目录:
-
- 一、客服工单自动化处理系统简介
- 二、流程设计
- 三、分步实现与代码解析
-
- [1. 定义子工作流(Sub-Workflows)](#1. 定义子工作流(Sub-Workflows))
- [2. 组装主工作流](#2. 组装主工作流)
- [3. 执行与监控](#3. 执行与监控)
- 四、完整代码和优化
一、客服工单自动化处理系统简介
场景需求:
- 输入:客户提交的工单文本(如"订单未收到,物流号123456")。
- 输出:
- 自动分类工单类型(物流/售后/技术问题)。
- 检索关联的订单数据、知识库文档。
- 生成解决方案草稿(含操作步骤和引用来源)。
- 要求:端到端延迟 <3秒,支持历史工单学习。
二、流程设计
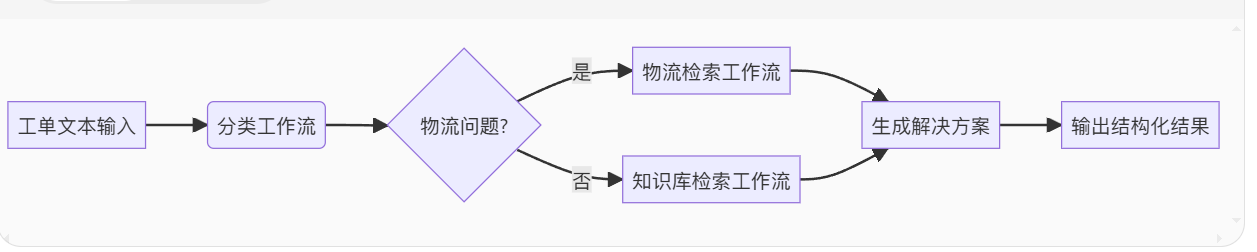
三、分步实现与代码解析
1. 定义子工作流(Sub-Workflows)
(1) 工单分类工作流
python
from llama_index.core.workflows import Workflow
from llama_index.core import PromptTemplate
# 定义分类Prompt
classify_prompt = PromptTemplate("""\
判断以下工单类型,仅输出物流/售后/技术:
工单内容: {ticket_text}
""")
# 创建分类工作流
classify_workflow = Workflow(
steps=[
("llm_chain", classify_prompt), # 调用LLM分类
("output_parser", lambda x: x.lower().strip()) # 标准化输出
],
name="工单分类"
)(2) 物流检索工作流
python
from llama_index.core import VectorStoreIndex
# 假设已构建物流知识库索引
logistics_index = VectorStoreIndex.from_documents(logistics_docs)
logistics_workflow = Workflow(
steps=[
("retriever", logistics_index.as_retriever(similarity_top_k=2)),
("reranker", lambda nodes: sorted(nodes, key=lambda x: x.score, reverse=True)[:1]) # 重排序
],
name="物流检索"
)2. 组装主工作流
python
from llama_index.core.workflows import SequentialWorkflow
main_workflow = SequentialWorkflow(
steps=[
classify_workflow,
{
"物流": logistics_workflow,
"default": knowledge_base_workflow # 其他类型走知识库
},
{
"template": PromptTemplate("""\
根据以下信息生成解决方案:
工单类型: {workflow_1_output}
检索结果: {workflow_2_output}
"""),
"llm": "gpt-4"
}
],
verbose=True # 打印执行日志
)3. 执行与监控
python
# 输入工单
ticket = "订单号123456显示已签收,但未收到货"
# 执行工作流
result = main_workflow.run(ticket_text=ticket)
# 输出结构化结果
print(f"""
工单类型: {result['workflow_1_output']}
解决方案: {result['workflow_3_output']}
引用文档: {result['workflow_2_output'][0].metadata['source']}
""")工作流流程图:
python
[工单分类] 输入: "订单号123456..." → 输出: "物流"
[物流检索] 检索到2个节点 → 筛选1个
[生成] 使用gpt-4生成156 tokens四、完整代码和优化
结合 LlamaIndex 工作流与性能优化技巧(并行分类/检索、异步生成、缓存复用)。
python
import asyncio
from llama_index.core import (
VectorStoreIndex, SimpleDirectoryReader, PromptTemplate,
StorageContext, Document
)
from llama_index.core.workflows import Workflow, SequentialWorkflow, ParallelWorkflow
from llama_index.core.cache import SimpleCache
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# #######################
# 0. 初始化全局配置(API密钥、缓存等)
# #######################
llm = OpenAI(model="gpt-3.5-turbo", temperature=0) # 分类和生成用
embed_model = OpenAIEmbedding() # 检索用
cache = SimpleCache() # 缓存工单处理结果
# #######################
# 1. 数据准备:知识库索引构建(启用缓存)
# #######################
def load_knowledge_base():
"""加载客服知识库文档并构建索引(缓存优化)"""
storage_context = StorageContext.from_defaults(cache=cache)
# 假设知识库包含物流/售后/技术文档
documents = [
Document(text="物流问题处理流程:1. 核对订单号 2. 联系物流公司", metadata={"type": "物流"}),
Document(text="售后退货步骤:提交申请→寄回商品→退款", metadata={"type": "售后"}),
Document(text="API故障排查:检查token有效期和接口权限", metadata={"type": "技术"})
]
# 并行构建两种索引
with ParallelWorkflow() as parallel:
vector_index = parallel.add_step(
VectorStoreIndex.from_documents,
args=(documents,),
kwargs={"embed_model": embed_model, "storage_context": storage_context},
description="向量索引"
)
keyword_index = parallel.add_step(
KeywordTableIndex.from_documents,
args=(documents,),
description="关键词索引"
)
return vector_index, keyword_index
# #######################
# 2. 定义子工作流(模块化复用)
# #######################
def create_classify_workflow():
"""工单分类工作流(复用LLM)"""
return Workflow(
steps=[
("llm", PromptTemplate("判断工单类型(物流/售后/技术): {ticket_text}")),
("output_parser", lambda x: x.split(":")[-1].strip())
],
output_key="ticket_type",
name="工单分类"
)
def create_retrieve_workflow(index, workflow_type):
"""检索工作流(动态路由到不同知识库)"""
return Workflow(
steps=[
("retriever", index.as_retriever(similarity_top_k=2)),
("reranker", lambda nodes: [n for n in nodes if n.metadata["type"] == workflow_type])
],
output_key=f"{workflow_type}_docs",
name=f"{workflow_type}检索"
)
# #######################
# 3. 主工作流(异步+缓存+并行)
# #######################
async def process_ticket(ticket_text, vector_index, keyword_index):
"""处理单个工单的完整工作流"""
# 定义子工作流
classify_wf = create_classify_workflow()
logistics_wf = create_retrieve_workflow(vector_index, "物流")
tech_wf = create_retrieve_workflow(keyword_index, "技术")
# 主工作流(条件路由+并行检索)
main_workflow = SequentialWorkflow(
steps=[
# 第一步:分类
classify_wf,
# 第二步:根据类型并行检索
{
"物流": logistics_wf,
"技术": tech_wf,
"default": create_retrieve_workflow(vector_index, "售后")
},
# 第三步:异步生成解决方案
{
"template": PromptTemplate("""
根据工单类型「{ticket_type}」和以下信息生成解决方案:
{{{ticket_type}_docs}} # 动态注入变量名,如 {物流_docs}
要求:列出步骤并标注来源
"""),
"llm": llm,
"mode": "async" # 启用异步生成
}
],
verbose=True # 打印执行日志
)
# 执行工作流(优先读缓存)
cache_key = f"ticket_{hash(ticket_text)}"
if cache_key in cache:
print("命中缓存!")
return cache.get(cache_key)
result = await main_workflow.arun(ticket_text=ticket_text)
# 缓存结果(有效期60秒)
cache.put(cache_key, result, expire=60)
return result
# #######################
# 4. 批量处理工单(性能测试)
# #######################
async def batch_process_tickets(tickets):
"""并发处理多个工单"""
# 初始化知识库
vector_index, keyword_index = load_knowledge_base()
# 启动异步任务
tasks = [process_ticket(t, vector_index, keyword_index) for t in tickets]
return await asyncio.gather(*tasks)
# #######################
# 示例运行
# #######################
if __name__ == "__main__":
# 测试工单
test_tickets = [
"我的订单123456物流显示签收但未收到",
"API接口返回500错误",
"想退货但找不到入口"
]
# 异步执行
results = asyncio.run(batch_process_tickets(test_tickets))
# 打印结果
for ticket, solution in zip(test_tickets, results):
print(f"工单: {ticket}")
print(f"解决方案: {solution}\n")流程图:

关键总结:
