原始文章发表在知乎,格式会规正一些,可阅读:《强化学习Actor/Learner框架介绍(lerobot版)》
近期看了一些强化学习相关的东西,也复现了一些算法,在具身操作场景,目前详细研究过的强化框架有两个:
RLinf:是清华出的一个框架,主要应用场景在仿真场景,里面集成了libero/maniskill等仿真环境,openvla-oft/pi0.5等主流vla模型的强化学习应用,ppo/grpo等经典强化学习算法。所以对一些大型VLA模型在仿真场景的强化学习提供了非常好的基础设施,此框架也非常占用资源,如果没有3个卡以上的资源,跑都不跑起来。笔者前段时间详细的研究过,写了两篇文章可供参考:《RLinf强化学习框架试用》, 《RLinf强化学习框架深入探索》。
Actor/Learner框架:这个名字不是官方的名字,只是一个形象的描述,此框架有Actor/Learner两个部分
Actor:使用最新的策略生成动作,然后下发给env,获取env的反馈,收集整个rollout信息给到Learner进行训练。
Learner:使用数据进行actor/critic网络的训练,将最新训练参数定期发给Actor,同时管理数据Buffer等功能。Actor/Learner之间通过网络协议进行通信,例如Grpc协议。
实现版本1:2024年底经典的hil-serl论文就是使用此框架进行开发,后续又有一些工作基于hil-serl的开源代码进行研发,例如ConRFT算法,《td3+bc与conrft强化学习算法总结》对ConRFT有简要的介绍。这个版本的模型是用jax进行训练推理,笔者没有详细的研究。
实现版本2:lerobot复现的hil-serl版本,此版本基于pytorch进行训练推理,笔者前期复现过两个案例:《具身智能hil-serl强化学习算法在lerobot机械臂上复现》,《具身智能hil-serl强化学习算法在lerobot机械臂上复现-案例2》。
本篇文章主要讲Actor/Learner实现版本2(lerobot版)的一些实现细节。
Actor
actor就负责运行策略模型,生成动作与机械臂交互,然后打包数据给learner进行训练。
actor核心流程可分解为下面的核心步骤,每个步骤上面都加了注释,下面的代码并不与原始代码一一对应,里面做了一些加工与简化。本节对tranision/env_processor/action_processor这三个核心概念做一些讲解。
创建transition对象,通过env_processor预处理流程加工成策略模型可使用的格式
transition = create_transition(observation=obs, info=info)
transition = env_processor(transition)
for interaction_step in range(cfg.policy.online_steps):
# 这一步看起来比较简单,就是根据当前的observation采样出一个动作。具体的模型网络架构可以参考下文的learner部分的介绍。
action = policy.select_action(batch=observation)
transition[TransitionKey.ACTION] = action
# action_processor作为一个后处理流程,将进行正逆运动学转换,生成物理机械臂可接收的格式,并更新此episode的状态
processed_action_transition = action_processor(transition)
# 拿到上面的目标关节角后,就将其下发给物理设备让其执行,执行完成后就可以拿到next_observation,reward等信息。
obs, reward, terminated, truncated, info = env.step(processed_action)
# 创建一个新的transition,代表与物理机械臂交互后产生一个新的状态。
new_transition = create_transition(
observation=obs,
action=processed_action,
reward=reward,
done=terminated,
truncated=truncated,
info=new_info,
complementary_data=complementary_data,
)
new_transition = env_processor(new_transition)
transition = new_transition
# 收集此episode的每个step产生的信息,当前episode结束后,整体打包发送给learner进程。
# Create transition for learner (convert to old format)
list_transition_to_send_to_learner.append(
Transition(
state=observation,
action=executed_action,
reward=reward,
next_state=next_observation,
done=done,
truncated=truncated,
complementary_info=complementary_info,
)
)transition:
创建一个transition对象,它里面有下面几个key,就是强化学习里面的经典的关键元素(很奇怪,没有next_obs)。这个对象作为actor模块状态维护的核心数据结构,维护了当前episode是否结束,是否成功,是否被截断等一些状态,也保存了人工接管产生的一些动作,操作等信息。transition对象在actor内部进行流转。
{
TransitionKey.OBSERVATION: observation,
TransitionKey.ACTION: action,
TransitionKey.REWARD: reward,
TransitionKey.DONE: done,
TransitionKey.TRUNCATED: truncated,
TransitionKey.INFO: info if info is not None else {},
TransitionKey.COMPLEMENTARY_DATA: complementary_data,
}
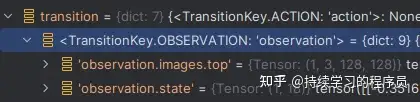
observation
observation中包括image和state数据,state除6个关节角度之外,还包括其角速度等共计18维信息。
done信息来源于两种情况:任务成功(通过键盘m键人工确认此episode成功)或人工中断任务(通过键盘r键人工选择重采数据,从而导致当前episode结束)。此逻辑在:InterventionActionProcessorStep类中。
truncated来源于一种情况:就是当前episode超时,配置文件中有个配置:control_time_s=30秒,当前episode超过30秒后会强制中断。此逻辑在:TimeLimitProcessorStep类中。
info信息来源于接管设备,此逻辑在:AddTeleopEventsAsInfoStep类中。接管设备会输出四个信息如下。这个信息是原始设备输出信息,经过后续的加工处理,变成上面所述的done信息。
{
TeleopEvents.IS_INTERVENTION: self.is_intervention,
TeleopEvents.TERMINATE_EPISODE: terminate_episode,
TeleopEvents.SUCCESS: success,
TeleopEvents.RERECORD_EPISODE: rerecord_episode,
}
env_processor:
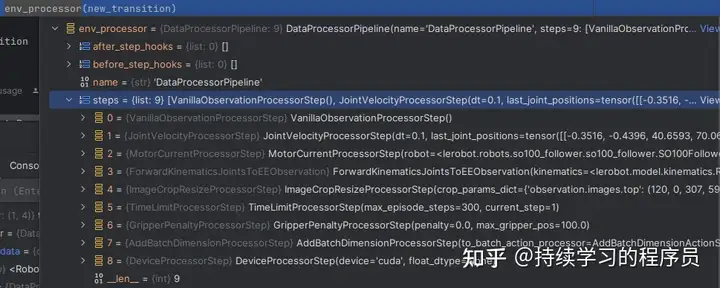
env_processor
transition被送进一个env_processor的pipeline中。它包括9个step,如上图。主要的功能可以简单的理解为一个Pre-processing,即预处理。例如JointVelocityProcessorStep主要功能是在observation中添加角速度等信息,最终将数据处理成策略模型可使用的格式。
可以发现这个pipeline的设计思想还是挺好的,将一些复杂的业务逻辑,拆分成一个一个的step类,这样代码理解与修改会更容易一些。多说一句,这方面做的最好的框架是mmdetection框架,真正做到了拆分得干净,互相之间不耦合,通过一个配置文件配置所有pipeline,通过配置文件就可以了解到所有的业务逻辑,并且通过某一配置项可以非常快速的找到其代码实现。而lerobot的框架做的还是不够彻底与优雅,代码还是稍显混乱。
action_processor
action_processor,也是一个pipeline,它可以简单的理解为一个Post-processing,即后处理。
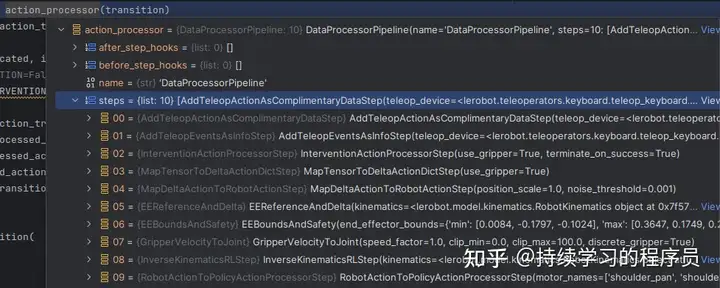
action processor
这10个步骤里面根据其名字大概就能猜出来它的作用。例如AddTeleopEventsAsInfoStep就是将接管设备输出的信息放在transition的info成员变量中(上面讲过)。在这里重点讲两个类:
EEReferenceAndDelta:此类的逻辑是:先通过运动学转换将当前关节角(lerobot机械臂的接口是关节角而不是ee坐标)转换为ee坐标t_curr (x/y/z/roll/pitch/yaw),因为策略或人工输出的动作是ee坐标系下面的delta,所以通过t_curr和delta,可以计算ee坐标系下面的目标位置。
InverseKinematicsRLStep,它获取上面EEReferenceAndDelta输出的目标动作(ee坐标系),做了一个逆运动学转换,将其转换为目标关节角,这个目标关节角后续可以直接下发给机械臂。
其它的step大概就是在transition里面添加一些其它信息,改一改里面的done等状态。
learner
Learner负责对actor/critic模型进行训练,并定期将最新的训练参数同步给Actor进程(与actor模型,也叫策略模型同名,但不是一个东西)
网络设计
使用大模型协助画了一下actor/critic网络的结构如下图一:
图一:actor/critic整体流程图

图二:特征提取网络结构
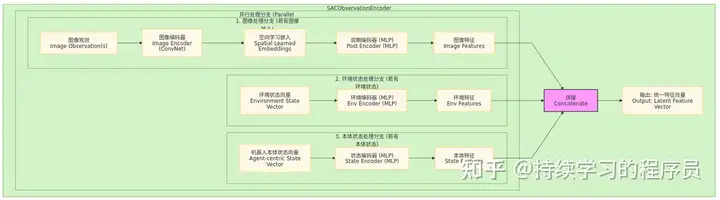
actor与critic共享了特征提取网络,其内部网络结构如上图二,在实现层面也做了很多优化,例如:
Image Encoder在训练的时候是冻结的
Image Encoder在推理的时候,结果会缓存,缓存生成的代码如下(代码1),因为这部分是一个ResNet网络,是整体中最耗时的部分(相对其它部分而言)。缓存的有效期是一个step,从上面图中可以看出来,在一个step中,actor和critic都会使用SACObservationEncoder提取特征,所以缓存后可节省一次Image Encoder的成本。
actor的优化器(代码2)只训练上图中Actor MLP Head的参数,其它的并不参与训练。可以看到,在SAC算法中,虽然actor的梯度信息来源于critic计算的q值,loss信息会通过critic网络反向传播到actor网络,此时critic网络参数也会计算梯度,但其实并不起作用(在后续critic网络训练时,zero_grad会清空此梯度),因为actor的优化器只优化actor的参数。critic网络参数只在强化学习训练critic网络时才会被训练到。从设计角度来看,actor网络相信critic网络中对于特征提取网络部分(SACObservationEncoder除image encoder外的其它部分)的参数的训练有效性。
代码1
observation_features, next_observation_features = get_observation_features(
policy=policy, observations=observations, next_observations=next_observations
)
代码2
optimizer_actor = torch.optim.Adam(
params=[
p
for n, p in policy.actor.named_parameters()
if not policy.config.shared_encoder or not n.startswith("encoder")
],
lr=cfg.policy.actor_lr,
)
kernel
模型设计中有一个kernel模块,对应上面图二中的"空间学习嵌入",以前没有太遇到过这种用法,研究了一下:
上游resnet10的输出:
输出tensor:torch.Size(1, 512, 4, 4)
kernel的shape:
输出tensor:torch.Size(1, 512, 4, 4, 8)
(上游resnet10的输出 * kernal).sum(dim=(2, 3))
输出tensor:torch.Size(1, 512, 8)
view(1, -1)
输出tensor:torch.Size(1, 4096)
post encode,一张图片输出成一个256维的特征向量
网络:Sequential(
(0): Dropout(p=0.1, inplace=False)
(1): Linear(in_features=4096, out_features=256, bias=True)
(2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(3): Tanh()
)
输出tensor:torch.Size(1, 256)
上面的五个步骤是一张图片从原始的(c,h,w)如何一步一步转换为一个256维的向量的过程。后面把多张图片的特征向量拼接后,通过mlp可以生成动作等信息。可以发现kernel作用在第二步。直接贴一下大模型对kernel的解读:
self.kernel 的作用是:作为一个可学习的"空间权重矩阵",用来对输入的图像特征(Feature Map)进行加权池化,从而提取出固定维度的特征向量。
可以把它理解为一种"软性"的、可学习的注意力机制:
输入:forward函数的输入 features 是一个来自卷积神经网络(CNN)的图像特征图,形状为 批次大小, 通道数, 高, 宽。
self.kernel是什么:它是一个可学习的参数(nn.Parameter),形状为 通道数, 高, 宽, num_features。你可以把它想象成有 num_features 个不同的"空间滤镜",每个"滤镜"都为输入的特征图上的每一个像素点(在每个通道上)都分配了一个可学习的权重。
如何工作: * 在 forward 函数中,输入的特征图 features 与 self.kernel 进行逐元素相乘。 * 然后,在空间维度(高和宽)上进行求和 sum(dim=(2, 3))。 * 这个过程实际上就是对特征图进行加权求和,而权重就是 self.kernel 中学习到的值。
目的:传统的池化方法(如最大池化或平均池化)是固定的、不可学习的。而 SpatialLearnedEmbeddings 模块通过学习 self.kernel,可以让模型自主地学会应该关注图像特征图的哪些区域。例如,对于一个机械臂任务,模型可能会学会给夹爪位置的特征赋予更高的权重。
总结:self.kernel 的作用是让模型从CNN输出的空间特征图中,以一种更智能、可学习的方式(而不是固定的全局池化)来提取和压缩信息,从而得到对任务更有用的特征表示。
关于sac算法中的熵:
sac算法的核心特点之一就是将动作熵作为loss的组成之一,熵就代表动作的确定程度,熵越高,代表不确定性越强,反之,确定性越强。通过将熵动态的锁定在某个目标值,以鼓励探索。(可以回想一下td3算法中的探索性如何体现:在输出的动作中人为的增加noise)
actor的损失函数(简化后)大致如下:
actor_loss = (alpha * log_probs - q_preds).mean()
那么:-actor_loss = (-alpha * log_probs + q_preds).mean() = (alpha * 熵 + q值).mean()
最小化loss,即等价于最大化熵 + q值,而alpha是熵的系数。最大化熵就是鼓励探索性。按一般的做法,alpha可以设定为一个超参数,人工来指定,但在sac算法中,alpha是自适应的,是一个自学习的参数,如何做到的呢?在讲方法之前,先设定目标。
目标:
sac算法中有一个目标熵的概念,例如目标熵的值是-1.5,那么当前策略的熵若小于-1.5的话,可以在上面公式中增加alpha权重,这样在actor的训练过程中,可以增加熵,鼓励探索性。若当前策略熵大于-1.5的话,说明探索过度,可通过降低alpha,这样在actor的训练过程中,可以减少熵,收紧探索性。整体上通过alpha的动态变化,来控制损失函数中熵的权重。
方法:
如下面代码所示,self.log_alpha就是上面公式中alpha的log值,为什么加log呢?加了log后,训练的参数就是self.log_alpha就是一个不限正负的数,更容易训练,另外alpha=self.log_alpha.exp()永远是一个正数,可确保系数为正。log_probs就是策略输出的概率的log值,self.target_entropy是一个目标值,在当前项目中它是-1.5(action维度的一半的负值,即-3/2)。
当-log_probs(熵)若小于-1.5,说明此时策略确定性太强,探索性不足,那么(-log_probs - self.target_entropy)整体小于0, 要想temperature_loss变小时,self.log_alpha就会增加。
当-log_probs(熵)若大于-1.5,说明此时策略确定性不足,探索性太强,那么(-log_probs - self.target_entropy)整体大于0, 要想temperature_loss变小时,self.log_alpha就会变小。
with torch.no_grad():
_, log_probs, _ = self.actor(observations, observation_features)
temperature_loss = (-self.log_alpha.exp() * (log_probs + self.target_entropy)).mean()
即:temperature_loss = (self.log_alpha.exp() * (-log_probs - self.target_entropy)).mean()
整体上通过temperature_loss的反向传播来动态的更新self.log_alpha,也就是这个简单的网络只有一个参数需要训练,就是self.log_alpha。大家可能有个疑问,概率值属于0,1区间,那么熵=-log§应该是一个正数,对于离散型概率确实是这样。但对于连续型概率密度函数,它的在某点的值是一个概率密度,并不是概率,概率密度代表随机变量在某点的集中程度或可能性,其值是可以大于1的。此时,熵的值可以为负数。