
这篇发布在Nature上的论文介绍了一种名为 AFLoc 的多模态视觉语言模型,旨在解决医疗影像分析中病灶定位 对专家标注过度依赖的问题。该模型通过多层级语义对齐 技术,将临床报告中的文本信息与医学影像的局部特征进行关联,实现了无需人工标注的自动定位与诊断 。实验结果证明,AFLoc 在胸部 X 线、眼底照影及病理切片等多种影像模态上均展现出卓越的跨场景泛化能力 ,性能优于现有的自监督和无监督学习方法。此外,该系统在实际临床工作流中显著提升了放射科医生的诊断准确率 并缩短了阅片时间。这种无需标注 的开发模式,不仅降低了算法构建成本,也为资源受限地区的医疗诊断提供了极具潜力的智能决策支持。
本文对其进行解读,由于原文没有写太多技术细节(理解确实也不复杂,但是用的数据集很多,实验比较扎实,代码写得很好,值得学习),本文会从代码层面进行剖析理解。
1.研究背景与核心痛点
标注成本高昂:传统的监督学习模型依赖于专家进行精确的边界框(bounding box)或像素级分割标注,这在医疗资源受限的环境下非常困难且难以推广。
现有方法的局限性:**非监督学习(异常检测)**通常只使用健康样本训练,但在处理高度异质性、病变对比度差异大的复杂病例时表现不佳;**现有视觉-语言模型 (VLM)**虽然能建立图像与报告的关联,但往往缺乏明确的定位标记。例如 GLoRIA 或 MedKLIP 等模型,可能因为仅关注单一层级的医疗概念(如单词)而忽略了不同语境下的语义变化,导致在临床实际应用中表现受限。
2.AFLoc 模型的核心架构
AFLoc 的核心优势在于其提出的多层级语义结构对比学习框架,实现了医学概念与图像特征的全方位对齐。
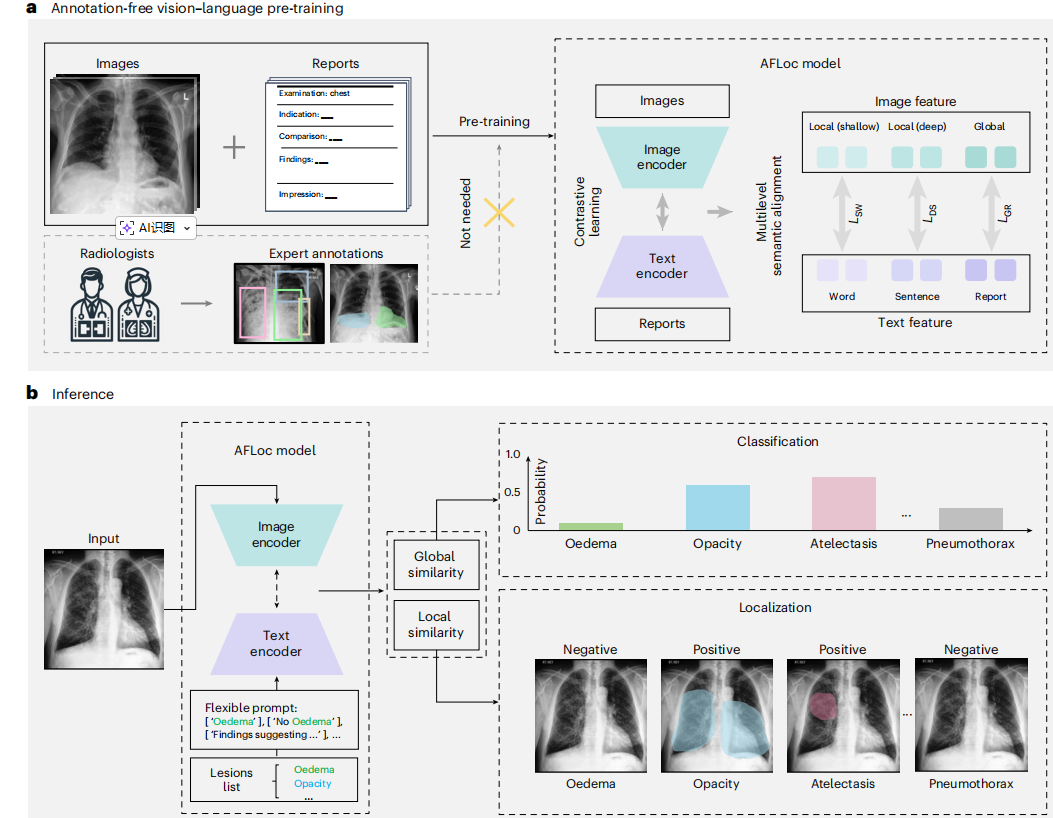
流程如下:
预训练阶段:利用现有的图像和文本报告进行多层级语义对齐训练,无需额外人工标注。
推理阶段:模型根据输入的疾病描述(Prompt)自动生成特征嵌入。
定位与分类:计算图像局部/全局特征与文本嵌入的相似度,生成热力图和分类概率。
后处理:仅在分类预测为阳性时输出定位结果,通过硬阈值生成二值分割掩码。
结构其实很简单:
1.图像特征的获取方式
图像编码器 (Image Encoder) :采用 ResNet-50 架构,提取三个层级的特征:浅层局部特征 (shallow local features)、深层局部特征 (deep local features)和全局特征(global features),。
AFLoc 采用了经典的 ResNet-50 作为图像编码器的骨干网络,通过提取不同阶段的卷积层输出来获得多层级特征:
• 浅层局部特征 (Shallow Local Features,vsv_svs) :从编码器的第三个下采样阶段提取。这些特征通常包含更多的纹理和细节信息,用于与单词级文本对齐。
• 深层局部特征 (Deep Local Features, vdv_dvd) :从编码器的第四个下采样阶段提取。这些特征具有更强的语义信息,用于与句子级文本对齐。
• 全局特征 (Global Features, vgv_gvg) :对图像编码器最后一个卷积层的输出进行平均池化 (Average Pooled) 处理,从而产生一个代表整张图像的向量。
• 维度匹配 :为了确保图像特征能与文本特征进行对比计算,模型对这三个层级的图像特征都应用了一个投影层 (Projection layer) 以对齐维度
2.文本特征的获取方式
模型使用 BioClinicalBERT 作为文本编码器,将临床报告分解并提取不同粒度的语义表示:
• 子词级特征 (Subword-level Features) :首先将报告标记化(Tokenize),输入编码器后,取最后 4 层特征的平均值作为基础的子词级表示。
• 单词级特征 (Word-level Features,twt_wtw) :通过汇总 (Summarized) 一个单词所属的所有子词特征,获得针对该单词的表示。
• 句子级特征 (Sentence-level Features,tst_sts) :通过对该句子包含的所有子词特征进行平均 (Averaged) 计算获得。
• 报告级特征 (Report-level Feature,trt_rtr) :通过对整篇报告中所有的子词特征进行平均计算,得到一个全局的文本向量
3.多层级语义对齐
开创性地 在医疗多模态任务中引入了极细致的三级对齐机制,这种获取方式是为了实现图像局部区域与文本描述的精确匹配
-
浅层局部特征与单词级特征对齐;
-
深层局部特征与句子级特征对齐;
-
全局特征与报告级特征对齐。 这种设计确保了模型既能捕捉到细微的病理细节,又能理解宏观的临床语境。
局部对齐 :通过计算相似性矩阵,将图像的局部特征(vsv_svs,vdv_dvd)与对应的单词(twt_wtw)和句子(tst_sts)进行对比学习。
全局对齐 :通过全局图像向量( vgv_gvg)与报告向量(trt_rtr)的对齐,确保模型理解整体临床语境。
实验证明 :消融实验显示,如果只使用单一粒度的特征(如仅单词或仅报告),定位性能会大幅下降,这证明了多粒度信息结合对于提高病理定位准确性的重要性。
3.主要研究成果与验证
该研究在 220,000 对胸部 X 光图像-报告数据集上进行了预训练,并在 8 个外部数据集(涵盖 34 种胸部病理)以及组织病理学和视网膜眼底图像上进行了验证。
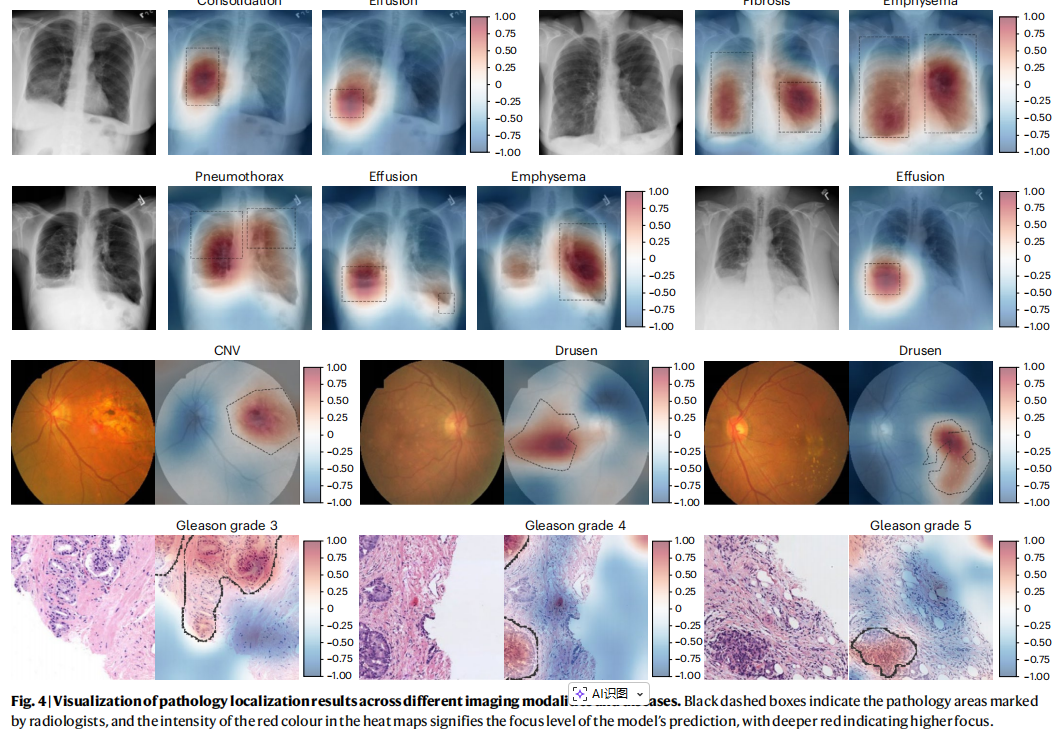
(1)胸部 X 光片表现:
在 RSNA Pneumonia、MS-CXR 等数据集上,AFLoc 在 IoU、Dice 系数和 CNR(对比噪声比)等指标上均显著优于 GLoRIA、BioViL 和 MedKLIP 等前沿方法。
在 CheXlocalize 数据集上,AFLoc 在空腔不透明度 (airspace opacity) 和胸腔积液 (pleural effusion) 等五种病理类型的定位上超越了人类基准
(2)跨模态泛化能力:
视网膜眼底图像:成功定位脉络膜新生血管 (CNV) 和玻璃膜疣 (drusen),表现优于 ConVIRT 等方法。
组织病理学:在 Gleason 评分(前列腺癌分级)任务中,其定位异常组织的能力超过了专门针对病理学设计的 PLIP 和 CONCH 模型。
新兴疾病适应性 :在未经针对性训练的情况下,AFLoc 对 COVID-19 肺炎的定位表现出良好的零样本 (zero-shot) 迁移能力。
4.关键洞察与消融实验
提示词 (Prompt) 的重要性:实验证明,**精确的临床术语描述(Precise description)**比简单的病理名称(Simple description)能显著提升定位精度,。例如,将提示词从"肺炎"改为"左下叶肺炎",AFLoc 的定位会更加聚焦且接近放射科医生的标注。
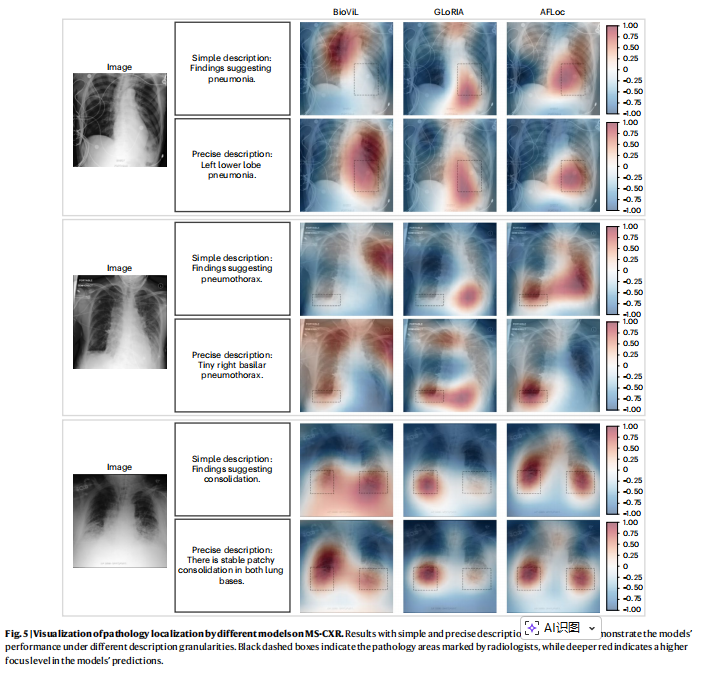
文本粒度的影响 :仅使用单词或仅使用报告层级特征都会导致性能大幅下降,证明了多层级信息组合对提高病理定位准确性的必要性
编码器选择:BioClinicalBERT 优于 LLaVA-Med,因为前者是在电子健康记录上训练的,与本研究使用的临床报告在领域语义上更契合。
5.临床应用价值
辅助诊断效率提升 :一项针对放射科医生的对照实验显示,在 AI 辅助下,医生的诊断得分从 10.80 提高到 11.74 ,且阅读时间缩短了 20.5%(从 27.92 秒降至 22.20 秒)。
小样本微调潜力:虽然 AFLoc 支持无标注定位,但只需 1% 到 10% 的标注数据进行微调,其分割性能就能进一步提升,显示出极佳的扩展性。
6.局限性
尽管表现优异,论文也指出了一些改进空间:
架构优化:未来可探索层次化多尺度特征融合框架,进一步强化特征提取。
不确定性估算:目前模型主要针对确诊结果进行定位,未来需整合不确定性技术,对分类不确定的病例发出警示。
更多模态拓展:将模型扩展到超声、MRI、基因组学和心电图等非视觉数据,构建统一的多模态表征空间。
7.代码理解
代码文件太多,不贴代码及注释,有很多细节是论文中没有写的,有很多工程技巧,为方便理解,我举了适当的简化例子,感兴趣请查看作者开源代码。
7.1 afloc/models/cnn_backbones.py:视觉骨干的"工厂函数"
提供 resnet_50 / densenet_121 / resnext_50 ... 等函数,统一返回三件事:把 model.fc 或 model.classifier 换成 Identity,使 backbone 输出"特征向量",不做分类。resnet 系列返回 interm_feature_dim=1024,但你会在 vision_model.py 里发现:局部特征真正取自 layer2/layer3,通道分别是 128/256(作者后续用 interm_feature_dim 只是作为 embedder 的输入通道基准,整体逻辑能跑通,但你要知道"局部特征通道 ≠ feature_dims")。
python
class Identity(nn.Module):
"""Identity layer to replace last fully connected layer"""
def forward(self, x):
return x
def resnet_34(pretrained=True):
model = models_2d.resnet34(pretrained=pretrained)
feature_dims = model.fc.in_features
model.fc = Identity()
return model, feature_dims, 1024
.....7.2 afloc/models/vision_model.py:图像编码器(ImageEncoder)
这是视觉侧的核心:取多层特征 + 投影到 768 维(或配置的 embedding_dim),用于三种对齐损失。
三种粒度的图像 embedding 同样来源于一次共享的 CNN 前向传播 ,区别在于从不同网络层级提取特征并进行投影 。具体而言,模型首先将输入图像统一上采样至 299×299 ,再送入 ResNet(或其他 backbone)主干网络;在前向过程中分别截取 浅层局部特征 (ResNet 的 layer2 输出,对应较高空间分辨率)、深层局部特征 (layer3 输出,对应更强语义但较低分辨率)以及 全局特征 (layer4 输出经全局平均池化)。随后,浅层与深层局部特征通过 1×1 卷积投影层 映射到与文本 embedding 相同的维度,用于保留空间结构的局部表示;全局特征则通过 线性投影层映射为单一向量,表示整幅图像的全局语义。最终,模型同时输出浅层局部、深层局部和全局三类图像 embedding,分别用于与文本的词级、句级和报告级表示进行多层次语义对齐。
最终图像侧给 AFLoc 的是:
img_emb_l:深层局部 embedding(句级对齐)img_emb_l2:浅层局部 embedding(词级对齐)img_emb_g:全局 embedding(报告级对齐)
代码中,对于resenet和densenet获取中间层特征的方式进行了分别处理:
对于Densenet是加钩子:
python
# 初始化时候:
if "densenet" in self.cfg.model.vision.model_name:
if self.cfg.model.vision.mode == 1:
# mode=1:选较深的 denseblock4 与 denseblock3 的 denselayer1.relu1 作为两个局部层
# hook1 对应更深层的 denseblock4
self.hook_fn1_module = self.model.features.denseblock4.denselayer1.relu1
# hook2 对应稍浅层的 denseblock3
self.hook_fn2_module = self.model.features.denseblock3.denselayer1.relu1
# 注册 forward hook:每次前向都会调用 hook_fn1 保存输出
self.hook_fn1_module.register_forward_hook(hook_fn1)
# 注册 forward hook:每次前向都会调用 hook_fn2 保存输出
self.hook_fn2_module.register_forward_hook(hook_fn2)
# mode=1 下作者设定中间层通道数为 512(用于后续 local_embedder 的输入通道)
self.interm_feature_dim = 512
elif self.cfg.model.vision.mode == 2:# mode=2:选 denseblock3 与 denseblock2 作为局部层(更浅一些)
self.hook_fn1_module = self.model.features.denseblock3.denselayer1.relu1# hook1:denseblock3
self.hook_fn2_module = self.model.features.denseblock2.denselayer1.relu1# hook2:denseblock2
self.hook_fn1_module.register_forward_hook(hook_fn1)
self.hook_fn2_module.register_forward_hook(hook_fn2)
self.interm_feature_dim = 256 # mode=2 下中间层通道数设为 256
elif self.cfg.model.vision.mode == 3:# mode=3:选更浅的 denseblock2 与 denseblock1
self.hook_fn1_module = self.model.features.denseblock2.denselayer1.relu1 # hook1:denseblock2
self.hook_fn2_module = self.model.features.denseblock1.denselayer1.relu1# hook2:denseblock1
self.hook_fn1_module.register_forward_hook(hook_fn1)
self.hook_fn2_module.register_forward_hook(hook_fn2)
self.interm_feature_dim = 128# mode=3 下中间层通道数设为 128
# 单独的forward
def densenet_forward(self, x, extract_features=False):
"""
Forward pass for DenseNet models.
Inputs:
x (torch.Tensor): batch of images (batch_size, 3, height, width)
extract_features (bool): whether to extract features
Returns:
x (torch.Tensor): global features (batch_size, 512)
local_features (torch.Tensor): local features (batch_size, 256, 19, 19)
local_features2 (torch.Tensor): local features 2 (batch_size, 128, 38, 38)
"""
# --> fixed-size input: batch x 3 x 299 x 299
# 同样先上采样到 299x299,统一输入尺度
x = nn.Upsample(size=(299, 299), mode="bilinear", align_corners=True)(x)
# 前向通过 DenseNet 特征提取部分(features 是一个大模块)
x = self.model.features(x)
x = F.relu(x, inplace=True)
# 全局平均池化到 1x1
x = F.adaptive_avg_pool2d(x, (1, 1))
# 展平得到全局向量
x = torch.flatten(x, 1)
# 从 hook1 保存的输出中取深层局部特征
local_features = self.hook_fn1_module.hook_fn1_output
# 从 hook2 保存的输出中取浅层局部特征
local_features2 = self.hook_fn2_module.hook_fn2_output
# 返回全局向量 + 两级局部特征
return x, local_features, local_features2对于ResNet是直接在forward中输出:
python
def resnet_forward(self, x, extract_features=False):
"""
Forward pass for ResNet models.
Inputs:
x (torch.Tensor): batch of images (batch_size, channel, height, width)
extract_features (bool): whether to extract features
Returns:
x (torch.Tensor): global features (batch_size, 512)
local_features (torch.Tensor): local features (batch_size, 256, 19, 19)
local_features2 (torch.Tensor): local features 2 (batch_size, 128, 38, 38)
local_features_final (torch.Tensor): local features final (batch_size, 512, 10, 10)
"""
# 把输入强制上采样到 299x299(作者固定输入尺度,保证局部网格大小稳定)
x = nn.Upsample(size=(299, 299), mode="bilinear", align_corners=True)(x)
# ResNet stem:conv1(输出通道 64)
x = self.model.conv1(x) # (batch_size, 64, 150, 150)
x = self.model.bn1(x)
x = self.model.relu(x)
x = self.model.maxpool(x)
# layer1:残差块组 1
x = self.model.layer1(x) # (batch_size, 64, 75, 75)
# layer2:残差块组 2(这里作为"浅层局部特征"输出)
x = self.model.layer2(x) # (batch_size, 128, 38, 38)
local_features2 = x # 保存浅层局部特征(更高分辨率,语义更浅)
# layer3:残差块组 3(这里作为"深层局部特征"输出)
x = self.model.layer3(x) # (batch_size, 256, 19, 19)
local_features = x # 保存深层局部特征(分辨率更低,语义更强)
# layer4:残差块组 4(更深层,语义更全局)
x = self.model.layer4(x) # (batch_size, 512, 10, 10)
local_features_final = x # 保存 final 局部特征(代码里虽返回,但默认不用于 loss)
# 自适应平均池化到 1x1,得到全局特征
x = self.pool(x) # (batch_size, 512, 1, 1)
# 拉平成向量(batch_size, 512)
x = x.view(x.size(0), -1) # (batch_size, 512)
# 返回全局特征向量 + 两级局部特征图 + final 特征图
return x, local_features, local_features2, local_features_final这里有个问题值得注意,为什么不统一都用钩子或者在forward中输出?因为resnet stage 边界天然清晰,而DenseNet block 内语义混合,只能精确截取。作者并不是要denseblock 的"最终输出",而是要 denseblock 内部"第一个 denselayer 的 relu 输出" ,denselayer1 的输出通道数是稳定、可控的,如果取 denseblock 的最终输出,通道数会非常大,且包含"过度拼接"的冗余特征。
7.3 afloc/models/text_model.py:文本编码器(BertEncoder)
从 BioClinicalBERT 拿 token 表示,再构造 word / sentence / report 三种粒度 embedding,并做投影与归一化。三种粒度的文本 embedding 都来源于 同一次 BioClinicalBERT 前向计算 ,区别只在于对 BERT 隐状态的聚合方式不同 。具体流程是:模型首先将输入报告送入 AutoModel,并开启 output_hidden_states=True,取 最后 last_n_layers 层的 hidden states ,在 layer 维度上按配置(mean 或 sum)进行聚合,得到每个 token 的上下文表示;随后,word-level embedding 是在 token 级表示上进一步通过 aggregate_tokens 将 WordPiece 子词(以 ## 开头)合并回"词",对同一词的子词 embedding 做均值或求和,形成词级序列表示;sentence-level embedding (当 take_sent_as_units=True 时)则在词/子词序列基础上,通过 aggregate_tokens_sent_as_units,利用 [SEP] 与句号等分隔符近似划分句子,并对每个句子内部的 token embedding 做平均,从而得到"句单元"序列表示;而 report-level embedding 则最为简单,直接对整个报告中所有有效 token 的 embedding 在序列维度上做全局平均,得到一个单一的向量表示整份报告。最终,这三种 embedding 在返回前都会(若 norm=True)做 L2 归一化,以便后续与图像特征进行对比学习。
值得注意的是:sent_embeddings 不是自然语言 parser 的句子,而是用 token 序列里的分隔符近似出来的句单元,这就是论文"句级对齐"的实现依据。
这部分代码实现看起来很复杂,不是因为"做了很多事",而是因为"同一件事被拆成了很多工程步骤,为了避免绕晕,我这里用个简单的例子来举例做了什么。
假设一条真实的影像报告是:"There is a mass in the left lung. No pleural effusion."
① Tokenizer 之后(最底层:token):
python
[CLS]
there
is
a
mass
in
the
left
lung
.
no
pleural
effusion
.
[SEP]
[PAD] [PAD] ...这是 token-level,不是 word、不是 sentence、不是 report。
word-level = 把 BERT 的 subword token 合并成"人类意义上的词" 。例如:"pleural" → 一个 token、"effusion" → 一个 token、"effusions" 可能会被拆成:effusion + ##s。BERT 给 每个 token 一个向量,如果发现:
python
effusion
##s就把这两个 token 的向量 合并(sum 或 mean) ,得到 一个"词"的 embedding
word-level:
python
[CLS] there is a mass in the left lung .
no pleural effusion . [SEP] [PAD] ...这就是 word_embeddings,在代码里对应的就是aggregate_tokens(...),shape 本质是:(batch, embedding_dim, num_words)
sentence-level = 把一整句话里的"词向量"再压缩成"一句话的向量"。
对我们的例子,
句子 1:There is a mass in the left lung.
句子 2:No pleural effusion.
本文并没有用NLP 的复杂句法分析,而是一个工程化的近似 :把 [SEP] 当成"句子结束",把 . 当成"句子分隔符",然后对 一句话里的所有 word embedding 取 mean ,得到一个 sentence embedding。
python
[CLS]
sent0 → "There is a mass in the left lung"
sent1 → "No pleural effusion"
[SEP]
[PAD] ...这就是 sent_embeddings,代码里对应的是:aggregate_tokens_sent_as_units(...),shape 本质是:(batch, embedding_dim, num_sent_units)
report-level = 整个报告的"总语义"
也就是说:"这整段话在说什么?",本文的方法也非常简单,没有用花式方式。直接把所有 word-level embedding 再做一次 mean / sum。或者(在多层 BERT 时),先对 token 维度平均,再对 layer 维度平均。得到的 report-level的一个向量,这个向量代表整份影像报告 ,用来和 整张图像的 global embedding 对齐。在代码里对应:report_embeddings,shape:(batch, embedding_dim)。
这是同一次 BERT 前向,不同"聚合尺度"的结果。
为什么 AFLoc 一定要搞这三层?
因为医学影像里的语义本身就是分层的:
- 词 → 病灶类型(mass / effusion / nodule)
- 句 → 病灶描述(位置、大小、是否存在)
- 报告 → 整体诊断语义
AFLoc 做的事情本质上是:用语言的"语义层级",去约束视觉的"空间层级"
再说得直白点就是:
word_embeddings → "一堆词,在图像上找局部证据"
sent_embeddings→ "一句话,在图像上找一个区域"
report_embeddings→ "整段话,对整张图像打分"
7.4 afloc/models/losses.py:三层对齐的对比学习损失
三层对齐的对比学习损失本质上由两类模块组成:全局对齐的 global_loss 和 局部对齐的 local_loss (同一套局部损失函数分别用于词级与句级)。其中 report--global 对齐(LGR) 由 global_loss(cnn_code, rnn_code) 实现:对 batch 内所有图像全局向量与文本报告向量计算两两相似度矩阵(归一化后的点积/余弦相似度),乘温度 temp3 后用交叉熵做 InfoNCE ,并同时计算"图→文"和"文→图"两个方向的对称损失。sentence--deep local 对齐(LDS) 与 word--shallow local 对齐(LSW) 都复用 local_loss(img_features, words_emb, cap_lens, ...):先用 attention_fn(query, context, temp1) 以文本序列(词或句单元 embedding)为 query、以图像局部特征图(深层或浅层)为 context 计算 cross-attention,得到每个词/句对应的加权图像上下文 weightedContext;再逐 token 计算文本向量与对应 weightedContext 的余弦相似度,经过温度 temp2 的指数化与 log-sum 聚合形成图文匹配分数,最终同样构造 batch 内相似度矩阵并用 temp3 做缩放,采用对称交叉熵实现局部层面的 InfoNCE。这样,代码用 global_loss 完成全局语义对齐,用 local_loss(两次调用) 分别完成深层局部-句级与浅层局部-词级对齐,三项损失在上层模型中加权求和对应论文的三层语义对齐训练目标。
下面用一个特别小、特别形象的例子,把 losses.py 里两件事讲清楚:
global_loss 在干嘛(报告级对齐)
local_loss + attention_fn 在干嘛(词/句级对齐 + 生成定位热图)
先用一个"最小 batch"例子,假设一个 batch 里只有 3 个样本:
-
图像:I0, I1, I2
-
文本(报告/句子/词序列):T0, T1, T2
训练的目标很简单:I0 应该和 T0 最像,I1 和 T1 最像,I2 和 T2 最像,同时,它们和"别人的文本/图像"要不像(负样本)。
global_loss 就是把 "图-文匹配" 变成一个 batch 内的 多分类问题,正确答案是对角线。
global_loss输入是cnn_code: 每张图一个向量(全局 embedding)→ shape (B, D)和rnn_code: 每段报告一个向量(报告 embedding)→ shape (B, D),先算一个 B×B 相似度矩阵 (余弦相似度 × temp3),这里 s00 就是 "I0 和 T0 的相似度"。
| T0 | T1 | T2 | |
|---|---|---|---|
| I0 | s00 | s01 | s02 |
| I1 | s10 | s11 | s12 |
| I2 | s20 | s21 | s22 |
然后做一个分类任务:
对 I0 这一行来说,模型要在 {T0,T1,T2} 里选正确的 T0,对 I1 这一行来说,选 T1,对 I2 这一行来说,选 T2,这就是 CrossEntropyLoss(scores0, labels),labels 就是 [0,1,2]。再反过来做一次(文本选图),所以有 loss0 和 loss1 两个方向。
local_loss:更像"拿着关键词去图里找证据",然后再做配对。local_loss 的核心难点在于:文本不是一个向量,而是一串 token(词或句单元),图像也不是一个向量,而是一张网格特征图(H×W 个区域)。所以它分两步:
第一步:attention_fn ------ "每个词去图上看哪里最相关"。输入query = 某条文本的 token embeddings(word-level 或 sentence-level) shape: (B, D, L),context = 图像局部特征网格,shape: (B, D, H, W)。假设 T0 里有 3 个词:
- w0 = "mass"
- w1 = "left"
- w2 = "lung"
而 I1 的图像局部网格有 19×19 个小块(361 个 region)。
attention_fn 做的事就是:计算每个 region 和每个词的匹配程度(点积),得到一个注意力分布:
- "mass" 在图上关注哪里
- "left" 在图上关注哪里
- "lung" 在图上关注哪里
最终输出:attn: (B, L, H, W) ------ 每个词一张热图 和weightedContext: (B, D, L) ------ 每个词对应一份"被加权汇聚过的图像证据向量"。
第二步:token-wise cosine + 聚合 ------ "每个词和它找到的图像证据比一比"
attention_fn 得到的 weightedContext 相当于每个词都有一个"图像证据向量",local_loss 接着做:对每个词,算cos(word_embedding, weighted_context_embedding)得到每张图一个 L 维向量(L=词数或句数)。把这些词的相似度合成一个"图文匹配分数":先 * temp2 再 exp(让差异放大、值为正),再对词维度 sum(或 mean,再 log。 这个组合本质上就是一种 log-sum-exp 风格的"把多词证据汇总成一句话证据"。于是,对固定的文本 T0,你会得到它和所有图像的分数列向量:
| score(T0, I0) | |
|---|---|
| I0 | r0 |
| I1 | r1 |
| I2 | r2 |
这就是 row_sim。对每个文本 Ti 都算一列,拼起来就是一个 B×B 矩阵 similarities:
| T0 | T1 | T2 | |
|---|---|---|---|
| I0 | a00 | a01 | a02 |
| I1 | a10 | a11 | a12 |
| I2 | a20 | a21 | a22 |
最后再像 global_loss 一样, 用 CrossEntropyLoss(similarities, labels) 强制对角线最大(图选文),再反向一次(文选图)。所以 local_loss 同时实现了两件事:对齐 (正确配对得分更高)和定位(注意力图告诉你每个词/句看图的哪一块)。
7.5classification/prompts.py
为每一个待预测的疾病类别构造一组语义多样但指向一致的自然语言描述,这些描述被划分为正向(pos)和负向(neg)两类。对于正向 prompts,脚本通常围绕同一疾病从不同角度进行改写,例如引入不同的严重程度(mild、severe)、影像学表现形式(consolidation、opacity)、以及空间位置描述(left lower lobe、right base 等),从而形成一个语义等价但表达多样的文本集合;负向 prompts 则用于明确表达"未见该病灶"或"无相关影像学征象"。这种设计的目的并不是让模型学习某一句特定描述,而是通过多样化的语言表达,逼近"该类别在语义空间中的整体分布",为后续构造稳定、鲁棒的类别表示打下基础。
这个脚本**把"一个医学类别(label)"改写成很多自然语言句子(prompts), 再把这些句子当作"文本输入",用于 zero-shot 分类。**也就是说,模型不再问"这是不是 effusion?",而是问"这张图像,像不像在说这句话?"假设现在有一个分类任务,类别里有:effusion。
医生会想:图上有没有胸腔积液?是左侧?右侧?双侧?小的?大的?
prompts.py 在做什么?它把这个"医学常识"提前写成文本模板 。对于 effusion,代码里定义的是:
severity(严重程度):small / stable / large / decreased / increased
subtype(类型):bilateral pleural effusion、subpulmonic pleural effusion
location(位置):left / right / tiny
然后做一件非常"暴力但有效"的事,三重 for-loop,全部组合!于是生成的正向 prompts 会像:
python
effusion: small bilateral pleural effusion left
effusion: large bilateral pleural effusion right
effusion: increased subpulmonic pleural effusion left
...可能一口气生成几十到上百条句子。
那 neg prompt(负提示)是干嘛的?对 effusion,neg prompt 非常简单:"no effusion."。这句话代表的是:"这张片子没有胸腔积液"。
在 zero-shot 分类时,模型实际上是在比较:图像 vs 正向描述(像不像"有 effusion")、图像 vs 负向描述(像不像"没有 effusion")。谁更像,就偏向哪个类别。
zero-shot 分类时发生了什么?图像经过 vision_model得到一个 全局图像 embedding (向量)。每个 prompt 句子经过 text_model得到一个 文本 embedding (向量)。然后计算相似度,如果 image 更像一堆 effusion 的正向句子→ effusion 概率高,如果 image 更像 "no effusion."→ effusion 概率低。这就是 prompt-based zero-shot 分类。
Pathology 分支为什么看起来"简单很多"?在代码中Chest X-ray prompt 特别多、特别复杂而Pathology prompt 很短、很干净。原因很现实,病理数据集的类别通常是:papillary / solid / acinar / lepidic,这些本身就是标准化的形态学术语,不需要再组合。所以 Pathology 的 prompt 逻辑是:每个类 → 一句"教科书式定义"。
所以,它不是在"生成文本", 而是在"把分类问题翻译成语言理解问题"。模型不是学effusion = 3,而是学"这张图,像不像在说:有 effusion?"。
prompts.py 正是把"类别"变成了"可对齐的语言锚点"。pos_query作用就是"如果这类存在,医生会怎么描述?",而neg_query就是"如果这类不存在,医生会怎么否认?",AFLoc 就是用这两句话,去"拷问"图像。
7.6classification/model_afloc.py
这些由 prompts.py 生成的文本描述被送入 AFLoc 预训练阶段已经对齐好的文本编码器
(BioClinicalBERT),并统一编码为报告级 embedding。对于同一个类别,模型会对该类别下所有正向 prompts 的 embedding 取平均,得到一个单一的"正类原型向量";如果启用了负向 prompts,则同样对负向描述取平均,得到对应的"负类原型向量"。随后,这些原型向量被直接拷贝进一个无偏置的线性层中,作为分类器的权重,并在推理阶段保持冻结,不再参与训练。这样,当一张图像经过 AFLoc 的图像编码器得到全局图像 embedding 后,只需与这些固定的类别原型向量做点积(或在多标签设置下对正/负原型做 softmax),即可得到各类别的预测概率。这种做法本质上复用了预训练阶段已经建立好的图文公共语义空间,用"文本定义类别、图像去匹配类别"的方式实现真正的 zero-shot 分类,而不需要任何额外的标注样本来学习分类头。
这个源码很简单,但有一点需要注意:
AFLoc 的 zero-shot 分类 =用文本 prompt 生成的 embedding,当作 linear 层的 weight,再用图像 embedding 去"点积投票"。
这里自然的一个疑问就是,为什么这样做?这个问题其实已经不是 AFLoc 这一个模型的问题,而是:
为什么在 zero-shot / CLIP 类方法中,可以把"文本 embedding 当作线性层的 weight"?
先从你最熟悉的东西开始:普通线性分类器在干嘛?一个最普通的线性分类器是:
logits=Wx(W∈RC×D,x∈RD)\mathrm{logits}=Wx\quad(W\in\mathbb{R}^{C\times D},x\in\mathbb{R}^D)logits=Wx(W∈RC×D,x∈RD)
几何意义(非常关键)Wi⋅x=∥Wi∥∥x∥cos(θi)W_i\cdot x=\|W_i\|\|x\|\cos(\theta_i)Wi⋅x=∥Wi∥∥x∥cos(θi)
也就是说:每一个类别的 weight 向量 WiW_iWi,本质上就是"这个类别在特征空间里的一个方向(prototype)"
分类就是在问:x 和哪个类别方向最对齐?
对于传统监督分类而言,类别方向 WiW_iWi 是 通过反向传播学出来的,这需要大量标注数据。
而对于zero-shot(AFLoc / CLIP):不学 WWW,而是:直接"算"出 W 。这其中的关键前提是图像 embedding 空间 和 文本 embedding 空间已经被对齐。
那回到刚才的问题,为什么"文本 embedding"可以当作"类别 weight"?前提是AFLoc 已经学会一件事。在预训练后:
一张图的 embedding和描述这张图的文本embedding在同一个语义空间里,方向是接近的
那么,"类别"是什么?
在 zero-shot 中:
类别 = 一种语义概念
比如:effusion = "有胸腔积液",pneumonia = "有肺炎表现"
而 prompts.py 正是在做一件事:
用一句(或多句)自然语言,来定义"effusion 这个概念"
所以:文本 prompt embedding 的几何意义,当你算:
python
emb = get_text_emb("bilateral pleural effusion")你得到的是一个向量:teffusion∈R768t_\mathrm{effusion}\in\mathbb{R}^{768}teffusion∈R768
这个向量的语义含义是:"胸腔积液"这个概念在 AFLoc 公共语义空间里的方向,这和线性分类器里的 WeffusionW_{\text{effusion}}Weffusion 在数学角色上是完全一致的。
继续思考为**什么是"塞进 linear.weight",而不是别的地方?**因为:
python
logits = self.fc(x)在 PyTorch 中等价于:logitsi=Wi⋅x\mathrm{logits}_i=W_i\cdot xlogitsi=Wi⋅x
如果我们直接把:
python
self.fc.weight[i] = text_embedding_of_class_i那模型算的就是:logitsi=⟨ximage,ttext⟩\mathrm{logits}i=\langle x\mathrm{image},t_\mathrm{text}\ranglelogitsi=⟨ximage,ttext⟩
也就是说算的是图像和"类别文本描述"的相似度,这正是 zero-shot 的定义。
**那为什么"平均多个 prompt"?**一个类别不是一句话能穷尽的:
python
effusion
= small effusion
= large effusion
= bilateral effusion
= left pleural effusion每一句 prompt 的 embedding:t1,t2,t3,...t_1,t_2,t_3,\ldotst1,t2,t3,...取平均:tˉ=1K∑ktk\bar{t}=\frac{1}{K}\sum_kt_ktˉ=K1∑ktk,这几何上是在做:对"effusion"这个语义簇求中心。源码中:
python
pos_cls_embed[i] = torch.stack(pos_embed).mean(dim=0)本质是在估计 类别中心向量。
那为什么不用 bias?
源码中:
python
nn.Linear(input_dim, num_classes, bias=False)原因很简单但很深刻:bias 会破坏"纯相似度"的几何意义,zero-shot 本质是 角度 / 方向比较,bias 会引入"类别先验",不再是纯语义匹配。
那 negative prompt 又是干嘛的?
可以把它理解成每个类别都有两个方向,如:正方向:"有 effusion",反方向:"no effusion",这样等价于问:这张图,更像"有 effusion",还是更像"没有 effusion"?
这是 AFLoc 比 CLIP 更偏医学的一个设计(医学里"否定"非常重要)。
其实"用文本 embedding 当作 linear weight"并不是技巧,而是这些方法共同遵循的第一性原理。为此我画了一个表格简要对比一下几种Zero-Shot:
| 维度 / 方法 | CLIP | ALIGN | AFLoc |
|---|---|---|---|
| 公共语义空间 | 图像编码器 + 文本编码器,通过全局对比学习对齐到同一向量空间 | 同 CLIP,规模更大、噪声更强的数据对齐 | 同 CLIP,但额外引入局部--局部、多粒度对齐 |
| 向量的几何含义 | 向量方向 ≈ 语义概念 | 向量方向 ≈ 语义概念 | 向量方向 ≈ 语义概念(且与空间位置相关) |
| 类别在几何中的角色 | 类别 = 文本描述向量(方向) | 类别 = 文本描述向量(方向) | 类别 = 文本 prompt 原型向量(方向) |
| 线性层 weight 的来源 | 直接用文本 embedding 作为 weight(不训练) | 同 CLIP | 同 CLIP,但可引入 pos / neg 双原型 |
| logit 的数学形式 | logit = x_img · t_text |
logit = x_img · t_text |
logit_pos = x_img · t_pos logit_neg = x_img · t_neg |
| zero-shot 分类本质 | 图像向量与"类别方向"的对齐度 | 同 CLIP | 同 CLIP,但显式比较"存在 / 不存在" |
| prompt 的角色 | 定义类别的"语义方向" | 同 CLIP | 定义类别方向 + 否定方向(医学友好) |
| prompt 聚合方式 | 多 prompt 平均 → 类别中心 | 多 prompt 平均 | 多 prompt 平均 → 正类中心 + 负类中心 |
| 是否有 bias | 无(保持纯相似度几何) | 无 | 无 |
| 局部特征是否参与对齐 | (仅全局) | (仅全局) | (word / sentence / report ↔ 多尺度图像) |
| 定位能力的几何来源 | 无显式定位 | 无显式定位 | 局部 embedding 与 token embedding 的方向对齐 → attention 热图 |
| 适用场景直觉 | 通用视觉--语言理解 | 大规模弱监督跨模态 | 医学影像:既要分类,又要"说清楚在哪" |
可以把这三种方法统一理解为:
一旦图像与文本被对齐到同一个向量空间, "类别"就不再是一个 id, 而是一个"方向向量"; 分类就是向量之间的对齐度比较。
CLIP / ALIGN:用文本直接定义类别方向
**AFLoc:**用文本定义类别方向,再用局部--局部对齐把"方向"投影回空间位置
7.7AFLoc-master/localization/
这部分代码的职责可以概括为三件事:一是把不同数据集的"定位标注"(box / polygon / rle / 像素mask)统一读出来并转成 mask;二是调用 AFLoc 做"图像--文本匹配"生成 similarity heatmap,并做尺寸对齐、边缘 NaN mask、归一化;三是在一组阈值上把 heatmap 二值化成预测掩码,计算 IoU/Dice/CNR/AUC 等指标并支持 bootstrap 置信区间。
7.8 localization/datasets.py
负责"把各种格式的标注统一成可评估的 mask/box",同时也提供 heatmap 归一化等通用工具函数。它包含几类关键函数:第一类是标注几何处理,例如 box_mapping 用于把 box 从原图空间映射到 resize/裁剪后的空间,box2mask 把 box 直接转成二值 mask,rle2mask 把 SIIM 那种 RLE 编码解成 mask;第二类是 heatmap 处理,norm_heatmap(heatmap_, nan, mode) 会在忽略 NaN 区域的前提下对热图做 min-max 归一化,默认把数值缩放到 [-1, 1](这点和论文描述一致),并保持 NaN 区域不参与归一化;第三类是数据加载入口与各数据集解析器,例如 load_data 作为统一入口,根据 dataset name 分发到 load_ms_cxr(MS-CXR phrase grounding)、load_rsna_grounding(RSNA Pneumonia box)、load_covid_rural(COVID Rural polygon)、load_chexlocalize(CheXlocalize pixel mask)、load_sicapv2_grounding(SICAPv2 等病理定位)等函数。整体上它把不同数据集最终组织成统一的记录结构(通常包含图像路径、文本描述/类别名、gt mask 或 gt box 等),让推理与评估部分不需要关心各数据集原始标注格式差异。