摘要
2024年3月,我参与了某大型半导体晶圆制造企业"新一代良率分析大数据平台"的研发工作,在项目中担任系统架构师,负责整体架构设计与技术选型。该企业拥有12英寸晶圆产线,生产工艺涵盖光刻、刻蚀等数百道工序,面临着严重的数据孤岛问题。MES(制造执行系统)、FDC(设备故障侦测)及各类量测设备产生的数据来源异构、格式多样且时效性要求不一,传统单一集成模式难以支撑全流程的良率归因分析。
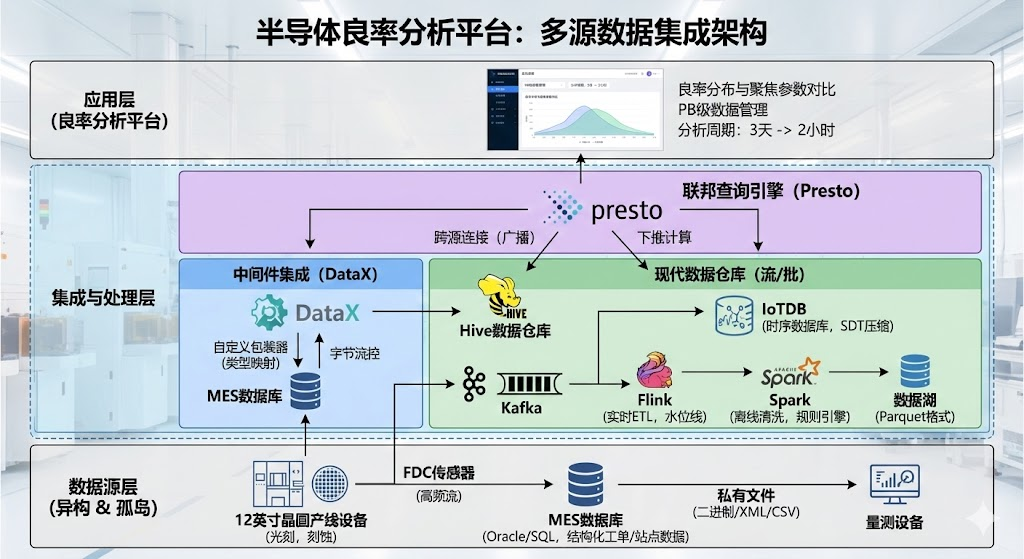
为此,我基于多源数据集成理论,设计了一套混合集成架构:采用基于中间件的DataX技术 屏蔽异构数据库差异,解决了静态业务数据的同步难题;构建了以时序数据库(IoTDB)为核心,结合Flink与Spark 计算引擎的现代数据仓库体系,实现了海量传感器数据的流批一体化处理;引入联邦数据库引擎Presto,实现了跨数据源的秒级关联查询。该平台上线后,成功纳管了PB级生产数据,将良率异常定位周期从3天缩短至2小时,有效支撑了先进制程的良率爬坡。本文将详细论述上述技术的具体应用与实施策略。
正文
一、 项目背景与问题分析
半导体集成电路制造被誉为精密制造的巅峰,其生产流程极长,涉及光刻、薄膜、扩散、刻蚀等七大生产区、数百台高精密设备。我所在的半导体企业随着产能扩张,原有的烟囱式系统架构已无法满足良率提升的需求。在项目启动初期,作为架构师,我深入调研了现状,发现多源数据集成面临三大核心痛点:
第一,数据源极度异构,标准混乱。 核心生产系统MES使用Oracle数据库,存储结构化的工单(Lot)与站点(Step)记录;设备监控系统FDC产生的是每秒百万级写入的高频时序传感器数据;而大量的量测设备(Metrology)输出的则是私有格式的二进制文件或XML/CSV文本。这些数据分散在10多个独立的系统中,缺乏统一的主键与元数据标准。
第二,数据时效性与体量的矛盾。 产线工程师既需要毫秒级的实时设备报警(EAP),又需要跨度长达3个月的全生命周期历史数据进行根因分析(RCA)。传统的关系型数据仓库无法同时满足高吞吐写入和海量历史存储。
第三,跨域查询性能低下。 良率工程师的典型分析场景是:"查找过去一周在光刻机A上加工过的所有晶圆,其对应的良率分布与当时光刻机聚焦深度(Focus)参数的相关性"。这涉及到跨越MES(关系型)和FDC(时序型)的Join操作,原有的人工Excel拼接方式效率极低,严重制约了生产效率。
面对这些挑战,单一的集成技术已无法奏效。经过架构评审,我决定综合运用联邦式、基于中间件、数据仓库三种集成技术,构建一套"逻辑统一、物理分层"的大数据平台。
二、 多源数据集成技术分析
在架构设计阶段,我从理论与适用性两个维度对三种主流技术进行了对比分析:
-
基于中间件的集成 :该技术通过构建统一的包装器(Wrapper)和中介器(Mediator),在应用层屏蔽底层数据源的异构性。其优势在于灵活性高,能以低侵入的方式适配遗留系统,特别适合解决异构数据库之间的数据搬运与协议转换问题。
-
数据仓库技术 :这是最经典的数据集成方式,通过ETL(抽取、转换、加载)将多源数据物理地汇聚到中心存储中。在大数据时代,它演进为"湖仓一体"架构。其优势在于数据质量高、历史可追溯,适合处理海量历史数据的深度挖掘与清洗。
-
联邦数据库系统 :该技术不移动原始数据,而是构建虚拟的全局视图,将查询分发至各源端执行。其优势在于数据自治性好、实时性强 ,适合处理不宜搬迁或需实时获取最新状态的轻量级跨源查询。
基于上述分析,我制定了"中间件负责搬运适配,数仓负责海量存储计算,联邦查询负责统一服务"的总体策略。
三、 多源数据集成在平台中的具体实现
1. 基于DataX中间件实现异构业务数据同步
MES、ERP及良率管理系统(YMS)存储了大量关于产品、工单、机台的静态维度数据,这些数据主要存储在Oracle和SQL Server中。为了将这些数据同步至大数据平台,我选择了阿里巴巴开源的 DataX 作为核心中间件。
在实施过程中,我重点解决了异构类型映射与源端压力控制两个难题。
首先是异构数据类型的映射 。MES系统中的Oracle数据库使用了大量非标准的自定义数据类型,直接通过JDBC同步至Hive时经常出现精度丢失或乱码。为此,我深入研究了DataX的源码,利用其插件化机制开发了定制的Reader插件(Wrapper)。该插件在读取数据前,会通过元数据映射表将Oracle的NUMBER类型精准转换为Hive的DECIMAL类型,并对特殊字符进行转义处理。同时,我配置了DataX的脏数据收集器(Dirty Data Collector),将无法转换的异常记录清洗至临时表,并触发告警,确保了同步任务的健壮性。
其次是同步压力控制。MES是工厂的心脏,全量抽取可能导致生产卡顿。我利用DataX的字节流控功能(Byte Speed),将单个任务的同步速率限制在50MB/s以内。同时,设计了"T+1"的增量同步策略,通过识别工单表的Last_Update_Time字段进行增量抽取,既保证了数据时效性,又将对生产库的影响降至最低。
2. 结合Flink、Spark与TSDB构建现代数据仓库
针对FDC系统产生的海量设备传感器数据(Sensor Data),其特点是写入频率极高(每秒数千万点)且查询主要基于时间范围。传统关系型数仓完全无法支撑,因此我设计了基于IoTDB(时序数据库) + Flink/Spark 的流批一体化数仓。
实时流集成(Flink) :我利用Flink构建了实时ETL通道。设备日志通过Kafka消息队列接入,Flink任务消费数据并进行实时清洗。在这里,我遇到了网络抖动导致数据乱序 的问题。为了解决此问题,我在Flink中引入了Watermark(水位线)机制,允许数据延迟5秒到达,对于迟到超过阈值的数据,通过侧输出流(Side Output)进行单独修正。清洗后的热数据直接写入IoTDB,供产线实时监控使用。
历史批处理(Spark):为了支持长周期的良率归因,我利用Spark引擎每天定时从IoTDB和HDFS中读取数据。由于半导体数据存在大量的噪声(如机台维护期间产生的无效数据),我设计了一套基于Spark SQL的规则引擎,剔除异常值,并将清洗后的数据转换为Parquet列式存储格式,存入数据湖。
存储选型决策 :在选型时,我对比了HBase和国产开源的IoTDB。测试显示,IoTDB针对时间序列数据采用了针对性的旋转门压缩算法(SDT),存储成本仅为HBase的1/10,且查询延迟更低。最终,我们选择了IoTDB作为核心存储底座。
3. 采用Presto实现跨源联邦查询
这是平台对外服务的"最后一公里"。良率工程师需要在一个SQL中同时关联查询MES的工单信息(位于Hive)和FDC的设备曲线(位于IoTDB)。为了实现"逻辑统一",我引入了 Presto 作为联邦查询引擎。
实施中的挑战在于内存溢出(OOM)与查询性能优化。
在项目初期,当工程师尝试将一张千万级的工单表与亿级的传感器表进行Join时,Presto集群经常因为内存耗尽而崩溃。为了解决这个问题,我采取了三项优化措施:
第一,优化Join策略 。利用Presto的Broadcast Join机制,强制将较小的工单表广播到各个计算节点,避免了大表之间的数据Shuffle。
第二,下推计算(Push Down) 。开发了IoTDB的Presto连接器(Connector),将时间范围过滤和聚合操作(如avg, max)下推至IoTDB端执行,Presto层仅处理聚合后的少量数据,大幅减少了网络传输和内存开销。
第三,资源隔离。通过Presto的Resource Group功能,限制单个查询的最大内存使用量和并发数,防止个别烂SQL拖垮整个集群。
通过这些优化,平台实现了跨源关联查询的秒级响应,工程师无需感知底层数据存储在何处,极大提升了分析效率。
四、 实施效果与总结
该大数据平台于2024年初正式上线运行,目前已稳定支撑了工厂两个季度的生产运营。
在数据规模上 ,平台纳管了全厂12个子系统,日处理增量数据超过50TB,累积存储达到PB级。
在业务价值上,跨系统数据的融合使得良率归因分析的时间从过去的3天缩短至2小时。例如,工艺部门通过平台成功发现某型号刻蚀机在特定气压下的良率波动规律,通过参数优化,使该产品的良率提升了1.5%,带来了数千万的经济效益。
总结与展望:
本项目的成功实践表明,在复杂的工业制造场景下,没有一种"万能"的数据集成技术。中间件技术 解决了异构接口的"通",现代数仓技术 解决了海量数据的"存"与"算",联邦查询技术解决了数据应用的"查"。三者有机结合,才能构建出强壮的数据底座。
当然,系统仍存在不足之处。目前对于非结构化的晶圆缺陷图片(AOI Image)主要还是基于文件路径的索引,检索效率较低。未来,我计划引入向量数据库 和多模态大模型技术,实现以图搜图和基于语义的缺陷检索,进一步提升平台的智能化水平。