一、Purge 线程的基本概念与作用
在 MySQL 的 InnoDB 存储引擎中,Purge 线程 (Purge Thread)是负责清理"已提交但不再需要的历史数据版本 "的后台线程。
其核心作用源于 InnoDB 的 多版本并发控制(MVCC)机制。
关键点如下:
- MVCC 依赖历史版本:当事务执行 UPDATE 或 DELETE 操作时,InnoDB 并不会立即物理删除旧记录,而是将其标记为"可删除",并保留旧版本以供其他可能仍在运行的事务读取。
- Purge 的职责 :一旦确认这些旧版本对所有活跃事务都不可见(即没有事务还需要它们),Purge 线程就会安全地从表空间中物理删除这些记录,并释放 Undo Log 空间。
- 防止 Undo 表空间无限增长:若无 Purge 机制,Undo 日志将持续累积,最终导致磁盘耗尽或性能严重下降。
简言之:Purge 线程是 MVCC 的"清道夫",确保数据库既能支持高并发读写,又能及时回收无用数据。
二、Purge 线程的操作流程
启动条件
- 自 MySQL 5.6 起,Purge 线程默认启用(由参数
innodb_purge_threads控制,默认值为 4)。 - 主线程不再承担 Purge 任务,转而由独立的后台线程处理,提升并发性。
Purge 线程执行步骤(简化流程)
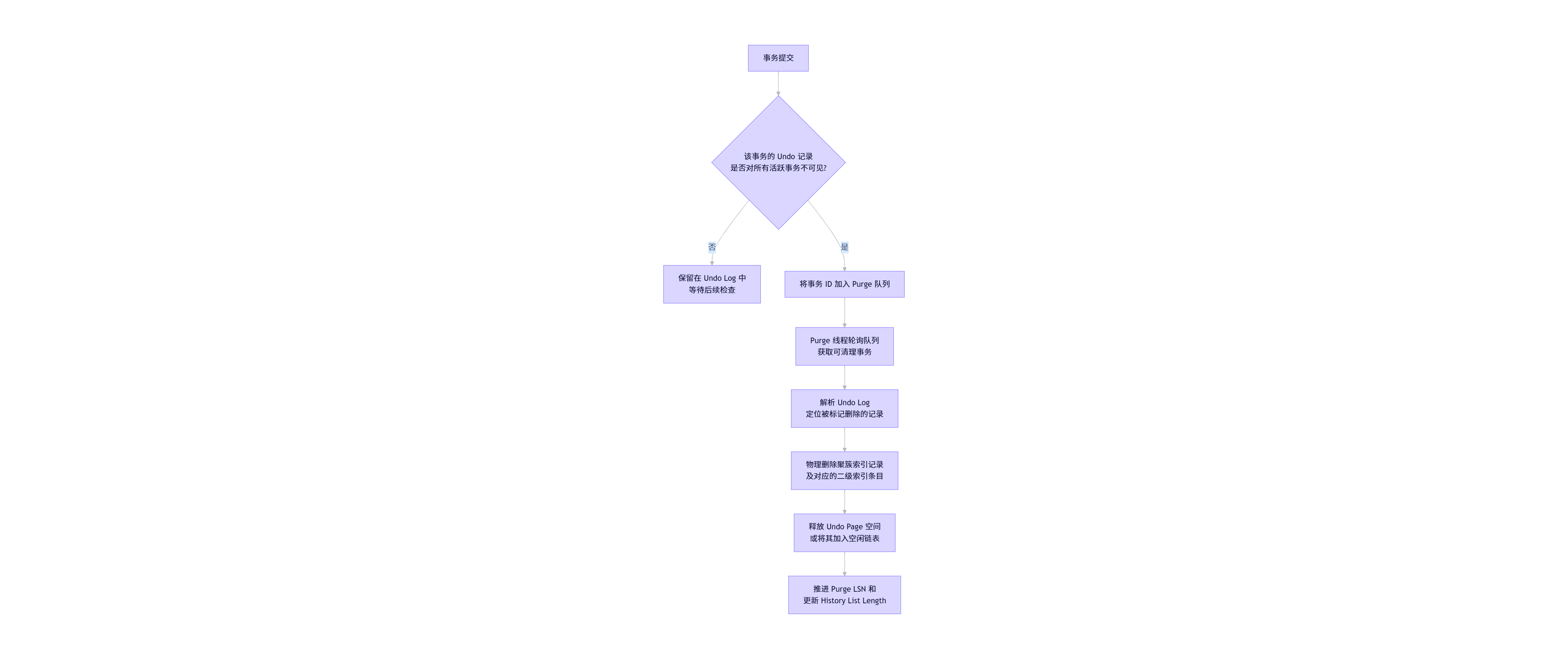
流程关键说明
| 步骤 | 说明 |
|---|---|
| A → B | 事务提交后,InnoDB 不会立即清理其 Undo 记录,而是等待"可见性判断"。 |
| B 判断依据 | 基于当前所有活跃事务的 Read View:若最小活跃事务 ID > 当前事务 ID,则该事务的旧版本已无任何读者需要。 |
| D:Purge 队列 | 实际由 Purge Coordinator Thread 维护一个待清理的 trx_id 列表,Worker Threads 消费该列表。 |
| F--G:物理删除 | 包括主键索引(聚簇索引)和所有二级索引的清理,可能触发 B+ 树合并操作。 |
| I:推进水位 | Purge LSN 是 InnoDB Checkpoint 机制的重要参考点;History list length 在 SHOW ENGINE INNODB STATUS 中可见,反映 Purge 延迟程度。 |
核心组件说明
| 组件 | 说明 |
|---|---|
| Undo Log | 存储事务修改前的数据快照,用于回滚和 MVCC |
| Read View | 事务启动时生成的可见性视图,决定哪些版本可见 |
| Purge Queue | 待清理的已提交事务 ID 列表 |
| Purge LSN | 是已被清理的 Undo Log 记录所对应的 Redo Log 中的最大 LSN |
三、Purge 线程与 MySQL 其他组件的交互
1. 与事务系统的交互
- 当一个事务提交后,其对应的 Undo 记录会被标记为"可 Purge",但不会立即清理。
- Purge 线程会等待所有早于该事务开始时间的 Read View 都结束,才安全清理。
2. 与 Buffer Pool 和磁盘 I/O
- Purge 操作涉及对聚簇索引和二级索引的物理删除,会触发页的读取与修改。
- 频繁或大规模 Purge 可能增加 I/O 压力,尤其在 SSD 性能不足的系统上。
3. 与 Checkpoint 机制的关系
- Purge 进度影响 Checkpoint LSN 的推进。
- 若 Purge 严重滞后,会导致 Redo Log 无法被覆盖,进而阻塞 Checkpoint,引发"Redo Log 写满"错误(如
ERROR 1205 (HY000): Lock wait timeout的间接诱因)。
原理:
InnoDB 的 Redo Log 能否被覆盖,取决于两个"水位线"中的 更保守者:
- 脏页刷盘水位(由 Buffer Pool 刷脏页决定)
- Undo 清理水位(由 Purge 线程推进的 Purge LSN 决定)
这是因为:
某些 Redo Log 记录不仅包含数据页修改,还包含 Undo 页的修改(例如 INSERT/UPDATE 生成的 Undo Log 写入操作)。
在这些 Undo 页被 Purge 并释放之前,对应的 Redo Log 不能安全丢弃------否则崩溃恢复时无法重建 Undo 链,导致 MVCC 或回滚失败。
因此,InnoDB 引入了 log_sys->lsn_available_for_checkpoint 的计算逻辑,其值为:
text
min(
最早未刷盘脏页的 LSN,
Purge LSN 对应的 Redo LSN
)若 Purge 严重滞后 → Purge LSN 停滞 → 可用 Checkpoint LSN 无法前进 → Redo Log 无法循环覆盖。
当 Redo Log 文件(通常 2×48MB 或更大)全部被"不可覆盖"的日志占据时,InnoDB 将暂停所有 DML 操作,等待 Checkpoint 推进。此时可能出现:
-
写入阻塞:应用线程卡住,响应超时。
-
错误日志 :虽然不会直接报
ERROR 1205(那是锁等待超时),但可能伴随:textInnoDB: Warning: too many concurrent transactions, log checkpoint is not advancingtextInnoDB: Wait for redo log flushed up to ...
四、Purge 线程的性能优化策略
常见问题场景
| 场景 | 表现 | 原因 |
|---|---|---|
| 长时间运行的只读事务 | Purge 严重滞后 | Read View 阻止旧版本清理 |
| 高频 DELETE/UPDATE | Undo 表空间快速增长 | 产生大量待 Purge 记录 |
| 单线程 Purge(旧版本) | CPU 利用率低,清理慢 | 并发能力不足 |
优化建议
-
增加 Purge 线程数量
sqlSET GLOBAL innodb_purge_threads = 8; -- 默认 4,最大 32(MySQL 8.0+)适用于多核 CPU 且 Purge 成为瓶颈的系统。
-
避免长事务
-
监控长时间未提交的事务:
sqlSELECT * FROM information_schema.innodb_trx ORDER BY trx_started ASC; -
设置
innodb_max_purge_lag限制 DML 操作速率(谨慎使用)。
-
-
合理配置 Undo 表空间(MySQL 8.0+)
-
使用独立 Undo 表空间便于管理与扩容:
iniinnodb_undo_tablespaces = 4 innodb_undo_directory = /data/undo
-
-
监控 Purge 延迟
-
查看 Purge 水位与最新事务的差距:
sqlSHOW ENGINE INNODB STATUS\G在输出中查找:
History list length: 12345 -- 值越大,Purge 越滞后
-
五、常见面试题
面试题 1:
为什么 Purge 线程不能立即删除已提交事务的旧数据?
答 :
因为 InnoDB 使用 MVCC 机制,其他并发事务可能仍需要读取该旧版本数据(基于其启动时的 Read View)。只有当所有活跃事务的 Read View 都不再需要该版本时,Purge 线程才能安全地物理删除它。这是保证一致性读 和隔离性的关键设计。
面试题 2:
如何判断 Purge 是否成为系统瓶颈?有哪些调优手段?
答 :
可通过以下方式判断:
SHOW ENGINE INNODB STATUS中 History list length 持续增长(> 10⁶ 通常需警惕);- Undo 表空间持续膨胀;
- 出现 Redo Log 无法循环覆盖的警告。
调优手段包括:
- 增加
innodb_purge_threads; - 杀掉长时间运行的只读事务;
- 升级到 MySQL 8.0 并使用独立 Undo 表空间;
- 避免大批次 DELETE,改用分批删除(如每次 1000 行)。