一、数据获取
本文使用"胡歌 - 电影 - 豆瓣搜索1.xlsx"数据集,该数据集是从豆瓣电影网站上爬取获得,一共112条数据代表胡歌参演的112部电影,有电影名称、上映时间、豆瓣评分、详细信息和电影简介5个字段,其中详细信息字段包括电影的导演、编剧、主演等信息。本文将在该数据集上搭建知识图谱与问答系统,可以实现对胡歌参演电影和胡歌搭档演员等问题的查询。
使用大模型提取结构化数据(结构化数据提取.py)。由于大模型提取数据存在损失,得到结果109条(结构化数据提取结果.xlsx)。
python
# pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
# pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple/
# pip install kor -i https://pypi.tuna.tsinghua.edu.cn/simple/
# pip install langchain-openai -i https://pypi.tuna.tsinghua.edu.cn/simple/
from langchain_openai import ChatOpenAI
from kor.extraction import create_extraction_chain
from kor.nodes import Object, Text, Number
import pandas as pd
# 读入数据
df = pd.read_excel('胡歌 - 电影 - 豆瓣搜索1.xlsx') # 替换为你的文件路径
# 定义Prompt
prompt = {
"示例引导": '''参考以下示例,从文本中提取结构化信息,包括电影名称、上映时间、豆瓣评分、导演、编剧、主演,若无明确信息则不填写,若有多条字段则以顿号分隔。'''
}
# 定义示例
movie_examples = [
(
'''
电影名称:猎场
上映时间:2017
豆瓣评分:5.7
详细信息:
导演:姜伟
编剧:姜伟
主演:胡歌/菅纫姿/陈龙/孙红雷/张嘉益/祖峰/李强/胡兵/万茜/章龄之/徐阁/王海燕/柯蓝/罗海琼/朱杰/李乃文/贾静雯/曹炳琨/王茜/董勇/冯恩鹤/赵立新/杜江/颜丙燕/刘天池/徐飒/曹卫宇/周放/王小毅/马元/王乐君/苑冉/林熙越/张晞临/高峰/张陆/张子嫣/秦雅思/屈刚/张建栋/张宏震/蒋君/孙之鸿/何波/仁龙/刘玥心/王孝天/冯晖更多...
类型:剧情
制片国家/地区:中国大陆
语言:汉语普通话
首播:2017-11-06(中国大陆)
集数:52
单集片长:45分钟
又名:欲望猎场/GameofHunting
IMDb:tt5236276
电影简介:
初出茅庐的郑秋冬十分渴望事业的成功,有些急功近利。受到现实的残酷惩罚后,郑秋冬并不气馁,在精神导师刘量体的指导帮助下,发愤图强,为成为高级猎头而努力拼搏。而后,林拜的出现,给郑秋冬带来了非凡机遇的同时,也再次检验了他的内心。郑秋冬诚信为本、努力上进和绝不轻言放弃的人生态度,让林拜敬佩,并与之成为挚友。在猎取各类高级人才的过程中,郑秋冬以超凡的工作能力和优秀的品质克服了各种挫折和难关,赢得了一个个客户的信任。事业渐入佳境的同时,罗伊人、熊青春和贾衣玫的接连出现,也让郑秋冬懂得什么是真正的爱。最终,郑秋冬凭借坚持纯粹、高尚的诚实信条,获得了事业璀璨荣耀的同时,也赢得了爱人的倾心。
''',
{
"电影名称": "猎场",
"上映时间": "2017",
"豆瓣评分": "5.7",
"导演": "姜伟",
"编剧": "姜伟",
"主演": "胡歌、菅纫姿、陈龙、孙红雷、张嘉益、祖峰、李强、胡兵、万茜、章龄之、徐阁、王海燕、柯蓝、罗海琼、朱杰、李乃文、贾静雯、曹炳琨、王茜、董勇、冯恩鹤、赵立新、杜江、颜丙燕、刘天池、徐飒、曹卫宇、周放、王小毅、马元、王乐君、苑冉、林熙越、张晞临、高峰、张陆、张子嫣、秦雅思、屈刚、张建栋、张宏震、蒋君、孙之鸿、何波、仁龙、刘玥心、王孝天、冯晖"
}
)
]
temperature = [0.1]
results = []
# 遍历每行数据
for row_idx in range(len(df)):
# 拼接当前行的影视信息
movie_name = df.iloc[row_idx]['电影名称']
release_time = df.iloc[row_idx]['上映时间']
douban_rate = df.iloc[row_idx]['豆瓣评分']
detail_info = df.iloc[row_idx]['详细信息']
movie_info = df.iloc[row_idx]['电影简介']
text = f"电影名称:{movie_name}\n上映时间:{release_time}\n豆瓣评分:{douban_rate}\n详细信息:\n{detail_info}\n电影简介:\n{movie_info}"
print(f"第{row_idx}行:{text}")
# 遍历不同Prompt类型和Temperature
for prompt_key, prompt_value in prompt.items():
for temp in temperature:
# 初始化大模型
llm = ChatOpenAI(
model="qwen-plus",
temperature=temp,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="123456" # 替换为你的API Key
)
# 加载示例
schema_examples = movie_examples if prompt_key == "示例引导" else []
# 定义影视信息的Schema
schema = Object(
id="movie",
description=prompt_value,
attributes=[
Text(id="电影名称", description="影视的中文名称"),
Text(id="上映时间", description="播出/上映的日期"),
Text(id="豆瓣评分", description="豆瓣评分"),
Text(id="导演", description="影视的导演姓名,顿号分隔"),
Text(id="编剧", description="影视的编剧姓名,顿号分隔"),
Text(id="主演", description="影视的主要演员姓名,多演员用顿号分隔"),
],
examples=schema_examples
)
# 创建提取链并调用
chain = create_extraction_chain(llm, schema)
try:
response = chain.invoke(text)
output = response.get('data', {}).get('movie', [])
except Exception as e:
print(f"提取失败:{e}")
output = []
# 整理提取结果
output_dict = output[0] if output else {}
extract_result = {
"电影名称": output_dict.get("电影名称", ""),
"上映时间": output_dict.get("上映时间", ""),
"豆瓣评分": output_dict.get("豆瓣评分", ""),
"导演": output_dict.get("导演", ""),
"编剧": output_dict.get("编剧", ""),
"主演": output_dict.get("主演", "")
}
print(extract_result)
# 构造结果行
result_row = {
**extract_result
}
results.append(result_row)
# 保存结果到Excel
result_df = pd.DataFrame(results)
result_df.to_excel("结构化数据提取结果.xlsx", index=False, engine="openpyxl")二、基于neo4j平台的知识图谱对话系统
(一)连接neo4j并导入数据
双击docker,在powershell中输入:docker run --publish=7475:7474 --publish=7688:7687 `--volume="//c/Users/zhang/Desktop/专业综合实践/data:/data" `--volume="//c/Users/zhang/Desktop/专业综合实践/import:/import" `docker.1ms.run/library/neo4j,在浏览器中输入http://localhost:7475,默认账号密码均为neo4j,修改密码为12345678。
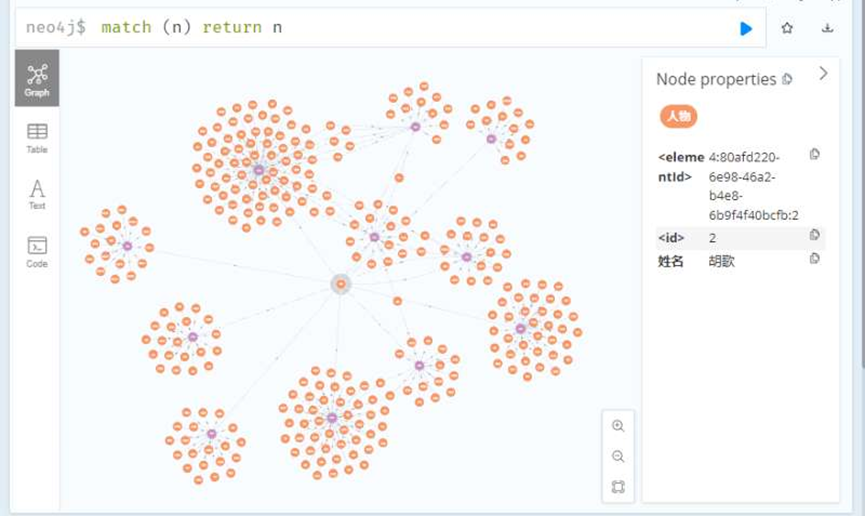
导入数据(neo4j_data_import.py),显示前300个节点。
python
# pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install neo4j -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
import pandas as pd
from neo4j import GraphDatabase, basic_auth
class Excel2Neo4j_Movie:
def __init__(self, neo4j_uri, neo4j_user, neo4j_password):
"""初始化Neo4j连接"""
self.driver = GraphDatabase.driver(
neo4j_uri,
auth=basic_auth(neo4j_user, neo4j_password)
)
def close(self):
"""关闭Neo4j连接"""
if self.driver:
self.driver.close()
def import_movie_data(self, excel_path, sheet_name=0):
"""导入影视数据到Neo4j"""
# 1. 读取Excel数据
print("开始读取Excel数据...")
df = pd.read_excel(
excel_path,
sheet_name=sheet_name,
usecols=['电影名称', '上映时间', '豆瓣评分', '导演', '编剧', '主演']
)
# 数据清洗:空值填充为"无"
df = df.fillna("无")
print(f"成功读取 {len(df)} 条影视数据")
# 2. 批量导入Neo4j
with self.driver.session() as session:
for index, row in df.iterrows():
# 提取单条数据(去除首尾空格)
movie_name = str(row['电影名称']).strip()
release_time = str(row['上映时间']).strip()
douban_score = str(row['豆瓣评分']).strip()
directors = [d.strip() for d in str(row['导演']).split('、') if d.strip()]
screenwriters = [s.strip() for s in str(row['编剧']).split('、') if s.strip()]
actors = [a.strip() for a in str(row['主演']).split('、') if a.strip()]
# 跳过电影名称为空的数据
if not movie_name or movie_name == "无":
print(f"跳过第{index + 1}行:电影名称为空")
continue
# ========== 1. 创建/匹配"电影"节点 ==========
create_movie_cypher = """
MERGE (m:电影 {名称: $movie_name})
SET m.上映时间 = $release_time,
m.豆瓣评分 = $douban_score
"""
session.run(
create_movie_cypher,
movie_name=movie_name,
release_time=release_time,
douban_score=douban_score
)
# ========== 2. 处理"导演"关系 ==========
for director in directors:
if director != "无":
director_cypher = """
MERGE (p:人物 {姓名: $director})
MERGE (m:电影 {名称: $movie_name})
MERGE (p)-[:导演]->(m)
"""
session.run(director_cypher, director=director, movie_name=movie_name)
# ========== 3. 处理"编剧"关系 ==========
for screenwriter in screenwriters:
if screenwriter != "无":
screenwriter_cypher = """
MERGE (p:人物 {姓名: $screenwriter})
MERGE (m:电影 {名称: $movie_name})
MERGE (p)-[:编剧]->(m)
"""
session.run(screenwriter_cypher, screenwriter=screenwriter, movie_name=movie_name)
# ========== 4. 处理"主演"关系 ==========
for actor in actors:
if actor != "无":
actor_cypher = """
MERGE (p:人物 {姓名: $actor})
MERGE (m:电影 {名称: $movie_name})
MERGE (p)-[:主演]->(m)
"""
session.run(actor_cypher, actor=actor, movie_name=movie_name)
# 进度提示
if (index + 1) % 10 == 0:
print(f"已处理 {index + 1} 条数据...")
print("影视数据导入Neo4j完成!")
# ==================== 主程序 ====================
if __name__ == "__main__":
# 配置信息
NEO4J_URI = "bolt://localhost:7688" # Neo4j连接地址
NEO4J_USER = "neo4j" # Neo4j用户名
NEO4J_PASSWORD = "12345678" # Neo4j密码
EXCEL_PATH = "结构化数据提取结果.xlsx" # 你的Excel文件路径
# 执行导入
try:
importer = Excel2Neo4j_Movie(NEO4J_URI, NEO4J_USER, NEO4J_PASSWORD)
importer.import_movie_data(EXCEL_PATH)
except Exception as e:
print(f"导入出错:{str(e)}")
finally:
importer.close()(二)自然语言查询
运行程序(neo4j_communicate.py),可以查询胡歌主演电影相关内容。
python
# pip install dashscope -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install neo4j -i https://pypi.tuna.tsinghua.edu.cn/simple
from neo4j import GraphDatabase, basic_auth
import dashscope
from dashscope import Generation
# Neo4j配置
NEO4J_URI = "bolt://localhost:7688"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "12345678"
# 阿里云通义大模型配置
DASHSCOPE_API_KEY = "123456" # 替换为你的API Key
class Neo4jNLQAService:
def __init__(self):
"""
初始化问答服务
"""
# 初始化Neo4j驱动
self.neo4j_driver = GraphDatabase.driver(
NEO4J_URI,
auth=basic_auth(NEO4J_USER, NEO4J_PASSWORD)
)
# 配置通义大模型
dashscope.api_key = DASHSCOPE_API_KEY
def close(self):
"""关闭Neo4j连接"""
if self.neo4j_driver:
self.neo4j_driver.close()
def _get_kg_prompt_template(self):
"""Cypher生成提示词模板"""
return """
你是Neo4j Cypher专家,需根据自然语言生成查询影视知识图谱的Cypher语句,规则如下:
1. 节点/关系定义:
- 电影节点:标签`电影`,属性`名称`、`上映时间`、`豆瓣评分`
- 人物节点:标签`人物`,属性`姓名`
- 关系:人物-[:导演]->电影、人物-[:编剧]->电影、人物-[:主演]->电影
2. 生成规则:
- 仅返回Cypher语句,无任何解释/多余文字
- 用中文标签/属性(如:电影、名称)
- 仅用MATCH查询,禁止CREATE/DELETE等修改语句
- 结果返回清晰别名(如m.名称 AS 电影名称)
用户查询:{natural_query}
"""
def natural_language_to_cypher(self, natural_query):
"""自然语言转Cypher语句"""
prompt = self._get_kg_prompt_template().format(natural_query=natural_query)
try:
response = Generation.call(
model="qwen-plus",
messages=[{"role": "user", "content": prompt}],
result_format='text',
temperature=0.1, # 低随机性保证稳定
max_tokens=1000
)
if response.status_code == 200:
# 清理Cypher语句(去除多余符号/文字)
cypher = response.output.text.strip()
cypher = cypher.replace("`", "").replace("Cypher", "").replace("cypher", "")
return cypher
else:
raise Exception(f"大模型调用失败:{response.status_code} - {response.message}")
except Exception as e:
raise Exception(f"转Cypher出错:{str(e)}")
def execute_cypher(self, cypher):
"""执行Cypher并返回格式化结果"""
try:
with self.neo4j_driver.session() as session:
result = session.run(cypher)
records = [dict(record) for record in result]
return {
"status": "success",
"data": records,
"count": len(records)
}
except Exception as e:
return {
"status": "error",
"message": f"执行Cypher出错:{str(e)}",
"data": []
}
def result_to_natural_language(self, natural_query, cypher_result):
"""将Cypher查询结果转换为自然语言回答"""
# 构造结果转自然语言的提示词
prompt = f"""
你是智能问答助手,需根据用户的查询和Neo4j查询结果,生成流畅的自然语言回答:
1. 回答要简洁、准确,贴合查询意图
2. 无结果时说明"抱歉,未查询到相关信息"
3. 仅返回回答内容,无多余解释
用户查询:{natural_query}
Neo4j查询结果:{cypher_result['data']}
"""
try:
response = Generation.call(
model="qwen-plus",
messages=[{"role": "user", "content": prompt}],
result_format='text',
temperature=0.3,
max_tokens=500
)
if response.status_code == 200:
return response.output.text.strip()
else:
return f"生成回答失败:{response.message}"
except Exception as e:
return f"生成回答出错:{str(e)}"
def nlqa(self, natural_query):
"""
自然语言问答主流程:
自然语言 → Cypher → 执行查询 → 自然语言回答
"""
# 1. 自然语言转Cypher
try:
cypher = self.natural_language_to_cypher(natural_query)
print(f"生成的Cypher语句:\n{cypher}")
except Exception as e:
return {
"status": "error",
"cypher": "",
"raw_result": {},
"natural_answer": f"Cypher生成失败:{str(e)}"
}
# 2. 执行Cypher
raw_result = self.execute_cypher(cypher)
# 3. 结果转自然语言回答
natural_answer = self.result_to_natural_language(natural_query, raw_result)
return {
"status": raw_result["status"],
"cypher": cypher,
"raw_result": raw_result,
"natural_answer": natural_answer
}
# ==================== 测试示例 ====================
if __name__ == "__main__":
print("\n===== 影视知识图谱问答测试 =====")
movie_nlqa = Neo4jNLQAService()
# 影视类自然语言查询示例
movie_queries = [
"查询胡歌主演的所有电影名称和上映时间?",
"查询胡歌主演的电影的导演有哪些?",
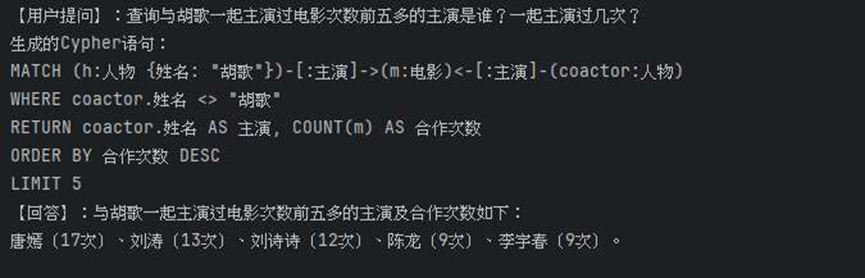
"查询与胡歌一起主演过电影次数最多的主演是谁?",
"查询与胡歌一起主演过电影次数前五多的主演是谁?一起主演过几次?"
]
for query in movie_queries:
print(f"\n【用户提问】:{query}")
result = movie_nlqa.nlqa(query)
print(f"【回答】:{result['natural_answer']}")
movie_nlqa.close()结果展示如下:



三、基于TuGraph平台的知识图谱对话系统
(一)连接TuGraph并导入数据
TuGraph启动与new4j的启动类似,启动docker,在powershell中输入命令docker run -d -v D:\tugraph_test:/mnt -p 7070:7070 -p 7687:7687 docker.1ms.run/tugraph/tugraph-runtime-ubuntu18.04 lgraph_server
打开浏览器,地址栏输入localhost:7070可以进入TuGraph平台登录界面,默认账号admin,密码73@TuGraph,需要修改密码(这里无法跳过,修改为123456)。
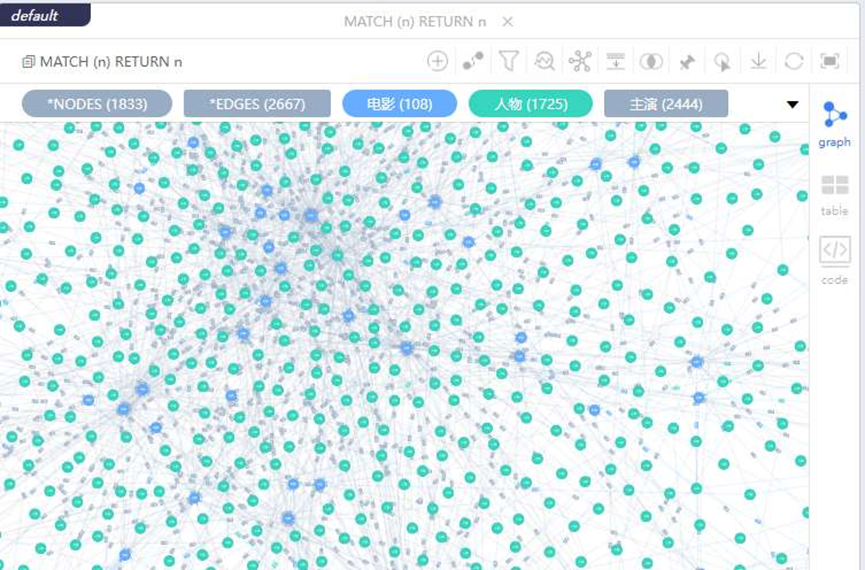
运行文件(tugraph_import_data.py)得到movie_nodes.csv,person_nodes.csv,screenwriter_relations.csv,director_relations.csv,actor_relations.csv,手动导入数据。
python
import pandas as pd
# 读取Excel
df = pd.read_excel("结构化数据提取结果.xlsx")
df = df.fillna("无").apply(lambda x: x.str.strip() if x.dtype == "object" else x)
# ==================== 1. 生成电影节点文件 ====================
movie_nodes = df[['电影名称', '上映时间', '豆瓣评分']].drop_duplicates()
movie_nodes[':LABEL'] = '电影' # TuGraph批量导入的标签列
movie_nodes.rename(columns={'电影名称': '名称:ID'}, inplace=True) # ID列必须加:ID
movie_nodes.to_csv("movie_nodes.csv", index=False, encoding="utf-8")
print("电影节点文件 movie_nodes.csv 生成完成")
# ==================== 2. 生成人物节点文件 ====================
all_persons = set()
for col in ['导演', '编剧', '主演']:
for val in df[col]:
if val != "无":
all_persons.update([p.strip() for p in val.split('、')])
person_nodes = pd.DataFrame({'姓名:ID': list(all_persons), ':LABEL': '人物'})
person_nodes.to_csv("person_nodes.csv", index=False, encoding="utf-8")
print("人物节点文件 person_nodes.csv 生成完成")
# ==================== 3. 拆分生成三类关系文件 ====================
# 3.1 导演关系文件(director_relations.csv)
director_relations = []
for _, row in df.iterrows():
movie = row['电影名称']
for d in row['导演'].split('、'):
if d != "无":
# 注意:START_ID是人物(导演),END_ID是电影,TYPE是关系类型
director_relations.append({
':START_ID': d, # 修正原代码的中文冒号错误
':END_ID': movie,
':TYPE': '导演'
})
dir_df = pd.DataFrame(director_relations)
dir_df.to_csv("director_relations.csv", index=False, encoding="utf-8")
print("导演关系文件 director_relations.csv 生成完成")
# 3.2 编剧关系文件(screenwriter_relations.csv)
screenwriter_relations = []
for _, row in df.iterrows():
movie = row['电影名称']
for s in row['编剧'].split('、'):
if s != "无":
screenwriter_relations.append({
':START_ID': s,
':END_ID': movie,
':TYPE': '编剧'
})
sw_df = pd.DataFrame(screenwriter_relations)
sw_df.to_csv("screenwriter_relations.csv", index=False, encoding="utf-8")
print("编剧关系文件 screenwriter_relations.csv 生成完成")
# 3.3 主演关系文件(actor_relations.csv)
actor_relations = []
for _, row in df.iterrows():
movie = row['电影名称']
for a in row['主演'].split('、'):
if a != "无":
actor_relations.append({
':START_ID': a,
':END_ID': movie,
':TYPE': '主演'
})
act_df = pd.DataFrame(actor_relations)
act_df.to_csv("actor_relations.csv", index=False, encoding="utf-8")
print("主演关系文件 actor_relations.csv 生成完成")(二)自然语言查询
运行代码(tugraph_communicate.py),查询胡歌主演电影相关内容。
python
from neo4j import GraphDatabase, basic_auth, exceptions
from dashscope import Generation
import dashscope
# ==================== 全局配置(请替换为你的实际信息) ====================
# TuGraph连接配置(兼容Neo4j Bolt协议)
TUGRAPH_BOLT_URI = "bolt://localhost:7687" # TuGraph Bolt地址(默认7687)
TUGRAPH_USER = "admin" # TuGraph用户名
TUGRAPH_PASSWORD = "123456" # TuGraph密码
TUGRAPH_GRAPH_SPACE = "default" # TuGraph图空间
# 阿里云通义大模型配置
DASHSCOPE_API_KEY = "123456" # 替换为实际API Key
MODEL_NAME = "qwen-plus" # 模型版本(qwen-turbo/qwen-plus)
class TuGraphNLQAService:
"""基于TuGraph的自然语言问答服务"""
def __init__(self):
"""
初始化服务
"""
# 1. 配置通义大模型
dashscope.api_key = DASHSCOPE_API_KEY
# 2. 用Neo4j驱动连接TuGraph(Bolt协议兼容)
self.driver = GraphDatabase.driver(
TUGRAPH_BOLT_URI,
auth=basic_auth(TUGRAPH_USER, TUGRAPH_PASSWORD)
)
# 测试TuGraph连接
try:
self.driver.verify_connectivity()
print(f"TuGraph {TUGRAPH_GRAPH_SPACE} 图空间连接成功")
except exceptions.Neo4jError as e:
raise Exception(f"TuGraph连接失败:{str(e)}")
def close(self):
"""关闭TuGraph连接"""
if self.driver:
self.driver.close()
print("TuGraph连接已关闭")
def _get_tugraph_session(self):
"""获取指定图空间的Session"""
return self.driver.session(database=TUGRAPH_GRAPH_SPACE)
def _get_cypher_prompt(self, natural_query):
"""根据图谱类型构建专属Cypher生成提示词"""
prompt = f"""
你是TuGraph OpenCypher生成专家,需严格按以下规则生成查询语句:
【图谱结构】
- 节点:电影(属性:名称、上映时间、豆瓣评分)、人物(属性:姓名)
- 关系:人物-[:导演]->电影、人物-[:编剧]->电影、人物-[:主演]->电影
【生成规则】
1. 仅返回纯Cypher语句,无任何解释/多余文字
2. 使用中文标签/属性(如:电影、名称)
3. 仅用MATCH查询,禁止CREATE/DELETE等修改语句
4. 结果返回清晰别名(如m.名称 AS 电影名称)
5. 适配TuGraph语法,无扩展关键字
用户自然语言查询:{natural_query}
"""
return prompt.strip()
def _get_answer_prompt(self, natural_query, cypher_result):
"""构建结果转自然语言回答的提示词"""
prompt = f"""
你是智能问答助手,需根据用户查询和TuGraph查询结果,生成流畅自然的中文回答:
【规则】
1. 回答简洁、准确,贴合用户查询意图
2. 无结果时回复:"抱歉,未查询到相关信息"
3. 仅返回回答内容,无多余解释/格式
用户查询:{natural_query}
TuGraph查询结果:{cypher_result['data']}
"""
return prompt.strip()
def natural_language_to_cypher(self, natural_query):
"""自然语言转TuGraph兼容的Cypher语句"""
if not natural_query or natural_query.strip() == "":
raise Exception("自然语言查询不能为空")
# 1. 构建专属提示词
prompt = self._get_cypher_prompt(natural_query)
# 2. 调用通义大模型生成Cypher
try:
response = Generation.call(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
result_format="text",
temperature=0.1, # 低随机性保证结果稳定
max_tokens=1000
)
# 3. 清洗Cypher语句(移除多余符号)
if response.status_code == 200:
cypher = response.output.text.strip()
cypher = cypher.replace("`", "").replace("Cypher", "").replace("cypher", "")
cypher = cypher.replace("'", "\\'") # 转义单引号避免语法错误
print(f"\n生成的Cypher语句:\n{cypher}")
return cypher
else:
raise Exception(f"大模型调用失败:{response.status_code} - {response.message}")
except Exception as e:
raise Exception(f"自然语言转Cypher失败:{str(e)}")
def execute_cypher(self, cypher):
"""执行TuGraph Cypher并返回格式化结果"""
if not cypher or cypher.strip() == "":
return {"status": "error", "message": "Cypher语句为空", "data": [], "count": 0}
try:
with self._get_tugraph_session() as session:
result = session.run(cypher)
records = [dict(record) for record in result] # 格式化结果
return {
"status": "success",
"message": "查询成功",
"data": records,
"count": len(records)
}
except exceptions.Neo4jError as e:
return {
"status": "error",
"message": f"Cypher执行失败:{str(e)}",
"data": [],
"count": 0
}
def result_to_natural_language(self, natural_query, cypher_result):
"""将TuGraph查询结果转换为自然语言回答"""
# 构建生成回答的提示词
prompt = self._get_answer_prompt(natural_query, cypher_result)
try:
response = Generation.call(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
result_format="text",
temperature=0.1, # 适度随机性让回答更自然
max_tokens=500
)
if response.status_code == 200:
answer = response.output.text.strip()
return answer
else:
return f"生成回答失败:{response.message}"
except Exception as e:
return f"生成回答出错:{str(e)}"
def nlqa(self, natural_query):
"""
自然语言问答主流程:
自然语言 → Cypher → 执行查询 → 自然语言回答
"""
# 1. 自然语言转Cypher
try:
cypher = self.natural_language_to_cypher(natural_query)
except Exception as e:
return {
"status": "error",
"cypher": "",
"raw_result": {},
"natural_answer": f"{str(e)}"
}
# 2. 执行Cypher查询
raw_result = self.execute_cypher(cypher)
# 3. 结果转自然语言回答
natural_answer = self.result_to_natural_language(natural_query, raw_result)
# 4. 组装最终结果
return {
"status": raw_result["status"],
"cypher": cypher,
"raw_result": raw_result,
"natural_answer": f"{natural_answer}"
}
# ==================== 测试示例 ====================
if __name__ == "__main__":
print("\n===== 影视知识图谱问答测试 =====")
movie_nlqa = TuGraphNLQAService()
# 影视类自然语言查询示例(覆盖不同场景)
movie_queries = [
"查询胡歌主演的所有电影名称和上映时间?",
"查询胡歌主演的电影的导演有哪些?",
"查询与胡歌一起主演过电影次数最多的主演是谁?",
"查询与胡歌一起主演过电影次数前五多的主演是谁?一起主演过几次?"
]
for query in movie_queries:
print(f"\n【用户提问】:{query}")
result = movie_nlqa.nlqa(query)
print(f"【回答】:{result['natural_answer']}")
movie_nlqa.close()结果展示如下:




四、收获与意见
通过对《专业综合实践》课程的学习,我学会了使用Neo4j和Tugraph图数据库,包括可视化平台的登录使用、创建schema导入数据、调用python接口、搭建对话系统等功能,还学会了调用大模型接口对自然语言处理转换。对此课程暂无意见。