目录
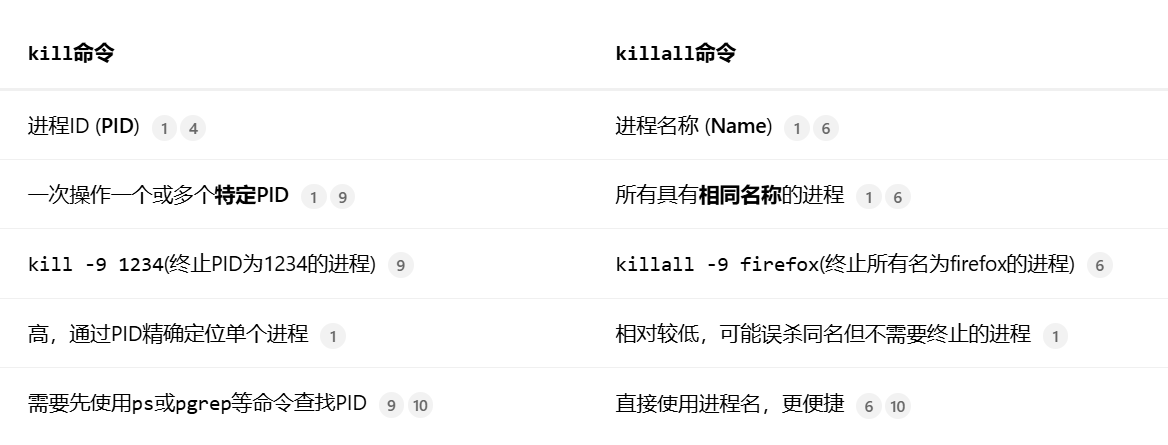
2.重新理解read、write、recv、send和tcp为什么支持全双工
[3.2.1. 使用 Json::Value 的 toStyledString 方法:](#3.2.1. 使用 Json::Value 的 toStyledString 方法:)
[3.2.3使用 Json::FastWriter&&Json::StyledWriter](#3.2.3使用 Json::FastWriter&&Json::StyledWriter)
[3.3.3使用 Json::CharReader的派生类](#3.3.3使用 Json::CharReader的派生类)
9.1什么是作业(job)和作业控制(JobControl)?
1.应用层
我们写的一个个解决我们实际问题,满足我们日常需求的网络程序,都是在应用层
1.1协议
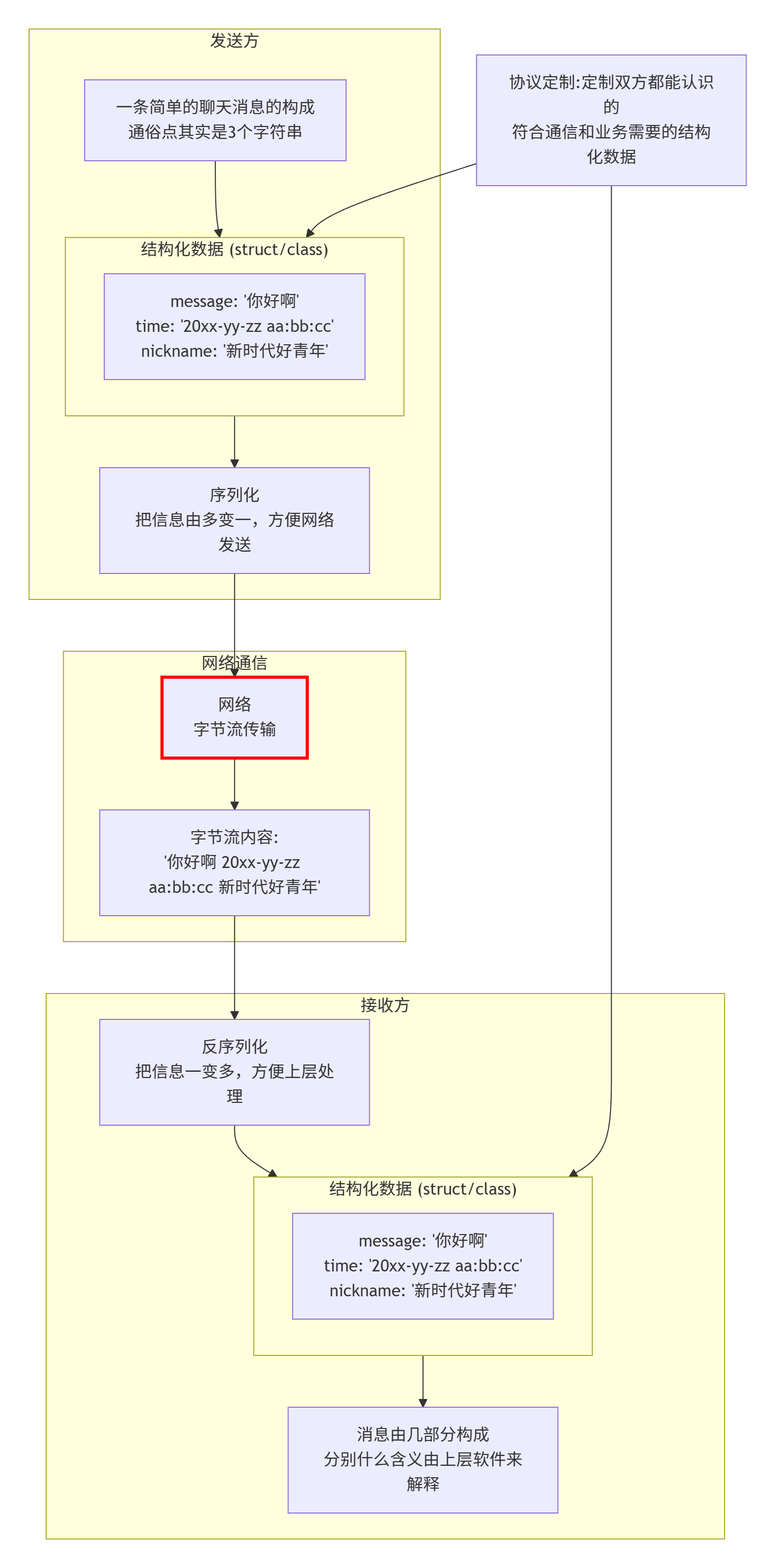
协议是一种"约定",socket api的接口,在读写数据时,都是按"字符串"的方式来发送接收的。如果我们要传输一些"结构化的数据"怎么办呢?
协议就是双方约定好的结构化的数据
1.2网络版计算器
例如,我们需要实现一个服务器版的加法器。我们需要客户端把要计算的两个加数发过去,然后由服务器进行计算,最后再把结果返回给客户端。
方案有好几种,其中一种就是:
客户端发送一个形如"1+2"的字符串;
这个字符串中有两个操作数,都是整形;
两个数字之间会有一个字符是运算符,运算符只能是+;
数字和运算符之间没有空格;
又或者:
定义结构体来表示我们需要交互的信息;
发送数据时将这个结构体按照一个规则转换成字符串,接收到数据的时候再按照相同的规则把字符串转化回结构体;
这个过程叫做"序列化"和"反序列化"
1.3序列化和反序列化
无论我们采用哪种方案,只要保证,一端发送时构造的数据,在另一端能够正
确的进行解析,就是ok的。这种约定,就是应用层协议
但是,为了让我们深刻理解协议,我们打算自定义实现一下协议的过程。
我们采用第二种方案,我们也要体现协议定制的细节
我们要引入序列化和反序列化,只不过我们会采用现成的方案--jsoncpp库
我们要对socket进行字节流的读取处理
2.重新理解read、write、recv、send和tcp为什么支持全双工
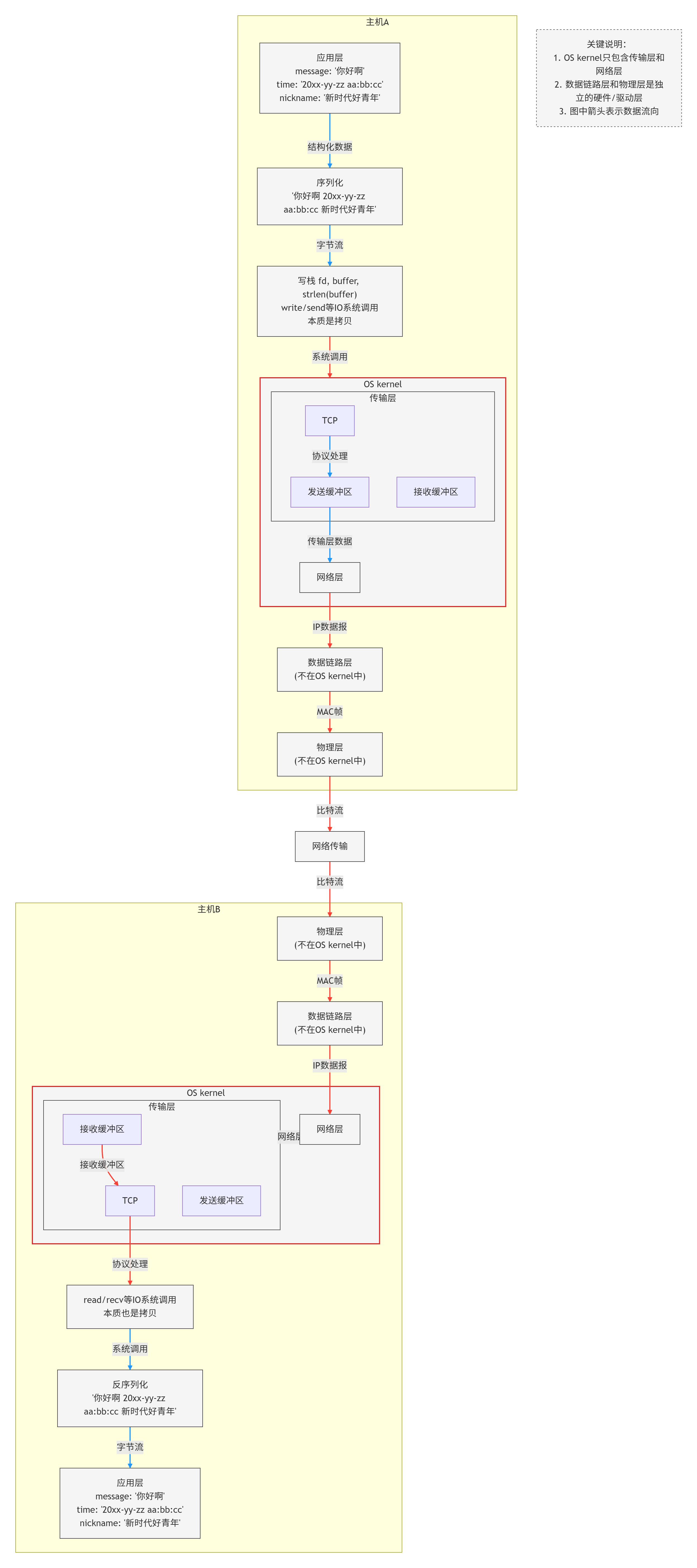
在任何一台主机上,TCP连接既有发送缓冲区,又有接受缓冲区,所以,在内核中,可以在发消息的同时,也可以收消息,即全双工。 注意,是一个连接就有一组缓冲区。
这就是为什么一个tcp,sockfd读写都是它的原因
实际数据什么时候发,发多少,出错了怎么办,由TCP控制,所以TCP叫做传输控制协议
因此实际上,网络通信是2个操作系统在通信。另外,为什么read和recv会阻塞?因为接收缓冲区内容为空。
但实际上,我们再以生产者消费者模型的视角 看待2个缓冲区,就会发现不管是发生还是接受缓冲区,都存在生产者和消费者,在不同缓冲区,身份是互换的,而所谓的阻塞,也就是用户进程阻塞,实质上在网络通信里就是用户层在进行同步,而同步就导致了需要等待数据就绪(发送缓区有空余或接受缓冲区有数据)。
tcp发送数据的本质,就是将自己的发送缓冲区拷贝到接收方的接受缓冲区。
因此,通信的本质就是拷贝。
最后,为什么说tcp发送的消息无法保证是一个完整的序列呢,因为实际上发送是由tcp自己控制的,我们应用层只能保证把序列写入发送缓冲区,对于tcp来说,他不认识什么序列,他只面向字节流,tcp只管发,和发错了怎么重发,不关心发送的内容是否完整。同样的,接收方从接收缓冲区取数据的时候,也不知道接受的数据是否完整,还需要应用层自己做额外的判断。
序列化和反序列化解决的是怎么发送和接受结构化数据,添加报头的形式解决的是接受结构化数据时的tcp粘报问题。
注意,udp不用担心粘报,完全是以数据报为单位发送和接受,不出现粘报。但也需要处理结构化数据,也就是要用序列化和反序列化。
3.序列化和反序列化Jsoncpp
3.1介绍
关于手写序列化和反序列化的内容,看后面,我们这里先介绍现成的方案。
Jsoncpp 是一个用于处理JSON 数据的 C++库。它提供了将JSON 数据序列化为字符串以及从字符串反序列化为C++数据结构的功能。Jsoncpp是开源的,广泛用于各种需要处理JSON 数据的C++项目中。
注意,这是第三方库,所以编译的时候要加-ljsoncpp
下面的介绍中,部分代码采用AI生成提供。不过我后面实际运用的时候会自己写的。
特性:
简单易用 :Jsoncpp 提供了直观的 API,使得处理JSON 数据变得简单。
高性能 :Jsoncpp 的性能经过优化,能够高效地处理大量JSON 数据。
全面支持 :支持JSON 标准中的所有数据类型,包括对象、数组、字符串、数字、布尔值和 null
错误处理 :在解析JSON数据时,Jsoncpp 提供了详细的错误信息和位置,方便开发者调试。
当使用Jsoncpp库进行JSON的序列化和反序列化时,确实存在不同的做法和工具类可供选择。
安装
ubuntu : sudo apt-get install libjsoncpp-dev
Centos: sudo yum install jsoncpp-devel
3.2序列化
序列化指的是将数据结构或对象转换为一种格式,以便在网络上传输或存储到文件中。
3.2.1. 使用 Json::Value 的 toStyledString 方法:
优点 :将Json::Value 对象直接转换为格式化的JSON字符串。
示例:
cpp#include <iostream> #include <string> #include <jsoncpp/json/json.h> int main() { Json::Value root; root["name"] = "joe"; root["sex"] = "男"; std::string s = root.toStyledString(); std::cout << s << std::endl; return 0; }结果:
cpp$ ./test.exe { "name" : "joe", "sex" : "男" }
3.2.2使用Json::Streamwriter
优点:提供了更多的定制选项,如缩进、换行符等。
示例:
cpp#include <iostream> #include <string> #include <sstream> #include <memory> #include <jsoncpp/json/json.h> int main() { Json::Value root; root["name"] = "joe"; root["sex"] = "男"; Json::StreamWriterBuilder wbuilder; // StreamWriter的工厂 std::unique_ptr<Json::StreamWriter> writer(wbuilder.newStreamWriter()); std::stringstream ss; writer->write(root, &ss); std::cout << ss.str() << std::endl; return 0; }结果为:
cpp$ ./test.exe { "name" : "joe", "sex" : "男" }
3.2.3使用 Json::FastWriter&&Json::StyledWriter
FastWriter:
优点 :比 StyledWriter 更快,因为它不添加额外的空格和换行符。
示例:
cpp#include <iostream> #include <string> #include <sstream> #include <memory> #include <jsoncpp/json/json.h> int main() { Json::Value root; root["name"] = "joe"; root["sex"] = "男"; Json::FastWriter writer; std::string s = writer.write(root); std::cout << s << std::endl; return 0; }结果:
cpp$ ./test.exe {"name":"joe","sex":"男"}StyledWriter:
cpp#include <iostream> #include <string> #include <sstream> #include <memory> #include <jsoncpp/json/json.h> int main() { Json::Value root; root["name"] = "joe"; root["sex"] = "男"; // Json::FastWriter writer; Json::StyledWriter writer; std::string s = writer.write(root); std::cout << s << std::endl; return 0; }结果:
cpp$ ./test.exe { "name" : "joe", "sex" : "男" }
3.3反序列化
反序列化指的是将序列化后的数据重新转换为原来的数据结构或对象。
3.3.1使用Json::Reader
优点 :提供详细的错误信息和位置,方便调试。
示例:
cpp#include <iostream> #include <string> #include <jsoncpp/json/json.h> int main() { // JSON 字符串,自己试的时候,完全可以先写入到文件,再读取回来就行了。 std::string json_string = "{\"name\":\"张三\",\"age\":30,\"city\":\"北京\"}"; // 解析 JSON 字符串 Json::Reader reader; Json::Value root; // 从字符串中读取 JSON 数据 bool parsingSuccessful = reader.parse(json_string, root); if (!parsingSuccessful) { // 解析失败,输出错误信息 std::cout << "Failed to parse JSON: " <<reader.getFormattedErrorMessages() << std::endl; return 1; } // 访问 JSON 数据 std::string name = root["name"].asString(); int age = root["age"].asInt(); std::string city = root["city"].asString(); // 输出结果 std::cout << "Name: " << name << std::endl; std::cout << "Age: " << age << std::endl; std::cout << "City: " << city << std::endl; return 0; }
3.3.2使用Json::parseFromStream
Json::parseFromStream是现代更推荐的流式解析方式
cpp#include <iostream> #include <string> #include <sstream> #include <jsoncpp/json/json.h> // 包含必要的头文件 int main() { // JSON 字符串,自己试的时候,完全可以先写入到文件,再读取回来就行了。 std::string json_string = "{\"name\":\"张三\",\"age\":30,\"city\":\"北京\"}"; // 解析 JSON 字符串 Json::Value root; std::stringstream ss(json_string); // 将字符串转换为字符串流 Json::CharReaderBuilder readerBuilder; // 创建CharReaderBuilder对象 std::string errors; // 用于存储错误信息 // 使用 parseFromStream 从流中读取并解析 JSON 数据 bool parsingSuccessful = Json::parseFromStream(readerBuilder, ss, &root, &errors); if (!parsingSuccessful) { // 解析失败,输出错误信息 std::cout << "Failed to parse JSON: " << errors << std::endl; return 1; } // 访问 JSON 数据 // 良好的实践:在访问前检查键是否存在[3](@ref) std::string name = root.isMember("name") ? root["name"].asString() : "Unknown"; int age = root.isMember("age") ? root["age"].asInt() : 0; std::string city = root.isMember("city") ? root["city"].asString() : "Unknown"; // 输出结果 std::cout << "Name: " << name << std::endl; std::cout << "Age: " << age << std::endl; std::cout << "City: " << city << std::endl; return 0; }
3.3.3使用 Json::CharReader的派生类
(不推荐了,上面的足够了)
在某些情况下,你可能需要更精细地控制解析过程,可以直接使用Json::CharReader 的派生类。
但通常情况下,使用 Json::parseFromStream 或 Json::Reader 的 parse 方法就足
够了。
3.4总结
toStyledString、 StreamWriter 和 FastWriter 提供了不同的序列化选项,可以根据具体需求选择使用。
Json::Reader和parseFromStream函数是Jsoncpp中主要的反序列化工具,它们提供了强大的错误处理机制。
在进行序列化和反序列化时,请确保处理所有可能的错误情况,并验证输入和输出的有效性。
3.5Json::Value
Json::Value是Jsoncpp库中的一个重要类,用于表示和操作JSON数据结构。
支持嵌套,比如root"self"=root
3.5.1构造函数
Json::Value() :默认构造函数,创建一个空的Json::Value 对象。
Json::Value(ValueType type, bool allocated = false):根据给定的ValueType(如 nullValue,intValue,stringValue 等)创建一个Json::Value 对象。
3.5.2访问元素
Json::Value& operator\[\](const char* key) :通过键(字符串)访问对象中的元素。如果键不存在,则创建一个新的元素。
Json::Value& operator\[\](const std::string& key) :同上, 但使用std::string 类型的键。
Json::Value& operator\[\](ArrayIndex index) :通过索引访问数组中的元素。 如果索引超出范围,则创建一个新的元素。
Json::Value& at(const char* key) :通过键访问对象中的元素,如果键不存在则抛出异常。
Json::Value& at(const std::string& key):同上,但使用 std::string 类型的键。
3.5.3类型检查
bool isNull() : 检查值是否为null。
bool isBool() : 检查值是否为布尔类型。
bool isInt() : 检查值是否为整数类型。
bool isInt64() : 检查值是否为64位整数类型。
bool isUInt() : 检查值是否为无符号整数类型。
bool isUInt64() : 检查值是否为64位无符号整数类型。
bool isIntegral() : 检查值是否为整数或可转换为整数的浮点数。
bool isDouble() : 检查值是否为双精度浮点数。
bool isNumeric() : 检查值是否为数字(整数或浮点数)。
bool isString() : 检查值是否为字符串。
bool isArray() : 检查值是否为数组。
bool isObject(): 检查值是否为对象(即键值对的集合)。
3.5.4赋值和类型转换
Json::Value& operator=(bool value) :将布尔值赋给 Json::Value 对象。
Json::Value& operator=(int value) :将整数赋给 Json::Value 对象。
Json::Value& operator=(unsigned int value) :将无符号整数赋给 Json::Value 对象。
Json::Value& operator=(Int64 value) :将64位整数赋给 Json::Value 对象。
Json::Value& operator=(UInt64 value) :将64位无符号整数赋给 Json::Value 对象。
Json::Value& operator=(double value) : 将双精度浮点数赋给 Json::Value 对象。
Json::Value& operator=(const char* value) :将C字符串赋给 Json::Value 对象。
Json::Value& operator=(const std::string& value) :将 std::string 赋给 Json::Value 对象。bool asBool() :将值转换为布尔类型(如果可能)。
int asInt() :将值转换为整数类型(如果可能)。
Int64 asInt64() :将值转换为64位整数类型(如果可能)。
unsigned int asUInt() :将值转换为无符号整数类型(如果可能)。
UInt64 asUInt64() :将值转换为64位无符号整数类型(如果可能)。
double asDouble() :将值转换为双精度浮点数类型(如果可能)。
std::string asString() :将值转换为字符串类型(如果可能)。
3.5.5数组和对象操作
size_t size() :返回数组或对象中的元素数量。
bool empty() :检查数组或对象是否为空。
void resize(ArrayIndex newSize): 调整数组的大小。
void clear(): 删除数组或对象中的所有元素。
void append(const Json::Value& value) :在数组末尾添加一个新元素。
Json::Value& operator\[\](const char* key, const Json::Value& defaultValue = Json::nullValue): 在对象中插入或访问一个元素,如果键不存在则使用默认值。
Json::Value& operator\[\](const std::string& key, const Json::Value& defaultValue = Json::nullValue): 同上,但使用 std::string 类型的键。
4.实现计算器
我就不浪费字数在这里详细说代码怎么写了(实在是太冗长了,直接断绝了我解释的欲望),我都放在gitee里,一些代码处我也写了注释,看不懂可以AI下。
我这里说下大概做了什么,首先我们对socket进行了封装(采用模板设计模式),将套接字与server端解耦合,然后把业务逻辑的部分也解耦合,然后写了自定义协议(即上面说的第二个方案)。
通过我的代码,其实也能够发现,为什么osi定义了7层模型,但实际上我们都是tcp/ip五层模型。
cppCalculate cal; Service calservice(std::bind(&Calculate::Excute, &cal, std::placeholders::_1)); std::unique_ptr<TcpServer> tsvr = std::make_unique<TcpServer> (port, std::bind(&Service::ServiceHelper, &calservice, std::placeholders::_1, std::placeholders::_2));会话层的功能其实就是我这里定义的TcpServer负责的,表示层则是由calService负责,Calculate负责的是应用层。
5.手写序列化和反序列化
关于切换手写和现成的json。有2种方案,一个是在makefile里定义宏变量。具体可参考我的代码。
另一个就是在程序代码里加入直接加入宏定义。
6.进程组
6.1什么是进程组
之前我们提到了进程的概念,每一个进程除了有一个进程ID(PID)之外还属于一个进程组。进程组是一个或者多个进程的集合,一个进程组可以包含多个进程。每一个进程组也有一个唯一的进程组ID(PGID),并且这个PGID类似于进程ID,同样是一个正整数,可以存放在pid_t数据类型中。
-e选项表示every的意思,表示输出每一个进程信息
-0选项以逗号操作符(,)作为定界符,可以指定要输出的列

6.2组长进程
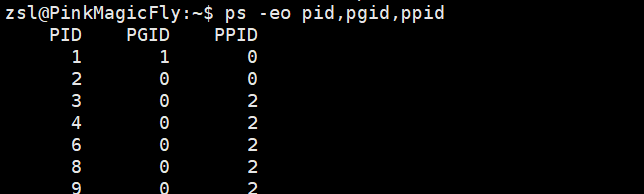
每一个进程组都有一个组长进程。组长进程的ID等于其进程ID。我们可以通过ps命令看到组长进程的现象:
从结果上看ps进程的PID和PGID相同,那也就是说明ps进程是该进程组的组长进程,该进程组包括ps和cat两个进程。
进程组组长的作用 :进程组组长可以创建一个进程组或者创建该组中的进程
进程组的生命周期:从进程组创建开始到其中最后一个进程离开为止。注意:只要该进程组中有一个进程存在,则该进程组就存在,这与其组长进程是否已经终止无关。
另外,我们写多进程的时候需要用到fork创建子进程,这时候父进程和所有子进程都在一个进程组里,且进程组组长就是父进程。

7.会话
7.1什么是会话
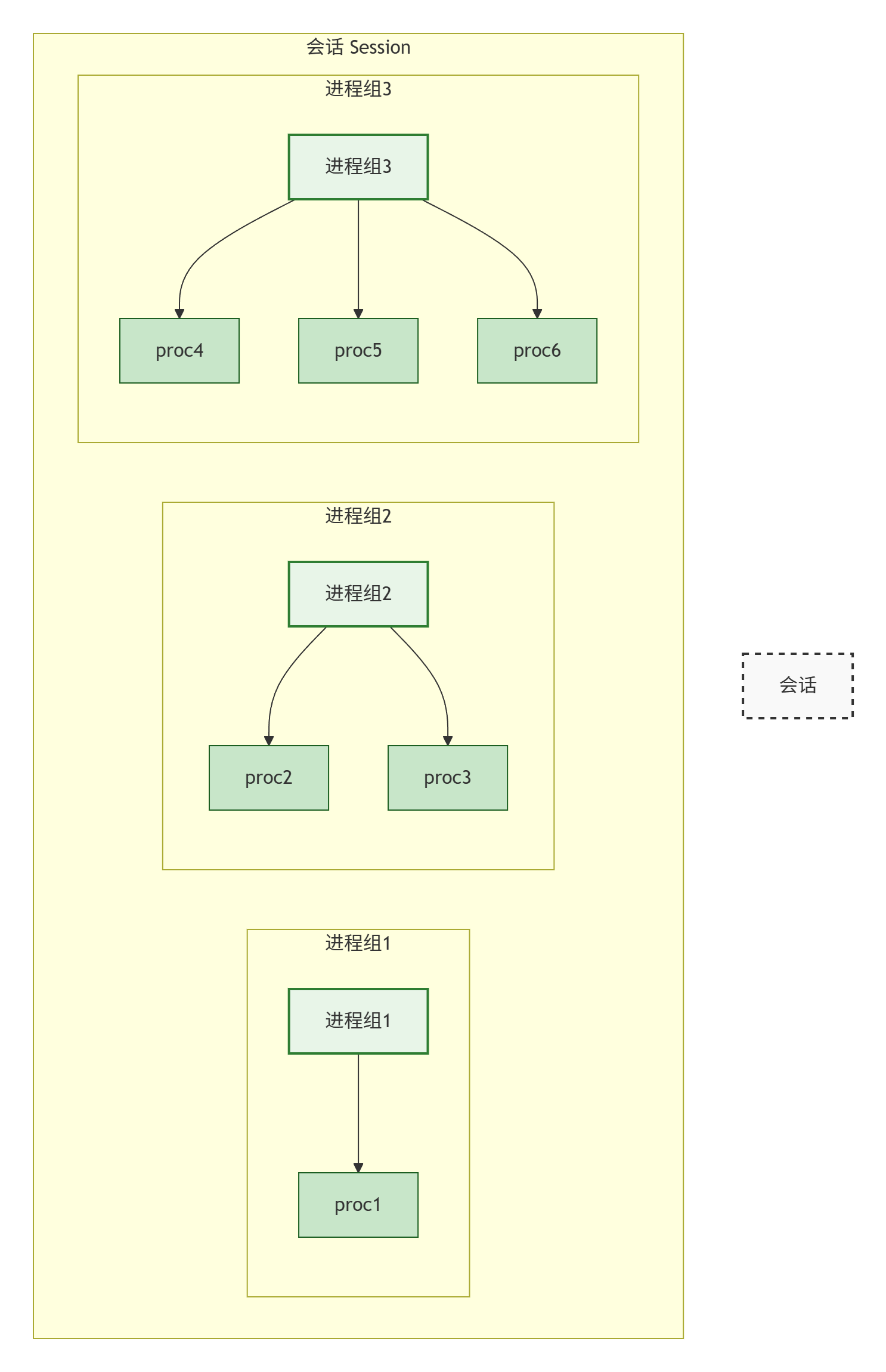
刚刚我们谈到了进程组的概念,那么会话又是什么呢?会话其实和进程组息息相关,会话可以看成是一个或多个进程组的集合,一个会话可以包含多个进程组。每一个会话也有一个会话ID(SID)
通常我们都是使用管道将几个进程编成一个进程组。如上图的进程组2和进程组3可能是由下列命令形成的:
bashproc2丨proc3 & proc4 | proc5丨proc6 & &表示将进程组放在后台执行从上述结果来看3个进程对应的PGID相同,即属于同一个进程组。

7.2如何创建会话
可以调用setseid函数来创建一个会话,前提是调用进程不能是一个进程组的组长。
cpp#include <unistd.h> 功能:创建会话 返回值:创建成功返回SID,失败返回-1 pid_t setsid(void);调用进程会变成新会话的会话首进程。此时,新会话中只有唯一的一个进程
调用进程会变成进程组组长。新进程组ID就是当前调用进程ID
该进程没有控制终端。如果在调用setsid之前该进程存在控制终端,则调用之后会切断联系
注意:这个接口如果调用进程原来是进程组组长,则会报错,为了避免这种情况,我们通
常的使用方法是先调用fork创建子进程,父进程终止,子进程继续执行,因为子进程会继承父进程的进程组ID,而进程ID则是新分配的,就不会出现错误的情况。
当我们用ssh登录到了linux上后,会被分配一个终端文件,这个终端文件会被绑定一个bash进程(进程组),注意,linux系统默认就有一个bash进程,当用户登录后,会分配一个-bash进程给用户的终端文件,分配和绑定的过程就是构建了一个会话。
pkill -9 bash可以强行终止所有终端(记得保存工作)
另外,这个TTY表示的pts/0说明了这个进程是被"330228会话中打开了终端文件pts/0的-bash进程(我这里是直接命令行管道,所以一定是bash)"创建的。
这也是为什么当前终端启动的进程,输入输出默认都是在当前终端,因为bash打开了终端文件,而当前终端启动的进程,最上面都是-bash进程,一定继承了文件描述符表。
新启动的任何任务,在新启动的时候,一定是默认属于该会话的。
7.3会话ID(SID)
会话ID是什么呢?我们可以先说一下会话首进程,会话首进程是具有唯一进程ID的单个进程,那么我们可以将会话首进程的进程ID当做是会话ID。注意:会话ID在有些地方
也被称为会话首进程的进程组ID,因为会话首进程总是一个进程组的组长进程,所以两者是等价的。
另外,因为bash基本就是第一个进程组,所以会话首进程基本都是bash
8.控制终端
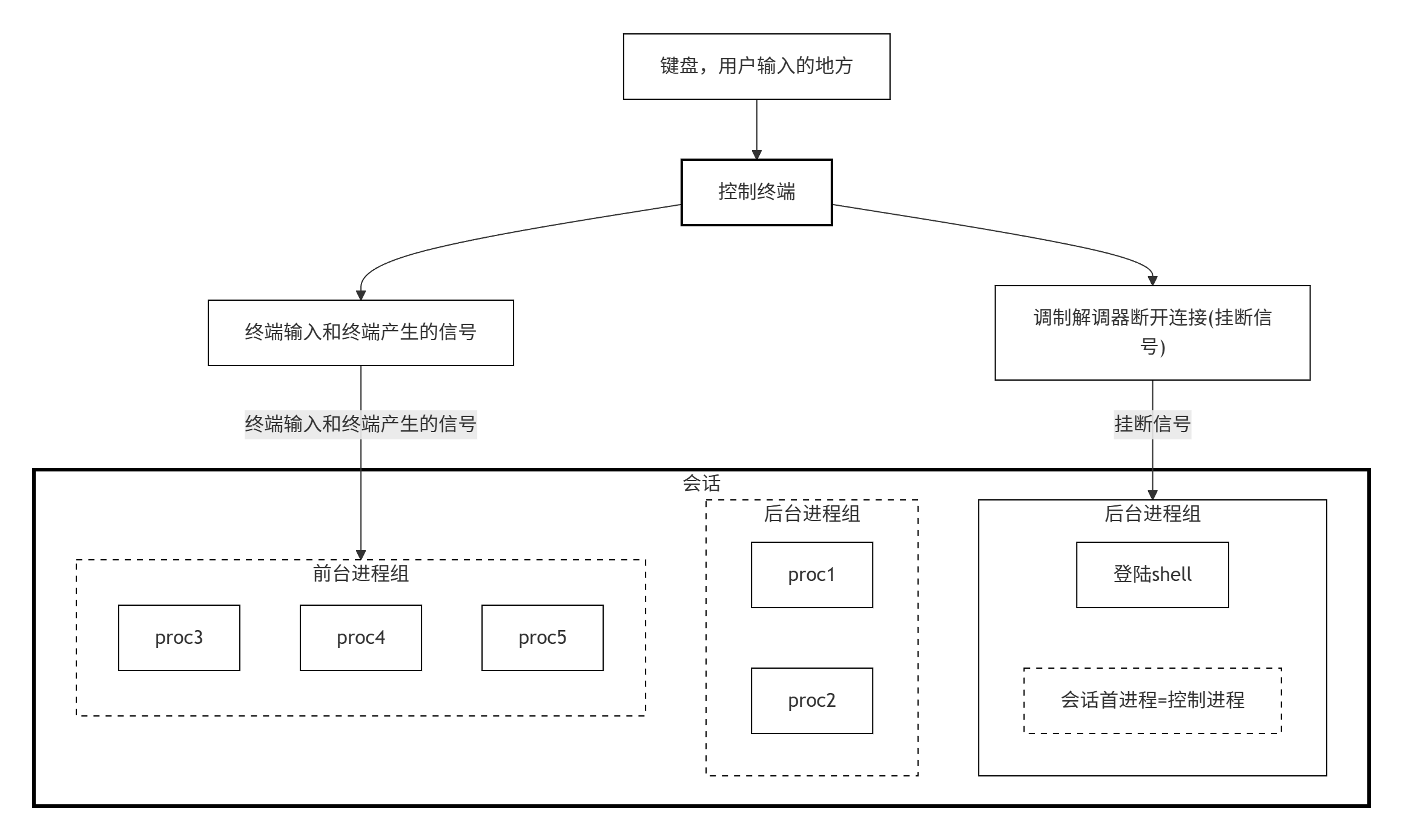
在UNIX系统中,用户通过终端登录系统后得到一个Shell进程,这个终端成为Shell进程的控制终端。控制终端是保存在PCB中的信息,我们知道fork进程会复制PCB中的信息,因此由Shell进程启动的其它进程的控制终端也是这个终端。默认情况下没有重定向,每个进程的标准输入、标准输出和标准错误都指向控制终端,进程从标准输入读也就是读用户的键盘输入,进程往标准输出或标准错误输出写也就是输出到显示器上。另外会话、进程组以及控制终端还有一些其他的关系.
一个会话可以有一个控制终端,通常会话首进程打开一个终端(终端设备或伪终端设备)后,该终端就成为该会话的控制终端。
建立与控制终端连接的会话首进程被称为控制进程。
一个会话中的几个进程组可被分成一个前台进程组以及一个或者多个后台进程组。
如果一个会话有一个控制终端,则它有一个前台进程组,会话中的其他进程组则为后台进程组。
无论何时进入终端的中断键(ctrl+c)或退出键(ctrl+\),就会将中断信号发送给前台进程组的所有进程。
如果终端接口检测到调制解调器(或网络)已经断开,则将挂断信号发送给控制进程(会话首进程)。
9.作业控制
9.1什么是作业(job)和作业控制(JobControl)?
作业是针对用户来讲,用户完成某项任务而启动的进程,一个作业既可以只包含一个进程,也可以包含多个进程,进程之间互相协作完成任务,通常是一个进程管道。
Shell分前后台来控制的不是进程而是作业或者进程组。一个前台作业可以由多个进程组成,一个后台作业也可以由多个进程组成,Shel可以同时运行一个前台作业和任意多个后台作业,这称为作业控制。
下列命令就是一个作业,它包括两个命令,在执行时Shell将在前台启动由两个进程组成的作业
bashcat ./test.txt | head -10以下来自AI

9.2作业号
放在后台执行的程序或命令称为后台命令,可以在命令的后面加上&符号从而让Shell识别这是一个后台命令,后台命令不用等待该命令执行完成,就可立即接收新的命令,另外后台进程执行完后会返回一个作业号以及一个进程号(PID)。
例如下面的命令在后台启动了一个作业,该作业由两个进程组成,两个进程都在后台运行:
第一行表示作业号和进程ID,可以看到作业号是1,进程ID是330690
到最后一个空行前表示该程序运行的结果。
最后一行分别表示作业号、默认作业、作业状态以及所执行的命令,注意想要出现,要先按下回车。
关于默认作业:对于一个用户来说,只能有一个默认作业 (+),同时也只能有一个即将成为默认作业的作业(-),当默认作业退出后,该作业会成为默认作业。
(+)表示该作业号是默认作业
(-)表示该作业即将成为默认作业
无符号:表示其他作业
9.3作业状态
作业状态 含义 正在运行【Running】 后台作业(&),表示正在执行 完成【Done】 作业已完成,返回的状态码为0 完成并退出【Done(code)】 作业已完成并退出,返回的状态码为非0 已停止【Stopped】 前台作业,当前被Ctrl+Z挂起 已终止【Terminated】 作业被终止
9.4作业的挂起与切回
9.4.1作业挂起
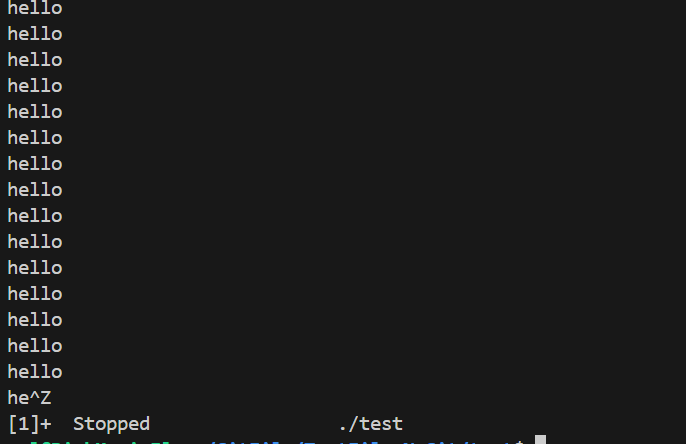
我们在执行某个作业时,可以通过Ctrl+Z键将该作业挂起,然后Shell会显示相关的作业号、状态以及所执行的命令信息。
可以发现通过Ctrl+Z 将作业挂起,该作业状态已经变为了停止状态
9.4.2作业切回
如果想将挂起的作业切回,可以通过 fg 命令,fg 后面可以跟 作业号 或 作业的命令名称。如果参数缺省则会默认将作业号为1的作业切到前台来执行,若当前系统只有一个作业在后台进行,则可以直接使用fg命令不带参数直接切回。具体的参数参考如下:
参数 含义 %n n为正整数,表示作业号 %string 以字符串开头的命令所对应的作业 %?string 包含字符串的命令所对应的作业 %+或%% 最近提交的一个作业 %- 倒数第二个提交的作业 注意:当通过fg命令切回作业时,若没有指定作业参数,此时会将默认作业切到前台执行,即带有"+"的作业号的作业
注意,在后台处于暂停状态的作业,我们可以输入bg 作业号,让它在后台继续运行。
9.4.3查看后台执行或挂起的作业
我们可以直接通过输入jobs命令查看本用户当前后台执行或挂起的作业
参数-l则显示作业的详细信息
参数-p则只显示作业的PID

9.4.4作业控制相关的信号
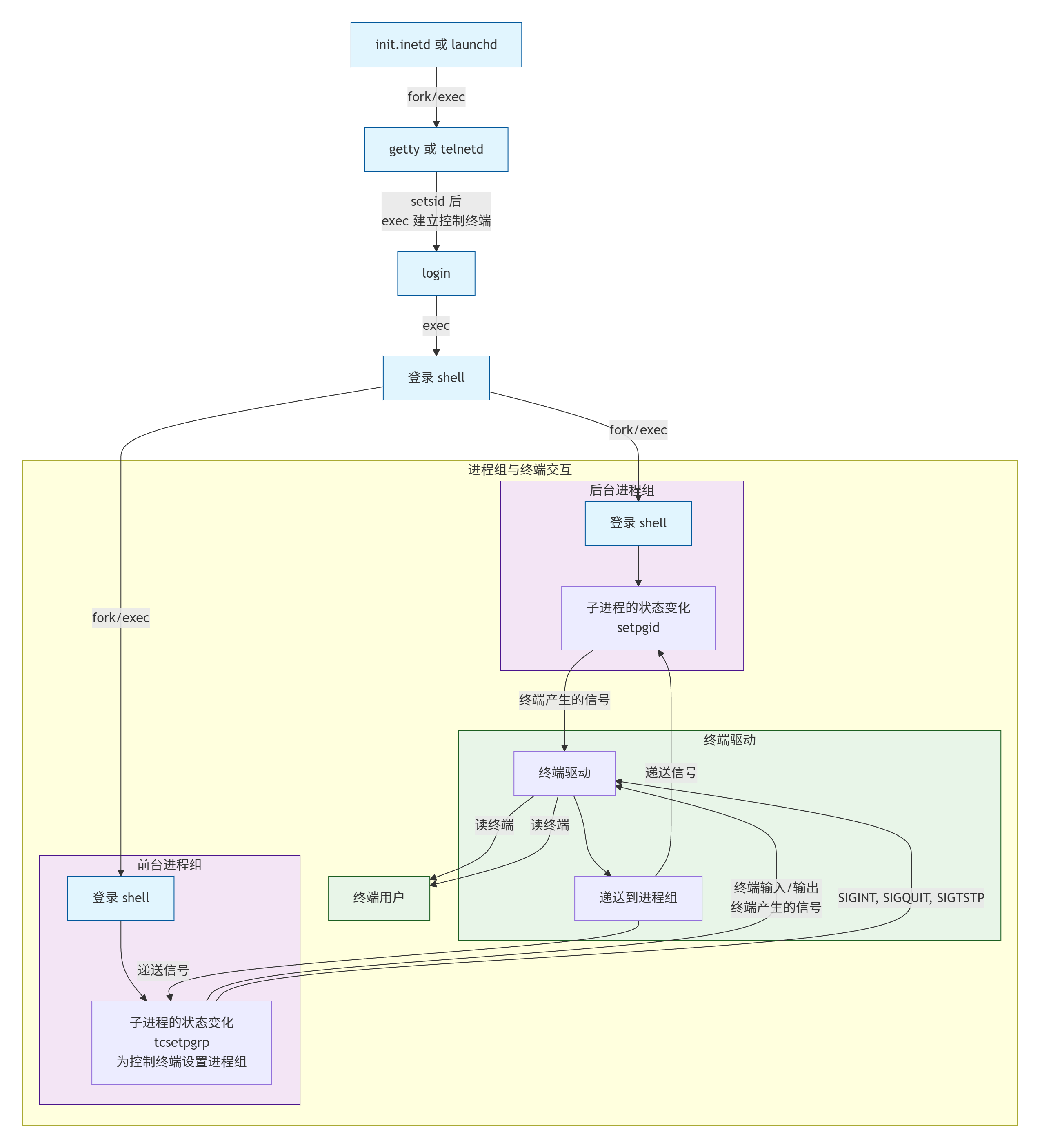
上面我们提到了键入Ctrl+Z可以将前台作业挂起,实际上是将STGTSTP信号发送至前台进程组作业中的所有进程,后台进程组中的作业不受影响。在unix系统中,存在3个特殊字符可以使得终端驱动程序产生信号,并将信号发送至前台进程组作业,它们分别是:
Ctrl+C:中断字符,会产生 SIGINT 信号
Ctrl+\:退出字符,会产生SIGQUIT 信号
Ctrl+Z:挂起字符,会产生 STGTSTP信号
终端的I/O(即标准输入和标准输出)和终端产生的信号总是从前台进程组作业连接打破实际终端。
10.守护进程
什么是守护进程,我们知道一个会话里有多个进程组,包括前台、后台。而一旦我们用户把终端关掉了,意味着会话结束了,这时候,这些进程很多都会自动结束,也有些不会结束,但是肯定会受到一些影响。
为了防止因为会话关闭而影响进程,我们就有了守护进程。把进程组放入另外一个不是由用户登录所创建的会话中,这样用户就算关闭了终端,也不会影响这些进程,这些进程就是守护进程。
做法有很多。这里仅供参考。
bashnohup ./tcpserver 8888 1>/dev/null 2>/dev/null & 这个是类似让进程以类似守护进程的方式进行,但是不完全是守护进程。这时候子进程既是守护进程,也是孤儿进程,因为守护进程是孤儿进程的一种特殊情况。
cpp#pragma once #include<iostream> #include<cstdlib> #include<signal.h> #include<unistd.h> #include<fcntl.h> #include<sys/types.h> #include<sys/stat.h> const char* root="/"; const char* dev_null="/dev/null"; void Daemon(bool ischdir,bool isclose){ // 1.忽略可能引起程序异常退出的信号 signal(SIGCHLD,SIG_IGN); signal(SIGPIPE,SIG_IGN); // 2.让自己不要成为组长 if(fork()>0) exit(0); // 3.设置让自己成为一个新的会话,后面的代码其实是子进程在走 setsid(); // 4.每一个进程都有自己的CWD,是否将当前进程的CWD更改成为/根目录 if(ischdir) chdir(root); // 5.已经变成守护进程,不需要和用户的输入输出,错误进行关联了, //而且对应的会话很可能已经关闭了,几乎会失败 if(isclose) { close(0); close(1); close(2); } else { //这里一般建议就用这种,/dev/null是linux基本都会提供的一个文件, //其特点是输入进去的内容都会被系统丢弃,从这个文件读也读不到任何内容。 int fd=open(dev_null,O_RDWR); if(fd>0) { dup2(fd,0); dup2(fd,1); dup2(fd,2); close(fd); } } }
11.如何将服务守护进程化
cpp#include"Daemon.hpp" int main() { //...... Daemon(false,false); while(1) { sleep(1); //模拟在服务进行任务 } return 0; }另外,关闭守护进程的时候,建议用killall ,以下为AI。