在人工智能计算进入"系统竞赛"的今天,我们面临一个核心矛盾:GPU算力以每年翻倍的速度增长,而存储访问的速度与效率却成为制约整体系统性能的致命瓶颈。特别是在大模型推理场景中,KV Cache对显存的巨大占用与高并发、低延迟访问需求,已从技术挑战演变为商业化的核心障碍。
传统的解决方案------无论是盲目扩充昂贵的HBM显存,还是采用高延迟的软件卸载方案------都无异于在高速公路上设置收费站,造成严重的"算力拥堵"与成本失控。
在此背景下,绿算技术隆重推出"擎翼"智能存储卸载解决方案。这不仅仅是一颗芯片,更是一套旨在重构智算中心存储架构的端到端系统级方案。它直面核心痛点,以全硬件卸载、AI场景深度优化与极致性价比,为千亿参数模型的规模化部署铺平道路。
行业痛点深度解构------我们为何需要新一代存储互联?
算力繁荣下的"存储墙"危机
当前,单台GPU服务器(如搭载8颗H100)的显存容量通常在数十GB到一两百GB之间。然而,一个千亿参数模型在处理长序列(如32K tokens)时,仅KV Cache一项就可能需要消耗数百GB甚至TB级的存储空间。这直接导致:
批处理规模(Batch Size)受限,GPU强大算力无法饱和利用。
长上下文应用难以落地,模型能力被硬件束缚。
频繁的权重交换(Swapping)引发性能断崖式下跌。
现有方案的失灵
方案A:无限堆叠GPU显存→成本呈指数级上升(HBM价格极其昂贵),能效比低下,技术上亦存在物理限制。
方案B:CPU+软件NVMe-oF卸载→引入微秒级甚至毫秒级延迟,CPU成为新的瓶颈,无法满足AI推理的实时性要求。
方案C:依赖国外专用硬件→存在供应链风险,技术定制化程度低,难以针对国内AI生态进行深度优化。
绿算技术解决方案核心------为AI而生的硬件重构
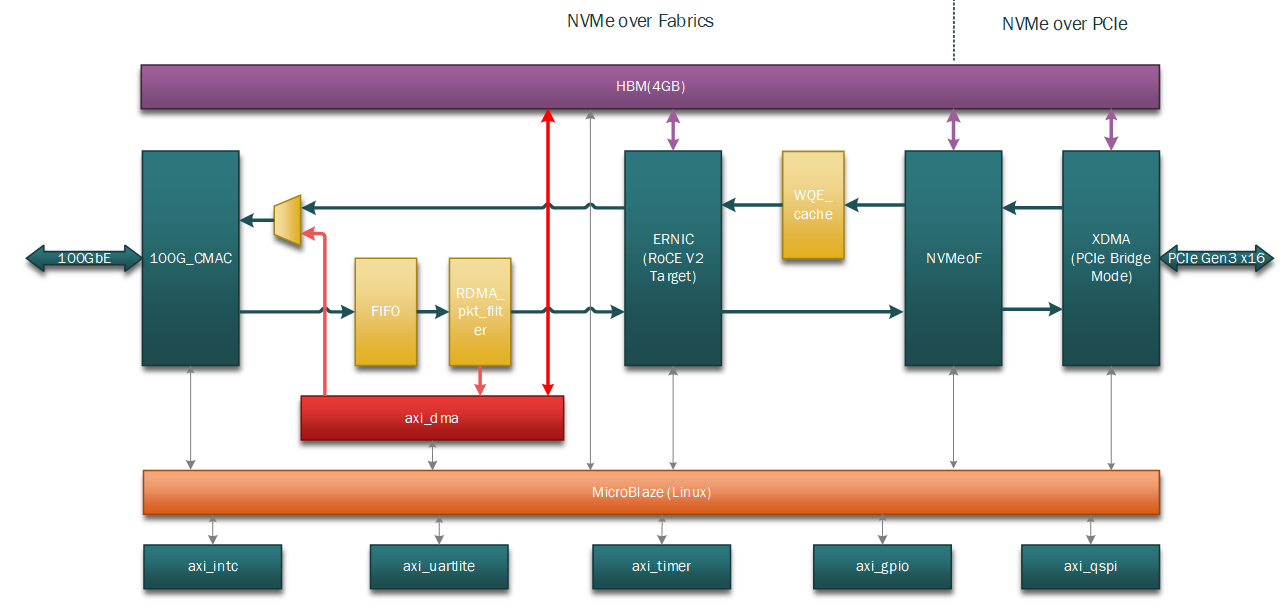
我们的方案,从根本上将NVMe-oF从"通用网络存储协议"进化为 "AI推理专用数据通道"。
硬件加速引擎:从"三层楼"到"一条高速公路"
传统软件方案数据路径漫长,需经历"网卡→CPU内存→CPU处理→系统总线→SSD"。我们的设计将其压缩为单芯片内的直通流水线:
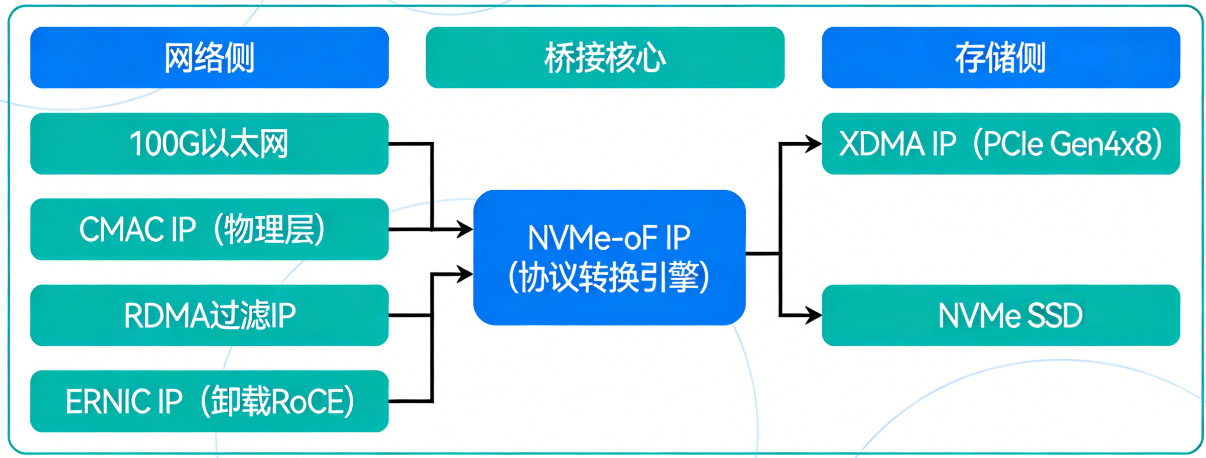
全程零CPU干预,零内存拷贝,延迟从"百微秒级"降至"十微秒级"。
针对KV Cache的七项专项优化
我们的芯片不仅是"通道",更是"智能缓存管理器"。
-
硬件级QoS隔离:256个独立RDMA队列对(QP),可为每个GPU核心或每个模型实例分配专属通道,彻底杜绝"邻居噪音"。
-
WQE Cache预解析:将工作队列元素(WQE)在芯片内缓存与解析,将指令延迟降至最低。
-
智能访问模式感知:硬件逻辑可识别Transformer的顺序访问模式,主动预取后续可能需要的KV数据至集成HBM缓存,命中率提升超40%。
-
GPU Direct Storage原生支持:作为英伟达生态的"一等公民",GPU可直接向该设备发起DMA操作,绕过主机内存。
-
高密度Namespace支持:单端口支持256个命名空间,为复杂多租户、多模型场景提供清晰的存储视图隔离。
-
混合协议支持:一套硬件同时支持高性能的RoCE v2与兼容性极佳的TCP,保障从试验到大规模部署的无缝演进。
-
极致能效设计:典型功耗9.3W,相比传统方案节能85%以上,万台集群年省电费可达数千万元。
性能巅峰,能效革新
在自研LightBoat 2300加速卡上的实测表明,本方案实现了卓越性能表现:其4KB随机读取达到489万IOPS,顺序读取带宽高达21.8 GB/s(单卡双100Gbe端口),已接近理论峰值。在实际业务场景中,该性能足以支撑数百个并发请求对海量KV数据的即时随机存取。
本方案的能效优势同样突出。在提供极致性能的同时,芯片典型功耗可控制在10瓦以下(设计目标)。相较于功耗达数百瓦的GPU,此功耗几乎可忽略不计。对于建设绿色集约化超大规模智算中心而言,该能效表现将通过乘数效应,为您带来显著的电费节约与运营成本优化。
全景应用场景与部署架构
场景一:单机极致扩展------打造"无限显存"GPU服务器
架构:8卡GPU服务器环境部署一台EBOF(配置2-4张"擎翼"卡),通过PCIe Switch连接24块NVMe SSD,构建本地第二级存储池。
价值:将可用的高速KV Cache存储池从数百GB扩展至数十TB,支持Batch Size提升3-5倍,极大提高GPU利用率和吞吐量。
场景二:机架级资源池化------构建共享式AI存储资源网
架构:将多台装载"擎翼"芯片的JBOF/EBOF设备通过100G交换机组成存储池,供整个机架或集群的GPU服务器按需挂载。
价值:实现存储资源的弹性伸缩与共享,提升存储利用率至70%以上,支持异构GPU机型灵活调度,降低总体TCO。
场景三:跨中心缓存同步------加速大模型训练与推理协同
架构:在异地训练与推理中心之间,利用"擎翼"设备的低延迟特性,实现热点模型权重和KV Cache的近实时同步。
价值:使推理集群能近乎"零等待"获取最新训练成果,加速模型迭代与业务上线周期。
量化收益与竞争壁垒
客户价值核算
假设一个拥有1000张H100 GPU的推理集群:
成本节约:采用本方案扩展KV Cache,相比同容量HBM方案,首期硬件投资节约超过60%。
性能收益:通过增大Batch Size和降低延迟,整体推理吞吐量预计提升35%-50%。
运营效率:存储与计算解耦,资源调度更灵活,设备利用率提升,运维复杂度下降。
核心竞争壁垒
-
场景化深度:非通用芯片,而是为"Transformer + KV Cache"这一决定性负载量身定制。
-
全栈自主可控:从核心IP到驱动软件完全自研,无"卡脖子"风险,支持快速定制迭代。
-
系统级验证:基于成熟的LightBoat2300 FPGA平台开发,风险低,上市快,生态兼容性好。
-
生态开放性:全面兼容标准NVMe-oF生态,与国内主流AI框架和云平台已完成初步适配。
我们已与多家头部互联网公司、AI独角兽及云服务商展开深度合作。AI的竞争,最终是基础设施效率的竞争。诚邀您携手,用更先进的存储架构,释放每一分算力的潜能,共同定义AI时代的基础设施新标准。
附录:关键性能指标摘要
协议支持:NVMe-oF 1.0, NVMe 1.3, RoCE v2/TCP
延迟:端到端<10μs
带宽:单端口21.8 GB/s(顺序读)
IOPS:489万(4K随机读)
并发:256 QP,256 Namespace
功耗:典型9.3W(芯片级)
形态:标准PCIe加速卡,兼容EBOF/JBOF