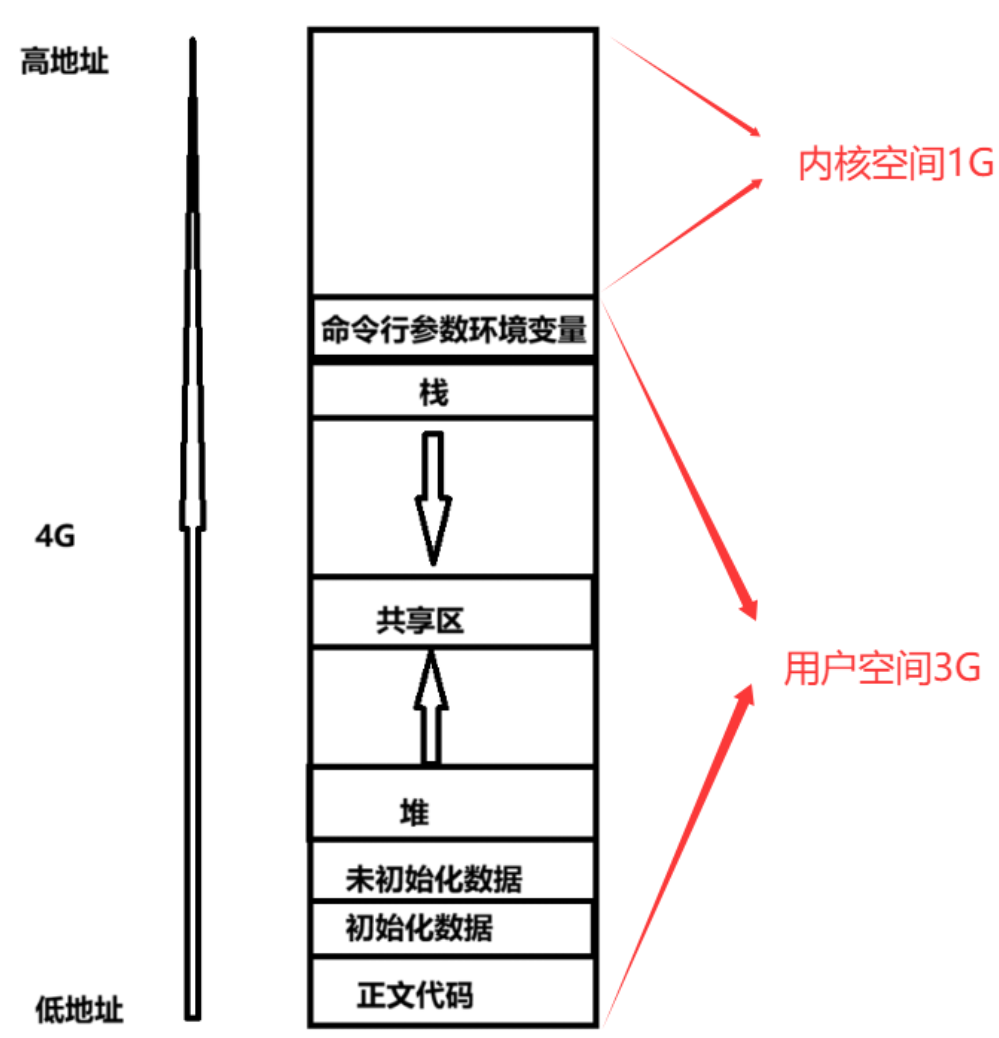
- 从上述图片我们知道虚拟内存空间是将000...000到FFF...FFF划分一个个区域:代码区、堆区、栈区...每个区都会有起始地址和最终地址
- 用户空间指程序员能直接用地址访问的空间,访问内核空间,则必须要使用系统调用

三、虚拟内存管理
- 描述linux下进程的地址空间的所有的信息的结构体是mm_struct(内存描述符)。每个进程只有一个mm_struct结构,在每个进程的task_struct 结构中,有一个指向该进程的mm_struct结构体指针
cpp
struct task_struct
{
struct mm_struct *mm;
}
struct mm_struct
{
/*...*/
struct vm_area_struct *mmap; /* 指向虚拟区间(VMA)链表 */
struct rb_root mm_rb; /* red_black树 */
unsigned long task_size; /*具有该结构体的进程的虚拟地址空间的⼤⼩*/
/*...*/
// 代码段、数据段、堆栈段、参数段及环境段的起始和结束地址。
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
}
- mm_struct 结构是对整个用户空间的描述。每一个进程都会有自己独立的 mm_struct ,这样每一个进程都会有自己独立的地址空间才能互不干扰
虚拟空间的组织方式
- 但是有一个问题,堆区空间我们并不是一次申请的,可以使用new,malloc多次申请堆上空间,那么又怎么管理堆上的这一小块小块申请的空间呢?
- 每一个进程都会有自己独立的 mm_struct ,操作系统肯定是要将这么多进程的 mm_struct组织起来的!虚拟空间的组织方式有两种
- 当虚拟区较少时采取单链表,由mmap指针指向这个链表
- 当虚拟区间多时采取红黑树进行管理,由mm_rb指向这棵树
- linux内核使用 vm_area_struct 结构来表示一个独立的虚拟内存区域(VMA),由于每个不同质的虚拟内存区域功能和内部机制都不同,因此一个进程使用多个vm_area_struct结构来分别表示不同类型的虚拟内存区域。上面提到的两种组织方式使用的就是vm_area_struct结构来连接各VMA,方便进程快速访问
cpp
struct vm_area_struct {
unsigned long vm_start; //虚存区起始
unsigned long vm_end; //虚存区结束
struct vm_area_struct *vm_next, *vm_prev; //前后指针
struct rb_node vm_rb; //红⿊树中的位置
unsigned long rb_subtree_gap;
pgprot_t vm_page_prot;//访问权限
struct mm_struct *vm_mm; //所属的 mm_struct
//.......
} __randomize_layout;pgprot_t vm_page_prot代码:访问权限,vm_area_struct中会保存每个区域的访问权限(读、写...)
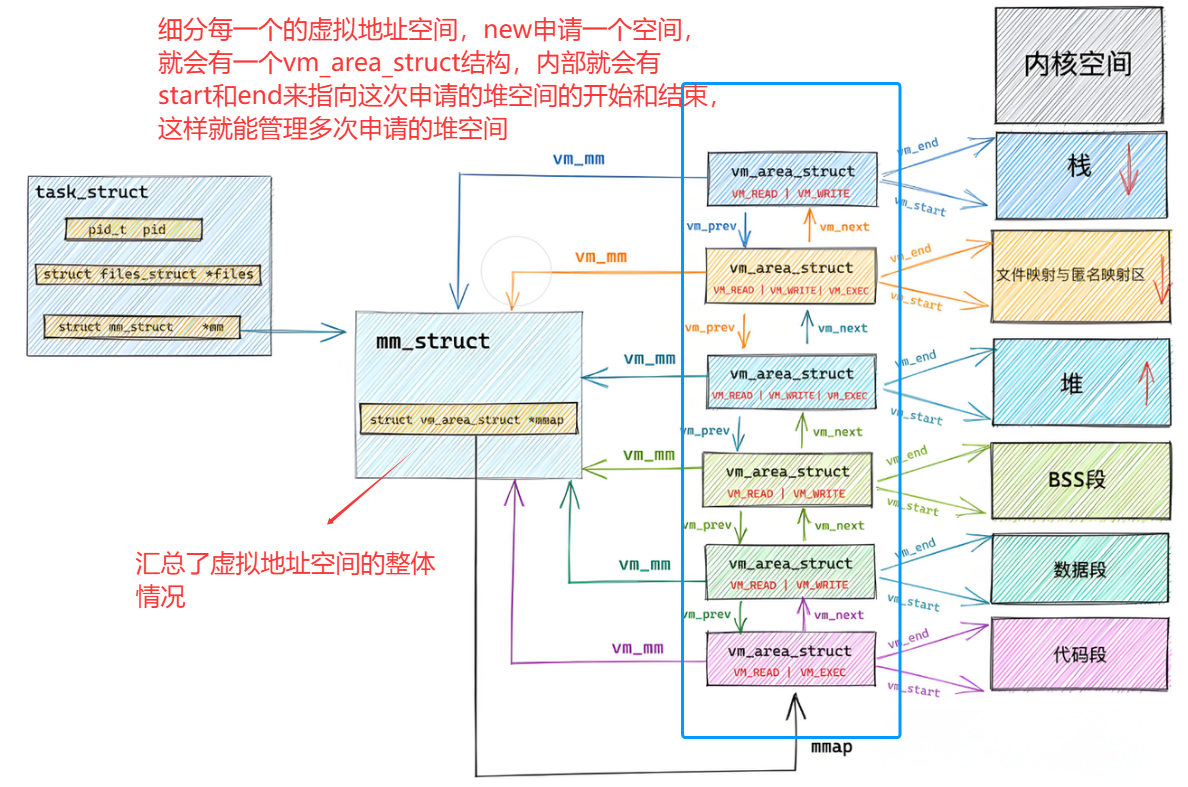
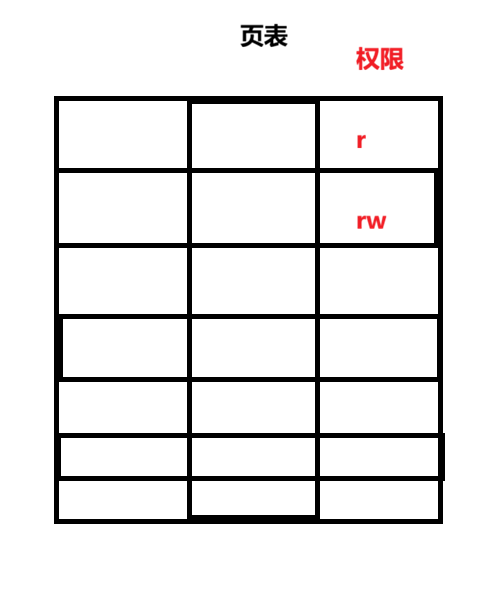
页表知识点补充与总结
- 进程中,我们的代码、常量是不能修改的,但是变量是可以修改的,这是怎么实现的呢?
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{
const char *str = "helloworld";
printf("code addr: %p\n", main);
printf("init global addr: %p\n", &g_val);
printf("uninit global addr: %p\n", &g_unval);
static int test = 10;
char *heap_mem = (char*)malloc(10);
char *heap_mem1 = (char*)malloc(10);
char *heap_mem2 = (char*)malloc(10);
char *heap_mem3 = (char*)malloc(10);
printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)
printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)
printf("read only string addr: %p\n", str);
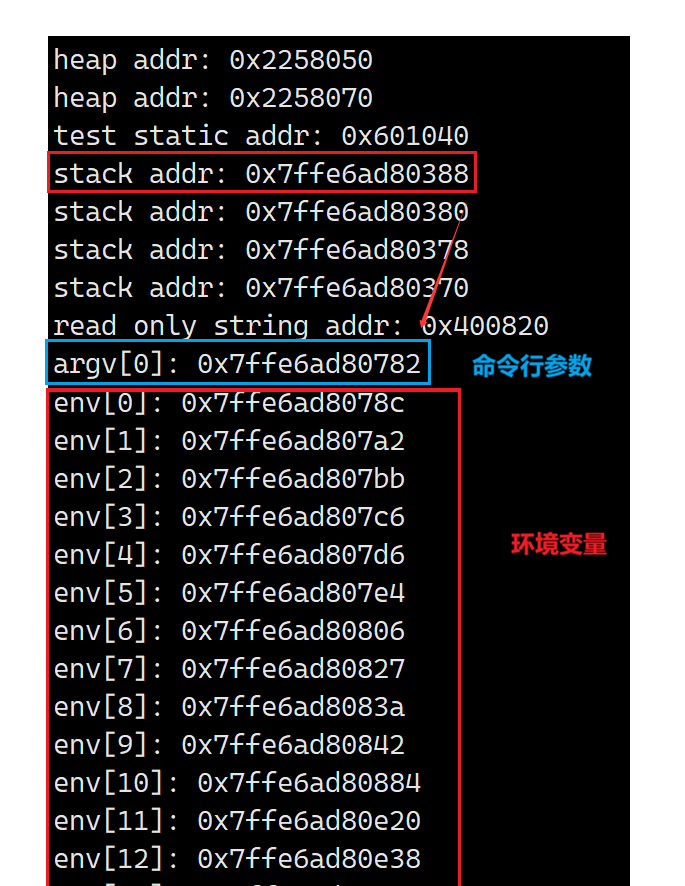
for(int i = 0 ;i < argc; i++)
{
printf("argv[%d]: %p\n", i, argv[i]);
}
for(int i = 0; env[i]; i++)
{
printf("env[%d]: %p\n", i, env[i]);
}
return 0;
}-
页表中,每一个区都会有一个权限 ,如果是代码区、常量区,那么只有读权限,不能修改,如果是变量,那么会设置权限为读写权限
-
从上述代码的结果我们可以看到代码区和str常量字符串地址都在代码区,因此在代码区中会有一个小区域是字符常量区,都是只读的,数据是不可修改的,所以我们不能
*str = 'C'将str中的helloworld修改为C,原因是如果我们要修改str内容,那么就需要拿到str的虚拟地址,再根据页表映射到物理地址,但是字符常量区是只读区域(权限检查),权限不匹配,因此无法转化为物理地址 -
定义的全局变量是全局有效的 ,因为它们在数据区,地址空间存在,那么全局数据区就要存在,所以全局变量会一直存在,包括static静态成员变量
-
命令行参数和环境变量属于父进程的地址空间内的数据资源,和代码区数据一样,子进程也会继承父进程的地址空间,所以子进程也能看到命令行参数和环境变量
四、为什么要有虚拟地址空间
- 有了虚拟地址就必须转换为物理地址。使用地址空间和页表进行映射,也一定要在OS的监管 之下来进行访问!!也顺便保护了物理内存中的所有的合法数据,包括各个进程以及内核的相关有效数据!(保护物理内存安全、维护进程独立性)
- 因为有地址空间的存在和页表的映射的存在,我们的物理内存中可以对未来的数据进行任意位置的加载 !在虚拟内存中都是按照区来保存的数据,代码就一定是在代码区,但是物理内存中代码数据都是在任意合法位置的,并不是按照代码放在一个区域,数据放在一个区域这样来加载的(进程看到自己的代码都是有序看待的,从"无序"变"有序")
- 创建一个进程时先创建内核数据结构,再加载进程的代码和数据(代码和数据可以全部加载到内存中,也可能是部分加载到内存中,也可能是使用的时候再加载进内存中)----惰性加载:提高内存使用率,这就是写时拷贝的原因(只有在修改的时候才进行,并不是创建出来就直接申请空间)
- 磁盘中代码和数据加载到内存中,就必须进行内存申请,物理内存的分配和进程的管理做到没有关系。进程管理模块和内存管理模块就完成了解耦合
- 因为有地址空间的存在,所以我们在C、C++上new,malloc空间的时候,其实是在地址空间上申请的,物理内存可以甚至一个字节都不给你。当你真正进行对物理地址空间访问的时候,才执行内存的相关管理算法,帮你申请内存,构建页表映射关系(延迟分配),这是由操作系统自动完成,用户包括进程完全0感知!!