Flink部署
Flink提交作业和执行任务的关键组件:
- 客户端(Client):代码由客户端获取并转换以后,提交给JobManager
- JobManager:就是Flink集群里的"话事人",对作业进行中央调度管理,他获取到要执行的作业后,会进一步处理转换。然后分发给众多的TackManager
- TaskManager:真正的"干活的人",他们来进行数据的处理操作。
| 节点服务器 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 角色 | JobManager、TaskManager | JobManager | JobManager |
步骤
- 创建三台虚拟机centOS7.5三台
- 修改主机名
- 配置hosts的ip地址
shell
#/etc/hosts
192.168.xxx.xxx jobmanager
192.168.xxx.xxx taskone
192.168.xxx.xxx tasktwo环境配置
修改CentOS镜像源
备份原有 Yum 源配置
shell
sudo cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak下载阿里云 Yum 源配置文件
shell
sudo curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo阿里源配置
shell
# 1. 删掉带内网地址的 repo
rm -f /etc/yum.repos.d/*aliyun*.repo \
/etc/yum.repos.d/CentOS-Base-*.repo
# 2. 重新下载公共版阿里云 CentOS 7 源
curl -o /etc/yum.repos.d/CentOS-Base.repo \
http://mirrors.aliyun.com/repo/Centos-7.repo
# 3. 重建缓存
yum clean all
yum makecacheJAVA环境配置
shell
echo "2. 安装 OpenJDK 1.8(devel 带编译工具)..."
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel环境变量
shell
#~/.bashrc
export JAVA_HOME=$(readlink -f /usr/bin/java | sed 's:/bin/java::' | sed 's:/jre/bin/java::')
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATHsource ~/.bashrc
关闭防火墙
shell
[root@jobmanager flink]# systemctl stop firewalld
[root@jobmanager flink]# systemctl disable firewalld
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
Removed symlink /etc/systemd/system/basic.target.wants/firewalld.service.
[root@jobmanager flink]#配置ssh免密连接(JobManager节点)
shell
# 1. 生成密钥(如果还没)
ssh-keygen -t rsa # 一路回车
# 2. 把公钥拷到三个taskmanager
ssh-copy-id root@192.168.47.133
ssh-copy-id root@192.168.47.134
ssh-copy-id root@192.168.47.135压缩包下载
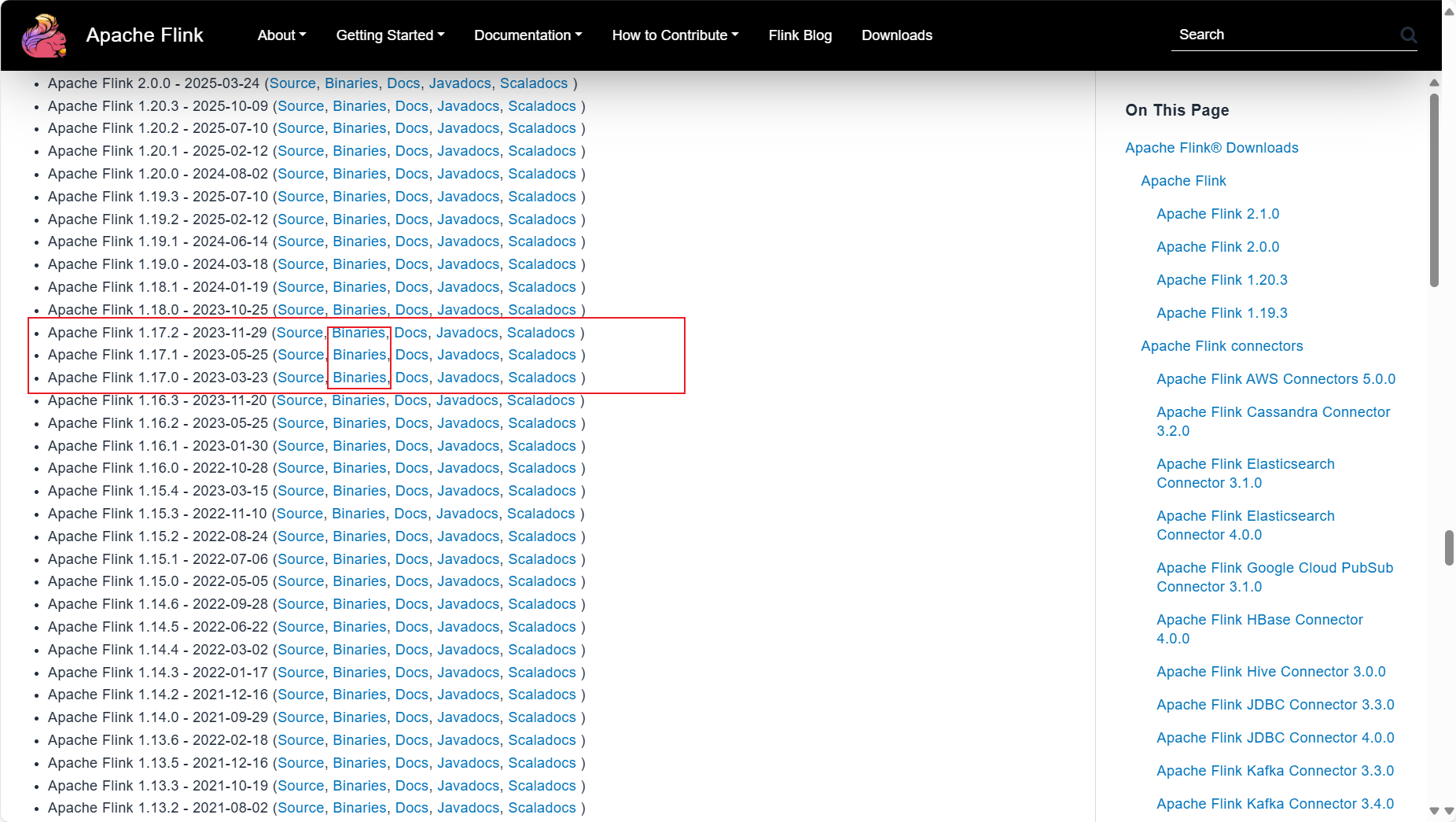
下载Flink安装包,在Flink官网
找个东西确实不好找直接Ctrl+F,搜索"1.17"
上传至虚拟机
解压后配置配文件(注意这是yaml文件,在写参数的时候,要在冒号后面加空格)
shell
#.../flink/conf/flink-conf.yaml
jobmanager.rpc.address: jobmanager
jobmanager.bind-host: 0.0.0.0
taskmanager.bind-host: 0.0.0.0
taskmanager.host: jobmanager
rest.address: jobmanager
rest.bind-address: 0.0.0.0参数解释
shell
#指定jobmanager节点的地址
jobmanager.rpc.address: jobmanager
#指定允许访问的ip,这里的0.0.0.0是允许所有ip访问
jobmanager.bind-host: 0.0.0.0
taskmanager.bind-host: 0.0.0.0
#当前节点的TaskManager的地址
taskmanager.host: jobmanager
#WebUI的访问地址
rest.address: jobmanager
rest.bind-address: 0.0.0.0配置文件解析
- jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。
- taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1728M,可以根据集群规模进行适当调整。
- taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的Slot数量进行配置,默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓Slot就是TaskManager中具体运行一个任务所分配的计算资源。
- parallelism.default:Flink任务执行的并行度,默认为1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
文件传输
通过scp指令将写好的配置文件发送到指定的节点的对应的目录下(这里的-r指的是把对应目录下的所有文件一并发送)
shell
scp -r (待发送文件) usrname@ip:地址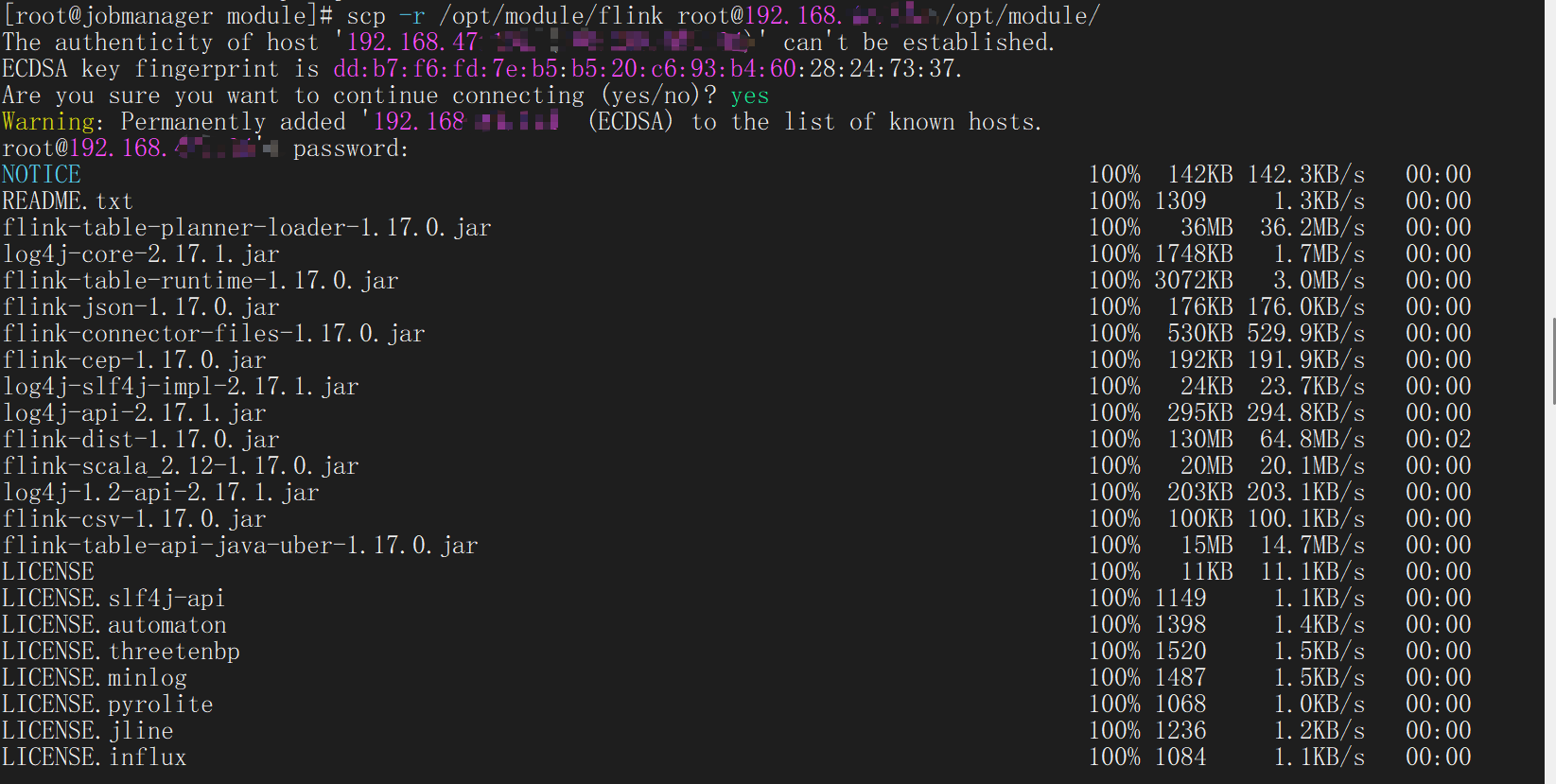
在两个Task节点修改相关的配置信息
其实只需要修改taskmanager.host参数改成当前节点的ip或者hostname
最后在jobmanager节点的conf/worker文件添加taskManager节点的ip
shell
#.../flink/conf/worker
192.168.xxx.xxx
192.168.xxx.xxx
192.168.xxx.xxx启动
执行启动脚本
shell
[root@jobmanager flink]# bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host jobmanager.
Starting taskexecutor daemon on host jobmanager.
Starting taskexecutor daemon on host taskone.
Starting taskexecutor daemon on host tasktwo.
[root@jobmanager flink]# jps
22112 StandaloneSessionClusterEntrypoint
22592 Jps
22460 TaskManagerRunner
[root@jobmanager flink]#TaksManager节点:
shell
[root@taskone flink]# jps
5024 TaskManagerRunner
5132 Jps
[root@taskone flink]#访问网页端
http://192.168.xxx.xxx:8081(JobManagerIP)
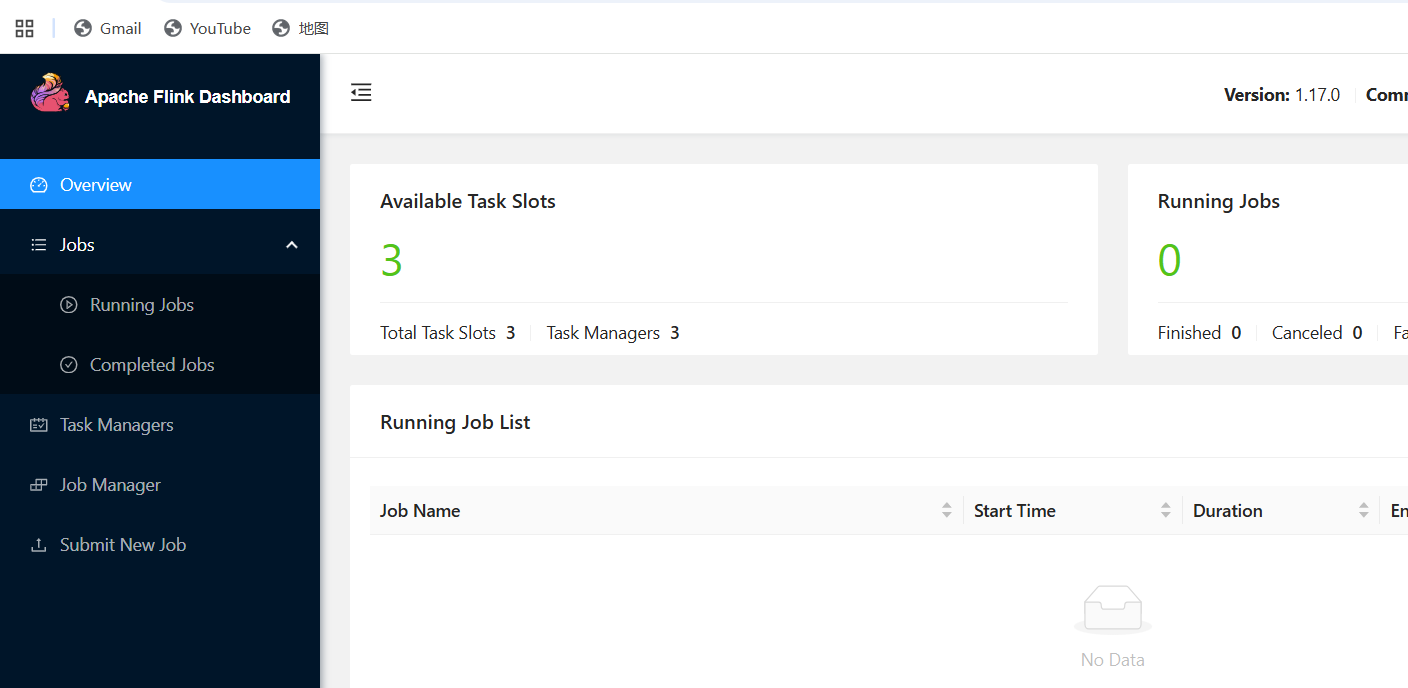
作业提交执行
我们在搭建好集群以后,来尝试将Java程序打包到Flink集群执行
pom.xml配置
xml
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.10.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- 新增:尚硅谷推荐的 shade 插件,专门打 fat-jar -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<!-- 排除 Flink 集群已提供的依赖,减小体积并避免冲突 -->
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
<exclude>org.apache.flink:flink-*</exclude>
</excludes>
</artifactSet>
<!-- 过滤签名文件,防止安全异常 -->
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<!-- 合并 META-INF/services 等资源 -->
<transformers combine.children="append">
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>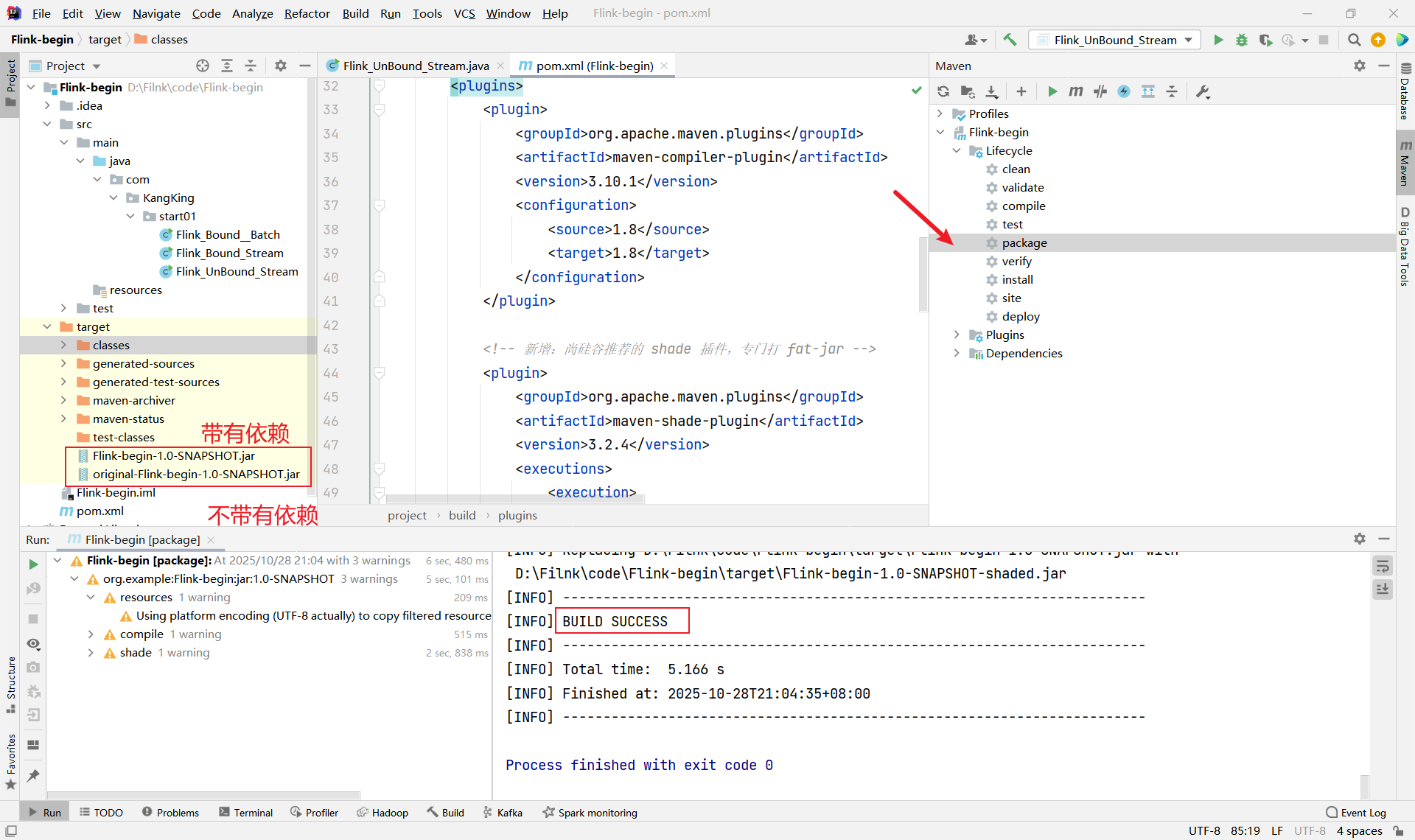
成功得到两个jar包
集群执行jar包
将jar包提交到集群
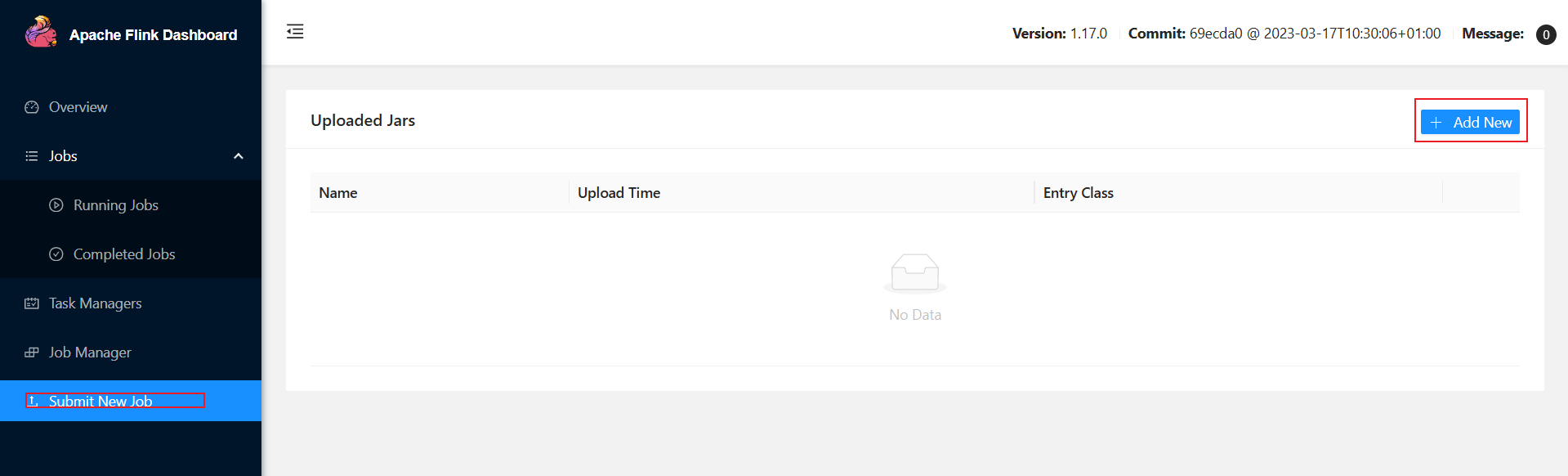

在IDEA中选择复制类的全限定名
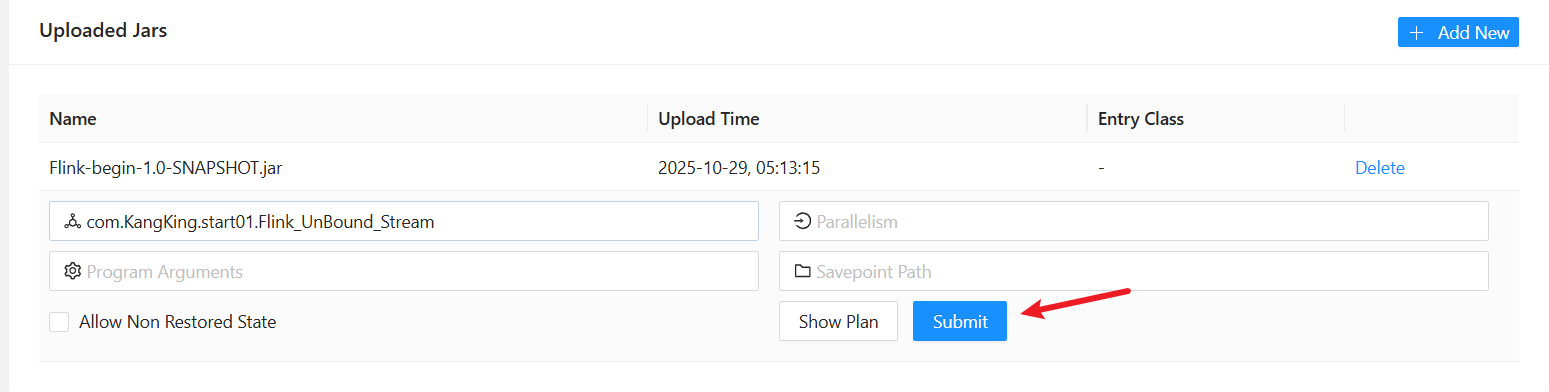
点击submit提交到集群
记得启动流处理对应节点的服务
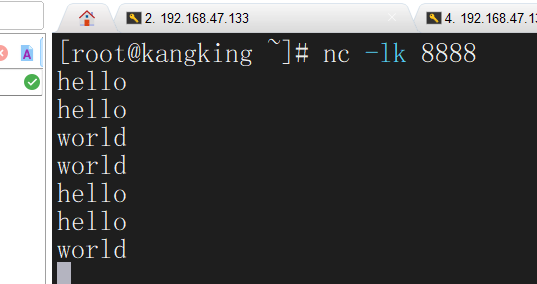
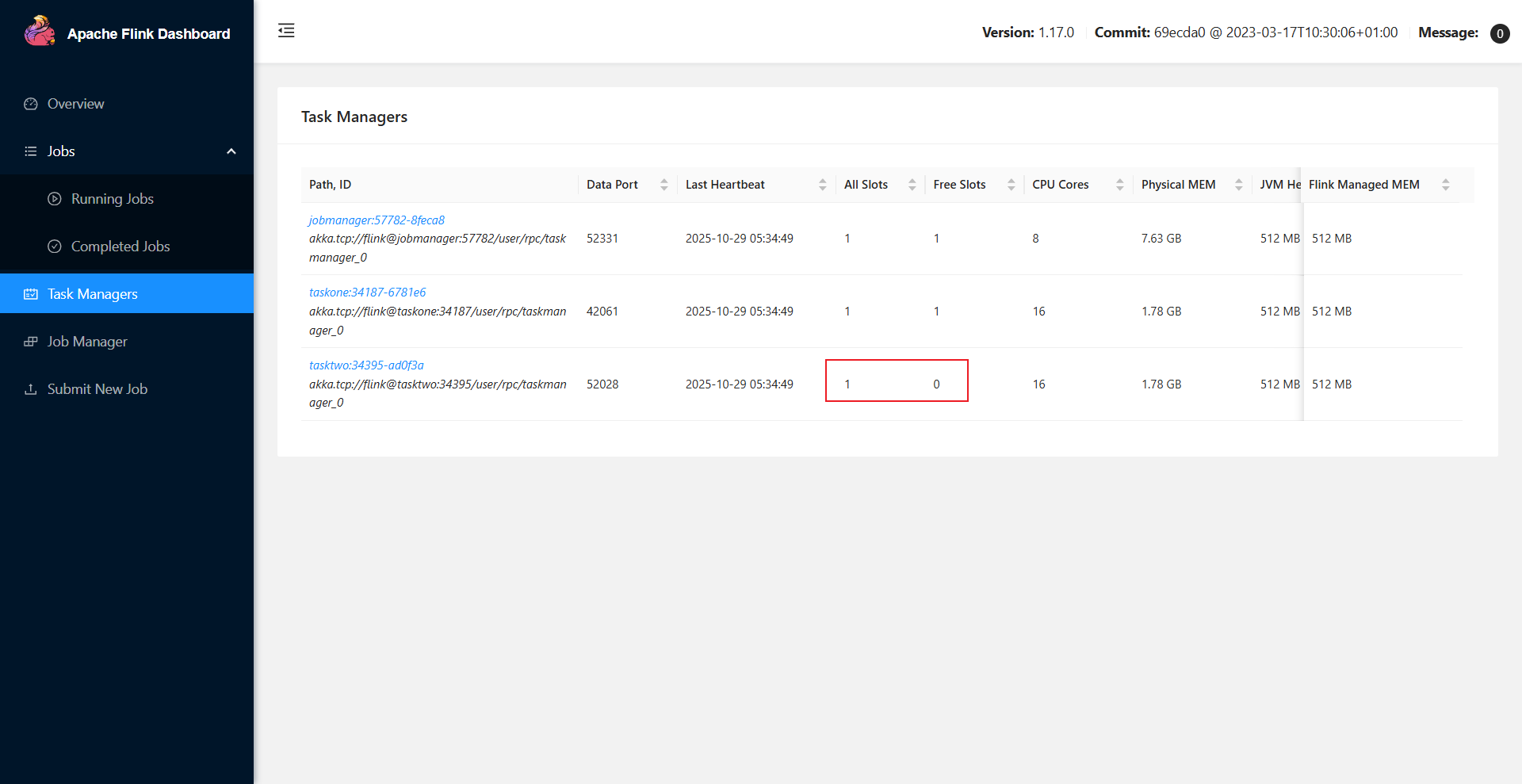
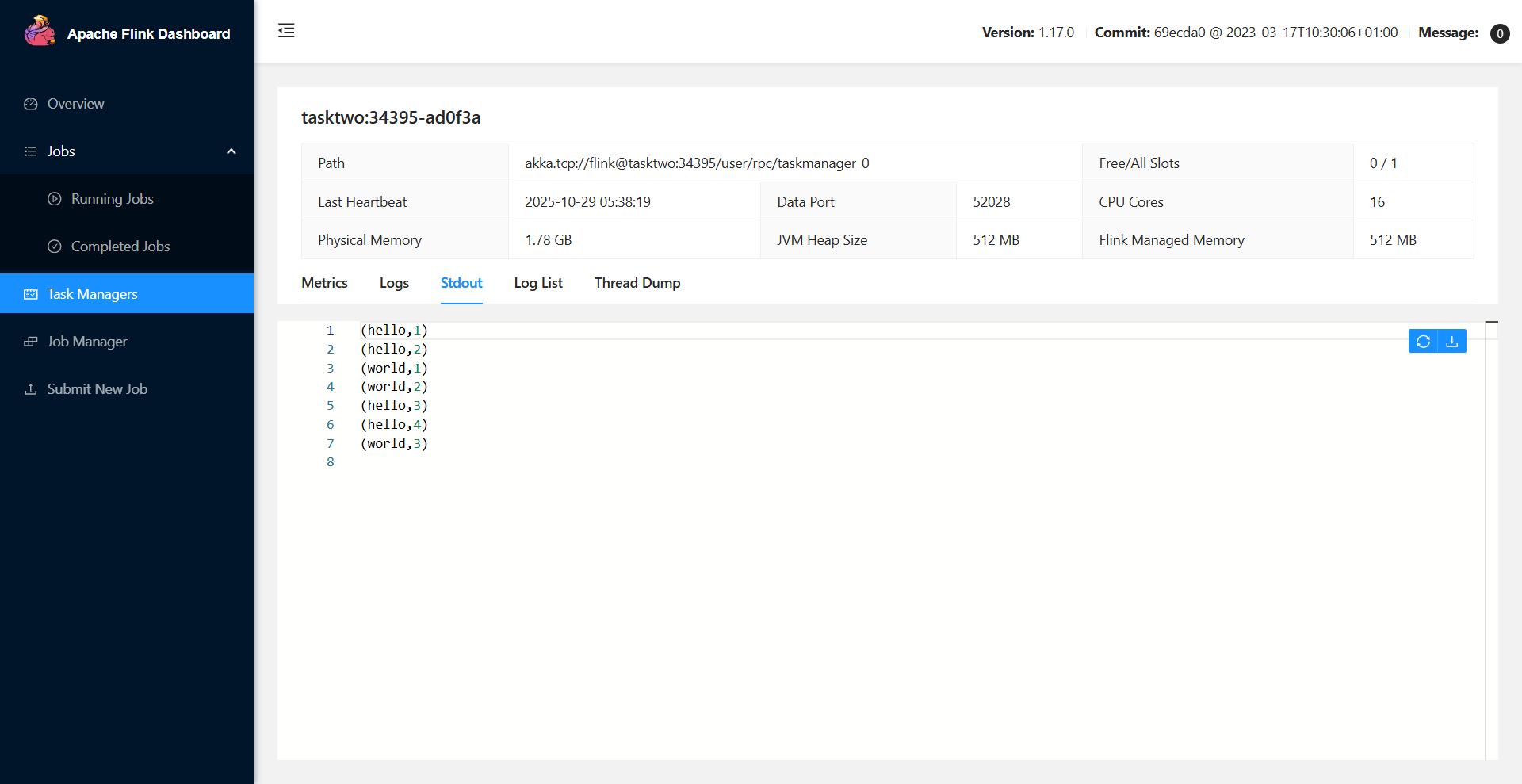
这时我们在Task Manager标签下发现taskTwo节点的资源减少了,说明我们的任务运行在了TaskTwo节点,我们点击进入TaskTwo节点查看他的Stdout就能看到对应的输出