C++AI大模型接入SDK---API接入大模型思路
文章目录
- C++AI大模型接入SDK---API接入大模型思路
-
- 1、API接入大模型思路
- [2、API key获取](#2、API key获取)
- 3、数据结构设计
- 4、日志封装
项目地址: 橘子师兄/ai-model-acess-tech - Gitee.com
博客专栏:C++AI大模型接入SDK_橘子师兄的博客-CSDN博客
博主首页:橘子师兄-CSDN博客
通过对ChatSDK的简单了解之后,接下来我们逐步拆解如何通过C++语言接入各种大模型。
1、API接入大模型思路
大模型需要强大的算法支持,训练一个大模型的成本太高,动辄几万甚至上百万,而且中间技术门槛也比较高,普通用户本地部署成本很高。为了降低大家的使用门槛,各个大模型厂商都开放了基于HTTP协议的大模型的API接口,不仅可以让企业或个人方便快速集成大模型能力,专注业务开发,构建自己个性化的服务,也能吸引大量开发者参与开发出各种应用服务,还能凑近整个生态的繁荣。下面以DeepSeek为例,下面是官方提供的使用curl工具给deepseek-chat模型发送消息的示例:
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <DeepSeek API Key>" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'以下使用apifox工具给DeepSeek的deepseek-chat发送聊天消息
Base url:https://api.deepseek.com
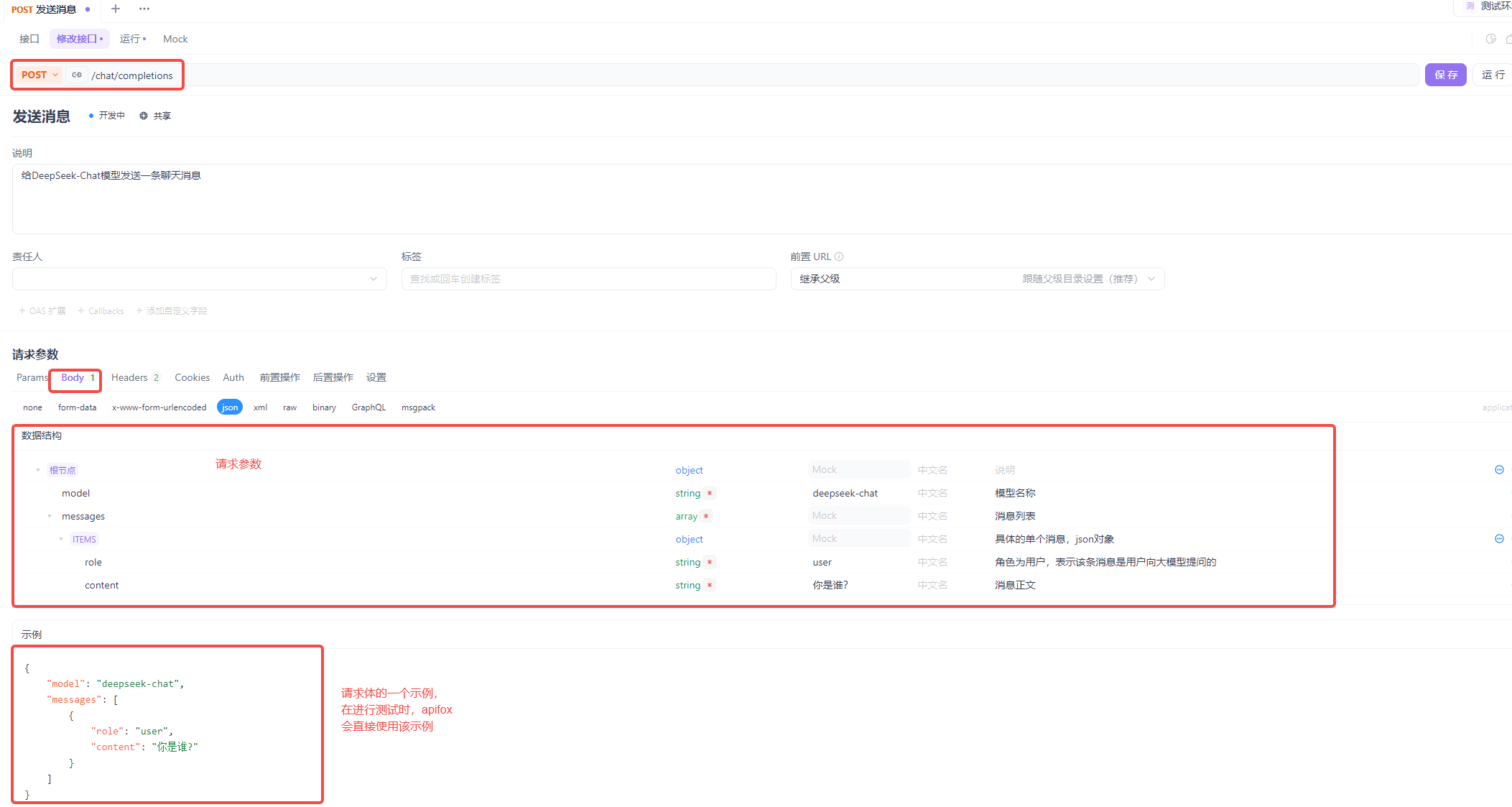
【角色 - role】
为模型提供当前文本的角色信息,帮助模型更好的理解上下文并生成合适的响应。
在大多数模型中,角色一般有三种:
user:表示当前文本是用户输入的内容
{
"role": "user",
"content": "你好,我想了解一下健康饮食的基本原则。"
}assistant:表示当前文本是模型自身输出的内容
{
"role": "assistant",
"content": "健康饮食的基本原则包括均衡摄入各种营养素、控制热量摄入、多吃蔬菜水果、减
少高糖高盐高脂肪食物等。"
}**system:**设置AI助手的身份,大模型将会以该身份回复用户问题
{
"role": "system",
"content": "你是一位专业的营养师,专注于健康饮食领域。"
}**tool:**实现工具调用(之前称作函数调用),大模型需要调用外部工具更好回答用户问题,tool消息
用来将工具执行结果返回给模型,让模型基于该结果生成最终回复。
请求头设置:

响应体暂时不用设置,直接采用默认接口,将来直接看DeepSeek返回的文本就好。
接口定义完成之后,配置测试环境:
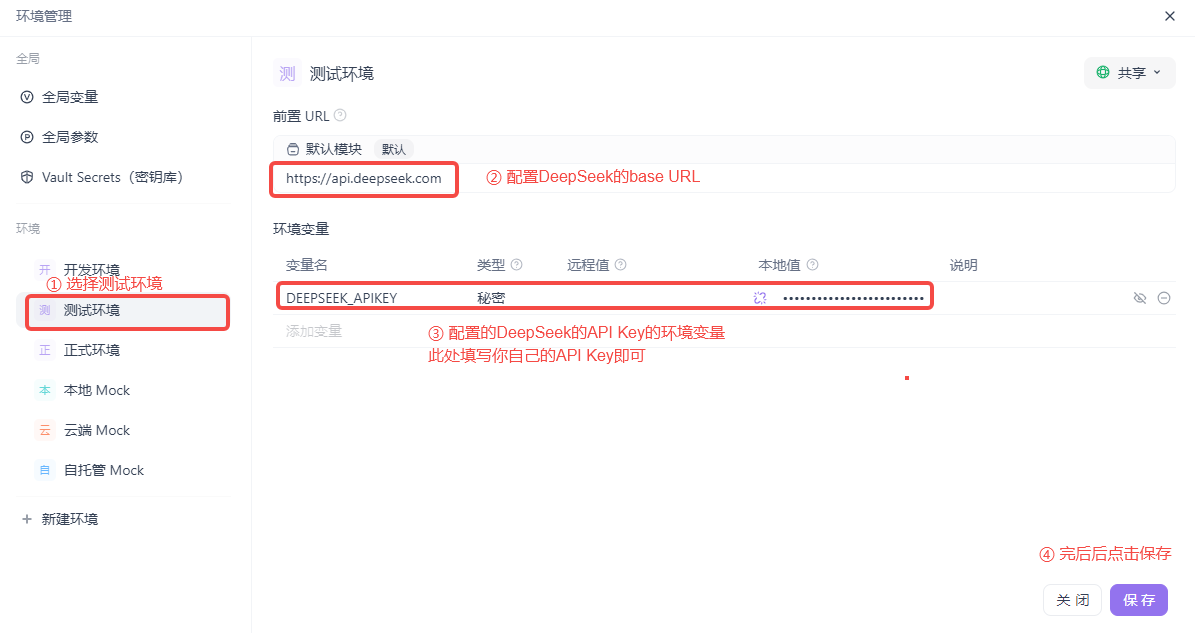
测试环境配置好之后,选择测试环境,点击发送按钮,apifox会将请求发送给DeepSeek的服务器,并将相应输出:
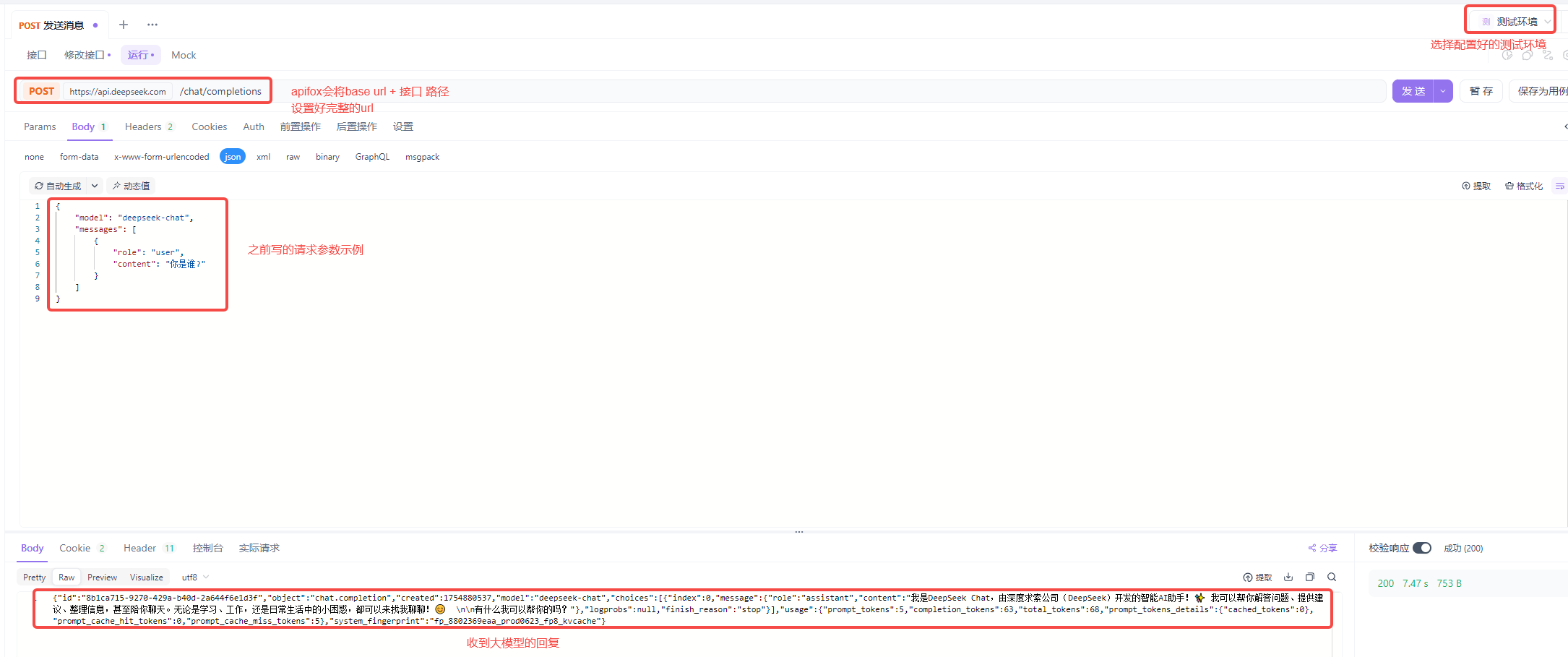
从该实例可以看出,在自己的应用程序中接入大模型方式非常简单:查看大模型官方提供的API接口,在程序中调用接口给大模型发送请求并响应即可。
2、API key获取
API Key是是一种用于身份验证和授权的密钥,本质就是一个通过特定算法生成的字符串,主要用于:
- 身份验证:验证你的应用程序是否被授权,只有拥有API Key的用户才能调用大模型的API
- 授权:限制应用程序对特定功能或资源的访问权限。比如:某些高级功能需要特定API Key才能访问
- 监控和限制:监控API的使用情况,比如统计请求次数、限制请求频率,以防滥用
- 计费:根据API的使用情况,向用户收取费用
考上大学后,家长为方便给你提供生活费以及学费,帮你办了一张某银行的银行卡,拿着银行卡就可以享受该银行提供的查询、取钱、转账等服务。
API Key :就像银行卡,每次办理业务时都需要带上银行卡
身份认证 :你去银行柜台办理业务,柜员会要求你出示银行卡。刷卡或读卡的过程就是验证这张卡是否真实、有效,是否属于本行
授权 :你的普通储蓄卡只能存取款和转账,而你父母的VIP黑金卡还能享受机场贵宾厅、专属理财经理等服务。卡的等级决定了你能做什么
监控和限制 :银行会监控每张卡的交易。你的银行卡可能有单日转账限额1万元的规定,防止卡片被盗后损失过大
计费: 银行会根据你的账户流水向你收取手续费、短信通知费等。
【DeepSeek api-key获取】
打开官网后,点击API开发者平台

点击API keys
点击创建API key按钮,获取API key
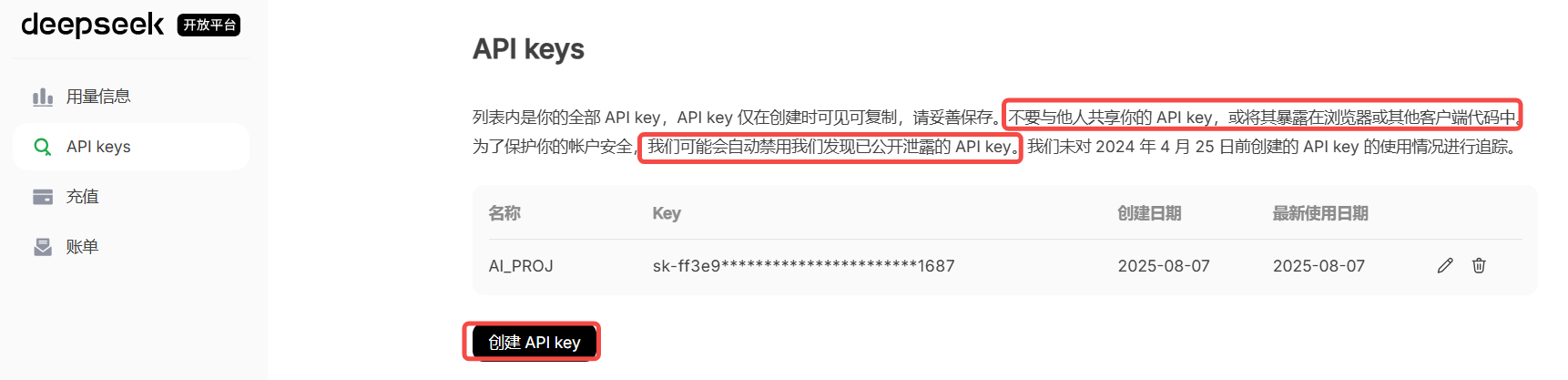
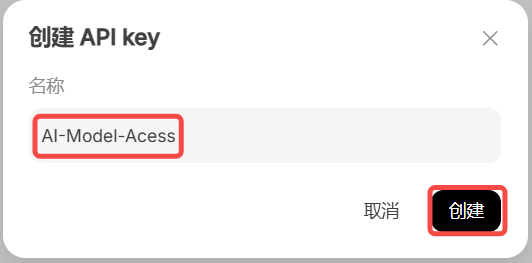
创建好之后,将你的API Key复制保存在本地,窗口关闭后将会以加密方式在网页显示。注意:请妥善保管好自己的API Key,切勿告诉他人。
点击网页左侧栏接口文档选项,在弹出的页面中就能看到模型名称 以及服务器地址:

【ChatGPT API key获取】
官网:https://openai.com/zh-Hans-CN/
如果没有账号需要先注册账号,这里直接使用邮箱来注册即可。
登录成功之后,就进入到开发者的API平台了
点击右上方的 API reference
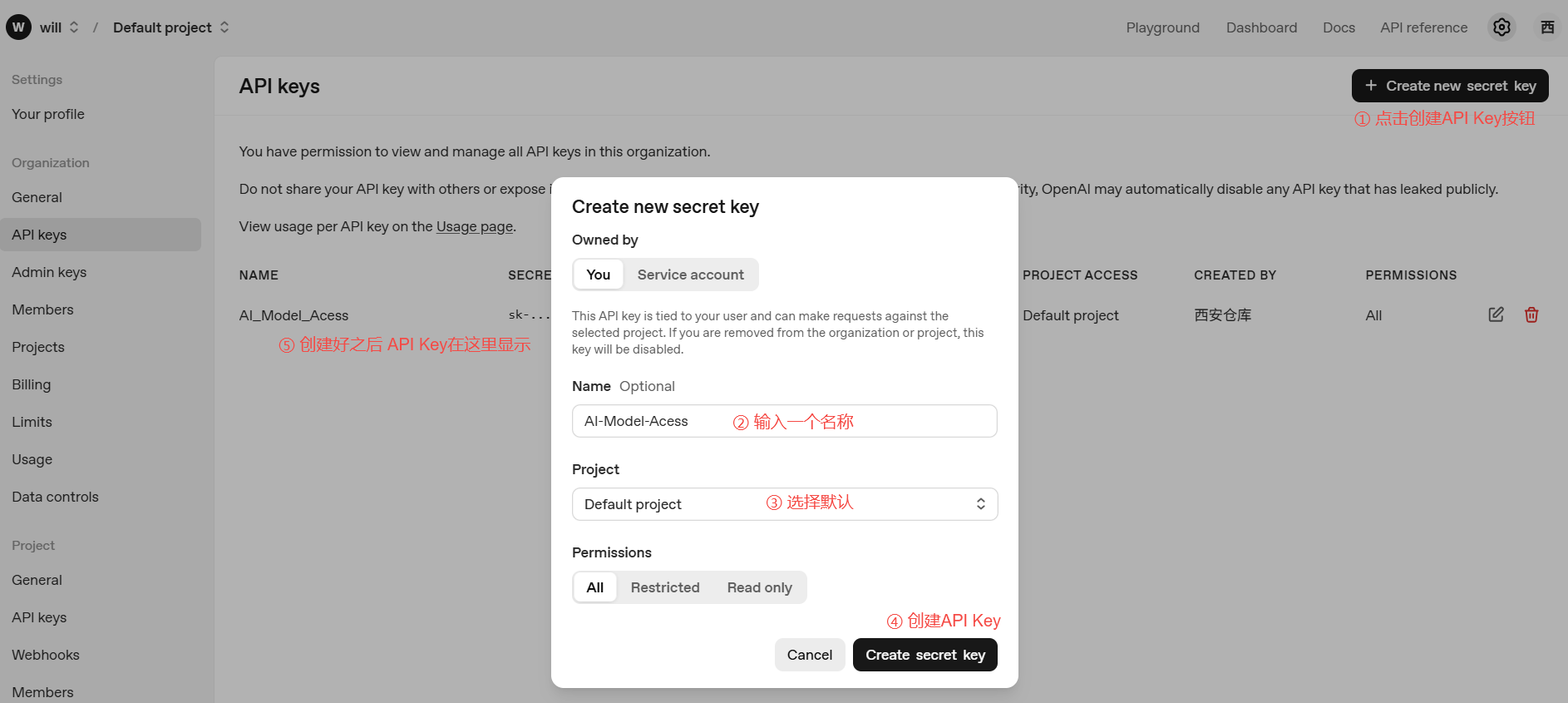
将API Key在自己本地保存好,后续接入ChatGPT时需要使用。
【Genimi API key获取】
官网:https://ai.google.dev/aistudio?hl=zh-cn

点击登录后进入登录叶面积,如果没有google账号时先要注册一个账号,直接邮箱注册即可。登录成功后点击 Get API Key按钮获取API Key
后续流程与ChatGPT类似,API Key创建好后请妥善保管,后续连接大模型时需要使用。
3、数据结构设计
虽然各个模型不同,但有一些公共的配置和描述信息,比如:
通过api调用模型时需要模型名称、温度值、最大tokens数、api key等;
在和模型聊天时,聊天信息需要管理;
每次开启和模型的新一轮对话,都是一次新的会话,将来可能需要实现会话管理。
这些数据在多个文件中都会用到,因此提前先将这些数据结构定义好,以方便后续使用。
common.h
c++
////////////////////////////// common.h ///////////////////////////////////////
#include <string>
#include <vector>
#include <ctime>
namespace ai_chat_sdk {
// 消息结构
struct Message {
std::string id; // 消息唯一标识符
std::string role; // "user" or "assistant"
std::string content; // 消息内容
std::time_t timestamp; // 消息生成时间
Message(const std::string& r, const std::string& c)
: role(r), content(c), timestamp(std::time(nullptr)) {}
};
// 会话结构
struct Session {
std::string id; // 会话内容
std::string model_name; // 模型名称
std::vector<Message> messages; // 消息列表
std::time_t created_at; // 消息创建时间
std::time_t updated_at; // 消息更新时间
Session(const std::string& model)
: model_name(model), created_at(std::time(nullptr))
, updated_at(std::time(nullptr))
{}
};
// 调用模型时配置信息
struct Config {
virtual ~Config() = default; // 启用运行时类型识别
std::string model_name; // 模型名称
double temperature = 0.7; // 采样温度
int max_tokens = 2048; // 最大tokens数
};
// API配置结构
// Ollama本地接入大模型,不需要api key,因此将api key单独拎出来
struct ApiConfig : public Config {
std::string api_key; // 接入模型时认证信息
};
// LLM模型信息
struct ModelInfo{
std::string _name; // 模型名称
std::string _desc; // 模型描述
std::string _provider; // 模型提供者
std::string _endpoint; // 模型base url
bool _isAvailable; // 模型是否被初始化
ModelInfo(const std::string& name, const std::string& desc = "", const
std::string provider = "", const std::string endpoint = "")
: _name(name)
, _desc(desc)
, _provider(provider)
, _endpoint(endpoint)
, _isAvailable(false)
{}
};
} // end ai_chat_sdk4、日志封装
C++中可以通过cout将信息打印到控制台,为什么还要封装日志库呢?
封装日志库有诸多优势:
日志级别管理
日志库通常支持多种日志级别(如TRACE、DEBUG、INFO、WARN、ERROR、FATAL等)。开发者可以根据需要设置不同的日志级别,以便在开发、测试和生产环境中灵活控制日志输出。在开发阶段,可以将日志级别设置为DEBUG,输出详细的调试信息;在生产环境中,将日志级别设置为ERROR或WARNING,只记录关键的错误和警告信息,避免日志文件过大。std::cout 没有内置的日志级别管理功能,所有输出都会被打印到控制台,无法根据上下文灵活控制输出内容。
日志格式化
日志库可以提供灵活的日志格式化功能,包括时间戳、日志级别、线程信息、文件名、行号等。如[2025-09-24 10:00:00] [INFO] [main.cpp:123] This is an info message 。这种格式化输出有助于快速定位问题和理解日志内容。std::cout 输出的内容格式单一,没有内置的格式化功能,需要手动添加时间戳、文件名等信息,代码繁琐且容易出错。
日志存储管理
日志库可以将日志信息输出到多种目标,如控制台、文件、远程服务器等。同时,日志库通常支持日志文件的轮转、压缩和归档,方便长期存储和管理。比如设置日志文件每天自动轮转,并在文件大小超过一定阈值时进行压缩归档。这有助于避免日志文件过大导致磁盘空间不足。而 std::cout 只能将信息输出到控制台,无法直接支持日志文件的存储和管理功能。
线程安全
在多线程程序中,日志库通常提供了线程安全的机制,确保日志输出不会出现冲突或数据错乱。在多线程环境下,多个线程可能同时尝试写入日志。日志库通过锁或其他同步机制确保日志输出的线程安全。std::cout 在多线程环境下可能会出现日志输出混乱的问题,需要开发者手动实现线程安全机制。
性能优势
日志库通常会进行性能优化,例如通过异步写入日志、缓冲机制等,减少日志输出对程序性能的影响。std::cout 是同步操作,每次输出都会阻塞当前线程,可能对程序性能产生较大影响。
因此,本项目采用google的spdlog日志库进行日志管理,为了使用方便,对spdlog库采用单例模式进行简单封装。
c++
//////////////////////////////// myLog.h
////////////////////////////////////////
#include <spdlog/spdlog.h>
#include <spdlog/sinks/stdout_color_sinks.h>
#include <spdlog/sinks/basic_file_sink.h>
#include <spdlog/async.h>
#include <mutex>
namespace bite {
class Logger{
public:
static void init_logger(const std::string &logger_name,
const std::string &logger_file,
spdlog::level::level_enum logger_level);
static std::shared_ptr<spdlog::logger> getLogger();
private:
Logger();
Logger(const Logger&) = delete;
Logger& operator=(const Logger&) = delete;
private:
static std::shared_ptr<spdlog::logger> _logger;
static std::mutex _mutex;
};
#define DBG(format, ...) bite::Logger::getLogger()->debug(std::string("
[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define INFO(format, ...) bite::Logger::getLogger()->info(std::string("
[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define WARN(format, ...) bite::Logger::getLogger()->warn(std::string("
[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define ERR(format, ...) bite::Logger::getLogger()->error(std::string("
[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define CRIT(format, ...) bite::Logger::getLogger()->critical(std::string("
[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
} // end bite
#define DBG(format, ...) bite::Logger::getLogger()->debug(std::string("
[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define INFO(format, ...) bite::Logger::getLogger()->info(std::string("
[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define WARN(format, ...) bite::Logger::getLogger()->warn(std::string("
[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define ERR(format, ...) bite::Logger::getLogger()->error(std::string("
[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define CRIT(format, ...) bite::Logger::getLogger()->critical(std::string("
[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
} // end bite
//////////////////////////////// myLog.cpp
////////////////////////////////////////
#include "../../include/util/my_logger.h"
namespace bite {
std::shared_ptr<spdlog::logger> Logger::_logger = nullptr;
std::mutex Logger::_mutex;
Logger::Logger()
{}
void Logger::init_logger(const std::string &logger_name, const std::string
&logger_file, spdlog::level::level_enum logger_level)
{
if(_logger == nullptr){
std::lock_guard<std::mutex> lock(_mutex);
if(_logger == nullptr){
// 设置全局自动刷新级别,当日志级别 ≥ logger_level时,spdlog会自动flush
spdlog::flush_on(logger_level);
// 启用异步日志,即将日志信息放入队列,有后台线程消费并写入
// 初始化线程池
// 参数1:队列大小
// 参数2:线程数量
spdlog::init_thread_pool(32768, 1);
if (logger_file == "stdout"){
// 创建一个待颜色的输出到控制台的日志器
_logger = spdlog::stdout_color_mt(logger_name);
}else{
// 创建一个输出到指定文件的异步日志器
_logger = spdlog::basic_logger_mt<spdlog::async_factory>
(logger_name, logger_file);
}
// 配置日志输出格式:
// %H:%M:%S 时分秒
// %n 日志器的名称
// %l: 日志级别的名字info、error,%-7l:左对齐占7个字符
// %v: 日志消息正文
_logger->set_pattern("%H:%M:%S [%n][%-7l]%v");
_logger->set_level(logger_level);
}
}
}
std::shared_ptr<spdlog::logger> Logger::getLogger()
{
return _logger;
}
} // end bite