**文章标题:**Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
(翻译)自动驾驶中的基础模型:场景生成与场景分析综述
文章发表于预印本:Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
续:文献阅读篇#10:自动驾驶中的基础模型:场景生成与场景分析综述(1)-CSDN博客
3、大型语言模型(LLMs)
本节介绍了大语言模型(LLM)的基础和发展历程,展示了关键技术进展,并报告了常用的适配技术(例如提示工程和微调策略)。随后,我们探讨了大语言模型如何支持场景生成、安全关键案例、真实场景合成、驾驶策略评估、闭环仿真以及高级驾驶辅助系统(ADAS)测试。本节最后以场景分析的讨论作为总结,包括问答、场景理解和场景评估。++(总结章节内容)++
A. 大型语言模型的发展
最突出的基础模型类别是大型语言模型(LLMs),它们专注于文本模态,并建立在变压器架构之上 22。这些模型的一个显著特征是使用自监督学习,通过从大规模未标记语料中预测文本的掩码或缺失部分来学习语言表示。这一范式使模型能够在无需人工标注的情况下捕捉丰富的上下文和语义信息。这种方法的基础是静态词嵌入 61,后来发展为预训练语言模型,如 GPT 23、BERT 15 和 T5 24。这些模型用从文本直接学习的动态、上下文感知表示取代了静态嵌入。GPT-3 的发布,具有 1750 亿参数 21,标志着自监督语言建模的一个重要里程碑,它展示了强大的泛化能力和少样本学习能力,与早期模型相比,大大减少了对任务特定微调的需求。++(LLM的特点和典例)++
OpenAI 在 2020 年提出的规模定律62显示,大型语言模型(LLM)的性能随着模型规模、数据量和计算量的增加而可预测地提升,这推动了向更大基础模型发展的趋势。然而,DeepSeek63对这一假设提出了挑战,证明数据质量和对齐程度同样重要。通过在合成专家数据上的监督微调以及通过群体相对策略优化(GRPO)的强化学习,他们训练出了在性能上具有竞争力的较小模型。++(GPT vs Deepseek的训练范式)++
由于大型语言模型(LLM)是在大规模未标注数据上进行预训练的,因此已经开发了各种适应技术,如提示工程和微调,以将LLM的行为调整到特定任务上。Sahoo 等人 64 在他们最近的综述中概述了这些技术。在这里,我们重点关注在驾驶场景生成和分析背景下应用的适应技术。++(承上启下)++
++提示工程:++
这指的是设计和构建输入提示,以引导预训练语言模型生成所需输出,而无需修改其内部参数。不同的技术包括:
(1) 上下文提示(CP):通过提供与任务相关的上下文或背景信息来增强提示,从而帮助模型更好地与预期的应用领域对齐。
(2) 思维链 (CoT):鼓励模型在给出最终答案之前生成中间推理步骤。这种结构化的推理增强了模型推理链的逻辑一致性,对于复杂的多步骤任务尤其有益。
(3) 上下文学习 (ICL):在提示中涉及任务示范(例如,一次示范或少量示范),以引导模型朝正确的任务行为方向发展。
(4) 自一致性(SC):一种解码策略,它会针对给定的提示生成多个输出,并选择最频繁或最一致的答案,从而提高答案的稳健性和可靠性。
(5) 检索增强生成(RAG):通过在推理时从数据库中检索外部知识来提升特定任务的性能。检索组件会识别相关文档以作为模型响应的依据,从而提高其准确性。
++微调:++
这些技术通过在数据集上训练模型来提升其执行特定任务的能力。不同的微调技术包括全量微调(Full Fine-Tuning,FFT)和参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)。FFT使用特定领域的数据更新所有模型参数。虽然这种方法有效,但它需要大量的计算资源且扩展性有限。PEFT只更新模型的一小部分参数,同时保持大部分模型参数冻结。PEFT的一个具体方法是低秩适配(Low-Rank Adaptation,LoRA),它在模型的注意力模块中注入可训练的低秩矩阵,使得只需最少的参数更新就能实现适配,并降低计算成本。例如,对GPT-3进行全量微调需要更新全部1750亿参数,而LoRA仅需训练大约3770万参数即可实现相似的性能 65。
此外,综述论文中还存在用于适应大型语言模型(LLM)的更高级技术。这些包括多阶段提示 66,67 以及多LLM代理系统(MLAs) 68,它们协调多个相互作用的LLM,以协作解决复杂任务。像LangChain 69 这样的工具框架,有助于构建模块化、基于代理的架构,超越传统的单提示交互。
B. 基于大型语言模型的场景生成
大型语言模型(LLM)的进步推动了基于LLM的场景生成,用于测试智能车辆系统。根据各自的目标,我们将现有的工作分为六类,并在表2中列出了每类的代表性工作:
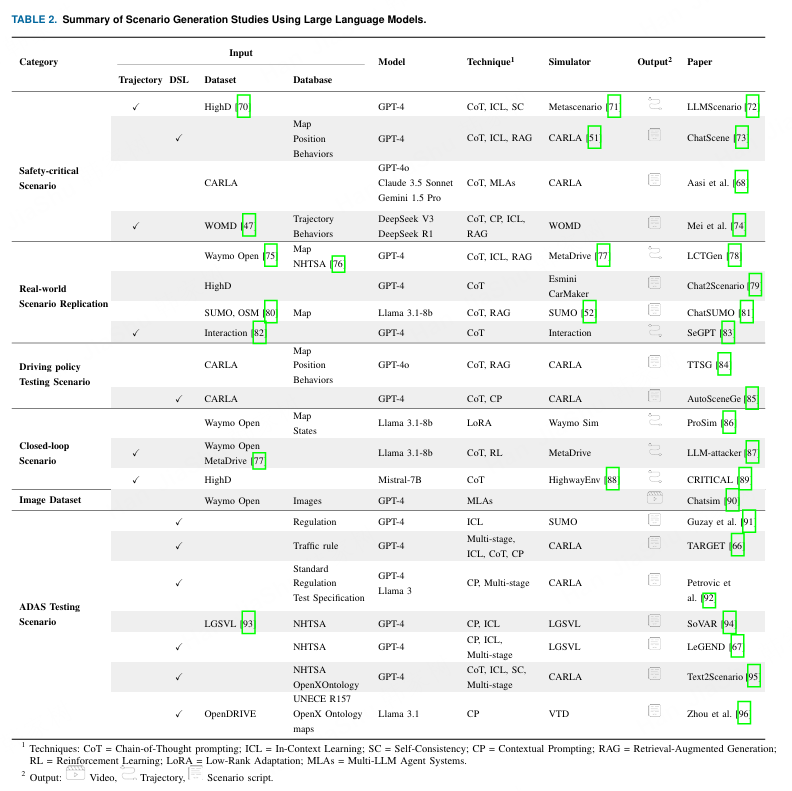
技术:CoT=链式思维提示;ICL=上下文学习;SC=自洽性;CP=上下文提示;RAG=增强检索生成;RL=强化学习;LoRA=低秩适应;MLAs=多LLM代理系统。
安全关键场景生成:
基于大型语言模型(LLM)的场景生成的一个关键应用在于创建安全关键场景。这些场景通常被称为**"边缘情况"、"长尾"或"分布外(OOD)"事件** ,对于评估自动驾驶系统的安全性和稳健性至关重要 11。++(定义)++
研究工作 LLMScenario 72 聚焦于基于 HighD 数据集 70 的安全关键场景生成,并使用 GPT-4。他们使用 ICL(少量示例学习),结合基于现实性和罕见性评估的关键示例来指导生成。通过使用 CoT 和 SC 提示,该框架在 MetaScenario 71 中逐步生成安全关键的轨迹。ChatScene 73 使用 GPT-4 结合 RAG,将文本描述的安全关键场景翻译为特定领域语言(DSL)脚本,例如 CARLA 51 的 Scenic 97。其检索数据库的构建方法是Sentence-T5 嵌入将行为和几何模式映射到代码片段。这些片段随后通过 RAG 检索并组装成完整的场景脚本。在结构化生成的基础上,Aasi 等人 68 提出了一个多代理管道,使用 CoT 提示构建 OOD 场景的分支树。他们的 Augmenter-LLM 基于 GPT-4o,将描述转换为 CARLA 场景配置,这些配置通过 API 调用包含地图、天气、对象和行为。然后,AVLM 按 OOD 类型对模拟场景进行分类。++(几个开环案例)++
上述方法是开环操作的。相比之下,Mei 等人 74 关注使用 Waymo Open Motion 数据集 47 进行在线交互式场景生成。他们的检索增强框架使用 DeepSeek-V3 和 DeepSeek-R1 实时推断车辆的风险行为,并合成对抗性轨迹使其与自车发生碰撞。一个记忆模块用于存储和检索意图--规划器对,从而允许对生成的场景进行持续优化和适应。++(一个闭环案例)++
尽管取得了可喜的进展,但当前的工作往往在离线环境中进行或仅关注有限的风险类型,这限制了它们的推广到复杂的多智能体环境的能力。未来的工作可以结合交互式生成,在仿真中增强安全性验证,并通过利用视觉语言模型(VLMs)评估生成场景的合理性和关键性来开发评估流程。++(局限)++
真实场景复现:
由于难以准确重现真实世界的条件,创建逼真的驾驶场景具有挑战性。一个常见的策略是在仿真环境中重放记录的驾驶数据,或利用真实的事故报告来重建相应的事件。通过以真实世界地图为基础,也可以复制逼真的交通场景,从而保留真实的基础设施、道路布局和环境特征。++(介绍)++
LCTGen 78 利用带有 ICL 和 CoT 提示的 GPT-4 将事故报告转换为结构化的类 YAML 描述。然后,一个检索模块将这些结构化描述与 Waymo Open Dataset 75 中的相关地图匹配。这些"地图基础"的输入随后由生成模型处理,该模型使用多层感知器和学习到的掩码来生成逼真的驾驶场景。在 Chat2Scenario 79 中,从 HighD 记录的数据集与用户定义的关键性和文本描述作为输入。他们使用带模板的上下文提示方案结合 GPT-4,并检索与用户输入匹配的 ASAM OpenScenario 98 格式的相关场景。对于微观仿真,ChatSUMO 81 利用带模板提示的 Llama 3.1 99 提取用户对交通流量、城市和网络类型的需求。然后,ChatSUMO 将这些参数转换为 SUMO 52 配置,通过 RAG 检索 osm 80 地图。仿真输出,包括交通密度、旅行时间和排放,通过 Streamlit 进行可视化和总结。SeGPT 83 从记录的轨迹中合成多样且具有挑战性的测试数据。他们的框架支持大规模场景合成,并比较零样本提示与 CoT 提示,以评估 LLM 指导生成在 82 数据集上的性能。++(几个案例)++
所回顾的论文从记录的数据和事故报告中生成场景。未来的一个方向是首先从记录的数据集中生成场景,然后将自然语言描述作为反馈纳入其中。这种混合方法可以通过将数据驱动的生成与人类直观需求对齐,显著增强生成场景的真实性和多样性。++(未来方向)++
驾驶政策测试场景生成:
驾驶策略测试场景对于评估自动驾驶模块(如运动规划器或控制器)至关重要。在 LCTGen 78 中,使用生成的真实世界碰撞场景来评估 MetaDrive 77 模拟器中运动规划器的性能。在 TTSG 84 中,使用 GPT-4o 生成的场景来验证关键场景下的多智能体规划。具体来说,他们使用结合大语言模型(LLMs)的 RAG 构建了道路和智能体数据库,并提出了排序策略来根据智能体的行为选择最适合的道路。相比之下,AutoSceneGen 85 使用代码设计的过滤器,根据仿真文档和 ICL 选择场景描述中有价值的部分,并将场景示例添加到提示中。然后,基于代码的验证器会传输并验证 GPT-4 的输出,该输出直接生成与 CARLA 兼容的 DSL 风格配置代码。生成的场景随后用于评估运动规划器的性能。++(几个案例)++
闭环情景生成:
最近的研究通过引入使用大语言模型的闭环场景生成来解决静态数据集的局限性。闭环场景能够验证多智能体的交互以及自我反应行为。
ProSim 86 提出了一个可提示的闭环仿真框架,其中使用目标点、路线草图、动作标签和自然语言指令等提示来引导智能体的行为。Llama3.1-8B 通过 LoRA 进行微调以生成策略令牌,一个轻量级策略模块在 Waymo 仿真器中以闭环方式展开智能体的轨迹。在 LLM-attacker 87 中,提出了一种对抗场景生成方法。它利用基于 Llama3.1-8B 的三个协调模块(初始化、反思和修改)来通过 CoT 识别并优化对抗性车辆行为。这些模块迭代生成和调整攻击者的轨迹,以与自车发生碰撞。他们的框架在闭环设置中使用 Waymo 开放数据集通过强化学习进行训练。相比之下,CRITICAL 89 专注于自车策略学习,而不依赖对抗性智能体。它通过 LangChain 69 将 Mistral-7B 集成到 HighwayEnv 环境 88 的标准强化学习循环中。他们的 LLM 用于生成多样化的场景配置,例如车辆密度、车辆数量,并用于塑造安全相关奖励,从而使策略在不同条件下的学习更加稳健。++(几个案例)++
这些工作共同展示了互补的策略:ProSim 实现了细粒度的控制和交互性,LLM-Attacker 专注于对抗性测试,而 CRITICAL 支持由大型语言模型引导的训练环境。未来的研究可以通过将这些范式统一到一个框架中,从而支持多样化的行为建模、对抗性稳健性以及可控的训练环境,从中受益。++(总结与未来)++
图像数据集生成:
现实世界的相机数据集在自动驾驶研究中被广泛使用,但通常缺乏生成特定测试用例所需的多样性和可编辑性。为了解决这一问题,近期的研究探索了基于语言引导的已记录图像编辑方法。
ChatSim 90 引入了一个与 GPT-4 协作的多智能体框架,其中每个大型语言模型(LLM)智能体根据自然语言指令处理特定的场景编辑任务,例如视点变更、车辆操作、资产插入和运动规划。ChatSim 利用神经渲染和光照估计来实现使用外部数字资产的逼真多摄像机场景合成。++(一个案例)++
ADAS测试场景生成:
为了评估ADAS系统的性能,有必要将抽象的功能场景(通常来源于法规或规范)转化为可执行的测试用例。近期的研究利用大型语言模型(LLM)来自动化这一过程,通过从文本中提取结构和语义,并生成用于模拟器的脚本。++(介绍)++
关于使用大型语言模型(LLMs)生成ADAS测试场景的开创性论文之一是Guzay等人 91 的研究,他们使用GPT-4和示例学习(ICL)将监管描述转换为与SUMO兼容的XML文件。在此基础上,TARGET 66 引入了一个多阶段提示方法,利用GPT-4将交通规则解析为CARLA的领域特定语言(DSL),其中使用了链式思维(CoT)和示例学习(ICL)。然后,一个规则到脚本生成器生成场景脚本。Petrovic等人 92 将这一方向扩展到处理ADAS测试拓扑和标准化文档。测试拓扑被转换为包含环境、传感器和执行器配置等元素的元模型。标准化文档则使用LLMs解析为对象约束语言(OCL)。基于组合的元模型、OCL约束以及特定测试描述,LLM(例如GPT-4或Llama 3)用于生成DSL测试场景,然后在CARLA中进行仿真。在一种更数据驱动的方法中,SoVAR 94 通过从NHTSA 76 报告中提取结构化属性,使用GPT-4重建碰撞场景,并通过约束求解生成轨迹和仿真脚本,最终通过API调用生成LGSVL 93 兼容的、侧重现实性的测试场景。相比之下,LeGEND 67 采用自上而下的方法:它将报告抽象为功能场景,通过两阶段GPT-4流程将其转化为逻辑DSL表示,并应用多目标搜索生成多样且关键的场景。++(几个案例)++
Text2Scenario 95 引入了一个基于 SOTIF 框架的标准化分层场景库,并结合 GPT-4 使用多阶段提示(CoT、ICL、SC)从自由形式描述中生成逻辑场景。生成的逻辑场景随后通过代码转换为 OpenScenario 格式,并在 CARLA 中进行仿真。最后,Zhou 等人 96 聚焦于车道保持系统,使用 Llama 3.1 和提示模板从与 UNECE R157 对齐的描述中提取场景元素。这些描述被结构化后,通过 OpenXOntology 和 OpenDRIVE 转换为 OpenScenario DSL 文件,然后在 VTD 仿真环境中进行仿真。++(一个案例)++
虽然基于大型语言模型的框架能够有效地根据事故报告和法规生成ADAS测试场景,但它们往往过于强调罕见的极端案例 67, 94,而忽视了对更广泛测试至关重要的常见驾驶场景。目前,我们还没有纳入常规测试案例并利用来自 OpenStreetMap(OSM)或 SUMO 的实际地图,以增强场景的多样性和真实性。++(局限)++
C. 基于大型语言模型的情景分析
最近的研究探索了将大型语言模型(LLMs)作为情景分析工具和方法的使用。一个关键挑战是,LLMs主要设计用于处理自然语言输入,而驾驶情景通常使用结构化数据格式定义,例如DSL脚本或具有预定义语法的传感器输出。这导致了情景信息的表示方式与LLMs的操作方式之间的不匹配。弥合这一差距对于利用语言模型有效地解读驾驶情景至关重要。我们将现有工作分为三个关键领域,并在表3中列出了具有代表性的工作。++(引出情景分析)++
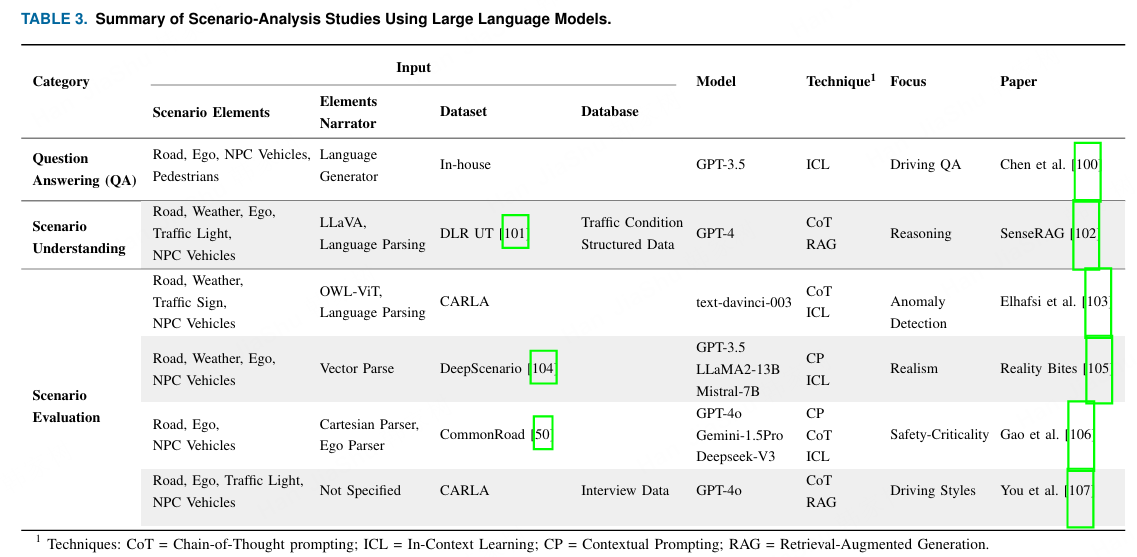
技术:CoT = 思维链提示;ICL = 上下文学习;CP = 上下文提示;RAG = 检索增强生成。
问答 (QA):
将大语言模型(LLM)应用于AD场景分析需要特定领域的知识,而通用的预训练模型可能缺乏这些知识。为了弥补这一差距,使用定制数据集进行微调至关重要。描述驾驶场景的问答数据集有助于LLM理解结构化的驾驶环境,并支持诸如轨迹规划和决策制定等下游任务。++(知识)++
一个显著的例子是100,该文献中,作者使用GPT-3.5自动生成具有驾驶场景的问答数据集。借助结构化语言生成器,他们将自有数据集中向量化的场景数据,包括车辆位置、速度和距离,转换为自然语言。通过使用ICL和预定义的驾驶规则,他们的模型生成多样化、具上下文感知的问答对,以反映真实的驾驶情境。100的数据集主要关注感知和预测。++(一个例子)++
场景理解:
在这里,LLM处理结构化的传感器或模拟器数据,例如代理状态、道路布局和交通信号,以支持场景描述(简明描述)和推理(捕捉意图和上下文的连贯叙述)等任务。++(理解)++
SenseRAG 102 引入了一个基于 RAG 的框架,利用 DLR 城市交通数据集 101 进行场景理解。他们使用视觉语言模型(VLM)将交通状况生成文本描述,然后将其映射到结构化数据库中,包括天气、城市和交通参与者的附加结构化信息。通过使用链式思维(CoT)提示和结构化查询语言(SQL)查询生成,GPT-4 可以检索并推理这些数据,以改进感知并增强轨迹预测。++(一个例子)++
情景评估:
近期的研究展示了大型语言模型(LLMs)如何通过对结构化仿真数据或转换为自然语言的场景图像进行推理,来支持驾驶场景的评估。这包括对异常检测、场景真实性、关键安全性和驾驶行为的评估。Elhafsi 等人 103 使用 LLMs 检测语义场景异常。他们的场景使用 OpenAI 的 text-davinci-003 进行评估,评估时通过链式思维(CoT)和少量示例学习(ICL)进行提示。《Reality Bites》 105 是最早评估的工作之一LLM 在评估场景真实性方面的推理能力。它将 XML 格式的 DeepScenario 104 数据转换为自然语言,并使用 ICL 提示与 GPT-3.5、Llama2-13B 和 Mistral-7B 等模型来判断与真实驾驶条件的一致性。Gao 等人 106 提出了一个框架,用于分析 CommonRoad 50 环境中驾驶场景的安全关键性。他们将结构化场景数据转换为自然语言,并通过 CP、CoT 和 ICL 提示 LLM 来评估场景的安全关键性,并推断智能体的风险等级。同时,他们通过修改识别出的对抗车辆轨迹生成安全关键场景。与此同时,You 等人 107 专注于整体驾驶评估,将访谈和模拟数据转换为用于 RAG 的结构化知识数据库。在他们的框架中,GPT-4o 根据汇总的上下文(包括场景级信息,如天气、自车数据以及周围交通参与者)对驾驶风格(谨慎、激进)和驾驶表现等级进行分类。++(多个情景评估的案例)++
总体而言,基于大型语言模型的场景评估仍然依赖于大量令牌的提示和人工设计的提示。新兴的推理模型,如 OpenAI GPT-5 和 Gemini 2.5 Pro,可能实现更高效的零样本方法。
D. ++局限性与未来方向++
我们对基于大型语言模型(LLM)的场景生成与分析的审查显示,许多现有方法在很大程度上依赖提示策略,如表2和表3所总结的那样。相应框架的有效性往往取决于人工设计的提示。为减轻这种依赖,近期一些工具如DSPy 108 提供了由AI驱动的提示优化框架,能够根据用户定义的评估指标自动生成与任务匹配的提示。另一个有前景的方向涉及VOLUME,它利用先进的推理模型,例如OpenAI的GPT-o1和DeepSeek-R1,这些模型提供更强的零样本推理能力,并可能减少对手工提示的依赖。
此外,未来的研究应探索超越单轮提示的方法,采用交互式、基于对话的生成。将大型语言模型(LLM)构建为类似聊天机器人的代理,可以让用户迭代地定义情景需求,从而合成定制化、符合约束的情景,而不是依赖静态输出。
++基于大语言模型的情景生成:++
基于仿真的场景生成与现实世界验证之间仍存在显著差距。弥合这一差距需要开发与实际安全标准(如 SOTIF)相一致的 ADAS 测试场景。通过利用大语言模型(LLM)的推理能力,未来的系统可以直接从文本描述和测试规范生成功能性和逻辑性场景。这将有助于创建具有挑战性的、安全关键的极端情况,并增强生成场景在现实世界测试和系统验证中的适用性。
++基于大型语言模型的情景分析:++
大型语言模型(LLMs)也越来越多地被用于理解和分析驾驶场景。虽然出现了许多创新的框架,但一个主要的限制在于计算效率低下。由于大多数大型语言模型是基于文本输入的,因此来自激光雷达、图像和雷达等传感器的数据必须首先通过叙述器或中间模块转换为自然语言描述,如表3所示。这个预处理步骤增加了延迟并提高了输入的复杂性。此外,提高分析质量通常需要复杂的提示策略,例如链式思维推理,进一步使实时部署变得复杂。为了解决这些挑战,一个有前景的做法是对大语言模型(LLM)进行情景理解任务的微调,从而避免依赖复杂的提示。然而,这一方向目前受到缺乏大规模、高质量情景问答数据集和评估基准的限制:大多数研究集中在框架验证,而不是数据集的创建。
问题: 大语言模型的输入和输出都是文本信息,如何理解场景信息甚至输入输出图像、视频?
1. 输入侧文本化:将场景信息转换为LLM可理解的文本描述
文中多个框架使用中间模块将非文本数据"翻译"成文本或结构化数据,供LLM处理。
例1:场景分析中的"解说员"(Narrator)
在 LLM-based Scenario Analysis 部分(第10页),论文明确指出:"Since most LLMs operate on textual inputs, sensor data ... must first be converted into natural language descriptions using narrators or intermediate modules, as shown in Table 3."
表3 中多篇论文的"Input"列列出了如 "Language Generator", "Vector Parse", "Cartesian Parser" 等模块,其作用正是将轨迹、传感器数据等转换为文本。
例2:利用VLM作为视觉"前端"
- 在 SenseRAG 框架(第10页)中,流程是:"use a VLM to generate traffic condition descriptions into textual descriptions, which are then mapped to a structured database"。这里,VLM充当了将视觉信息文本化的"解说员"。
2. 输出侧可执行化:LLM生成控制仿真器的脚本或代码
LLM的输出并非最终图像/视频,而是能驱动仿真器生成这些内容的程序代码。
例1:生成领域特定语言脚本
在 ChatScene (第7页)中,方法的核心是:"translate textual safety-critical descriptions into domain-specific language (DSL) scripts such as Scenic for CARLA "。LLM输出的是 Scenic脚本,由CARLA仿真器执行后,才呈现为3D场景视频。
在 ADAS测试生成 (第10页)中,TARGET 和 Petrovic et al. 等方法均使用LLM来"generate DSL test scenarios " 或 "CARLA-compatible scenario scripts"。
例2:生成仿真配置文件
- ChatSUMO (第9页)的工作流程是:LLM "translates these parameters into SUMO configurations"。输出是仿真平台SUO的配置文件,从而生成交通流场景。
总结线索 :原文虽未在第三章开篇集中阐明,但通过后续大量实例表明,LLM在驾驶场景中扮演的是**"语义理解与规划中心"** 的角色。它通过前端模块(如VLM、解析器)接收文本化后的场景信息 ,经过推理后,输出结构化的、机器可执行的指令(脚本、代码) ,最终由仿真引擎或渲染器生成可视化的图像、视频或交互场景。这构成了一个完整的"文本作为中介"的流水线。
**改进点1:**应该做好场景生成、情景分析等的定义,说明LLM模型在这些任务和各个案例中的具体作用。