【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Ubuntu】【Hugo】搭建私人博客:模糊搜索 Fuse.js(三)
分析了 Hugo PaperMod 搜索的默认配置项,以及支持用户可自定义的搜索配置项,下面继续
搭建私人博客
OK,下面来看 Fuse 搜索引擎实例的创建
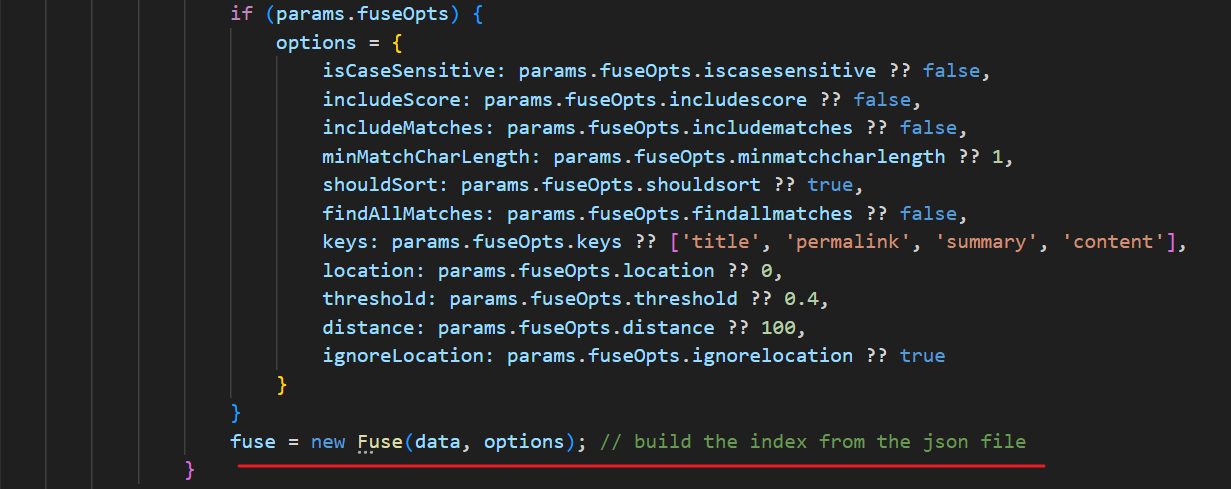
这里面的两个参数:
data:从index.json里加载的文章数组options:上面构建好的用户自定义配置对象
此时 new Fuse(...) 会遍历 data 中的每篇文章,并对 keys 指定的字段建立倒排索引 ,然后返回一个可复用的搜索对象,之后就可以通过 let results = fuse.search("ssh tunnel"); 这样返回匹配的文章列表(按相关性排序)
对关键字 keys 指定的字段建立倒排索引是搜索引擎(包括 Fuse.js,Elasticsearch,Lucene 等)高效查找数据的核心原理,下面来详细分析下
正排索引
在分析倒排索引之前,先来看下正排索引,做个对比
假如有一本书,目录是这样的
| 标题 ID | 内容 |
|---|---|
| 1 | 苹果很好吃 |
| 2 | 香蕉和苹果都是水果 |
| 3 | 大家喜欢吃苹果 |
这种格式就是正排索引,按标题索引内容,如果想知道第 2 篇文章写了什么,查一下标题 ID 就可以知道,但如果想知道哪些文章里有关键词【苹果】,就得逐篇扫描所有内容,那么效率就很低,时间复杂度 O(n)
倒排索引
OK,下面再来看上面提到的倒排索引,之前正排索引是【标题】->【内容】,现在倒排索引是【关键词】->【标题】,倒排索引会把上面举例的数据转换成下面这样:
| 关键词 | 标题 ID |
|---|---|
| 苹果 | 1,2,3 |
| 很好吃 | 1 |
| 香蕉 | 2 |
| 水果 | 2 |
| 喜欢 | 3 |
可以看到,在倒排索引中,当用户搜索【苹果】关键词,搜索引擎直接查倒排表,就可以立马找到结果 [1,2,3],瞬间返回,而不需要扫描全文,时间复杂度从 O(n) 降到 O(log n),快的飞起
OK,回到 fastsearch.js,首先定义了关键字段 keys: ['title', 'summary', 'content'],Fuse.js 在初始化时(new Fuse(data, options)),会遍历每一篇文章(data 中的每个对象),然后对 keys 中指定的每一个字段进行分词,并把每个词映射到包含它的文档 ID,举个例子,假设有两篇文章
javascript
[
{
id: 1,
title: "SSH 隧道教程",
summary: "教你如何使用 SSH 反向隧道"
},
{
id: 2,
title: "Git 使用指南",
summary: "Git 是分布式版本控制系统"
}
]Fuse.js 会对 title 和 summary 建立倒排索引(简化版)如下
| 词 | 文档 ID |
|---|---|
| ssh | 1 |
| 隧道 | 1 |
| 教程 | 1 |
| 使用 | 1,2 |
| git | 2 |
| 分布式 | 2 |
| 版本控制 | 2 |
实际上,Fuse.js 还支持模糊匹配(比如 sssh 也能匹配 ssh),所以它的索引比传统倒排更复杂,但核心思想是一样的
OK,最后再来对比下传统搜索引擎和 Fuse.js 的倒排索引
| 特性 | 传统引擎(比如 Elasticsearch) | Fuse.js |
|---|---|---|
| 索引存储 | 磁盘/内存,支持持久化 | 纯内存,页面关闭就消失 |
| 分词 | 支持中文分词,同义词等 | 默认按空格/字母分词(对中文效果一般) |
| 模糊匹配 | 需额外配置 | 内置强大模糊算法(基于 Levenshtein 距离) |
| 适用场景 | 大型网站,海量数据 | 小型静态站(< 1000 篇文章) |
Fuse.js 的倒排索引其实是为模糊搜索优化的内存结构,不完全等同于数据库的倒排,但思想一致
对 keys 指定的字段建立倒排索引,就是把文章中指定字段(比如标题,摘要等)中的每个词进行分类,预先记录这个词会出现在哪些文章里,这样搜索时就能秒级定位结果,而不用一片片翻,这是所有现代搜索引擎(从 Google 到博客搜索框)高效工作的基石
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【Ubuntu】【Hugo】搭建私人博客:搜索功能(五)