文章目录
- 一、Locust分布式
-
- [1.1 实现方式](#1.1 实现方式)
- [1.2 测试代码](#1.2 测试代码)
- [1.3 终端实现](#1.3 终端实现)
- 二、使用没有web的Locust
一、Locust分布式
1.1 实现方式
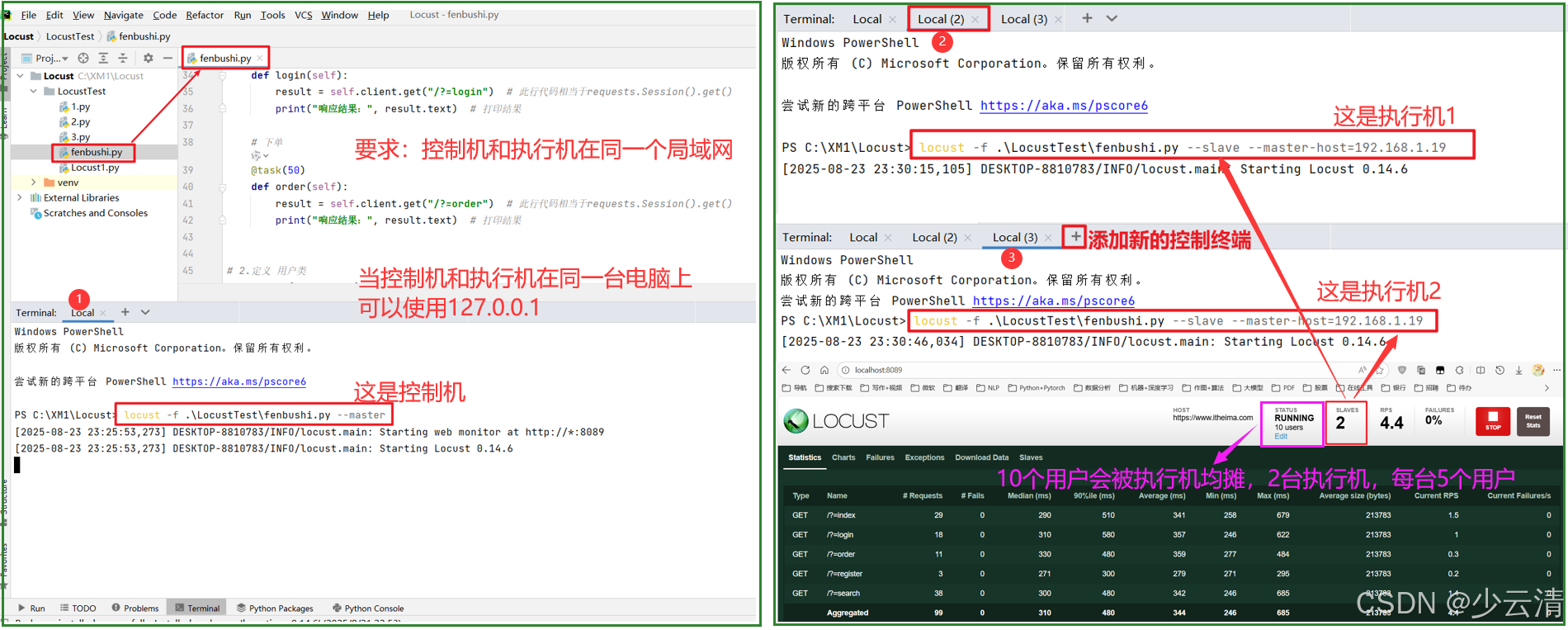
Locust 下实现分布式,十分容易,只需要在启动脚本时,分别给 控制机、执行机指定不同参数即可:
要求:控制机和执行机要在同一个局域网内。
控制机:--master
执行机:--slave --master-host=控制机IP地址
1.2 测试代码
python
from locust import TaskSet, HttpLocust, task
"""
locust比重:500用户并发送
- 首页:150
- 搜索商品:200
- 注册:20
- 登录:80
- 下单:50
"""
# 1.定义 任务集 和 任务
class TaskClass(TaskSet): # TaskClass 表示任务集
""""定义任务"""
# 访问首页
@task(150)
def index(self):
result = self.client.get("/?=index") # 此行代码相当于requests.Session().get()
print("响应结果:", result.text) # 打印结果
# 搜索
@task(200)
def search(self):
result = self.client.get("/?=search") # 此行代码相当于requests.Session().get()
print("响应结果:", result.text) # 打印结果
# 注册
@task(20)
def register(self):
result = self.client.get("/?=register") # 此行代码相当于requests.Session().get()
print("响应结果:", result.text) # 打印结果
# 登录
@task(80)
def login(self):
result = self.client.get("/?=login") # 此行代码相当于requests.Session().get()
print("响应结果:", result.text) # 打印结果
# 下单
@task(50)
def order(self):
result = self.client.get("/?=order") # 此行代码相当于requests.Session().get()
print("响应结果:", result.text) # 打印结果
# 2.定义 用户类
class User(HttpLocust):
# 绑定任务
task_set = TaskClass # task_set 属性名不能变; 注意:TaskClass 后,没有 ()
# 设置 用户间 最小延迟时间 - 单位 ms
min_wait = 1000
# 设置 用户间 最大延迟时间
max_wait = 3000
# 指定 主机地址
host = "https://www.baidu.com"1.3 终端实现
控制机终端命令:
bash
PS C:\XM1\Locust> locust -f .\LocustTest\fenbushi.py --master执行机终端命令:
bash
PS C:\XM1\Locust> locust -f .\LocustTest\fenbushi.py --slave --master-host=192.168.1.19二、使用没有web的Locust
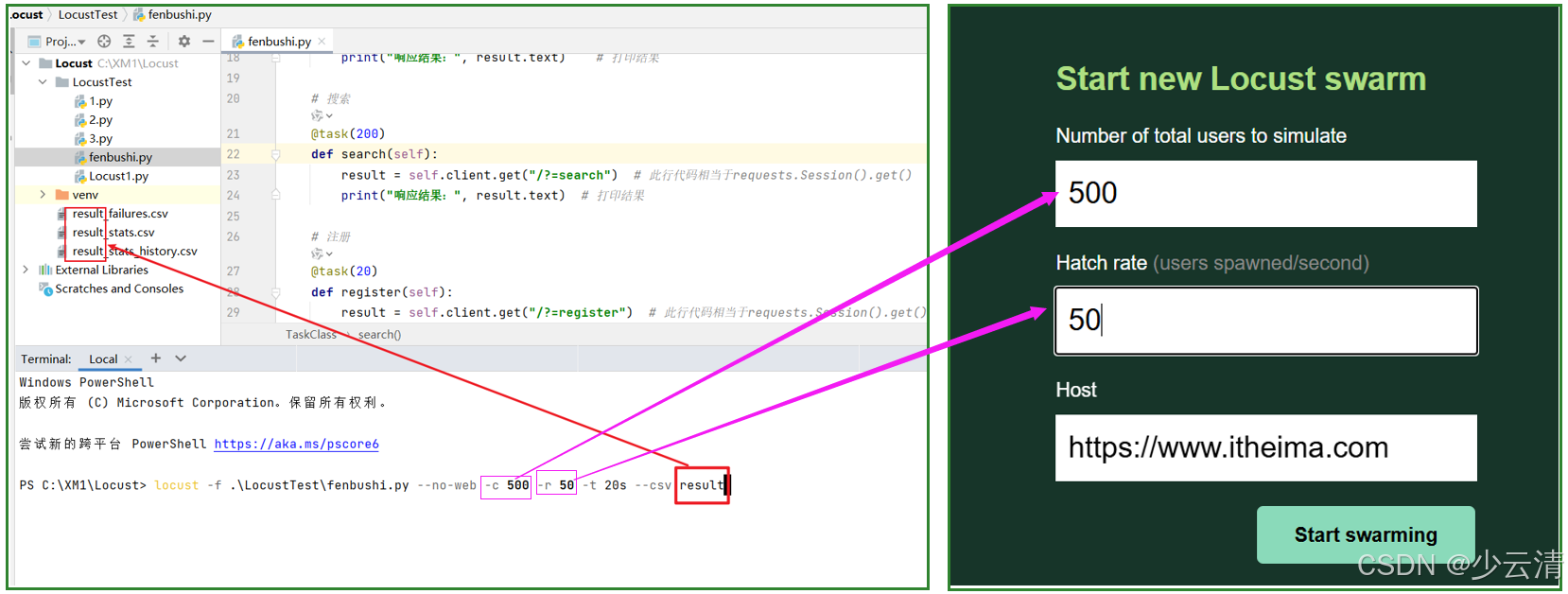
Locust 脚本运行时,也可以用参数来指定UI界面中的东西:
- -f:脚本文件名
- --no-web:不以web页面形式运行
- -c:用户数 (相当于web页面中,第一个输入框)
- -r:1s启动用户数 (相当于web页面中,第二个输入框)
- -t:运行时间。秒s,分m,小时h。如1h30m10s
- --csv:指定生成csv结果文件的前缀。语法 --csv result
bash
PS C:\XM1\Locust> locust -f .\LocustTest\fenbushi.py --no-web -c 500 -r 50 -t 20s --csv result