LLMs之SoT:《Reasoning Models Generate Societies of Thought》翻译与解读
导读 :该论文提出并证实了一个新的推理解释框架:大型语言模型的推理能力提升源于其内部隐式形成的"多主体思想对话结构"(society of thought),这种群体式互动行为比简单延长推理链更能解释其复杂认知表现,并为未来更高效推理策略的设计提供了理论与实践依据。
>> 背景痛点
● 推理机制理解不足:现有的大型语言模型(LLMs)在多领域表现强大,但对其内部推理能力形成机制缺乏清晰解释;简单延长推理链并不能完全解释推理提升的原因。
● 定量分析结构缺乏:缺乏对推理模型内部行为特征(如对话特性、观点多样性)与实力提升之间因果关系的系统定量分析。
● 推理与社交认知理论联系不足:人类推理被认为与社会对话结构密切相关,而现有模型在形成类社会互动思路的角色方面理论和实证研究稀缺。
>> 具体的解决方案
● 社会思想模拟构建理论 --- 提出 "society of thought" 概念:推理模型内部生成的长链推理并非简单展开,而是像多视角、多主体之间的对话模拟,体现隐含的不同视角与知识背景。
● 引入量化指标与机制分析 --- 利用 LLM-as-judge 和行为标记方法,对模型推理轨迹中的"对话行为"(如提问、观点转换、冲突与融合)和"社会情绪角色"进行量化描述。
● 控制实验验证结构性推理行为 --- 设计基于强化学习的实验,将对话结构作为特定特征驱动因素,以比较不同推理策略在推理准确性提升中的作用。
>> 核心思路步骤
● 提出假设:强化学习推理模型通过隐式模拟多主体交互(类似"群体智慧")来改善推理表现,而非单纯延长推理链。
● 行为特征标注:定义推理链中的四类对话行为(问答、观点转换、冲突、融合)以及基于社会情绪角色的结构性互动标记。
● 模型比较分析:将强化学习推理模型(如 DeepSeek-R1、QwQ-32B)与传统指令调优模型在多个推理任务(如数学、逻辑推理等)上的行为特征频率进行对比,观察其对准确率的关联模式。
● 实验证据验证:通过强化学习实验观测带有对话结构引导的推理是否能更快地提升准确率,并验证其行为特征是否更像群体互动式逻辑探索。
● 行为与难度关联检验:分析在高难度任务中模型是否更频繁表现出对话结构特征,进一步支持"社会化推理思想"对复杂任务的益处。
>> 优势
● 理论解释更深入:不仅关注推理链长度,还揭示了模型内部如何生成类社交对话行为提升推理质量的原因,补充了对复杂模型内部工作机制的理解。
● 行为量化方法创新:使用 LLM-as-judge 标签推理行为及社会情绪角色,提供了新的分析框架,可应用于其它类型策略分析。
● 任务关联性强:在真实复杂推理任务中展示该理论解释的有效性,说明其不仅有理论意义,还有实践对提升模型推理效果的启示。
● 启发跨学科观念:将群体智慧与认知科学理论引入模型解释框架,为未来推理模型设计与训练策略研究提供新思路。
>> 论文结论与经验观点(经验与建议)
● 结论:推理提升不是单一延长链条 --- 推理模型表现提升更应归因于生成出不同观点间的"内部对话"模拟结构,而不仅是简单更长的链式思考。
● 观点:互动式结构有益 --- 包括 "冲突观点"、"观点转换"等互动行为在更高难度任务中更频繁出现,表明这些社交式思路对增强准确性尤为关键。
● 建议:利用对话特征促进推理训练 --- 在设计训练和奖励机制时,可引入对话提示或对多视角表征的评价指标,以鼓励模型发展更具"社会性"的推理结构。
● 建议:行为分析工具重要性 --- 提倡使用自动评估的行为质量分析手段(如 LLM-as-judge)监测训练过程中的推理行为特征,从而更好地调控推理策略。
目录
[《Reasoning Models Generate Societies of Thought》翻译与解读](#《Reasoning Models Generate Societies of Thought》翻译与解读)
《Reasoning Models Generate Societies of Thought》翻译与解读
|------------|--------------------------------------------------------------------------------------------------------------|
| 地址 | 论文地址:https://arxiv.org/abs/2601.10825 |
| 时间 | 2026年01月15日 |
| 作者 | Google(谷歌) University of Chicago(芝加哥大学) Santa Fe Institute(圣塔菲研究所) |
Abstract
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Large language models have achieved remarkable capabilities across domains, yet mechanisms underlying sophisticated reasoning remain elusive1, 2. Recent reasoning-reinforced models, including OpenAI's o-series, DeepSeek-R1, and QwQ-32B, outperform comparable instruction-tuned models on complex cognitive tasks3, 4, attributed to extended test-time computation through longer chains of thought5. Here we show that enhanced reasoning emerges not from extended computation alone, but from the implicit simulation of complex, multi-agent-like interactions---a society of thought---which enables the deliberate diversification and debate among internal cognitive perspectives characterized by distinct personality traits and domain expertise. Through quantitative analysis using classified outputs and mechanistic interpretability methods applied to reasoning traces6, 7, we find that reasoning models like DeepSeek-R1 and QwQ-32B exhibit much greater perspective diversity than baseline and merely instruction-tuned models, activating broader conflict between heterogeneous personality- and expertise-related features during reasoning. This multi-agent structure manifests in conversational behaviours including question-answering sequences, perspective shifts, and reconciliation of conflicting views, as well as in socio-emotional roles that characterize sharp back-and-forth conversation, which together account for the accuracy advantage in reasoning tasks through both direct and indirect facilitation of cognitive strategies8, 9. Controlled reinforcement learning experiments further reveal that base models spontaneously increase conversational behaviours when solely rewarded for reasoning accuracy, and fine-tuning models with conversational scaffolding substantially accelerates reasoning improvement compared to base models and models fine-tuned with monologue-like reasoning. These findings indicate that the social organization of thought enables effective exploration of solution spaces. We suggest that reasoning models establish a computational parallel to collective intelligence in human groups10, 11, 12, where diversity enables superior problem-solving when systematically structured and suggest new opportunities for agent organization to harness the wisdom of crowds. | 大型语言模型在各个领域都展现出了卓越的能力,但其复杂推理背后的机制仍不为人知。近期的推理强化模型,包括 OpenAI 的 o 系列、DeepSeek-R1 和 QwQ-32B ,在复杂认知任务上的表现优于同类指令调优模型,这得益于推理过程中更长的思维链所带来的更长时间的计算。在此,我们表明,增强的推理能力并非仅源于更长时间的计算,而是源于对复杂、多主体类似交互的隐性模拟------一种思想社会,它使得内部认知视角能够有意识地多样化和辩论,这些视角具有不同的个性特征和领域专长。通过使用分类输出和应用于推理轨迹的机制可解释性方法进行定量分析,我们发现像 DeepSeek-R1 和 QwQ-32B 这样的推理模型比基准模型和仅指令调优的模型展现出更大的视角多样性,在推理过程中激活了更多与不同个性特征和领域专长相关的特征之间的冲突。这种多智能体结构体现在对话行为中,包括问答序列、视角转换以及对冲突观点的调和,还体现在社会情感角色中,这些角色塑造了激烈的来回对话,它们共同通过直接和间接促进认知策略,为推理任务的准确性优势做出了贡献。受控的强化学习实验进一步表明,当仅以推理准确性作为奖励时,基础模型会自发增加对话行为,而采用对话支架进行微调的模型与基础模型以及采用类似独白式推理进行微调的模型相比,推理能力的提升速度大幅加快。这些发现表明,思维的社会组织能够有效地探索解决方案空间。我们提出,推理模型在计算上与人类群体中的集体智慧建立了平行关系,在这种关系中,当多样性得到系统性组织时,能够实现更出色的问题解决,并为利用群体智慧的智能体组织提供了新的机会。 |
1、Introduction
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Artificial intelligence (AI) systems have undergone a remarkable transformation in recent years, with large language models (LLMs) demonstrating increasingly sophisticated abilities across domains, from mathematics and code to scientific and creative writing to critical decision support1, 2. Nevertheless, a persistent challenge has been the development of robust reasoning capabilities---the ability to methodically analyze problems, consider alternatives, detect errors, and arrive at reliable conclusions. Recent reasoning models, such as DeepSeek-R1, QwQ, and OpenAI's o-series models (o1, o3, o4), are trained by reinforcement learning to "think" before they respond, generating lengthy "chains of thought". This led to substantial improvement in reasoning accuracy compared to existing instruction-tuned language models (e.g., DeepSeek-V3, Qwen-2.5, GPT-4.1)3, 4. Yet, the character of "thinking" within reasoning models that drives success remains underexplored. We propose that reasoning models learn to emulate social, multi-agent-like dialogue between multiple perspectives---what we term a "society of thought"---to improve their reasoning, given the centrality of social interaction to the development of reason in both cognitive and social scientific accounts. Mercier and Sperber's "Enigma of Reason" argument posits that human reasoning evolved primarily as a social process, with knowledge emerging through adversarial reasoning and engagement across differing viewpoints10. Empirical work supports the idea that groups outperform individuals on a wide range of reasoning tasks by pooling information, calibrating confidence, and exhibiting collective intelligence through balanced turn-taking among diverse perspectives13, 14, 12, 15. Cognitive diversity, stemming from variation in expertise and personality traits, enhances problem solving, particularly when accompanied by authentic dissent16, 17, 18, 19, 11, 20, 21, 22. Together, these findings suggest that robust reasoning emerges through interaction and the integration of diverse perspectives, and that key reasoning strategies, including verification and backtracking, may be realized through the conversation of simulated personas. | 近年来,人工智能(AI)系统经历了显著的变革,大型语言模型(LLM)在数学、编程、科学和创意写作以及关键决策支持等领域展现出了愈发复杂的技能1, 2。然而,一个持续存在的挑战是开发出强大的推理能力------即系统地分析问题、考虑替代方案、发现错误并得出可靠结论的能力。最近的推理模型,如 DeepSeek-R1、QwQ 以及 OpenAI 的 o 系列模型(o1、o3、o4),通过强化学习训练来"思考"后再作出回应,生成了冗长的"思维链"。这使得其推理准确性相较于现有的指令调优语言模型(如 DeepSeek-V3、Qwen-2.5、GPT-4.1)有了显著提升3, 4。然而,推理模型中推动成功的"思考"特性仍待深入探究。鉴于认知科学和社会科学的诸多论述中,社会互动在推理能力的发展中占据核心地位,我们提出推理模型应学习模拟多视角之间的社会性、多智能体式的对话------我们称之为"思想社会"------以提升其推理能力。梅西耶和斯珀伯在《推理之谜》中的论点认为,人类推理主要作为一种社会过程而进化,知识通过不同观点之间的对抗性推理和交流而产生。实证研究表明,群体在广泛推理任务中的表现优于个体,这得益于信息的汇集、信心的校准以及通过不同视角之间平衡的轮流发言所展现的集体智慧。源于专业知识和个性特征差异的认知多样性能够增强问题解决能力,尤其是在存在真实异议的情况下。这些发现共同表明,通过互动以及整合不同的观点,强大的推理能力得以形成,而包括验证和回溯在内的关键推理策略,或许可以通过模拟角色之间的对话来实现。 |
| While diversity and debate contribute directly to collective intelligence, many theories further suggest that individuals reason better when they simulate this capacity. A single, self-centered perspective can lead to systematic biases in reasoning; if individuals effectively simulate multiple, self-distanced perspectives with their minds, as in dialectical thinking, this can reduce decision biases within them23, 24, 25. The "social brain hypothesis" suggests that higher-order intelligence primarily evolved to meet the cognitive demands of processing and simulating social interactions26, 27. Individuals who simulate others' differing perspectives through improved "theory-of-mind" capabilities enhance collective team performance18. Furthermore, theorists have argued that individual reason itself emerged from a simulation of collective discourse. Bakhtin's notion of the "dialogic self" and Cooley and Mead's theory of the "looking glass self" argue that human thought itself takes the form of an internalized conversation among multiple perspectives28, 29, 30, Mead2022-rw. Even in the history of artificial intelligence, Minsky conceptualized intelligence as an emergent property of interacting cognitive agents, or a "Society of Mind"31. Therefore, whether AI systems directly simulate multi-agent discourse or simulate minds that, in turn, simulate multi-agent discourse, we propose that reasoning models like DeepSeek-R1 improve reasoning via "society of thought"---implicit simulations of multi-agent-like interactions between diverse perspectives that give rise to them. We use the term to denote text generation that simulates social exchange among multiple perspectives to increase the collective diversity of ideas through conversational roles that put them in competition. Without deploying separate models prompted to interact with one another32, 33, 34, we suggest that behaviourally similar conversations between diverse perspectives occur and are leveraged within reasoning models. | 尽管多样性和辩论直接促进了集体智慧,但许多理论进一步指出,当个体模拟这种能力时,他们的推理能力会更强。单一的、以自我为中心的观点可能会导致推理中的系统性偏差;如果个体能够有效地在脑海中模拟多个、自我疏离的观点,就像辩证思维那样,这可以减少他们自身的决策偏差23、24、25。社会脑假说认为,高阶智力主要是在满足处理和模拟社会互动的认知需求的过程中进化而来的26、27。通过提升"心理理论"能力来模拟他人不同观点的个体,能够提升团队的整体表现18。此外,理论家们还主张,个体的推理能力本身是从对集体讨论的模拟中发展而来的。巴赫金的"对话自我"概念以及库利和米德的"镜中自我"理论认为,人类思维本身是以多种视角之间的内部对话形式存在的28, 29, 30, 米德2022-rw。甚至在人工智能的历史中,明斯基也将智能视为相互作用的认知代理的涌现属性,即"心智社会"31。 因此,无论人工智能系统是直接模拟多代理对话,还是模拟那些反过来模拟多代理对话的心智,我们提出像 DeepSeek-R1 这样的推理模型通过"思想社会"------即不同视角之间类似多代理互动的隐性模拟来改进推理,这些视角由此产生。我们用这个术语来表示模拟多个视角之间社会交流的文本生成,通过让它们相互竞争的对话角色来增加集体思想的多样性。无需部署单独的模型来相互提示32, 33, 34,我们建议在推理模型内部会发生行为上类似的不同视角之间的对话,并加以利用。 |
| Reasoning models like DeepSeek-R1 develop reasoning abilities through reinforcement learning, which iteratively compensates reasoning behaviour that yields correct answers. Following these performance improvements, debates have naturally arisen about what kinds of behaviours contribute to better reasoning performance. While earlier studies focus on how the model learns to scale test-time computations and generate longer reasoning traces35, 2, merely increasing trace length does not account for the observed improvements in reasoning capabilities. This suggests that qualitative changes in reasoning structure matter more than quantitative scaling alone36, 35, 37. Recent analyses pinpoint behavioural patterns that improve reasoning accuracy, such as verification of earlier assumptions, backtracking, and exploration of alternatives4, 8, 36, 35, 37. Mechanistic interpretability research has shown that features in language models such as the frequent use of words like "wait," "but," and "however"---are associated with these behaviours38, 39, 40, 41. The characteristics of these features, however, such as their prevalence in social and conversational settings, have rarely been explored. Research in other contexts has suggested that the simulation of multi-agent conversations can boost accuracy and divergent thinking in LLMs42, 43, 44, 45, 46, 34, 47. While LLMs can exhibit cognitive biases that hinder reasoning, the simulation of interaction between different perspectives could mitigate biases when verified through checks and balances48, 34, 49. This leads us to hypothesize that reinforcement learning may systematically select and reward behaviour patterns that resemble multi-agent interactions within reasoning models, and these simulated interactions enable models to reason effectively. Here we investigate the prevalence of reasoning traces of DeepSeek-R1, as well as QwQ-32B, that mimic simulated social interactions, quantifying how conversational behaviours, socio-emotional roles, and diversity of implicit agent "perspectives" contribute to reasoning performance. We first identify whether conversational behaviours and socio-emotional roles---hallmarks of human dialogue such as questioning, perspective taking, and reconciliation---are present in DeepSeek-R1's and QwQ-32B's reasoning traces. Then we test whether conversational behaviour contributes to reasoning performance. Based on the mechanistic interpretability method applied to DeepSeek-R1's distilled model (DeepSeek-R1-Llama-8B), we find that steering features associated with a discourse marker, such as expressing surprise in conversational contexts, improves reasoning accuracy both directly and indirectly through the facilitation of cognitive strategies. | 像 DeepSeek-R1 这样的推理模型通过强化学习来培养推理能力,该过程会反复补偿能得出正确答案的推理行为。随着性能的提升,关于哪些行为有助于提高推理能力的争论自然就出现了。早期的研究主要关注模型如何在测试时学习扩展计算量以及生成更长的推理路径 35, 2,但仅仅增加推理路径的长度并不能解释所观察到的推理能力的提升。这表明推理结构的质变比单纯的量变更重要 36, 35, 37。最近的分析指出了能提高推理准确性的行为模式,比如对早期假设的验证、回溯以及对替代方案的探索 4, 8, 36, 35, 37。机制可解释性研究显示,语言模型中的某些特征,比如频繁使用"等待"、"但是"和"然而"等词,与这些行为有关 38, 39, 40, 41。然而,这些特征的特性,比如它们在社交和对话场景中的普遍性,却很少被探究。在其他情境下的研究已表明,模拟多智能体对话能够提升大型语言模型的准确性和发散性思维能力42、43、44、45、46、34、47。尽管大型语言模型可能会表现出妨碍推理的认知偏差,但通过制衡机制验证不同视角之间的交互模拟能够减轻这些偏差48、34、49。这使我们推测,强化学习可能会系统地选择和奖励类似于推理模型中多智能体交互的行为模式,而这些模拟交互使模型能够有效地进行推理。 在此,我们探究了 DeepSeek-R1 以及 QwQ-32B 中模拟社交互动的推理痕迹的普遍性,量化了对话行为、社会情感角色以及隐含智能体"视角"的多样性对推理性能的贡献。首先,我们确定 DeepSeek-R1 和 QwQ-32B 的推理痕迹中是否存在对话行为和社会情感角色------诸如提问、换位思考和和解等人类对话的显著特征。然后,我们测试会话行为是否有助于推理表现。基于应用于 DeepSeek-R1 精简模型(DeepSeek-R1-Llama-8B)的机制可解释性方法,我们发现与话语标记相关的引导特征,例如在会话情境中表达惊讶,能直接和间接地通过促进认知策略来提高推理准确性。 |
| Next, we analyze the diversity of reasoning "perspectives" or simulated voices within DeepSeek-R1's and QwQ-32B's reasoning traces. Literature suggests that LLM reasoning can fail if models do not engage in meaningful disagreement and instead conform to misleading initial claims through pleasant, "sycophantic" conversations that propagate incorrect assumptions and knowledge49, 50, 51. Successful reasoning models may therefore exhibit disagreement driven by diversity in simulated perspectives, expressed through distinct personalities and expertise to avoid the "echo chamber" that leads to wrong answers. Therefore, we analyze reasoning traces using LLM-as-judge to accurately identify distinct voices underlying conversation. We find that DeepSeek-R1 and QwQ-32B display much greater personality and expertise diversity than non-reasoning models within their reasoning traces, presumably to maximize the benefits of multi-agent-like interaction through diversification. We further find that steering a conversational feature in a model's activation space leads to the activation of a more diverse range of personality- and expertise-related features. Finally, we conduct a controlled reinforcement learning experiment to examine the role of conversational behaviours. We focus on self-taught reinforcement learning that rewards only accuracy and correct formatting (i.e., wrapping the thinking process between <think> and </think>), the common approach for improving modern language models' reasoning capabilities4. Based on a symbolic arithmetic task (Countdown game)8, 52, as well as a misinformation identification task, we apply reinforcement learning that rewards reasoning traces leading to accurate answers on open-source LLMs. Interestingly, experiments reveal that the base model can spontaneously develop conversational behaviours---such as self-questioning and perspective shifts---when rewarded solely for reasoning accuracy, without any explicit training signal for dialogue structure. Moreover, following methods of prior ablation research8, we observe that initially fine-tuning these models for conversational structure leads to faster accuracy improvements, outperforming both their baseline counterparts and models fine-tuned with "monologue-like" reasoning, particularly during the early stages of training in two distinct model systems (Qwen-2.5-3B and Llama-3.2-3B). These results suggest that conversational scaffolding facilitates the discovery and refinement of reasoning strategies during reinforcement learning. | 接下来,我们分析 DeepSeek-R1 和 QwQ-32B 推理轨迹中推理"视角"或模拟声音的多样性。文献表明,如果模型不进行有意义的争论,而是通过令人愉快的、"谄媚"的对话来顺从误导性的初始主张,从而传播错误的假设和知识,那么 LLM 推理可能会失败 49, 50, 51。因此,成功的推理模型可能会通过不同的模拟视角来展现分歧,通过不同的个性和专长来避免导致错误答案的"回音室"效应。因此,我们使用 LLM 作为裁判来分析推理轨迹,以准确识别会话背后的不同声音。我们发现,DeepSeek-R1 和 QwQ-32B 在其推理过程中展现出比非推理模型更显著的个性和专业知识多样性,这可能是为了通过多样化来最大化类似多智能体交互的好处。我们还发现,在模型的激活空间中引导对话特征会激活更多与个性和专业知识相关的特征。 最后,我们进行了一项受控的强化学习实验,以考察对话行为的作用。我们专注于仅奖励准确性和正确格式(即在 <think> 和 </think> 之间包裹思考过程)的自教式强化学习,这是提高现代语言模型推理能力的常见方法。基于一个符号算术任务(倒计时游戏)以及一个错误信息识别任务,我们在开源的大语言模型上应用强化学习,奖励那些能得出准确答案的推理过程。有趣的是,实验表明,当仅奖励推理准确性而没有任何关于对话结构的明确训练信号时,基础模型能够自发地发展出诸如自我提问和视角转换之类的对话行为。此外,依照先前消融研究8 的方法,我们发现,最初对这些模型进行对话结构的微调能够更快地提升准确率,在两个不同的模型系统(Qwen-2.5-3B 和 Llama-3.2-3B)的训练早期阶段,其表现优于相应的基线模型以及采用"独白式"推理进行微调的模型。这些结果表明,在强化学习期间,对话式引导有助于发现和优化推理策略。 |
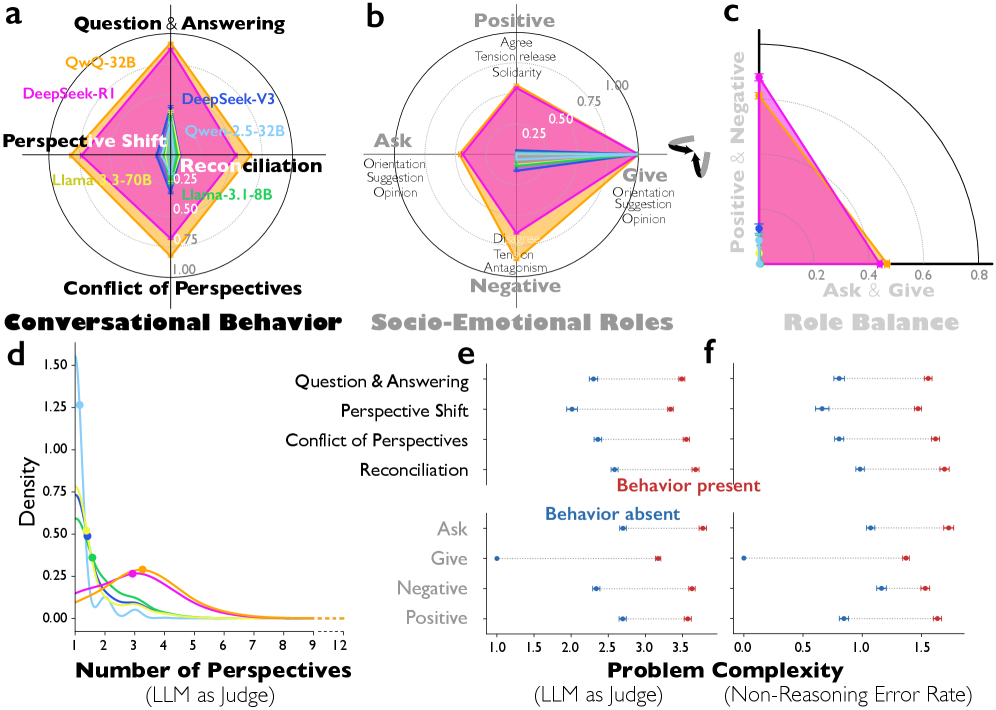
Fig. 1: Conversational behaviours and Bales' socio-emotional roles in chain-of-thought reasoning. a, Proportion of reasoning traces containing each conversational behaviour (question answering, perspective shift, conflict of perspectives, and reconciliation). b, Proportion of Bales' twelve socio-emotional roles expressed in reasoning traces, grouped into four higher-level categories: ask versus give information, and positive versus negative emotional roles (see Extended Data Fig. 3 for definitions of all twelve roles). c, Jaccard index measuring the balance of each socio-emotional role pair, defined as the number of reasoning traces containing both roles divided by the number containing either role (i.e., ask & give; positive & negative). d, Distribution of the number of distinct perspectives in reasoning traces, identified using an LLM-as-judge. e, Differences in problem complexity by the presence of conversational behaviours and higher-level socio-emotional roles in DeepSeek-R1, measured on a seven-point Likert scale (1 = extremely easy; 7 = extremely difficult) using an LLM-as-judge. Points indicate mean complexity for traces where the behaviour or role is present (red) or absent (blue). f, Differences in problem complexity by the presence of conversational behaviours and socio-emotional roles in DeepSeek-R1, measured by instruction-tuned (non-reasoning) models' error rates on the same problems (see Methods: Measurements). Error bars indicate 95% confidence intervals.图 1:对话行为与贝尔斯的社会情感角色在链式思维推理中的表现。a,包含每种对话行为(问答、视角转换、视角冲突和视角调和)的推理痕迹的比例。b,贝尔斯十二种社会情感角色在推理痕迹中表达的比例,分为四个更高级别的类别:询问与提供信息,以及积极与消极情感角色(所有十二种角色的定义见扩展数据图 3)。c,衡量每对社会情感角色平衡的杰卡德指数,定义为同时包含这两种角色的推理痕迹数量除以包含任一角色的推理痕迹数量(即询问与提供信息;积极与消极)。d,使用 LLM 作为裁判识别的推理痕迹中不同视角数量的分布。e,DeepSeek-R1 中对话行为和更高级别的社会情感角色的存在对问题复杂性的影响,使用 LLM 作为裁判,以七点李克特量表衡量(1 = 极易;7 = 极难)。点表示存在(红色)或不存在(蓝色)特定行为或角色的轨迹的平均复杂度。f,DeepSeek-R1 中对话行为和社交情感角色的存在与否对问题复杂度的影响,通过指令调优(非推理)模型在相同问题上的错误率来衡量(见方法:测量)。误差线表示 95% 的置信区间。
Discussion
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Our findings suggest that reasoning models like DeepSeek-R1 do not simply generate longer or more elaborate chains of thought. Rather, they exhibit patterns characteristic of a social and conversational process generating "societies of thought"---posing questions, introducing alternative perspectives, generating and resolving conflicts, and coordinating diverse socio-emotional roles. These interactional patterns rarely occur in non-reasoning models across different model sizes (671B, 70B, 32B, 8B), even when controlling for reasoning trace length, suggesting that reasoning optimization introduces an intrinsic social structure within the reasoning process itself rather than merely increasing text volume. The model appears to reason by simulating internal societies, structuring thought as an exchange among interlocutors rather than as a single uninterrupted voice. The implication here is that social reasoning emerges autonomously through RL as a function of its consistent ability to produce correct answers, rather than through explicit human supervision or fine-tuning. This structure does not appear to be merely stylistic. Conversational behaviours and socio-emotional roles are more frequently activated when DeepSeek-R1 faces more difficult problems, and they explain a substantial portion of the accuracy advantage over non-reasoning models. Steering experiments provide evidence that conversational markers are tied to reasoning performance. When we amplify a feature associated with conversational surprise---a discourse marker signaling perspective shift and constrast---accuracy on multi-step reasoning tasks doubles. Structural equation modeling reveals that conversational steering is associated with accuracy through both direct effects and indirect pathways mediated by cognitive strategies previously identified as central to reasoning, including verification, backtracking, subgoal setting, and backward chaining. This suggests that the social structure of reasoning might not be epiphenomenal but mechanistically implicated in how the model explores solution spaces and deploys effective problem-solving strategies. | 我们的研究结果表明,像 DeepSeek-R1 这样的推理模型并非只是生成更长或更复杂的思维链。相反,它们展现出一种社会和对话过程的特征模式,即生成"思想社会"------提出问题、引入不同观点、产生并解决冲突以及协调各种社会情感角色。这些交互模式在不同规模的非推理模型(6710 亿、700 亿、320 亿、80 亿)中很少出现,即使在控制推理痕迹长度的情况下也是如此,这表明推理优化在推理过程本身中引入了一种内在的社会结构,而不仅仅是增加文本量。该模型似乎通过模拟内部社会来进行推理,将思维结构化为对话者之间的交流,而非单一的不间断的声音。这里的意思是,社会推理是通过强化学习自主产生的,这是其持续产生正确答案的能力所导致的,而非通过明确的人类监督或微调实现的。 这种结构似乎并非仅仅是风格上的。当 DeepSeek-R1 面临更难的问题时,对话行为和社交情感角色会更频繁地被激活,这解释了其相对于非推理模型的准确性优势的很大一部分原因。引导实验提供了证据,表明对话标记与推理表现相关联。当我们放大与对话中的意外相关的特征------一种表示视角转变和对比的语篇标记时,多步推理任务的准确率翻了一番。结构方程模型表明,对话引导通过直接效应和间接途径与准确性相关联,这些间接途径由先前确定为推理核心的认知策略所介导,包括验证、回溯、子目标设定和反向推理。这表明推理的社会结构可能并非是附带现象,而是与模型如何探索解决方案空间和部署有效的解决问题策略有着机制上的关联。 |
| We further find that this interactional organization is supported by diversity among multiple implicit "voices" within reasoning traces. These voices vary systematically in personality traits and domain expertise, and mechanistic interpretability analyses corroborate that models activate more diverse personality- and expertise-related features when steered toward conversational markers. This pattern suggests that findings from human team research---where diversity in socially oriented traits such as extraversion and neuroticism enhances collective performance, whereas diversity in task-oriented traits such as conscientiousness can impair coordination and efficiency21, 65---may offer a useful lens for interpreting language models' collective reasoning behaviours. Most R1 reasoning personas were surprisingly disciplined and hard-working! Reinforcement learning (RL) experiments further support the functional role of conversational structure. Models fine-tuned on multi-agent dialogues learn to reason more effectively than models fine-tuned only on correct, monologue-like reasoning traces. The benefit therefore lies not in the correctness of initial reasoning but in the procedural scaffolding provided by conversational organization. Although these experiments used relatively small 3B-parameter models (Qwen-2.5-3B and Llama-3.2-3B) on simple arithmetic tasks and misinformation detection tasks, the results suggest that even minimal social structuring within reasoning traces can accelerate the emergence of generalizable reasoning behaviour. | 我们进一步发现,这种交互组织是由推理痕迹中多个隐含"声音"的多样性所支持的。这些声音在个性特征和领域专业知识方面存在系统性的差异,机制可解释性分析证实,当引导模型朝向对话标记时,模型会激活更多与个性和专业知识相关的多样化特征。这种模式表明,来自人类团队研究的发现------在诸如外向性和神经质等社交倾向特质方面的多样性能够提升集体表现,而在诸如尽责性等任务导向特质方面的多样性则可能损害协调性和效率 21, 65------或许为解读语言模型的集体推理行为提供了一个有用的视角。大多数 R1 推理角色出人意料地自律且勤奋! 强化学习(RL)实验进一步证实了对话结构的功能作用。在多智能体对话上进行微调的模型比仅在正确、类似独白的推理轨迹上进行微调的模型能更有效地进行推理。因此,其优势不在于初始推理的正确性,而在于对话组织所提供的程序性支撑。尽管这些实验使用的是相对较小的 30 亿参数模型(Qwen-2.5-3B 和 Llama-3.2-3B),在简单的算术任务和错误信息检测任务上进行测试,但结果表明,即使推理轨迹中存在最简单的社会结构,也能加速通用推理行为的出现。 |
| Collectively, these findings suggest the benefits of studying "social scaling" in reasoning-optimized models. As their test-time computations expand, reasoning traces evolve from isolated monologues into structured dialogues among differentiated internal perspectives. High-performing reasoning thus seems to depend on how attention, role-taking, and conflict resolution are coordinated within emergent "societies of thought." Our goal is not to take sides on whether reasoning model traces should be regarded as discourse among simulated human groups or a computational mind's simulation of such discourse. Indeed, as we note above, even this distinction becomes fundamentally unclear as some theories of cognition posit how mature individual minds develop from simulations of multi-agent interaction. Nevertheless, alignments between our findings on successful reasoning models and prior literature on successful human teams (e.g., diverse personality traits lead to successful collaborations) suggest that principles governing effective group collaboration may offer valuable insights for interpreting and engineering reasoning behaviours in language models. This perspective extends long-standing research on human team collaboration, where group composition and diversity are known to shape collective intelligence through variations in personality and expertise16, 17, 18, 19, 11, 20, 21 . Analogous dynamics within AI systems remain largely unexplored. Early investigations of human--AI collaboration70 have begun to characterize this emerging domain, but how diversity and coordination operate within the reasoning traces of large language models remains an open question. DeepSeek-R1's and QwQ's internal reasoning patterns suggest that such models may already self-organize a productive heterogeneity of perspectives, implying that diversity could be as fundamental to artificial reasoning as it is to human collaboration and collective dominance. A growing trend in AI involves agentic architectures that deploy multiple agents engaged in more complex configurations than single-channel debate, including hierarchy, complex networks and even entire institutions of interacting agents71, 72, 42, 43, 44, 45, 46, 34. Our work suggests the importance of exploring alternative structures, but also inhabiting them with diverse perspectives, personalities, and specialized expertise that drive complementarity and collective success in the human social world. Understanding how diversity and social scaffolding interact could shift how we conceptualize large language models, from solitary problem-solving entities toward collective reasoning architectures, where intelligence arises not merely from scale but the structured interplay of distinct voices. | 综合来看,这些发现表明研究推理优化模型中的"社会扩展"是有益的。随着测试时计算量的增加,推理轨迹从孤立的独白演变为不同内部视角之间的结构化对话。因此,高性能推理似乎取决于在新兴的"思维社会"中如何协调注意力、角色扮演和冲突解决。我们的目标并非在于判定推理模型的轨迹应被视为模拟的人类群体之间的交流,还是计算思维对这种交流的模拟。实际上,正如我们上文所指出的,随着一些认知理论提出成熟个体思维是如何从多主体互动的模拟中发展而来,这种区分从根本上变得模糊不清。然而,我们关于成功推理模型的研究结果与先前关于成功人类团队的文献(例如,多样化的个性特征有助于成功的合作)之间的契合表明,有效团队协作的原则或许能为解读和设计语言模型中的推理行为提供宝贵的见解。这种视角拓展了长期以来关于人类团队协作的研究,其中团队构成和多样性通过个性和专业知识的差异塑造集体智慧是众所周知的16, 17, 18, 19, 11, 20, 21。而在人工智能系统内部的类似动态机制仍很大程度上未被探索。关于人机协作的早期研究70 已经开始对这一新兴领域进行描述,但大型语言模型的推理轨迹中多样性与协调性如何运作仍是一个悬而未决的问题。DeepSeek-R1 和 QwQ 的内部推理模式表明,此类模型可能已经能够自我组织出富有成效的视角多样性,这意味着多样性对于人工智能推理的重要性可能与之对于人类协作和集体优势的重要性一样重要。 人工智能领域的一个日益增长的趋势是采用代理架构,部署多个代理参与比单通道辩论更复杂的配置,包括层级结构、复杂网络甚至由交互代理组成的整个机构71, 72, 42, 43, 44, 45, 46, 34。我们的工作表明,探索替代结构很重要,但同时也要让这些结构充满多样化的视角、个性和专业技能,以推动人类社会中的互补性和集体成功。理解多样性和社会支持结构如何相互作用,可能会改变我们对大型语言模型的认知,从孤立的问题解决实体转向集体推理架构,在这种架构中,智能的产生不仅源于规模,还源于不同声音的结构化互动。 |