高并发下的数据扫描策略 和 任务触发架构
之前在某海外社交 App 搞过支付相关业务------你懂的,foreigners + 社交 + 虚拟金币 = 框框充钱停不下来 💰。正是在这种"土豪流水哗哗响"的场景下,我才真正体会到:订单超时取消,不是功能,是底线! 当时调研方案写了一沓草稿(没它我今天真想不起来细节)------再次验证那句老话:好记性不如烂笔头,好架构不如烂代码跑通!
当然,不是所有方案都适合你。
------你要是每天就 10 单,用
Thread.sleep(30*60*1000)都行;------但一旦上亿单,高并发下的超时取消,就是一场"数据与时间的赛跑"。
这套路还被迁移到后面的物流公司做业务,这方案针对其他行业医疗、IoT......凡是"状态+时效"的敏感场景,皆可套用!做人要灵活!
🧪 先亮结论(别急着杠):
"分库分表 + 定时任务 + RMQ 延时消息" 不是三个东西,而是两层组合拳:
- 底层扫描策略:分库分表 + 分片定时任务 → 解决"怎么扫亿级数据",别管我们有没有这么大的量,我们老板说我们有,我们必须得有(实际差不多)
- 上层触发架构:RMQ 延时(快) + 定时任务(稳) → 解决"怎么可靠触发"
它们不是互斥选项,而是"快腿+铁脚"的黄金搭档!
下面,我们一条条"审问":
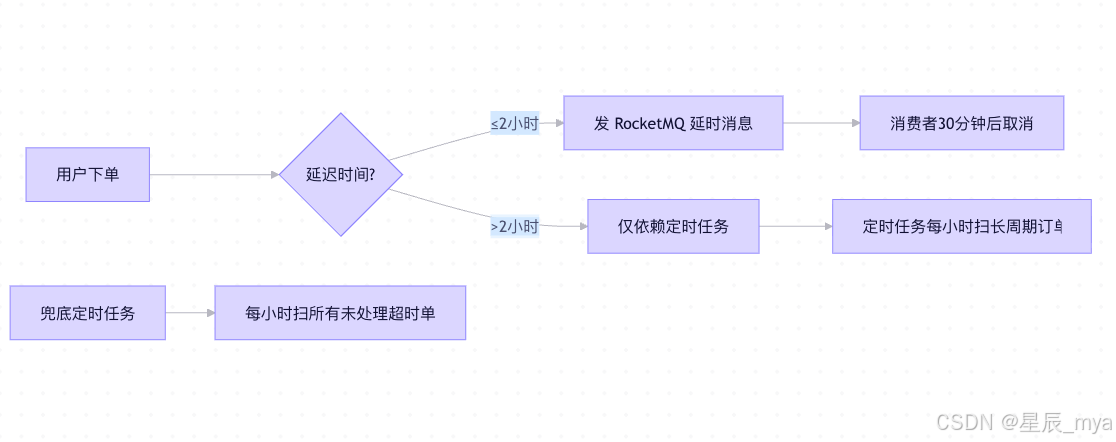
🚀 第一招:短延迟(≤2h)------ RMQ 延时消息 + 本地消息表(快如闪电)
- RocketMQ 的 18 级延迟(最大 2 小时)精度够、吞吐高,适合"30分钟未支付自动取消"。
定时任务确实是最可控、可审计、强一致 的方式,你扫的是最终写入 DB 的状态( 订单是否该取消,只取决于 DB 中 status 和 create_time) ,天然和订单主流程一致;;但是纯定时任务的话会有延迟:可能下一次才能轮到你, 像下面的@Scheduled(fixedDelay = 1000);
// 后台异步投递(独立线程),这个可以借助xxl-job,失败重试
@Scheduled(fixedDelay = 1000)
public void pollAndSendToMQ() {
//发送失败,后台持续重试 查询findReadyToSend 会再次查出然后重试
List<OutboxMessage> messages = outboxMapper.findReadyToSend();
for (OutboxMessage msg : messages) {
if (rmqProducer.send(msg)) {
outboxMapper.markAsSent(msg.getId()); // 标记已发送
}
// 发送失败?下次继续重试!
}
}💡 总结 :
RMQ 延时像"智能闹钟"------设好就忘,到点就响。但万一它死机了?所以你得有个"老妈子"(本地消息表)天天催:"该发消息了!
当然这块定时任务也能优化,比如任务调度器分配分片 (如xxl-job分片广播),实例只扫 order_id % N == 自己的分片ID;无锁、无冲突、线性扩展,DB 压力均匀
定时任务分片:XXL-JOB、ElasticJob、Quartz Cluster
// XXL-JOB 示例:分片广播模式
@XxlJob("cancelOrderJob")
public void execute() {
//任务实例,部署N个任务实例,协作扫描这些表
int shardIndex = XxlJobHelper.getShardIndex(); // 当前实例编号(0 ~ N-1)
int shardTotal = XxlJobHelper.getShardTotal(); // 总实例数N
// 计算该实例负责的分片范围
//tableSuffix表序号=当前实力编号
//共拆1024张表 循环,1024总分片数是必须知道的,可以变但是要是一个常量数字,推荐2^10,对齐内存/缓存
//tableSuffix += shardTotal,每次跳过 shardTotal个表,大家轮流"认领"
for (int tableSuffix = shardIndex; tableSuffix < 1024; tableSuffix += shardTotal) {
String tableName = "orders_" + suffix;
//扫描这张表中的超时订单
List<Order> timeoutOrders = orderMapper.selectTimeoutFromTable(tableName);
for (Order order : timeoutOrders) {
cancelOrderSafely(order); // 幂等取消
}
}
}- for循环分片效果:A 0 4 0, 4, 8, 12, ..., 1020
- B 1 4 1, 5, 9, 13, ..., 1021
自己扫自己分片,这片我罩着 那片你负责 - C 2 4 2, 6, 10, 14, ..., 1022天然隔离,
无遗漏无锁 - D 3 4 3, 7, 11, 15, ..., 1023 每个实例扫约 1024 / 4 = 256 张表
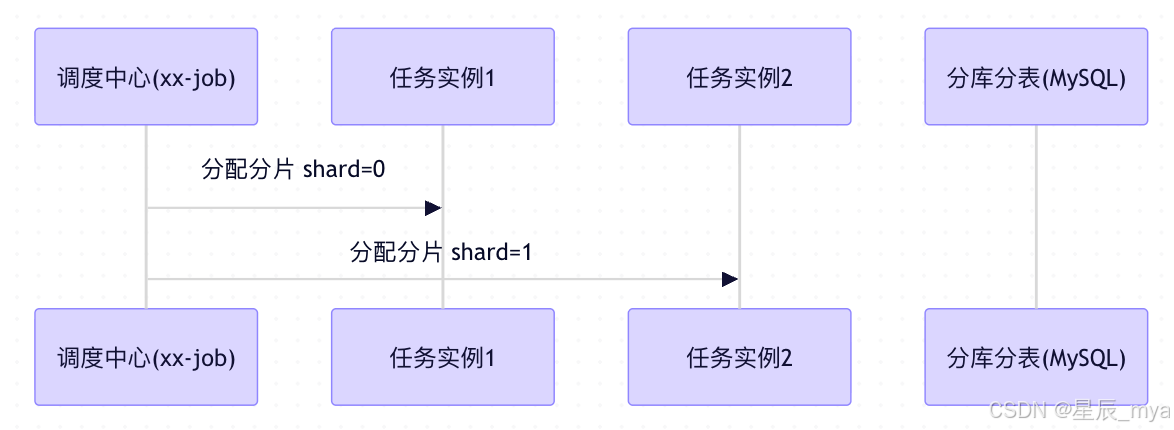
如果压力大,加实例就行!比如从 4 个扩到 8 个:
- 实例 0:0, 8, 16, ...
- 实例 1:1, 9, 17, ...
- ... 挂了只影响自己那嘎达,是不是很有分寸感、边界感
- 自动重新分配,无需改代码
RMQ 延时消息:
是加速器 。如 RocketMQ 的 18 级延迟(最大 2 小时),适合快速取消未支付订单,但无法覆盖"7 天自动收货"这种长周期;部分重复 再次复习吧算是
// 订单创建事务,同一个事务中
@Transactional
public void createOrder(Order order) {
// 1. 写订单表
orderMapper.insert(order);
// 2. 写本地消息表(同一事务!)
messageOutboxMapper.insert(new OutboxMessage(
"ORDER_CANCEL",
toJson(orderId),
System.currentTimeMillis() + 30*60*1000
));
}
// 后台异步投递(独立线程),这个可以借助xxl-job
@Scheduled(fixedDelay = 1000)
public void pollAndSend() {
//发送失败,后台持续重试 查询findReadyToSend 会再次查出然后重试
List<OutboxMessage> messages = outboxMapper.findReadyToSend();
for (OutboxMessage msg : messages) {
if (rmqProducer.send(msg)) {
outboxMapper.markAsSent(msg.getId()); // 标记已发送
}
// 发送失败?下次继续重试!
}
}
//补充msg
DefaultMQProducer producer = new DefaultMQProducer("DelayProducerGroup");
producer.start();
Message msg = new Message(
"ORDER_CANCEL_TOPIC", // Topic
"UNPAID_ORDER", // Tag(可选)
("{orderId: \"12345\"}").getBytes() // 消息体
);
// ⭐ 关键:设置延时等级(不是直接设秒数!)
msg.setDelayTimeLevel(3); // 表示第3级延迟,1:1s 2:5s 3:10s 4:30s 5:1m 6:2m 7:3m 8:4m 9:5m 10:6m 11:7m 12:8m 13:9m 14:10m 15:20m 16:30m 17:1h. 18:2h
producer.send(msg);时间轮 + 多级 CommitLog, 消息存到SCHEDULE_TOPIC_XXXX内部topic中,后台线程DeliverDelayedMessageTimerTask,到期消息投递到指定的topic中,注意哦这个顺序是乱的,不能保证
而且事务是不支持延时消息的,需先提交事务,再发延时消息
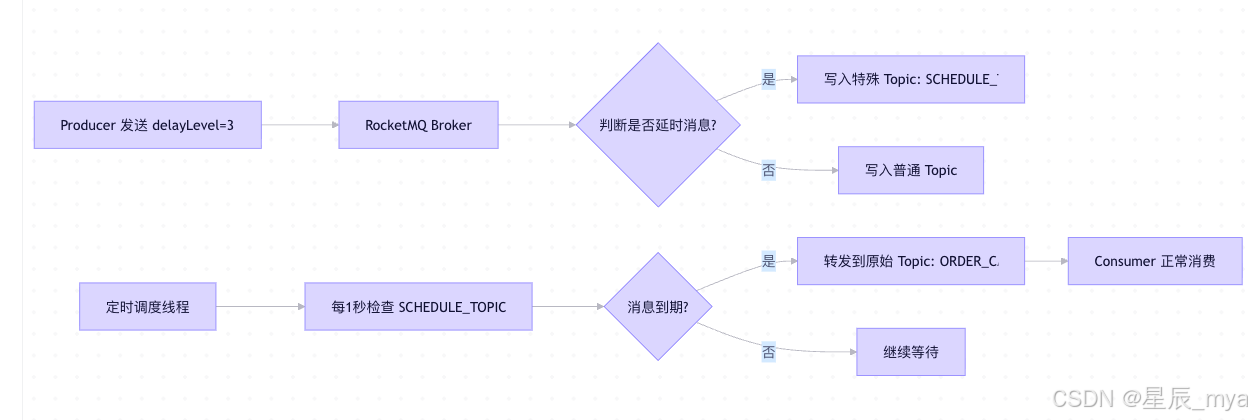
消费吧蛋炒饭君:
public class OrderCancelConsumer implements MessageListenerConcurrently {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ...) {
for (MessageExt msg : msgs) {
String orderId = parseOrderId(msg.getBody());
// ⭐ 先查状态!避免重复取消
if (orderService.getStatus(orderId) == OrderStatus.UNPAID) {
orderService.cancelOrder(orderId); // 幂等接口
}
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
}| 限制 | 原因 | 影响 |
|---|---|---|
| 最大延迟 2 小时 | RocketMQ 延时级别固定(1s~2h 共 18 级) | 无法用于"7 天自动收货" |
| 消息可能丢失 | Broker 宕机 + 未刷盘(异步刷盘模式) | 需配合 本地消息表 或 定时任务兜底 |
| 无精确时间控制 | 延迟是"至少",非"精确"(受消费线程调度 网络影响) | 30 分钟可能 30 分 5 秒才触发 |
那么对于超过2h的情况咱们怎么办?
"长延迟用定时任务"是高并发、强一致性系统中的经典解法 ,尤其适用于 "7天自动收货""30天未评价自动好评""90天订单归档" 等超过 MQ 延迟上限(如 上面RocketMQ 的 2 小时)的场景
🎯 核心思想:不依赖外部中间件,直接读取数据库最终状态
咱们上面也提到多,定时任务是没有外部依赖、强一致(只相信表里面status和create_time),并且可以做记录日志,时间也是可以任选,这就是无拘无束、自由自在的感觉吧
-
按
order_id % 1024拆成 1024 张表:orders_0,orders_1, ...,orders_1023@XxlJob("autoConfirmReceiptJob")
public void execute() {
int shardIndex = XxlJobHelper.getShardIndex(); // 当前实例编号(0 ~ N-1)
int shardTotal = XxlJobHelper.getShardTotal(); // 总实例数(如 32)//分片扫描:每个实例负责部分分表 for (int suffix = shardIndex; suffix < 1024; suffix += shardTotal) { String tableName = "orders_" + suffix; scanTableForAutoConfirm(tableName); }}
private void scanTableForAutoConfirm(String tableName) {
long lastOrderId = 0;
while (true) {
//满足条件的100个单子
Listbatch = orderMapper.selectBatch(tableName, cutoffTime, lastOrderId, 100);
if (batch.isEmpty()) break;
//开启业务处理 更新状态 记录日志
for (Order order : batch) {
// 幂等确认(同上)
confirmOrderSafely(order);
lastOrderId = order.getOrderId();
}
}
}
单机的也比较简单:自己看吧
// 每小时执行一次
@Scheduled(cron = "0 0 * * * ?") // 每小时整点
public void scanAndAutoConfirm() {
// 查找:已发货 + 超过7天 + 未确认收货
Listorders = orderMapper.selectForAutoConfirm(
OrderStatus.DELIVERED,
System.currentTimeMillis() - 7L * 24 * 3600 * 1000
);for (Order order : orders) { // 幂等更新:只有状态仍是 DELIVERED 才确认 int updated = orderMapper.confirmReceiptIfStatusMatch( order.getOrderId(), OrderStatus.DELIVERED, // 期望旧状态 OrderStatus.CONFIRMED // 新状态 ); if (updated > 0) { log.info("✅ Auto-confirm order: {}", order.getOrderId()); // 可触发积分、通知等后续逻辑 } }}
兜底
即使这样也是会有风险的,所以低频率定时任务1h扫描漏单,一个都不能少,必须都消费掉
// 1h扫描所有"该处理但未处理"的订单
List<Order> leakOrders = orderMapper.selectLeakedOrders(cutoffTime);
for (Order order : leakOrders) {
handleSafely(order); // 幂等处理
}
| MQ | 延时实现 | 最大延迟 | 自定义时间 | 可靠性 |
|---|---|---|---|---|
| RocketMQ | 内部队列 + 时间轮 | 2 小时 | ❌ 固定18级 | ⭐⭐⭐⭐(持久化) |
| RabbitMQ | TTL + DLX | 无上限 | ✅ 任意秒 | ⭐⭐(内存压力大) |
| Kafka | ❌ 原生不支持 | --- | --- | --- |
| Pulsar | ✅ 支持任意延迟 | 无上限 | ✅ | ⭐⭐⭐⭐ |
当然这还是有个隐患,咱们开始的标题也提到了,再怎么说订单数量很大的情况下,单表查询岂不是吃了熊心豹子胆、在关公面前耍小卡拉米,所以是不是得分库分表,要不然做什么事情都背着一个超级大的麻袋一样,这多费劲,所以咱们分而治之
分库分表
- 按
order_id取模,比如order_id % 1024 如果按用户查询比较多也可以按用户,一切跟业务强度挂钩- 拆成 1024 个物理表 (如
orders_0,orders_1, ...,orders_1023) - 可能分布在多个 MySQL 实例(分库)或同一实例(分表)
💡 目的:写入和查询都分散到不同表,避免热点
😎 最后一句金句收尾:
**"短延迟靠 MQ,像外卖小哥------快但可能迟到;
长延迟靠定时任务,像邮政老伯------慢但永不丢件。
真正的大厂架构:
------既雇得起小哥,也信得过老伯,
------还配了个'鹰眼'(兜底任务)盯死角!
这才叫:快、稳、全!"** 💥