1. 项目背景
随着信息技术的飞速发展,大数据技术在农业领域的应用日益广泛。农产品价格的波动直接关系到农民的收入和消费者的利益,甚至影响社会的稳定。传统的农产品价格监测手段往往滞后,难以应对瞬息万变的市场环境。
本项目旨在构建一个基于机器学习的农产品价格数据分析与预测系统。通过网络爬虫技术实时获取各大农产品交易平台的交易数据,利用Python强大的数据分析库(Pandas、Numpy)进行数据清洗与处理,并结合机器学习算法(Random Forest)构建价格预测模型。最终,通过Web可视化界面直观展示农产品价格走势、市场分布及预测结果,为政府决策、农民种植和消费者购买提供科学的数据支持。
演示视频及代码资料下载:https://www.bilibili.com/video/BV1KDzHBKEaH/

配套论文
配套PPT
2. 技术架构
本系统采用 B/S(Browser/Server) 架构,前后端分离开发模式,确保了系统的可扩展性和维护性。
- 开发语言:Python 3.x
- Web框架:Django 2.0
- 前端框架:Vue.js + Element UI
- 数据爬虫:Scrapy + Selenium (应对动态加载页面)
- 数据分析:Pandas, Numpy
- 机器学习:Scikit-learn (随机森林回归 RandomForestRegressor)
- 数据可视化:Matplotlib, Seaborn
- 数据库:MySQL
- 开发环境:Windows / Linux, PyCharm
3. 系统功能设计
系统主要包含以下几个核心模块:
- 数据采集模块:定时从"惠农网"等目标网站爬取农产品(蔬菜、水产等)的名称、价格、产地、销量、商家信息等数据。
- 数据预处理模块:对采集的数据进行去重、缺失值填充、异常值处理(如3σ原则)及格式转换。
- 数据分析与可视化模块 :
- 价格走势分析:展示不同农产品的历史价格变化。
- 产地分布分析:统计不同产区的农产品数量和价格差异。
- 特征重要性分析:分析影响价格的关键因素(如起批量、评价数等)。
- 价格预测模块:基于历史数据训练机器学习模型,对未来价格进行预测。
- 用户管理模块:包含用户注册、登录、收藏、评论等功能。
- 资讯模块:展示农业相关的新闻资讯。
4. 数据库设计
系统核心数据表设计如下(部分):
4.1 农产品信息表 (vegetableinfo)
这也是主数据表,存储爬取到的详细农产品信息。
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | BigInt | 主键 |
| title | Varchar | 商品标题 |
| jiage | Float | 价格 |
| shopname | Varchar | 商家名称 |
| supplyaddress | Varchar | 发货地 |
| donenum | Integer | 成交量 |
| pingjianum | Integer | 评价量 |
| ... | ... | ... |
4.2 价格预测表 (vegetableinfoforecast)
存储预测结果及相关数据。
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | BigInt | 主键 |
| title | Varchar | 标题 |
| jiage | Float | 预测价格/实际价格 |
| pingjianum | Integer | 评价数(特征) |
| ... | ... | ... |
4.3 惠农网原始数据表 (cnhnb)
用于存储爬虫抓取的原始数据缓存。
| 字段名 | 类型 | 说明 |
|---|---|---|
| url | Text | 商品链接 |
| origin | Varchar | 产地 |
| store | Varchar | 店铺名 |
| ... | ... | ... |
5. 核心代码实现
5.1 数据爬虫 (Scrapy)
使用Scrapy框架结合XPath提取数据,对于由于反爬虫无法直接获取的数据,结合了Selenium/DrissionPage进行模拟浏览器抓取。
# spider/Spider/spiders/CnhnbSpider.py (部分)
class CnhnbSpider(scrapy.Spider):
name = 'cnhnbSpider'
spiderUrl = 'https://www.cnhnb.com/p/cjsl/'
def parse(self, response):
list = response.xpath('''//div[@class='supply-list']''')
for item in list:
fields = CnhnbItem()
try:
fields["title"] = str(item.xpath('''.../img/@title''').extract()[0].strip())
fields["price"] = float(item.xpath('''.../span/text()''').extract()[0].strip())
# ... 其他字段提取
except:
pass
yield fields5.2 机器学习预测 (Random Forest)
使用 RandomForestRegressor 进行价格预测。首先对非数值型特征(如标题、商家名)进行 LabelEncoder 编码,然后划分训练集和测试集,最后进行模型训练和评估。
# main/Vegetableinfoforecast_v.py (核心逻辑)
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
def to_forecast(data, req_dict, value):
# 1. 特征编码
labels = {}
for key in data.keys():
if pd.api.types.is_string_dtype(data[key]):
label_encoder = LabelEncoder()
labels[key] = label_encoder
data[key] = label_encoder.fit_transform(data[key])
# 2. 特征选择 (X) 和 目标值 (y)
X = data[['title', 'shopname', 'supplyaddress', 'pingjianum']]
y = data[['jiage']]
# 3. 数据集划分
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=22)
# 4. 模型训练 (随机森林回归)
estimator = RandomForestRegressor(n_estimators=100, random_state=42)
estimator.fit(x_train, y_train.values.ravel())
# 5. 预测与评估 visualization
y_pred = estimator.predict(x_test)
# 绘制 实际值 vs 预测值 散点图
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, alpha=0.5)
plt.xlabel("实际值")
plt.ylabel("预测值")
plt.title("实际值与预测值(随机森林回归)")
plt.savefig(".../figure.png") # 保存图片供前端展示
return predicted_df5.3 数据清洗与异常值处理
在爬取数据后,利用Pandas进行清洗,例如去除重复行、填充空值,并使用 3σ原则 (Standard Deviation) 剔除异常价格数据,保证分析准确性。
# CnhnbSpider.py (pandas_filter方法)
def pandas_filter(self):
df = pd.read_sql('select * from cnhnb limit 50', con=engine)
# 去重与空值处理
df.drop_duplicates(inplace=True)
df.dropna(inplace=True)
df.fillna(value='暂无', inplace=True)
# 3σ原则过滤异常值
# 假设 df2 是数值型数据列
# cond = (df2 > 3 * df2.std()).any(axis=1)
# df2.drop(labels=df2[cond].index, axis=0, inplace=True)6 系统实现
6.1 系统前台功能实现
本系统前台功能模块设计以用户需求为导向,提供全面且便捷的服务。系统首页为用户提供农产品价格的总览,展示当前市场动态和关键指标。蔬菜信息模块和水产品信息模块分别提供相关农产品的详细价格走势、产地信息及市场供需情况。惠农网模块则整合惠农网数据,为用户呈现更广泛的市场信息。资讯新闻模块实时更新农业行业动态,帮助用户把握市场趋势。系统首页页面如图5-1所示:
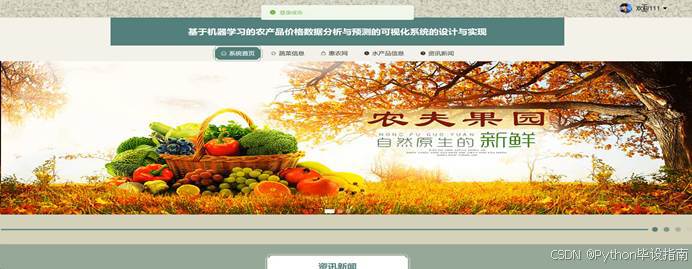
图5-1系统首页页面
个人中心模块包含个人资料管理、密码修改和我的收藏功能,用户可在此管理个人信息并收藏关注的农产品信息。个人中心页面如图5-2所示:
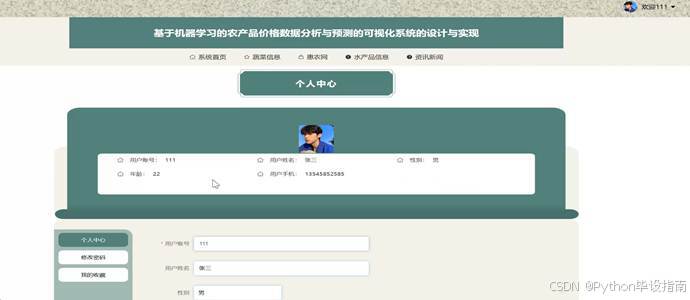
图5-2个人中心页面
6.2 管理员功能实现
管理员主页面作为系统控制中心,提供全面的管理功能。页面通常详细列出所有管理模块,包括系统首页、用户管理、蔬菜信息管理、惠农网管理、水产品信息管理、蔬菜价格预测管理、系统管理、个人中心等,确保管理员能够高效地进行日常管理工作。整个页面布局清晰,功能模块化,便于管理员快速定位和操作。管理员主页界面如图5-3所示:

图5-3 管理员主页界面
在蔬菜信息管理模块中,管理员可通过输入标题或商家名称快速查询相关蔬菜信息。系统支持添加新蔬菜信息,包括名称、价格、产地、上市时间等详细内容。管理员还可启动爬虫程序,自动从指定平台抓取最新数据并更新到系统中。管理员能够查看蔬菜的详细信息列表,对其中的记录进行修改或删除操作,确保信息的准确性和时效性;蔬菜信息管理如图5-4所示:
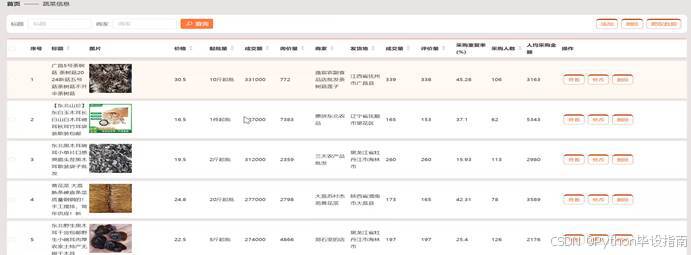
图5-4 蔬菜信息管理界面
在"惠农网管理"模块中,管理员可以通过输入商品标题、产地或商家名称进行精准查询,快速定位所需信息。系统支持添加新商品信息,包括价格、产地、商家等详细内容。管理员还可启动爬虫程序,自动从惠农网抓取最新数据并更新至系统。管理员能够查看商品的详细信息列表,并对其中的记录进行修改或删除操作,确保数据的准确性和时效性;惠农网管理如图5-5所示:
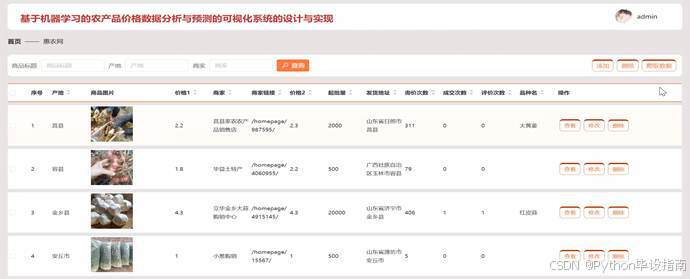
图5-5 惠农网管理界面
在水产品信息管理模块中,管理员可输入标题、分类或供应商名称进行精准查询,快速获取所需信息。系统支持添加新水产品信息,涵盖名称、分类、产地、供应商、价格及库存等详细内容。管理员还可通过爬虫功能,从指定数据源抓取最新水产品信息并自动更新至系统。管理员能够查看水产品详细信息列表,并对其中的记录进行修改或删除操作,确保信息的准确性和完整性,为用户提供可靠的水产品数据支持;水产品信息管理如图5-6所示:
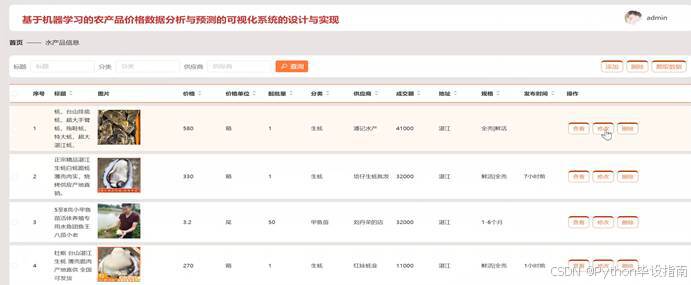
图5-6 水产品信息管理界面
在"蔬菜价格预测管理"模块中,管理员可输入标题或商家进行查询,快速定位相关蔬菜信息。支持添加新蔬菜信息,并通过爬虫技术从指定数据源抓取最新价格数据。系统利用机器学习算法(如ARIMA、LSTM等)对历史数据进行分析,生成预测图表。管理员可查看、修改或删除蔬菜价格预测的详细信息,确保数据的准确性和时效性;蔬菜价格预测管理如图5-7所示:
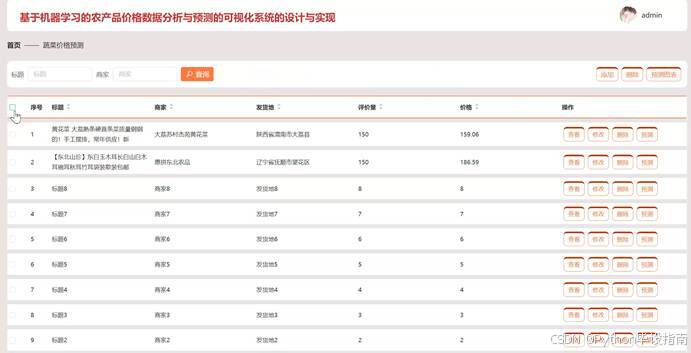
图5-7 蔬菜价格预测管理界面
看板作为系统的核心可视化模块,实时呈现多维度的市场数据统计信息。它包括商家成交量统计、品种成交次数统计和产地成交次数统计,直观展示市场活跃度和交易分布。显示蔬菜信息总数、惠农网总数和水产品信息总数,帮助用户快速掌握数据规模。价格统计模块实时更新各类农产品的价格走势,而水产品成交额统计则聚焦于水产品市场的交易金额,为用户和管理员提供全面、动态的市场洞察。看板界面如图5-8所示:
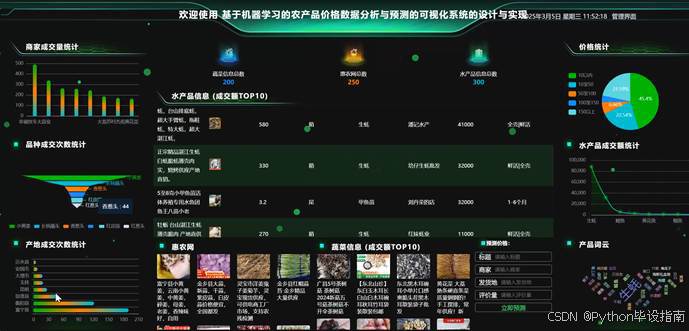
图5-8 看板界面
6.3 用户功能实现
用户主页简洁明了,包含"系统首页"和"个人中心"两大核心功能。系统首页为用户提供农产品价格动态、市场趋势等关键信息的实时展示,帮助用户快速把握市场情况。个人中心则提供个性化服务,用户可在此修改个人信息、密码,管理收藏内容,满足个性化需求。用户主页界面如图5-9所示:

图5-9 用户主页界面
7. 总结与展望
本项目成功实现了一个基于机器学习的农产品价格分析与预测系统。
- 优点 :
- 实现了全流程自动化:从爬虫抓取 -> 数据清洗 -> 存入数据库 -> 模型训练 -> 结果展示。
- 结合了随机森林算法,相比传统的线性回归,能更好地处理非线性关系,预测精度更高。
- 前后端分离架构,界面友好,交互流畅。
- 不足与改进 :
- 目前数据主要来源于单一平台(惠农网),未来可以扩展爬取更多平台数据,进行多源数据融合。
- 预测模型特征较少,未来可加入"季节"、"天气"、"物流成本"等更多维度特征,进一步提升预测准确率。
- 可视化图表目前主要以静态图片为主,未来可引入 ECharts 实现更丰富的动态交互图表。
演示视频及代码资料下载:https://www.bilibili.com/video/BV1KDzHBKEaH/****