点击蓝字 关注我们

本文共计3218字 预计阅读时长10分钟
1月16日,Agentic AI Summit 2026在北京中关村展示中心会议中心举办,聚焦 Agent 从底座到应用的全链路实践。腾讯云大数据围绕 Data+AI 深度融合的产业趋势,带来数据智能即服务(DIaaS)整体实践,并发布了面向 AI 的数据湖方案 TCLake+EMR。该方案以统一多模态数据底座与 CPU+GPU 混合调度为核心,推动数据平台进入统一底座阶段。
伴随 Data+AI 深度演进,AI 应用从奢侈品变成必需品。企业既要把画像与标签等结构化数据接入 Agent,也要把商品图文、PDF、音视频等非结构化数据完成预处理、切片、向量化与 Rerank,构建可用的 RAG 链路;同时,大模型性能提升也更依赖高质量、多样性的多模态数据。
这类变化让数据平台面临新的要求:传统组装式数据平台与 AI 工作负载天然割裂,计算资源与数据难以共享;统一元数据与多模态存储能力不足,非结构化数据难以实现统一处理、统一存储、统一应用;底层调度长期以 CPU 为中心,难以覆盖 AI 工作负载所需的 GPU;当 Data+AI 叠加后,平台复杂度上升,排障与调优对人工依赖更高。
01
# DIaaS# 让数据智能触手可及
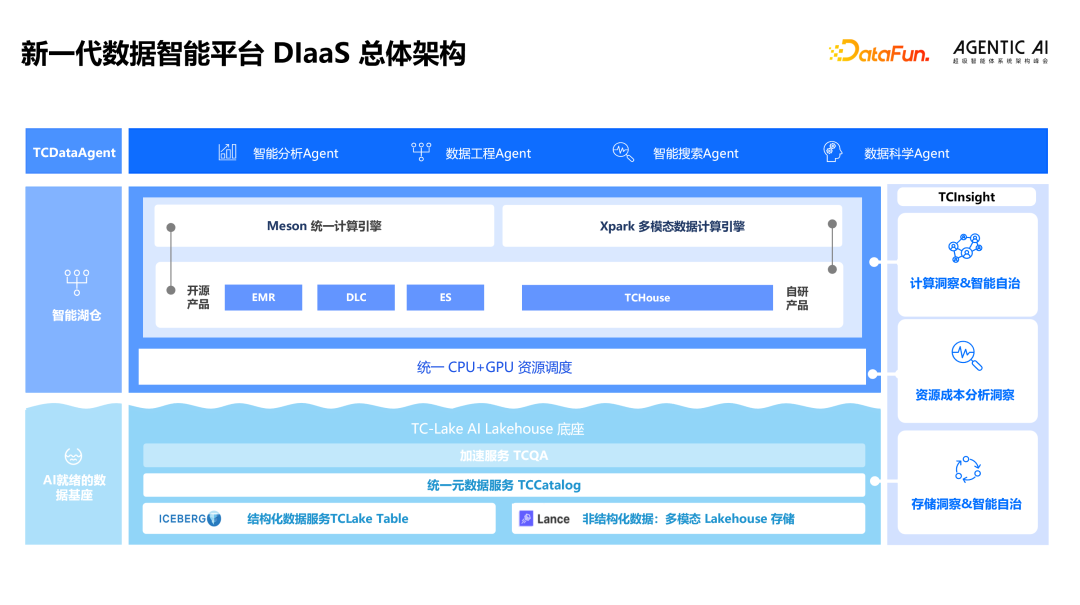
面向上述变化,腾讯云大数据推出数据智能即服务平台 DIaaS(Data Intelligence as a Service):以统一的多模态数据存储底座、统一的多模态计算引擎、统一的资源调度、统一平台自治服务为核心,通过低/无代码的自然语言交互方式与数据分析智能体(TCDataAgent),让用户在与 Agent 的交互过程中完成数据分析、机器学习训练、多模态数据检索等任务,让非技术人员也能轻松使用数据智能。
DIaaS 的关键组件包括统一多模态智能数据湖 TCLake、多模态统一计算引擎 Meson、数据分析智能体 TCDataAgent、平台智能管家服务 TCInsight,以及面向超大规模 CPU+GPU 一体化平台集群的统一资源调度服务。在自然语言交互能力上,TCDataAgent 的 NL2SQL 能力在 BIRD-Bench 评测中取得 75.74 分,跻身全球前三、国内第一。
02
# TCLake+EMR #
让数据与算力在同一底座上协同
面向 AI 的数据湖方案 TCLake+EMR,以一套多模态数据湖底座承载结构化与非结构化数据,以一套 CPU+GPU 混合调度体系承载数据工程与 AI 工作负载,并打通从数据准备、训练评估到部署推理的端到端闭环。
TCLake 是腾讯云推出的开放、智能、融合的新一代 AI 数据湖底座,提供覆盖结构化+非结构化数据的统一管理,内置多模态统一数据目录、批流一体表格式、智能数据管理、数据加速服务,上层无缝对接腾讯云及主流开源 Data+AI 生态引擎。在能力设计上,TCLake 提供批流一体表格式 TCIceberg(兼容 Apache Iceberg),并提供兼容 Lance 生态的自研多模态数据格式,一套格式同时覆盖结构化数据以及视频、音频、文档、模型等非结构化数据业务需求;同时通过大数据智能管家实现小文件合并、无效数据清理、数据组织优化等智能自治,通过原生加速引擎提供计算感知、智能分层、分层加速等 Workload 加速能力。
与 TCLake 的统一数据底座相配套,EMR 完成定位升级,从数据平台升级为数据智能平台,面向数据分析师、业务人员、数据科学家、AI 工程师提供开箱即用的数据智能服务与能力。底层调度从传统 CPU 体系走向 Ray+CPU+GPU 混合调度,面向超大规模 CPU+GPU 一体化平台集群,实现传统数据工程与 AI 工作负载的统一任务与资源调度;在多引擎栈上,支持在 Spark、Ray、Meson、Xpark 等框架间进行全局资源调度与智能弹缩,保障高优先级训练任务的资源供给,同时在闲时缩容避免浪费。
围绕统一底座的性能与效率, 在计算引擎侧重点强化两类能力。一是自研高性能计算引擎 Meson。Meson 作为原生向量化查询引擎,可无感加速 Spark SQL 与 DataFrame 工作负载,并通过兼容 Spark API 及函数级 fallback 机制,在不改业务代码的前提下提升性能与稳定性。Meson 采用 Pipeline 执行模型提升并发,结合列式计算、向量化算子与 SIMD 指令集提升吞吐,并通过兼容策略降低引入成本。在 TPCDS 1TB 测试中,Meson 相较社区 Spark 整体性能提升 2.7 倍;部分计算密集型查询提升可达 5 倍,同时 CPU 与 IO 等资源消耗显著下降。
二是面向 Python 生态与 AI 场景的多模态数据计算引擎 Xpark。Xpark 基于 Python 生态提供一体化的多模态分析、预处理、训练与推理能力,内置跨模态处理算子与 AI Function,以更少的工程拼装覆盖典型多模态链路,提升开发效率;同时支持自定义镜像与自定义算子/模型接入,便于企业复用内部能力并快速扩展。
在异构算力承载上,EMR 结合 TCRay 增强统一调度与生态承载能力,对 Ray 的容错、Object Store 读写与 Evict 性能、Actor 编排等进行增强,并结合向量化与 JIT 优化、Shuffle 改进、并行读取优化与 Checkpoint 故障恢复机制,覆盖从数据处理到训练与对齐、从推理加速到应用编排与 MLOps 的完整 AI 工作负载,包括分布式训练、LLM 预训练、SFT 监督微调、DPO/RLHF 等对齐流程、超参搜索与实验并行,以及在线服务侧的多模型路由、批流推理、RAG、多模态生成式应用与 Multi-Agent 编排等。
03
# 多行业落地 #
更高效率、更低成本、更易运维
面向 AI 的数据湖方案 TCLake+EMR 已在多个行业落地,把多模态数据处理、异构算力调度与平台自治能力收敛到同一底座,减少跨平台搬运与重复建设,提升交付效率并降低综合 TCO。
在智能终端行业,面向端侧 GenAI 应用增长,企业需要统一的多模态处理与分析能力,用于支撑拍照一键购物比价、AI 截图、手机文档图文解析、智能会议记录等功能。基于面向 AI 的数据湖方案 TCLake+EMR,通过增加 GPU 节点快速具备多模态数据处理能力,并借助预设多模态算子完成多类 AI 应用的数据预处理;结合 CPU+GPU 混合调度,在传统数据工程与 AI 工作负载间高效调度,提升 CPU 和 GPU 利用率。多模态数据应用开发效率提升 20%,结合统一调度进一步节省 30%+ 计算成本;同时引入 TCInsight 智能管家能力后,故障响应时间缩短 50%,实体计算资源缩减 15%。
在机器人硬件行业,面对海量环境视频数据的关键帧抽取需求,面向 AI 的数据湖方案 TCLake+EMR 提供开箱即用的视频关键帧抽取算子,并通过 CPU+GPU 混合调度为不同处理作业合理编排资源,预期整体可降低 30%+ 的 GPU 算力成本。
面向集团型企业的复杂场景,面向 AI 的数据湖方案 TCLake+EMR 支持在同一平台内同时完成传统数据工程与深度学习训练,数据与算力在同一底座上复用,减少跨系统导出/导入与双平台维护成本;在客户测算口径下,整体成本相较原有海外平台可实现显著下降,最高可达 70%。
腾讯云大数据持续打造 AI-Ready 的智能大数据平台,帮助各行业客户加速释放数据与智能融合价值。
Tencent BigData
关注腾讯云大数据 ╳探索数据的无限可能
往期精彩



求点赞

求分享

求喜欢
