最近发现精排每天定时10:25会有一个p99的耗时毛刺
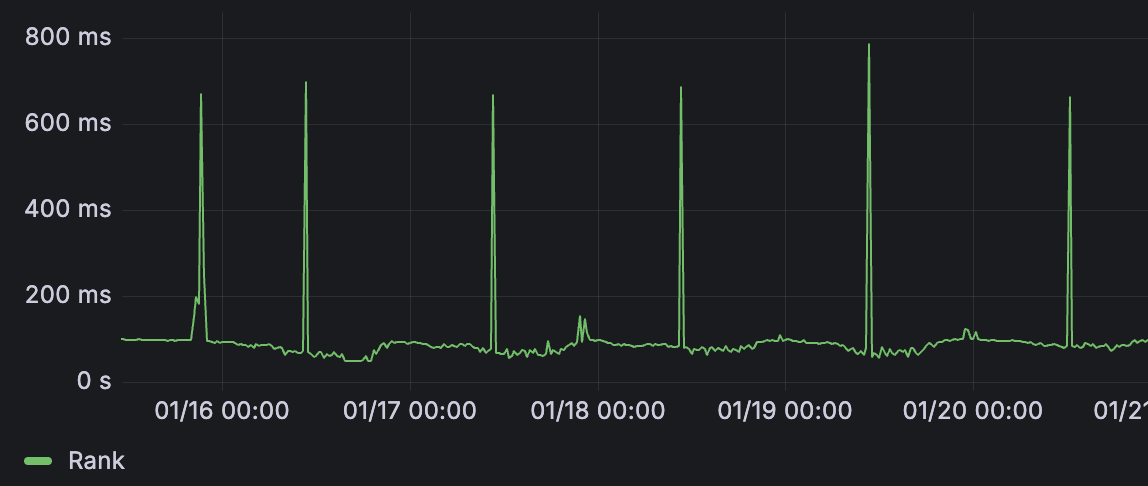
这个毛刺的产生是因为算法同学会每天10:25更新模型造成的。
但是更新模型为什么会造成耗时毛刺?
tf serving按理说是热更的,也就是说在模型加载完成之前是不提供服务的。
那如果有耗时毛刺,说明是有请求打到了tf serving,并且慢了。
那,难道不是热更?热更失败了?热更没更完就提供服务了?
好在tf serving是提供metric上报的。这让我们有了抓手!
tf serving启动时候支持一个monitor的file路径,而且只能是文件路径:
tensorflow_model_server
--port=8500
--rest_api_port=8502
--monitoring_config_file=/data/monitor.conf
--model_config_file_poll_wait_seconds=60
--model_config_file=xxx
--enable_model_warmup=true/data/monitor.conf里的内容很简单,如下:
prometheus_config: {
enable: true,
path: "/metrics"
}这样启动的tf服务就会支出在8502端口提供上报功能metrics接口。
在promethus中配置一下。我这边的背景是阿里云容器,所以我配置如下就可以采集到容器中的metrcis。可以参考:
- job_name: 'rec_tf_serving_monitor'
metrics_path: /metrics
kubernetes_sd_configs:
- role: pod
kubeconfig_file: "/root/.kube/config"
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: recommend
action: keep
- source_labels: [__meta_kubernetes_pod_label_app]
regex: a-server-.+
action: keep
- source_labels: [__meta_kubernetes_pod_label_app]
regex: a-server-feed
target_label: env
replacement: prod
- source_labels: [__meta_kubernetes_pod_label_app]
regex: a-server-feed-test
target_label: env
replacement: test有了上报后,能看到很多不懂的metric。其中一个看起来很相关,因为耗时也是定时毛刺的:
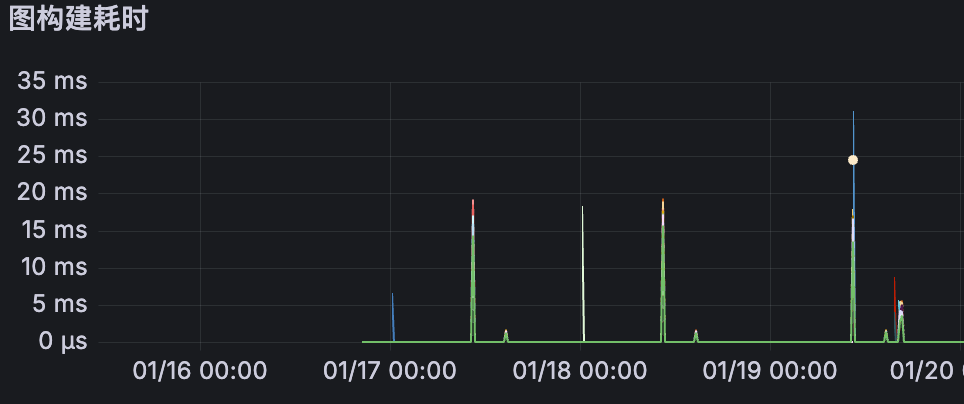
图构建耗时
:tensorflow:core:graph_build_time_usecs
图优化耗时
:tensorflow:core:graph_optimization_usecs
图构建调用次数
:tensorflow:core:graph_build_calls
这仨看起来都是相关的,其他的metric不懂,也看不懂,就不提了。
感兴趣可以自己搜相关概念。后续有空会继续深入学习了解。了解各个metric的含义。
最后问ai,知道了图构建的过程中涉及一个warmup(热身)。
这个warmup相当于是工程里的预热,算法同学会按x batch去热身,让模型提前缓存起来shape,这样真实batch的请求打过来就可以直接命中缓存提高命中率,如果predict的batch比warmup的batch大的话,那warmup没学到这么大batch的结构,就会当下现热身。现热身有两个问题:
1/ 消耗资源,跟线上请求造成资源竞争;
2/ 同步等待,会导致慢请求,造成耗时毛刺;
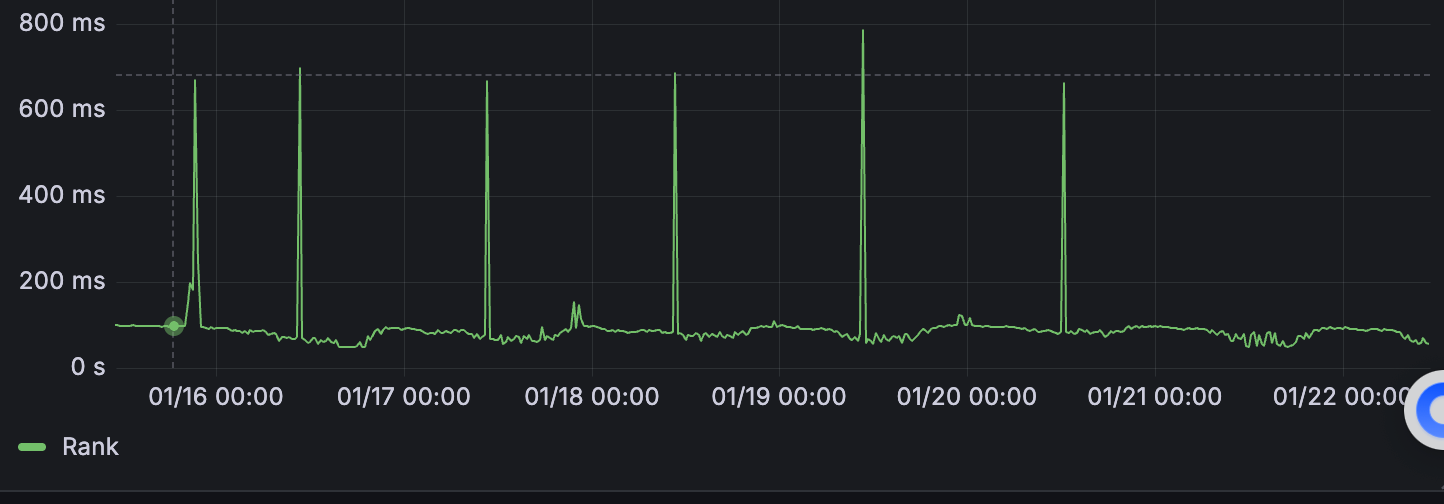
我们的算法同学训练的batch是1024,warmup的batch是1,我们工程线上predict的batch是200和300和500,最多是500。于是让算法同学warmup batch是512的,这样可以包含predict的batch size。
果然奏效了!
参考:
https://farer.org/2020/12/28/tensorflow-serving/
https://gist.github.com/candlewill/7dad6d0a3ee8471184021485c0ef0e0a