【在某些特定领域场景中(如医学领域,科研领域),LLMs缺乏特定领域的知识,或者无法正确回忆事实和知识,这会导致幻觉。(幻觉指的是模型生成的文本毫无意义,或者与提供的输入不一致)从而产生不可想象的后果。(如在医学领域,无法正确对患者的症状推荐相应的药物,从而影响生命安全。)所以本文基于此,旨在教会大型语言模型从知识图谱中搜索领域知识。】
文章目录
摘要
大型语言模型(LLMs),如ChatGPT和GPT-4,因其新兴能力和泛化性而能够解决多种任务。然而,LLMs有时缺乏特定领域的知识,这会导致在推理过程中出现幻觉(hallucination)。在一些先前的研究中,通过在外部知识库中检索知识来训练额外的模块(如图神经网络GNNs),旨在解决缺乏特定领域知识的问题。然而,整合额外模块存在两个问题:1)在遇到新领域时需要重新训练这些模块;2)由于LLMs的强大检索能力未被充分利用,这会成为瓶颈。
在本文中,我们提出了一种范式,称为知识求解器(Knowledge Solver, KSL),通过利用LLMs自身强大的泛化能力,教会它们从外部知识库中搜索必要的知识。具体来说,我们设计了一个简单而有效的提示(prompt),将检索过程转化为一个多跳决策序列,从而以零样本(zero-shot)的方式赋予LLMs搜索知识的能力。此外,KSL能够提供完整的检索路径,从而增加LLMs推理过程的可解释性。
我们在三个数据集上进行了实验:常识问答(CommonsenseQA)、开放书籍问答(OpenbookQA)和医学问答(MedQA-USMLE),发现我们的方法显著提高了LLMs基线的性能。
引言
最近,像ChatGPT这样的大型语言模型因其通用能力而受到了研究人员和从业者的广泛关注。例如,足够大的语言模型能够在零样本情况下很好地完成不同任务,如文本总结、机器翻译和问答。然而,在某些场景中,LLMs缺乏特定领域的知识,或者无法正确回忆事实和知识,这会导致幻觉。幻觉指的是模型生成的文本毫无意义,或者与提供的输入不一致。
从知识库中检索相关文本是一种经典的增强语言模型性能的方法,例如提高生成质量和生成文本的事实性。通常,检索模块被用来找到与查询最相关的文档,然后将输入文本和检索到的文档以特定方式结合起来输入到模型中。受此启发,一些方法利用检索到的文本来增强LLMs。然而,仅仅依赖于嵌入之间的相似性只会使模型学习到浅层特征,而不是理解语义,这反过来又阻碍了模型搜索真正有用的知识。相反,知识图谱(KGs)是清晰、逻辑性强且优越的知识载体。因此,有效地利用KGs应该能够增强LLMs在需要知识的任务上的性能。
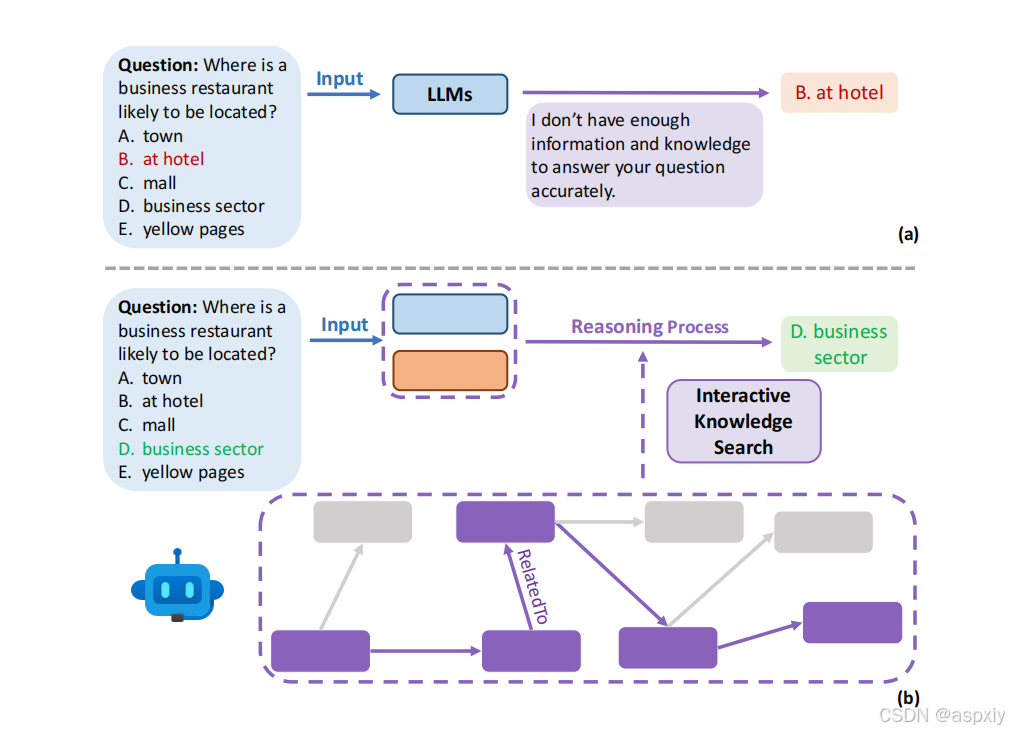 图1:知识求解器。图中展示了在问答任务中,普通语言模型(a)和零样本知识求解器(b)的对比示例。我们的方法通过利用语言模型自身的泛化能力,帮助其搜索执行任务所需的必要知识。图中紫色部分表示语言模型选择的正确路径中的节点和关系。
图1:知识求解器。图中展示了在问答任务中,普通语言模型(a)和零样本知识求解器(b)的对比示例。我们的方法通过利用语言模型自身的泛化能力,帮助其搜索执行任务所需的必要知识。图中紫色部分表示语言模型选择的正确路径中的节点和关系。
因此,有一些研究工作利用知识图谱帮助LLMs进行预测。然而,这些方法都需要在检索到的知识上训练额外的知识感知模块,如图神经网络(GNNs)。这存在两个缺点:1)在遇到新领域时需要重新训练;2)由于LLMs的强大检索能力未被充分利用,这会成为瓶颈。
在本文中,我们提出了知识求解器(KSL),以解决这些缺点,教会LLMs自己从外部知识库中搜索知识。具体来说,我们将从知识图谱中搜索必要知识的过程简化为一个多跳决策序列。在每一步中,我们将知识图谱中的局部信息转化为文本提示(包括LLMs选择的历史路径),基于此,LLMs在上下文中选择相关知识以完成任务。整个过程类似于人类在互联网上搜索以实现某些目标。此外,基于LLMs选择的完整路径,我们可以解释LLMs的整个决策过程。这允许在出现坏案例时进行分析,而这种能力在以前的黑盒检索方法中是不存在的。
我们在三个数据集上评估了我们的方法:CommonsenseQA、OpenbookQA和MedQA-USMLE,这些数据集都需要知识推理。KSL在零样本和微调设置中都显著提高了LLMs基线的性能。
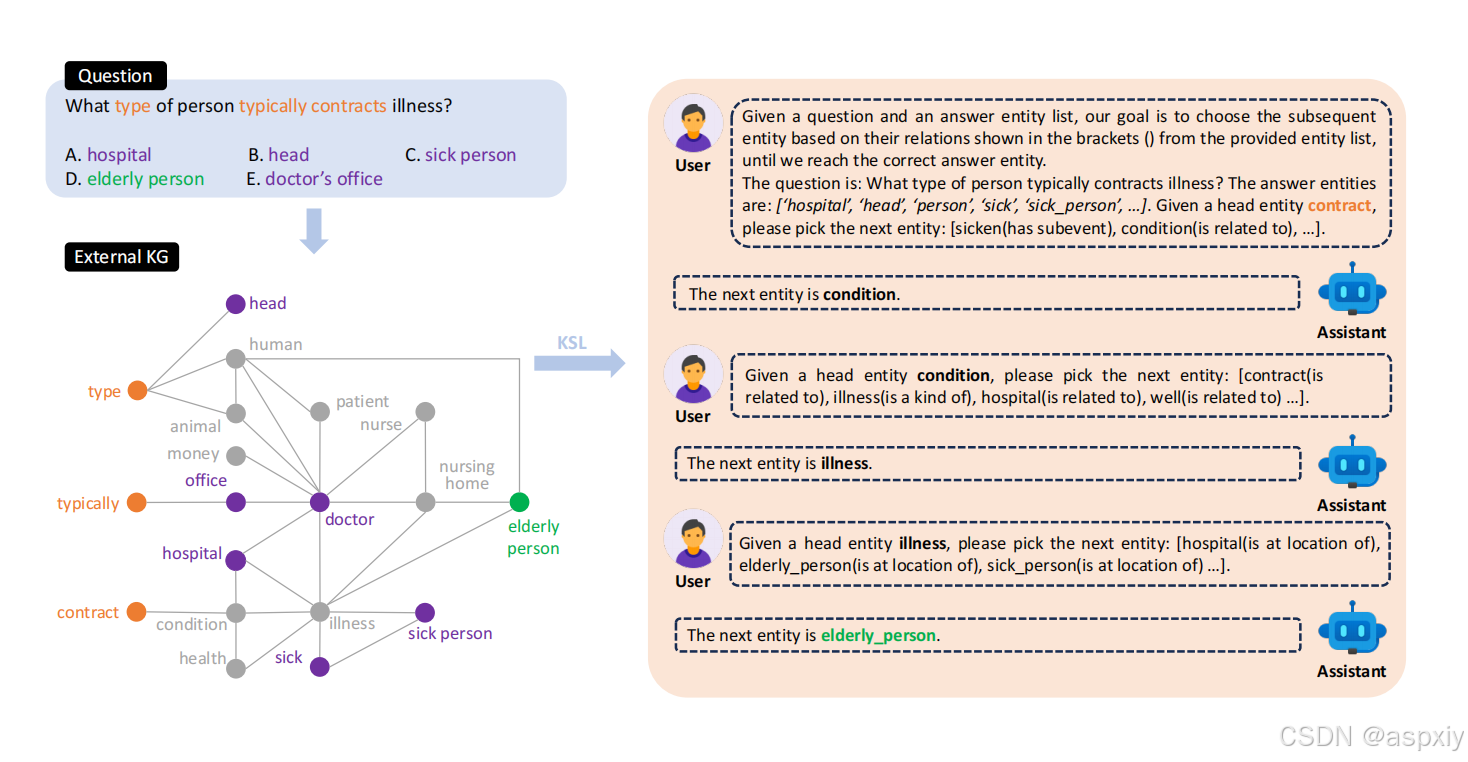 图2:方法概述。对于每个问题和答案选项对,我们检索相关的知识子图,并将其编码为文本提示,直接注入到语言模型中,以帮助它们完成需要知识的任务。在这种问答场景中,语言模型与提供的外部知识进行交互,以选择正确的答题路径。
图2:方法概述。对于每个问题和答案选项对,我们检索相关的知识子图,并将其编码为文本提示,直接注入到语言模型中,以帮助它们完成需要知识的任务。在这种问答场景中,语言模型与提供的外部知识进行交互,以选择正确的答题路径。
我们的主要贡献总结如下:
1.我们提出了知识求解器(KSL),这是第一个利用LLMs自己从知识图谱中索相关知识的范式。
2.我们的范式KSL能够在零样本情况下显著提高LLMs在知识需求任务上的性能,而无需额外模块和训练。
3.KSL能够为LLMs的整个推理过程提供可解释性。
4.当计算负担可承受时,使用我们的特别构建的数据集对LLMs进行微调,借助知识图谱,可以进一步提升LLMs的性能。
相关工作
大型语言模型(LLMs)
预训练语言模型(PLMs)在大规模数据集上进行训练,使其能够理解上下文并生成文本。近年来,像GPT-1、BERT、XLNet、RoBERTa和ALBERT。这样的预训练语言模型已被广泛应用于各种自然语言处理(NLP)任务。对于问答任务,这些模型被大量现有框架所利用。
大型语言模型(LLMs)的快速发展带来了新的创新突破,其巨大的规模和容量令人瞩目。基础LLMs,如T5、GPT-3、PaLM、GPTJ、LLaMA、GLM、BLOOM、RWKV、MOSS和LLaMA 2,在大规模数据集上进行训练,以捕捉通用语言模式。此外,指令微调的LLMs,如InstructGPT、Flan-PaLM、Flan-T5、BLOOMZ、Alpaca和Vicuna,旨在遵循用户指令。基于人类反馈的强化学习(RLHF)LLMs,如ChatGPT和GPT-4,结合了强化学习技术,以基于人类反馈优化模型性能。然而,在某些场景中,LLMs缺乏执行相关任务的特定领域知识。我们提出的范式KSL,教会LLMs自己从外部知识库中搜索知识,以帮助模型实现目标。
知识库问答(KBQA)
知识库问答(KBQA)专注于使机器能够使用从知识库(KBs)中检索到的相关知识来回答问题。KBQA的方法大致可以分为两类:(i)基于文本检索的方法和(ii)基于知识图谱的方法。我们的研究与第二组一致,重点是将知识图谱整合到LLMs中。
基于文本检索的方法已在广泛的NLP任务中进行了实验。与其直接微调预训练语言模型以增强语言任务性能,越来越多的研究者转向更轻量级的方法,即冻结模型参数并增加小型可训练模块。这些轻量级微调技术包括适配器调整(adapter tuning)、提示调整(prompt tuning)、前缀调整(prefix tuning),以及如输入依赖提示调整、冻结阅读器和LM递归等更复杂的架构。
算法 1 知识求解器零样本推理:

【知识求解器(Knowledge Solver, KSL)的零样本推理过程具体步骤如下:】
输入:
问题实体集合 Vq :包含与问题相关的实体 {vq1, vq2, ..., vqn}。
答案实体集合 Va:包含与答案相关的实体 {va1, va2, ..., van}。
输出:
最终选择的答案实体 vhi。
算法逻辑:
定义一个函数 REL_EXTR:
输入:当前头实体 vh 和子图 Gsub。
功能:提取与头实体 vh 直接相连的所有尾实体及其关系,并将它们存储在列表 tail_relation_list 中。
输出:返回包含所有尾实体及其关系的列表。主算法流程:
步骤9:根据问题实体集合 Vq 和答案实体集合 Va,从知识图谱中检索子图 Gsub。
步骤10:从问题实体集合 Vq 中随机选择一个实体作为初始头实体 vh1。
步骤11:初始化轮次计数器 round 为0。
步骤12-22:对于每个头实体 vhi,执行以下操作:
如果当前头实体 vhi 属于答案实体集合 Va,则终止循环(找到了答案实体)。
如果达到最大轮次限制 round_maximum,则终止循环。
调用 REL_EXTR 函数,提取当前头实体 vhi 的所有尾实体及其关系。
将提取的尾实体列表输入到LLMs(大型语言模型),由LLMs选择下一个头实体 vh(i+1)。
轮次计数器 round 加1。
步骤23:返回最终选择的头实体 vhi,即答案实体。基于知识图谱的方法也广泛应用于问答领域。KagNet构建了代表问题和答案实体之间路径的模式图,然后使用GCN-LSTM-HPA架构进行编码。为了实现高准确性和有效的模型可扩展性,多跳图关系网络(Multi-hop Graph Relation Network)结合了基于路径的推理可解释性和GNN的可扩展性,增加了结构化的注意力机制。与之不同的是,QA-GNN将QA上下文向量链接到模式图中的主题实体。DRAGON提出了一个用于双向文本和知识图谱整合的自监督模型,而GreaseLM通过分层模态交互融合了PLMs和GNN表示。与之前训练额外模块(如GNNs)的工作不同,我们的方法KSL鼓励LLMs自己从外部知识库中搜索必要的知识。
问题定义
本文旨在帮助LLMs在缺乏特定领域知识时更好地完成知识需求任务。我们选择问答作为评估的知识需求任务。为了缓解缺乏知识的问题,我们启发LLMs与提供的外部知识进行交互,并自发地识别适当的路径以得出正确答案。根据先前的研究,我们将知识图谱定义为一个多重关系图G = (V, E)。其中V是知识图谱中的实体节点集合;E ∈ V × R × V是连接V中节点的边的集合,R表示关系类型的集合。
给定一个问题选项对q, A,我们将问题和选项中提到的实体链接到给定的知识图谱G,并按照先前的研究将所有问题实体表示为Vq ∈ V,答案实体表示为Va ∈ V。然后,我们从知识图谱G中检索子图Gsub = 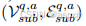 。Gsub包含Vq和Va之间所有k跳路径上的节点。
。Gsub包含Vq和Va之间所有k跳路径上的节点。
方法
如图2所示,我们的方法KSL首先从知识图谱中检索与给定问题选项对q, A相关的子图Gsub。然后,我们将Gsub编码为文本提示TK,注入到LLMs中,这将初始化类似对话的推理过程,鼓励LLMs利用自身能力搜索必要的知识,并引导自己实现最终目标。
算法2:生成训练指令数据集:

算法2:生成训练指令数据集推理过程解释:
输入参数:
Q:一个包含所有问题和答案选项对的序列,形式为Q = {[q1, A1], [q2, A2], ..., [qN, AN]},其中qj是问题,Aj是对应的答案选项。
G:结构化的知识源(知识图谱)。
E:一个编码器,用于将知识图谱的子图(Gsub)转换为文本提示(TK)。
主要步骤:
1. 初始化路径列表:
total_paths = []
用于存储所有问题实体到正确答案实体的路径。
2. 遍历每个问题和答案选项对:
for each [qj, Aj] in Q do
对于每个问题和答案选项对[qj, Aj],执行以下操作:
3. 提取问题和答案选项中的实体:
extract question and answer choices entities Vq and Va
从问题qj和答案选项Aj中提取相关的实体集合Vq(问题实体)和Va(答案实体)。
4. 从知识图谱中检索子图:
retrieve subgraph Gsub from G
根据问题和答案选项中的实体,从知识图谱G中检索相关的子图Gsub。
5. 遍历每个问题实体:
for each question entity vqi in Vq do
对于问题实体集合Vq中的每个实体vqi,执行以下操作:
6. 随机选择一个正确答案选项实体:
randomly select correct answer choice entity vca
从答案选项实体集合Va中随机选择一个正确答案选项实体vca。
7. 找到最短路径:
path = find_shortest_path(Gsub, source=vqi, target=vca)
在子图Gsub中,找到从问题实体vqi到正确答案实体vca的最短路径path。
8. 将路径添加到总路径列表:
total_paths.append(path)
将找到的路径path添加到路径列表total_paths中。
9. 从子图中移除路径上的节点:
remove all nodes on the path except for vca from Gsub
从子图Gsub中移除路径path上的所有节点,但保留正确答案实体vca。
10. 结束问题实体的循环:
end for
11. 结束问题和答案选项对的循环:
end for
12. 初始化训练数据列表:
training_data = []
用于存储生成的训练数据实例。
13. 遍历所有路径:
for each path pi in total_paths do
对于每个路径pi,执行以下操作:
14. 初始化历史记录列表:
hist = []
用于存储路径中节点的历史信息。
15. 遍历路径中的每个节点(除了最后一个节点):
for each node nj in pi except for the last node do
对于路径pi中的每个节点nj(除了最后一个节点),执行以下操作:
16. 创建一个实例:
instance = {}
初始化一个空字典instance,用于存储训练数据实例。
17. 设置指令:
instance["instruction"] = instruction
将指令(instruction)添加到实例中。指令可能是预先定义的,用于指导模型的任务。
18. 设置头实体:
head entity vhj = nj
将当前节点nj作为头实体vhj。
19. 提取尾实体:
tail_entity vtj = entity_extract(Gsub, vhj)
从子图Gsub中提取与头实体vhj相关的尾实体vtj。
20. 提取关系:
relation rhtj = relation_extract(Gsub, vhj, vtj)
从子图Gsub中提取头实体vhj和尾实体vtj之间的关系rhtj。
21. 设置输入:
instance["input"] = E(vhj, hist)
使用编码器E将头实体vhj和历史记录hist转换为文本提示,作为输入input。
22. 设置输出:
instance["output"] = E(vtj)
使用编码器E将尾实体vtj转换为文本提示,作为输出output。
23. 将实例添加到训练数据中:
training_data.append(instance)
将生成的实例instance添加到训练数据列表training_data中。
24. 更新历史记录:
hist.append([instance["input"], instance["output"]])
将当前实例的输入和输出添加到历史记录hist中,用于后续节点的上下文信息。
25. 结束节点循环:
end for
26. 结束路径循环:
end for
27. 返回训练数据:
return training_data
返回生成的训练数据集training_data,用于后续的语言模型训练。知识求解器零样本推理
为了帮助模型完成需要特定领域知识的任务(如问答),我们将外部知识注入到LLMs中。对于每个检索到的子图Gsub,我们将其实体和关系转化为文本提示TK,输入到LLMs中,并利用LLMs强大的泛化能力,激励它们自主搜索必要信息。
给定问题q和答案选项集合A = a1, ..., aN(其中N是答案选项的总数),我们检索Gsub并将其视为外部知识。Gsub包含所有问题实体Vq、所有答案选项实体Va、中间实体以及实体之间的对应关系R。为了初始化LLMs的问答推理过程,我们首先随机选择一个问题实体vq ∈ Vq,然后鼓励LLMs基于自身判断选择一条路径,直到最终达到答案实体va ∈ Va。具体来说,我们可以将LLMs的问答推理过程分解为几轮(总轮数取决于LLMs自身的判断。在实践中,我们将轮数限制设置为Nr)。对于每个问题和答案选项对q, A,这些轮次将形成一条明确的推理路径,这不仅为LLMs补充了特定领域的外部知识,还增加了LLMs的可解释性。
在每一轮中,我们将当前头实体vh以及所有链接的尾实体Vt = vt1, ..., vtN及其对应的关系Rht = rht1, ..., rhtN放入文本提示中,以告知LLMs外部知识的存在。LLMs将根据其参数中隐含的先验知识和以文本提示形式呈现的显式外部知识(如关系)选择最有可能的尾实体作为下一轮的头实体,用于问答。然后,这个实体选择过程将重复进行,直到选择了一个答案实体va。最终,我们根据答案实体va与答案选项a之间的映射关系,确定LLMs选择的答案选项。整个推理过程完全通过文本生成完成,而不是对预定义实体进行分类,因为在许多场景中,我们无法访问LLMs的logits。每一轮的输入文本提示还包括实体选择的完整历史记录,类似于对话。整个推理过程也如算法1所示。
知识求解器微调
当LLMs可访问时,我们可以在外部知识上对它们进行微调,将这些知识转化为LLMs的参数。根据Alpaca,我们利用指令微调对LLMs进行微调。
具体来说,我们使用Alpaca中的类似模板。与一般的指令微调不同,LLMs在零样本情况下被激励遵循用户的指令,我们的主要目标是鼓励LLMs学习特定领域的知识。因此,我们在所有实例中固定指令(实际上,指令可以根据特定领域的知识进行修改)。输入和响应格式与我们在知识求解器零样本推理中所述的相同,我们将每个检索到的子图Gsub转化为多个输入-响应对,从问题实体vq到正确答案选项中的答案实体va。每个输入包含实体选择历史(类似于用户和LLMs之间的对话)、当前头实体、所有连接的尾实体及其对应关系。响应包括正确路径的下一个尾实体。具体来说,对于每个问题和答案选项对q, A,我们遍历所有问题实体vq ∈ Vq,同时保持所有提取路径的分离。构建指令微调数据集的整个过程也如算法2所示。我们的指令微调数据集的示例可以在图3中看到。我们使用LoRA对LLMs进行微调,因为它可以显著减少GPU内存负担。
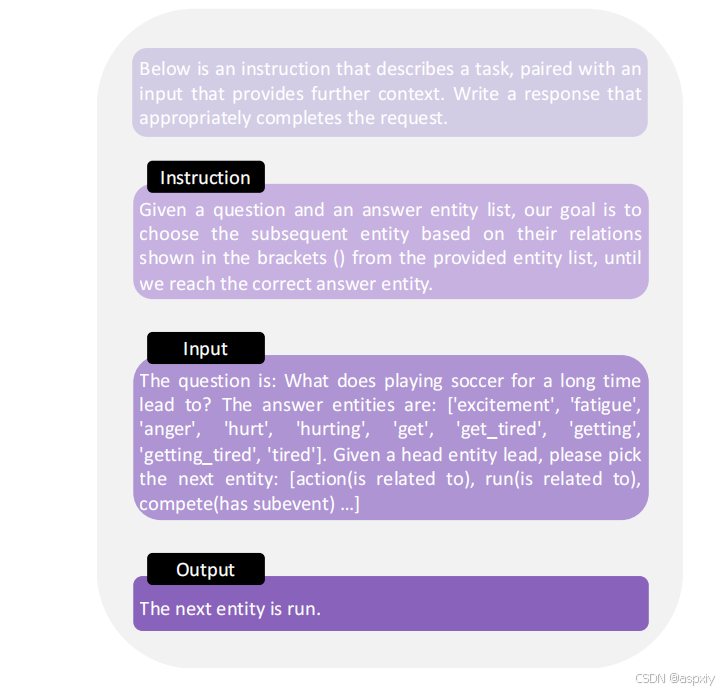
图3:训练示例。我们构建的指令微调数据集中的实例。
对于推理,微调后的KSL使用与零样本知识求解器相同的方式。对于每个问题和答案选项对q, A,我们随机选择一个问题实体vq以初始化推理过程。我们将对所有问题实体的平均结果留作未来研究。
实验
数据集
我们在三个问答数据集上评估我们的方法------知识求解器(KSL):常识问答(CommonsenseQA)、开放书籍问答(OpenbookQA)和医学问答(MedQA-USMLE)。
常识问答(CommonsenseQA):这是一个针对常识推理的问答数据集,包含总共12102个问题。问题生成的方法是从ConceptNet中采样与源概念相关的三个目标概念。每个问题有五个选项,其中三个是由众包工人根据目标概念编写的,另外两个作为干扰项。CommonsenseQA是KGQA(知识图谱问答)领域中最常见的基准数据集之一。本文使用KagNet中原始的数据划分进行预处理。
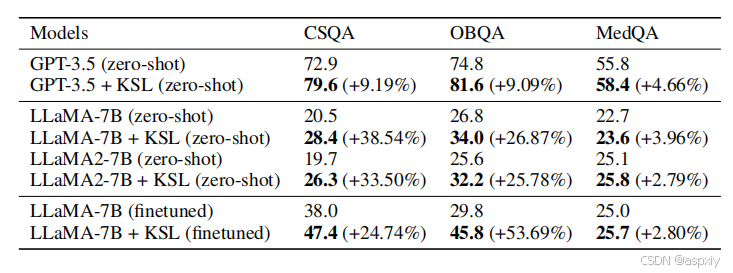
表1:性能评估。我们在三个数据集(CommonsenseQA、OpenBookQA 和 MedQA-USMLE)上报告了语言模型基线以及零样本和微调后的知识求解器(KSL)的准确率。
开放书籍问答(OpenbookQA):该数据集包含大约6000个多项选择题和超过1000个小学水平的科学事实的"开放书籍"。问答过程需要结合科学事实、常识知识和多跳推理能力。本文遵循原始的数据划分。
医学问答(MedQA):这是一个为解决现实世界医学问题而设计的多语言数据集,所有问题和答案均来自专业医学考试。本文专注于USMLE子集,数据来自美国国家医学委员会考试,遵循原始的数据划分。
知识图谱
对于CommonsenseQA和OpenbookQA,我们使用ConceptNet。它通过标记的关系连接普通人类语言中的单词和短语。我们采用MHGRN中的关系设置,包括总共34种多向关系类型。在问题-答案对中提到的所有主题实体之间的路径被找到并作为子图进行锚定。
在MedQA的USMLE数据集中,我们采用了QA-GNN中构建的知识图谱,其中包含来自统一医学语言系统(UMLS)和DrugBank的生物医学词汇。
对于每个问题和答案选项对q, A,我们按照MHGRN中描述的预处理步骤,从结构化的知识图谱G中检索子图Gsub,跳数k = 2。
实现与训练细节
零样本
我们主要使用三个LLMs(GPT-3.5、LLaMA-7B和LLaMA 2-7B)作为基线。对于GPT-3.5,我们调用OpenAI API使用gpt-3.5-turbo-16k。在推理过程中,总轮数Nr的限制设置为5。
微调
我们使用LoRA在8个NVIDIA A40 GPU上对LLaMA-7B进行微调,每个GPU有48GB内存。对于CommonsenseQA,训练集包含114552个实例,开发集包含14391个实例。对于OpenbookQA,训练集包含57458个实例,开发集包含5814个实例。对于MedQA-USMLE,训练集包含13561个实例,开发集包含1677个实例。全局批量大小为128,学习率设置为3e-4。我们在LoRA中将秩r设置为16,α设置为16。dropout概率为0.05。我们微调Transformer中自注意力模块的查询、键、值和输出投影矩阵Wq、Wk、Wv、Wo。输入序列的最大长度为1152。CommonsenseQA和OpenbookQA的微调总轮数为3,MedQA-USMLE为5。我们使用验证损失最低的检查点进行最终测试集推理。
评估指标
对于CommonsenseQA、OpenbookQA和MedQA-USMLE这三个问答数据集,我们遵循先前的研究,使用准确率作为评估指标。然而,由于我们仅进行文本生成,而不是对预定义集合进行分类,因此很难使用传统方法计算准确率。相反,我们调用OpenAI API,将手工制作的提示(详见附录)输入到GPT-4中,以判断LLMs的生成内容是否与真实答案匹配。
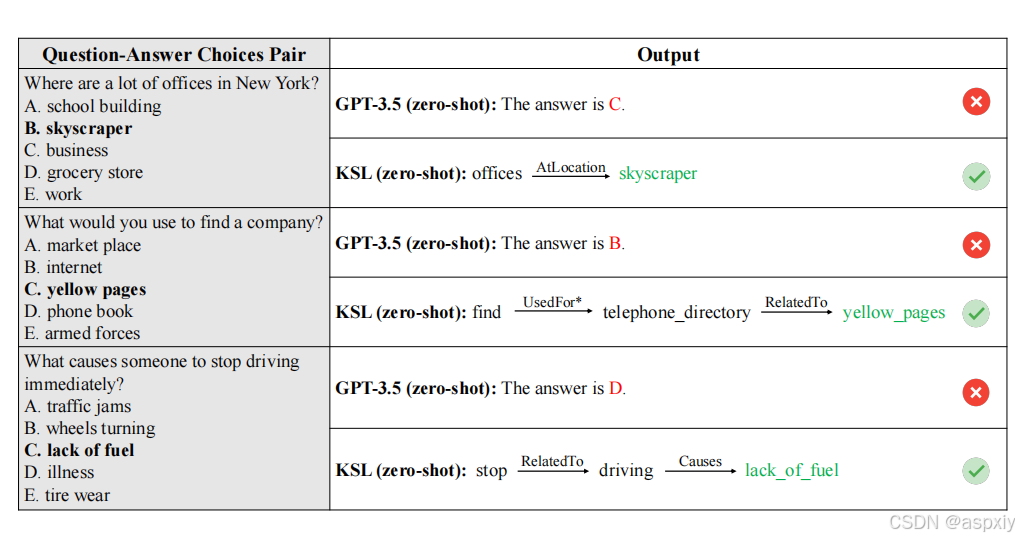
图4:KSL(GPT-3.5)的定性结果。展示了GPT-3.5和零样本KSL(GPT-3.5)在一些示例上的生成回答。加粗的选择表示正确答案。星号()表示关系被反转。*
最终,我们使用GPT-4给出的评分来计算准确率(0表示LLMs的输出完全不相关,而1表示LLMs生成的答案正确匹配真实答案)。
实验结果
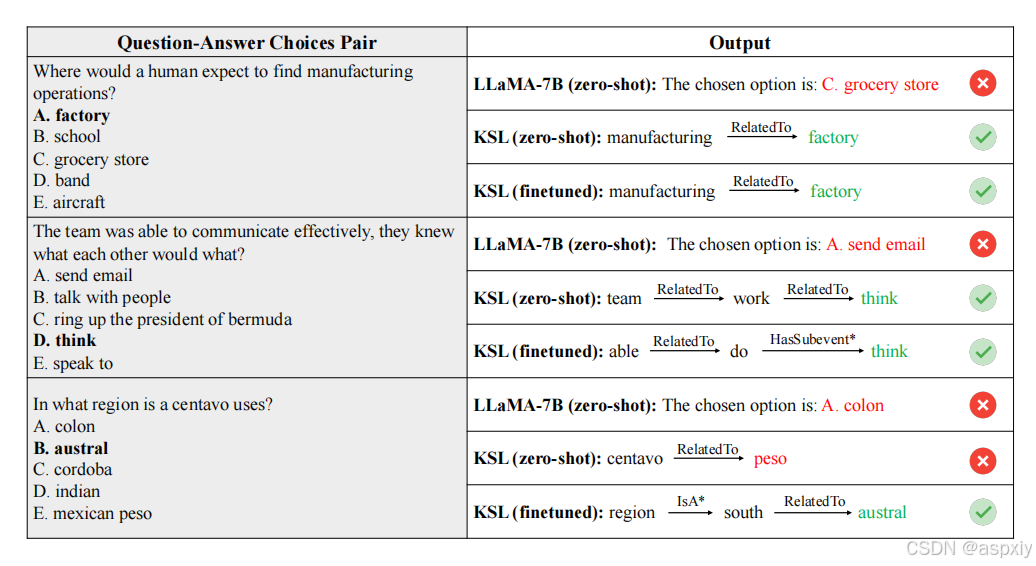
图5:KSL(LLaMA-7B)的定性结果。展示了LLaMA-7B以及零样本/微调后的KSL(LLaMA-7B)在一些示例上的生成回答。加粗的选择表示正确答案。星号()表示关系被反转。*
零样本知识求解器结果:如表1所示,我们的知识求解器(KSL)显著提升了LLMs基线(GPT-3.5、LLaMA-7B和LLaMA 2-7B)的性能,表明:1)我们的方法能够帮助模型更好地完成知识需求任务;2)当提供外部知识时,LLMs具备一定的自主搜索必要信息的能力。为每个需要特定领域知识的场景训练一个适配器将耗费大量的计算和时间成本。相比之下,我们的零样本知识求解器可以利用LLMs自身的新兴能力,在仅提供外部知识的情况下完成特定领域的知识需求任务,教会LLMs与外部知识互动以实现最终目标。
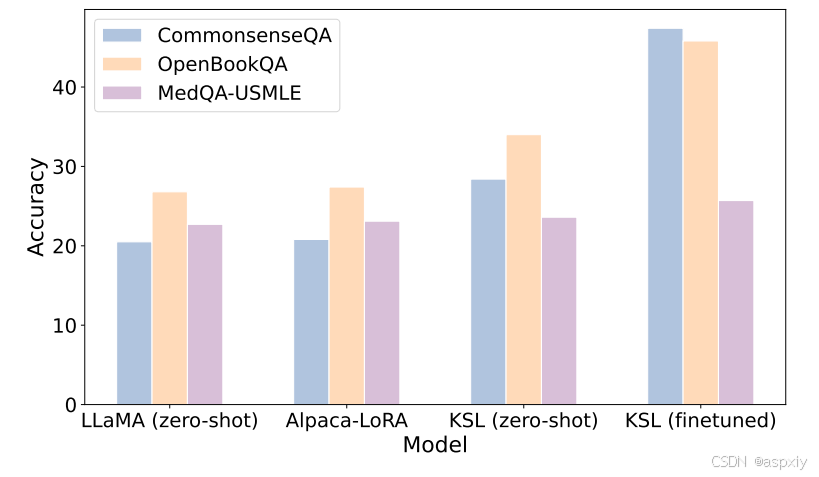
图6:微调后的KSL(LLaMA-7B)的消融实验。我们将我们的KSL与LLaMA和Alpaca-LoRA进行了比较。
微调知识求解器结果:与训练单独的适配器(如GNNs)不同,我们的方法还可以在提供的外部知识上对LLMs进行微调,将知识注入到LLMs的参数中。如表1所示,微调后的KSL(LLaMA-7B)可以进一步提升性能,并在三个数据集上超越微调后的LLaMA-7B。这表明,当计算负担可承受时,我们的方法能够有效地帮助LLMs记忆知识,以完成特定领域的知识需求任务。有趣的是,MedQA-USMLE上的提升并不像CommonsenseQA和OpenbookQA上那样显著。问题可能在于知识图谱不够大,对于许多问题和答案选项对,很难检索到完整的子图。在许多情况下,几个答案实体没有包含在子图中,或者从问题实体到答案实体没有路径。
定性结果
我们在图4和图5中展示了一些定性结果。结果表明,我们的零样本KSL能够帮助LLMs在没有任何额外训练的情况下完成知识需求任务。在提供外部知识的情况下,LLMs可以自主查找必要的知识以实现最终目标。我们的方法可以帮助LLMs纠正它们缺乏相关特定领域知识时的错误。例如,普通的LLaMA-7B^Touvro2023a^不知道在哪里可以找到制造业务,而零样本KSL(LLaMA-7B)可以正确回答这个问题。微调后的KSL(LLaMA-7B)可以进一步提升LLMs解决知识需求任务的能力,例如回答"centavo在哪个地区使用?"这些问题证明了KSL的有效性。
消融研究
如表1所示,微调后的KSL(LLaMA-7B)可以显著提高性能。为了探究这种性能提升主要来源于指令微调本身,还是我们特别构建的知识数据集,我们还在CommonsenseQA(Talmor等人,2018)、OpenBookQA(Mihaylov等人,2018)和MedQA-USMLE(Jin等人,2021)上评估了Alpaca-LoRA(Taori等人,2023),并使用与普通LLaMA-7B(Touvron等人,2023a)相同的推理方法。值得注意的是,Alpaca-LoRA的最大序列长度为512,而我们交互式推理方法的输入序列长度通常超过512。
如图6所示,使用与LLaMA-7B(Touvron等人,2023a)相同的LoRA技术(Hu等人,2021)进行微调的Alpaca-LoRA,其性能与普通LLaMA-7B(Touvron等人,2023a)相当。这表明,我们特别设计的知识数据集是使语言模型在知识密集型任务中受益的主要来源。此外,Alpaca-LoRA(Taori等人,2023)的表现不如我们的零样本KSL(LLaMA-7B)。这表明,通过利用语言模型自身的能力来搜索相关知识是一种有效且高效的方法,可以帮助模型更好地完成知识密集型任务。
结论
在本文中,我们提出了知识求解器(KSL),它可以帮助LLMs在零样本和微调情况下更好地完成特定领域的知识需求任务。在提供外部知识的情况下,LLMs能够利用自身能力搜索必要的知识和信息,以完成相关任务,而无需额外的训练或模块。我们的交互式推理方法不仅可以明确地将知识注入LLMs,还可以引导LLMs解决问题。我们还证明了性能提升主要来源于我们特别设计的推理方法(对于零样本)和任务(对于微调),而不是指令微调。目前,我们交互式推理方法的初始问题实体是随机选择的。我们将如何选择第一个实体以初始化任务的执行留作未来的研究方向。