
金仓数据库中包含各种数据库对象,常见的KingBase对象有:数据库、模式、表、索引、视图、存储过程、存储函数和触发器等等。
这里将介绍金仓数据库中常见的数据库对象以及如何使用它们。
| 视频讲解如下 |
|---|
| 【赵渝强老师】国产金仓数据库的数据库对象 |
一、 数据库与模式
数据库本身也是一个KingBase的数据库对象。数据库对象中包含其他所有的数据库对象,如:模式、表、视图、索引等等。使用命令create database可以创建一个新的数据库,下面展示了该命令的格式:
sql
CREATE DATABASE name
[ WITH ] [ OWNER [=] user_name ]
[ TEMPLATE [=] template ]
[ ENCODING [=] encoding ]
[ LC_COLLATE [=] lc_collate ]
[ LC_CTYPE [=] lc_ctype ]
[ TABLESPACE [=] tablespace_name ]
[ ALLOW_CONNECTIONS [=] allowconn ]
[ CONNECTION LIMIT [=] connlimit ]
[ IS_TEMPLATE [=] istemplate ]一个数据库包含一个或多个模式(Schema),模式中又包含了表、函数及操作符等数据库对象。创建新数据库时,KingBase会自动创建名为public的模式。使用命令create schema可以创建一个新的模式,下面展示了该命令的格式:
sql
CREATE SCHEMA schema_name [ AUTHORIZATION role_specification ] [ schema_element [ ... ] ]
CREATE SCHEMA AUTHORIZATION role_specification [ schema_element [ ... ] ]
CREATE SCHEMA IF NOT EXISTS schema_name [ AUTHORIZATION role_specification ]
CREATE SCHEMA IF NOT EXISTS AUTHORIZATION role_specification
其中 role_specification 可以是:
user_name
| CURRENT_USER
| SESSION_USER在了解到数据库与模式的概念后,下面通过具体的操作来演示如何创建和使用它们。
(1)创建一个新的数据库dbtest。
sql
scott=# create database dbtest;(2)查看已存在的数据库列表。
sql
scott=# \l
# 输出的信息如下:
数据库列表
名称 | 拥有者 | 字元编码 | 校对规则 | Ctype | ICU 排序 | 存取权限
-----------+--------+----------+-------------+-------------+----------+-------------------
dbtest | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | |
kingbase | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | |
scott | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | |
security | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | |
template0 | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | | =c/system +
| | | | | | system=CTc/system
template1 | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | | =c/system +
| | | | | | system=CTc/system
test | system | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | |
(7 行记录)(3)切换到数据库dbtest。
sql
scott=# \c dbtest
您现在以用户名"system"连接到数据库"dbtest"。(4)查看数据库dbtest中的模式。
sql
dbtest=# \dn
# 输出的信息如下:
架构模式列表
名称 | 拥有者
------------------+--------
anon | system
dbms_job | system
dbms_scheduler | system
dbms_sql | system
kdb_schedule | system
perf | system
public | system
src_restrict | system
sys_hm | system
sysaudit | system
sysmac | system
wmsys | system
xlog_record_read | system
(13 行记录)
# 这里的public的模式是创建数据库对象的默认模式。(5)创建一个新的模式。
sql
dbtest=# create schema firstschema;(6)重新查看数据库dbtest中的模式。
sql
dbtest=# \dn
# 输出的信息如下:
架构模式列表
名称 | 拥有者
------------------+--------
anon | system
dbms_job | system
dbms_scheduler | system
dbms_sql | system
firstschema | system
kdb_schedule | system
perf | system
public | system
src_restrict | system
sys_hm | system
sysaudit | system
sysmac | system
wmsys | system
xlog_record_read | system
(14 行记录)二、 创建与管理表
表是一种非常重要的数据库对象。金仓数据库的数据都是存储在表中。KingBase的表是一种二维结构,由行和列组成。表有列组成,列有列的数据类型。下面通过具体的步骤来演示如何操作金仓数据库的表。这些操作包括创建表、查看表、修改表和删除表。
(1)创建一张新的表test2.
sql
dbtest=# create table test2(id int,name varchar(32),age int);
# 由于创建表时没有指定模式的名称,因此表将创建在public模式下。
# 如果要在指定的模式下创建表,可以使用下面的语句:
dbtest=# create table firstschema.test2(id int,name varchar(32),age int);(2)查看表的结构。
sql
dbtest=# \d test2
# 输出的信息如下:
数据表 "public.test2"
栏位 | 类型 | 校对规则 | 可空的 | 预设
------+----------------------------+----------+--------+------
id | integer | | |
name | character varying(32 char) | | |
age | integer | | | (3)在表中增加一个字段。
sql
dbtest=# alter table test2 add gender varchar(1) default 'M';
# 这里增加了一个gender字段用于表示性别,默认是"M"。(4)重新查看表的结构。
sql
dbtest=# \d test2
# 输出的信息如下:
数据表 "public.test2"
栏位 | 类型 | 校对规则 | 可空的 | 预设
--------+----------------------------+----------+--------+--------------
id | integer | | |
name | character varying(32 char) | | |
age | integer | | |
gender | character varying(1 char) | | | 'M'::varchar(5)修改表将gender字段的长度改为10个字符。
sql
dbtest=# alter table test2 alter gender type varchar(10);(6)删除gender字段。
sql
dbtest=# alter table test2 drop column gender;(7)删除表test2。
sql
dbtest=# drop table test2;
三、 在查询时使用索引
数据库查询是数据库的主要功能之一,最基本的查询算法是顺序查找(linear search)时间复杂度为O(n),显然在数据量很大时效率很低。优化的查找算法如二分查找(binary search)、二叉树查找(binary tree search)等,虽然查找效率提高了。但是各自对检索的数据都有要求:二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构。所以在数据之外,数据库系统还维护着满足特定查找算法的数据结构。这些数据结构以某种方式指向数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构就是索引。金仓数据库官方对索引的定义为:索引(Index)是帮助KingBase高效获取数据的数据结构。索引是一种数据结构。金仓数据库默认的索引类型是B树索引。下图是一颗简单的B树,可见它与二叉树最大的区别是它允许一个节点有多于2个的元素,每个节点都包含key和数据,查找时可以使用二分的方式快速搜索数据。
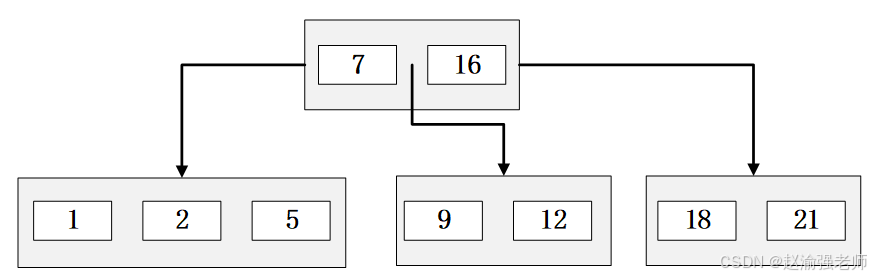
在了解到了KingBase索引的基本知识以后,下面将通过具体的步骤演示来说明如何在KingBase中创建索引,并且在查询语句中使用它。
(1)查看scott数据库中部门表dept和员工表emp上的索引信息。
sql
scott=# select index_name,index_type,table_name,status
from user_indexes where table_name in ('DEPT','EMP');
# 输出的信息如下:
index_name | index_type | table_name | status
------------+------------+------------+--------
DEPT_PKEY | BTREE | DEPT | VALID
EMP_PKEY | BTREE | EMP | VALID
(2 行记录)
# user_indexes是一个视图,可以通过它获取某个用户创建的索引信息。(2)使用create index命令在员工表emp的薪水sal字段上创建完全索引。
sql
scott=# create index index_full on emp using btree(sal);
# 完全索引会基于该字段上的所有值创建索引。
# 同时,在创建索引的时候会进行锁表的操作,可以使用 CIC (create index concurrently),
# 但创建索引的时间相对较长。例如:
scott=# create index concurrently index1 on emp using btree(sal);(3)下面的语句将在员工表上创建一个部分索引。
sql
scott=# create index index_part on emp using btree(sal) where sal<3000;
# 部分索引是对于表的部分数据创建索引。
# 如果发现表的某一部分数据查询次数较多时,可以考虑在这部分数据上创建一个部分索引。
# 部分索引相较于完全索引,查询的性能将得到提高,并且部分索引文件所占的空间也会小于全索引。(4)在员工表emp的员工姓名ename上创建表达式索引。
sql
scott=# create index index_exp on emp(lower(ename));
# 对于表达式索引的维护代价比较高,因为在每一行插入或更新时需要重新计算相应表达式的值,
# 但是针对于表达式索引在查询时的效率更高,因为表达式的值会直接存储在索引中。(5)使用explain语句查看SQL查询时的执行计划。
sql
scott=# explain select * from emp where lower(ename) like 'king';
# 输出的信息如下:
QUERY PLAN
----------------------------------------------------
Seq Scan on emp (cost=0.00..1.21 rows=1 width=42)
Filter: (lower((ename)::text) ~~ 'king'::text)
(2 行记录)
# 从输出的执行计划可以看出,此时并没有使用到表达式索引。
# 这是由于KingBase并不能强制使用特定的索引,或者完全阻止KingBase进行Seq Scan的顺序扫描。
# 但可以通过将参数enable_seqscan设置为 off的方式让KingBase尽可能避免执行某些扫描类型,
# 但这样的方式多用于开发和调试中。(6)禁止金仓数据库使用顺序扫描。
sql
scott=# set enable_seqscan = off;(7)重新使用explain语句查看SQL查询时的执行计划。
sql
scott=# explain select * from emp where lower(ename) like 'king';
# 输出的信息如下:
QUERY PLAN
----------------------------------------------------------------------
Index Scan using index_exp on emp (cost=0.14..8.16 rows=1 width=42)
Index Cond: (lower((ename)::text) = 'king'::text)
Filter: (lower((ename)::text) ~~ 'king'::text)
(3 行记录)四、 使用视图简化查询语句
当SQL的查询语句比较复杂并且需要反复执行,如果每次都重新书写该SQL语句显然不是很方便。因此金仓数据库数据库提供了视图用于简化复杂的SQL语句。视图(View)是一种虚表,其本身并不包含数据。它将作为一个select语句保存在数据字典中的。视图依赖的表叫做基表。通过视图可以展现基表的部分数据;视图数据来自定义视图的查询中使用的基表。在金仓数据库中创建视图的基本语法格式如下:
sql
CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ] [ RECURSIVE ] [ FORCE ] VIEW name [ ( column_name [, ...] ) ]
[ WITH ( view_option_name [= view_option_value] [, ... ] ) ]
[ BEQUEATH { CURRENT_USER | DEFINER } ]
AS query
[ WITH { [ CASCADED | LOCAL ] CHECK OPTION } | READ ONLY ]在了解的视图的作用后,下面通过具体的步骤来演示如何使用视图。
(1)基于员工表emp创建视图。
sql
scott=# create or replace view view1
as
select * from emp where deptno=10;
# 视图也可以基于多表进行创建,例如:
scott=# create or replace view view2
as
select emp.ename,emp.sal,dept.dname
from emp,dept
where emp.deptno=dept.deptno;(2)查看视图view2的结构。
sql
scott=# \d view2
# 输出的信息如下:
视图 "public.view2"
栏位 | 类型 | 校对规则 | 可空的 | 预设
-------+----------------------------+----------+--------+------
ename | character varying(10 char) | | |
sal | integer | | |
dname | character varying(10 char) | | | (3)从视图中查询数据。
sql
scott=# select * from view2;
# 输出的信息如下:
ename | sal | dname
--------+------+------------
MILLER | 1300 | ACCOUNTING
CLARK | 2450 | ACCOUNTING
KING | 5000 | ACCOUNTING
SCOTT | 3000 | RESEARCH
JONES | 2975 | RESEARCH
SMITH | 800 | RESEARCH
ADAMS | 1100 | RESEARCH
FORD | 3000 | RESEARCH
WARD | 1250 | SALES
TURNER | 1500 | SALES
ALLEN | 1600 | SALES
BLAKE | 2850 | SALES
MARTIN | 1250 | SALES
JAMES | 950 | SALES
(14 行记录)(4)通过视图执行DML操作,例如:给10号部门员工涨100块钱工资。
sql
scott=# update view1 set sal=sal+100;
# 并不是所有的视图都可以执行DML操作。在视图定义时含义以下内容,视图则不能执行DML操作:
# 1. 查询子句中包含distinct和组函数
# 2. 查询语句中包含group by子句和order by子句
# 3. 查询语句中包含union 、union all等集合运算符
# 4. where子句中包含相关子查询
# 5. from子句中包含多个表
# 6. 如果视图中有计算列,则不能执行update操作
# 7. 如果基表中有某个具有非空约束的列未出现在视图定义中,则不能做insert操作(5)创建视图时使用WITH CHECK OPTION约束 。
sql
scott=# create or replace view view3
as
select * from emp where sal<1000
with check option;
# WITH CHECK OPTION表示对视图所做的DML操作,不能违反视图的WHERE条件的限制。(6)在view3上执行update操作。
sql
scott=# update view3 set sal=2000;
# 此时将出现下面的错误信息:
# ERROR: 新行违反了视图"view3"的检查选项
# DETAIL: 失败, 行包含(7369, SMITH, CLERK, 7902, 1980/12/17, 2000, null, 20).