目录
[1.1 典型场景](#1.1 典型场景)
[1.2 技术方案](#1.2 技术方案)
[1.3 局限性](#1.3 局限性)
[1.4 代表技术](#1.4 代表技术)
[二、2017-2019:APM 时代](#二、2017-2019:APM 时代)
[2.1 典型场景](#2.1 典型场景)
[2.2 技术方案](#2.2 技术方案)
[2.3 局限性](#2.3 局限性)
[2.4 代表技术](#2.4 代表技术)
[3.1 典型场景](#3.1 典型场景)
[3.2 技术方案](#3.2 技术方案)
[3.3 局限性](#3.3 局限性)
[3.4 代表技术](#3.4 代表技术)
[4.1 典型场景](#4.1 典型场景)
[4.2 技术方案:从自建到云平台](#4.2 技术方案:从自建到云平台)
[4.3 局限性](#4.3 局限性)
[4.4 代表技术](#4.4 代表技术)
[五、2026-未来:AI Agent 智能运维与云原生监控](#五、2026-未来:AI Agent 智能运维与云原生监控)
[当前现实:AI 能力已经落地](#当前现实:AI 能力已经落地)
写在前面
博主消失的一段时间一直在忙着准备面试和参加一些线下的技术分享会,有一阵子没更新文章了。在准备面试材料的时候,我把自己做过的 MessagePulse 项目(12,000 QPS 的高并发消息系统)从头梳理了一遍,发现最让我能聊出深度的话题,反而是监控体系------从最开始的 ELK 查日志,到 Prometheus + Grafana,再到后来接触的阿里云 ARMS。
正好前几天有个"养虾热潮"技术分享会,和一众大佬交流到了"企业级监控实践"或许整合AI Agent智能(比如现在的OpenClaw或者以后的新的智能体范式框架结构),我就好奇这个领域把我这几年对这个领域的理解整理了一下,发现从 2015 年到 2025 年这十年间,企业监控确实走过了一条清晰的演进路径。于是就把当时的分享内容整理成了这篇文章**。**下一篇将继续更新Spring AI Alibaba,博主已经在码字啦!!!
监控要解决的,从来不是"看得见"这个问题
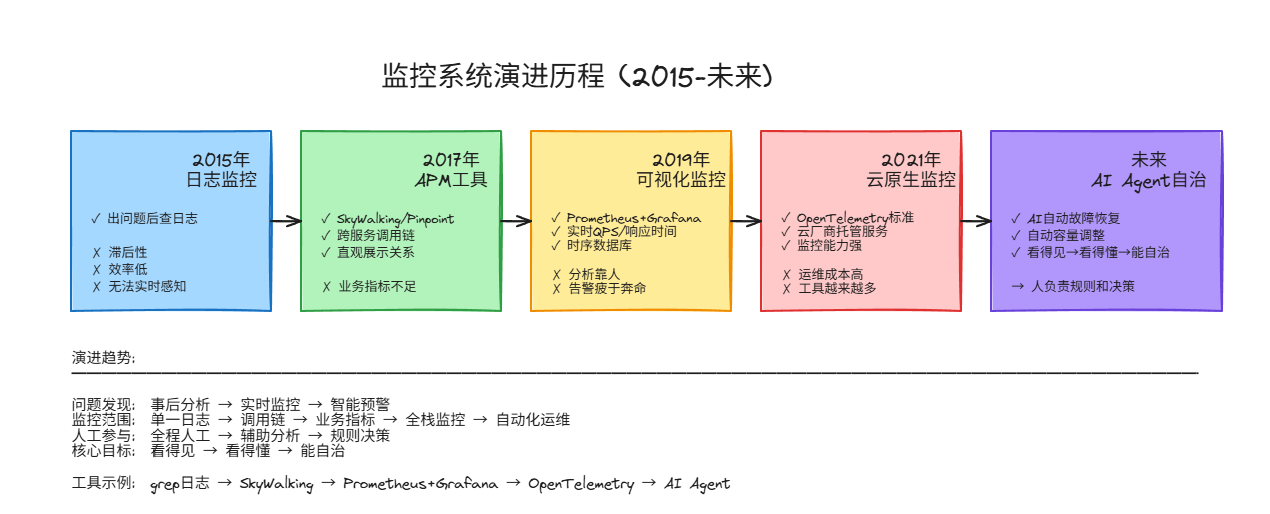
回想 2015 年,大部分运维工程师的日子是这样的:出了事,登录十台服务器,一台台翻日志,grep、awk、grep、awk。等找到问题,用户已经投诉了两小时。这种方式最让人抓狂的是:你根 本不知道系统现在怎么样,只能等出事后再去翻"尸体"。

2017 年,微服务火了,但调用链复杂得让人头疼。一个用户请求可能经过十个服务,哪个环节出问题了,查起来像大海捞针。SkyWalking、Pinpoint 这些 APM 工具确实解决了"跨服务排查难"的问题------至少你能看到请求从哪来、到哪去、在哪卡住了。但它们主要盯着技术调用链,业务指标监控还是空白。你知道响应慢,但不知道慢对业务影响有多大。

2019 年,Prometheus + Grafana逐渐成了标配。时序数据库加上可视化看板,QPS、响应时间、错误率这些核心指标能实时看到了。进步是肯定的,但问题也很现实:数据有了,分析还是要靠人。告警一个接一个炸,运维人员疲于奔命,半夜被叫起来处理告警仍是常态。

2021 年后,云原生监控体系成熟了。OpenTelemetry 统一了数据采集标准,云厂商提供了托管监控服务。工具越来越好用,但人却越来越累------监控能力越强,运维成本反而越高。工具越来越多,人还是跑不过来。

到了 2025 年,AI Agent 开始进入运维领域。重点从"看得见"、"看得懂"变成了"能自治"。根据预先定义的规则,AI可以自动执行故障恢复、容量调整等常规运维动作,人只负责制定规则和最终决策。终于,人类可以从重复劳动中解放出来了。
可能你和我也很好奇,监控可观测系统这么久的演化,还是曲曲折折,它一步步的演化历程具体是怎么样的,那么下面就让我们来一起看看吧!
一、2015-2017:日志时代
1.1 典型场景
某电商公司在"双十一"期间发现订单接口响应慢。运维人员登录到服务器,使用 grep 搜索日志文件,发现某个第三方支付接口超时。但这种排查方式有几个问题:
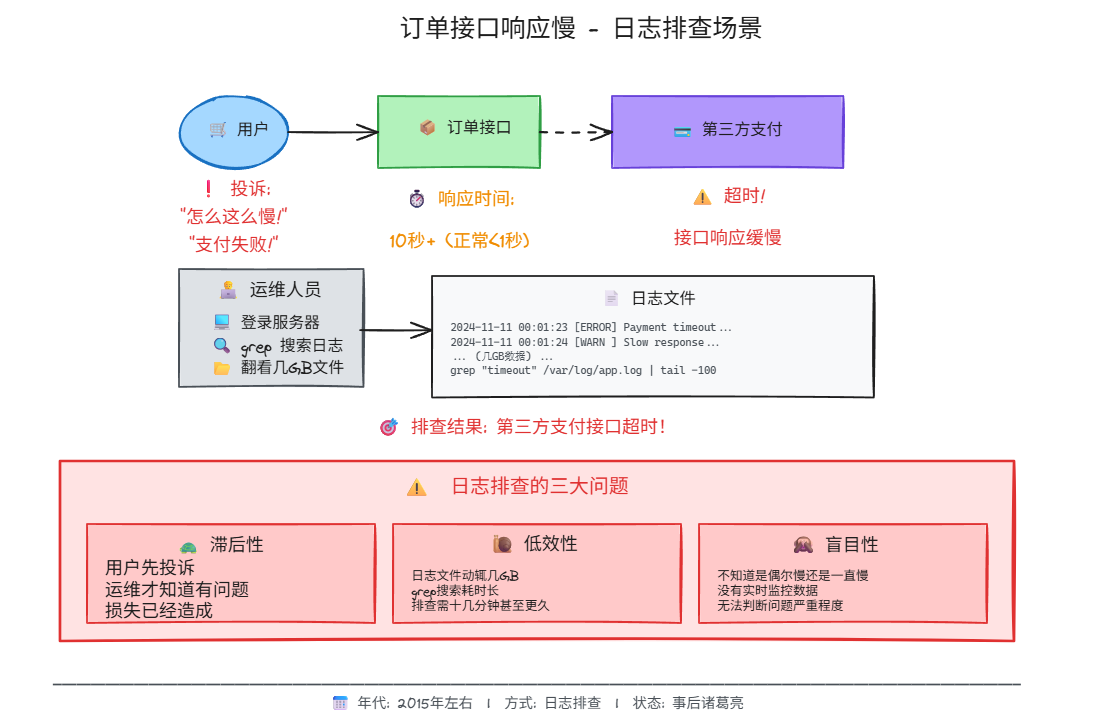
- 滞后性:用户先投诉,运维才知道
- 低效性:日志文件动辄几 GB,搜索耗时长
- 盲目性:不知道是偶尔慢还是一直慢

1.2 技术方案
这个阶段的主流方案是 ELK Stack(Elasticsearch + Logstash + Kibana):
应用 → Logstash(采集) → Elasticsearch(存储) → Kibana(查询)通过集中式日志管理,可以快速检索和分析日志。阿里巴巴在 2015 年左右就开始使用自研的日志系统,解决了日志分散、检索困难的问题。
1.3 局限性
日志方案解决了"事后排查"的问题,但无法做到:
- 实时监控:不知道当前系统状态
- 趋势分析:无法看到 QPS、RT 等指标的变化
- 预警能力:只能被动响应,无法主动发现
1.4 代表技术
- ELK Stack:日志采集、存储、可视化
- Graylog:集中式日志管理
- Splunk:商业日志分析平台
二、2017-2019:APM 时代
2.1 典型场景
某互联网公司上线了微服务架构后,发现一个用户请求要经过十几个服务。某个接口报错了,但不知道是哪个服务出的问题。人工排查需要逐个查看服务的日志,耗时很长。
2.2 技术方案
APM(Application Performance Monitoring)工具通过字节码注入或代理方式,自动采集服务间的调用关系:
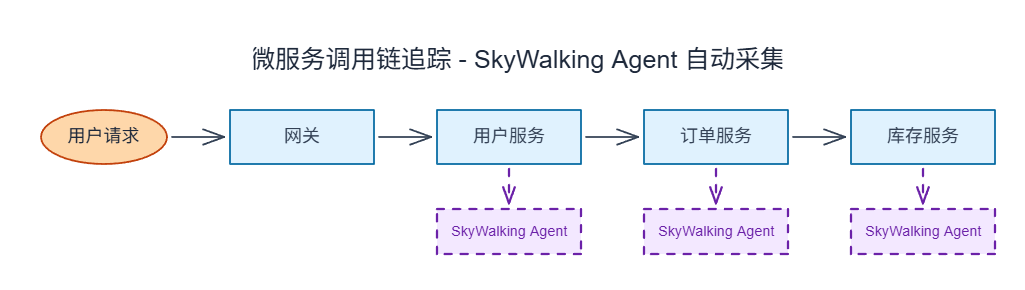
字节跳动的案例:字节在 2018 年开源了 CloudWeGo-Trace,解决了微服务调用链追踪的问题。通过分布式追踪,可以:可视化完整调用链路、定位慢请求的具体环节、分析服务依赖关系。
2.3 局限性
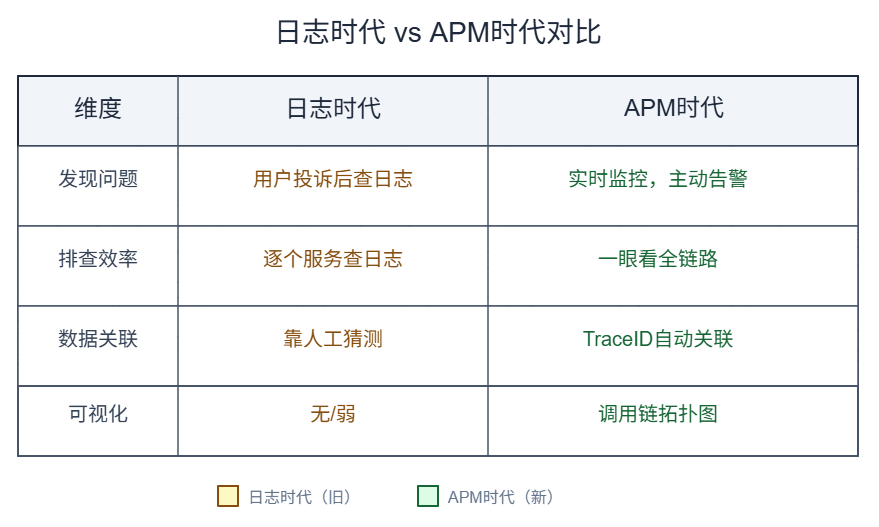
APM 方案解决了"调用链追踪"的问题,但:
- 业务指标缺失:无法监控订单量、支付成功率等业务数据
- 数据孤岛:链路数据和业务数据无法关联
- 被动分析:还是要人去分析调用链,无法自动化
2.4 代表技术
- SkyWalking:国产 APM,支持多语言
- Pinpoint:韩国 Naver 开源,调用链追踪精度高
- Zipkin:Twitter 开源,轻量级分布式追踪
三、2019-2021:指标监控时代
3.1 典型场景
某公司接入了 SkyWalking 后,能看见调用链了,但不知道业务整体情况。老板问:"现在系统 QPS 是多少?" 技术人员答不上来,因为 APM 工具不提供这类聚合指标。

3.2 技术方案
概览 | Prometheus - Prometheus 监控系统
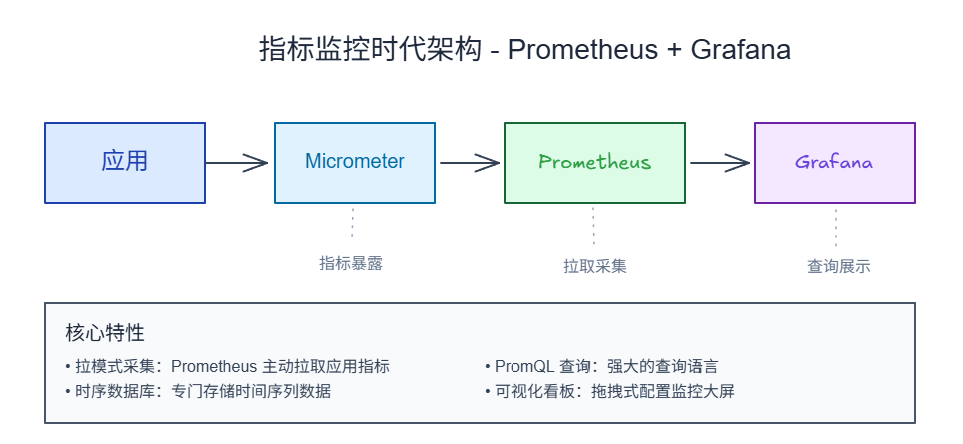
Prometheus + Grafana 成为主流方案:
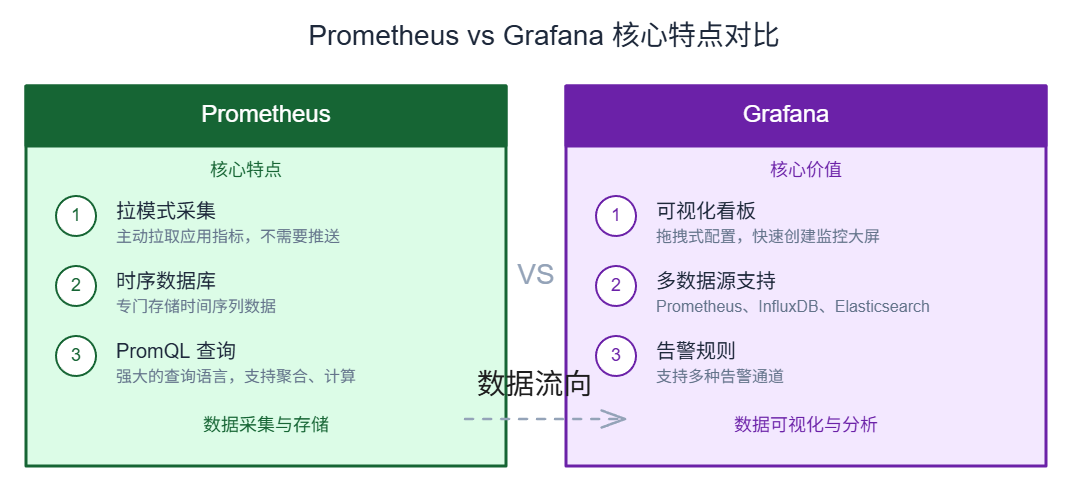
两者核心特点:
3.3 局限性
指标监控解决了"数据分析"的问题,但:
- 告警疲劳:阈值设置不好,告警发个不停
- 人工决策:发现问题后,还是要人去分析和处理
- 规则维护:告警规则越来越多,维护成本高
3.4 代表技术
- Prometheus:时序数据库,适合监控指标采集
- Grafana:可视化平台,支持多种数据源
- InfluxDB:另一种时序数据库,与 Prometheus 形成竞争
四、2021-2025:云原生监控时代
4.1 典型场景
某公司上了 Prometheus + Grafana 后,监控能力很强了,但运维团队发现:
- 监控工具越来越多:Prometheus、Grafana、SkyWalking、ELK...
- 数据越来越分散:指标、链路、日志互不相通
- 运维成本越来越高:工具越多,需要的人也越多

4.2 技术方案:从自建到云平台
早期企业需要自己搭建 Prometheus + Grafana + SkyWalking + ELK 的完整监控体系。但大厂发现,自建监控的运维成本太高,开始转向使用云厂商提供的集成式监控平台。
**阿里云 ARMS(应用实时监控服务)**是国内有代表性的云监控平台:
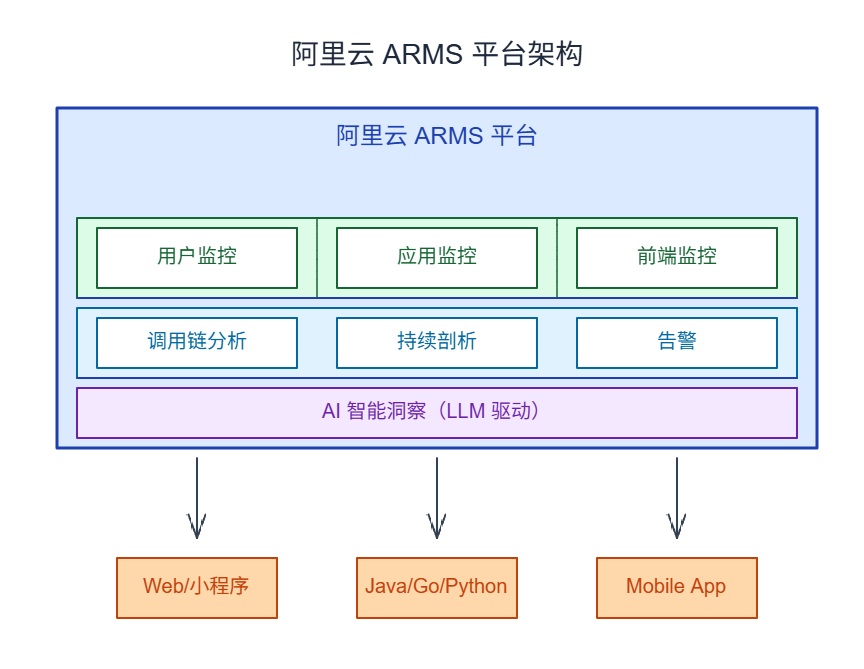
ARMS 的核心特点:
支持全栈技术
Web、小程序、桌面端、移动端都能监控。后端支持 Java、Golang、Python------你用什么技术栈都行。
完整追踪调用链
从前端按钮点击到后端数据库查询,整个链路都能看见。排查问题时不用再翻前端日志、翻后端日志、翻中间件日志,一条链路全搞定。
用 AI 减少告警噪音
告警太多?LLM会把重复的、相关的告警合并成一个问题,还能告诉你哪个服务影响了多少用户。不用半夜起来看一千条一模一样的告警。
兼容开源标准
用 OpenTelemetry 采集数据,用 Prometheus 存指标。不用换掉你现有的工具,接入就行。
腾讯云可观测平台(TCOP)同样提供类似能力:
如果你在用腾讯云,TCOP 把指标、链路、日志、事件四个维度的数据统一了------不用来回切换三个系统查问题。内置了 Prometheus 和 Grafana,开箱即用。不用自己搭监控集群,也不用学告警规则怎么配。LLM 功能也在路上,可以用自然语言问"为什么昨天下午接口变慢了",而不是自己写 PromQL 查询。
4.3 局限性
云平台监控解决了"自建成本高"的问题,但:
- 成本不低:按数据写入量计费,流量大的企业费用可观
- 厂商锁定:数据在云端,迁移成本较高
- 仍需人工:平台提供的是工具,分析决策还是要人
4.4 代表技术
- 云平台监控:阿里云 ARMS、腾讯云 TCOP、华为云 APM
- 托管服务:AWS CloudWatch、Azure Monitor、Google Cloud Operations
- 开源标准:OpenTelemetry(统一数据采集)
五、2026-未来:AI Agent 智能运维与云原生监控
5.1 现实例子:AI 能力已经落地
"AI 运维"不再是概念。2024 年,主流云平台已经提供了真实的 AI 能力:
- 阿里云 ARMS:LLM 告警收敛、故障洞察、Copilot 自助探索
- 腾讯云 TCOP:AI 工作台、LLM 大模型应用监控
- 华为云 AOM:智能告警、异常检测
这些功能不是未来规划,而是已经在平台上可用的能力。
但当前的 AI 能力存在局限:AI 只负责"分析"和"建议",人类负责"决策"和"执行"。人类疲劳时容易判断失误,半夜起来加班处理告警仍是常态。(当然,目前已经开始尝试AI智能运维了,AI开始自主做一些操作了。)
5.2 未来设想:以人为核心的自治系统
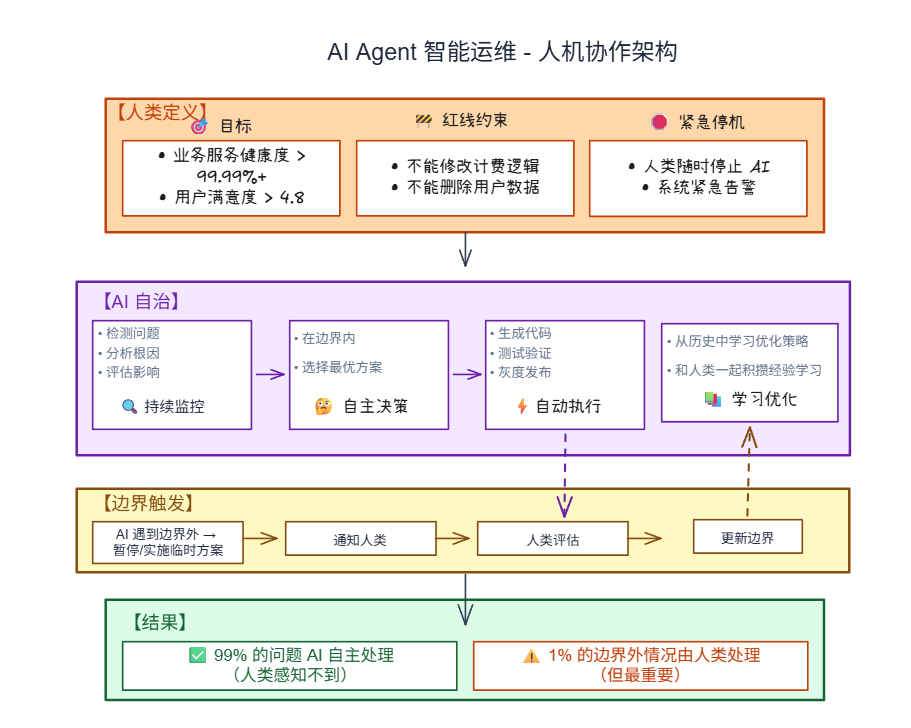
核心观点:AI 自治 ≠ 人类不再需要,而是人类不再做重复劳动,专注于决策和边界定义。
系统运作方式
人类定义系统的目标函数和红线约束,AI 在边界内自主决策和执行,就像OpenClaw一样,专属于服务器守护者的运维OpenClaw甚至是更为智能化先进化的产品,由未来的运维负责管理维护协调:
一个典型的凌晨 2 点
| 现在 | 未来 |
|---|---|
| 凌晨 2:14,告警响起 | 凌晨 2:14,同级别的告警响起 |
| 运维工程师被叫醒 | AI 自主处理研判抉择,评估事态紧急程度,判断是否需要通知运维工程师 |
| 登录系统,手动排查 | 无论是否通知都将进行 检测 → 分析 → 执行 → 验证 |
| 疲劳决策,容易出错 | 基于边界规则,理性决策 (即刻进行容灾处理,然后生成告警报表分析,先运维人员一步到场) |
| 手动执行 | 自动添加索引 |
| 等到 6 点再修复(延迟 4 小时) | 5 分钟内给出临场的解决方案 |
| 影响用户 28,800 人 | 影响用户 312 人 |
| 运维工程师睡 3 小时,熬夜一直守护,探讨策略。甚至严重直接较大面积关停服务设备 | 运维工程师一觉睡到天亮或是在线上同运维AI Agent进行讨论决策,探讨评估Agent的临时策略 |
| 第二天早上 9 点到公司,继续处理 | 第二天早上 9 点到公司,看报告,看效果 |
| "昨晚修复了 3 个问题" | "昨晚避免了 342 人访问延迟" |
人类扮演什么角色?
| 角色 | 职责 | 日常工作 |
|---|---|---|
| 价值观定义者 | 定义系统的目标函数 | 设定业务健康度、用户满意度、成本效率等目标 |
| 边界设定者 | 定义 AI 可以做什么 | 设定风险等级、影响范围、时间窗口等边界 |
| 审计者 | 审查 AI 的决策 | 定期查看 AI 的决策日志,调整边界 |
| 异常处理者 | 处理边界外情况 | AI 遇到未知场景时,人类介入并更新边界 |
消失的工作 :写监控配置、半夜响应告警、手动排查故障、重复性操作
核心工作:定义目标、设定边界、审计决策、处理未知场景
演进的内在逻辑
回顾这十年的演进,可以发现清晰的逻辑线索:
看不见(日志)→ 看得见(APM)→ 看得懂(指标)→ 能自治(人与未来智能Agent携手的时代)每个阶段都解决了一个核心问题,同时也产生了新的问题:
| 时代 | 解决的问题 | 产生的新问题 |
|---|---|---|
| 日志时代 (2000s) | 出了事后不知道为什么 (日志散落在各台服务器) | 出事了才知道 (无法实时监控,用户先投诉) |
| APM 时代 (2010s) | 调用链太复杂,查不到根因 (请求从哪来、到哪去,看不清) | 看得到技术问题,看不到业务影响 (RT 升高了,但不知道损失多少) |
| 指标监控 (2015s) | 数据太多,人工看不过来 (日志、链路、指标各是各的) | 告警炸了,人类疲劳决策 (半夜起来,100 条告警,哪条先处理?) |
| 云原生监控 (2020s) | 工具太多,运维成本高 (Prometheus、Grafana、Jaeger...) | 仍然需要人工 (工具统一了,但半夜还是要起来扩容) |
| AGI智能监控系统 (2030s) | 人类不再做重复劳动 (告警收敛、自动修复、智能决策) | 如何定义边界 (什么可以让 AI 自己做?什么必须人类审批?) 如何建立信任 (AI 做了对的决策,人类敢让它执行吗?) |
演进的终点不是"人类退出",而是"人类升级"!
- 从"看不见"到"看得见":技术让我们能看到问题
- 从"看得见"到"看得懂":数据让我们能理解问题
- 从"看得懂"到"能自治":AI 让我们能预防问题
- 始终不变的是:人类定义目标,AI 执行任务
这不仅是技术的演进,更是人类角色的进化------从"操作者"到"治理者",从"响应问题"到"定义未来"。
技术若失去人的意义,就像离开了人的文明也再也不是文明了!

参考博文
公牛集团沐光团队基于阿里云 ARMS 的可观测最佳实践. 阿里云客户案例. https://www.aliyun.com/customer-stories/manufacturing-2025-goneogroup
【升职加薪秘籍】我在服务监控方面的实践(5)-应用监控. 腾讯云开发者社区. https://cloud.tencent.cn/developer/article/2331031
Observability in under 5 seconds: Reflecting on a year of grafana/otel-lgtm. Grafana官方博客. https://grafana.com/blog/observability-in-under-5-seconds-reflecting-on-a-year-of-grafana-otel-lgtm/
如何通过云原生APM实现应用的自动化监控? 云杉网络博客. https://www.yunshan.net/blog/archives/36965.html
可观测发布"AI 工作台",实现从被动救火到主动运维的智能升级! 腾讯云官方发布. https://cloud.tencent.cn/developer/article/2541492
让每次语音唤醒都可靠,公牛沐光重构可观测体系. 阿里云开发者社区. https://developer.aliyun.com/article/1683529