目录
[1 SPPNet](#1 SPPNet)
[1.1 SPPNet](#1.1 SPPNet)
[1.2 映射](#1.2 映射)
[1.3 SPP层](#1.3 SPP层)
[1.4 SPPNet总结](#1.4 SPPNet总结)
[1.5 问题](#1.5 问题)
[2 Fast R-CNN](#2 Fast R-CNN)
[2.1. RoI pooling](#2.1. RoI pooling)
[2.2. End-to-End model](#2.2. End-to-End model)
[2.3 多任务损失-Multi-task loss](#2.3 多任务损失-Multi-task loss)
[2.4 R-CNN、SPPNet、Fast R-CNN效果对比](#2.4 R-CNN、SPPNet、Fast R-CNN效果对比)
[2.5 Fast R-CNN总结](#2.5 Fast R-CNN总结)
[2.6 问题](#2.6 问题)
[3 Faster R-CNN](#3 Faster R-CNN)
[3.1 Faster R-CNN](#3.1 Faster R-CNN)
[3.2 RPN原理](#3.2 RPN原理)
[3.3 候选区域的训练](#3.3 候选区域的训练)
[3.4 Faster R-CNN的训练](#3.4 Faster R-CNN的训练)
[3.5 效果对比](#3.5 效果对比)
[3.6 Faster R-CNN总结](#3.6 Faster R-CNN总结)
[3.7 问题](#3.7 问题)
1 SPPNet
R-CNN的速度慢在哪?
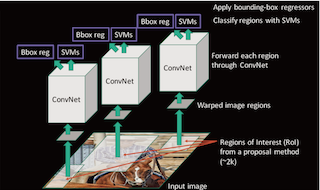
每个候选区域都进行了卷积操作提取特征。
1.1 SPPNet
SPPNet主要存在两点改进地方,提出了SPP层
- 减少卷积计算
- 防止图片内容变形
| R-CNN模型 | SPPNet模型 |
|---|---|
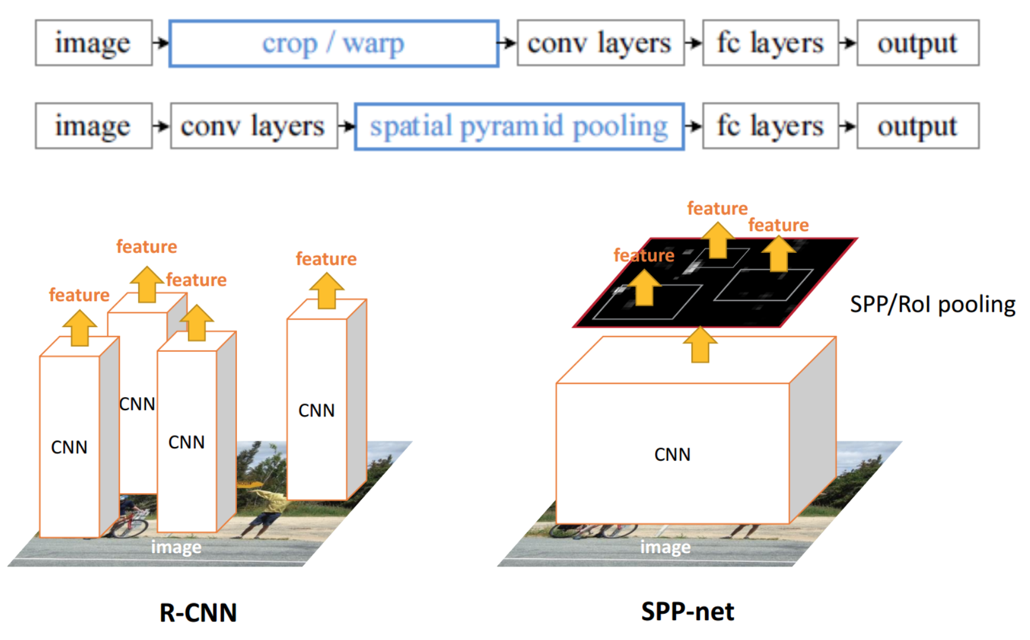
| 1. R-CNN是让每个候选区域经过crop/wrap等操作变换成固定大小的图像 2. 固定大小的图像塞给CNN 传给后面的层做训练回归分类操作 | 1. SPPNet把全图塞给CNN得到全图的feature map 2. 让候选区域与feature map直接映射,得到候选区域的映射特征向量 3. 映射过来的特征向量大小不固定,这些特征向量塞给SPP层(空间金字塔变换层),SPP层接收任何大小的输入,输出固定大小的特征向量,再塞给FC层 |
1.2 映射
原始图片经过CNN变成了feature map,原始图片通过选择性搜索(SS)得到了候选区域,现在需要将基于原始图片的候选区域映射到feature map中的特征向量。映射过程图参考如下:
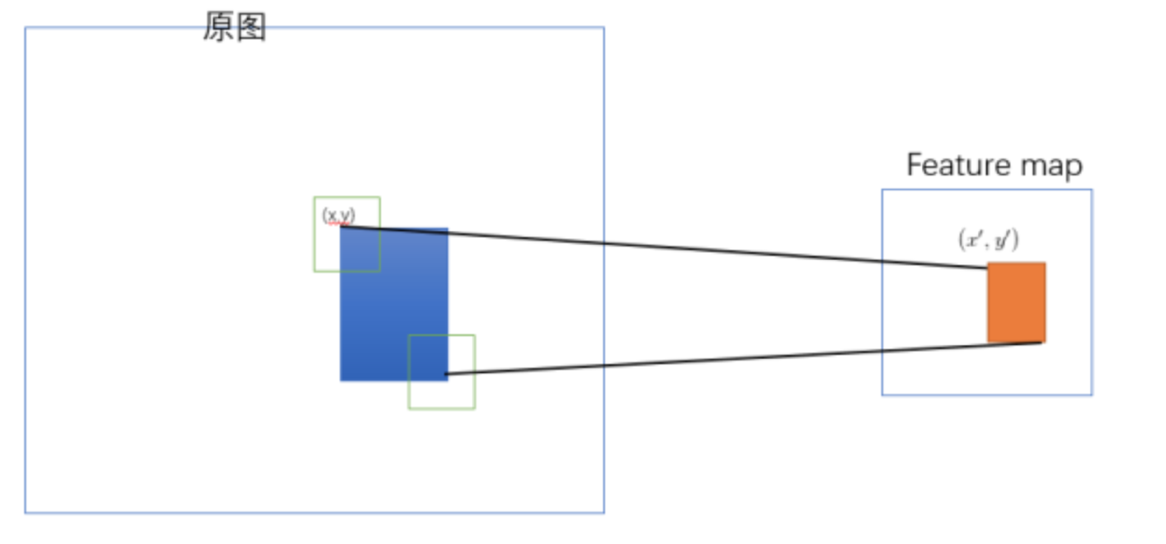
整个映射过程有具体的公式,如下
假设(x′,y′)(x′,y′)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关心与网络结构有关:(x,y)=(S∗x′,S∗y′),即
-
左上角的点:
- x′=x/S+1
-
右下角的点:
- x′=x/S−1
其中 SS 就是CNN中所有的strides的乘积,包含了池化、卷积的stride。论文中使用S的计算出来为=16
拓展:如果关注这个公式怎么计算出来,请参考:http://kaiminghe.com/iccv15tutorial/iccv2015_tutorial_convolutional_feature_maps_kaiminghe.pdf
1.3 SPP层
spatial pyramid pooling:空间金字塔池化
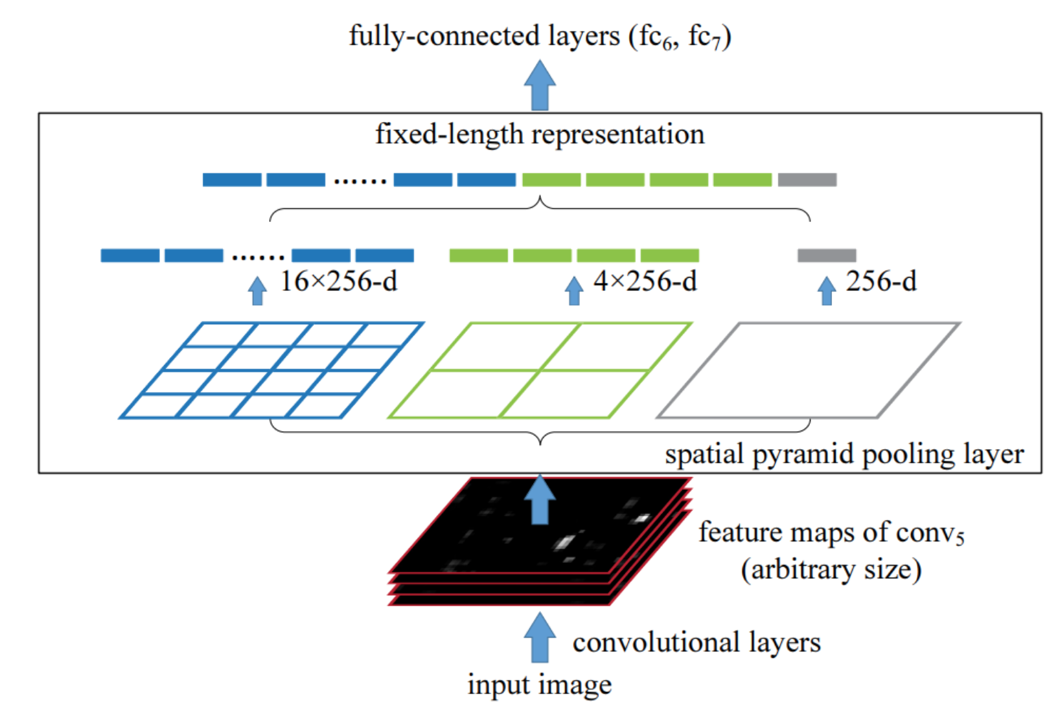
通过spatial pyramid pooling 将任意大小的特征图转换成固定大小的特征向量
示例:假设原图输入是224x224,对于conv出来后的输出是13x13x256的,可以理解成有256个这样的Filter,每个Filter对应一张13x13的feature map。接着在这个特征图中找到每一个候选区域映射的区域,spp layer会将每一个候选区域分成1x1,2x2,4x4三张子图,对每个子图的每个区域作max pooling,得出的特征再连接到一起,就是(16+4+1)x256的特征向量,接着给全连接层做进一步处理,如下图:
1.4 SPPNet总结
来看下SPPNet的完整结构
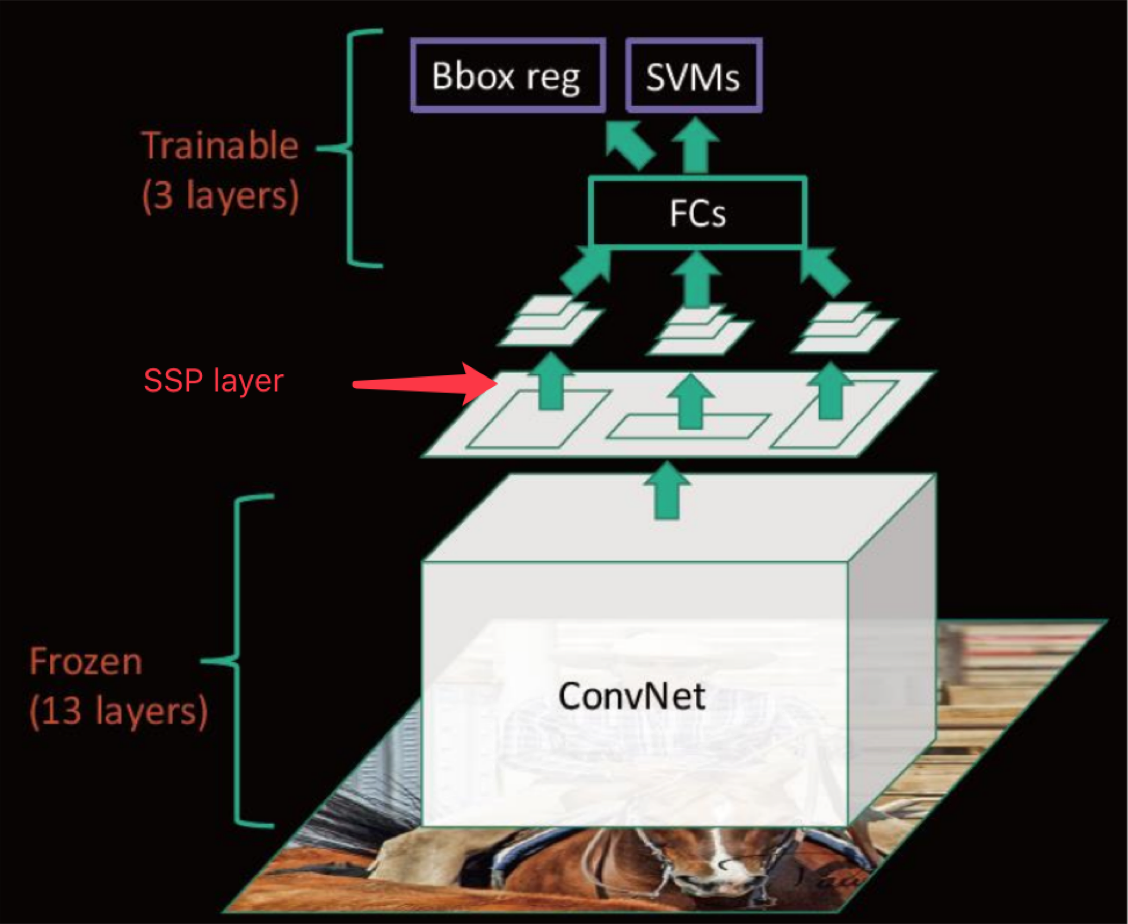
- 优点
- SPPNet在R-CNN的基础上提出了改进,通过候选区域和feature map的映射,配合SPP层的使用,从而达到了CNN层的共享计算,减少了运算时间, 后面的Fast R-CNN等也是受SPPNet的启发
- 缺点
- 训练依然过慢、效率低,特征需要写入磁盘(因为SVM的存在)
- 分阶段训练网络:选取候选区域、训练CNN、训练SVM、训练bbox回归器, SPP-Net在fine-tuning阶段无法使用反向传播微调SPP-Net前面的Conv层
1.5 问题
1、SPPNet的映射过程描述?公式?
2、spatial pyramid pooling的过程?
3、SPPNet相对于R-CNN的改进地方?
2 Fast R-CNN
改进的地方:
- 提出一个RoI pooling,然后整合整个模型,把CNN、SPP变换层、分类器、bbox回归几个模块一起训练
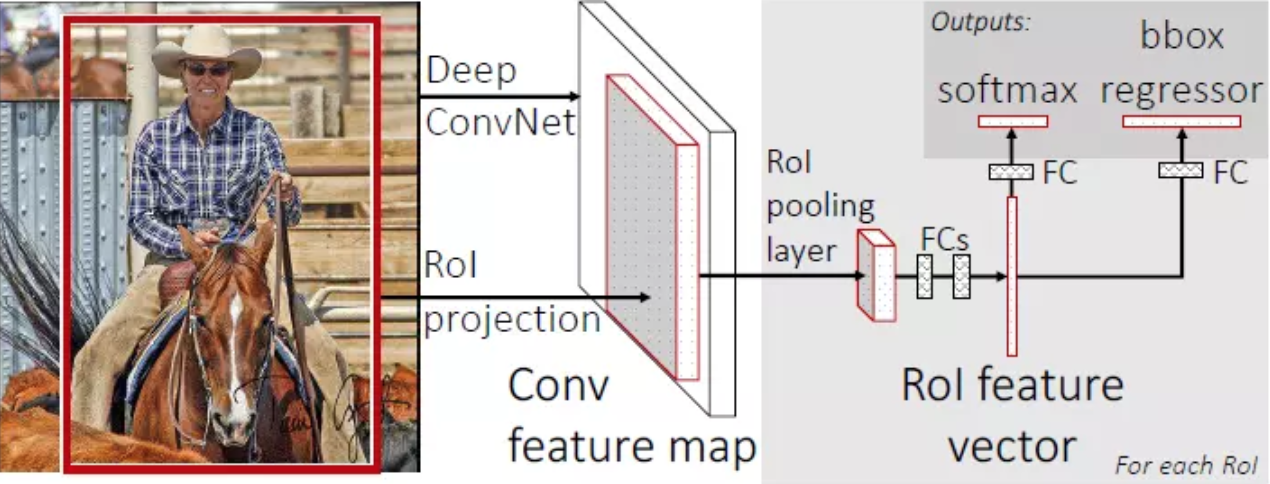
- 步骤
- 首先将整个图片输入到一个基础卷积网络,得到整张图的 feature map
- 将region proposal(RoI)映射到feature map中
- RoI pooling layer提取一个固定长度 的特征向量,每个特征会输入到一系列全连接层,得到一个RoI特征向量**(此步骤是对每一个候选区域都会进行同样的操作)**
- 其中一个是传统softmax层进行分类,输出类别有K个类别加上"背景"类
- 另一个是bounding box regressor
2.1. RoI pooling
首先RoI pooling只是一个简单版本的SPP,目的是为了减少计算时间并且得出固定长度的向量。
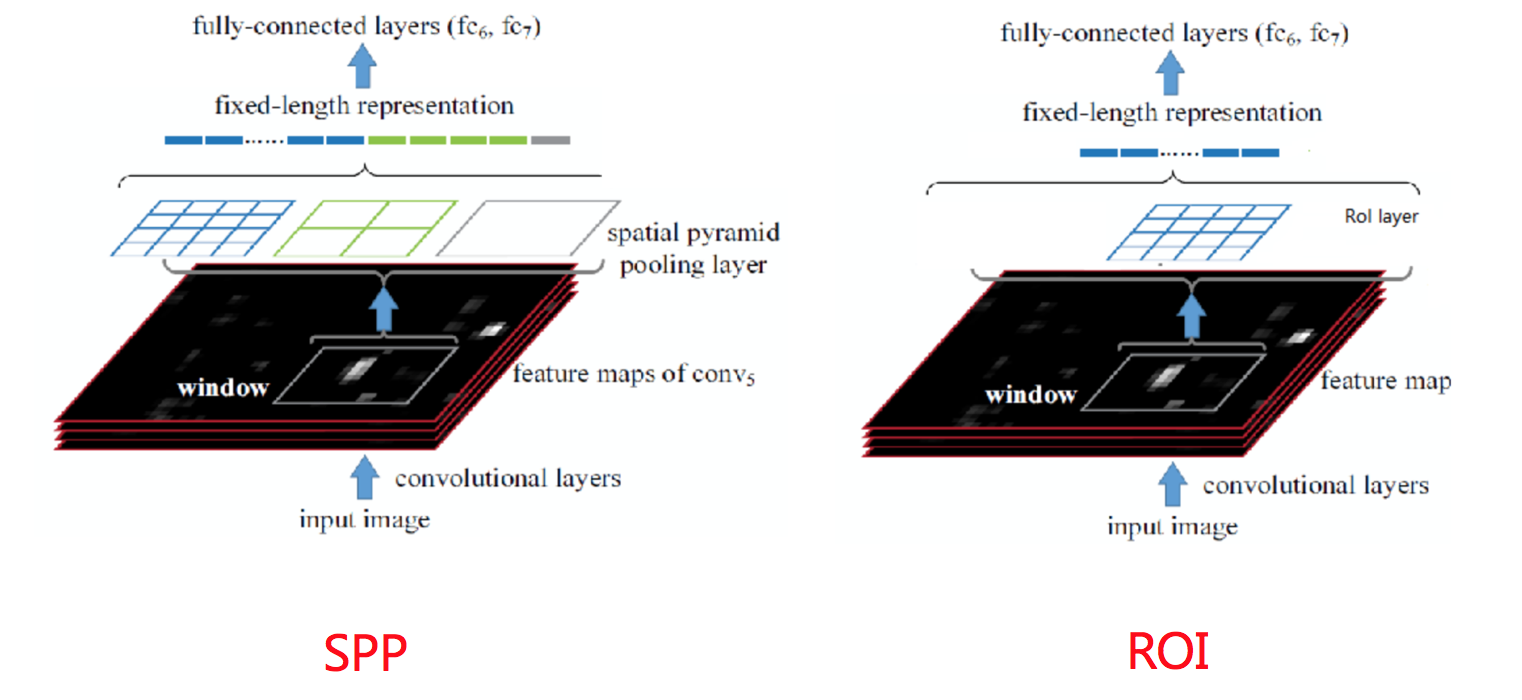
- RoI池层使用最大池化将任何有效的RoI区域内的特征转换成具有H×W的固定空间范围的小feature map,其中H和W是超参数 它们独立于任何特定的RoI。
目标检测任务中,候选区域(RoI)的大小和形状是千变万化的。但是,后续的全连接层(Fully Connected layers)或分类器要求输入的特征向量必须是固定长度的。
这句话描述的正是解决这个矛盾的关键过程:
- 输入:任意大小的有效 RoI 区域。
- 处理:使用最大池化(Max Pooling)操作。
- 输出 :一个尺寸被强制转换为
H×W的小型特征图(feature map)。通过这一步骤,无论原始 RoI 是大是小,经过 RoI Pooling 层后,都会变成统一规格的特征表示,从而可以进行批量处理和后续的分类与边界框回归。
例如:VGG16 的第一个 FC 层的输入是 7 x 7 x 512,其中 512 表示 feature map 的层数。在经过 pooling 操作后,其特征输出维度满足 H x W。假设输出的结果与FC层要求大小不一致,对原本 max pooling 的单位网格进行调整,使得 pooling 的每个网格大小动态调整为 h/H,w/W, 最终得到的特征维度都是 HxWxD。它要求 Pooling 后的特征为 7 x 7 x512,如果碰巧 ROI 区域只有 6 x 6 大小怎么办?每个网格的大小取 6/7=0.85 , 6/7=0.85,以长宽为例,按照这样的间隔取网格:0,0.85,1.7,2.55,3.4,4.25,5.1,5.95,取整后,每个网格对应的起始坐标为:0,1,2,3,3,4,5
为什么要设计单个尺度呢?这要涉及到single scale与multi scale两者的优缺点
- single scale,直接将image定为某种scale,直接输入网络来训练即可。(Fast R-CNN)
- multi scal,也就是要生成一个金字塔,然后对于object,在金字塔上找到一个大小比较接近227x227的投影版本
后者比前者更加准确些,没有突更多,但是第一种时间要省很多,所以实际采用的是第一个策略,因此Fast R-CNN要比SPPNet快很多也是因为这里的原因。
2.2. End-to-End model
从输入端到输出端直接用一个神经网络相连,整体优化目标函数。
接着我们来看为什么后面的整个网络能进行统一训练?
特征提取CNN 的训练和SVM分类器 的训练在时间上是先后顺序,两者的训练方式独立 ,因此SVMs的训练Loss无法更新SPP-Layer之前的卷积层参数,去掉了SVM分类这一过程,所有特征都存储在内存中,不占用硬盘空间,形成了End-to-End模型(proposal除外,end-to-end在Faster-RCNN中得以完善)
- 使用了softmax分类
- RoI pooling能进行反向传播,SPP层不适合
| 特性 | SPP-Net | Fast R-CNN |
|---|---|---|
| 分类器 | SVM (支持向量机) | Softmax (网络内部层) |
| 训练方式 | 多阶段(先提特征,再训SVM) | 端到端(End-to-End) |
| Loss传播 | 无法更新SPP层之前的参数 | Loss可全程反向传播 |
| 存储 | 需要将特征存入硬盘/内存 | 不需要存储特征 |
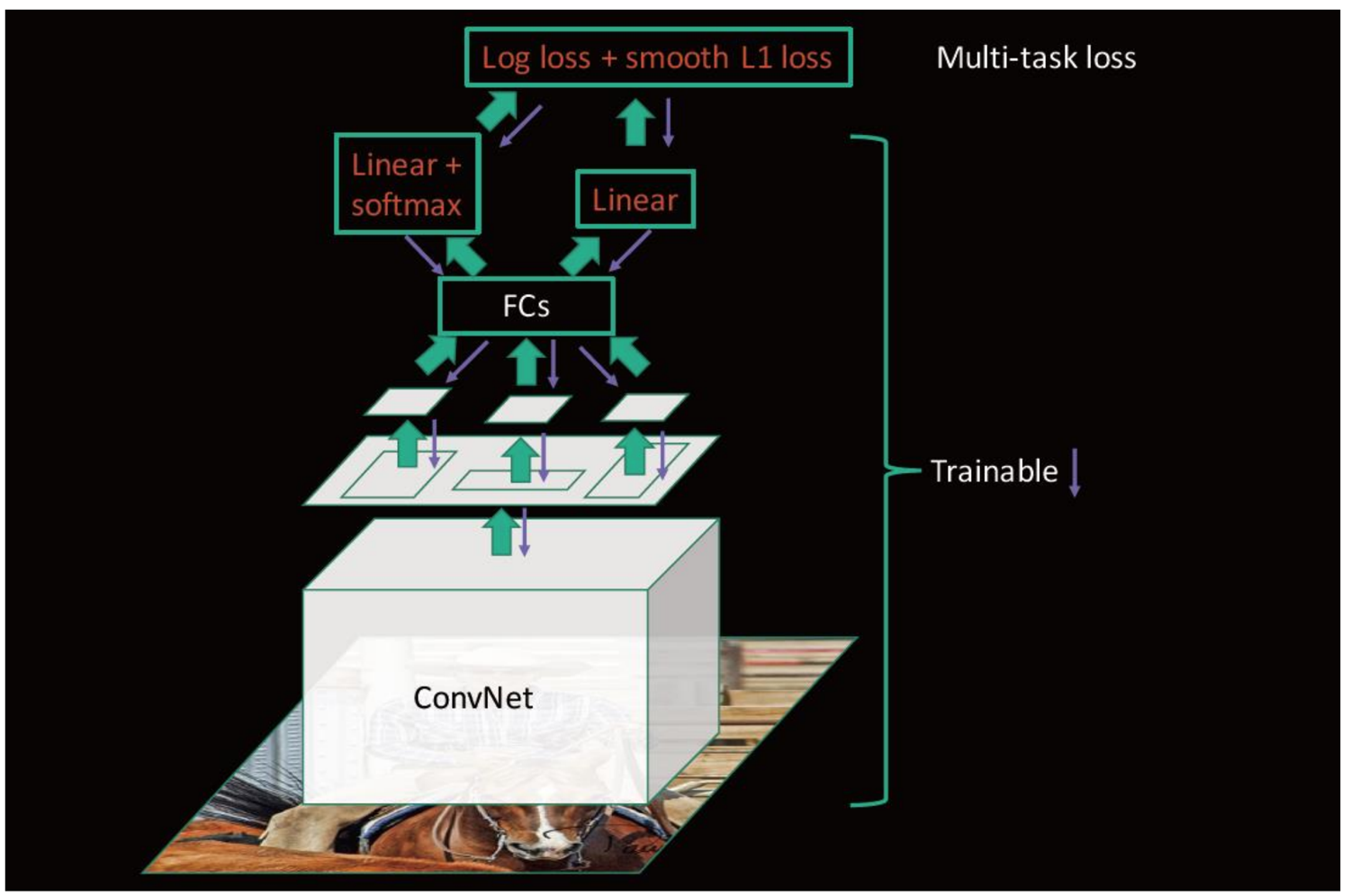
2.3 多任务损失-Multi-task loss
两个loss,分别是:
- 对于分类loss,是一个N+1路的softmax输出,其中的N是类别个数,1是背景,使用交叉熵损失(这里+1是因为有空白背景不属于规定的类别(猫、狗....))
- 对于回归loss,是一个4xN路输出的regressor,也就是说对于每个类别都会训练一个单独的regressor的意思,使用平均绝对误差(MAE)损失即L1损失
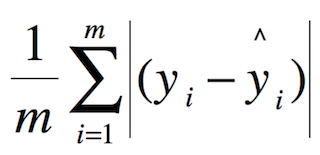
- fine-tuning训练:
- 在微调时,调整 CNN+RoI pooling+softmax+bbox regressor网络当中的参数
2.4 R-CNN、SPPNet、Fast R-CNN效果对比
| 参数 | R-CNN | SPPNet | Fast R-CNN |
|---|---|---|---|
| 训练时间(h) | 84 | 25 | 9.5 |
| 测试时间/图片 | 47.0s | 2.3s | 0.32s |
| mAP | 66.0 | 63.1 | 66.9 |
其中有一项指标为mAP,这是一个对算法评估准确率的指标,mAP衡量的是学出的模型在所有类别上的好坏
2.5 Fast R-CNN总结
- 缺点
- 使用Selective Search提取Region Proposals,没有实现真正意义上的端对端,操作也十分耗时
前面的fastR-CNN、SPPNet都会有外部分割算法实现候选框的选择这个部分
- 输入图片 → Selective Search → 生成候选区域(Region Proposals)。
- 这些候选区域随后被映射到 ConvNet 提取的特征图上,作为 RoI Pooling 层的输入。
2.6 问题
1、详细说明RoI pooling过程?
2、Fast R-CNN的损失是怎么样的?
3 Faster R-CNN
在Fast R-CNN还存在着瓶颈问题:Selective Search(选择性搜索)。要找出所有的候选框,这个也非常耗时。那我们有没有一个更加高效的方法来求出这些候选框呢?
3.1 Faster R-CNN
在Faster R-CNN中加入一个提取边缘的神经网络 ,也就说找候选框的工作也交给神经网络来做了。这样,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。
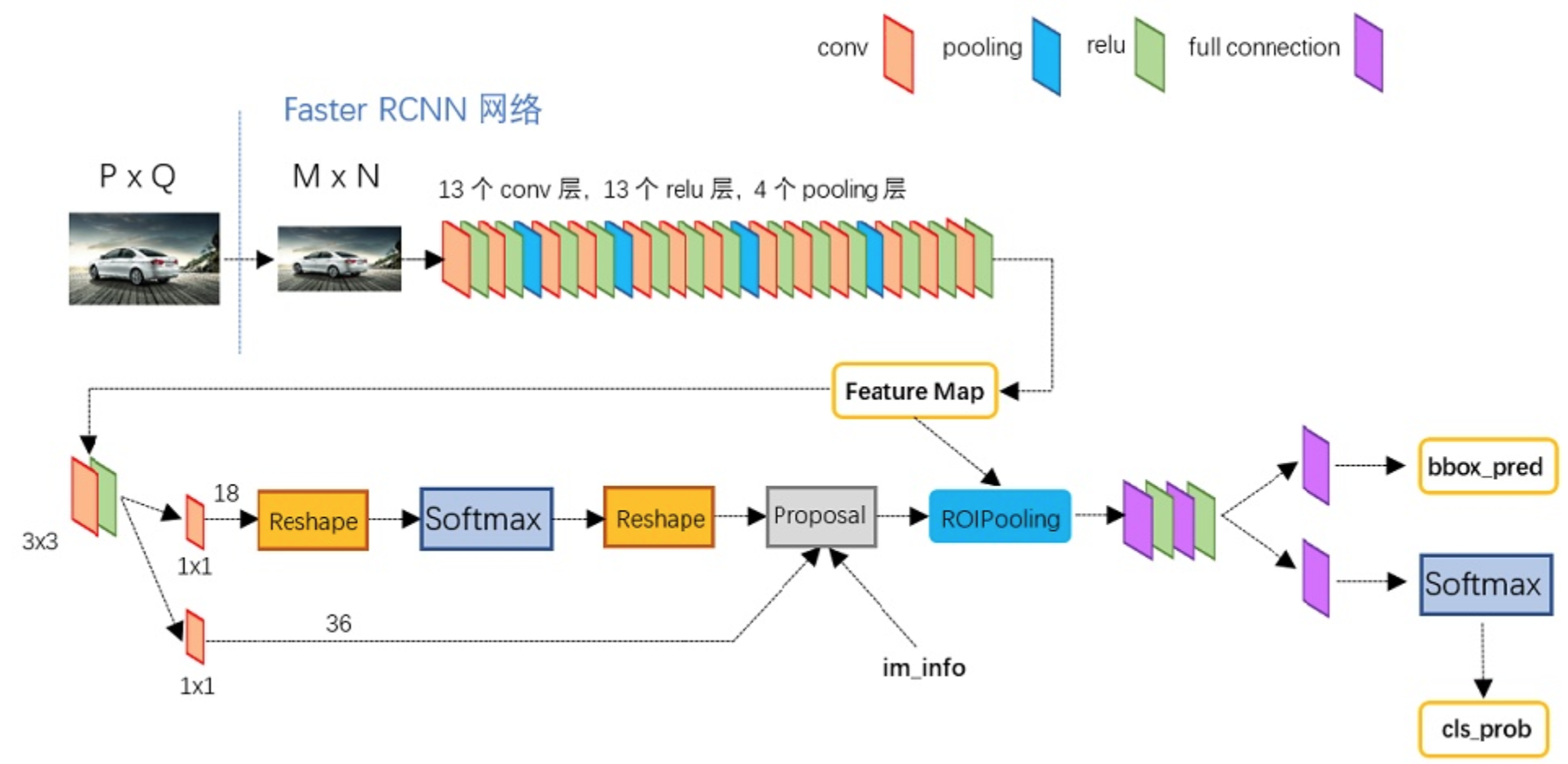
Faster R-CNN可以简单地看成是区域生成网络+Fast R-CNN的模型,用区域生成网络(Region Proposal Network,简称RPN)来代替Fast R-CNN中的选择性搜索方法,结构如下:
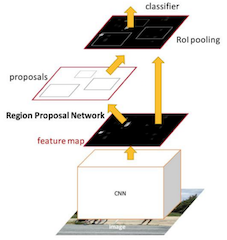
- 1、首先向CNN网络(VGG-16)输入任意大小图片
- 2、Faster RCNN使用一组基础的conv+relu+pooling层提取feature map。该feature map被共享用于后续RPN层和全连接层。
- 3、Region Proposal Networks。RPN网络用于生成region proposals,该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals,输出其Top-N(默认为300)的区域给RoI pooling
- 生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> Proposal Layer生成proposals
- 4、第2步得到的高维特征图和第3步输出的区域建合并输入RoI池化层(类), 该输出到全连接层判定目标类别。
- 5、利用proposal feature maps计算每个proposal的不同类别概率,同时bounding box regression获得检测框最终的精确位置
3.2 RPN原理
RPN网络的主要作用是得出比较准确的候选区域。整个过程分为两步
- 用n×n(默认3×3=9)的大小窗口去扫描特征图 ,每个滑窗位置映射到一个低维的向量(默认256维),并为每个滑窗位置考虑k种(在论文设计中k=9)可能的参考窗口(论文中称为anchors)
- 低维特征向量输入两个并行连接的1 x 1卷积层然后得出两个部分:reg窗口回归层(用于修正位置)和cls窗口分类层(是否为前景或背景概率)
在特征图上,每一个滑窗中心位置(即每一个像素点),都会独立地生成一个256维向量。
- 数量对应: 如果特征图大小是H×W ,那么就会有H×W 个滑窗中心,对应产生 H×W 个256维向量。
1 anchors
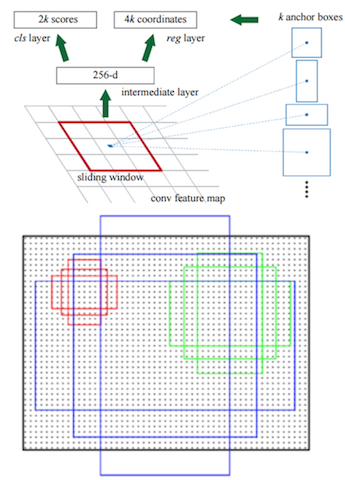
- 3*3卷积核的中心点对应原图上的位置,将该点作为anchor的中心点,在原图中框出多尺度、多种长宽比的anchors,三种尺度{ 128,256,512 }, 三种长宽比{1:1,1:2,2:1}
第一步:定位(3x3 卷积核中心 →→ 原图位置)
特征图与原图的对应关系: 卷积神经网络会把原图缩小(下采样),比如原图是 800×800,经过网络后变成 50×50 的特征图。通常下采样倍数是 16 倍。
滑窗操作: 用一个 3×3 的窗口在 50×50 的特征图上滑动。
中心点映射: 特征图上的每一个点,都对应原图上一个 16×16 像素的区域。
当 3×3 窗口滑到特征图的某个位置时,我们取这个窗口的中心点。
这个中心点映射回原图,就是一个具体的坐标(比如原图上的 (x,y) )。
结论: 这个(x,y) 坐标,就是我们要在原图画框的起始点(中心)。
第二步:定形(在原图中框出多尺度、多种长宽比)
有了中心点 (x,y) 之后,我们不只画一个框,而是在同一个中心点 上,画出 9 种不同形状的框(Anchors)。
这就涉及到你问的两个参数集合:
- 三种尺度 {128, 256, 512} 是什么意思?
这代表 Anchor 的边长(大小)。
含义: 这些数字通常指 Anchor 边长的像素值(或参考值)。
作用: 让模型学会检测不同大小的物体。
128: 较小的框,用来检测小物体(如远处的车)。
256: 中等的框,用来检测中等物体。
512: 很大的框,用来检测大物体(如近处的人)。
- 三种长宽比 {1:1, 1:2, 2:1} 是什么意思?
这代表 Anchor 的形状。
含义: 宽度与高度的比例。
作用: 让模型适应不同形状的物体。
1:1 (正方形): 适合检测头部、球体等看起来比较方的物体。
1:2 (横向矩形): 宽度是高度的2倍,适合检测横着的物体(如停在路边的车)。
2:1 (纵向矩形): 高度是宽度的2倍,适合检测竖着的物体(如人、电线杆)。
- 组合起来的实际效果
在刚才确定的中心点 (x,y) 上:
组合逻辑: 3 种尺度 × 3 种长宽比 = 9 个 Anchor。
具体画面:
以(x,y) 为中心,画一个 128×128 的正方形。
以 (x,y) 为中心,画一个 128×256 的横矩形。
以(x,y) 为中心,画一个256×128 的竖矩形。
...以此类推,直到512 的大框。
举个具体的例子 🌰
假设特征图上的一个点映射回原图的中心坐标是 (100, 100)。
此时,RPN(区域提议网络)会在这个位置"凭空"生成以下 9 种框(列举部分):
表格
尺度 长宽比 生成的 Anchor 形状 (近似) 适用场景 128 1:1 左上角 (36, 36) 右下角 (164, 164) 小方块物体 128 1:2 左上角 (36, 4) 右下角 (164, 196) 竖条状小物体 256 1:1 左上角 (-28, -28) 右下角 (228, 228) 中等大小物体 512 2:1 左上角 (-124, -124) 右下角 (324, 324) 覆盖画面的大物体 总结
"3x3卷积核的中心点" 决定了 Anchor 在哪里 (中心位置);
"三种尺度和三种长宽比" 决定了 Anchor 长什么样(大小和形状)。通过这种机制,模型不需要真的去"猜"物体在哪,只需要回答这9个预设好的框里,哪个框最像我们要找的物体,以及需要把这个框微调成什么样。
举个例子:
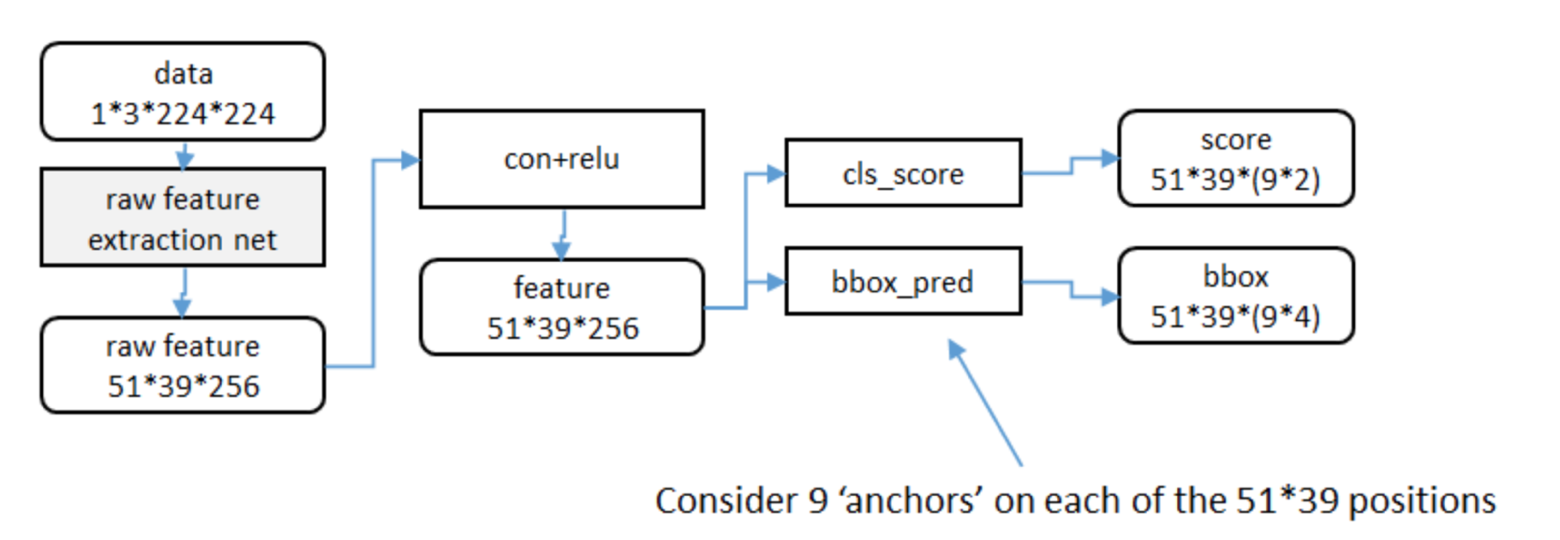
3.3 候选区域的训练
- 训练样本anchor标记
- 1.每个ground-truth box有着最高的IoU的anchor标记为正样本
- 2.剩下的anchor/anchors与任何ground-truth box的IoU大于0.7记为正样本,IoU小于0.3,记为负样本
- 3.剩下的样本全部忽略
- 正负样本比例为1:3
A. 纯人工标注(传统模式)
流程: 收集图片 -> 人工在每张图上画框 -> 生成数据集 -> 训练模型。
缺点: 极其耗时、昂贵。标注一张图可能需要几分钟,如果是几千张图的项目,人工成本非常高,且容易出现标注不一致的情况。
B. AI 辅助标注(现代高效模式)
流程: 利用预训练模型(如 COCO 上训练好的 YOLOv8)先对图片进行自动推理,生成初步的框(Pseudo-labels)。
人工介入: 人工只需要做**"修正"**工作------检查 AI 画的框对不对,不对的拉一下,漏的补一个。
优势: 这种模式下,人工不再是"画框工",而是"质检员",效率可以提升数倍。
- 训练损失
- RPN classification (anchor good / bad) ,二分类,是否有物体,是、否
- RPN regression (anchor -> proposal) ,回归
- 注:这里使用的损失函数和Fast R-CNN内的损失函数原理类似,同时最小化两种代价
候选区域的训练是为了让得出来的 正确的候选区域, 并且候选区域经过了回归微调。
在这基础之上做Fast RCNN训练是得到特征向量做分类预测和回归预测。
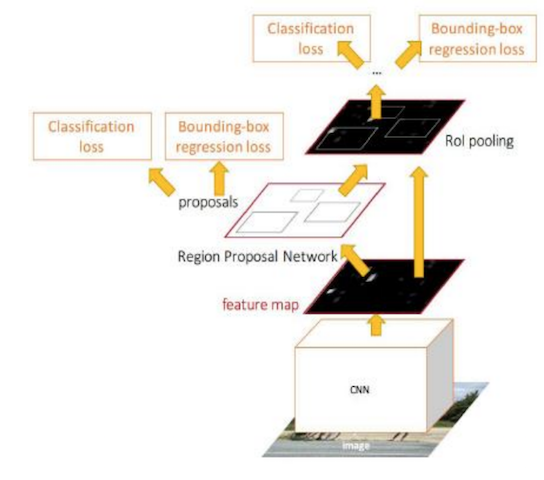
3.4 Faster R-CNN的训练
Faster R-CNN的训练分为两部分,即两个网络的训练。前面已经说明了RPN的训练损失,这里输出结果部分的的损失(这两个网络的损失合并一起训练):
-
Fast R-CNN classification (over classes) ,所有类别分类N+1
-
Fast R-CNN regression (bbox regression)
3.5 效果对比
| R-CNN | Fast R-CNN | Faster R-CNN | |
|---|---|---|---|
| Test time/image | 50.0s | 2.0s | 0.2s |
| mAP(VOC2007) | 66.0 | 66.9 | 66.9 |
3.6 Faster R-CNN总结
- 优点
- 提出RPN网络
- 端到端网络模型
- 缺点
- 训练参数过大
- 对于真实训练使用来说还是依然过于耗时
可以改进的需求:
- RPN(Region Proposal Networks) 改进 对于小目标选择利用多尺度特征信息进行RPN
- 速度提升 如YOLO系列算法,删去了RPN,直接对proposal进行分类回归,极大的提升了网络的速度
3.7 问题
1、Faster RCNN改进之处?
2、如何得到RPN的 anchors?