文章目录
- 一、什么是Flink?
-
- [1. 快速开始](#1. 快速开始)
-
- [1.1 下载Flink](#1.1 下载Flink)
- [1.2 启动或停止集群](#1.2 启动或停止集群)
- [1.3 提交任务](#1.3 提交任务)
- [1.4 查看任务](#1.4 查看任务)
- [2. k8s部署](#2. k8s部署)
-
- [2.1 版本选择](#2.1 版本选择)
- [2.2 部署](#2.2 部署)
- 二、Kafka到Hive
-
- [1. 创建Flink项目骨架](#1. 创建Flink项目骨架)
- [2. 接入kafka](#2. 接入kafka)
- [3. 写入文件系统](#3. 写入文件系统)
-
- [3.1 csv](#3.1 csv)
- [3.2 json](#3.2 json)
- [3.3 parquet(Hive储存格式)](#3.3 parquet(Hive储存格式))
- [4. 代码实现](#4. 代码实现)
- [5. 运行](#5. 运行)
- 三、Hive查看
-
- [1. 新建外部表](#1. 新建外部表)
- [2. 由于是外部新增文件,需要hive感知到](#2. 由于是外部新增文件,需要hive感知到)
- [3. 查询今天100条数据](#3. 查询今天100条数据)
- [4. 好家伙查了两分半,别着急,我们下次讲Starrocks给它提提速](#4. 好家伙查了两分半,别着急,我们下次讲Starrocks给它提提速)
一、什么是Flink?
Apache Flink 是 Apache 基金会顶级开源项目,是用于无界 / 有界数据流的分布式有状态计算引擎,核心优势是流批一体、高吞吐低延迟、精确一次语义与完善的状态和时间管理,可部署在 YARN、K8s 等主流集群,广泛用于实时计算、ETL、事件驱动应用等场景。
批计算本身就是一种特殊的流计算,批和流本身就是相辅相成的。
- Batch Computing: Flink Hive Spark
- Stream Computing: Flink
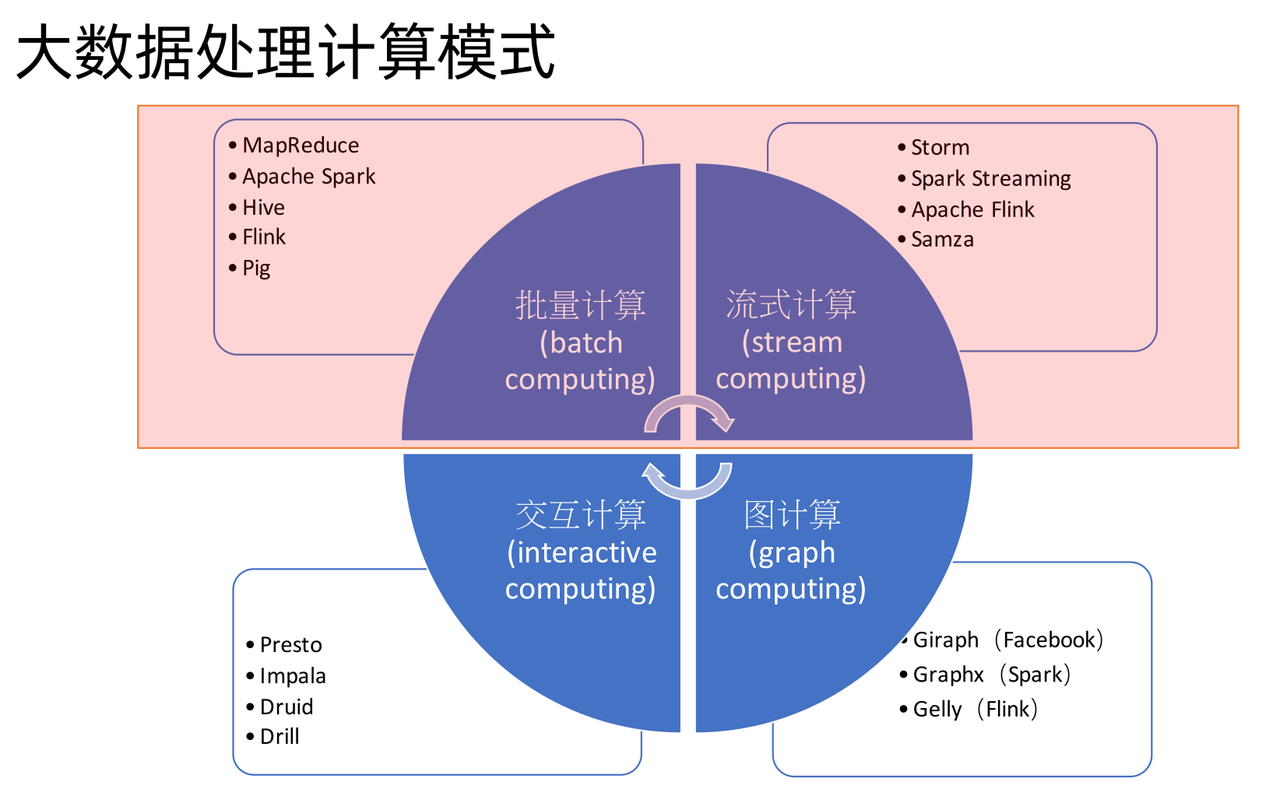
Storm:消息传输可能重复
Spark Streaming: 以固定时间间隔(如几秒钟)处理一段段的批处理作业(微批处理)
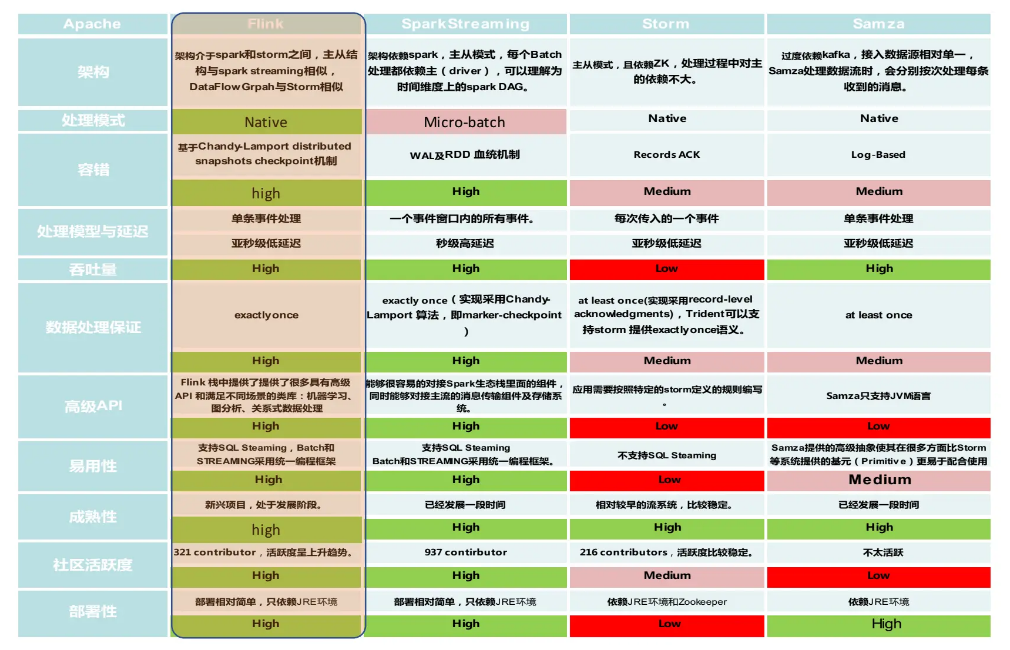
Flink:真正的流处理框架(DataFlow Model)
1. 快速开始
1.1 下载Flink
You need to have Java 11 installed,Apache Flink 1.20.3
1.2 启动或停止集群
bash
./bin/start-cluster.sh
./bin/stop-cluster.sh1.3 提交任务
bash
./bin/flink run examples/streaming/WordCount.jar1.4 查看任务
2. k8s部署
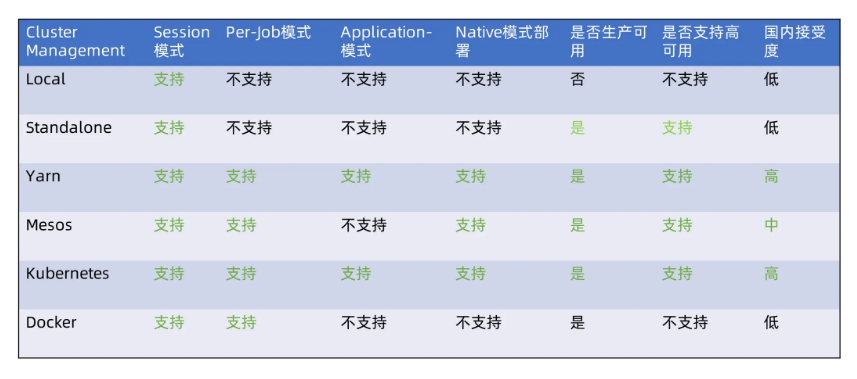
不建议Yarn,一个公司同时维护Hadoop集群和Kubernetes集群,Double人力成本。Hadoop已经被蚕食的差不多了,HDFS被JFS取代,Map/Reduce被Spark取代,Yarn被Kubernetes取代。
2.1 版本选择
后期我们还会使用CDC,建议版本为
- Flink CDC: 3.5.0
- Flink: 1.20.3
| Flink® CDC Version | Flink® Version |
|---|---|
| 1.0.0 | 1.11.* |
| 1.1.0 | 1.11.* |
| 1.2.0 | 1.12.* |
| 1.3.0 | 1.12.* |
| 1.4.0 | 1.13.* |
| 2.0.* | 1.13.* |
| 2.1.* | 1.13.* |
| 2.2.* | 1.13., 1.14. |
| 2.3.* | 1.13., 1.14. , 1.15., 1.16. |
| 2.4.* | 1.13., 1.14. , 1.15., 1.16., 1.17.* |
| 3.0.* | 1.14., 1.15. , 1.16., 1.17., 1.18.* |
| 3.1.* | 1.16., 1.17. , 1.18., 1.19. |
| 3.2.* | 1.17., 1.18. , 1.19., 1.20. |
| 3.3.* | 1.19., 1.20. |
| 3.4.* | 1.19., 1.20. |
| 3.5.* | 1.19., 1.20. |
2.2 部署
values.yaml
yaml
# https://artifacthub.io/packages/helm/bitnami/flink/1.4.5?modal=values
global:
security:
## @param global.security.allowInsecureImages Allows skipping image verification
allowInsecureImages: true
image:
registry: docker.io
repository: bitnamilegacy/flink
tag: 1.20.3-debian-12-r5traefik.yaml
yaml
# https://doc.traefik.io/traefik/reference/routing-configuration/kubernetes/crd/http/ingressroute/
apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: flink-ingress-route-http
namespace: flink
spec:
entryPoints:
- web
routes:
- match: Host(`flink.example.top`)
kind: Rule
services:
- name: flink-jobmanager
port: 8081Jenkinsfile
Jenkinsfile
pipeline {
agent {
node {
label 'k8s-node1'
}
}
stages {
stage('Helm部署') {
steps {
sh 'printenv'
sh '''
helm upgrade --install -n flink --create-namespace flink oci://registry-1.docker.io/bitnamicharts/flink --version 1.4.5 -f values.yaml
'''
}
}
stage('配置域名') {
steps {
sh 'printenv'
sh '''
kubectl apply -f traefik.yaml
'''
}
}
stage('配置验证') {
steps {
sh 'printenv'
sh '''
kubectl get ingressroute.traefik.io --all-namespaces
'''
}
}
}
}二、Kafka到Hive
Hive搭建参考之前文章:https://blog.csdn.net/sinat_15906013/article/details/154903213
HomeAssistant接入Kafka参考之前文章:https://blog.csdn.net/sinat_15906013/article/details/147773807
1. 创建Flink项目骨架
bash
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.20.32. 接入kafka
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.3.0-1.20</version>
</dependency>3. 写入文件系统
https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/connectors/table/filesystem/
3.1 csv
https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/connectors/table/formats/csv/
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>3.2 json
https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/connectors/table/formats/json/
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>3.3 parquet(Hive储存格式)
https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/connectors/table/formats/parquet/
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>${flink.version}</version>
</dependency>实际测试下来需要:
parquet依赖avro格式,依赖hadoop hdfs写入
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>${flink.version}</version>
<!-- <scope>compile</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>${flink.version}</version>
<!-- <scope>compile</scope>-->
</dependency>
<!-- Source: https://mvnrepository.com/artifact/org.apache.parquet/parquet-avro -->
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.15.2</version> <!-- 必须与 flink-parquet 使用的版本一致 -->
</dependency>
<!-- Hadoop 依赖(集群运行时,依赖由Flink集群提供) -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.4.2</version>
<!--<scope>provided</scope>--> <!-- 本地运行需要包含 -->
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.4.2</version>
<!--<scope>provided</scope>--> <!-- 本地运行需要包含 -->
</dependency>
<!-- dnsjava 依赖,Hadoop 3.4.2 需要 -->
<dependency>
<groupId>dnsjava</groupId>
<artifactId>dnsjava</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.19.0</version>
</dependency>加入hadoop后没有日志打印了
需要新增文件log4j.properties
# Root logger option
log4j.rootLogger=INFO, console
# Direct log messages to console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
# Flink specific logging
log4j.logger.org.apache.flink=INFO
log4j.logger.org.apache.kafka=INFO
log4j.logger.org.apache.hadoop=WARN4. 代码实现
- 新增HomeAssistantDTO
问豆包生成:解释下HomeAssistant中Kafka消息中的每个字段意思
java
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* 核心标识与状态:entity_id 是实体唯一 ID,state 是核心状态值,attributes 是补充属性;
* 时间戳关键区别:
* last_changed:仅 state 真正变化时更新;
* last_updated:state/attributes 任意变化时更新;
* last_reported:设备主动上报数据时更新;
* 溯源信息:context 记录状态变化的来源和触发者,用于审计和调试。
*
* @see
* @since 1.0.0
*/
@NoArgsConstructor
@AllArgsConstructor
@Data
public class HomeAssistantDTO {
/**
* 核心含义:实体的唯一标识符,是 Home Assistant 中最基础、最核心的字段。
* 格式规则:采用 域.对象ID 的格式(例如 light.living_room、sensor.temperature_kitchen),其中:
* 域(domain):代表实体类型(如 light 灯光、sensor 传感器、switch 开关);
* 对象ID:该类型下的唯一名称,由用户或系统自定义。
* 作用:通过这个 ID 可以精准定位、控制或查询某个具体设备 / 传感器的状态,是操作实体的 "身份证"。
*/
private String entity_id;
/**
* 核心含义:实体的核心状态值,是最常用的字段,通常为简单的字符串 / 数值类型。
* 示例:
* 灯光实体:on / off;
* 温度传感器:25.5;
* 开关实体:unavailable(设备离线)。
* 特点:仅存储核心状态,不包含附加信息,是实体最直观的状态体现。
*/
private String state;
/**
* 核心含义:实体的附加属性集合,是一个 JSON 格式的字符串(你代码中定义为 String 类型,实际是结构化数据序列化后的结果),用于存储 state 之外的补充信息。
* 示例:
* 温度传感器的 attributes 可能包含:unit_of_measurement: "°C"(单位)、friendly_name: "厨房温度"(友好名称)、device_class: "temperature"(设备类型);
* 灯光实体的 attributes 可能包含:brightness: 80(亮度)、color_temp: 350(色温)。
* 作用:扩展 state 的信息维度,存储实体的细节参数,让状态描述更完整。
*/
private String attributes;
/**
* 核心含义:实体的实际状态(state)发生变化的时间戳(字符串格式,通常为 ISO 8601 格式,如 2026-01-21T10:30:00+08:00)。
* 关键区别:仅当 state 的值真正改变时才会更新(例如灯光从 off 变 on),如果只是 attributes 变化,该字段不变。
*/
private String last_changed;
/**
* 核心含义:设备 / 传感器主动上报状态的时间戳。
* 适用场景:主要用于有主动上报机制的设备(如物联网传感器定时上报数据),无论 state 是否变化,只要设备上报了数据,该字段就会更新。
* 与 last_changed 区别:即使 state 没变化(比如温度一直是 25℃,但传感器仍上报),last_reported 也会更新,而 last_changed 不会。
*/
private String last_reported;
/**
* 核心含义:实体的任意数据(state 或 attributes)发生变化的时间戳。
* 关键特点:范围最广 ------ 无论是 state 改变,还是 attributes 改变(如灯光亮度从 80 变 90,state 仍为 on),该字段都会更新。
* 与 last_changed 关系:last_changed 是 last_updated 的子集(state 变化时,两者都会更新;仅 attributes 变化时,只有 last_updated 更新)。
*/
private String last_updated;
/**
* context
* 核心含义:实体状态变化的上下文信息,是一个 JSON 格式的字符串,记录状态变化的 "溯源信息"。
* 包含内容:通常包含:
* id:唯一标识本次状态变更的 UUID;
* user_id:触发变更的用户 ID(如用户手动操作);
* parent_id:关联的上游操作 ID(如自动化触发的变更);
* origin:变更来源(如 local 本地操作、mqtt MQTT 消息触发)。
* 作用:用于追溯状态变化的原因、来源,方便调试和审计(比如排查 "谁 / 什么操作改变了灯光状态")。
*/
private String context;
}- 新增LastUpdatedBucketAssigner根据last_updated分区
Cursor提示词:输出parquet文件的目录是dt=2026-01-21这种的,能否更加last_updated设置分区呢,时间格式 "last_reported": "2026-01-06T13:10:49.663432+00:00",
java
import org.apache.flink.core.io.SimpleVersionedSerializer;
import org.apache.flink.streaming.api.functions.sink.filesystem.BucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.SimpleVersionedStringSerializer;
import java.time.OffsetDateTime;
import java.time.format.DateTimeFormatter;
/**
* 自定义 BucketAssigner
*
* @see
* @since 1.0.0
*/
public class LastUpdatedBucketAssigner implements BucketAssigner<HomeAssistantDTO, String> {
@Override
public String getBucketId(HomeAssistantDTO element, Context context) {
try {
String ts = element.getLast_updated();
OffsetDateTime odt = OffsetDateTime.parse(ts, DateTimeFormatter.ISO_OFFSET_DATE_TIME);
String day = odt.toLocalDate().toString();
return "dt=" + day;
} catch (Exception e) {
// 解析失败时兜底到一个 default 分区
return "dt=unknown";
}
}
@Override
public SimpleVersionedSerializer<String> getSerializer() {
return SimpleVersionedStringSerializer.INSTANCE;
}
}- 主程序
java
import com.alibaba.fastjson.JSON;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.formats.parquet.avro.ParquetAvroWriters;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.OnCheckpointRollingPolicy;
import java.util.Properties;
public class HomeAssistantJob {
public static void main(String[] args) throws Exception {
// 1. 创建 Flink 流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 开启 Checkpoint(关键:保证 Parquet 文件写入的一致性,避免数据丢失/重复)
env.enableCheckpointing(1000); // 30 秒一次 Checkpoint
env.setParallelism(2); // 设置并行度,根据集群资源调整
// 2. 配置 Kafka Source,消费 Kafka 数据
Properties properties = Config.loadConfig();
String bootstrapServers = (String) properties.get("flink.connector.kafka.bootstrap-servers");
String topic = (String) properties.get("flink.connector.kafka.topic");
String path = (String) properties.get("flink.connector.filesystem.parquet.path");
String kafkaGroupId = "flink-home-assistant-group"; // 消费者组 ID
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers(bootstrapServers)
.setTopics(topic)
.setGroupId(kafkaGroupId)
// 初始偏移量:从最早开始消费(集群运行可改为 latest)
.setStartingOffsets(OffsetsInitializer.committedOffsets())
// .setStartingOffsets(OffsetsInitializer.earliest())
// 消息序列化格式(这里 Kafka 中存储的是 JSON 字符串)
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
// 3. 读取 Kafka 数据,转换为 DataStream
DataStream<String> kafkaDataStream = env.fromSource(
kafkaSource,
WatermarkStrategy.noWatermarks(), // 无水印需求,简单配置
"Kafka Home Assistant Source"
);
DataStream<HomeAssistantDTO> homeAssistantStream = kafkaDataStream
.map(jsonStr -> {
// 利用 FastJSON 解析 JSON 字符串(需引入 fastjson 依赖)
return JSON.parseObject(jsonStr, HomeAssistantDTO.class);
})
.name("Convert JSON to Avro");
// 5.1 配置 Parquet 写入器(使用反射方式绑定 POJO)
var parquetWriter = ParquetAvroWriters.forReflectRecord(HomeAssistantDTO.class);
// 5.2 配置文件输出规则(分桶、滚动策略)
FileSink<HomeAssistantDTO> parquetFileSink = FileSink
.forBulkFormat(new Path(path), parquetWriter)
// 分桶策略:按时间分桶(每小时一个目录,格式:yyyy-MM-dd/HH)
// .withBucketAssigner(new DateTimeBucketAssigner<>("'dt='yyyy-MM-dd"))
.withBucketAssigner(new LastUpdatedBucketAssigner())
// 滚动策略:Bulk格式使用 OnCheckpointRollingPolicy
.withRollingPolicy(OnCheckpointRollingPolicy.build())
// 输出文件配置(前缀、后缀)
.withOutputFileConfig(
OutputFileConfig.builder()
.withPartPrefix("home-assistant")
.withPartSuffix(".parquet")
.build()
)
.build();
// 6. 将数据写入 Parquet 文件
homeAssistantStream.sinkTo(parquetFileSink).name("Write to Parquet FileSink");
// 7. 执行 Flink 任务
env.execute("Flink Kafka to Parquet File System Job");
}
}- application.properties配置
properties
# kafka
flink.connector.kafka.bootstrap-servers=
flink.connector.kafka.topic=
# jdbc
flink.connector.jdbc.url=
flink.connector.jdbc.table-name=
flink.connector.jdbc.driver=com.mysql.jdbc.Driver
flink.connector.jdbc.username=
flink.connector.jdbc.password=
# filesystem-csv
flink.connector.filesystem.csv.path=file:///mnt/data/filesystem/csv
# filesystem-json
flink.connector.filesystem.json.path=file:///mnt/data/filesystem/json
# filesystem-parquet
flink.connector.filesystem.parquet.path=file:///home/d/jfs-public/homelab-ods/home-assistant5. 运行
由于Flink任务关闭了,目前kafka消息有两天的积压

文件目前也是到22号
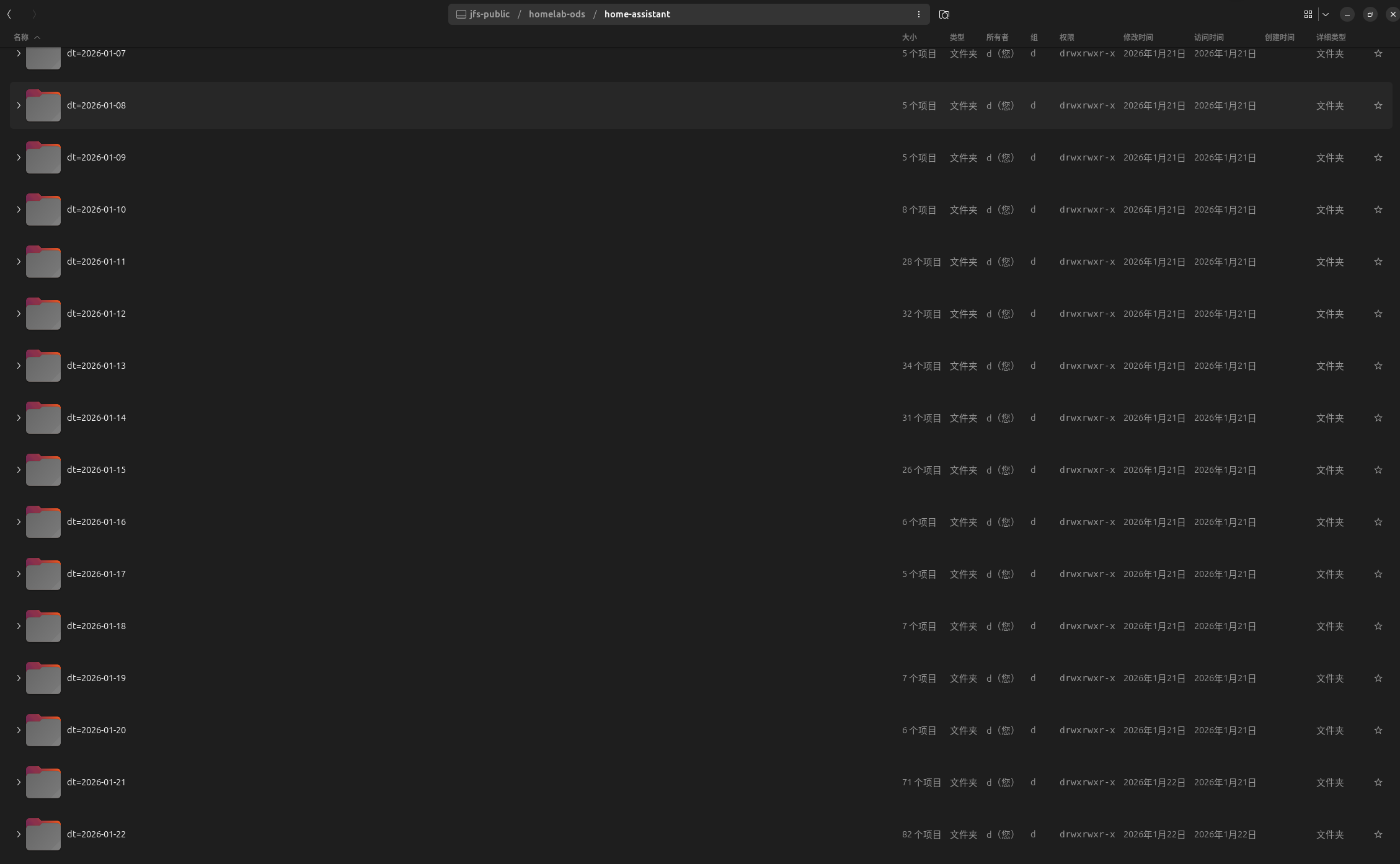
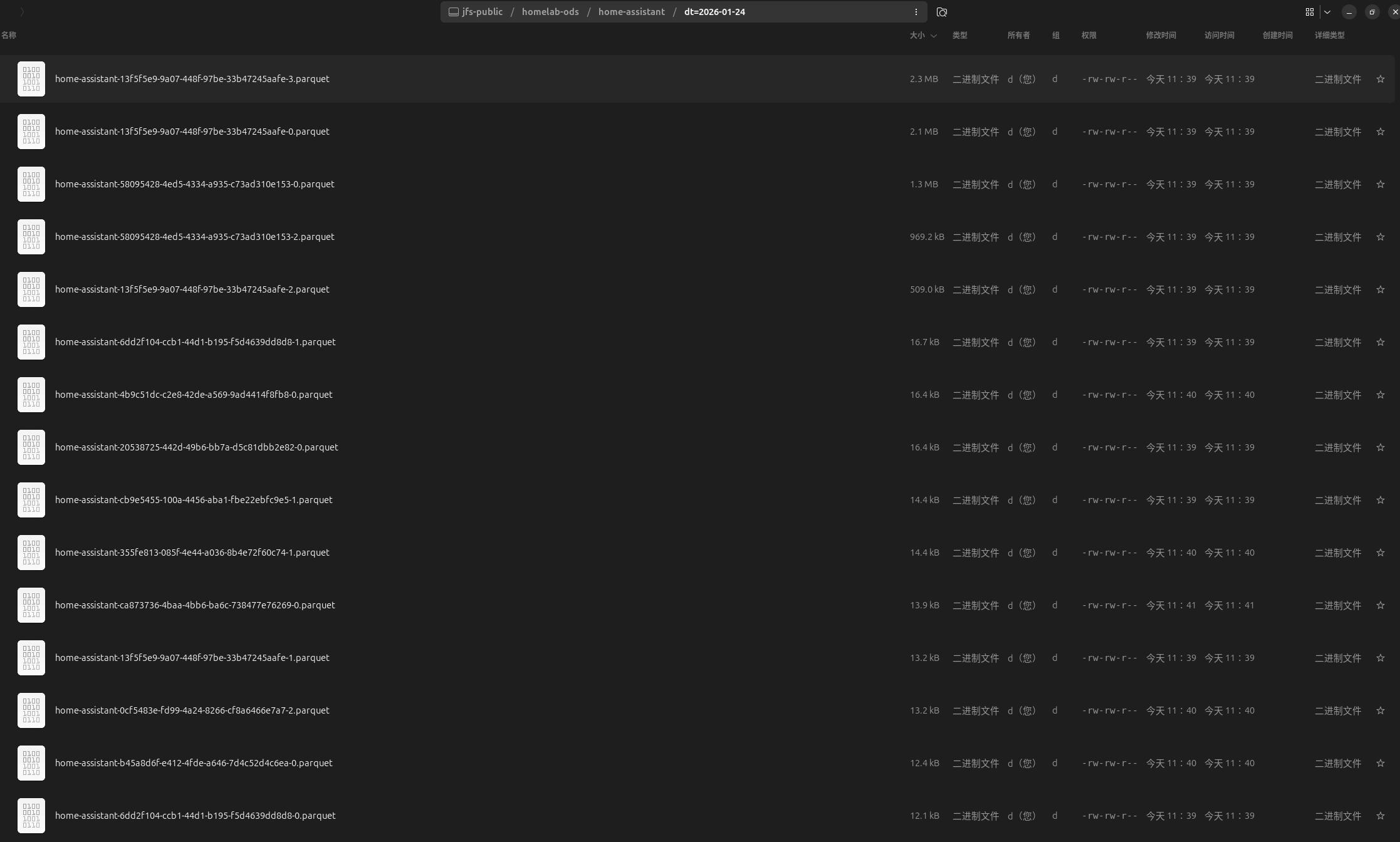
程序启动后一直实时写入中

到24号了
三、Hive查看
1. 新建外部表
sql
create external table if not exists home_assistant(
entity_id string,
state string,
attributes string,
last_changed string,
last_reported string,
last_updated string,
context string
)
partitioned by
(
`dt` string comment 'dt'
)
stored as parquet
location 'jfs://jfs-public/homelab-ods/home-assistant'
tblproperties
(
'comment'='home_assistant'
);2. 由于是外部新增文件,需要hive感知到
sql
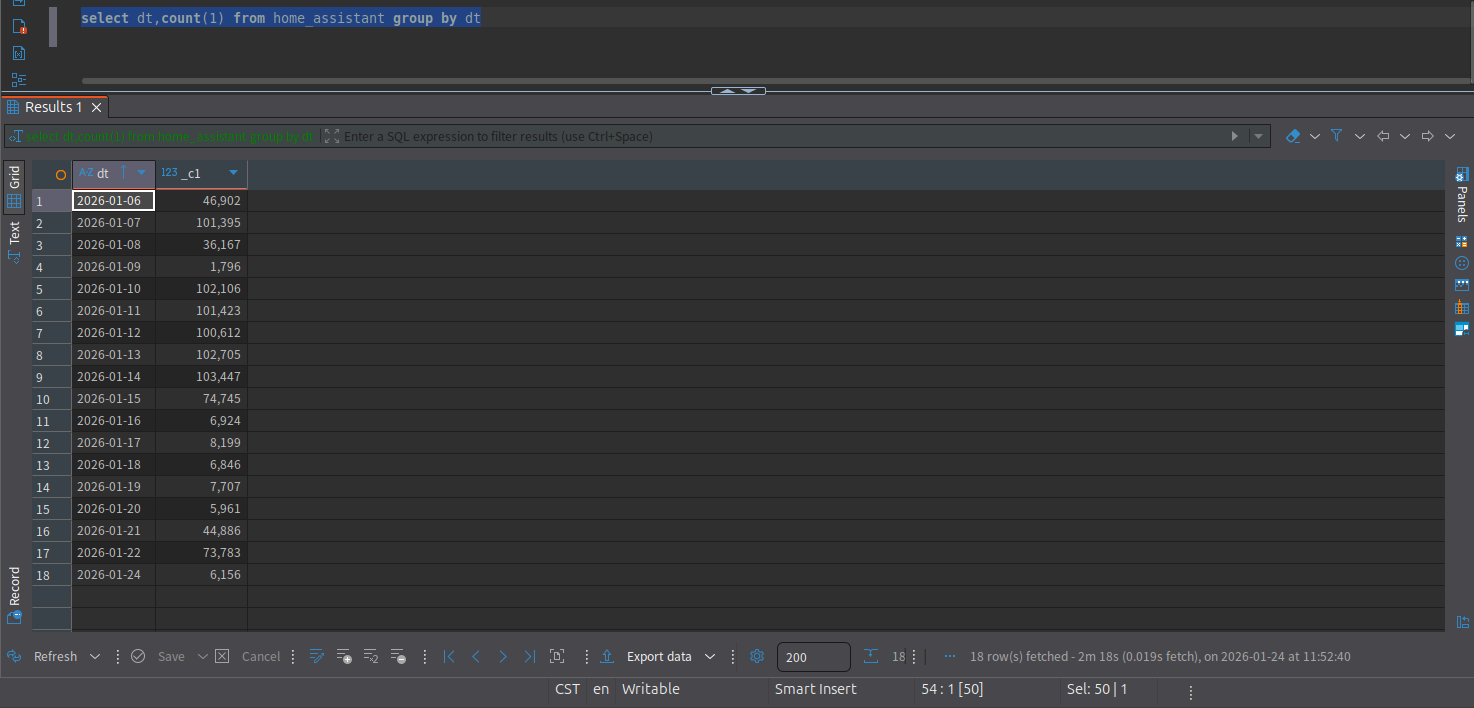
msck repair table home_assistant3. 查询今天100条数据
sql
select * from home_assistant where dt='2026-01-24' limit 100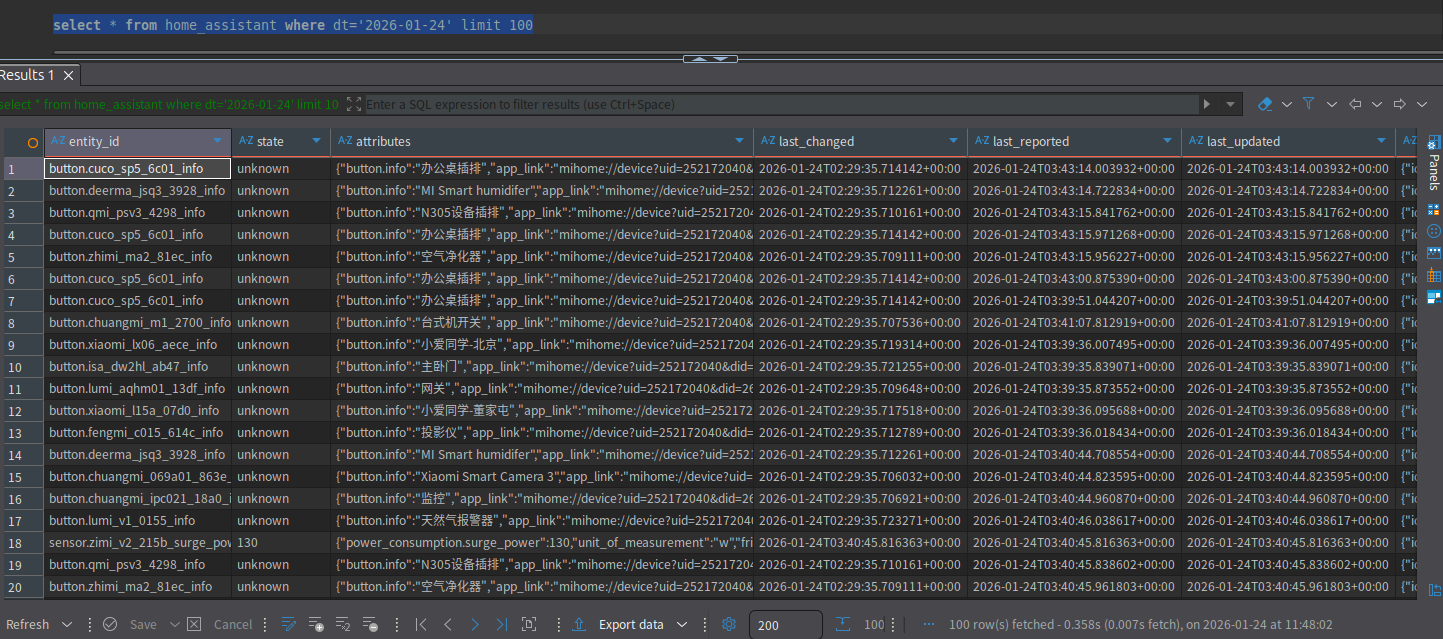
4. 好家伙查了两分半,别着急,我们下次讲Starrocks给它提提速
bash
select dt,count(1) from home_assistant group by dt