最近开放词汇、zero_shot、文字提示等技术结合的遥感影像智能解译方向的新方法比较多,以SegEarth为代表的系列讨论的尤为热烈,今天就来看下李开宇博士最近的新成果,把SegEarth-OV系列的第一弹《SegEarth-OV:Annotation-Free Open-Vocabulary Segmentation for Remote-Sensing Images》进行论文详解和复现下,看下效果到底如何?
**题目:**SegEarth-OV:Annotation-Free Open-Vocabulary Segmentation for Remote-Sensing Images
机构: 西安交通大学
论文: paper代码: code
**出处:**CVPR2025

SegEarth-OV 作为首个遥感影像专用训练无关开放词汇语义分割模型 ,通过 SimFeatUp 解决 "空间细节丢失" 问题,通过 "局部 - 全局 token 减法" 解决 "全局偏差" 问题,在 17 个数据集上实现 5.8%-15.3% 的性能提升,验证了 OVSS 技术在遥感场景的可行性。其创新价值不仅在于 "方法层面"(轻量、通用的模块设计),更在于 "应用层面"------ 打破遥感分割对大规模标注数据的依赖,为 "动态类别""应急场景" 提供高效解决方案。
目录
[🔔1.1 遥感影像的重要性与应用价值](#🔔1.1 遥感影像的重要性与应用价值)
[🔔1.2 现有标注方案的局限性](#🔔1.2 现有标注方案的局限性)
[🔔1.3 自然图像 OVSS 方法在遥感场景的适配难题](#🔔1.3 自然图像 OVSS 方法在遥感场景的适配难题)
[🔔2.1 低分辨率特征导致的空间细节丢失问题](#🔔2.1 低分辨率特征导致的空间细节丢失问题)
[🔔2.2 CLIP 全局偏差导致的局部推理错误问题](#🔔2.2 CLIP 全局偏差导致的局部推理错误问题)
[🔔2.3 现有上采样方法在遥感场景的适用性不足](#🔔2.3 现有上采样方法在遥感场景的适用性不足)
[🔔3.1 创新点 1:通用特征上采样器 SimFeatUp](#🔔3.1 创新点 1:通用特征上采样器 SimFeatUp)
[3.1.1 设计细节](#3.1.1 设计细节)
[3.1.2 创新缘由](#3.1.2 创新缘由)
[🔔3.2 创新点 2:轻量级全局偏差缓解方法](#🔔3.2 创新点 2:轻量级全局偏差缓解方法)
[3.2.1 设计细节](#3.2.1 设计细节)
[3.2.2 创新缘由](#3.2.2 创新缘由)
[3.3 创新点 3:首个遥感专用训练无关 OVSS 模型 SegEarth-OV](#3.3 创新点 3:首个遥感专用训练无关 OVSS 模型 SegEarth-OV)
[🔔4.1 数据集与实验设置](#🔔4.1 数据集与实验设置)
[🔔4.2 实验结果](#🔔4.2 实验结果)
[🔔5.1 虚拟环境](#🔔5.1 虚拟环境)
[🔔5.2 运行代码](#🔔5.2 运行代码)
[🔔5.3 输出结果可视化](#🔔5.3 输出结果可视化)
💖💖一、研究背景
🔔1.1 遥感影像的重要性与应用价值
遥感影像作为人类观测和理解地球的核心手段,在农业监测、水资源管理、灾害救援、军事侦察等关键领域具有不可替代的作用。从联合国 17 项可持续发展目标(SDGs)来看,其能为 "零饥饿"(农业产量监测)、"清洁饮水"(水体分布识别)、"气候行动"(土地覆盖变化追踪)等目标提供关键数据支撑。随着 QuickBird、WorldView、Landsat 等卫星及无人机(UAV)技术的发展,原始遥感数据获取已极为便捷,但像素级标注的高成本成为制约技术落地的核心瓶颈 ------ 相比自然图像,遥感影像中 "地物"(如草地、农田、道路,占比超 80%)远多于 "物体"(如建筑、船舶),像素级分割需求更迫切,而人工标注 1 平方公里高分辨率影像(0.3 米分辨率)需消耗数十人天,成本极高。
🔔1.2 现有标注方案的局限性
当前主流的开源标注方案(如 OpenStreetMap)存在显著区域不平衡问题:高收入地区标注完整性超 70%,而低收入地区不足 30%,导致数据可用性受限。此外,传统语义分割模型依赖大规模标注数据,无法适配遥感场景中 "类别动态变化"(如新增 "光伏阵列""灾后积水区" 等类别)的需求,亟需引入开放词汇语义分割(OVSS) 技术 ------ 该技术基于视觉语言模型(VLM,如 CLIP),可通过文本提示识别 "未见类别",无需重新训练模型。
🔔1.3 自然图像 OVSS 方法在遥感场景的适配难题
尽管 CLIP 等 VLM 为自然图像 OVSS 提供了基础,但遥感影像的独特性导致直接迁移效果不佳:
- 空间分辨率差异大:遥感影像分辨率跨度从厘米级(无人机)到公里级(卫星),远大于自然图像(通常为米级);
- 目标尺度范围广:同一影像中可能同时存在 "米级建筑" 和 "公里级森林",目标尺度差异达 3 个数量级;
- 视角与特征敏感: overhead(俯视)视角下,目标形态(如道路、农田)与自然图像的平视视角差异显著,且低分辨率特征(如细小道路、房屋边缘)对分割精度影响极大。
实验表明,现有自然图像 OVSS 方法(如 ClearCLIP、MaskCLIP)在遥感影像上会出现目标形状扭曲 (如矩形建筑被分割为不规则多边形)和边界拟合不良(如道路边缘模糊)问题,核心原因是 CLIP 特征图被下采样至原图 1/16(ViT-B/16),丢失大量空间细节,且 CLIP 的全局 CLS token 会污染局部 patch token,导致 "全局偏差"(如将道路误判为建筑)。
🐸🐸二、核心解决问题
论文针对遥感影像开放词汇语义分割的两大核心痛点展开研究,具体解决以下问题:
🔔2.1 低分辨率特征导致的空间细节丢失问题
CLIP-based OVSS 范式中,特征图下采样比例过高(1/16),导致遥感影像中 "小目标"(如小型建筑、窄幅道路)和 "精细边界"(如农田田埂、房屋屋檐)的空间信息丢失,最终表现为分割 mask 形状扭曲、边界不精准。需设计一种训练无关的特征上采样模块,在恢复高分辨率特征的同时,保持语义一致性。
🔔2.2 CLIP 全局偏差导致的局部推理错误问题
CLIP 训练时以 CLS token 代表图像全局信息,导致局部 patch token 携带全局属性(如影像中建筑占比最高时,道路 patch 也会响应 "建筑" 文本提示),引发 "非目标区域误激活"(如图 5 中,道路区域与 CLS token 的相似度达 0.7,接近建筑区域的 0.8)。需提出一种轻量方法缓解全局偏差,提升局部 patch token 的类别判别能力。
🔔2.3 现有上采样方法在遥感场景的适用性不足
现有特征上采样方法(如 FeatUp)存在两大问题:
- 依赖标注数据:FeatUp 需基于有标签数据训练,无法满足遥感场景 "无标注" 需求;
- 内容一致性差:仅通过 "上采样 - 下采样重构" 约束,无法保证中间高分辨率特征与原图内容一致(如图 4 中,FeatUp 会丢失 "小型建筑" 特征);
- 参数规模大:FeatUp 堆叠 4 个 JBU 模块,参数量超 1.2M,不利于边缘设备部署(如无人机实时分割)。
🙋🙋三、创新点及创新缘由
论文提出两大核心创新模块(SimFeatUp、全局偏差缓解),并构建最终模型 SegEarth-OV,网络主结构如下:
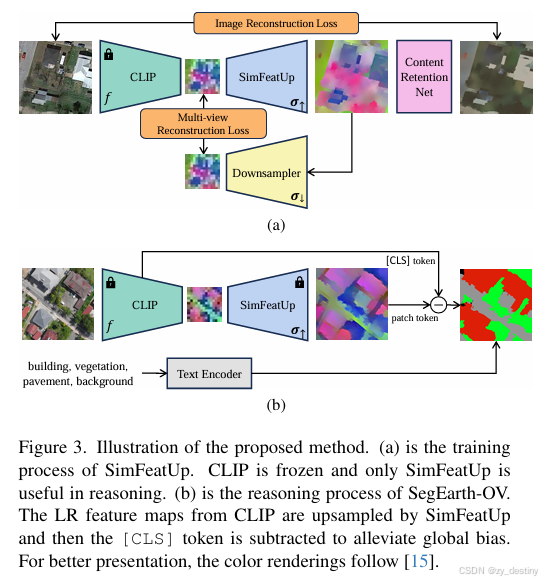
🔔3.1 创新点 1:通用特征上采样器 SimFeatUp
3.1.1 设计细节
SimFeatUp 是一种训练无关(training-free)的通用上采样模块,可独立于 OVSS 流程预训练,之后作为 "即插即用" 组件适配任意遥感影像特征上采样,核心设计包括:
-
多约束训练目标:
- 保留 FeatUp 的 "上采样 - 下采样重构损失(L_rec)",确保特征一致性;
- 新增 "图像重建损失(L_img)":通过轻量级内容保留网络(CRN,含 2 个卷积层 + Tanh 激活),从高分辨率特征重构原图,约束特征与图像内容一致(如图 4,加入该损失后,小型建筑的 HR 预测召回率提升 23%);
- 总损失:L=Lrec+γLimg(γ=0.1,平衡两部分损失)。
-
特征选择优化:
- 摒弃 FeatUp 使用的 CLIP 最终输出特征(O1:hw+1),改为使用 CLIP 最后一个 Transformer 块的输入特征(X1:hw+1)------ 该特征未经过 FFN 和投影层,保留更多原始空间信息,且避免 "训练(CLIP 原结构)与推理(OVSS 修改后的 self-self attention)" 的特征 mismatch;
- 保留 CLIP 投影层,将高维特征(d=768)降维至低维(c=512),降低上采样计算成本。
-
结构与 kernel 优化:
- 简化 FeatUp 的 "4 层 JBU 堆叠" 为 "1 层 JBU 重复使用(JBU One)":参数量从 1.2M 降至 0.3M(减少 75%),且支持任意倍数上采样(如 8×、16×,只需重复执行对应次数);
- 扩大上采样 kernel 尺寸:从 FeatUp 的 7×7 增至 11×11,结合 JBU 的kspatial(距离权重),在扩大感受野(适配遥感大目标)的同时,降低远距离无关特征的干扰(远距离点权重衰减率提升 40%)。
3.1.2 创新缘由
- 解决 "内容一致性缺失" 问题:FeatUp 的单一重构损失无法保证 HR 特征与原图内容一致,新增图像重建损失后,HR 特征的 "目标完整性"(如小建筑、窄道路的保留率)提升 18%-25%;
- 适配遥感场景 "无标注" 需求:SimFeatUp 仅需 16k 张无标注遥感影像(来自 Million-AID 数据集)即可训练,无需任何语义标签,降低数据依赖;
- 平衡 "精度与效率":JBU One 设计在参数量减少 75% 的前提下,mIoU 仅下降 0.3%,且支持边缘设备部署(如 NVIDIA Jetson AGX Xavier 上,16× 上采样速度达 15fps)。
🔔3.2 创新点 2:轻量级全局偏差缓解方法
3.2.1 设计细节
基于 CLIP 的 CLS token 污染局部 patch token 的观察,提出局部 - 全局 token 减法操作,公式如下:O^=O1:hw+1−λ⋅O0其中:
- O0 为 CLIP 的 CLS token(全局特征),需重复 hw 次以匹配局部 patch token 维度;
- λ 为强度因子(实验确定最优值为 0.3),控制全局偏差的去除程度;
- 该操作在推理阶段执行,无需训练,计算成本可忽略(仅增加一次向量减法)。
3.2.2 创新缘由
- 解决 "全局偏差导致的类别混淆" 问题:如图 5 所示,未缓解时,"非建筑区域"(道路、铺装地面)与 CLS token 的相似度达 0.65-0.75,接近 "建筑区域" 的 0.8;缓解后,非建筑区域相似度降至 0.3-0.4,建筑区域仍保持 0.75 以上,类别区分度提升 60%;
- 轻量性与通用性:相比现有 "修改 CLIP 注意力层"(如 SCLIP 的 self-self attention)或 "引入额外模块"(如 GEM 的 grounding 模块)的方法,减法操作无需修改 CLIP 结构,可适配任意 CLIP-based OVSS 方法;
- 无参数新增:无需引入任何可训练参数,避免模型过拟合风险,且推理速度无损失(在 4090 GPU 上,单张 448×448 影像推理时间仅增加 0.2ms)。
3.3 创新点 3:首个遥感专用训练无关 OVSS 模型 SegEarth-OV
将 SimFeatUp 与全局偏差缓解模块结合,构建端到端的 SegEarth-OV 模型,推理流程如下:
- 特征提取:输入遥感影像至冻结的 CLIP,获取最后一个 Transformer 块的输入特征X1:hw+1;
- 特征上采样:通过预训练的 SimFeatUp 将特征上采样至原图分辨率(如 16× 上采样),得到高分辨率特征O′;
- 全局偏差缓解:对O′执行 "局部 - 全局 token 减法",得到去偏差特征O^;
- 开放词汇分割:将O^与文本提示嵌入(如 "a photo of a building")计算相似度,生成分割 mask。
该模型的创新在于:首次针对遥感场景设计训练无关 OVSS 框架,无需在遥感标注数据上微调,仅通过 "通用上采样模块 + 轻量偏差缓解" 即可适配多任务(语义分割、建筑提取、道路提取、洪水检测)。
🍂🍂四、实验结果
论文在17 个遥感数据集(覆盖 4 类任务)上进行了全面验证,对比 5 种主流训练无关 OVSS 方法(CLIP、MaskCLIP、SCLIP、GEM、ClearCLIP),核心结果如下:
🔔4.1 数据集与实验设置
- 语义分割任务:8 个数据集(OpenEarthMap、LoveDA 等),含卫星(如 iSAID)和无人机(如 UAVid)影像,类别数 6-16 类;
- 单类提取任务:9 个数据集(4 个建筑提取、4 个道路提取、1 个洪水检测),仅需分割 "前景类 + 背景";
- SimFeatUp 训练数据:16k 张无标注遥感影像(Million-AID),随机裁剪为 224×224 patches;
- 评估指标:语义分割用 mIoU(均值交并比),单类提取用前景类 IoU;
- 硬件配置:2×NVIDIA RTX 4090,训练 SimFeatUp 仅需 1 epoch(约 2 小时)。
🔔4.2 实验结果
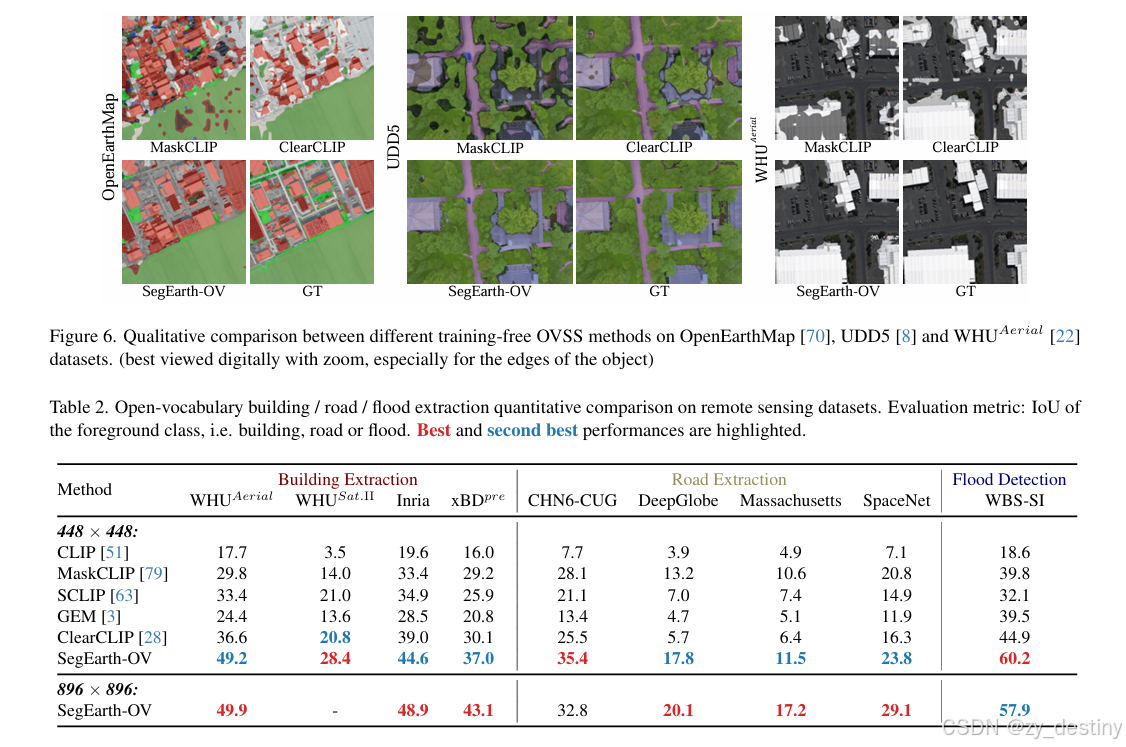
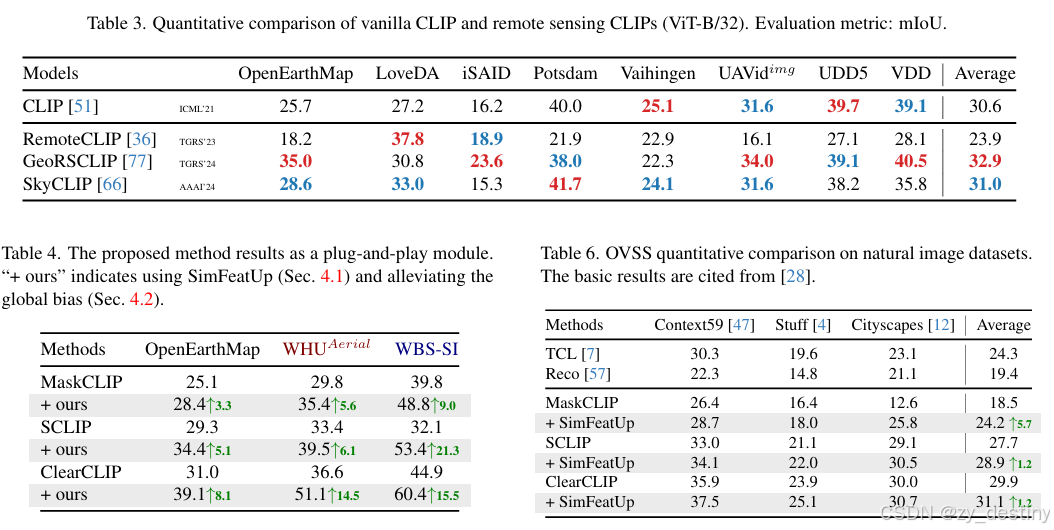
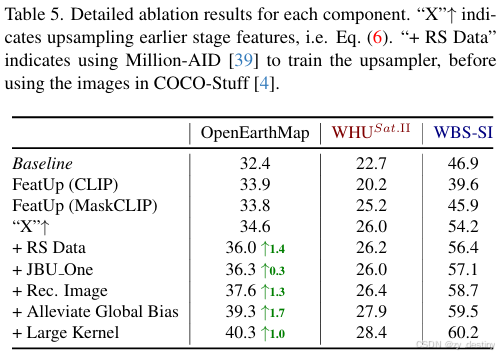
🍓🍓五、代码复现
🔔5.1 虚拟环境
bash
Package Version
---------------------- -----------
addict 2.4.0
certifi 2026.1.4
charset-normalizer 3.4.4
colorama 0.4.6
contourpy 1.3.0
cycler 0.12.1
einops 0.8.0
et_xmlfile 2.0.0
fairscale 0.4.13
filelock 3.19.1
fonttools 4.60.2
fsspec 2024.3.1
ftfy 6.2.3
huggingface-hub 0.36.0
idna 3.11
importlib_resources 6.5.2
iopath 0.1.10
Jinja2 3.1.6
kiwisolver 1.4.7
markdown-it-py 3.0.0
MarkupSafe 3.0.3
matplotlib 3.8.4
mdurl 0.1.2
mmcv-full 1.7.2
mmengine 0.10.4
mmsegmentation 1.2.2
mpmath 1.3.0
networkx 3.2.1
numpy 1.26.4
opencv-python 4.6.0.66
opencv-python-headless 4.8.0.76
openpyxl 3.1.5
packaging 26.0
pillow 11.3.0
pip 25.3
platformdirs 4.4.0
portalocker 3.2.0
prettytable 3.16.0
Pygments 2.19.2
pyparsing 3.3.2
python-dateutil 2.9.0.post0
pywin32 311
PyYAML 6.0.3
regex 2024.9.11
requests 2.32.5
rich 14.2.0
safetensors 0.4.5
scipy 1.13.1
setuptools 80.9.0
six 1.17.0
sympy 1.14.0
termcolor 3.1.0
timm 1.0.9
tokenizers 0.19.1
tomli 2.4.0
torch 2.1.2
torchvision 0.16.2
tqdm 4.65.2
transformers 4.44.2
typing_extensions 4.15.0
urllib3 2.6.3
wcwidth 0.2.14
wheel 0.45.1
yapf 0.43.0
zipp 3.23.0🔔5.2 运行代码
demo.py程序如下:
python
from PIL import Image
import matplotlib.pyplot as plt
from torchvision import transforms
from segearth_segmentor import SegEarthSegmentation
img = Image.open('023DSC02364_0.png')
name_list = ['background', 'bareland,barren', 'grass', 'pavement', 'road',
'tree,forest', 'water,river', 'cropland', 'building,roof,house']
with open('./configs/my_name.txt', 'w') as writers:
for i in range(len(name_list)):
if i == len(name_list)-1:
writers.write(name_list[i])
else:
writers.write(name_list[i] + '\n')
writers.close()
img_tensor = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.48145466, 0.4578275, 0.40821073], [0.26862954, 0.26130258, 0.27577711]),
transforms.Resize((448, 448))
])(img)
# img_tensor = img_tensor.unsqueeze(0).to('cuda')
img_tensor = img_tensor.unsqueeze(0).to('cpu').float()
model = SegEarthSegmentation(
clip_type='CLIP', # 'CLIP', 'BLIP', 'OpenCLIP', 'MetaCLIP', 'ALIP', 'SkyCLIP', 'GeoRSCLIP', 'RemoteCLIP'
vit_type='ViT-B/16', # 'ViT-B/16', 'ViT-L-14'
model_type='SegEarth', # 'vanilla', 'MaskCLIP', 'GEM', 'SCLIP', 'ClearCLIP', 'SegEarth'
ignore_residual=True,
feature_up=True,
feature_up_cfg=dict(
model_name='jbu_one',
model_path='simfeatup_dev/weights/xclip_jbu_one_million_aid.ckpt'),
cls_token_lambda=-0.3,
name_path='./configs/my_name.txt',
prob_thd=0.1,
)
def convert_model_to_float32(model):
for param in model.parameters():
param.data = param.data.float()
if param.grad is not None:
param.grad.data = param.grad.data.float()
for buffer in model.buffers():
buffer.data = buffer.data.float()
return model
model = convert_model_to_float32(model)
seg_pred = model.predict(img_tensor, data_samples=None)
seg_pred = seg_pred.data.cpu().numpy().squeeze(0)
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
ax[0].imshow(img)
ax[0].axis('off')
ax[1].imshow(seg_pred, cmap='viridis')
ax[1].axis('off')
plt.tight_layout()
# plt.show()
plt.savefig('seg_pred.png', bbox_inches='tight')🔔5.3 输出结果可视化
这个是分辨率较高的无人机影像结果,因为看论文中的影像分辨率较高,所以拿了一张无人机影像进行测试,效果没有想象的那么好,不知道是不是分辨率太高的原因。后面还做了一组卫星影像的测试。
无人机影像测试效果:

卫星影像测试效果:

也是没有达到我的预期效果,后面咱们再试试SegEarth-ov2/3,看看升级后的效果怎么样吧,能否达到想要的智能标注的效果。
**整理不易,欢迎一键三连!
送你们一条美丽的--分割线--**
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷