HVI: A New Color Space for Low-light Image Enhancement
HVI:一种新的微光图像增强颜色空间
CVPR 2025文章
目录
[论文总结. 1](#论文总结. 1)
[一.研究背景. 3](#一.研究背景. 3)
[1.1 目前主流方法以及弊端. 3](#1.1 目前主流方法以及弊端. 3)
[1.2 相关研究 HSV 4](#1.2 相关研究 HSV 4)
[1.3论文的创新方式. 5](#1.3论文的创新方式. 5)
[二、模型架构. 7](#二、模型架构. 7)
[2.1 HVI变换. 7](#2.1 HVI变换. 7)
[2.1.1 RGB->HSV 7](#2.1.1 RGB->HSV 7)
[2.1.2 极化操作. 9](#2.1.2 极化操作. 9)
[2.1.2 可学习强度崩溃函数. 10](#2.1.2 可学习强度崩溃函数. 10)
[2.2结构分析. 11](#2.2结构分析. 11)
[2.2.1 HVI Color Transformation (HVIT) 11](#2.2.1 HVI Color Transformation (HVIT) 11)
[2.2.2 Enhancement Network 12](#2.2.2 Enhancement Network 12)
[2.2.3 PHVIT 12](#2.2.3 PHVIT 12)
[2.2.4 CIDNet整体架构. 14](#2.2.4 CIDNet整体架构. 14)
[2.3 学习目标(损失计算). 14](#2.3 学习目标(损失计算). 14)
[三、模型结果. 16](#三、模型结果. 16)
[四、个人总结以及想法. 18](#四、个人总结以及想法. 18)
一.研究背景
1.1 目前主流方法以及弊端
当前低照度图像增强领域的主流方法(如基于深度学习的数据驱动方法)的核心任务,是学习一个从低照度图像到正常照度图像的亮度映射函数。其技术范式通常为:
- 数据:使用成对的低照度-正常照度图像进行监督学习。
- 空间 :在标准RGB色彩空间中进行端到端映射学习。
- 目标:通过网络直接拟合像素级的亮度提升关系。
但是RGB空间中,亮度空间和色彩空间高度耦合,是一种为显示与存储 而优化的设备相关色彩空间。其三个通道(R, G, B)的数值共同编码了光强 与色度 的混合信息,图像亮度L可近似表示为三个通道的加权和(如 L = 0.299R + 0.587G + 0.114B),而色度信息则蕴含在三个通道的相对比例关系中。因此,任何对像素值(如为提升亮度而进行的全局或局部操作)的改动,都会同时扰动其亮度与色度分量。当网络专注于学习亮度映射时,在sRGB空间中对像素值的调整会不可避免地改变原始的色彩平衡。这种扰动在低照度区域尤为显著,因为低信噪比放大了颜色通道的不均衡性。
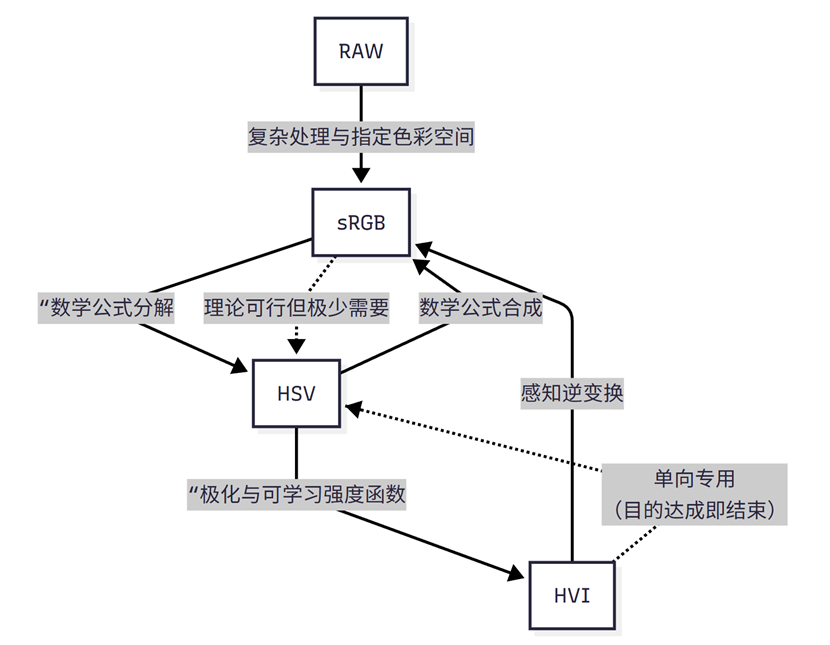
1.2 相关研究 HSV
受Kubelka-Munk理论的启发,最近的方法试图将图像从sRGB色彩空间转换为色调,饱和度和值(HSV)色彩空间,他把图像分成色相(Hue),饱和度(Saturation),明度(Value),理论上我想要提亮照片只用提高明度,保持饱和度和色相不变就行。
HSV将色相分为六种并排号0-6(红橙黄绿青蓝紫红),相当于就是把一个环状的调色盘从红色处切开,这就导致0和6都是红色,所以当遇见红色的时候有些会判断靠近0,有些判断靠近6,所以在处理红色的时候(比如红旗、红衣服),这个系统里"红色"在颜色环的头和尾是断开的,就容易在红色区域产生红色杂点或条纹(红色断层)。
从饱和度层面看,其从RGB转换HSV的时候,S的计算公式为
S = Δ / I_max
其中Δ = 最大值(R,G,B) - 最小值(R,G,B)。这代表了三个颜色通道之间的差异 ,是色度信息 的度量,I_max = 最大值(R,G,B)。这代表了该像素点的绝对亮度 。这就会导致一个问题,在低照度图像中RGB信噪比也就是整个225空间中占比可能很低,假设一个几乎全黑的像素,其真实信号为(R=3,G=2,B=1)。由于噪声,实际读数为(R=3±1, G=2±1,B=1±1)。如果噪声使得R=4,B=0,S=(4-0)/4=1饱和度直接拉满。这意味着一个微小的、随机的噪声波动,将一个黑色点瞬间"解释"为一个**完全饱和的纯色点,**这就会导致在黑色区域会出现大量彩色的噪点。
1.3论文的创新方式
为了解决这种问题,论文在HSV的基础上提出了新的色彩空间HVI,在色相和饱和度(HS)平面中进行极化,以使相似的红点坐标的距离更小,从而消除了主HSV空间中的红色不连续噪声)。对于黑平面噪声问题,引入了一个可训练的黑暗密度参数k及其对应的自适应强度坍缩函数Ck,该函数将低光区域的半径压缩为零,并具有随着强度增加逐渐扩展到1的灵活性。
对于色相H,论文极化就是把原先的一条0-6的直线变成坐标
- 横坐标 H' = cos(π × H / 3)
- 纵坐标 V' = sin(π × H / 3)
从公式中我们可以看到他把色彩放入sin和cos函数中,能让0和6的点的值相等,所以就能够避免红色断开的问题。
对于饱和度S,它本质上就是设计一个门控思想的阀门,它通过每个像素的亮度值看。亮度越低(越黑),这个阀门就关得越紧(压缩得越狠);亮度越高,阀门就开得越大(压缩得越轻,甚至不压缩),整个压缩的程度是从学习中获得。
最后进行融合,先让RGB转化成HSV,然后结合H和S进行计算Ĥ = C_k × S × H' 和 V ̂ = C_k × S × V' **,最后I=V,**然后就可以得到最后的HVI。
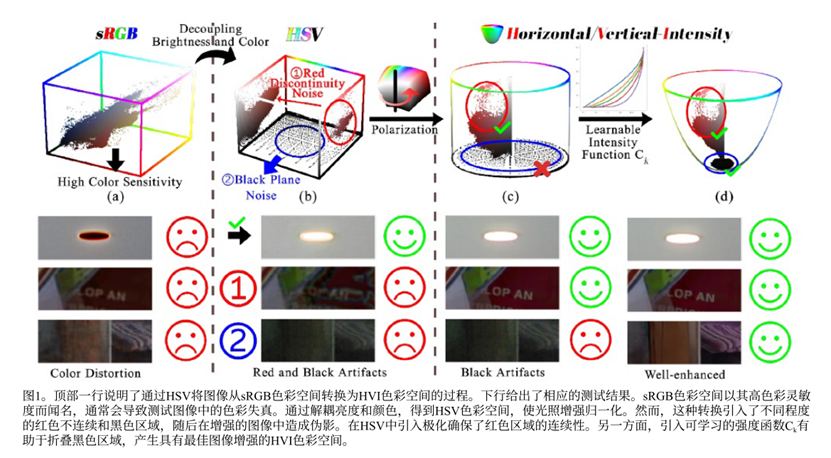
HVI的设计目标,就是构建一个色彩表示体系,使得在这个体系中进行数学运算(如增强、降噪)后得到的结果,能最大程度地满足人类的感知偏好。它不止追求工程上的PSNR而是通过计算,而是把RGB想成一个一个的点,计算最小欧式距离,通过极化实现红色不会出现大的欧式距离的情况,更符合人眼,将主观的"感知相似性"转化为可计算的空间几何约束 (欧氏距离最小化),通过创新性的数学变换(极化、可学习压缩),主动塑造HVI空间的几何结构,使其内在的度量属性(距离) 与外部的感知目标(相似性) 保持一致。
二、模型架构
2.1 HVI变换
2.1.1 RGB->HSV
在传统的LLIE任务中,之前很多是应用Retinex理论联系神经网络分离进行计算,实际上,这种方法很难适应物理定律和人体感知,它核心在于认定光照分量在空间上是缓慢变换的,并且反射分量在同一个物体是固定的,只有在边缘处才会突变。但是,人眼并不追求"均匀的物理光照"。我们天生适应并期望图像中存在自然的照明变化 ,如柔和的阴影、渐变的光晕和明暗对比。这些变化是场景深度、纹理和氛围的关键线索。于Retinex的方法在强制施加"光照平滑"先验时,往往会过度平滑 或错误估计 这些自然的照明变化。结果,增强后的图像虽然亮度"均匀"了,却失去了立体感和真实感,看起来"扁平"且不自然。人眼要的不是均匀的光,而是符合认知的光影关系。 同时人眼的颜色恒常性是语境依赖和不完全的。**在复杂光照(如混合光源、强烈色偏)下,人眼也会在一定程度上"感知"到光源色。**Retinex模型机械地试图完全消除所有光照色偏,有时会产生不自然的颜色校正,例如在温暖的烛光下强行将肤色恢复成日光下的白色,反而失去了氛围。
在这篇论文中,它使用Max-RGB来估算V,就是取一个点RGB亮度最高的值作为整个点的亮度,不使用神经网络,在能使用简单、稳定、可解释的经典方法的地方,绝不引入不必要的复杂性。
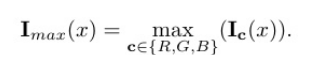
最近的研究表明,低照度图像噪点会扰动RGB,它主要影响的是H和S,因为H是由RGB的比例关系影响,S受最大值和最小值的影响,他们一旦出现偏差,就会导致颜色出现差错,相比于Max-RGB得到的受的影响大,影响的效果也明显。
论文用计算机视觉两个经典的理论光度不变性和二色反射模型,作为理论依据去分离光照和物品本身的颜色,它最后会分成HS平面和V平面,一个关注颜色和饱和度,一个只关心亮度,相同颜色物体哪怕在不同光照下,其在HS面上坐标应该是相同的
饱和度图(S)
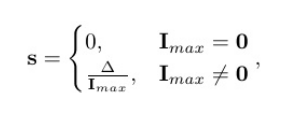
色相图(H)
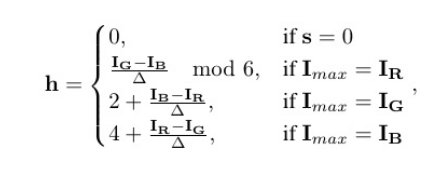
将sRGB图像转换为HSV空间有效地将亮度与颜色分离,从而实现更准确的颜色去噪和更自然的照度恢复。然而,这种转换也放大了红色和黑暗区域的噪声(原因上文有讲)
2.1.2 极化操作
极化操作就是把之前HSV中分开的红色部分又通过转化成一个正交化的H-V平面,公式在1部分中有写,他们与横轴的夹角,正是原来的色相角H,所以极化是可逆的可以通过 arctan2(v', h') 恢复出H。和上文中所提到的一样,极化操作可以让色彩连接在一起,不会出现断裂的情况。
S表示到原点的距离,他从HSV里面纯度变成HVI里面直观的几何距离,他所带来的效果
- 连续性:因为颜色点被映射到了一个平坦、连续的二维平面上,"相似颜色距离小"的准则得以成立。算法在这个平面上进行任何操作,都会自然地保持颜色的连续性(尤其是红色)。
- 可控制性 :饱和度S现在是一个径向距离 。这使得我们可以通过一个外部的、智能的函数 来全局或局部地调制它。这就是可学习强度函数C ₖ 的作用。
- 噪声抑制 :Cₖ 函数会在暗部自动减小,其效果等同于压缩整个色度平面的半径(即减小 S 的实际有效值)。这样,暗部那些因噪声而产生的、具有虚假高饱和度值的离散颜色点,就会被强力拉回原点附近,其距离(即视觉显著性)大大降低,从而抑制了"黑色平面噪声"。
2.1.2 可学习强度崩溃函数
坍缩函数的意义就是抑制低照度区域,使得降低噪点的出现,同时保留高光强区域
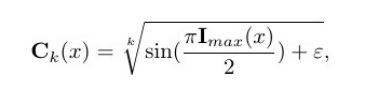
其中k∈Q+是一个可训练的参数,用于控制深色点密度,并使用一个小的ε= 1×10---8来避免梯度爆炸。
- 亮度控制 :观察函数可知,当输入I_max 很小(接近0,极暗)时,sin()值接近0,因此Ck 的输出也非常小。
- 半径压缩 :在极暗的像素上,一个极小的Ck 意味着,无论该像素原本的饱和度S算出来是多少(很可能因噪声而被放大),在最终计算 Ĥ = C_k · S · h' 和 V̂ = C_k · S · v' 时,都会被这个极小的 Ck 强力压缩。
- 几何结果 :这些暗部像素的颜色向量 (Ĥ, V̂) 的长度(C_k × S)被压缩到近乎为零,使得它们在色度平面上全部紧密地聚集在原点 (0, 0)附近。
最后通过Ĥ = C_k × S × H' 和 V ̂ = C_k × S × V' **,最后I=V,**然后就可以得到最后的HVI。
2.2结构分析
2.2.1 HVI Color Transformation (HVIT)
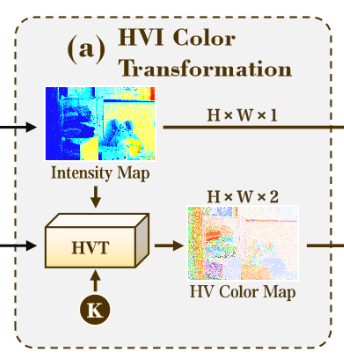
在这个HVIT模块中,主要还是进行的就是一个RGB转换HVI的过程,首先通过Max-RGB计算出强度分布图,也就是Intensity Map,然后K计算CK,再生成HV,生成HV Color Map
2.2.2 Enhancement Network
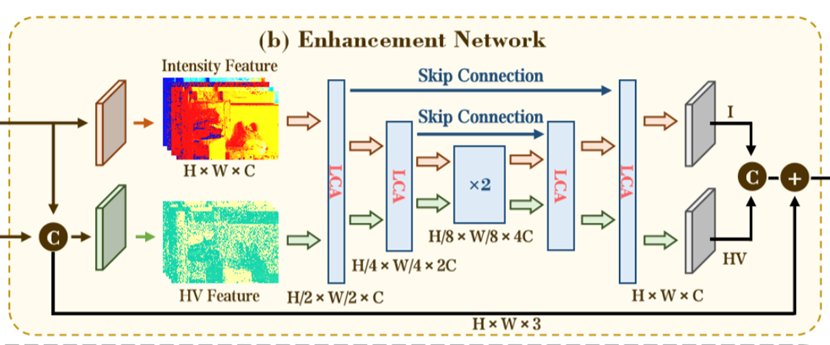
这个双分支增强网络,其整个流程架构就是把I和HV图都送入一个双路径U-Net一个处理光照一个处理颜色,然后在每一层的U-Net引入一个LCA模块,这个LCA模块是一个交叉注意力模块,他让色彩跟光照有联系,光照和色彩有联系
2.2.3 PHVIT
就是把HVI转为HSV,因为在HVI的处理过程中,整个图片被量化成了坐标,所以要转化为人眼可看的RGB,在这个过程中,引入可学习的缩放参数α_S和α_I,这给了网络最后的调整机会:
第一步:恢复归一化的极化坐标
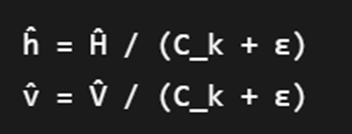
首先分理处CK,因为CK是从原始输入图像中得到的,这是在"撤销"HVI变换中对颜色向量的缩放,恢复出只与颜色种类和纯度相关的坐标(ĥ, v̂)
第二步:计算色相H(Hue)
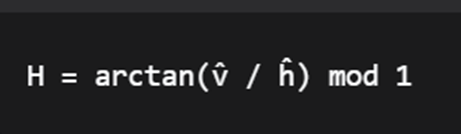
(ĥ, v̂)是二维平面上的坐标,arctan(v̂/ĥ)计算的是该点相对于原点的**角度,**mod 1:确保角度值在[0,1)范围内(对应0°-360°)
第三步:计算饱和度S(Saturation)

前边我们知道hv点距离原点的距离就是S,现在S只用乘一个科学系参数α**_S,**他是可学习的饱和度缩放因子。网络可以通过学习调整这个参数,微调最终的色彩鲜艳程度
第四步:计算亮度V(Value)
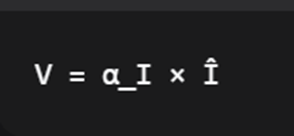
通过学习的亮度缩放因子调整整个图片的亮度
第五步:HSV → sRGB
这一步是确定的,有专门的转换公式
2.2.4 CIDNet整体架构
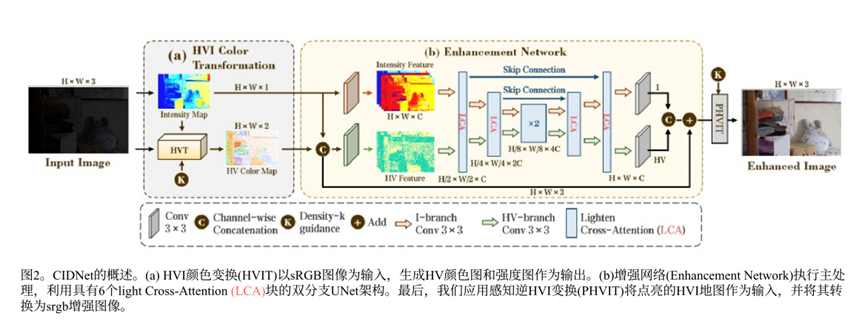
整体流程RGB->HSV->HVI->HSV->RGB
2.3 学习目标(损失计算)
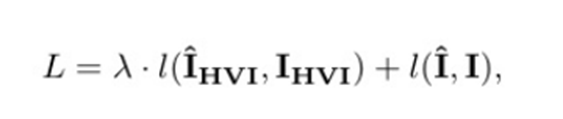
(1)参数结构
- L :总损失(要最小化的目标)
- λ :权重超参数(通常在0.1-1之间),用于平衡两个损失项的重要性
- l(·, ·) :基础损失函数(通常是L1或L2距离)
- Ī _HVI :网络输出的增强图像在HVI空间的表示
- I_HVI :真实正常光图像在HVI空间的表示(通过相同的HVI变换得到)
- Ī :网络输出的增强图像在sRGB空间的表示
- I :真实正常光图像在sRGB空间的表示
(2)优化目标
这是一个双空间混合损失函数,它不止计算HVI色彩空间的损失,还计算RGB中的损失,因为在HIV中我们要得到的是更贴近人眼观测的数据,RGB得到的是传统的根据单个像素判别的数据,单纯RGB没法满足人眼对某些颜色敏感的变换,只要像素值整体接近,即使颜色有偏差,损失也可能很小,所以两者结合就比较好
|----------|------------|----------------|-----------------|
| 损失类型 | 关注点 | 数学特性 | 解决的问题 |
| HVI空间损失 | 颜色分布、感知相似性 | 在优化过的颜色空间中计算距离 | 红色断层、黑色噪声、颜色和谐 |
| sRGB空间损失 | 像素级精度、结构细节 | 原始像素空间的绝对/相对误差 | 边缘清晰度、纹理细节、整体亮度 |
三、模型结果
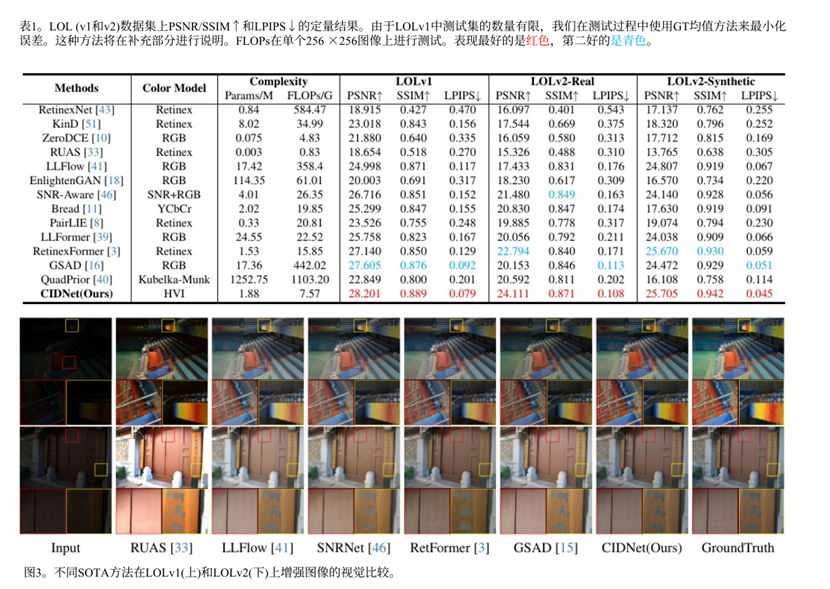
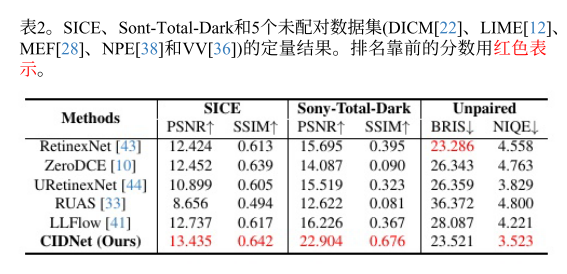

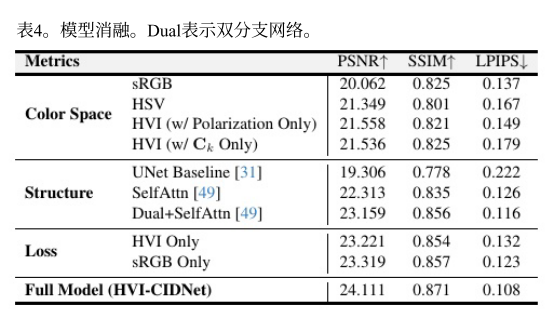
四、个人总结以及想法
这篇论文主要内容就是改进了HSV,改成HVI,最近度的文章都已经不再用RGB处理图像,上一篇是用RAW,这一片是用HVI,对于未来的发展方向可能已经不在重视在RGB的处理上,在上篇文章中有提到RAW在转化RGB的时候就已经有了色彩的丢失,有没有可能我直接在RAW照片上转化HVI会获得更好的效果。
低照度图像处理现在大家的解决方案都是将亮度色彩分离,而前几年比较火的直接送进transformer的操作好像没有了,大家不再是把transformer这类强大的模型作修改来满足视觉任务,而是做轻量化的注意力头在U-Net网络里面,这篇文章整体的复杂度不高,没有用过大过长的训练去解决问题,如果在整个基础上,我能进一步把他的注意力机制模块进行改进,比如restormer通道注意力,能不能做的更轻量化,这样就可以在更小的设备上进行部署。
这篇文章在HVI部分的核心有一部分是为了更符合人眼观察,我觉得这是个很好的地方,因为现在好多没模型好像只是在单纯的数据上进行比较,其实跟人眼观察并不相同。